YOLO入门教程(番外):目标检测的两阶段深度学习方法
先将 RPN 输出的 “归一化提议坐标” 映射到特征图的实际像素位置,再逐个截取提议对应的特征区域,最后用自适应池化统一尺寸 —— 确保无论提议原始尺寸如何,都能输出 7×7 的标准特征,为后续检测头的分类和回归提供统一输入。
这里就是简单了解一下R-CNN这些概念和流程就行,时间有限我们得补充了这部分的概念抓紧迈入YOLO。
- 学习资料:《基于深度学习的目标检测原理与应用》
- 作者:翟中华 孙云龙 陆澍旸 编著
我现在看东西必须用鼠标一个一个字得划过,不动手完全专注不了注意力,emmmm。可能我需要开始冥想了!
有部分内容,是让AI总结归纳的,详细的内容可以去看学习资料的原文书籍。
本文讲解目标检测的两阶段深度学习方法,从深度学习方法之于目标检测的“开山鼻祖”R-CNN,到它的改进版本Fast R-CNN、Faster R-CNN,详细讲解算法的思想及原理、改进方法、创新细节、网络架构及模型的训练、评估,重点讲解Faster R-CNN,因为这个方法是R-CNN系列中最为成熟和应用最广泛的方法。
1 R-CNN目标检测思想
目标检测主要解决两个问题:分类(Classification)和定位(Localization),如图5-1-1所示。
目标检测既要检测出图像中的猫(Cat),又要框出图像中猫的位置。
如果图像中有多个目标,就要框出多个目标的位置与多个目标的类别,如狗(Dog)、鸭子(Duck)。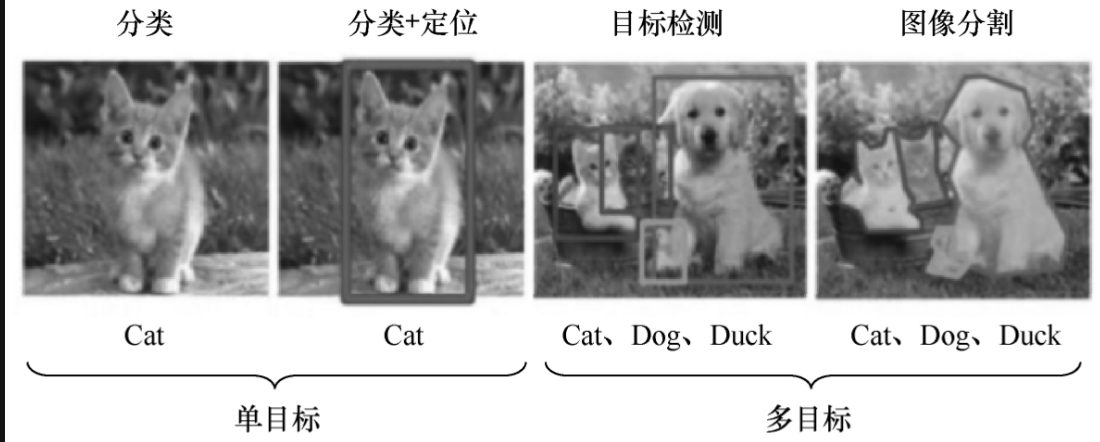
1.1 目标检测数据集
目标分类的数据集通常使用目标检测竞赛的数据集Pascal VOC、COCO,如图5-1-2所示。
其中,Pascal VOC数据集比较小,只有20个分类、10000幅图像、25000个带注释对象。
注释对象之所以比图像多,是因为一幅图像中有多个需要检测的目标。
相对于ImageNet数据集,Pascal VOC较小,因为目标检测初期检测速度是很慢的,所以如果直接使用ImageNet数据集,则时间消耗非常大;如果使用100000幅图像来做竞赛,则检测时间就需要几天,比赛无法接受这个时间长度。
而COCO数据集就比较大,有200个分类,共3种标注类型:目标实例(Object Instances)、目标上的关键点(Object Keypoints)和看图说话(ImageCaptions)。

1.2 从滑动窗口到选择搜索
如何进行目标检测呢?
最简单的检测方法就是使用滑动窗口,如图5-1-3所示,即通过一个扫描窗口,从图像左上角开始,从左到右,从上到下,一直扫到右下角。
例如,需要检测下图中人物的脸,先预设一个用来框定人脸的方框,由于人脸可能出现在图中任何位置,所以,需要使用预设的窗口在图像中滑动,并搜索图像的每个可能区域,直到检测完所有位置,在某个位置可能会检测到人脸。

虽然滑动搜索是一种非常简单的、符合人类直觉的目标检测方法,但是这种方法有一个问题:计算量过大,方框中大部分都是背景,浪费算力。
这个缺点正是入手改进的突破点,因为人脸通常是由相似的像素和结构组成的,背景也是由相似的像素点组成的,所以,应该想办法把目标和背景区分开。
这就诞生了区域建议算法,近来有很多研究都提出了产生类别无关区域推荐的方法,如选择性搜索(Selective Search)、类别无关物体推荐(Category-Independent Object Proposals)等。
一幅图像中包含的信息非常丰富,图像中的物体有不同的形状、尺寸、颜色、纹理,而且物体间还有层次关系。R-CNN采用Selective Search,基于颜色、纹理、大小和形状进行分组。
选择搜索的基本步骤共分为5步,如图5-1-4所示。
- (1) 使用Felzenszwalb等人在论文中描述的方法生成输入图像的初始分割,如图5-1-4(a)与图5-1-4(d)所示。
