【完整源码+数据集+部署教程】中医舌苔分类检测系统源码和数据集:改进yolo11-bifpn-SDI
【完整源码+数据集+部署教程】中医舌苔分类检测系统源码和数据集:改进yolo11-bifpn-SDI
背景意义
研究背景与意义
中医舌苔作为中医诊断的重要组成部分,能够反映出人体内脏的健康状况和气血的变化。舌苔的颜色、形态及厚度等特征,常常被中医师用来辅助判断疾病的性质和发展阶段。随着现代医学技术的发展,传统的舌苔观察方法逐渐向数字化、智能化转型。基于计算机视觉的舌苔分类检测系统应运而生,能够通过高效、准确的方式分析舌苔特征,辅助中医诊断。
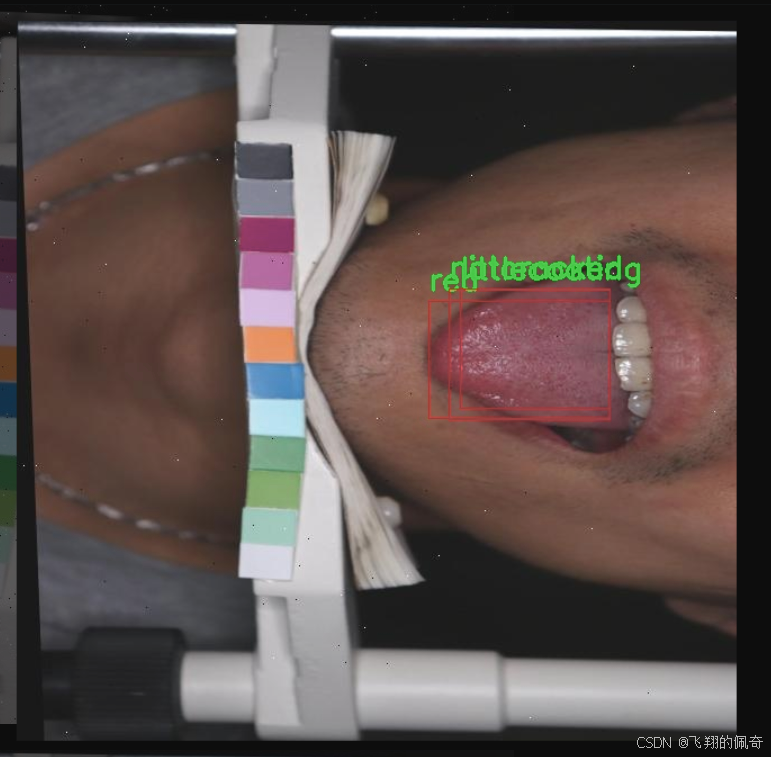
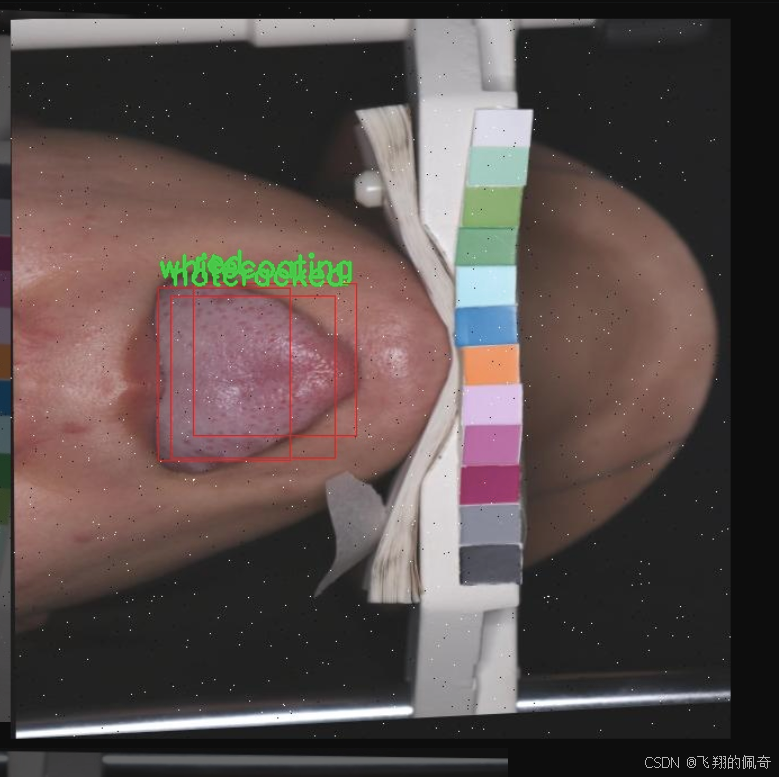
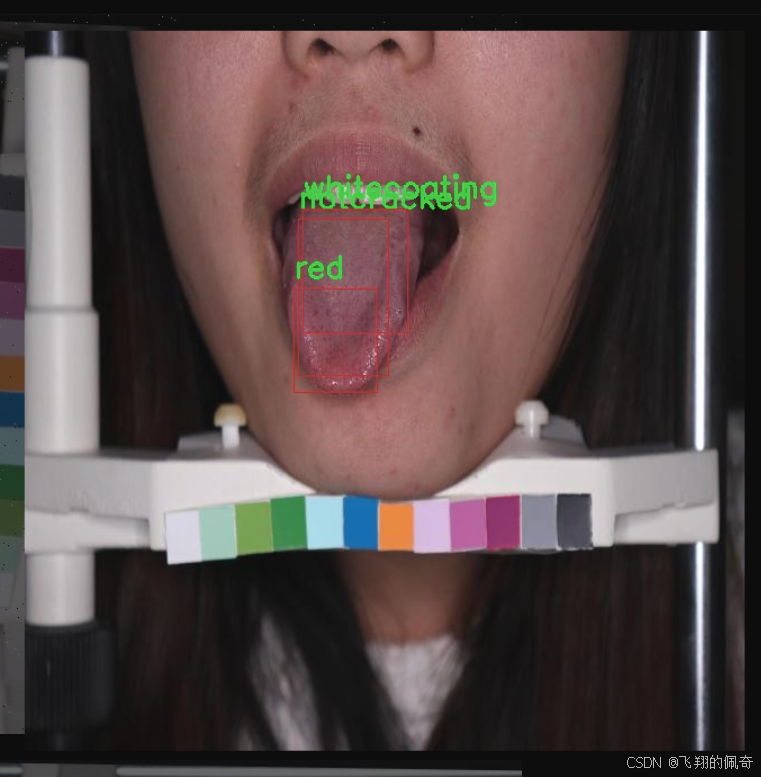
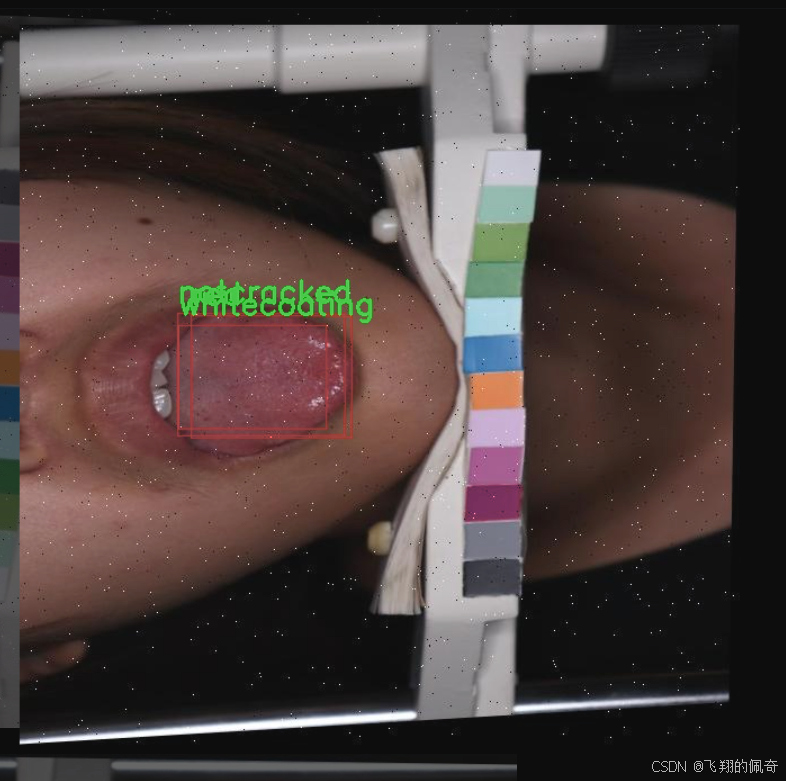
本研究旨在基于改进的YOLOv11模型,构建一个高效的中医舌苔分类检测系统。该系统将针对舌苔的八种主要类型进行分类,包括蓝紫色、裂纹、薄苔、不裂纹、苍白、红色、白苔和黄苔。通过对487幅舌苔图像的深度学习训练,系统将能够自动识别和分类不同类型的舌苔,为中医诊断提供有力的技术支持。
数据集的构建和预处理过程为模型的训练提供了坚实的基础。通过多种数据增强技术,研究确保了模型的鲁棒性和泛化能力。这些技术不仅增加了数据的多样性,还提高了模型在实际应用中的适应性。此外,改进的YOLOv11模型在目标检测领域表现出色,其高效的特征提取能力和实时检测性能,将为舌苔分类提供更加精准的解决方案。
综上所述,基于改进YOLOv11的中医舌苔分类检测系统,不仅为中医诊断提供了现代化的工具,也为推动中医与人工智能的深度融合开辟了新的方向。通过本研究的开展,期望能够提升舌苔分析的效率和准确性,进而促进中医的科学化和规范化发展。
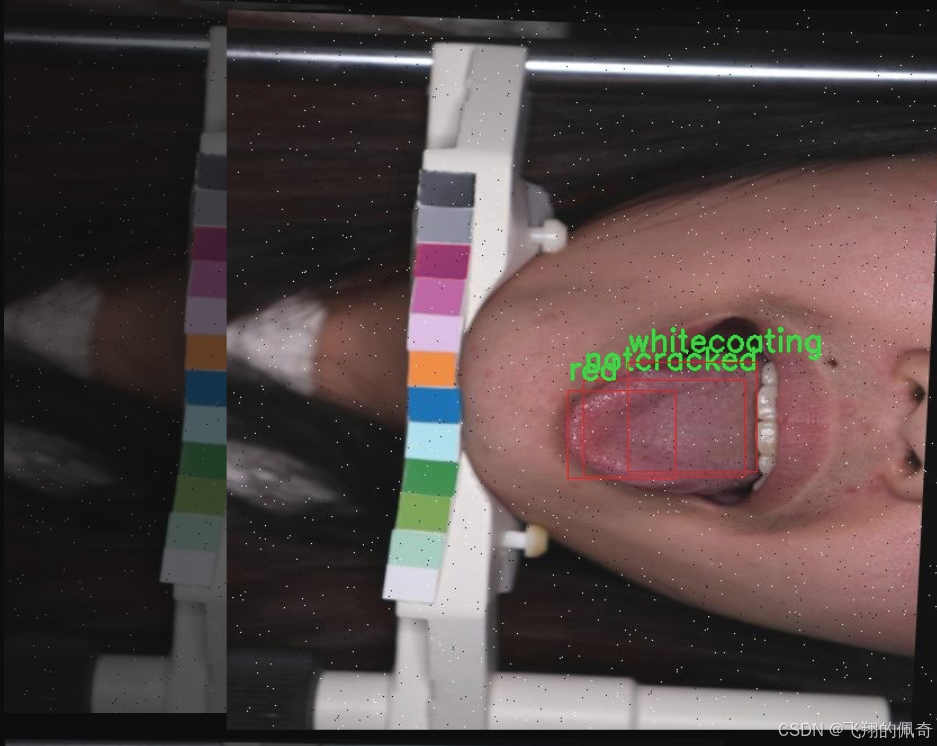
图片效果
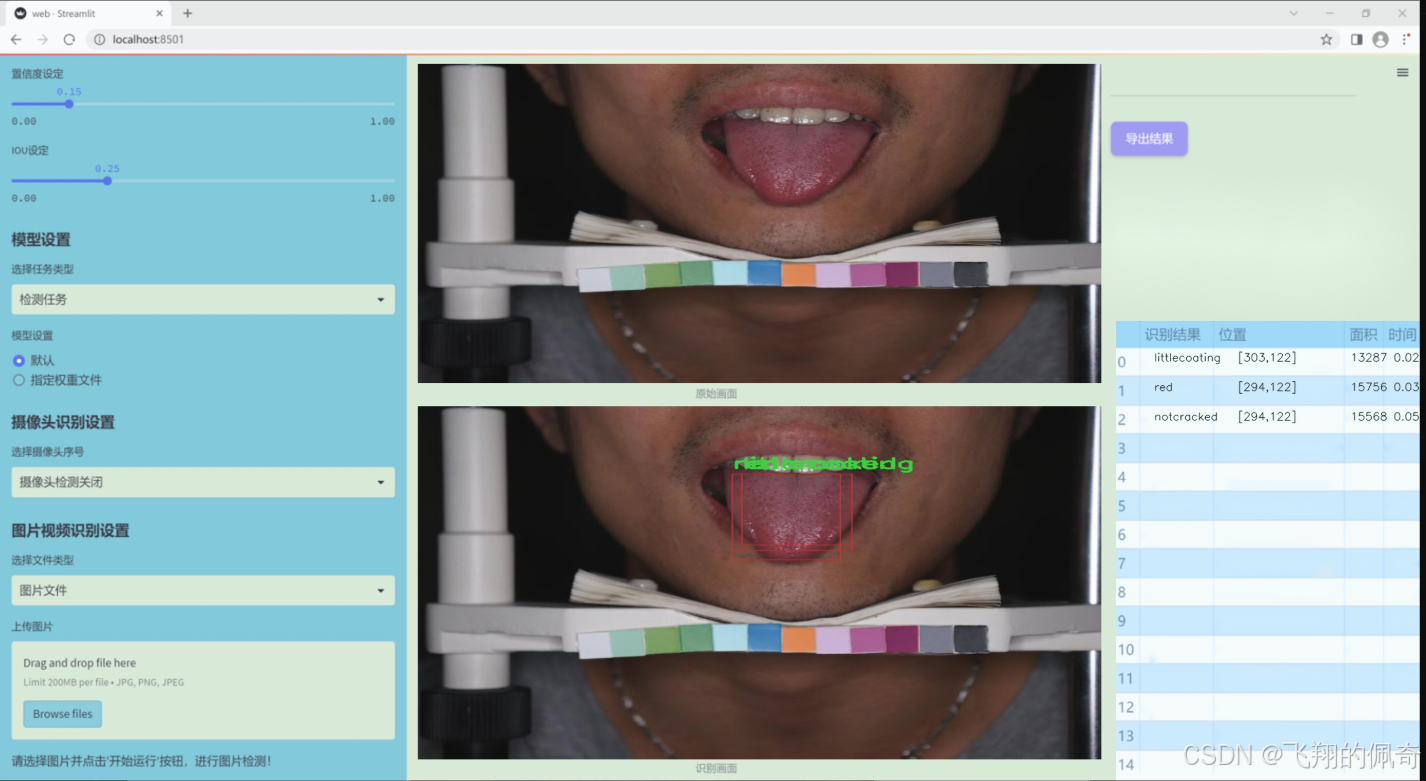
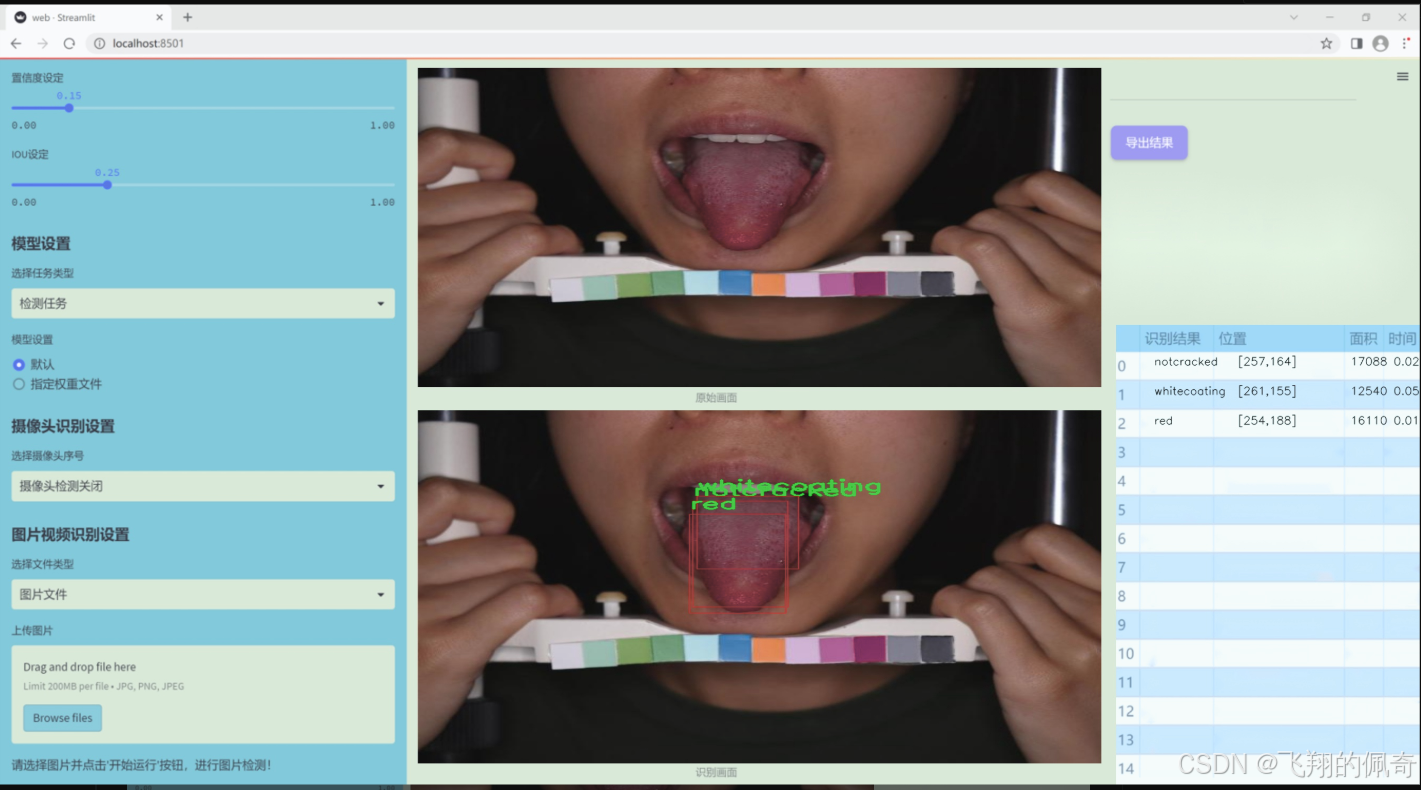
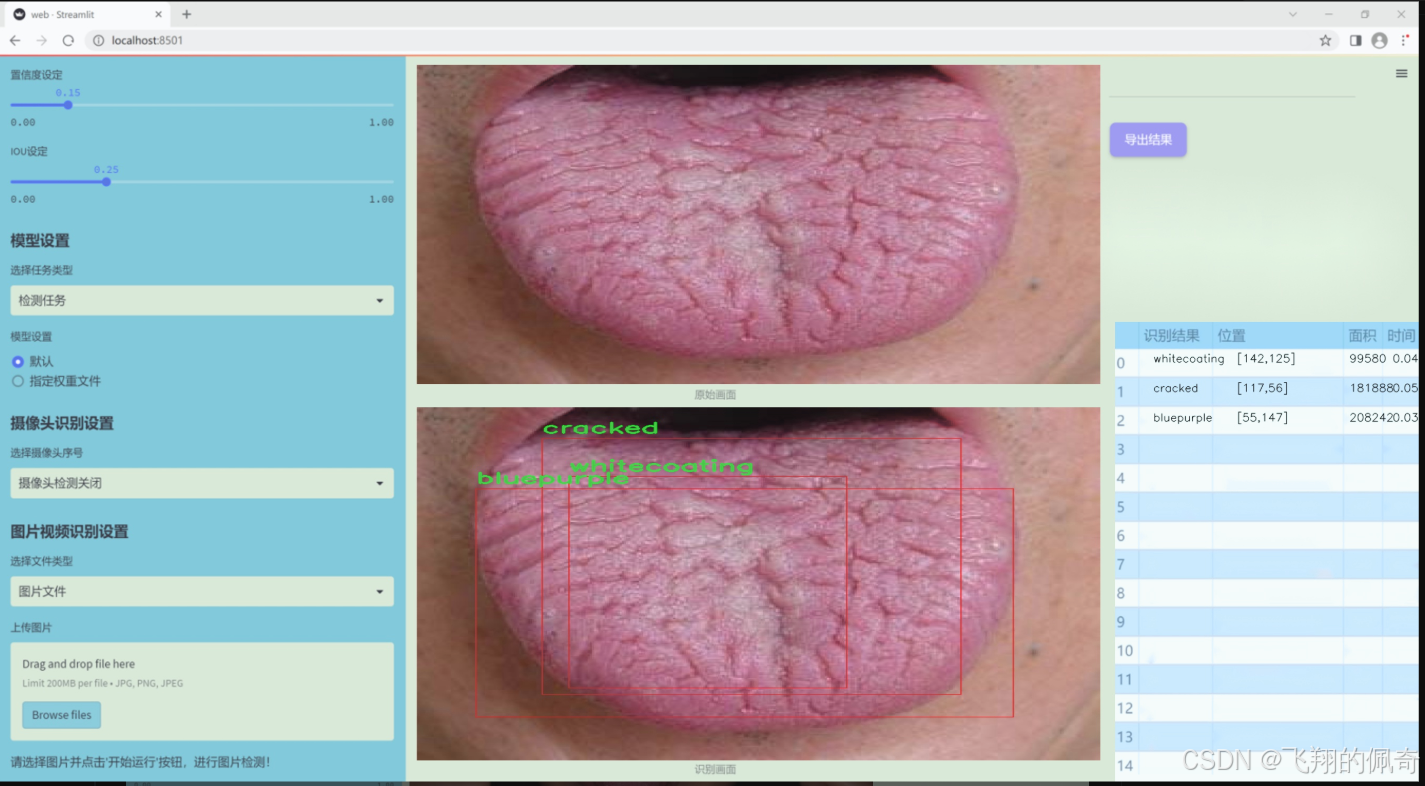
数据集信息
本项目数据集信息介绍
本项目旨在开发一种改进的YOLOv11中医舌苔分类检测系统,为了实现这一目标,我们构建了一个专门针对舌苔特征的多类别数据集。该数据集包含8个不同的舌苔类别,分别为:蓝紫色、裂纹、薄苔、无裂纹、苍白、红色、白苔和黄苔。这些类别的选择是基于中医理论中对舌苔的分类标准,旨在为舌苔的分析和诊断提供更为细致的支持。
数据集的构建过程涵盖了多种舌苔图像的采集,确保了样本的多样性和代表性。每个类别的图像均经过精心挑选,确保能够准确反映出不同舌苔的特征。例如,蓝紫色舌苔通常与气血不足或寒湿内盛相关,而红色舌苔则可能指示体内热邪的存在。通过对这些舌苔特征的细致分类,我们的目标是提高模型在舌苔分析中的准确性和鲁棒性。
