加州大学团队推出了效率、成功率最优越的策略!4层网络,成功复现了复杂双臂操作
VITA由加州大学戴维斯、加州大学伯克利的研究人员提出,是目前效率、成功率最为优越的流匹配策略之一。最为震撼的是,VITA只使用4层简单MLP网络,便在实机试验当中成功实现了ALOHA复杂双臂操作。VITA的核心设计极为优雅。与传统流/扩散策略从高斯分布开始采样不同,VITA策略以图像分布作为流策略的源,直接流入机器人的动作分布。VITA生成过程无噪声,且不依赖交叉注意力等视觉条件网络,从而简化模

ICLR 2026 论文 VITA,刷新机器人策略效率、简洁性的新高度!
VITA: VIsion-To-Action Flow Matching Policy
VITA由加州大学戴维斯、加州大学伯克利的研究人员提出,是目前效率、成功率最为优越的流匹配策略之一。最为震撼的是,VITA只使用4层简单MLP网络,便在实机试验当中成功实现了ALOHA复杂双臂操作。
VITA的核心设计极为优雅。与传统流/扩散策略从高斯分布开始采样不同,VITA策略以图像分布作为流策略的源,直接流入机器人的动作分布。VITA生成过程无噪声,且不依赖交叉注意力等视觉条件网络,从而简化模型、提升效率。具身智能之心将在这里对VITA进行深入解读。
文章被ICLR 2026录用,代码已在GitHub开源。
- 官网:https://ucd-dare.github.io/VITA/
- 代码:https://github.com/ucd-dare/VITA
- 论文:https://arxiv.org/abs/2507.13231
无噪声流策略
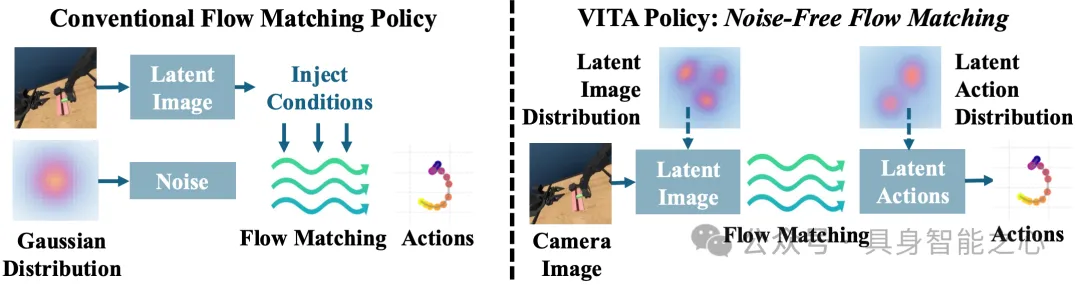