- (2) 递归地将较小的相似区域组合成较大的区域。使用贪心算法将相似的区域组合成更大的区域。贪心算法过程如下:从一组区域中选择两个最相似的区域,将它们组合成一个更大的区域,多次迭代,重复上述步骤,过程如图5-1-4(b)和图5-1-4(e)所示。
- (3)使用分割的区域提议来生成候选框位置,过程如图5-1-4©与图5-1-4(f)所示。将图5-1-4(b)与图5-1-4(e)相似的候选框区域合并。

1.3 R-CNN网络架构及训练过程
R-CNN是深度学习应用于目标检测领域的“开山之作”,于2014年由Ross Girshick提出。
正因为是初期的算法,所以其保留了一些传统的检测方法。之所以说R-CNN是深度学习的检测方法,是因为R-CNN使用CNN代替传统认为提取特征的方式,而提取特征正是神经网络的强项所在,如图5-1-5所示。
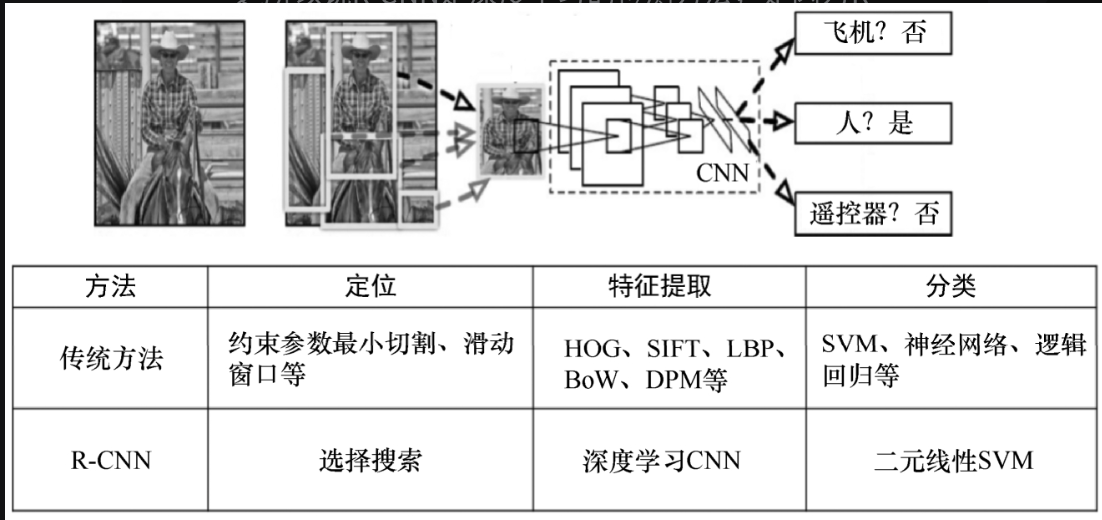
R-CNN的主要提升在于使用CNN提取特征,CNN在训练的过程中是很慢的,而在测试的时候非常快。
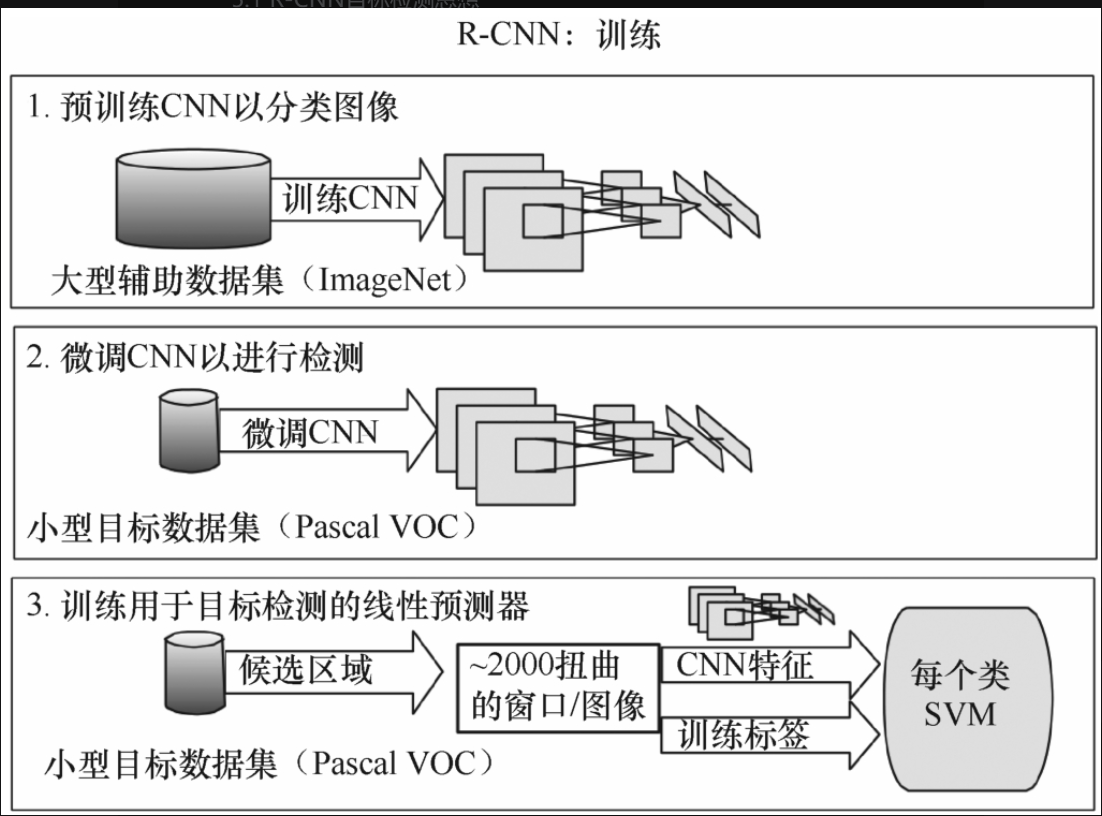
图5-1-6所示为R-CNN训练过程,共包括3步。
-
(1)预训练CNN以分类图像,预训练的具体方式是先在大型数据集ImageNet分类任务上训练CNN并保存模型,如图5-1-7所示。Pascal VOC数据集比较小,而在深度神经网络训练中,小数据集是非常容易过拟合的。在相似任务中训练的网络参数是可以迁移过来用在其他相似的任务上的,这就是迁移学习思想的应用。对于迁移学习,这里不做展开,读者可以参阅相关资料。
-
(2)微调CNN以检测,如图5-1-8所示,包含如下3步。
-
①通过选择搜索算法提出与类别无关的候选区域,每个图像有约2000个候选框。对应区域可能包含目标对象,也可能只是背景,并且它们的大小不同。
-
②根据CNN的要求,候选区域被扭曲(或称重塑,Reshape)为固定大小。
-
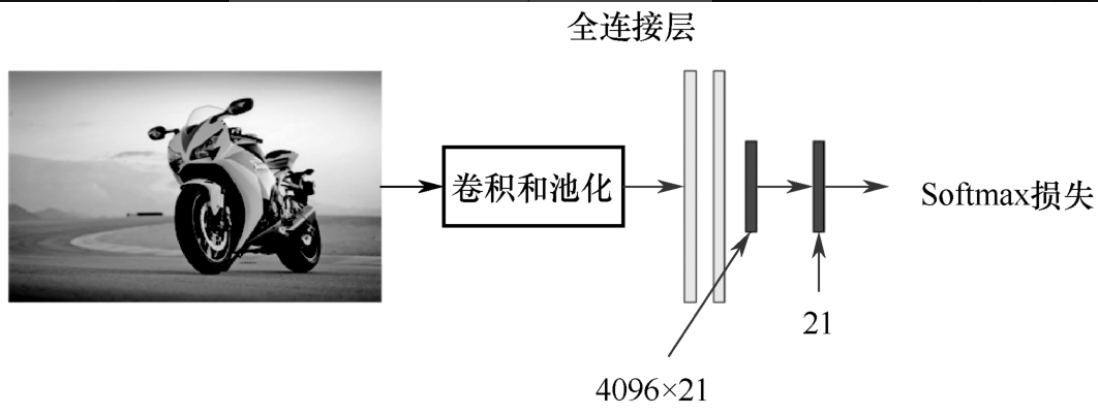
③继续在K+1个类别(对于Pascal VOC数据集,就是20个类别+1个背景)的候选区域上微调CNN,额外的一类是指背景。在微调阶段,应该使用更小的学习率,并且小批量地对正例进行过采样,因为大多数候选区域只是背景。
-
-
(3)训练用于目标检测的线性预测器,包含如下两步。
- ①开始训练预测器,把2000个候选框输入CNN进行特征提取,然后输入到针对每个类别独立训练的二分类SVM分类器中,最后得到该框属于每个类别的概率。正样本是真值标记框,负样本是低于阈值的其他框。
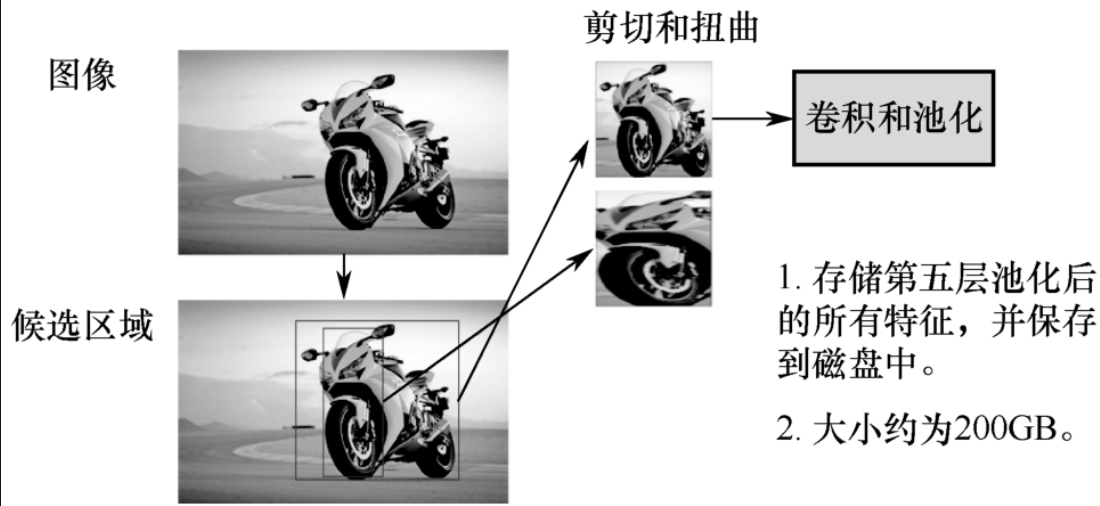
- ②为了减少定位误差,训练回归模型以对候选框进行修正,这些候选框是CNN得到的。具体操作方法如下:重塑图像大小,对图像进行剪切及扭曲,如图5-1-9所示。对每幅图像进行选择搜索后得到的框不能直接放入网络,必须剪切成227×227大小后再送入网络,这是因为网络的最后分类中有全连接层,全连接层的输入必须相同。存储第五层池化后的所有特征,并保存。
-
最后,确定正负样本。如图5-1-10所示,使用SVM对框出来的样品分类。为什么摩托车的一部分是负样本呢?因为该图相对于真值框(Ground Truth)的交并比(IoU)小于重叠阈值0.3,所以,把它分为负样本,设置的阈值越小,对检测器的精度要求越高。
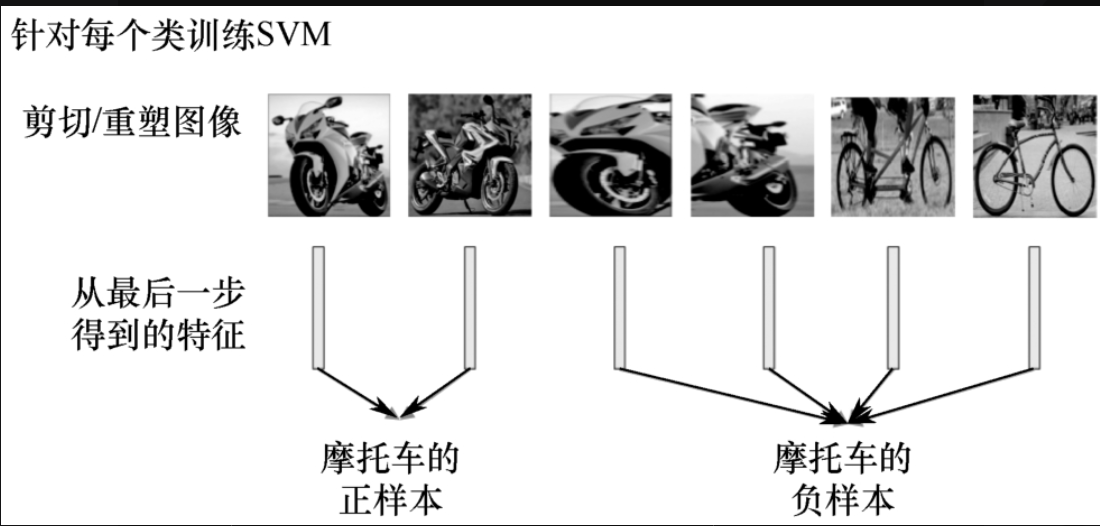
注意,微调和SVM正负样本阈值设置不同,在微调时,设置0.5为阈值,即将与真值框有最大交并比重叠的框标记为正样本,所有其他候选区域标记为负样本。
为什么在微调CNN与训练SVM时,正例和负例的定义有所不同?