在数据集的标注过程中,我们采用了专业的中医医师进行审核,以确保每个图像的类别标注符合中医理论的标准。这一过程不仅提升了数据集的质量,也为后续的模型训练提供了可靠的基础。通过使用这一数据集,我们期望改进YOLOv11的性能,使其在舌苔分类检测任务中能够实现更高的准确率和更快的响应速度,从而为中医诊断提供更加高效的技术支持。
核心代码
以下是代码中最核心的部分,保留了YOLOv8检测头的实现,并添加了详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
from …modules import Conv, DFL, make_anchors, dist2bbox
class Detect_DyHead(nn.Module):
“”“YOLOv8检测头,使用动态头进行目标检测。”“”
def __init__(self, nc=80, hidc=256, block_num=2, ch=()):
"""
初始化检测头的参数。
参数:
nc (int): 类别数量,默认为80。
hidc (int): 隐藏层通道数,默认为256。
block_num (int): 动态头块的数量,默认为2。
ch (tuple): 输入通道数的元组。
"""
super().__init__()
self.nc = nc # 类别数量
self.nl = len(ch) # 检测层的数量
self.reg_max = 16 # DFL通道数
self.no = nc + self.reg_max * 4 # 每个锚点的输出数量
self.stride = torch.zeros(self.nl) # 构建时计算的步幅
self.conv = nn.ModuleList(nn.Sequential(Conv(x, hidc, 1)) for x in ch) # 输入通道的卷积层
self.dyhead = nn.Sequential(*[DyHeadBlock(hidc) for _ in range(block_num)]) # 动态头块
self.cv2 = nn.ModuleList(
nn.Sequential(Conv(hidc, hidc // 4, 3), Conv(hidc // 4, hidc // 4, 3), nn.Conv2d(hidc // 4, 4 * self.reg_max, 1)) for _ in ch
) # 生成框的卷积层
self.cv3 = nn.ModuleList(
nn.Sequential(
nn.Sequential(Conv(hidc, hidc, 3), Conv(hidc, hidc, 1)),
nn.Conv2d(hidc, self.nc, 1),
)
for _ in ch
) # 类别的卷积层
self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity() # DFL层
def forward(self, x):
"""前向传播,返回预测的边界框和类别概率。"""
for i in range(self.nl):
x[i] = self.conv[i](x[i]) # 通过卷积层处理输入
