用于机器人控制的迭代组合数据生成方法
25年12月来自UPenn和Stony Brook U的论文“Iterative Compositional Data Generation for Robot Control”。收集机器人操作数据成本高昂,因此难以获取多目标、多机器人和多环境场景下组合数量庞大的任务的演示数据。虽然最近的生成模型可以为单个任务合成有用的数据,但它们没有利用机器人领域的组合结构,难以泛化到未见的任务组合。本文提出一
25年12月来自UPenn和Stony Brook U的论文“Iterative Compositional Data Generation for Robot Control”。
收集机器人操作数据成本高昂,因此难以获取多目标、多机器人和多环境场景下组合数量庞大的任务的演示数据。虽然最近的生成模型可以为单个任务合成有用的数据,但它们没有利用机器人领域的组合结构,难以泛化到未见的任务组合。本文提出一种语义组合扩散Transformer,它将状态转移分解为机器人、物体、障碍物和目标特定的组件,并通过注意机制学习它们之间的交互。在有限的任务子集上训练后,证明模型可以零样本生成高质量的状态转移数据,从而学习未见任务组合的控制策略。此外,引入一种迭代自改进过程,其中合成数据通过离线强化学习进行验证,并纳入后续的训练轮次。
在真实数据采集成本高昂的领域,利用自生成数据增强模型训练是一种提高样本效率的有效方法。在机器人操作领域,获取新经验需要操作实体机器人——这是一个耗时耗力的过程,并且会产生磨损、维护和能源成本。因此,针对每一种可能的新操作任务从头开始收集数据很快就会变得不切实际,各种大规模数据采集工作也证实了这一点(Walke et al., 2023; O’Neill et al., 2024; Khazatsky et al., 2024)。最近的研究表明,当前的生成模型可以生成足够高质量的数据,从而能够在实际经验大幅减少的情况下训练模型,包括在控制设置中(Yu et al., 2023; Lu et al., 2023; Liang et al., 2023)。然而,大多数现有方法侧重于提高单个任务内的样本效率,而没有利用自生成数据来加速学习全新的任务(Janner et al., 2022; Lu et al., 2023)。
机器人学和强化学习中的组合泛化。在机器人学中,组合泛化已通过多种机制实现。一些方法引入模块化或架构偏好,旨在组合语义单元,例如指令或高级技能(Kuo et al., 2020; Wang et al., 2023; Xu et al., 2018; Devin et al., 2019)。其他工作则直接针对控制层,设计模块化、分解式或以实体为中心的策略架构,以鼓励跨任务重用行为组件(Mendez et al., 2022b; Zhou et al., 2025; Devin et al., 2017)。