CPMF复现笔记(2):训练MVTecAD-3D数据集, 精度SOTA
在上一篇博文中,我详细介绍了CPMF的环境配置与数据预处理,预处理的作用有2个:第一是去除背景(这也是几乎所有MVTecAD-3D相关文章都会进行的操作),二是生成多视角图像和与之对应的点云特征。小插曲:root/feature_extractors/features.py的第66行需要稍微修改一点,因为模型和数据一个在cpu一个在gpu,不然会报错。可以看到,对于每一个xyz,都生成了一系列的各
文章来自曹云康的最新论文《Complementary Pseudo Multimodal Feature for Point Cloud Anomaly Detection》,在MVTecAD-3D取得了最佳分数。代码地址GitHub - caoyunkang/CPMF: [PR] Complementary Pseudo Multimodal Feature for Point Cloud Anomaly Detection

在上一篇博文中,我详细介绍了CPMF的环境配置与数据预处理,预处理的作用有2个:第一是去除背景(这也是几乎所有MVTecAD-3D相关文章都会进行的操作),二是生成多视角图像和与之对应的点云特征。
经过预处理的数据集结构如下:

可以看到,对于每一个xyz,都生成了一系列的各个视角的图像。生成个数在预处理参数中可以指定。这里我没有进行修改,还是默认的27个。
生成好了之后,就可以直接运行作者提供的训练代码了。data-path就是之前生成的这个多视角数据集。exp-name是这次实验的名称,会按照这个名称保存结果。
python main.py --category bagel --n-views 27 --no-fpfh False --data-path $data_dir --exp-name $exp_name --backbone resnet18举例,我使用的指令如下。
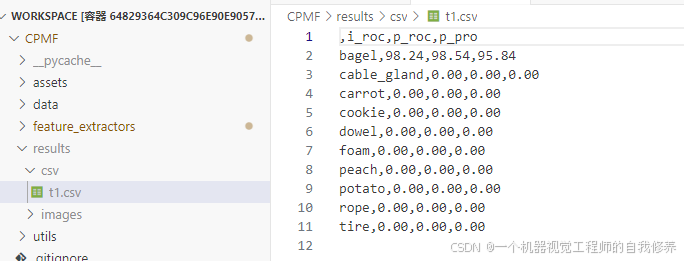
python main.py --category bagel --n-views 27 --no-fpfh False --data-path ../datasets/mvtec_3d/mvtec_3d_multiview --exp-name t1 --backbone resnet18在这里,我的实验名称为t1,那么我得到的结果保存在results/csv/t1.csv中。
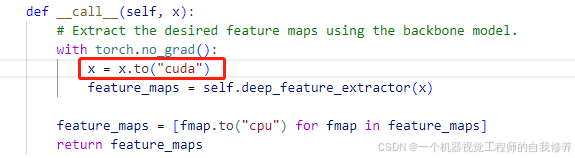
小插曲1:root/feature_extractors/features.py的第66行需要稍微修改一点,因为模型和数据一个在cpu一个在gpu,不然会报错
RuntimeError: Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same or input should be a MKLDNN tensor and weight is a dense tensor小插曲2:作者给的训练代码默认是不生成异常分数的图像的,如果需要生成,要添加 --draw True参数。生成时可能因为我的某些包的版本与作者不同,会报错OSError: 'science' is not a valid package style, path of style file, URL of style file, or library style name (library styles are listed in `style.available`)。解决方法也很简单,把root/utils/visz_utils.py的176行从下面第一行修改成第二行就可以。结果同样在results/images/exp-name路径下。
with plt.style.context(['science', 'ieee', 'no-latex']):with plt.style.use(['science', 'notebook', 'ieee']):结果对比:
下图是文章中的数据,贝果类别的Image ROCAUC和AU PRO分别为0.9830和0.9576



![]()
我运行的结果为0.9828和0.9584,与论文非常符合。


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)