x = self.dyhead(x) # 通过动态头处理
shape = x[0].shape # 获取输出形状
for i in range(self.nl):
x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1) # 拼接生成框和类别的输出
if self.training:
return x # 训练模式下返回中间结果
else:
# 动态锚点生成
self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5))
x_cat = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2) # 拼接所有输出
box, cls = x_cat.split((self.reg_max * 4, self.nc), 1) # 分割边界框和类别
dbox = dist2bbox(self.dfl(box), self.anchors.unsqueeze(0), xywh=True, dim=1) * self.strides # 解码边界框
y = torch.cat((dbox, cls.sigmoid()), 1) # 返回边界框和类别概率
return y
def bias_init(self):
"""初始化检测头的偏置,警告:需要步幅可用。"""
for a, b, s in zip(self.cv2, self.cv3, self.stride):
a[-1].bias.data[:] = 1.0 # 边界框偏置初始化
b[-1].bias.data[:self.nc] = math.log(5 / self.nc / (640 / s) ** 2) # 类别偏置初始化
代码核心部分解释:
类定义:Detect_DyHead是YOLOv8的检测头,负责生成目标检测的边界框和类别概率。
初始化方法:设置类别数量、隐藏层通道数、动态头块数量等参数,并构建卷积层和动态头。
前向传播方法:处理输入数据,生成边界框和类别概率,并在训练和推理模式下有不同的返回值。
偏置初始化:初始化边界框和类别的偏置,以提高模型的性能。
以上是YOLOv8检测头的核心实现,包含了必要的注释以帮助理解每个部分的功能。
这个程序文件 head.py 是一个用于 YOLOv8 目标检测模型的实现,主要定义了不同的检测头(Detect Head)类。这些类用于处理输入特征图并生成目标检测的输出,包括边界框和类别概率。以下是对文件内容的详细说明:
首先,文件导入了一些必要的库,包括 torch 和 torch.nn,以及一些自定义模块和函数。all 列表定义了可以被外部导入的类。
接下来,定义了多个检测头类,每个类都有其特定的结构和功能。主要的检测头类包括:
Detect_DyHead:这是一个动态头,用于处理检测模型。它初始化了一些参数,如类别数量、隐藏通道数、块数量等。forward 方法实现了前向传播,计算预测的边界框和类别概率。
Detect_AFPN_P345 和 Detect_AFPN_P2345:这些类实现了带有自适应特征金字塔网络(AFPN)的检测头,适用于不同的特征层组合。
