收藏!小白程序员必看:用 Agent Skills 让大模型从“陪聊”进化成“专家”
本文探讨了如何通过“Agent Skills”让大语言模型(LLM)从简单的聊天机器人进化为专业智能体。文章指出,传统通用对话模式存在“博而不精”的问题,而Agent Skills为AI提供了标准化的“入职指南”,使其能捕获流程知识、灵活添加功能模块。Agent Skills具备可组合性、可移植性和执行力三大特点,通过渐进式披露机制和标准化的目录结构,有效突破上下文限制,实现模块化、按需、确定性的
最近我试图用一个超级长的 Prompt(提示词)去解决一个复杂任务时,刚开始 AI 好像还挺懂我的,但随着对话的深入,或者任务稍微复杂一点,它就开始“胡言乱语”了。要么是它忘了前面的设定,要么就是它开始一本正经地胡说八道,特别是在处理数学计算、或者需要严格逻辑的时候,那个幻觉(Hallucination)简直让人头大。
你可能会想:“是不是我的 Prompt 写得还不够完美?我是不是得再去学那什么几百页的提示词工程指南?”
其实,朋友们,我发现有时候这真不是 Prompt 写得好不好的问题。
如果你只是在一个对话框里,试图用一段话教会 AI 做所有事,那你其实是在把它当成一个“聊天机器人”在用。但我们真正想要的,是一个能干活、能执行、靠谱的“智能体(Agent)”。
今天,我就带大家深入扒一扒一个非常硬核的概念——Agent Skills(智能体技能)。这玩意儿,才是让 LLM(大语言模型)从“陪聊”进化成“专家”的关键。
01 为什么你的 Agent 总是“差点意思”?
首先,咱们得把观念转一转。
以前我们用 ChatGPT 或者 Claude,那个模式叫“通用对话”。你问它“番茄炒蛋怎么做”,它答得头头是道。但如果你问它“帮我把这个文件夹里所有 PDF 的第三页提取出来,重命名后发邮件给财务”,它可能就开始犯难了,或者只能给你一段它“想象中”的代码,根本跑不通。
为啥?因为通用模型是“博而不精”的 。
这就好比你招了一个新员工,他是哈佛毕业的,上知天文下知地理,但他刚进你们公司,不知道你们公司的报销流程,不知道代码库在哪,也不知道服务器密码。
这时候,你需要的不是让他再去读一遍百科全书,而是要给他一本“员工手册(Manual)”。