一些方法致力于自动识别策略并将其分解为功能模块(Yang et al., 2020; Goyal et al., 2021; Mittal et al., 2020)。另一种互补的研究方向是利用以场景为中心的模型,该模型使用结构化的目标关系表示来构建新物理配置中的低级视觉运动技能(Qi et al., 2025)。这些方法展现利用任务结构的重要性,但它们通常假设机器人、物体和目标的分解是预设计的。
机器人和强化学习中的生成数据。合成数据已成为扩展机器人学习的关键概念。一项研究工作通过轨迹级增强来扩展模仿数据集,即对专家演示进行扰动、重采样或重新生成,以提高覆盖率(Mandlekar et al., 2023; Jiang et al., 2025; Ameperosa et al., 2025; Wang et al., 2024)。尽管这些方法丰富演示集,但它们仍然局限于相同底层任务的变体,而无法扩展到新的组合。强化学习领域的互补研究探索生成式回放,其中学习的生成模型合成转换,以补充或替换智体回放缓冲区中的条目(Huang et al., 2017; Ludjen, 2021; Imre, 2021; Lu et al., 2023; Voelcker et al., 2025)。随着生成建模技术的进步——从变分自编码器(Kingma & Welling,2014)和生成对抗网络(Goodfellow et al.,2014)到最近的扩散模型(Karras et al.,2022)——这些方法对重放经验的保真度和样本效率也相应提高。然而,这些方法仍然只针对训练期间观察的相同任务生成数据。它们并不尝试为原始任务分布之外的未见因素组合生成转换。另一个正交方向侧重于视觉增强,包括渲染驱动和纯视觉流程,这些流程能够程序化地生成合成视频数据集(Singh et al., 2024; Bonetto et al., 2023; Yu et al., 2024; Han et al., 2025; Yu et al., 2025),以及在保持动作不变的情况下增强图像的生成式和基于扩散的方法(Chen et al., 2023; Yu et al., 2023)。虽然这些方法能够有效地增加视觉多样性,但它们无法提供反映全新任务语义的转换级数据。
机器人学中的组合数据生成。近期研究表明,让机器人接触组合变化因素可以显著提高泛化能力,并降低人工采集数据集的数据需求(Gao et al., 2024)。与此同时,组合生成模型应运而生,它们能够合成新的物体和任务组合,从而扩展训练经验空间(Zhou et al., 2024; Barcellona et al., 2025)。这些方法展示了将环境分解为可重用组件的实用性,但它们基于图像表示,并且通常依赖于预定义的分解。更重要的是,以往的组合生成方法并未解决如何利用自身合成的组合数据来改进生成模型这一难题。