Detect_Efficient:实现了高效的检测头,使用了更少的参数和计算量。
DetectAux:实现了一个辅助检测头,适用于多任务学习。
Detect_LSCD 和 Detect_LSCSBD:实现了轻量级共享卷积检测头,优化了计算效率。
Detect_TADDH:实现了任务动态对齐检测头,利用了任务分解的思想来处理特征。
Detect_NMSFree:实现了无非极大值抑制(NMS)的检测头,适用于需要更高效后处理的场景。
每个检测头类都实现了 forward 方法,负责将输入特征图经过卷积层处理,生成边界框和类别概率。类中还定义了 bias_init 方法,用于初始化偏置参数,以提高模型的收敛速度。
此外,文件中还定义了一些辅助类,如 Scale 和 Conv_GN,用于实现可学习的缩放参数和标准卷积操作。
最后,文件中还包含了一些用于分割和姿态估计的检测头类,如 Segment_Efficient、Pose_LSCD 和 OBB_LSCD,这些类扩展了目标检测的功能,支持更多的任务。
整体来看,这个文件实现了 YOLOv8 模型的检测头部分,提供了多种不同的检测头结构,以适应不同的应用场景和需求。
10.3 hcfnet.py
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SpatialAttentionModule(nn.Module):
def init(self):
super(SpatialAttentionModule, self).init()
# 定义一个2D卷积层,用于生成空间注意力图
self.conv2d = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3)
self.sigmoid = nn.Sigmoid() # 使用Sigmoid激活函数将输出限制在0到1之间
def forward(self, x):
# 计算输入特征图的平均值和最大值
avgout = torch.mean(x, dim=1, keepdim=True) # 平均池化
maxout, _ = torch.max(x, dim=1, keepdim=True) # 最大池化
# 将平均值和最大值拼接在一起
out = torch.cat([avgout, maxout], dim=1)
# 通过卷积层和Sigmoid激活函数生成注意力图
out = self.sigmoid(self.conv2d(out))
return out * x # 将注意力图应用于输入特征图
class PPA(nn.Module):
def init(self, in_features, filters) -> None:
super().init()
# 定义多个卷积层和注意力模块
self.skip = nn.Conv2d(in_features, filters, kernel_size=1, bias=False) # 跳跃连接
self.c1 = nn.Conv2d(filters, filters, kernel_size=3, padding=1)