大家看这张图,左边是那个聪明的机器人,右边就是我们需要给它配备的“技能包”。
Agent Skills 的本质,就是给这个通用的 AI,外挂了一套标准化的“入职指南”。
有了这个东西,我们就不用每次都费劲巴拉地写几千字的 Prompt 去通过对话“催眠”它,而是直接把一个封装好的能力包丢给它:“嘿,遇到这个问题,就按这个手册里的流程办。”
这样做的价值是巨大的。你的 Agent 不再是一个孤立的聊天窗口,它变成了一个可以捕获流程知识、可以灵活添加功能模块的专用代理 。
02 Agent Skills 的三大超能力
那这个 Skills 到底强在哪?咱们把它拆开看,其实就三个关键词:可组合性、可移植性、执行力。
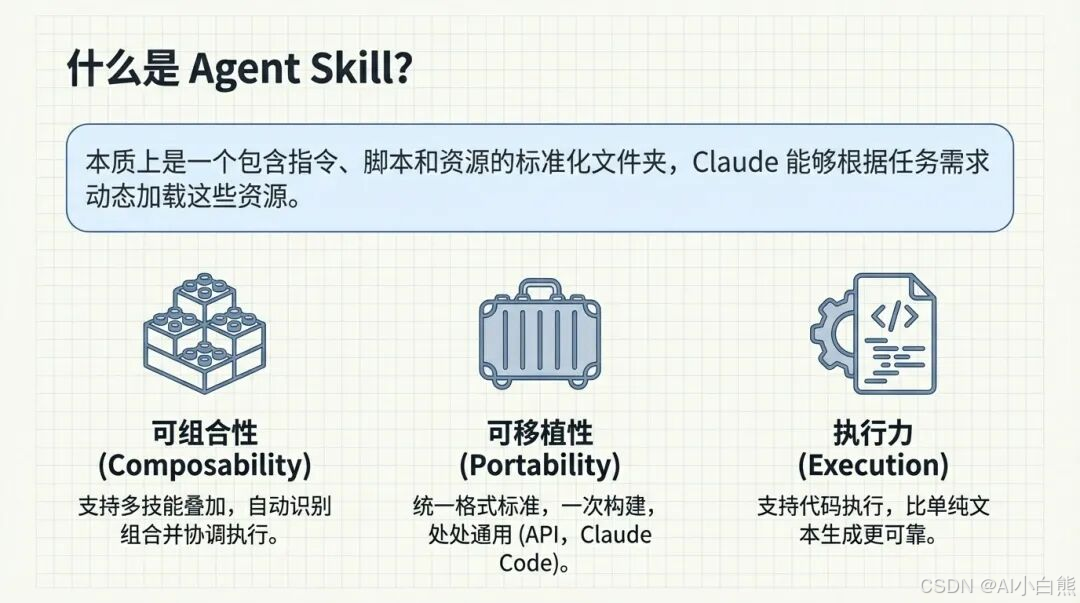
可组合性(Composability):就像搭乐高积木一样 。你写好了一个“PDF处理技能”,又写好了一个“邮件发送技能”。当用户说“处理完PDF发邮件”时,Agent 能自动识别并把这两个技能串起来用 。
可移植性(Portability):咱们今天讲的这套标准,是一次构建,到处通用的 。不管你是用 API 还是用 Claude Code 这种终端工具,技能包的格式是统一的。
执行力(Execution):这一点最重要,也是我今天要重点讲的 。
咱们很多朋友最头疼的就是 AI 的数学和逻辑能力。
举个例子,你给 AI 一个乱序的数字列表,让它排序。如果只是靠 LLM 自己的“大脑”去生成文本,它其实是在做“概率预测”,它不是真的在算,它是在猜下一个数字是谁 。这就很容易出错,这就是所谓的“幻觉风险” 。
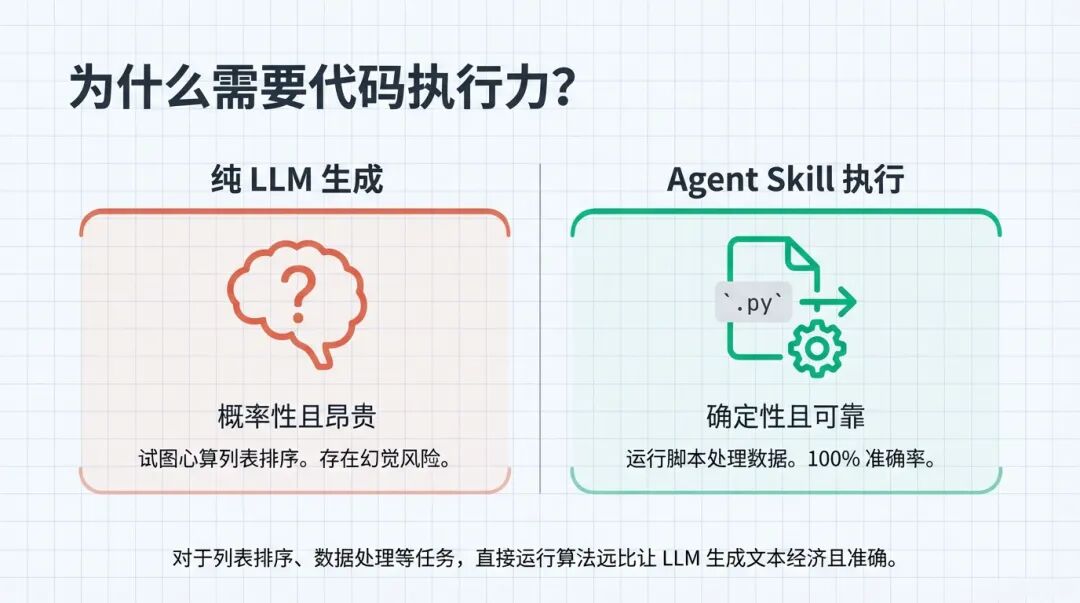
大家看这个对比。左边是纯 LLM 生成,费脑子还容易错;右边就是 Agent Skill 的逻辑——直接运行代码。
如果任务是“列表排序”,我们为什么要逼着一个语言模型去心算呢?直接让它写一段 Python 脚本,在后台一跑,结果 100% 准确,既省钱又靠谱 。这就是 Agent Skills 强调的“执行力”——用代码逻辑去弥补语言模型的短板。
03 核心机制:渐进式披露(Progressive Disclosure)
好,听到这儿你可能觉得:“这不就是写插件吗?”
不全对。Agent Skills 的设计哲学里,有一个非常高级的概念,叫“渐进式披露”。这个词听着有点学术,但道理非常简单,也是为了解决咱们现在 AI 开发中最大的瓶颈——上下文窗口(Context Window)限制。
虽然现在模型支持 128k 甚至 1M 的上下文,但你把几百兆的文档一股脑塞进去,不仅贵,而且模型会“迷糊”,处理速度也会变慢。
Agent Skills 采用了一种“漏斗型”的加载机制。
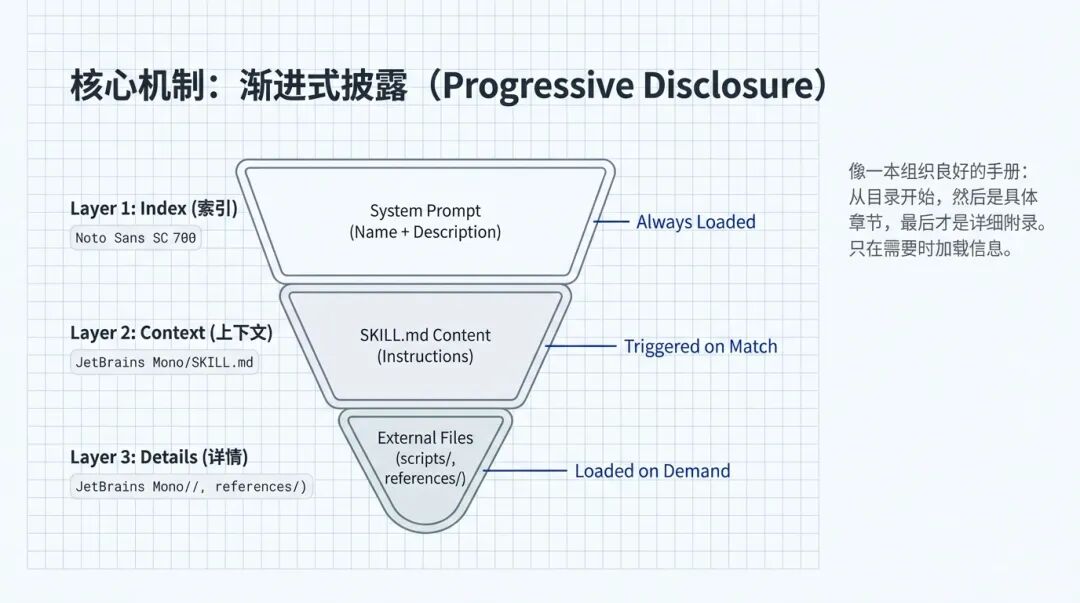
大家仔细看这张漏斗图,这可是核心中的核心!
第一层:索引(Index)。也就是 System Prompt 层面 。这里我们只加载技能的名字(Name)和简短的描述(Description)。这一层是 Always Loaded(常驻)的 。这就好比员工手册的“目录”,Agent 只要看一眼目录,就知道自己有哪些本事,但具体怎么做,它还不需要知道 。
第二层:上下文(Context)。当用户的需求命中了某个技能(比如用户提到了“帮我修图”),Agent 才会去加载这个技能对应的核心文件——SKILL.md。这时候,具体的指令才会被读取 。
第三层:详情(Details)。如果这个任务超级复杂,需要查阅 API 文档或者调用具体的脚本,Agent 才会去加载External Files(外部文件) 。这才是 Loaded on Demand(按需加载) 。