本文研究机器人学习系统能否通过使用自改进生成模型(如图所示)为未见过的任务生成人工训练数据,从而迭代地提高其解决未见过任务的能力。其利用跨具身机器人操作领域固有的组合结构这一洞见,即每个任务的解决方案都涉及可重用目标、技能和控制器模型的独特组合。其核心假设是,构建能够显式利用这种组合性的模型架构,可以零样本地生成高质量的合成训练数据,用于新的任务组合,从而避免在物理机器人上从头开始重新学习每个任务。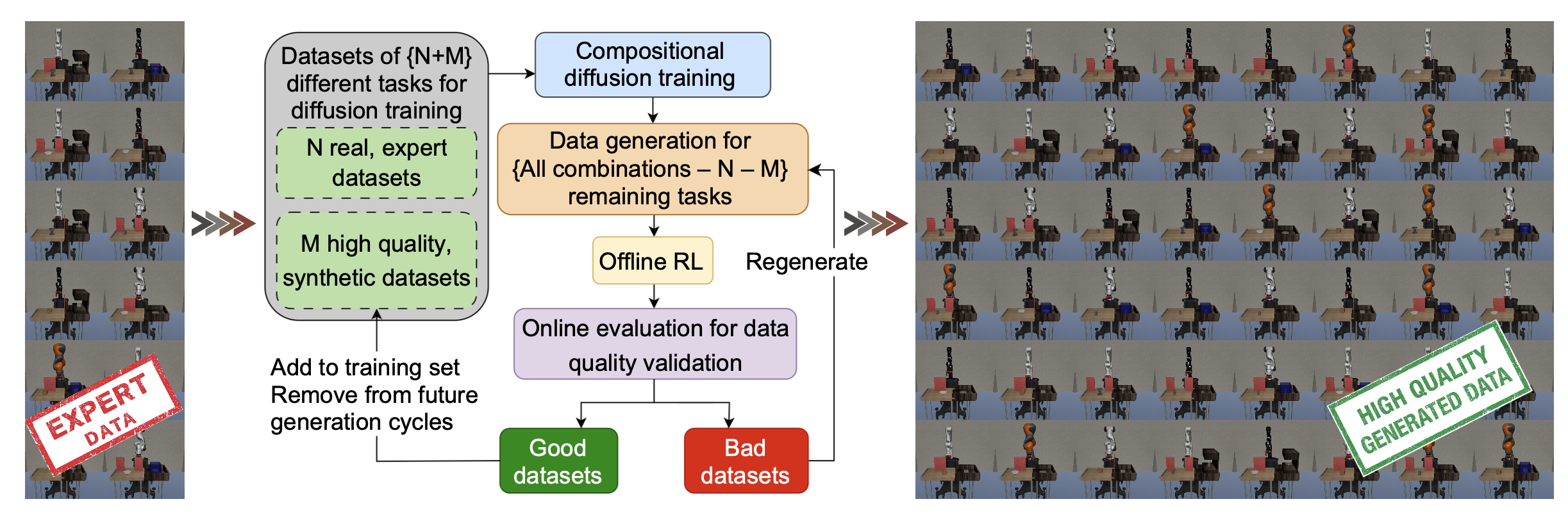
关注的是强化学习(RL)场景,其中任务以组合方式定义(Mendez et al., 2022a; Hussing et al., 2024),由少量元素(例如机器人、物体、障碍物和目标)组合而成。直观地说,机器学习方法可以利用这些领域固有的组合结构泛化到未见过的任务配置。然而,标准的单任务和多任务智体在这种场景下需要大量数据,当可用数据量较小时,它们难以利用组合结构。当策略架构反映底层任务分解时,学习器能够更好地利用这种结构(Devin et al., 2017; Andreas et al., 2017; Mendez et al., 2022a;b)。
一个突出的挑战是,预先定义此类架构需要关于正确分解的强大先验知识。尽管所考虑的机器人任务已有大量先验工程知识可供参考,但这些先验知识是否最优尚不明确。本文训练一个Transformer模型直接从数据中学习组合结构,利用Transformer模型作为图神经网络(GNN)的特性。并非在任务组合子集上训练策略并评估其零样本泛化能力,而是在相同的任务子集上训练一个Diffusion Transformer(DiT)模型,从而为未见过的任务组合策略生成训练数据,进而减少学习新行为所需的数据量。
该模型为每个单独的任务模块(例如,特定的机器人、物体或环境)学习一个独立的token化器,并使用交叉注意机制来推断连接这些编码器的图。这产生一种类似于早期工作(Mendez,2022a)中使用的硬编码组合网络的表示,但其结构是从数据中学习而来,而非预先指定。
CompoSuite 基准
CompoSuite (Mendez,2022a) 是一个用于评估组合式强化学习 (RL) 智体的模拟机器人操作基准测试平台。CompoSuite 通过从以下四个维度中各选择一个元素进行组合,提供 4 × 4 × 4 × 4 = 256 个不同的操作任务:
机械臂:KUKA 的 IIWA、Kinova 的 Jaco、Franka 的 Panda、Kinova 的 Gen3。
物体:盒子、哑铃、盘子、空心盒。
障碍物:无障碍物、阻挡物体的墙壁、物体附近的门道、阻挡目标的墙壁。
目标:抓取并放置、推动、放置在架子上、放入垃圾桶。
