PL/PGSQL实战:OpenGauss数据库开发技巧
PLPGSQL是一种程序语言,叫做过程化SQL语言(),pl/pgsql是PostgreSQL数据库对SQL语句的扩展。在普通SQL语句的使用上增加了编译语言的特点,所以pl/pgsql就是把数据操作和查询语句组织在pl/pgsql代码的过程性单元中,通过逻辑判断、循环等操作实现复杂的功能或者计算的程序语言。本案例选择OpenGauss数据库作为示例,并借助开发者空间云主机提供的免费OpenEul
目录
UPDATE/DELETE WHERE CURRENT OF
案例介绍
PLPGSQL是一种程序语言,叫做过程化SQL语言(Procedural Language/Postgres SQL),pl/pgsql是PostgreSQL数据库对SQL语句的扩展。在普通SQL语句的使用上增加了编译语言的特点,所以pl/pgsql就是把数据操作和查询语句组织在pl/pgsql代码的过程性单元中,通过逻辑判断、循环等操作实现复杂的功能或者计算的程序语言。
本案例选择OpenGauss数据库作为示例,并借助开发者空间云主机提供的免费OpenEuler系统环境和OpenGaussDB实例,直观地展示 PL/PGSQL在商业应用开发与过程化编程能力和实际应用开发中为开发者带来的便利。
通过实际操作,让大家深入了解如何利用 PLPGSQL 开发并部署一个函数功能模块。在这个过程中,大家将学习到从函数创建、数据批量读取到SQL程序编写以及与触发器集成等一系列关键步骤,从而掌握 PLPGSQL 的基本使用方法,体验其在应用开发中的优势。
PL/PGSQL实践
PLPGSQL是数据库的编程语言。相当于在数据库中用SQL语言进行逻辑处理与代码开发。可以把业务系统中封装的功能模块下沉到数据库端实现,以达到减轻业务系统的逻辑压力、降低架构复杂度和简化业务系统实现难度。
PLPGSQL是一种块结构型语言,例如匿名块,存储过程和函数体的完整文本必须是块。块定义如下:
[ <<标签>> ]
[ 声明
变量;
变量 := 赋值 ]
BEGIN
SQL QUERY
END [ 标签];
PLPGSQL定义的功能模块(存储过程和函数)可以互相嵌套。例如SQL块中嵌套子SQL块,存储过程引用PLPGSQL定义的其他函数和模块功能。
变量赋值与引用
变更声明与赋值
SQL块中所使用的所有变量都必须在plpgsql定义body的开头,用关键字 DECLARE 声明。
变量声明的语法
name [ CONSTANT ] type [ COLLATE collation_name ] [ NOT NULL ] [ { DEFAULT | := | = } expression ];例如:
DECLARE
var1 TEXT;
var2 INTEGER := 10;
url VARCHAR;
quantity NUMERIC(5);
myrow tablename%ROWTYPE;
myfield tablename.columnname%TYPE;
arow RECORD;
CURSOR c1 IN SELECT col1, col2 FROM table_name WHER 谓词过滤条件;
以上的示例为声明块(DECLARE), := 为PL/SQL中的等号赋值。
DECLARE
quantity integer DEFAULT 32;
url varchar := 'http://mysite.com';
transaction_time CONSTANT timestamp with time zone := now();
tax := subtotal * 0.06;
my_record.user_id := 20;
my_array[j] := 20;
my_array[1:3] := array[1,2,3];
complex_array[n].realpart = 12.3;
变量一旦声明,变量的值就可以在同一SQL块中后续初始化表达式中被使用,例如:
DECLARE
x integer := 1;
y integer := x + 1;
变量声明之Function Parameters
引用变量不需要声明,变量引用主要用于函数参数引用。传递给函数的参数使用标识符 $1、$2 等命名,也可以为 $n 参数名声明别名,以增加可读性。然后,可以使用别名或数字标识符来引用参数值。
有两种方法可以创建别名。首选的方法是在 CREATE FUNCTION 命令中为参数指定一个名称,例如:
CREATE FUNCTION sales_tax(subtotal real) RETURNS real AS $$
BEGIN
RETURN subtotal * 0.06;
END;
$$ LANGUAGE plpgsql;

另一种方法是显式声明别名,使用声明语法
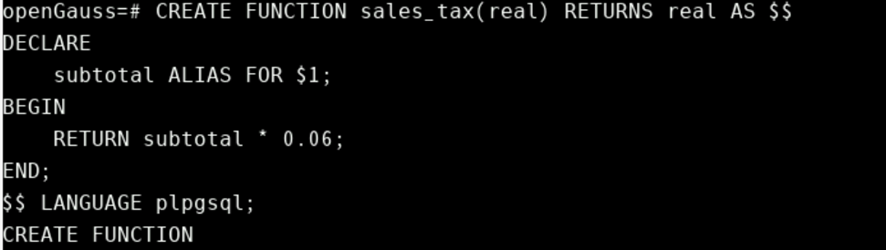
name ALIAS FOR $n;此样式中的相同示例如下所示:
CREATE FUNCTION sales_tax(real) RETURNS real AS $$
DECLARE
subtotal ALIAS FOR $1;
BEGIN
RETURN subtotal * 0.06;
END;