传统流/扩散策略从高斯等简单分布采样,并在去噪过程中反复调用交叉注意力等条件化机制将视觉信息融入生成过程,带来昂贵的时间与空间开销。然而,策略效率对于机器人的实时性策略极为重要。为了解决此痛点,VITA提出了优雅的解决方案,直接将图像分布作为流的源分布,学习从视觉到动作的流。因为流的源已包含视觉信息,生成阶段不再需要反复条件化。
最为惊艳的是,当使用图像向量表示时,VITA把策略简化为向量间的映射,故而使得MLP策略网络成为可能。VITA 是首个能在实机环境中,成功解决 ALOHA 等复杂双臂任务的纯 MLP 策略。
VITA在 ALOHA、AV-ALOHA 与 Robomimic 的 9 个仿真任务和 5 个真实任务进行全面评估。任务涵盖了单臂、双臂、主动视觉等复杂任务。结果表明,MLP实现的VITA在成功率上取得击败或媲美SOTA,且推理速度在不同网络结构(MLP/Transformer)实现下都得到了巨大提升(1.5×–2.3×)。
技术解读
动作、视觉存在巨大的跨模态差异;机器人动作数据稀缺;直接建模两者的流匹配非常困难。在这里我们详细讲解VITA为此提出的技术:包括引入潜动作空间进行跨模态维度匹配,以及名为流潜空间解码(Flow Latent Decoding,FLD)的端到端训练技术。
流匹配需要两端分布的维度相同。然而视觉模态维度往往远远大于动作模态维度。VITA为此引入了潜在动作空间,将机器人动作升高维度,与视觉表征匹配。VITA通过学习动作编码器与解码器构建此潜在动作空间。作者首先尝试了传统的潜空间扩散方法:在图像生成领域,潜空间扩散方法普遍使用冻结的预训练图像潜空间,与扩散模型一同训练。然而此类无法在机器人数据上表现很差。作者认为原因在于动作数据的稀缺性,导致预训练的动作潜空间性能差,且无法在后续的流训练中进行修正。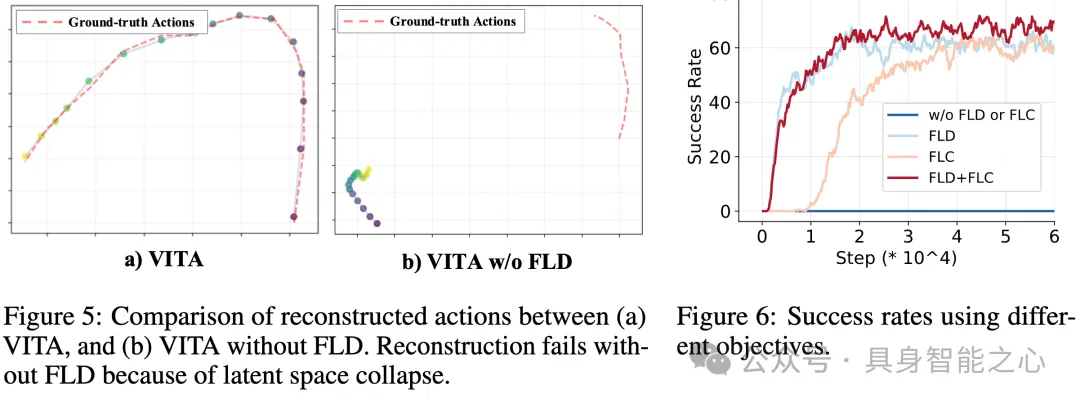