对于每个任务,状态以符号表示形式提供,其中包含机器人本体感知特征(关节和抓手位置和速度)以及场景中物体、障碍物和目标的绝对和相对笛卡尔坐标位置。每个任务都通过从四个维度(机器人、物体、障碍物和目标)中各选择一个唯一的元素来定义。为了说明其组合结构,如图显示 CompoSuite 中的四个示例任务。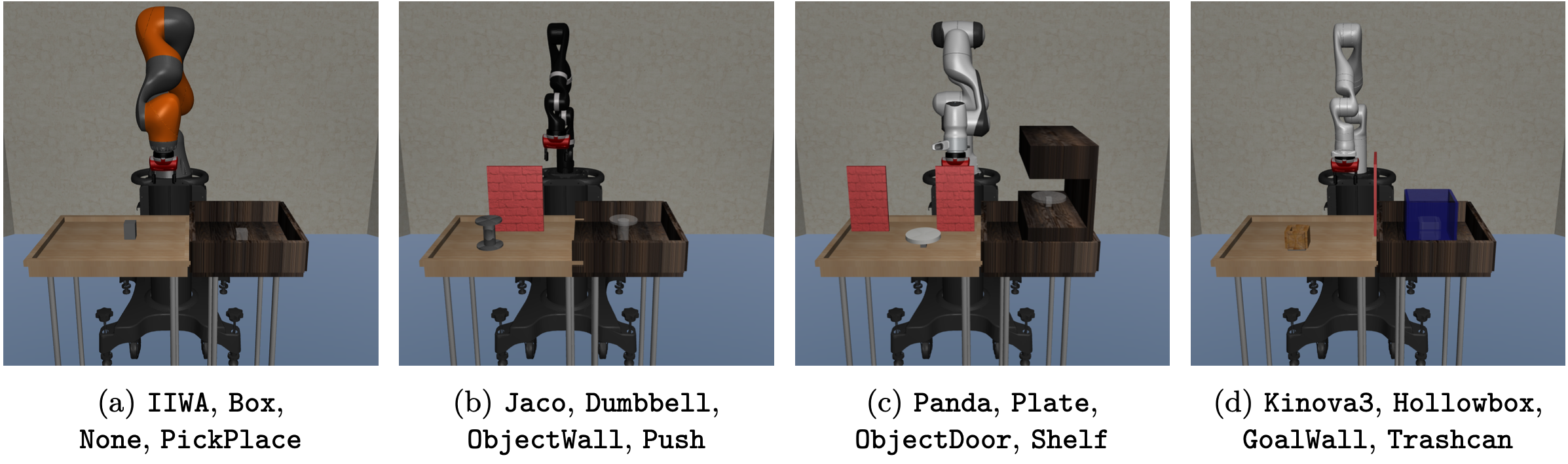
状态向量还包含一个长度为 16 的二进制指示向量,该向量通过四个one-hot子向量(每个维度一个)来标识任务。如图所示说明这种布局。奖励采用密集的分阶段奖励来指导学习。
Hussing (2024) 发布 CompoSuite 中每个任务的 100 万个转换数据,共四个数据集变体(总计约 10 亿个转换数据)。这四个数据集涵盖从早期训练到专家水平的各种性能水平,并使用近端策略优化 (Schulman,2017) 和SAC算法 (Haarnoja,2018) 训练的策略生成。轨迹存储为转换元组 ⟨s, a, r, s′, d⟩。在实验中,仅关注专家数据集。
扩散模型
扩散模型是一种生成模型,它学习逆转应用于数据的渐进噪声过程(Ho et al., 2020)。用扩散模型生成用于训练的人工数据。更准确地说,用 Elucidated Diffusion 框架(Karras et al., 2022)。给定一个数据向量 x_0,考虑一组噪声水平 {σ_t},其中 σ_t > 0。对于每个 t,前向过程 q 通过添加幅度为 σ_t 的高斯噪声生成一个噪声样本 x_t,使得对于任何固定的噪声水平 σ_t,给定 x_0 的 x_t 条件分布为 q(x_t | x_0, σ_t) = N (x_0,σ2_t I)。这里,P_mean ∈ R 和 P_std > 0 是标量超参,用于控制对数噪声分布 log σ_t 的均值和标准差。训练神经网络 ε_θ 以根据噪声样本 x_t 及其对应的噪声水平 σ_t 预测干净样本 x_0。训练目标是噪声加权重建损失。
在生成阶段,模型构建一个反向去噪过程,该过程基于噪声水平递减序列 {σ_t}。从高噪声初始化 x_T ∼ N (0, σ_T2 I) 开始,模型迭代地应用去噪器来定义反向转移 p_θ(x_t−1 | x_t),直到获得一个近似服从数据分布的合成样本 x_0。
假设任务图具有功能组合性。Mendez (2022b) 定义一组硬编码的模块,每个模块代表一个任务元素,并将任务解决方案定义为该图中的固定路径。假设每个任务由基本元素组成,每个基本元素都是一个随机变量,对应于转换的一个组成部分,例如状态或下一状态的因子、动作、奖励或终止指示符。令 F 表示所有此类基本元素的集合。那么,每个元素 f ∈ F 都与一个输入空间 Xf 和一个表示空间 Yf 相关联。编码器-解码器对 (e_f, o_f) 将原始变量映射到表示空间 e_f: Xf → Yf,并将原始变量反向映射到 o_f: Yf → Xf。