04 怎么触发?全靠“意图匹配”
那 Agent 怎么知道什么时候该用什么技能呢?
这就要回到第一层。当用户发出一句 Query(指令)时,系统会扫描所有技能的 Name 和 Description 。
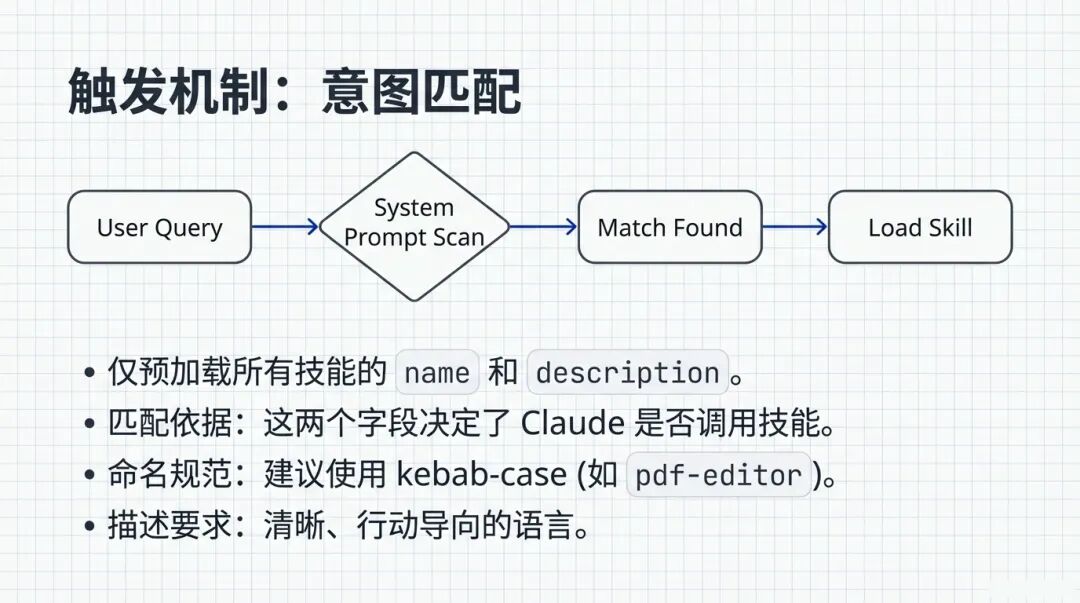
看这个流程图。匹配的依据非常简单,就是你在配置文件里写的描述。
User Query: “帮我把这个 PDF 转成图片。”
System Scan: 扫描现有技能… 发现一个叫pdf-converter的技能。
Match Found: 匹配成功!
Load Skill: 这时候才把具体的指令加载进来 。
所以,这里有个小技巧给到大家:
预加载极简:系统仅预加载所有技能的 name 和 description,别的一概不看 。
命名规范:建议使用 kebab-case(如pdf-editor),看着专业 。
描述要求:必须是清晰、行动导向的语言。别写什么“这是一个很好的工具”,要写“用于处理某某数据,执行某某操作”。
05 手把手教你:标准化的目录结构
说到这,实操环节来了。一个标准的 Agent Skill 到底长什么样?文件怎么摆放?
别乱放,官方有一套推荐的标准化目录结构(Directory Structure) 。

