Context Engineering
摘要: Context Engineering(上下文工程)是通过设计和管理上下文信息优化AI模型理解与生成能力的技术。其核心策略包括: 保存(短期/长期存储用户数据); 选择(动态筛选相关上下文); 压缩(摘要或结构化处理以节省资源); 隔离(防止多任务/用户间信息混淆)。 这些方法可提升AI回答的准确性、效率及安全性,适用于聊天机器人、个性化推荐等场景。
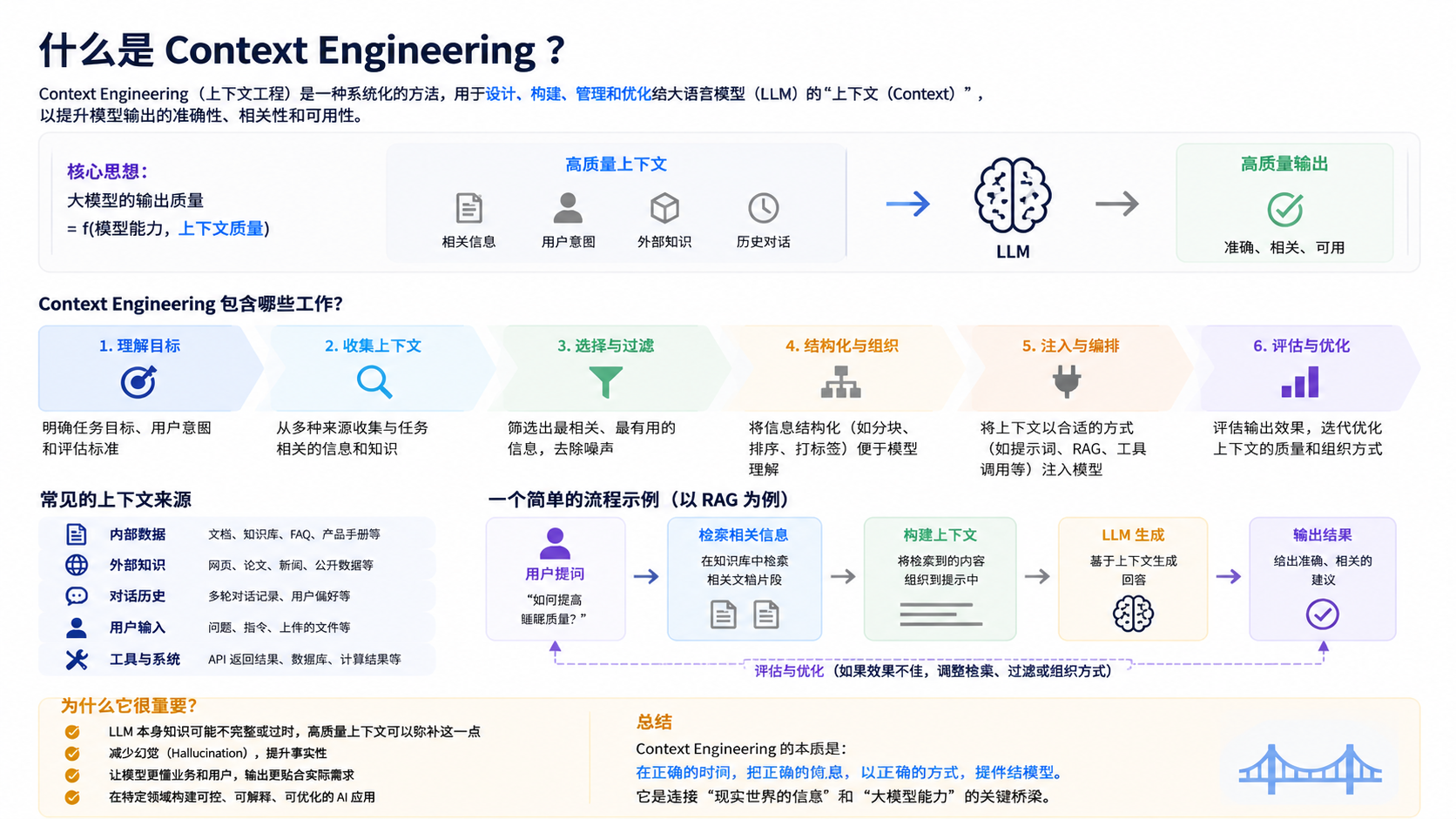
“Context Engineering(上下文工程)”是近年来在人工智能,尤其是大语言模型(LLM)应用中越来越热门的一个概念。
它的核心目标是通过精心设计和管理上下文,让模型更准确、高效地理解和生成内容;
一、Context Engineering 是什么?