self.c2 = nn.Conv2d(filters, filters, kernel_size=3, padding=1)
self.c3 = nn.Conv2d(filters, filters, kernel_size=3, padding=1)
self.sa = SpatialAttentionModule() # 空间注意力模块
self.drop = nn.Dropout2d(0.1) # Dropout层
self.bn1 = nn.BatchNorm2d(filters) # 批归一化
self.silu = nn.SiLU() # SiLU激活函数
def forward(self, x):
# 通过跳跃连接获取特征
x_skip = self.skip(x)
# 通过多个卷积层处理输入
x1 = self.c1(x)
x2 = self.c2(x1)
x3 = self.c3(x2)
# 将所有特征图相加
x = x1 + x2 + x3 + x_skip
x = self.sa(x) # 应用空间注意力模块
x = self.drop(x) # 应用Dropout
x = self.bn1(x) # 批归一化
x = self.silu(x) # 激活函数
return x # 返回处理后的特征图
class DASI(nn.Module):
def init(self, in_features, out_features) -> None:
super().init()
self.tail_conv = nn.Conv2d(out_features, out_features, kernel_size=1) # 尾部卷积层
self.skips = nn.Conv2d(in_features[1], out_features, kernel_size=1) # 跳跃连接
self.bns = nn.BatchNorm2d(out_features) # 批归一化
self.silu = nn.SiLU() # SiLU激活函数
def forward(self, x_list):
# 从输入列表中获取不同分辨率的特征图
x_low, x, x_high = x_list
x = self.skips(x) # 通过跳跃连接处理中间特征图
x_skip = x # 保存跳跃连接的输出
x = torch.chunk(x, 4, dim=1) # 将特征图分成4个部分
# 处理不同分辨率的特征图
if x_high is not None:
x_high = self.skips(x_high)
x_high = torch.chunk(x_high, 4, dim=1)
if x_low is not None:
x_low = self.skips(x_low)
x_low = F.interpolate(x_low, size=[x.size(2), x.size(3)], mode='bilinear', align_corners=True)
x_low = torch.chunk(x_low, 4, dim=1)
# 将不同分辨率的特征图结合
if x_high is None:
x0 = self.conv(torch.cat((x[0], x_low[0]), dim=1))
x1 = self.conv(torch.cat((x[1], x_low[1]), dim=1))
x2 = self.conv(torch.cat((x[2], x_low[2]), dim=1))
x3 = self.conv(torch.cat((x[3], x_low[3]), dim=1))
elif x_low is None:
x0 = self.conv(torch.cat((x[0], x_high[0]), dim=1))
x1 = self.conv(torch.cat((x[1], x_high[1]), dim=1))
x2 = self.conv(torch.cat((x[2], x_high[2]), dim=1))
x3 = self.conv(torch.cat((x[3], x_high[3]), dim=1))
else:
x0 = self.bag(x_low[0], x_high[0], x[0])
x1 = self.bag(x_low[1], x_high[1], x[1])
x2 = self.bag(x_low[2], x_high[2], x[2])
x3 = self.bag(x_low[3], x_high[3], x[3])
# 将处理后的特征图拼接
x = torch.cat((x0, x1, x2, x3), dim=1)
x = self.tail_conv(x) # 通过尾部卷积层
x += x_skip # 加上跳跃连接的输出
x = self.bns(x) # 批归一化
x = self.silu(x) # 激活函数
return x # 返回最终输出
代码说明:
SpatialAttentionModule: 该模块实现了空间注意力机制,通过计算输入特征图的平均值和最大值来生成注意力图,并将其应用于输入特征图上。
PPA: 该模块是一个特征提取器,使用多个卷积层和空间注意力模块来处理输入特征图,并通过跳跃连接增强特征。
DASI: 该模块结合了不同分辨率的特征图,使用跳跃连接和卷积层进行特征融合,并应用批归一化和激活函数来生成最终输出。
这个程序文件 hcfnet.py 实现了一个深度学习模型的几个模块,主要用于图像处理任务。代码中使用了 PyTorch 框架,定义了多个神经网络层和模块,具体包括空间注意力模块、局部全局注意力模块、ECA(Efficient Channel Attention)、PPA(Parallel Processing Attention)和 DASI(Dynamic Attention with Skip Connections)等。
首先,SpatialAttentionModule 类实现了一个空间注意力机制。它通过对输入特征图进行平均池化和最大池化,生成两个特征图,然后将它们拼接在一起并通过一个卷积层和 Sigmoid 激活函数生成注意力权重。最终,输入特征图与注意力权重相乘,以增强重要特征。