对于训练SVM,仅将所有的真值标记框作为其各自类别的正例,而将与该类下的所有真值框交并比小于0.3的候选目标作为该类别的负例,交并比超过0.3的候选区将被忽略。
这样的区别是由训练效果决定的,当开始微调时,最初使用与用于SVM训练相同的正例和负例定义,发现结果比使用当前对正负样本的定义所获得的结果差得多。
图5-1-11所示为R-CNN最终效果。
上文已经说过,为了减少定位误差,对边界框使用回归技术进行校正,使边框恰好框住目标物体,对于这部分内容,会在5.9节详细展开,一方面,因为Faster R-CNN算法是R-CNN系列中最强大的,应用更广;
另一方面,R-CNN算法原理和架构对于初学者来说已经很有挑战了,把边界框回归放于后边,有利于读者更好地专注于R-CNN原理。
2 目标检测指标——二分类器
如果仅仅是目标分类问题,则非常简单:直接看其分类的准确性即可。
对于目标检测网络,既要看目标检测框的位置是否准确,还要看其分类效果是否精确,这样就比较困难。
mAP(mean Average Precision,平均精度均值)是目标检测常用的指标,其中,mean和Average都是均值的意思,为什么mAP是平均均值呢?
下面将分阶段讲解。
首先要讲的是Ground Truth。
Ground Truth是一种人为标定的真值框,如图5-2-1所示。任何深度学习的真实值都是人为标定(认定)的真实值,如图5-2-1中框出的马(Horse)、人(Person)、狗(Dog),将目标框出来以后再进行分类。因此,目标检测的目标有两个:一个是将物体框出来;另一个是对物体进行分类。

表5-2-1所示为Ground Truth实例。这5个值就可以定位所有的真值框。在物体检测网络中会产生大量候选框(如R-CNN会产生2000个左右的候选框)。
但是在真实图像中,通常只有3~4个目标需要检测,大部分候选框框到的是背景,因此,使用交并比衡量候选框的置信度(前景、背景置信度),交并比越高,则置信度越高。

首先需要从二分类器说起,因为目标检测作为一个多分类器,其评估指标是从二分类器迁移过来的。
二分类器根据标签正负与预测结果为正负可以分为4个不同的样本:
- 如果标签为正,预测结果也为正,则称为真正(TP);
- 如果标签、预测结果都为负,则称为真负(TN);
- 同理,如果标签为正,预测为负,则称为假负(FN);
- 如果标签为负,预测为正,则称为假正(FP)。
将这4个指标一起呈现在表5-2-2中,称为混淆矩阵(Confusion Matrix),其中,Positive为正,Negative为负。

测性分类模型越准越好。
那么,对应到混淆矩阵中,希望TP与TN的数量大,而FP与FN的数量小。
当得到模型的混淆矩阵后,需要去看有多少观测值在第二、第四象限对应的位置,这里的数值越多越好;反之,在第一、第三象限对应位置出现的观测值越少越好。
在目标检测中,标签为正表示物体框中有物体,标签为负表示物体框中的是背景。
如果一个模型的背景框检测率为99%,而物体检测率为10%,那么没人会认为这是一个合格的模型,因此,应更关心物体的检出率,这就衍生出精确率、召回率来衡量模型性能,具体公式如下。

精确率显示所有预测正确的正样本在所有预测为正的样本中的表现情况,而召回率就是所有预测正确的正样本在所有标签为正的样本中的表现
可以看到精确率、召回率分子只有TP,而分母没有TN,说明指标最关心物体预测正确率,而不关心背景预测错误率。
PR曲线是以精确率和召回率为变量做出的曲线,其中,召回率为横坐标,精确率为纵坐标,如图5-2-2所示。
随着数据的增多,精确率慢慢降低,召回率慢慢增高。
这是因为检测器不是一个完美的检测器,如果检测器是完美的,则PR曲线将是一条横线。
如图5-2-3所示的PR曲线是理想曲线,因为在现实问题中候选框都是整数,所以,真实的PR曲线是一个离散的曲线,并且会因为召回率不变、精确率一直下降的情况而出现尖角。为了方便计算,可以将尖角抹平,因此,图5-2-3中阶梯式的黑色实线就是需要计算的PR曲线,而且其是一个近似值。