$$ LANGUAGE plpgsql;
注解:
下面两个用例不完全等价。在第一个用例情况下,参数可以引用为 int_t.sales_tax,但在第二个用例下,它不能引用(除非在内部块附加一个标签,参数可以使用该标签来替代)。
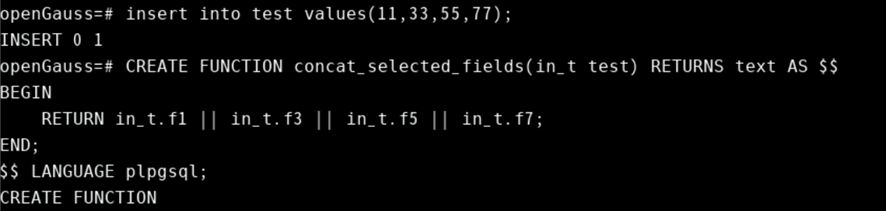
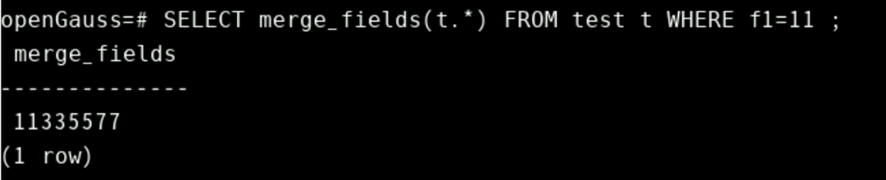
下面用例参数int_t的类型sometablename是当前表的表名。由于该函数中使用了表字段的f1,f3,f5,f7四列,所以这块根据实际引用表结构而对应的改变引用字段名。
CREATE FUNCTION concat_selected_fields(in_t sometablename) RETURNS text AS $$
BEGIN
RETURN in_t.f1 || in_t.f3 || in_t.f5 || in_t.f7;
END;
$$ LANGUAGE plpgsql;

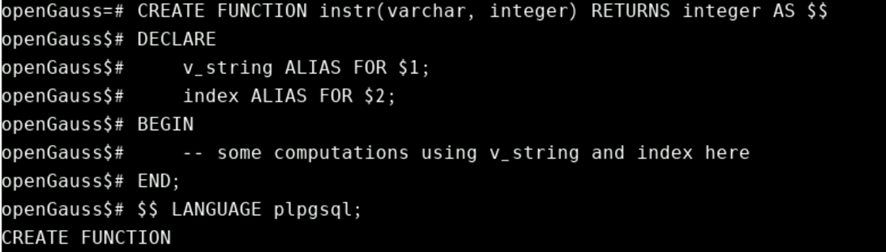
CREATE FUNCTION instr(varchar, integer) RETURNS integer AS $$
DECLARE
v_string ALIAS FOR $1;
index ALIAS FOR $2;
BEGIN
-- some computations using v_string and index here
END;
$$ LANGUAGE plpgsql;
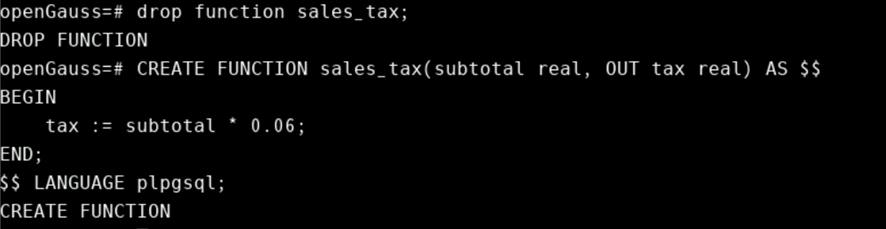
当使用输出参数声明PL/PGSQL函数时,与正常输入参数相同的方式为输出参数提供 $n 名称和可选别名。输出参数实际上是一个以NULL开关的变量;它应该在函数执行期间赋值。参数的最终值是返回值。例如上面的第一个示例也可以用下面的方式实现。
CREATE FUNCTION sales_tax(subtotal real, OUT tax real) AS $$
BEGIN
tax := subtotal * 0.06;
END;
$$ LANGUAGE plpgsql;
创建函数前确保该函数不存在,否则同schema下同名函数冲突。
注意:此处省略了返回值 RETURN real。
要调用具有OUT参数的函数,在函数调用中省略输出参数(s)。
SELECT sales_tax(100.00);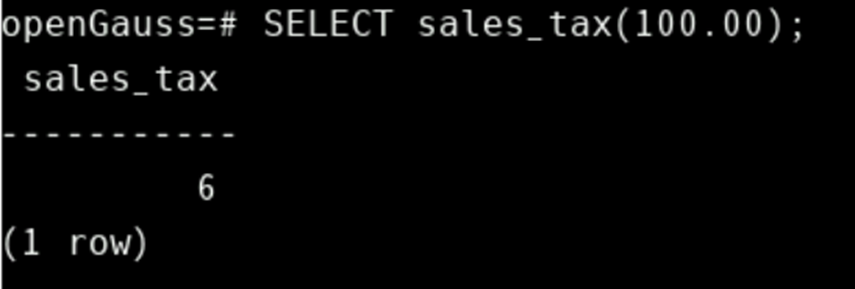
在返回多个值时,输出参数非常有用。如下:
CREATE FUNCTION sum_n_product(x int, y int, OUT sum int, OUT prod int) AS $$
BEGIN
sum := x + y;
prod := x * y;
END;
$$ LANGUAGE plpgsql;
SELECT * FROM sum_n_product(2, 4);
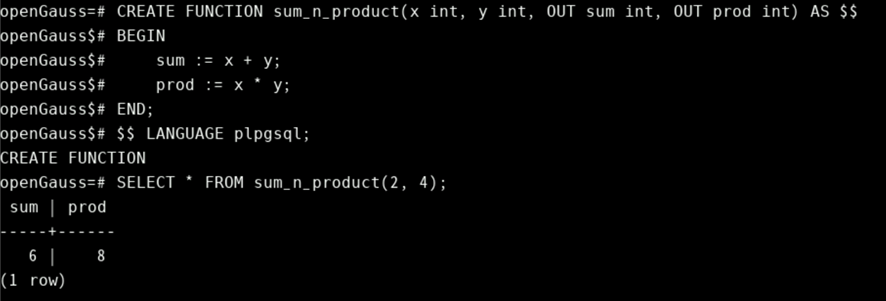
这种写法有效地创建了函数结果的匿名记录类型。如果给出 RETURN 子句,则必须是RETURN RECORD。
如果把上面的函数 sum_n_product 改写成存储过程,如下:
CREATE PROCEDURE sum_n_product(x int, y int, OUT sum int, OUT prod int) AS
BEGIN
sum := x + y;
prod := x * y;
END;

在对存储过程的调用中,必须指定所有参数。对于输出参数,从普通SQL调用过程时可以指定NULL:
CALL sum_n_product(2, 4, NULL, NULL);截图运行结果
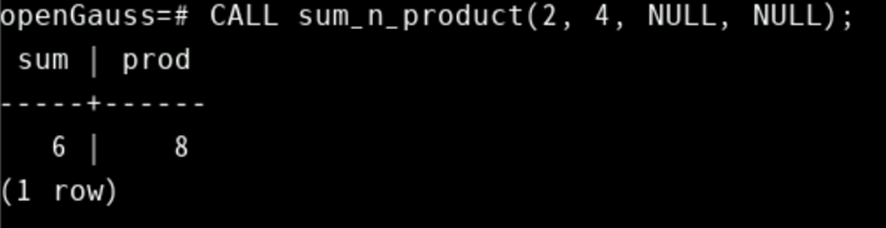
但是,当从PL/PGSQL调用存储过程时,应该为任何输出参数编写一个变量;该变量将接收调用的结果。PL/PGSQL函数的另一种方法是声明返回类型 RETURNS TABLE。例如:
CREATE FUNCTION extended_sales(p_itemno int)
RETURNS TABLE(quantity int, total numeric) AS $$
BEGIN
RETURN QUERY SELECT s.quantity, s.quantity * s.price FROM sales AS s
WHERE s.itemno = p_itemno;
END;
$$ LANGUAGE plpgsql;
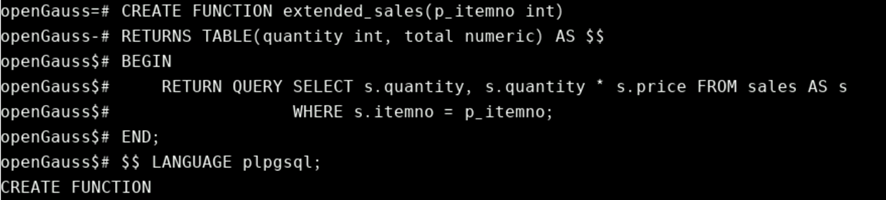
该方式完全等价于声明一个或多个OUT参数并指定 RETURNS SETOF 类型。
当PL/PGSQL函数的返回类型声明为多态类型时将创建一个特殊参数 $0 。它的数据类型根据实际输入类型推断出函数的返回类型。$0 被初始化为NULL,并且可以被函数修改,因此它也可以用来保存返回值。$0 也可作别名。例如下面函数适用于 + 运算符的任何数据类型:
CREATE FUNCTION add_three_values(v1 anyelement, v2 anyelement, v3 anyelement)