定义一个计算图 G = (V, E),它捕捉所有任务的共享结构。其中,顶点 V = Yf,f ∈ F 表示空间,边 E 表示变换,指定信息如何在表示空间之间流动。一个特定的 MDP M_n 由该任务中存在的元素子集 F_n ⊆ F 以及 G 在其表示空间上的导出子图来表征,并具有这些元素值的联合分布。CompoSuite 基准测试符合这种观点:通过沿机器人、物体、障碍物和目标轴选择一个元素来获得一个任务,从而实例化一组特定的状态因子顶点及其交互。
由于该图在表示空间中运行,因此可用于实例化 MDP 上的各种学习函数,例如策略或条件生成模型。定义在 G 上的概率模型可以指定给定任意已观测元素子集的值时,未观测基本元素的条件分布。
将Transformer视为图
对计算图的结构进行硬编码需要大量的域知识,并且可能导致次优架构。因此,希望直接从数据中学习图结构。
为此,依赖于以下发现:著名的Transformer架构(Vaswani,2017)可以解释为图神经网络(GNN)(Joshi,2025)。具体来说,一个具有L层的Transformer通过重复应用自注意层和前馈层,将输入token序列x_1, …, x_K映射到输出表示序列hL_1, …, hL_K。对于每个token i 和层 l,模型计算Q、K和V:ql_i = W_Q hl−1_i, kl_j = W_K hl−1_j, vl_j = W_V hl−1_j,其中 W_Q、W_K 和 W_V 是学习的权重矩阵。然后,模型将第 i 个token对其他每个token j 的注意权重分配为 αl_ij = softmax_j (ql⊤_i kl_j /√d) 并将其他token的V聚合到一个更新的表示 hl_i = sum_j (αl_ij vl_j),其中 FF 实现前馈层,h0_i = x_i。在将Transformer解释为图神经网络(GNN)时,每个token i对应于一个具有特征向量hl−1_i的节点,自注意机制在这些节点构成的全连接有向图上实现消息传递。通过学习权重矩阵W_Q、W_K和W_V,Transformer能够学习在图中恰好存在从节点j到节点i的强有向边时,将高注意分配给从token i到 token j的节点。
将 Transformer 解释为图神经网络 (GNN) 意味着 Transformer 可以自动发现一组在组合上相关的问题的底层图结构。这使得设计合适的图的架构挑战简化为设计一个能够表示这种图的token化方案。
语义组合扩散 Transformer