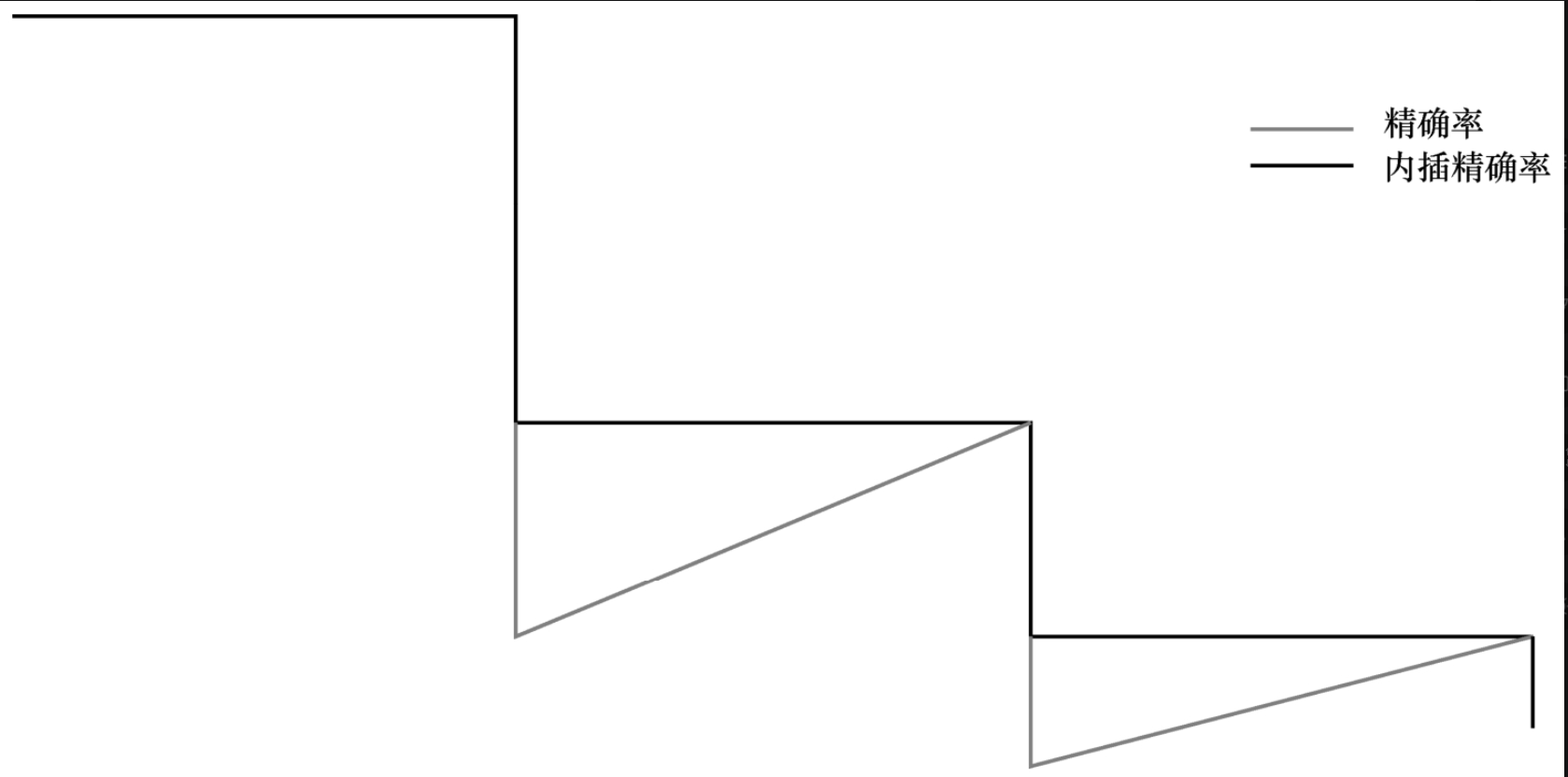
如果PR曲线是连续的,则只要对曲线进行积分就能计算AP;对于离散的PR曲线,取11个召回率值(如0,0.1,0.2,…,1)作为阈值,则有:

式中,pinter为内插精确率。以上是对二分类器计算AP的情况,对于多分类器的AP,只需将不同类别的AP进行平均,形成mAP。
用一个非常通俗的比喻来解释 AP 和 mAP。
核心思想:AP 是衡量一个“寻宝者”综合能力的分数
想象一下,你是一个寻宝者(你的目标检测模型),你的任务是在一个巨大的沙滩(一张图片)上找到一种特定的贝壳(某一类物体,比如“猫”)。
-
精确率: 你挖出来的东西里,有多少是真正的宝藏?
- 你挖了10次,有7次是那种特定的贝壳,3次是石头。你的精确率就是70%。
- 高精确率意味着: 你很谨慎,不常出错。只要你报告说“我找到了!”,那基本就真的是宝藏。但缺点是你可能会因为太谨慎而错过很多真正的宝藏。
-
召回率: 整个沙滩上的所有宝藏,你找到了多少?
- 沙滩上总共藏了10个那种贝壳,你找到了其中的7个。你的召回率就是70%。
- 高召回率意味着: 你很勤奋,几乎不会漏掉宝藏。但缺点是你挖了一大堆石头回来,搞得自己筋疲力尽,报告里有很多错误。
寻宝者的困境: 你无法同时保证挖出来的全是宝藏(高精确率),又能把沙滩上所有宝藏都找到(高召回率)。你越努力去找全所有宝藏(提高召回率),就难免会挖到越多石头(降低精确率)。
什么是 AP?—— 给单个寻宝者打分
AP(Average Precision,平均精度) 就是用来综合评价你作为“贝壳寻宝者”的综合能力的分数。
怎么评价?
我们让你在沙滩上从最像宝藏的地方开始挖,一直挖到最不像的地方。
- 画曲线: 我们记录下你每多挖一次,当前的“精确率”和“召回率”是多少。然后以召回率为横轴,精确率为纵轴,画出一条曲线(PR曲线)。这条曲线就展示了你从“谨慎”到“勤奋”的整个工作过程。
- 算面积: AP 就是这条曲线下面的面积!
- 面积越大,说明你的综合能力越强!
- 这意味着:在任何一个召回率水平上,你的精确率都很高。换句话说,你既能找到很多宝藏,又能保证自己挖到的大部分都是宝藏。你是一个又准又全的寻宝者!
为什么用面积? 因为它综合考虑了你在所有工作状态下的表现(从高精确率低召回率,到低精确率高召回率),而不是只看某一个瞬间。这是一个非常全面和稳定的评价指标。
什么是 mAP?—— 评选全能寻宝冠军
现在,沙滩上不只有一种贝壳,还有海螺、珊瑚等等(多类别物体:猫、狗、汽车…)。我们需要一个寻宝者能找到所有这些东西。
mAP(mean Average Precision,平均平均精度) 就是评选“全能寻宝冠军”的最终分数。
怎么评选?
- 单项比赛: 分别考核寻宝者找“贝壳”的能力(AP_贝壳)、找“海螺”的能力(AP_海螺)、找“珊瑚”的能力(AP_珊瑚)…
- 计算平均分: 把寻宝者在所有单项上的得分(AP)加起来,再除以项目的数量,得到的这个平均分,就是 mAP。
mAP = (AP_贝壳 + AP_海螺 + AP_珊瑚 + ...) / N
- mAP 越高,说明这个寻宝者(模型)的综合能力越强,无论找哪种宝藏,表现都非常优秀和稳定! 它是衡量目标检测模型好坏最核心、最常用的指标。
总结一下:
- 精确率(Precision):你这次挖的,有多少是真货?(准不准)
- 召回率(Recall):所有真货,你挖出了多少?(全不全)
- AP(平均精度):评价你找一种东西时,“准”和“全”的综合水平(PR曲线下面积)。
- mAP(平均平均精度):评价你找所有东西时的平均综合水平(所有AP的平均值)。这是我们最关心的最终成绩!