接下来,LocalGlobalAttention 类则实现了局部和全局的注意力机制。它将输入特征图划分为小块,经过多层感知机(MLP)处理后生成局部特征,并计算注意力权重。局部特征通过余弦相似度与一个可学习的提示向量进行比较,生成掩码,最后通过一个线性变换和上采样恢复到原始特征图的尺寸。
ECA 类实现了一种高效的通道注意力机制。它使用自适应平均池化和一维卷积来生成通道权重,并通过 Sigmoid 激活函数来调整输入特征图的通道强度。
PPA 类是一个复合模块,结合了前面提到的空间注意力、ECA 和局部全局注意力。它通过多个卷积层处理输入特征,并在不同层次上应用注意力机制,最终输出经过归一化和激活函数处理的特征图。
Bag 类实现了一种加权融合机制,通过计算边缘注意力来结合不同来源的特征图。
最后,DASI 类是一个更复杂的模块,结合了来自不同尺度的特征图。它使用跳跃连接和卷积层来融合高、低分辨率特征,并通过 Bag 模块来实现动态加权融合。这个模块的设计使得模型能够更好地捕捉多尺度信息,从而提高性能。
整体来看,这个文件实现了一种先进的图像处理网络结构,利用注意力机制和多尺度特征融合来增强模型的表达能力,适用于各种计算机视觉任务。
10.4 prepbn.py
以下是经过简化和详细注释的核心代码部分:
import torch
import torch.nn as nn
定义一个自定义的批量归一化类
class RepBN(nn.Module):
def init(self, channels):
super(RepBN, self).init()
# 定义一个可学习的参数 alpha,初始值为 1
self.alpha = nn.Parameter(torch.ones(1))
# 定义一个一维批量归一化层
self.bn = nn.BatchNorm1d(channels)
def forward(self, x):
# 将输入的维度进行转置,以适应 BatchNorm 的输入格式
x = x.transpose(1, 2)
# 进行批量归一化,并加上 alpha 权重的原始输入
x = self.bn(x) + self.alpha * x
# 再次转置回原来的维度
x = x.transpose(1, 2)
return x
定义一个线性归一化类
class LinearNorm(nn.Module):
def init(self, dim, norm1, norm2, warm=0, step=300000, r0=1.0):
super(LinearNorm, self).init()
# 注册缓冲区用于存储 warm-up 计数器和迭代计数器
self.register_buffer(‘warm’, torch.tensor(warm))
self.register_buffer(‘iter’, torch.tensor(step))
self.register_buffer(‘total_step’, torch.tensor(step))
self.r0 = r0 # 初始比例
# 初始化两个归一化层
self.norm1 = norm1(dim)
self.norm2 = norm2(dim)
def forward(self, x):