考虑将任务图编码到扩散模型中,通过将 ε_θ 实现为扩散 Transformer (DiT; Peebles & Xie, 2023) 来实现。该模型在原始转移空间中处理带噪声的输入 (x_t,1,…,x_t,K),并在每个扩散步骤中输出去噪预测 ε_θ (x_t, t),该预测被解释为每个分量的附加噪声预测。扩散 Transformer 架构内部使用特定于因子的编码器将输入映射到token嵌入,通过自注意机制处理这些嵌入,并在反向扩散过程的每一步解码回原始空间。
将任务图 f ∈ F 的每个分量与 CompoSuite 的元素关联起来,来构建每个状态转移的输入序列。对于当前状态和下一个状态,将每个轴上的每个元素视为一个因子——例如,每个机械臂就是一个因子。此外,还分别添加一个因子来表示动作、奖励和终止信号。这样就得到一个可以直接在任务图上学习的 DiT。为了进行表示学习,为每个因子配备一个参数化的编码器-解码器对 (e_f, θ, o_f, ψ),两者都实例化为神经网络。编码器将输入映射到学习的嵌入 yf = e_f,θ(zf),将其解释为存在于表示空间 Yf 中。集合 (yf),f ∈ F 被视为 Transformer 处理的 K 个tokens。对特定于某个因素的 token集进行自注意机制实现图组合推理:在每个扩散步骤中,每个因素 f 的表示都会通过关注所有其他因素 f′ ∈ F 来更新,例如,当前机器人token可以根据当前物体、障碍物和目标token进行条件化,从而反映 G = (V,E) 的边。在每个扩散步骤中,Transformer 输出去噪后的token嵌入 y ̄f,然后使用解码器将其映射回原始变量域,从而在原始转换空间中得到预测值 (o_f, ψ(y ̄f )),其中 f ∈ F。
对于条件化,原始 DiT 通过自适应层归一化注入诸如扩散步骤 t 之类的变量。这会生成每个块的尺度和平移参数,用于控制自注意机制和前馈更新。通过一个额外的输入嵌入来实现任务条件化,该嵌入会调制所有 Transformer 块。对于每个扩散步骤 t 和任务索引 n,构建一个上下文嵌入 u(t, n) = E_t(t) + E_n(n),并将其输入到一个小型网络中。该网络为 DiT 的每个块生成自适应归一化和门控参数。该路径仅通过这些自适应变换将 (t, n) 注入模型,并保持因子-特定token化的组合语义不变。由此得到的网络提供一个扩散模型,只需选择正确的编码器和条件,即可训练该模型为每个任务生成强化学习 (RL) 转换。如图所示可视化提出的架构。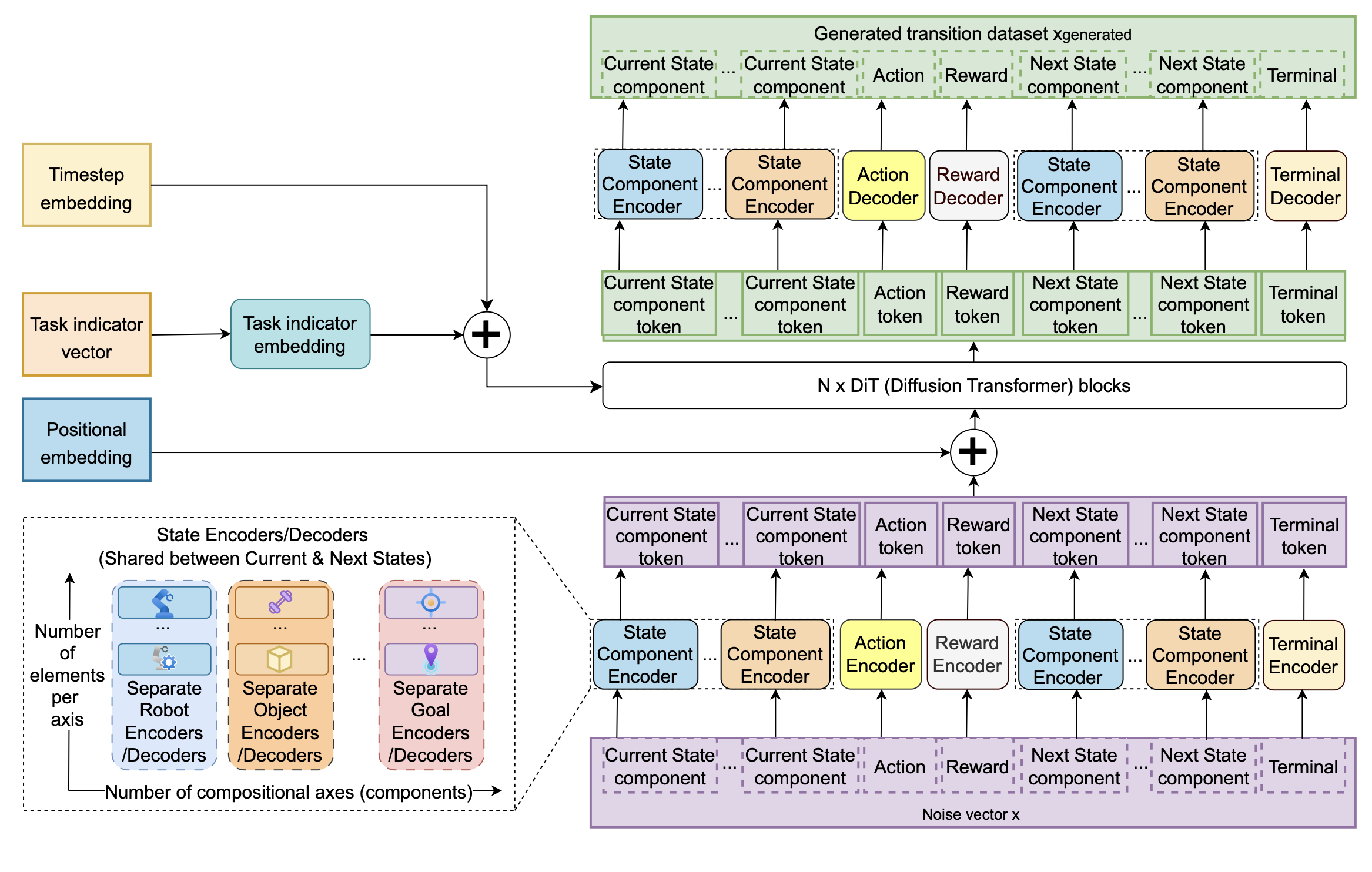
使用此架构进行扩散建模,可以生成因子特定组件嵌入的联合表示。对于每个任务索引 n,学习的扩散模型定义原始转换空间中去噪转换 x_0 的分布 p_θ(x_0 | n)。在去噪器中,因子特定的编码器将每个成分映射到词元嵌入 (ȳf),其中 f ∈ F。共享的扩散transformer模块(通过自适应层归一化受任务条件调节)利用自注意机制处理这些嵌入,以学习因子之间的关系。解码器将这些嵌入映射回原始空间。由于这种基于成分嵌入的联合表示在不同任务间共享,可以利用从一个任务中学习的结构来改进其他任务的边缘分布,并在添加新任务时逐步优化每个因子的预测分布。