3 R-CNN目标检测模型评估结果
5.2节讲解了目标检测的评估方法,本节讲解R-CNN的评估结果:每个分类效果如何、错误主要体现在哪里及其R-CNN在其他地方的应用。
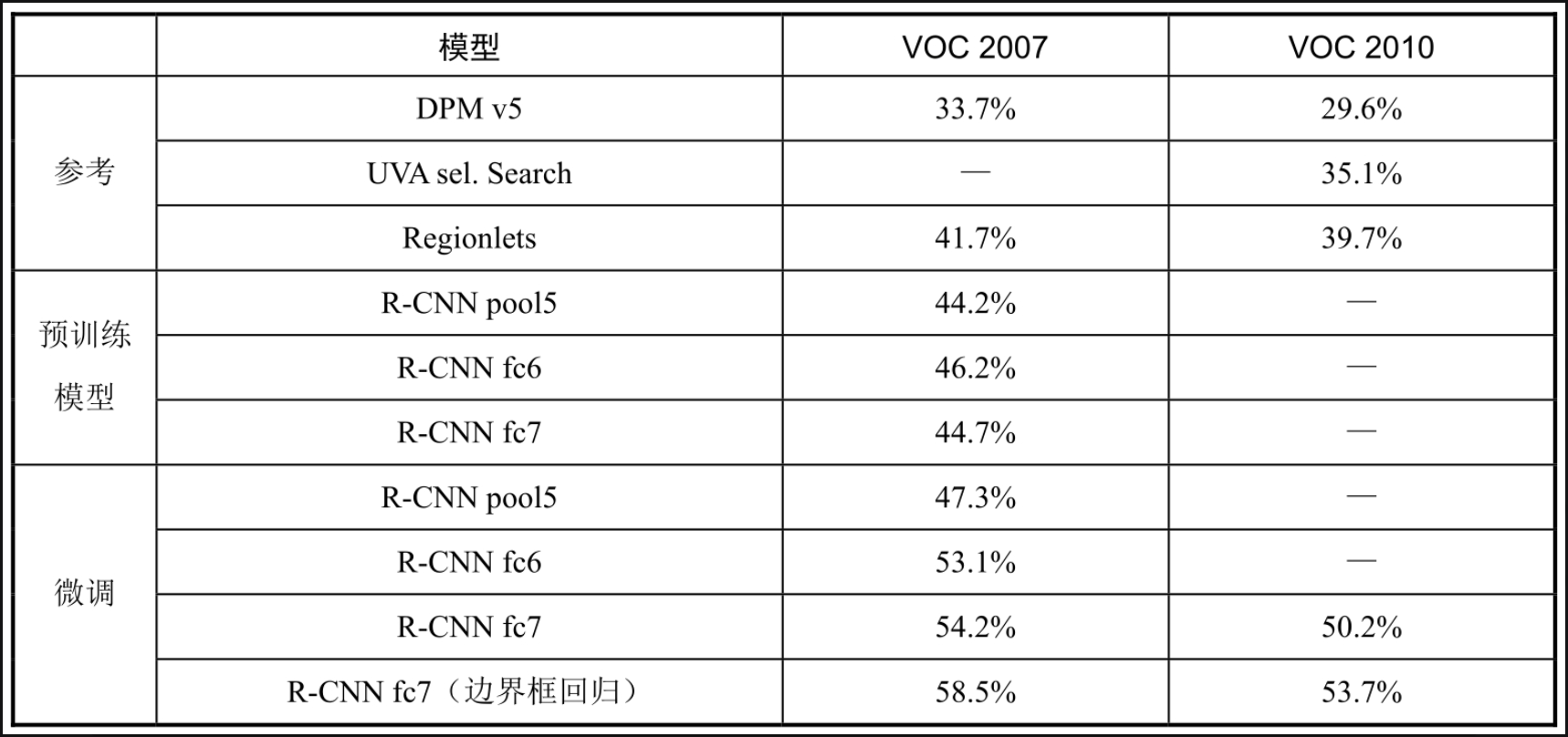
传统方法的mAP为33.7%左右,而R-CNN的mAP最高达58.5%,差不多翻一番,如表5-3-1所示。具体到每个类,其分辨效果如何?
如图5-3-1所示,因为自行车的框比较大,几乎占完整个画面,所以,自行车的检测效果是最好的,其AP为62.5%。
最差的就是鸟类,如图5-3-2所示,其AP为41.4%,因为该类的框比较小,物体也比较小,所以,检测效果比较差。

这些AP高低差异及检测错误是如何产生的呢?
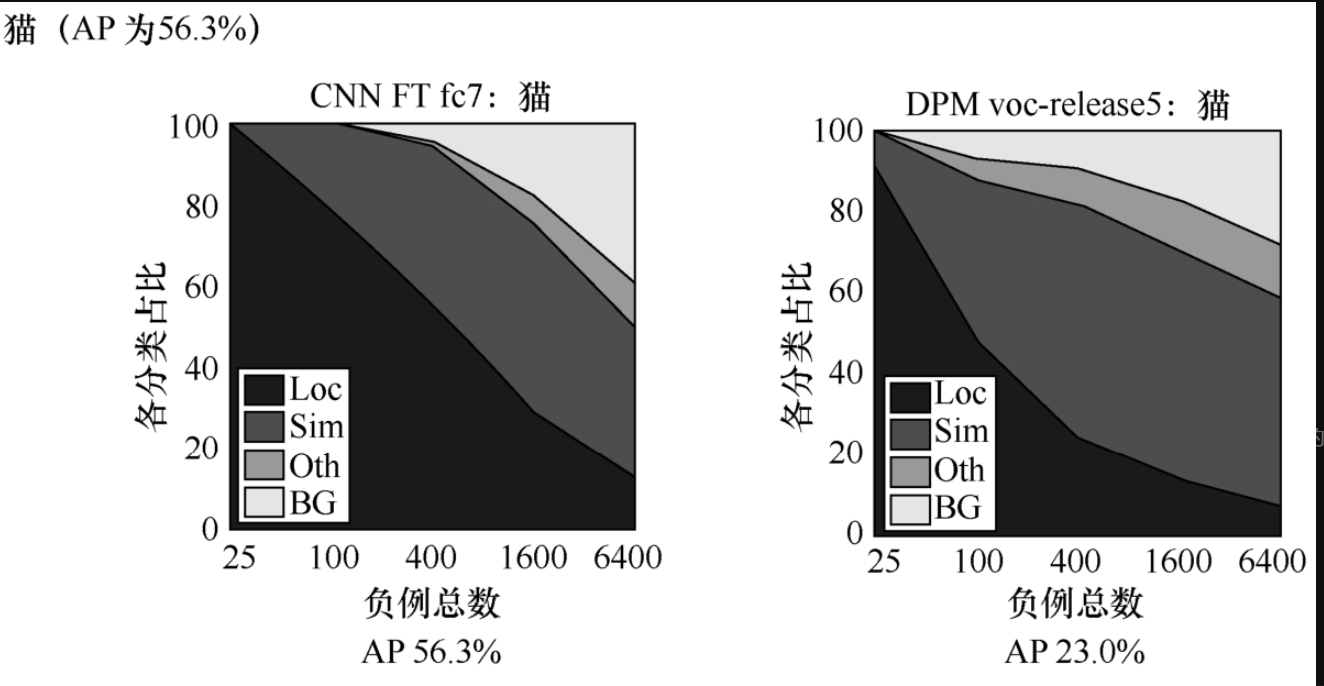
以猫的AP图作为案例,如图5-3-3所示,其中Loc是Location的简写,意思是位置错误;
Sim是Similarity的简写,表示与猫相似的物体导致其出错;
BG为BackGround的简写,表示背景错误(交并比<0.5表示背景);
Oth为Other的简写,表示非相似物体的错误,如将人识别成猫。
由图5-3-3可知,CNN最差的就是位置错误,对于非相似物体错误较少,说明CNN取到的特征是比较好的。
对于传统模型DPM,猫的AP比较低,主要错误为相似物体错误,而位置错误比较小,这是因为传统方法使用的是滑动窗口法,把所有位置都考虑进去,相似物体错误比较多,说明传统方法人为设置的不同物体特征比较相似。
CNN对相似物体的识别比较好,说明CNN自动提取特征能力较强。

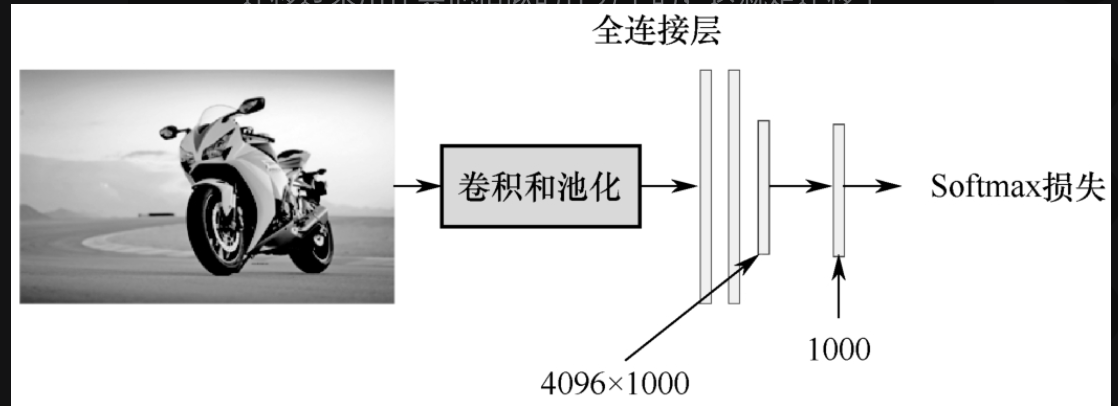
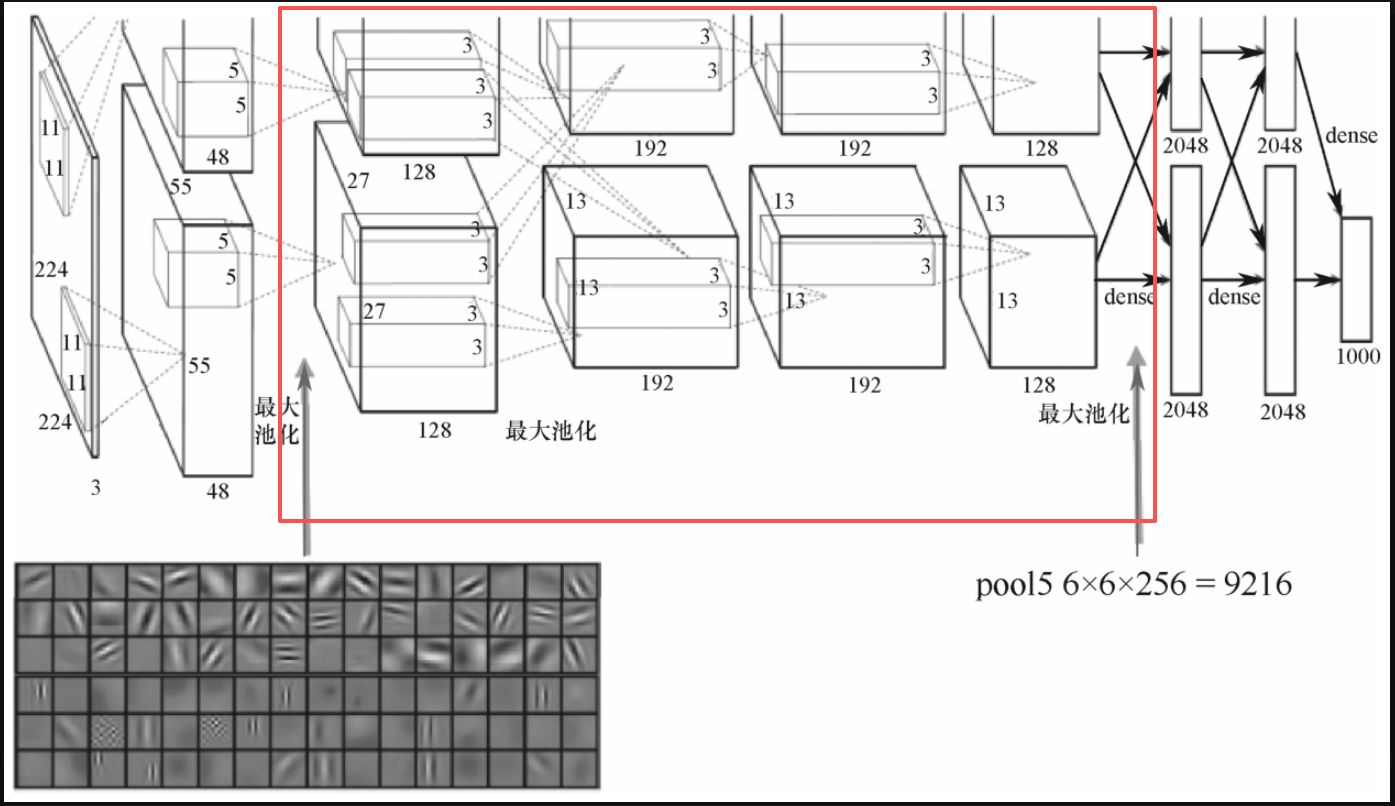
回到CNN的网络结构,如图5-3-4所示,CNN提取特征是在池化层,换句话说,在全连接层(dense)之前结束,而全连接层是最后用来分类的。
具体看一下效果,对于CNN提取到的特征,仅留下交并比大于0.5的特征,其余的在R-CNN中剔除。
植物的特征如图5-3-5所示。

电视机的特征如图5-3-6所示。
虽然CNN在大部分模型上准确率都比较高,都比人更好,但是人设计出来的特征更加灵活,人可以根据不同的情况设计不同的特征。
例如,检测人脸动物可以用HOG,检测车牌可以用SIFT。对于不同的情况,人可以建立不同的特征工程来适应问题,而机器的泛化性比较高。
例如,对于单个人脸特征/人设计的特征并不比深度学习差,但是对于100个分类的特征设计,机器是强于人的。
观点:“虽然CNN(卷积神经网络) 在大部分模型上准确率都比较高…但是人设计出来的特征更加灵活…例如,检测人脸动物可以用HOG,检测车牌可以用SIFT。”
-
CNN (Convolutional Neural Network, 卷积神经网络):
- 注释:深度学习的一种主流架构,特别擅长处理图像数据。它通过多层“卷积”操作自动从数据中学习由简单到复杂的特征(如从边缘到纹理再到物体部件),无需人工干预。
-
HOG (Histogram of Oriented Gradients, 方向梯度直方图):
- 注释:一种经典的传统图像特征描述符。它通过计算图像局部区域的梯度方向直方图来构成特征,能很好地描述物体的轮廓和形状,曾广泛应用于行人检测、人脸检测。
-
SIFT (Scale-Invariant Feature Transform, 尺度不变特征变换):
- 注释:另一种非常著名的传统局部特征描述符。它对图像的旋转、尺度缩放、亮度变化等能保持不变性,对视角变化、仿射变换也有一定稳定性,非常适合进行图像匹配,例如在车牌识别中匹配字符。
通俗理解:
这就像比较手工定制工具和全自动万能工具箱。
- 人工特征(HOG, SIFT) 像手工定制工具(如特制螺丝刀)。老师傅(专家)针对特定问题(如拧某种螺丝/检测车牌)设计的工具,在这个特定任务上非常高效、精准、灵活。
- CNN 像全自动万能工具箱。你只需要给它大量数据(各种螺丝的照片),它就能自己学习并生成识别它们的工具。它的优势在于泛化性——处理大量不同任务(如1000个物体分类)的平均能力极强,但需要大量数据和算力。
因此,结论是:在单一、定义明确的简单任务上,精心设计的人工特征可能不输给CNN;但在复杂的、多类别的现实任务中,CNN的自动化和大规模学习能力(即泛化性)远胜于人。这就是机器(深度学习)强于人的地方。
3.1 R-CNN 用于细粒度类别检测
细粒度检测的核心是 “同类辨异”—— 比如在交通场景中,不仅要识别 “汽车”,还要区分 “小轿车”“SUV”“卡车”。R-CNN 作为两阶段检测的先驱,采用 “三步法” 实现该任务:
-
用 “选择搜索” 从图像中生成 2000 个可能含目标的区域提议;
-
每个提议单独输入 CNN(如 AlexNet)提取 512 维特征;
-
用 SVM 分类器对特征分类,区分细分子类别。
评估表现:在遥感船舶数据集(含 5 种船舶型号)中,R-CNN 的平均精度(AP)约 35%-38%;在鸟类细分类数据集(CUB-200)中,AP 仅 30% 左右。短板在于区域提议质量参差(部分提议漏目标或含大量背景),导致特征提取不精准,远低于后续模型(如 Faster R-CNN 在 CUB-200 上 AP 可达 55%+)。
3.2 R-CNN 用于目标检测与分割
R-CNN 的 “检测” 能力是基础 —— 通过边界框标记目标位置(如 “猫在图像左上角,框坐标为 (50,30,200,180)”),而 “分割” 仅为附加功能:
从区域提议中截取对应图像区域,用简单阈值分割(如灰度阈值)粗略勾勒目标轮廓。
评估缺陷:分割精度极低(轮廓与真实目标重叠率不足 50%),且检测与分割完全独立 —— 分割时未利用 CNN 提取的特征,仅依赖原始图像像素,导致背景干扰严重(如分割 “狗” 时会把周围草地也划入轮廓)。但它首次验证了 “CNN + 区域提议” 可用于目标定位,为后续分割模型(如 Mask R-CNN)铺垫了思路。
4 R-CNN 的缺陷和 Fast R-CNN 的改进
4.1 R-CNN 的缺陷
R-CNN 虽开创先河,但三大缺陷使其难以落地:
-
速度极慢:2000 个区域提议需逐个输入 CNN,单张图像处理耗时 50-60 秒(相当于拍一张照要等 1 分钟才能出结果),无法满足实时场景(如视频监控需每秒处理 25 帧);
-
显存浪费:每个提议单独处理时,需反复加载 CNN 参数,显存占用峰值达 8GB 以上,普通显卡无法支撑;
-
训练碎片化:区域提议生成、CNN 特征提取、SVM 分类、边界框回归需分 4 步训练,且各步骤参数不共享,无法端到端优化(比如分类器学好了,回归器却没跟上)。
4.2 感兴趣区域池化(RoI Pooling)
Fast R-CNN 的核心改进就是用 “RoI 池化” 解决 R-CNN 的重复计算问题,原理可拆解为两步:
-
整图一次提特征:先将整幅图像输入 CNN(如 VGG16),生成一张缩小 16 倍的特征图(比如原图 800×600,特征图 50×37),避免 2000 次重复计算;
-
提议特征 “缩印”:对每个区域提议,在特征图上找到对应区域,按 “划分网格 + 最大值池化” 压缩成固定尺寸(如 7×7)。
举例:若提议对应特征图区域是 28×28,就分成 7×7=49 个 4×4 的小网格,每个网格取最大值,最终输出 7×7 的特征 —— 像把不同尺寸的照片都缩印成 7×7 的 “标准卡片”,方便后续全连接层统一处理。
4.3 Fast R-CNN 创新损失函数设计
为解决 “训练碎片化”,Fast R-CNN 设计多任务损失函数,将 “分类” 和 “回归” 两个任务的损失合并优化:
总损失 = 分类损失(Cross-Entropy Loss) + 回归损失(Smooth L1 Loss)
-
分类损失:判断提议是 “背景”“猫”“狗” 等类别(如输出 “猫” 的概率为 0.92);
-
回归损失:修正边界框位置(如原提议框偏右,通过损失计算让框左移 10 个像素)。
优势:模型训练时可同时学习 “认物” 和 “画框”,参数共享且端到端优化,训练效率提升 3 倍以上。
5 Fast R-CNN 网络架构和模型评估
5.1 Fast R-CNN 模型工作流程
完整检测流程仅需 4 步,比 R-CNN 简洁得多:
-
输入图像,用 “选择搜索” 生成 2000 个区域提议;
-
整图通过 CNN(如 VGG16 的 13 个卷积层 + 4 个池化层)生成特征图;
-
对每个提议,用 RoI 池化将对应特征图区域压缩为 7×7 特征;
-
7×7 特征输入全连接层,分支输出:① 21 类概率(20 个目标类 + 1 个背景类);② 4 个边界框偏移量(x/y 方向偏移、宽 / 高缩放)。
5.2 Fast R-CNN 网络架构
架构分为 “特征提取 - 特征处理 - 结果输出” 三部分,各层功能明确:
| 层级 | 组成 | 作用 |
|---|---|---|
| 特征提取层 | 13 个卷积层(Conv)+4 个池化层(Pool) | 从原图提取高层语义特征(如 “猫的耳朵、爪子特征”) |
| RoI 池化层 | 网格划分 + 最大值池化 | 将不同尺寸的提议特征统一为 7×7 |
| 检测头(全连接层) | 2 个全连接层(FC)+2 个输出分支 | 分支 1:分类(21 类概率);分支 2:回归(4 个偏移量) |
5.3 RoI 池化反向传播方法
反向传播是模型训练的关键(通过梯度更新参数),RoI 池化的反向传播核心是 “定位梯度来源”:
-
前向记录位置:池化时,记录每个 7×7 网格中 “最大值来自特征图的哪个像素”(比如第 3 行第 2 列网格的最大值,来自特征图第 10 行第 8 列像素);
-
反向传递梯度:计算损失后,仅将梯度传递给 “记录的最大值像素”,其他像素梯度设为 0。
通俗说:“谁贡献了最大值,就给谁‘奖励’(梯度更新)”,避免无关像素干扰,确保参数更新精准。
5.4 Fast R-CNN 结果评估
在 PASCAL VOC 2007 数据集(含 20 类目标,5011 张图像)上的评估结果:
-
速度:单张图像处理时间从 R-CNN 的 50 秒缩短至 2 秒(提升 25 倍),但 “选择搜索” 生成提议仍需 0.5 秒,占总耗时 25%;
-
精度:平均精度均值(mAP)从 R-CNN 的 66% 提升至 70.0%,其中 “汽车”“人” 等大目标 AP 达 80%+,小目标(如 “鸟”“猫”)AP 仍较低(60% 左右);
-
显存占用:峰值显存从 8GB 降至 4GB,普通 GTX 1060 显卡可支持训练。
6 Fast R-CNN 的创新(延伸至 Faster R-CNN)
6.1 Faster R-CNN 的创新思想
Fast R-CNN 的瓶颈是 “选择搜索”—— 纯手工设计的算法,生成提议耗时且无法通过训练优化。Faster R-CNN 的核心创新是:用 “区域建议网络(RPN)” 替代选择搜索,让 “提议生成” 也成为可训练的神经网络模块,最终实现 “端到端检测”(从图像输入到结果输出,全流程由一个网络完成,无需外部算法)。