假设我们要写一个技能叫 my-skill ,它的结构应该是这样的:
- 根目录
my-skill SKILL.md:这是大脑。包含指令与 YAML 配置的核心文件 。scripts/:这是手脚。存放 Python 或 Bash 可执行代码 。references/:这是参考书。存放 API 规范、JSON Schema、长文档assets/:这是素材库。模板、图片、静态文件放这 。
这种结构清晰明了,不仅 Agent 读得懂,咱们开发者维护起来也方便。
06 深度解析:SKILL.md 怎么写?
SKILL.md是整个技能的灵魂。它通常由两部分组成:Frontmatter(前置配置)和正文提示词。
第一部分:Frontmatter 配置

这部分是写在文件最开头的 YAML 格式配置 。有几个参数特别关键:
name: 唯一标识符,这就是触发的核心依据 。
description: 给 AI 看的“自我介绍”,决定了你会不会被召唤 。
model: 你甚至可以指定这个技能专门用哪个模型跑(比如claude-3-opus) 。
disable-model-invocation: 这个参数很有意思。如果设为true,就是防止 AI 自动执行高风险操作 。
第二部分:正文提示词(Prompt Body)

配置写好了,接下来就是告诉 AI 具体怎么干活。我们建议按照这 5 个步骤来写 :
概述 (Overview):讲清楚功能与使用场景 。
前置条件 (Pre-reqs):干活前需要检查什么所需工具或文件 。
操作步骤 (Steps):这是重点!要用 Step 1, Step 2 这种清晰的列表,使用祈使句。
输出格式 (Output):你想要 JSON 还是 Markdown?在这里规定死期望的结果形式 。
错误处理 (Error Handling):出现问题时的应对策略 。
07 避坑指南:提示词编写的最佳实践
写代码有“代码规范”,写 Skill 也有“最佳实践”。我总结了几条大家容易踩的坑:

控制篇幅:建议整个SKILL.md不要超过 5000 字符 。别把所有废话都写在里面,避免上下文过载。
指令性语言:对 AI 说话要硬气一点。多用祈使句(如“分析代码…”),避免用“你应该…”这种软绵绵的话 。
引用外部:遇到长的文档,将详细文档移至references/,保持核心简洁 。
相对路径:这一点超级重要!引用文件时,始终使用{baseDir}变量,严禁硬编码绝对路径。
08 资源管理策略:如何突破上下文限制?
刚刚我们提到了“渐进式披露”,这里再通过一个直观的对比图加深一下印象。
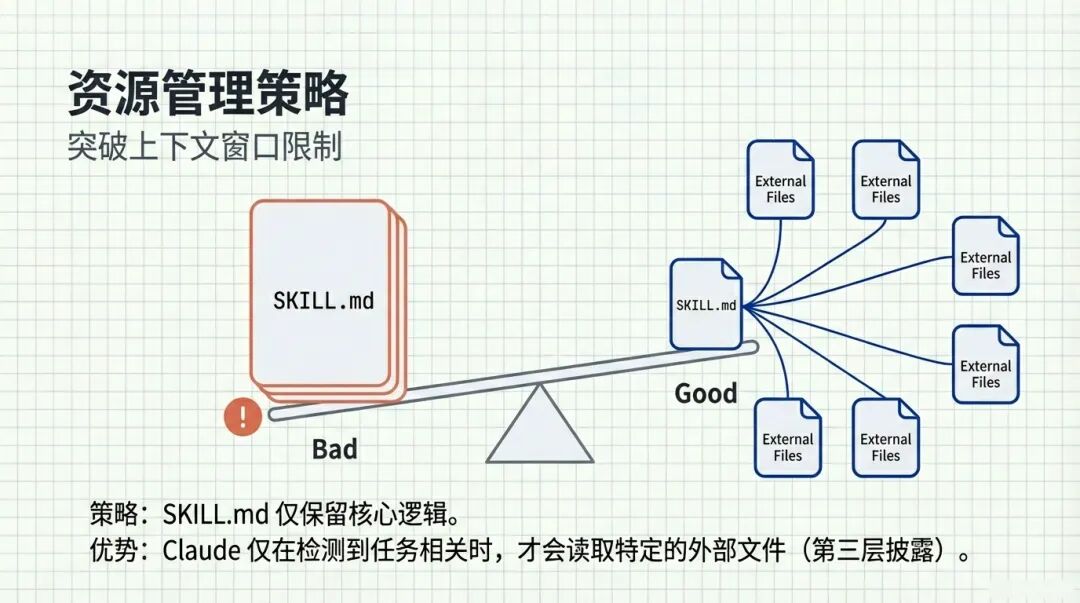
左边是Bad Case:把所有乱七八糟的外部文件内容直接塞进SKILL.md。结果就是SKILL.md变得巨重无比,像一块大石头,压得模型喘不过气。
右边是Good Case:SKILL.md只是一个调度中心,它通过链接指向外部文件 。
策略就是:SKILL.md 仅保留核心逻辑。
优势显而易见:Claude 仅在检测到任务相关时,才会读取特定的外部文件(这是第三层披露) 。
09 动真格的:Scripts 文件夹
咱们前面说了,Agent Skills 的核心优势是执行力。那执行力靠什么落地?就靠scripts/文件夹 。

这里面存放的是可通过 Bash 工具调用的代码(Python/Bash) 。典型场景包括:
- 自动化脚本 (Automation)
- 数据处理 (Data Processing)
- 验证器 (Validators)
- 代码生成器 (Code Generators)
最爽的一点是,无需加载脚本内容到上下文,仅需调用。
比如一个bash run_script.sh命令发过去,那边代码就开始跑了,跑完直接给结果。这比让 AI 在对话框里一行行敲代码效率高太多了 。
同理,references/和assets/也是这个逻辑。