RETURNS anyelement AS $$
DECLARE
result ALIAS FOR $0;
BEGIN
result := v1 + v2 + v3;
RETURN result;
END;
$$ LANGUAGE plpgsql;
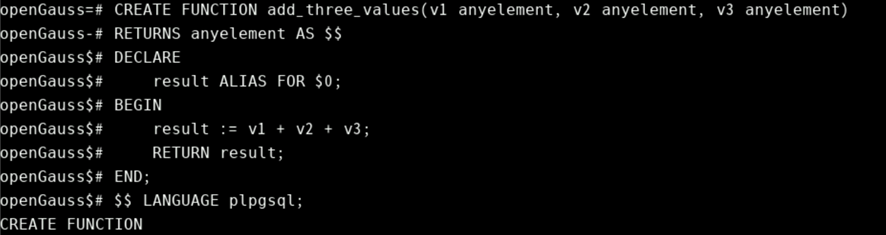
通过将一个或多个输出参数声明为多态类型,可以获得相同的效果。在该情况下,不使用特殊的 $0 参数,输出参数本身具备相同的结果,例如:
DROP FUNCTION IF EXISTS add_three_values;
CREATE FUNCTION add_three_values(v1 anyelement, v2 anyelement, v3 anyelement, OUT sum anyelement)
AS $$
BEGIN
sum := v1 + v2 + v3;
END;
$$ LANGUAGE plpgsql;

anycompatible是PostgreSQL特性,OpenGaussDB暂时没有移植该功能。故下面anycompatible类型只了解即可。
在实践中,声明多态函数中使用任何兼容的数据类型会非常有效,以便自动将输入参数提升为一个常见的公共类型。例如:
CREATE FUNCTION add_three_values(v1 anycompatible, v2 anycompatible, v3 anycompatible)
RETURNS anycompatible AS $$
BEGIN
RETURN v1 + v2 + v3;
END;
$$ LANGUAGE plpgsql;
上面用例引用方法如下:
SELECT add_three_values(1, 2, 4.7);该函数调用,会自动将参数值1, 2从integer整型转换成numeric小数型。
注:多态类型有11种,anyelement只是其中一个,该内容属于数据类型。由于数据类型较为简单不做过多说明,读者自学数据类型。
变量声明之ALIAS
该内容主要用于触发器的实现。因为触发器有涉及到Update和Delete等DML。而数据的Update和Delete会涉及到新元组(new tuple)和旧元组(old tuple)。比如Delete的谓词条件Where语句中column = old.tuple。
语法如下:
newname ALIAS FOR oldname;例如:
DECLARE
prior ALIAS FOR old;
updated ALIAS FOR new;
注意:由于ALIAS创建了两种不同的方式来命名同一个对象,因此不受限制的使用可能会引起困惑。最好仅用于覆盖预定名称。
变量声明之Copying Types
语法如下:
name table.column%TYPE
name variable%TYPE
%TYPE提供表字段或者先前声明PL/PGSQL变量的数据类型,可以声明在数据库中已经存在的变量类型。例如:
变量与数据库中表 users 的字段 user_id 是相同的数据类型,则PL/PGSQL在声明variable时,可以用如下写法:
declare
variable users.user_id%TYPE;
还可以在%TYPE之后写入数组修饰,创建一个保存引用类型的数组变量:
declare
variables users.user_id%TYPE[];
variables users.user_id%TYPE ARRAY[4]; -- equivalent to the above
正如在声明表字段为数组时,无论编写多个括号还是特定的数组维度并不重要:
OpenGaussDB将给定元素类型的所有数组为相同类型,而不考虑维度。
重点
通过使用%TYPE,不需要知道被引用的结构中的数据类型。如果被引用项的数据类型在将来发生变化(例如:将user_id的类型从整数更改为实数),也不需要改变函数定义。
%TYPE 在多态函数中特别有用,因为内部变量所需的数据类型在一次调用到下一次调用时可能发生变化。可以通过将%TYPE应用于函数的参数或结果占位符来创建适当的变量。
表结构中使用数组类型时,则方法如下(其写法不同于PL/PGSQL变量声明)
CREATE TABLE sal_emp (
name text,
pay_by_quarter integer[],
schedule text[][]
);
CREATE TABLE tictactoe (
pay_by_quarter integer ARRAY,
sales integer ARRAY[4],
squares integer[3][3]
);
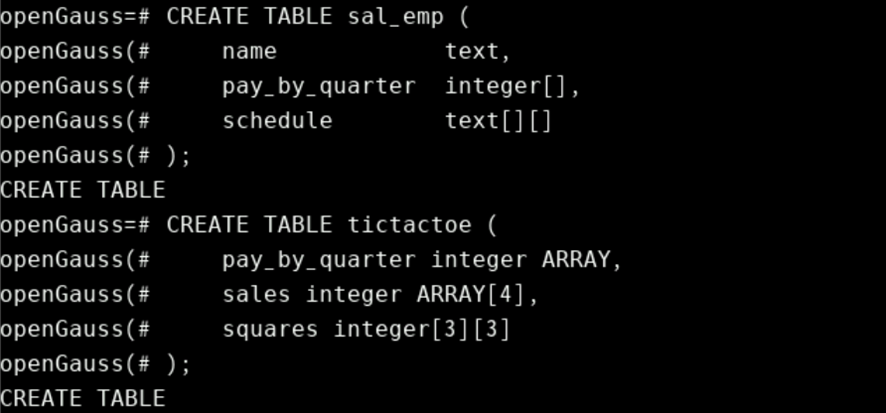
读者自学数组类型的字段写入,数组访问,此处不作过度讲解,自行学习。
变量声明之Row Types
语法如下
name table_name%ROWTYPE;
name composite_type_name;
复合类型的变量被称为行变量或者行类型变量。只要 SELECT 或 FOR 查询的列集合与变量声明的类型相匹配中,则该变量就能存储该查询的整行结果集(元组Tuple)。通常使用小数点表示访问元组的各个字段(例如:rowvar.field)。