6.2 替代选择搜索的锚框(Anchor)
RPN 能生成高质量提议,关键在于 “锚框” 设计 —— 相当于给模型预设 “目标搜索模板”:
-
锚框参数:在特征图每个像素上,预设 9 个锚框,涵盖 3 种尺寸(128×128、256×256、512×512)和 3 种长宽比(1:1、1:2、2:1);
-
锚框作用:覆盖图像中不同大小、不同形状的目标(如 128×128 锚框对应 “小猫”,512×512 锚框对应 “汽车”,1:2 锚框对应 “电线杆”),避免模型漏检特殊形状目标。
举例:若特征图尺寸为 50×37,总锚框数 = 50×37×9=16650 个,远超选择搜索的 2000 个,提议覆盖更全面。
6.3 区域建议网络(RPN)
RPN 是 Faster R-CNN 的 “提议生成器”,基于锚框工作,结构分为两步:
-
特征共享:复用 Fast R-CNN 的特征提取层输出的特征图(无需额外提特征,节省计算);
-
双分支输出:在特征图上滑动 3×3 卷积核,每个位置输出两个结果:
-
分类分支:判断每个锚框是 “前景”(含目标)还是 “背景”(无目标),输出 2 个概率值;
-
回归分支:修正锚框位置和大小,输出 4 个偏移量(让锚框更贴近真实目标)。
最终,RPN 从 16650 个锚框中筛选出 300 个高质量提议(过滤面积过小、越界、背景概率高的锚框),耗时仅 0.02 秒,比选择搜索快 25 倍。
7 深入剖析 Faster R-CNN 中边界框回归
7.1 为什么使用边界框回归
锚框是 “预设模板”,存在两个问题:
-
位置偏移:锚框中心可能与真实目标中心偏差(如锚框在 (100,80),真实猫在 (110,85));
-
尺寸不符:锚框宽高可能与真实目标差异大(如锚框宽 100,真实猫宽 80)。
若直接用锚框作为检测结果,边界框精度会很低(与真实框重叠率不足 60%)。边界框回归的作用就是 “微调锚框”,让修正后的框与真实目标重叠率提升至 80% 以上,确保检测准确性。
7.2 边界框回归的数学支撑
回归通过计算 “偏移量” 修正锚框,设:
-
锚框参数:Aₓ(中心 x 坐标)、Aᵧ(中心 y 坐标)、A_w(宽度)、A_h(高度);
-
真实框参数:Gₓ(中心 x 坐标)、Gᵧ(中心 y 坐标)、G_w(宽度)、G_h(高度);
-
模型预测偏移量:dₓ、dᵧ(位置偏移)、d_w、d_h(尺寸偏移)。
偏移量计算公示:
dₓ = (Gₓ - Aₓ) / A\_w # x方向偏移,除以A\_w是为了归一化(不同尺寸锚框偏移量范围一致)
dᵧ = (Gᵧ - Aᵧ) / A\_h # y方向偏移
d\_w = log(G\_w / A\_w) # 宽度缩放,对数变换确保缩放比例为正(G\_w/A\_w>0)
d\_h = log(G\_h / A\_h) # 高度缩放
修正后框参数:
Pₓ = Aₓ + dₓ × A\_w # 预测框中心x坐标
Pᵧ = Aᵧ + dᵧ × A\_h # 预测框中心y坐标
P\_w = A\_w × exp(d\_w) # 预测框宽度(exp还原对数变换)
P\_h = A\_h × exp(d\_h) # 预测框高度
举例:锚框 Aₓ=100,A_w=50,真实框 Gₓ=110,G_w=40,则 dₓ=(110-100)/50=0.2,d_w=log (40/50)=log (0.8)≈-0.223,修正后 Pₓ=100+0.2×50=110,P_w=50×exp (-0.223)≈40,与真实框完全匹配。
8 Faster R-CNN 的全景架构和损失函数
8.1 全景架构
Faster R-CNN 是 “RPN+Fast R-CNN” 的融合体,共 4 个核心模块,形成闭环:
-
特征提取层:用 VGG16/ResNet50 等 CNN,将原图缩为 16 倍特征图,同时供给 RPN 和 RoI 池化层;
-
RPN 层:基于特征图和锚框,生成 300 个高质量区域提议;
-
RoI 池化层:将提议对应特征图区域压缩为 7×7 特征;
-
检测头:全连接层分支输出:① 21 类分类概率;② 4 个边界框偏移量(修正提议框)。
架构优势:全模块参数共享(特征提取层被 RPN 和检测头共用),无重复计算,端到端训练。
8.2 损失函数
Faster R-CNN 的总损失是 “RPN 损失” 和 “检测头损失” 的总和,确保两个模块协同优化:
总损失 = RPN损失 + 检测头损失
- RPN 损失:针对锚框的优化,含两部分:
-
RPN 分类损失:判断锚框是前景 / 背景(用 Cross-Entropy Loss);
-
RPN 回归损失:修正锚框位置(用 Smooth L1 Loss);
- 检测头损失:针对提议的优化,与 Fast R-CNN 一致:
-
分类损失:判断提议属于 21 类中的哪一类;
-
回归损失:修正提议框位置。
平衡系数 λ:由于回归损失数值通常比分类损失大,需用 λ=10 平衡两者权重,避免分类损失被 “淹没”,公式调整为:
总损失 = RPN分类损失 + λ×RPN回归损失 + 检测头分类损失 + λ×检测头回归损失
9 Faster R-CNN 的训练步骤及测试步骤
9.1 Faster R-CNN 的训练步骤
采用 “四步交替训练法”,确保 RPN 和检测头逐步优化:
-