然而,端到端训练同时更新动作的潜空间以及流匹配模型也极具挑战性。文章中提到端到端训练会造成潜在空间塌陷问题,模型完全无法重构潜在动作表示。作者认为潜空间塌陷的原因是:编码器产生的的潜在动作,与流匹配生成的潜在动作,造成的训练-测试差距。训练过程中,动作解码器使用了编码器输出的潜在动作作为流模型的目标;然而,模型推断时在需要求解流匹配ODE(Ordinary Differential Equation)逐步生成潜在动作。
为此作者提出了非常符合直觉的解决方案去弥合此训练-测试差距:**既然测试过程中的动作生成是通过ODE求解来完成的,那我们为何不在训练过程中计算ODE所造成的误差,并以此为损失函数更新模型,确保这种差异被消除?**该技术被作者命名为流潜空间解码(Flow Latent Decoding,FLD)。如图所示,VITA通过在训练时调用ODE生成目标动作,求取改动作与真实目标的误差,反向传播过ODE更新流模型,用真实目标锚定ODE产生的潜在表征,弥合了潜空间流模型训练-测试分布时的差距,有效避免潜在空间塌陷问题。作者认为,此技术对于其他生成领域(如图像)的端到端潜空间生成极具借鉴意义。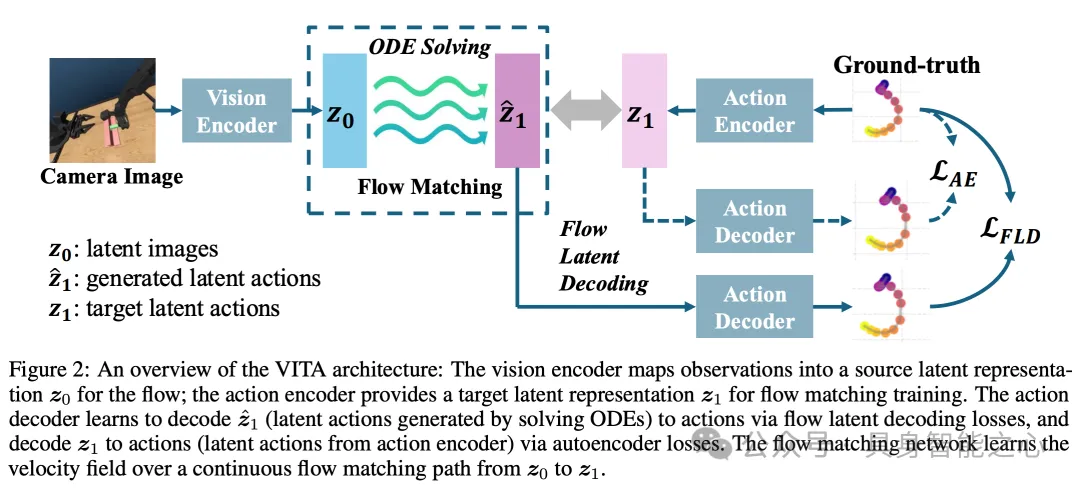
性能
VITA的实验涵盖9个仿真任务, 5个真实任务。测试涵盖了单臂、双臂、主动视觉等复杂任务。VITA在所有任务中击败、媲美SOTA方法,且效率大幅提升。
VITA使用了纯MLP网络结构。其他的基线模型往往依赖Transformer、UNet等复杂结构以取得最好性能,且当传统流策略只使用MLP时,无可避免性能大幅下降,而VITA由于将流简化为了无条件模块的向量间的映射,因此可以仅仅使用MLP网络学习有效的策略。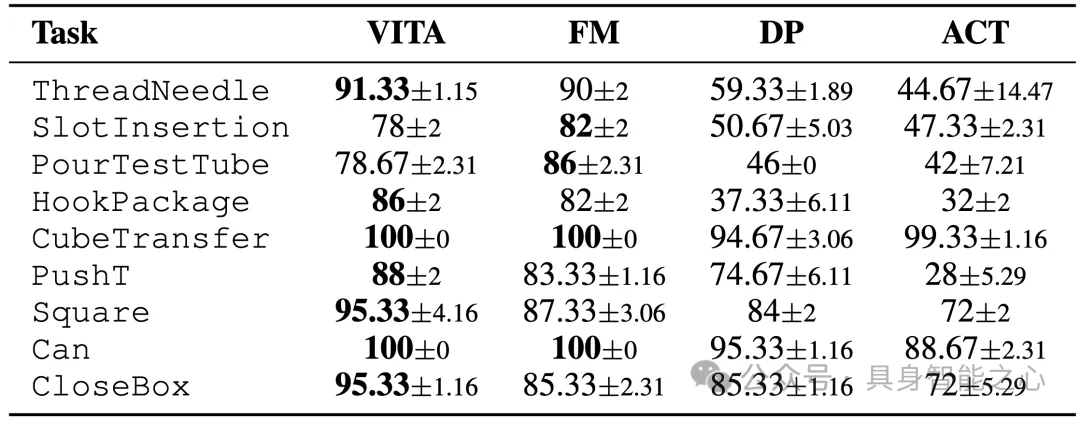