使用 table_name%ROWTYPE 表示将 ROWTYPE 类型的变量声明为现有表或视图的行具有相同的类型,也可通过给出复合类型的类型名来声明 ROWTYPE 变量。由于每个表关系都有一个同名的关联复合类型,因此在 OpenGaussDB 中,是否写 %ROWTYPE 其实不重要。但是使用 %ROWTYPE 的表关系更具有可移植性。
%ROWTYPE 与 %TYPE 一样,后面可以跟数组修饰符来声明一个变量,该变量保存引用复合类型的数组。
函数的参数可以定义成复合类型(表完整的行)。在该情况下,对应的标识符 $n 将是行变量,可以从中选择字段,例如 $1.usr_id 。
复合类型的示例如下所示:Table1 和 Table2 是至少具有上述字段的现有表:
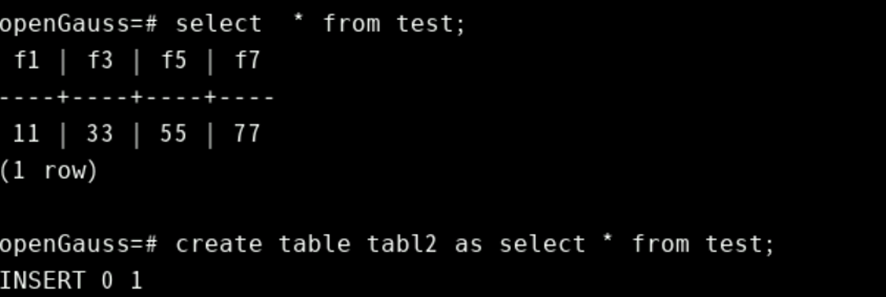
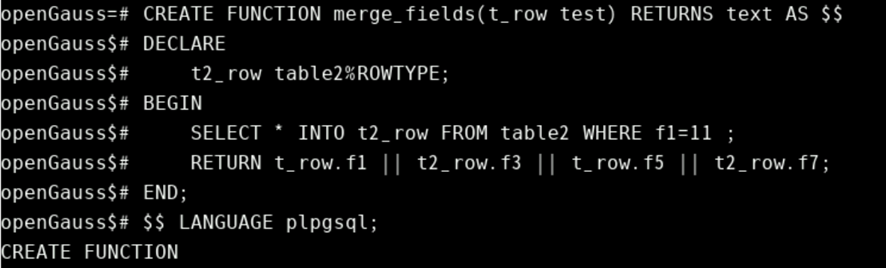
变量声明之Record Types
语法如下:
name RECORD;Record 变量类似于RowType变量,但其没有预定义结构。在 SELECT 或 FOR 操作期间分配的实际的Row结构就是Record变量的结构类型。所以每次在变量赋值时,变量的子结构都会发生变化。所以在变量被第一次赋值之前,它没有子结构,并且任何访问该变量的字段都将导致运行时报错。
注意:RECORD类型变量并不是一个实际的数据类型,只是占位符。当PL/PGSQL函数的返回类型被声明为RECORD时,它与RECORD变量的概念并不完全一样,即便该函数可能使用RECORD变量来保存其返回结果集。在这两种情况下,编写自定义函数时,实际的ROW结构是未知的,但是对于返回RECORD的函数,实际的结构是在解析调用查询时确定的,而RECORD变量可以动态地更改其行结构。
PL/PGSQL中变量的比较运算操作
该部分内容比较简单不做详细讲解,理解如下用例:
CREATE FUNCTION less_than(a text, b text) RETURNS boolean AS $$
BEGIN
RETURN a < b;
END;
$$ LANGUAGE plpgsql;

SELECT less_than(text_field_1, text_field_2) FROM table1;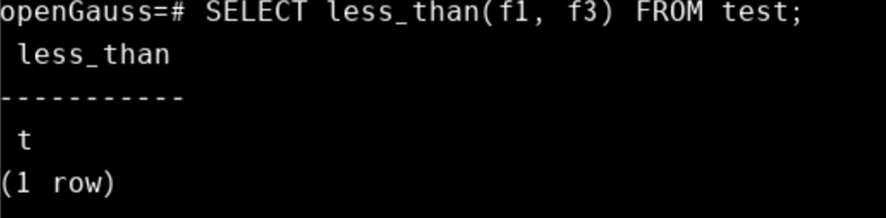
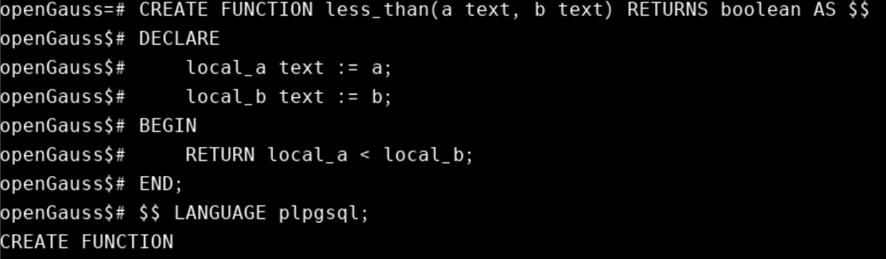
CREATE FUNCTION less_than(a text, b text) RETURNS boolean AS $$
DECLARE
local_a text := a;
local_b text := b;
BEGIN
RETURN local_a < local_b;
END;
$$ LANGUAGE plpgsql;
CREATE FUNCTION less_than_c(a text, b text) RETURNS boolean AS $$
BEGIN
RETURN a < b COLLATE "C";
END;
$$ LANGUAGE plpgsql;

变量引用之循环变量迭代
- For Loop中迭代的循环整数变量。
- 迭代游标结果数据集的循环变量。
后续循环控制和游标章节会展示具体用法,此处不做过多详解。
条件控制
PL/pgSQL有两种条件控制语句:IF语句和CASE语句。其中IF语句有3种形式:
IF ... THEN ... END IF
IF ... THEN ... ELSE ... END IF
IF ... THEN ... ELSIF ... THEN ... ELSE ... END IFCASE语句有2种形式:
CASE ... WHEN ... THEN ... ELSE ... END CASE
CASE WHEN ... THEN ... ELSE ... END CASEIF-THEN
语法如下:
IF boolean-expression THEN
statement
END IF;例如:(下面SQL需要在存储过程/函数中套用)
IF v_user_id <> 0 THEN
UPDATE users SET email = v_email WHERE user_id = v_user_id;
END IF;
IF-THEN-ELSE
语法如下:
IF boolean-expression THEN
statements
ELSE
statements
END IF;用法如下:(下面SQL需要在存储过程/函数中套用)
IF parentid IS NULL OR parentid = ''
THEN
RETURN fullname;
ELSE
RETURN hp_true_filename(parentid) || '/' || fullname;
END IF;
IF v_count > 0 THEN
INSERT INTO users_count (count) VALUES (v_count);
RETURN 't';
ELSE
RETURN 'f';
END IF;
IF-THEN-ELSIF
语法如下:
IF boolean-expression THEN
statements
[ ELSIF boolean-expression THEN
statements
[ ELSIF boolean-expression THEN
statements
...
]]
[ ELSE
statements ]
END IF;例如:(下面SQL需要在存储过程/函数中套用)
IF number = 0 THEN
result := 'zero';
ELSIF number > 0 THEN
result := 'positive';
ELSIF number < 0 THEN
result := 'negative';
ELSE
-- hmm, the only other possibility is that number is null
result := 'NULL';
END IF;
IF demo_row.sex = 'm' THEN
pretty_sex := 'man';
ELSE
IF demo_row.sex = 'f' THEN
pretty_sex := 'woman';
END IF;
END IF;
CASE search-expression WHEN
语法如下:
CASE search-expression
WHEN expression [, expression [ ... ]] THEN
statements
[ WHEN expression [, expression [ ... ]] THEN
statements
... ]
[ ELSE
statements ]
END CASE;该语法功能与C语言的SWITCH CASE类似。(下面SQL需要在存储过程/函数中套用)
CASE x
WHEN 1, 2 THEN
msg := 'one or two';
ELSE
msg := 'other value than one or two';
END CASE;
SELECT * INTO myrec FROM emp WHERE empname = myname;
IF NOT FOUND THEN
RAISE EXCEPTION 'employee % not found', myname;
END IF;
BEGIN
SELECT * INTO STRICT myrec FROM emp WHERE empname = myname;
EXCEPTION
WHEN NO_DATA_FOUND THEN
RAISE EXCEPTION 'employee % not found', myname;
WHEN TOO_MANY_ROWS THEN
RAISE EXCEPTION 'employee % not unique', myname;
END;
Searched CASE
语法如下:
CASE
WHEN boolean-expression THEN
statements
[ WHEN boolean-expression THEN
statements
... ]
[ ELSE
statements ]
END CASE;
用例如下:(下面SQL需要在存储过程/函数中套用)
CASE
WHEN x BETWEEN 0 AND 10 THEN
msg := 'value is between zero and ten';
WHEN x BETWEEN 11 AND 20 THEN
msg := 'value is between eleven and twenty';
END CASE;
该形式的CASE语句和IF-THEN ELSEIF类似等价。
注:条件控制语句都是结合存储过程PROCEDURE和自定义函数FUNCTION,在SQL体中套用的。
循环控制
PL/pgSQL在执行一些重复的SQL语句时,一般用循环结构实现,PL/pgSQL包含的循环语法有LOOP, EXIT, CONTINUE, WHILE, FOR, FOREACH。
LOOP
语法如下:
[ <<label>> ]
LOOP
statements
END LOOP [ label ];
LOOP语句定义了一个无条件循环,该循环将无限期地重复,直到由EXIT或RETURN语句终止。可选Label由嵌套循环中的EXIT和CONTINUE语句使用,以指定该语句的引用哪个循环。
EXIT
语法如下:
EXIT [ label ] [ WHEN boolean-expression ];EXIT后面若没有跟Label,内部循环到END LOOP则结束退出。如果EXIT有Label,则该标签是当前循环体或者外层嵌套循环体的标签。在循环体的END处结束或者控制SQL块。
若指定WHEN,则当 boolean-expression 为True时,才会退出循环。否则控制流程将运行SQL体退出后的语句。该语法用于所有类型的循环体,并不限制于无条件循环体。
当有BEGIN语句开始SQL块时,EXIT将跳到BEGIN开启的SQL块之后继续执行。
例如:(下面SQL需要在存储过程/函数中套用)
LOOP
-- some computations
IF count > 0 THEN
EXIT; -- exit loop
END IF;
END LOOP;
LOOP
-- some computations