如果是必须要读的文档(比如 API 规范、JSON Schema),放references/。如果是静态资源(比如 HTML 模板、图片),放assets/,这种通常只引用,不直接加载 。
10 实例拆解:做一个 PDF 处理技能
光说不练假把式。咱们来看一个真实的案例:PDF 处理技能。
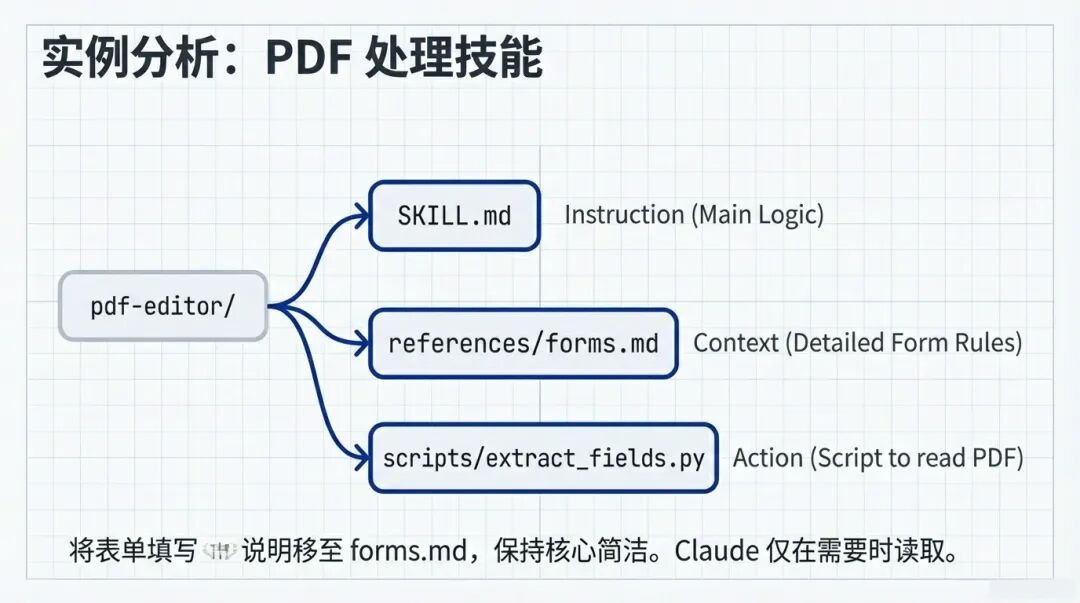
我们可以这样拆解:
-
- 它是总指挥(Main Logic) 。里面写清楚了:“如果用户要填表,就去读表单规则;如果用户要提取数据,就去运行提取脚本。”
pdf-editor/SKILL.md -
- 这里面存放详细的表单填写规则(Detailed Form Rules)。太长了,所以不放在主文件里,需要时再读 。
references/forms.md -
- 这是一个 Python 脚本,专门用来读取 PDF 字段。Agent 不需要看懂 Python 代码,只需要调用它 。
scripts/extract_fields.py
看,这样一个结构,就把复杂的业务逻辑解耦了。将表单填写说明移至 forms.md,保持核心简洁 。
最后,给大家一个技能构建核心清单,做完技能记得自查一遍:

☐命名:简洁明了的 kebab-case 。
☐描述:包含明确的触发条件和行动意图 。
☐安全:对高风险操作启用disable-model-invocation: true。
☐路径:检查所有引用是否使用{baseDir}。
☐精简:核心SKILL.md是否已剥离非必要长文本? 。
11 深度总结:Agent 的进化
讲到这,大家应该感觉到了,Agent Skills 绝不仅仅是建几个文件夹那么简单。它代表了 AI 的进化 。

它把 AI 的能力变成了:
模块化 (Modular):像乐高一样拼装能力 。
按需 (On-demand):像搜索引擎一样获取知识 。
确定性 (Deterministic):像程序一样执行任务 。
未来的 AI 应用,肯定不是靠一个几万字的 Prompt 撑起来的,而是由无数个这样小而美的 Skills 协作完成的。

现在,像 LangChain Deep Agents 这样类似的体系结构正在成为行业标准 。构建能够与复杂计算环境交互的通用智能体已成为现实 。
所以,朋友们,下一步该干嘛?

不要试图构建一个全能的 Prompt。
开始为你的一般智能体编写“员工手册”吧。将知识封装为可组合的资源包,赋予它真正的专业能力 。这才是玩转 AI 的终极姿势。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 11
11 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)