自改进组合分布
用训练的 DiT 来生成训练数据,其目的有两个:一是训练未见过任务(没有真实训练数据)的行为策略;二是更新 DiT 本身。由于其组合图结构,模型可以在一组组合任务上进行训练,零样本地生成新任务组合的数据,并利用生成的数据来改进 DiT。值得注意的是,由于学习分布的分解部分来改进其边缘分布,生成器不仅改进生成数据的任务,也改进共享某些因子的任务。例如,考虑机器人和物体不同的任务(例如,CompoSuite 的一个子集)。假设数据集包含三个任务的转换:(机械臂Panda,盒子)、(机械臂Jaco,盒子) 和 (机械臂Panda,盘子),但没有 (机械臂Jaco,盘子) 的真实数据。组合 DiT 可以通过组合学习的雅各布和盘子因子来生成 (机械臂Jaco,盘子) 的合理转换。基于这些额外样本进行重训练,可以增加共享的“盒子”因子可用的有效数据量,并将其约束在多个机器人环境中,从而使任何涉及“盒子”的下游任务(例如,(机械臂IIWA, 盒子))都能受益于比仅使用原始任务所能获得的更清晰的物体边缘。
在算法1中总结了流程。该算法从训练任务子集中的一组(真实)数据开始,并按轮次进行。在每一轮中,将DiT模型拟合到所有训练数据。然后,为所有现有的验证和测试任务生成数据,使用TD3-BC(Fujimoto & Gu,2021)在生成的数据上训练策略,并在环境中在线评估该策略。如果任何任务的成功率(sr)大于某个阈值τ,将为该任务生成的数据添加到训练集中。这种基于性能的过滤器只允许用于训练高质量策略的合成数据。如果没有任务超过质量阈值,将增加耐心参数c。当耐心值超过预设阈值 C 时,会降低质量阈值 τ。
算法 1 中的方法使用自生成数据来训练数据生成器。一个问题是,为单个任务添加次优数据是否会导致所有任务的性能下降。使用先前生成模型的迭代生成数据进行训练通常会导致模型性能随时间推移而下降,这种现象被称为模型崩溃(Shumailov,2024)。组合式 Transformer 架构仅使用为特定任务生成的数据来训练该任务元素特有的编码器-解码器对。因此,每个生成的数据集仅对 Transformer 所有权重的一个子集做出贡献(例如,为机械臂Panda编码器-解码器生成的数据不会用于更新机械臂Jaco编码器-解码器的参数)。组合式架构固有的这种机制在一定程度上防止 DiT 发生模型崩溃。
基线
首先将本文方法与两种静态离线强化学习方法进行比较,这两种方法无法生成新任务的数据,以此来展示迭代数据生成的价值。
硬编码组合式强化学习。用 TD3-BC 通过离线强化学习训练 Mendez (2022a) 的多任务组合式架构。该架构专门用于解决 CompoSuite 任务,但它采用了硬编码的组合结构。