EXIT WHEN count > 0; -- same result as previous example
END LOOP;
<<ablock>>
BEGIN
-- some computations
IF stocks > 100000 THEN
EXIT ablock; -- causes exit from the BEGIN block
END IF;
-- computations here will be skipped when stocks > 100000
END;
CONTINUE
语句:
CONTINUE [ label ] [ WHEN boolean-expression ];如果CONTINUE语句不带Label标签,则SQL自动从循环体的下一次循环开始位置执行,即跳过循环体中剩余的SQL语句。如果CONTINUE语句带Label标签,则执行循环体中标签指示的位置。
若指定了关键字WHEN,并且boolean-expression为true时,才会执行下一次循环的迭代。如果boolean-expression为false,则执行流传递给CONTINUE后面的SQL。
CONTINUE语句能和所有类型的循环体一起使用;它不限于和无条件循环体。
示例如下:(下面SQL需要在存储过程/函数中套用)
LOOP
-- some computations
EXIT WHEN count > 100;
CONTINUE WHEN count < 50;
-- some computations for count IN [50 .. 100]
END LOOP;
WHILE循环
语法如下:
[ <<label>> ]
WHILE boolean-expression LOOP
statements
END LOOP [ label ];
当 boolean-expression 为True时,则进行WHILE的SQL循环体执行statement。每次循环执行SQL时,都会判断 boolean-expression 。(下面SQL需要在存储过程/函数中套用)
WHILE amount_owed > 0 AND gift_certificate_balance > 0 LOOP
-- some computations here
END LOOP;
WHILE NOT done LOOP
-- some computations here
END LOOP;
FOR循环
语法如下:
[ <<label>> ]
FOR name IN [ REVERSE ] expression .. expression [ BY expression ] LOOP
statements
END LOOP [ label ];
FOR循环 IN 后面的 expression 表达式是一个整数值范围上迭代。变量名自动定义来整数类型,该变量生命周期只存在于内循环。在变量的起始值和结束值每次进入循环体时计数一次。如果未指定 BY 关键字,则迭代为1,否则为BY子句中指定的值。如果REVERSE关键字被指定,则表示FOR循环的迭代变量是从大到小遍历,每次循环迭代变量减少。
FOR循环体的几种示例写法如下:
-- 迭代变量i增序遍历,从1到10,增量默认为1
FOR i IN 1..10 LOOP
-- i will take on the values 1,2,3,4,5,6,7,8,9,10 within the loop
END LOOP;
-- 迭代变量i降序遍历(REVERSE),从10到1,降量默认为1
FOR i IN REVERSE 10..1 LOOP
-- i will take on the values 10,9,8,7,6,5,4,3,2,1 within the loop
END LOOP;
-- 迭代变量i降序遍历(REVERSE),从10到1,降量默认为2(BY 2)
FOR i IN REVERSE 10..1 BY 2 LOOP
-- i will take on the values 10,8,6,4,2 within the loop
END LOOP;
注:
如果FOR循环的迭代变量i在增序遍历中,起始值比结束值大,则循环体SQL不会被执行,也不会报错。反之降序遍历同理。
Query Results作变循环迭代变量
用不同的FOR循环体语句,可以迭代SQL查询结果集,并做对应的操作。语法如下:
[ <<label>> ]
FOR target IN query LOOP
statements
END LOOP [ label ];
target可以是 record 变量,row 变量或者是逗号分隔的标题列表。依次为查询的每一行结果集分配给迭代变量,在循环体中被引用。
示例如下:
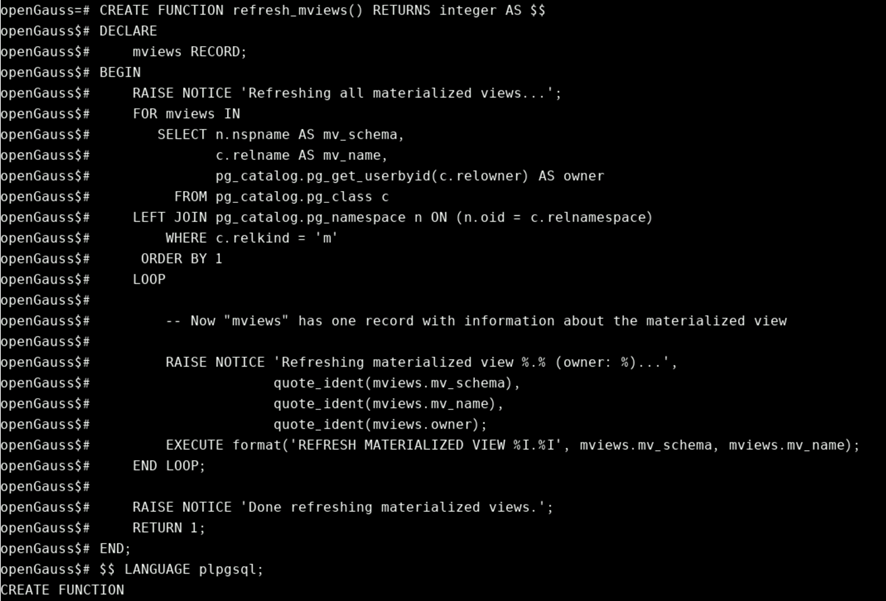
CREATE FUNCTION refresh_mviews() RETURNS integer AS $$
DECLARE
mviews RECORD;
BEGIN
RAISE NOTICE 'Refreshing all materialized views...';
FOR mviews IN
SELECT n.nspname AS mv_schema,