预训练特征提取器:用 ImageNet 数据集(1000 类图像)预训练 CNN(如 VGG16),得到初始特征提取能力;
-
训练 RPN:固定 CNN 参数,仅训练 RPN 的卷积层和全连接层,让 RPN 能生成准确提议;
-
训练检测头:固定 CNN 和 RPN 参数,用 RPN 生成的提议训练检测头,优化分类和回归能力;
-
联合微调:同时微调 CNN、RPN、检测头的所有参数,让三个模块协同工作(此步骤迭代 10-20 轮,确保整体性能最优)。
9.2 Faster R-CNN 的测试步骤
测试流程快速高效,单张图像处理仅需 0.2 秒:
-
输入图像,经特征提取层生成特征图;
-
RPN 生成 300 个提议,过滤面积 < 16×16、越界的提议;
-
RoI 池化将提议特征压缩为 7×7,输入检测头,得到 21 类概率和修正后的框坐标;
-
非极大值抑制(NMS):去除重叠率 > 0.5 的重复框(如多个框都检测到 “猫”,保留置信度最高的 1 个);
-
输出最终结果:每个目标的类别(如 “猫,置信度 0.95”)和边界框坐标(如 (55,32,205,185))。
10 详细讲解 Faster R-CNN 关键部分 RoI 代码(PyTorch 实现)
RoI 池化是连接 RPN 提议与检测头的核心,以下代码逐行解析其实现逻辑:
\# 1. 导入必要库:F是PyTorch的函数库,含池化、激活等操作
import torch
import torch.nn.functional as F
\# 2. 定义RoIPooling类,继承PyTorch的Module(所有神经网络模块的基类)
class RoIPooling(torch.nn.Module):
  def \_\_init\_\_(self, output\_size):
  \# 初始化父类(必须步骤)
  super(RoIPooling, self).\_\_init\_\_()
  \# 设定RoI池化的输出尺寸(固定为7×7,适配后续全连接层)
  self.output\_size = output\_size # 输入为元组,如(7,7)
  def forward(self, feature\_map, rois):
  \# forward是模型前向传播的核心函数,输入两个参数:
  \# feature\_map:特征提取层输出的特征图,形状为\[batch\_size, channels, H, W]
  \# 例:\[1, 256, 50, 37] → 1张图,256个特征通道,特征图尺寸50×37
  \# rois:RPN生成的区域提议,形状为\[N, 4](N为提议数量,通常300)
  \# 每个提议的4个值:\[x1, y1, x2, y2](左上角x/y,右下角x/y,已归一化到0-1范围)
  \# 3. 将归一化的提议坐标映射到特征图的实际尺寸
  \# 提取特征图的高度H和宽度W
  h, w = feature\_map.shape\[2], feature\_map.shape\[3]
  \# 映射x坐标:归一化x1/x2 × 特征图宽度w → 得到特征图上的实际x坐标
  rois\[:, \[0, 2]] = rois\[:, \[0, 2]] \* w
  \# 映射y坐标:归一化y1/y2 × 特征图高度h → 得到特征图上的实际y坐标
  rois\[:, \[1, 3]] = rois\[:, \[1, 3]] \* h
  \# 坐标需为整数(像素位置),转换为long类型
  rois = rois.long()
  \# 4. 对每个提议执行RoI池化,存储结果
  pool\_results = \[]
  \# 遍历每个提议(N个提议,循环N次)
  for i in range(rois.shape\[0]):
  \# 提取当前提议的坐标:x1, y1, x2, y2
  x1, y1, x2, y2 = rois\[i]
  \# 从特征图中截取当前提议对应的区域:\[通道数, 高度范围, 宽度范围]
  roi\_feature = feature\_map\[:, :, y1:y2, x1:x2]
  \# 用自适应最大值池化,将截取的区域压缩为output\_size(7×7)
  \# adaptive\_max\_pool2d会自动计算池化核大小,无需手动设定
  pooled = F.adaptive\_max\_pool2d(roi\_feature, self.output\_size)
  \# 将当前提议的池化结果加入列表
  pool\_results.append(pooled)
  \# 5. 将所有提议的池化结果拼接成一个张量,形状为\[N, channels, 7, 7]
  \# 例:\[300, 256, 7, 7] → 300个提议,每个提议256通道,7×7特征
  return torch.cat(pool\_results, dim=0)
代码核心逻辑总结:
先将 RPN 输出的 “归一化提议坐标” 映射到特征图的实际像素位置,再逐个截取提议对应的特征区域,最后用自适应池化统一尺寸 —— 确保无论提议原始尺寸如何,都能输出 7×7 的标准特征,为后续检测头的分类和回归提供统一输入。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 24
24 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)