简单来说,Context Engineering 是设计和管理上下文信息的技术与策略,目的是让 AI 或应用系统更高效、更准确地理解和利用已有信息。上下文可以是:用户输入、历史对话、外部知识、任务状态等。
用比喻来说:
- Context 就像“记忆碎片”,帮模型理解当前任务
- Context Engineering 就像“整理记忆”,决定哪些碎片重要、怎么存、怎么用、怎么防止混乱
二、Context Engineering的四种实现策略
1、 保存 Context(Context Persistence)
概念:将上下文信息长期或短期保存,以便后续使用。
关键点:
- 短期记忆(Session Context):只在当前会话中保存,如聊天机器人里的对话历史
- 长期记忆(Persistent Context):跨会话保存,用于用户画像、偏好、历史数据
实现方式:
- 数据库存储(关系型/非关系型数据库)
- Key-Value 存储(如 Redis)
- 本地文件或云存储
注意事项:
- 隐私和安全:敏感数据要加密或脱敏
- 版本控制:记录上下文的更新时间,避免过时信息误导 AI
举例:
用户问:“我上次买的那本书怎么样?”
- 模型通过保存的 Context 找到“上次购买的书” → 回答更精准
2、选择 Context(Context Selection)
概念:从保存的上下文中挑选最相关的部分用于当前任务。
关键点:
- 相关性排序:根据关键词、主题、时间、重要性排序
- 任务匹配:选择与当前问题或目标高度相关的上下文
- 动态筛选:不同问题选择不同上下文片段
方法:
- 基于相似度检索(Embedding、向量搜索)
- 基于规则筛选(如最近 3 条对话、特定标签上下文)
举例:
用户问:“帮我写一封跟上次类似的邮件。”
- 选择上次邮件内容作为上下文 → 生成风格一致的邮件
3、压缩 Context(Context Compression)
概念:当上下文太多,模型的处理能力有限时,需要压缩或抽象上下文,保留核心信息。
技术手段:
- 摘要压缩:把长文本压缩成短摘要
- 结构化抽象:把自然语言上下文转换成关键字段、标签或向量
- 去噪处理:剔除无关信息,减少冗余
目的:
- 节省计算资源
- 避免模型被大量无关信息干扰
举例:
一个用户有 100 条聊天记录 → 压缩成:
- 最近兴趣话题
- 常用称呼
- 未完成任务列表
4、隔离 Context(Context Isolation)
概念:不同任务或用户的上下文信息需要隔离,防止混淆或泄露。
应用场景:
- 多用户系统:确保用户 A 的数据不会影响用户 B
- 多任务系统:同一用户不同项目的上下文隔离,防止模型混淆
实现方式:
- Session ID / User ID 绑定上下文
- 任务/项目独立存储上下文
- 使用命名空间或标签区分上下文
举例:
用户 A 在做财务分析任务,用户 B 在写旅行计划
- AI 不会把旅行计划内容带到财务分析的回答里
✅ 总结:
- 保存:保留上下文,区分短期/长期
- 选择:挑选最相关的上下文,提升准确性
- 压缩:摘要或结构化上下文,节省计算
- 隔离:确保不同任务或用户的上下文不混淆

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)