c.relname AS mv_name,
pg_catalog.pg_get_userbyid(c.relowner) AS owner
FROM pg_catalog.pg_class c
LEFT JOIN pg_catalog.pg_namespace n ON (n.oid = c.relnamespace)
WHERE c.relkind = 'm'
ORDER BY 1
LOOP
-- Now "mviews" has one record with information about the materialized view
RAISE NOTICE 'Refreshing materialized view %.% (owner: %)...',
quote_ident(mviews.mv_schema),
quote_ident(mviews.mv_name),
quote_ident(mviews.owner);
EXECUTE format('REFRESH MATERIALIZED VIEW %I.%I', mviews.mv_schema, mviews.mv_name);
END LOOP;
RAISE NOTICE 'Done refreshing materialized views.';
RETURN 1;
END;
$$ LANGUAGE plpgsql;
如果该循环体通过 EXIT 关键字退出,则在循环体退出后依然可以访问 Row 变量的数据。
FOR-IN-EXECUTE语句是ROW变量迭代的另一个语法
[ <<label>> ]
FOR target IN EXECUTE text_expression [ USING expression [, ... ] ] LOOP
statements
END LOOP [ label ];
与上面的结构类似,不同的是Query查询结果集被作为字符串表达式处理,在FOR循环的SQL对其进行评估和重规划,可以像普通SQL一样使用预处理的SQL查询和灵活的动态SQL,参数值可以使用USING插入动态SQL。
Query查询结果集的处理的另一种方案是使用游标。
数组的LOOP循环体结构
FOREACH 循环体和 FOR 循环体比较类似,其用于替代SQL查询结果集迭代变量的语法,其迭代变量是一个数组变量。语法如下:
[ <<label>> ]
FOREACH target [ SLICE number ] IN ARRAY expression LOOP
statements
END LOOP [ label ];
如果没有SLICE关键字,或者SLICE被指定为0,则通过计算表达式生成的数组里各个数值遍历循环体SQL,循环体将分配访问序列中每个变量的值。示例如下:
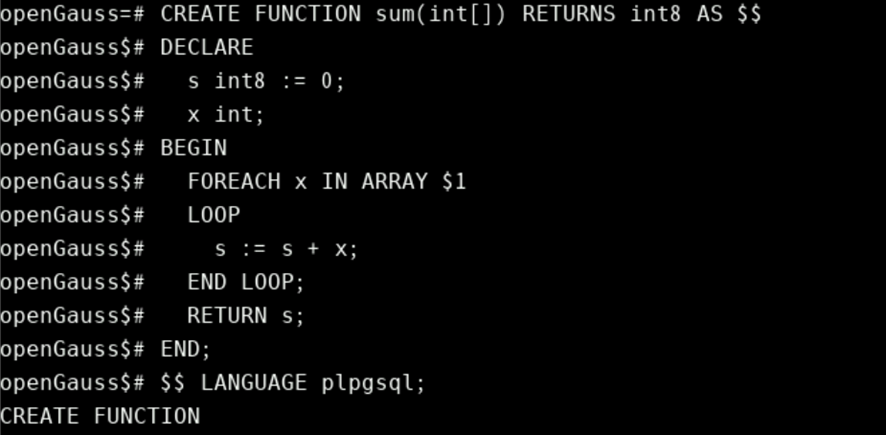
CREATE FUNCTION sum(int[]) RETURNS int8 AS $$
DECLARE
s int8 := 0;
x int;
BEGIN
FOREACH x IN ARRAY $1
LOOP
s := s + x;
END LOOP;
RETURN s;
END;
$$ LANGUAGE plpgsql;
无论是多维数组,数据都是按存储顺序访问。虽然target只是一个变量,在遍历复合类型数组时,target则表示复合变量的数组列表。当SLICE值为正时,FOREACH遍历数组的SLICE不再是单个值,SLICE值则是一个不超过数组维度的整数常量。target变量是一个数组值,其接收遍历数组数据里每个SLICE,数组的维度用SLICE来指定。
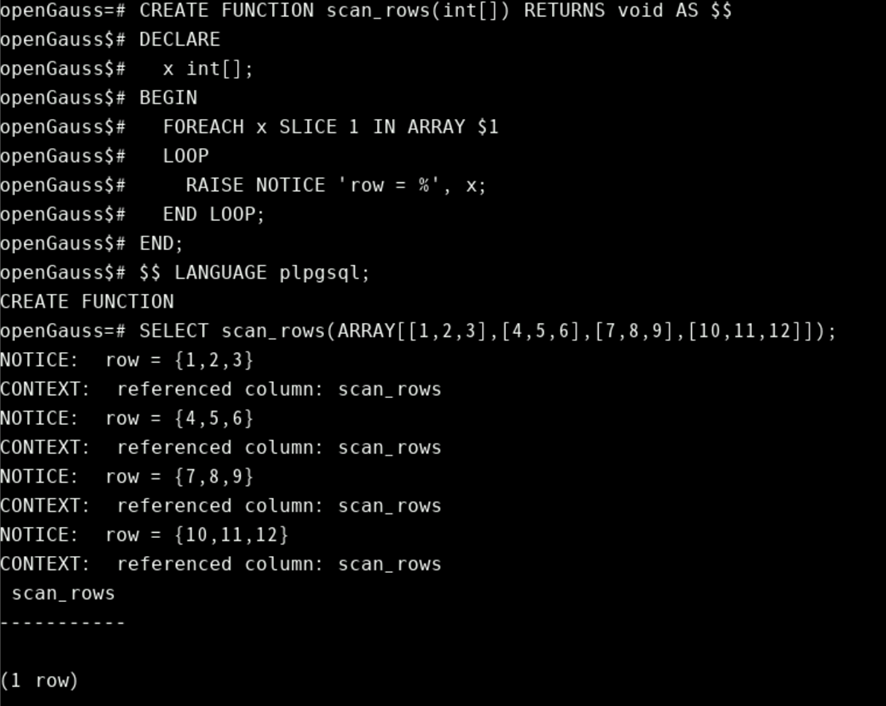
下面用例通过一维数组SLICE迭代变量展示其用法。
CREATE FUNCTION scan_rows(int[]) RETURNS void AS $$
DECLARE
x int[];
BEGIN
FOREACH x SLICE 1 IN ARRAY $1
LOOP
RAISE NOTICE 'row = %', x;
END LOOP;
END;
$$ LANGUAGE plpgsql;
SELECT scan_rows(ARRAY[[1,2,3],[4,5,6],[7,8,9],[10,11,12]]);
ERROR抓取
默认情况下,PL/pgSQL函数中发生的任何错误都会中止该函数和周围事务的执行。通过使用带有EXCEPTION子句的BEGIN块来捕获错误并从中恢复。该语法是START语法的常规扩展:
[ <<label>> ]
[ DECLARE
declarations ]
BEGIN
statements
EXCEPTION
WHEN condition [ OR condition ... ] THEN
handler_statements
[ WHEN condition [ OR condition ... ] THEN
handler_statements
... ]
END;