if self.training: # 如果模型处于训练模式
if self.warm > 0: # 如果仍在 warm-up 阶段
self.warm.copy_(self.warm - 1) # 减少 warm-up 计数
x = self.norm1(x) # 仅使用 norm1 进行归一化
else:
# 计算当前的 lamda 值,用于加权
lamda = self.r0 * self.iter / self.total_step
if self.iter > 0:
self.iter.copy_(self.iter - 1) # 减少迭代计数
# 使用两个不同的归一化方法
x1 = self.norm1(x)
x2 = self.norm2(x)
# 线性组合两个归一化的结果
x = lamda * x1 + (1 - lamda) * x2
else:
# 如果不是训练模式,直接使用 norm2 进行归一化
x = self.norm2(x)
return x
代码说明:
RepBN 类:实现了一个自定义的批量归一化层,除了进行标准的批量归一化外,还引入了一个可学习的参数 alpha,用于调整输入特征的权重。
LinearNorm 类:实现了一个线性归一化层,结合了两个不同的归一化方法(norm1 和 norm2)。在训练过程中,使用 warm-up 机制逐步过渡到两种归一化的线性组合。
这个程序文件定义了两个神经网络模块,分别是 RepBN 和 LinearNorm,它们都继承自 PyTorch 的 nn.Module 类,用于实现特定的归一化操作。
RepBN 类实现了一种自定义的批量归一化(Batch Normalization)。在初始化方法中,它接受一个参数 channels,用于定义输入数据的通道数。该类中定义了一个可学习的参数 alpha,初始值为 1,并且创建了一个标准的批量归一化层 bn。在 forward 方法中,输入 x 首先进行维度转换,将通道维度和序列维度交换。接着,输入数据通过批量归一化层进行处理,并与 alpha 乘以原始输入相加。最后,再次进行维度转换,返回处理后的结果。
LinearNorm 类则实现了一种线性归一化的机制,允许在训练过程中根据迭代次数动态调整归一化的方式。初始化时,它接受多个参数,包括 dim(维度)、norm1 和 norm2(两个归一化方法)、warm(预热步数)、step(总步数)和 r0(初始比例因子)。在 forward 方法中,如果模型处于训练状态且预热步数大于 0,则使用 norm1 进行归一化,并减少预热步数。如果预热结束,则根据当前的迭代次数计算一个比例因子 lamda,并使用 norm1 和 norm2 进行线性组合,返回加权后的结果。如果模型处于评估状态,则直接使用 norm2 进行归一化。
整体来看,这个文件提供了两种不同的归一化方法,分别适用于不同的训练阶段和需求,旨在提高模型的训练效果和稳定性。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 15
15 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)