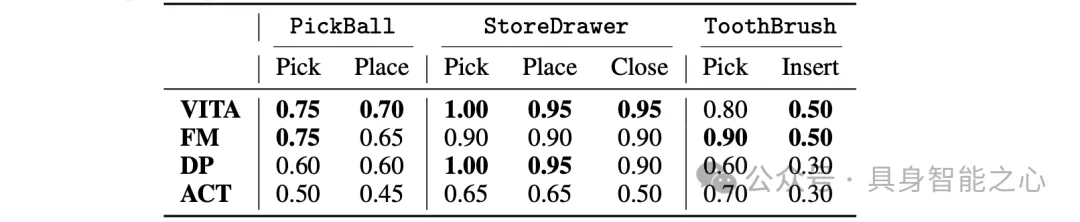
作者对比了VITA和各类策略在使用向量表征(MLP网络)、和grid表征(Transformer网络)下的性能。VITA击败了主流的生成式策略。推理速度提升 1.5×–2.3×,峰值显存下降 18.6%–28.7%。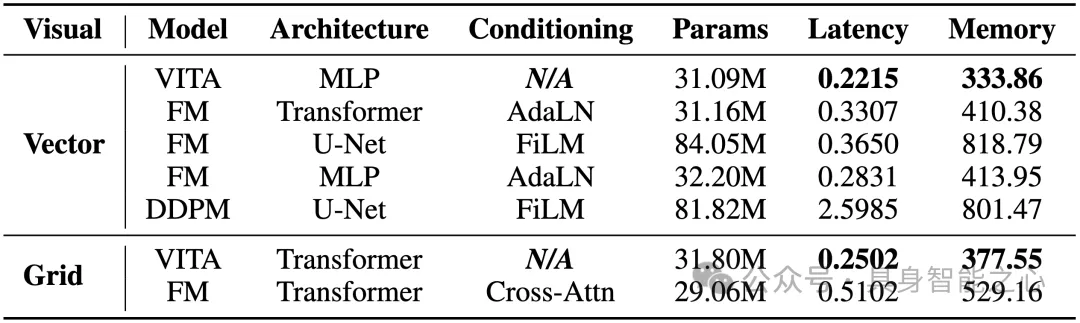
思考
VITA独特去噪过程
下图展示了传统流匹配与 VITA 在去噪过程的差异。传统方法从高斯分布开始采样,去噪到动作,而 VITA 则是从图像表示流到动作表示。作者发现,VITA所得到的图像表示,直接经过动作解码器,也可解出平滑动作轨迹,并在后续的流ODE过程中提升精度。换句话说,VITA学到的图像表征,蕴含了动作语义信息。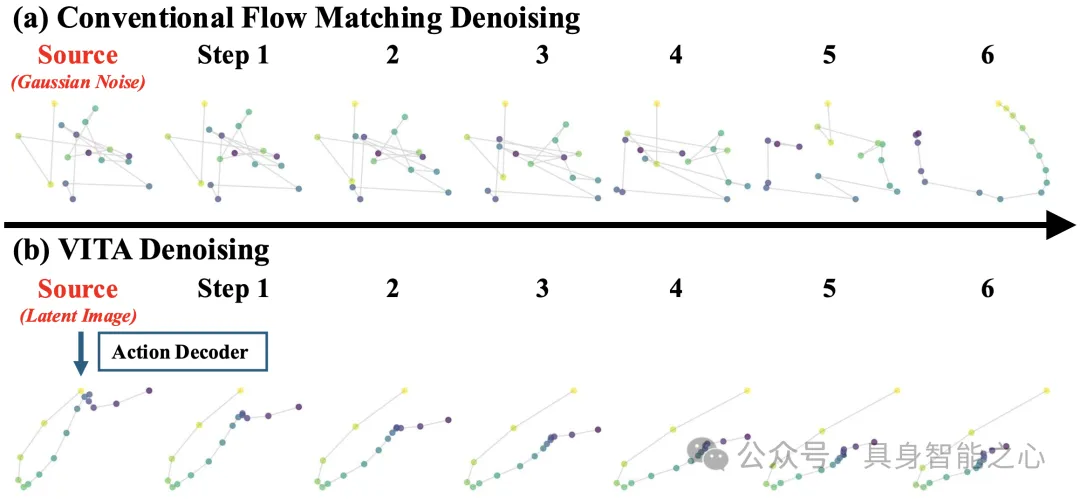
生成策略的随机性探讨
传统的流策略与扩散策略使用了高斯噪声源,采样具备随机性(stochasticity),扩散策略进一步基于随机微分方程(SDE)随机性更强。正是由于随机性的存在,这类方法具备刻画动作数据多模态(multi-modality)分布的能力。
在扩散策略提出之后,机器人研究社区似乎普遍形成了一种共识,即生成式策略能够有效拟合多模态动作分布,从而在表达能力和任务成功率上取得优势。
与传统方法不同,VITA 默认采用确定性的视觉编码器,并结合基于常微分方程(ODE)的流匹配过程,整体属于完全确定性(deterministic)的策略范式,不包含任何随机成分,因此从理论上讲并不具备建模多模态动作分布的能力。
VITA 于2025年七月发布,其完全确定性的设计引发了广泛讨论:为何一个不含随机性的策略,仍然能够在多项复杂任务中取得较高的成功率?