语义组合式强化学习。为了测试学习连接在组合式表示中的优势,还基于该架构实现一个语义组合式强化学习方法。用 TD3-BC 训练一个多任务模型,该模型使用语义组合式 Transformer 作为编码器。然而,并没有使用各自的解码器来解码每个元素,而是对所有输出token进行均值池化,并使用额外的前馈层处理拼接后的向量以获得动作。
接下来,考虑三种基线架构,它们根据算法 1 迭代生成数据。
单体架构。为了突出单体架构组合泛化的困难,考虑合成经验回放(SynthER;Lu,2023)的一个变体。SynthER 使用离策略强化学习算法(例如 TD3)收集的数据训练扩散模型,以人工转移来扩充强化学习批次。特别关注用于扩散的神经网络架构,因为它在生成用于强化学习训练的有效转移方面展现出潜力。具体来说,SynthER 采用单体架构,通过多个残差前馈层对扩散去噪器 ε_θ 进行参数化。通过将去噪器 ε_θ 与任务指示符关联起来,使该架构适应多任务设置。在每一层,噪声过渡通过加性嵌入进行增强,这些嵌入编码时间步长和任务信息 x~_t = x_t + E_t(t) + E_c©,其中 E_t(t) 通过正弦特征编码扩散时间步长,而 E_c© 将多热任务指示符线性投影到同一潜在空间。这种条件化策略在不修改架构的情况下将任务信息注入残差计算中。
标准 DiT。接下来,将其与不包含语义或组合token化的标准 DiT(Peebles & Xie,2023)进行比较。该 DiT 简单地将输入分割成大小约为 15 的块,并使用共享编码器计算tokens。这产生了一个与组合语义编码器具有相同token数量的 Transformer,但没有组合结构。
语义扩散模型 (Semantic DiT)。Token化方案将输入分割成语义块(例如,机器人状态、物体状态、动作),并为每个元素使用单独的编码器-解码器对(例如,一个用于机器臂 IIWA,一个用于机器臂 Jaco)。为了验证训练单独的编码器-解码器来学习每个元素的不同表示空间的必要性,将其与另一种扩散模型进行比较。该扩散模型也将输入分割成语义块,但对同一轴上的元素训练一个共享的编码器-解码器(例如,一个用于所有机器人)。虽然这种方法保留输入的语义含义,但它没有对构成 CompoSuite 任务图的节点进行建模。
在每一轮数据生成中,扩散模型会为尚未超过阈值 τ 的保留任务(即扩散模型未见过的任务)生成数据。使用生成的数据,通过 TD3-BC 训练特定任务的强化学习策略,训练 50,000 步,每 5,000 步运行 10 条评估轨迹。在评估步骤和数据生成迭代中,始终保留任务中表现最佳的策略。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 40
40 0
0- 0



 已为社区贡献211条内容
已为社区贡献211条内容

所有评论(0)