作者针对这一现象进行了专门分析。首先,作者尝试在 VITA 中显式引入随机性,例如将 ODE 替换为 SDE,或使用 variational autoencoder (VAE) 作为视觉编码器以产生随机性,亦或在视觉表征中直接添加噪声。然而这些改动不仅未能提升性能,反而导致整体不同程度下降。
作者提出解释:在当前大量机器人操作任务中,策略成功率更依赖于动作生成的精度(precision),而非对多模态分布的表达能力。换言之,动作数据的多模态特性未必是影响成功率的核心因素,相比之下,策略是否能够稳定、精确地产生正确动作,并避免毫米级误差所引发的灾难性失败,反而更加关键。
论文中讨论了毫米级误差导致机器人任务失败的普遍性挑战,并且对比了 VITA 与传统流策略在动作精度指标(MSE,mean squared error)上的表现,结果表明,VITA 在动作精度与收敛速度方面均显著优于传统方法。
2025 年十二月发表的论文 Much Ado About Noising,作为打破迷信之作,指出多模态拟合能力并非生成式机器人策略取得高成功率的决定性因素,进一步支持了VITA文章阐释的观点。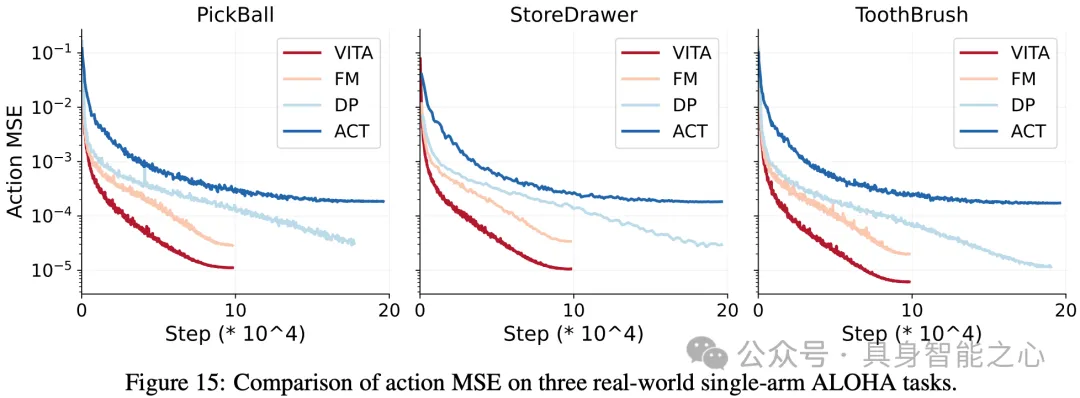
演示视频
VITA的实验涵盖9个仿真任务, 5个真实任务。测试涵盖了单臂、双臂、主动视觉等复杂任务。作者还测试了VITA在实时扰动、未知物体情况下的表现。
-
实时扰动、未知物体
-
各类任务
-
主动视觉。使用三条机械臂,其中一条主动视觉机械臂
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 11
11 0
0- 0



 已为社区贡献93条内容
已为社区贡献93条内容

所有评论(0)