当没有错误输出时,该语法会执行所有的SQL语句,SQL控制流传递给END关键字后的下一个SQL语句。但如果在语句中发生错误,则放弃对SQL的进一步处理,并将SQL控制流传递给异常列表,该列表用于搜索与发生错误第一个匹配的信息。如果找到匹配信息,则执行相应的 handler_statements ,然后将SQL控制流传递给END关键字后的下一个SQL语句。如果列表中没有匹配到发生错误的内容,刚该 ERROR 会通过 EXCEPTION 终止对该函数的处理。
该 condition 名字可能是任意一个错误码,如同类别的名称可以匹配类型中的任何错误。特殊condition的名称 OTHERS 匹配除QUERY_CANCELED和ASSERT_FAILURE之外的所有错误类型。condition 名称不区分大小写。另外错误条件可以由SQLSTATE代码指定。例如下面示例,其是等价的。
WHEN division_by_zero THEN ...
WHEN SQLSTATE '22012' THEN ...
当错误被 EXCEPTION 子句捕获时,PL/pgSQL函数的局部变量被保存,但SQL块中对数据库持久状态的所有更改都将回滚。下面示例作为参考:
INSERT INTO mytab(firstname, lastname) VALUES('Tom', 'Jones');
BEGIN
UPDATE mytab SET firstname = 'Joe' WHERE lastname = 'Jones';
x := x + 1;
y := x / 0;
EXCEPTION
WHEN division_by_zero THEN
RAISE NOTICE 'caught division_by_zero';
RETURN x;
END;
当控制流到达分配的y时,则会输出 division_by_zero分支要输出的错误信息。该数据会被EXCEPTION 子句捕获,RETURN 语句中返回的x的增量值,但 UPDATE 命令的效果则被回滚。但SQL体之前的 INSERT 不被回滚。因此数据库的最终结果是包含 Tom Jones 的数据,而不是包含 Joe Jones 的内容。
注:与不包含SQL子句块相比,包含子句块的进入和退出成本要高的多。因此,除非必要时才使用。
从ERROR中获取信息
在PL/pgSQL中,关于当前 exception 有两种方法获取 error message。指定特殊变量和 GET STACKED DIAGNOSTICS 语法关键字。
在一个 exception 处理句柄中,指定特殊变量 SQLSTATE 包含了引发异常对应的错误码。特殊变量 SQLERRM 包含与异常相关的错误信息。这些变量在 EXCEPTION 结构外是没有被定义的。
在异常处理 SQL 程序中,也可用 GET STACKED DIAGNOSTICS 关键字来检索当前有关的异常消息。命令格式如下:
GET STACKED DIAGNOSTICS variable { = | := } item [ , ... ];每个关键字都具备指定变量的状态值。当前可用状态值如下表所示:
| 名称 | 类型 | 描述 |
|---|---|---|
| RETURNED_SQLSTATE | text | exception的SQLSTATE错误码 |
| COLUMN_NAME | text | exception相关的字段名 |
| CONSTRAINT_NAME | text | exception相关的约束名 |
| PG_DATATYPE_NAME | text | exception相关的数据类型名 |
| MESSAGE_TEXT | text | exception的主要消息文本 |
| TABLE_NAME | text | exception相关的表名 |
| SCHEMA_NAME | text | exception相关的模式名 |
| PG_EXCEPTION_DETAIL | text | exception的详细信息,前提是该message存在 |
| PG_EXCEPTION_HINT | text | exception提示消息的文本内容,前提是message存在 |
| PG_EXCEPTION_CONTEXT | text | exception的堆栈文本信息 |
如果 EXCEPTION 没有设置变量值,则返回一个空字符串。例如:
DECLARE
text_var1 text;
text_var2 text;
text_var3 text;
BEGIN
-- some processing which might cause an exception
...
EXCEPTION WHEN OTHERS THEN
GET STACKED DIAGNOSTICS text_var1 = MESSAGE_TEXT,
text_var2 = PG_EXCEPTION_DETAIL,
text_var3 = PG_EXCEPTION_HINT;
END;
该部分具体的示例,见OpenGaussDB官方网站用例,此处不再详述。
https://docs.opengauss.org/zh/docs/latest/docs/SQLReference/GET-DIAGNOSTICS.html
NULL语句
在PL/pgSQL中,NULL占位符是非常有用的。例如 NULL 以指示 if/then/else 链的一个分支故意为空。故此用NULL语句。
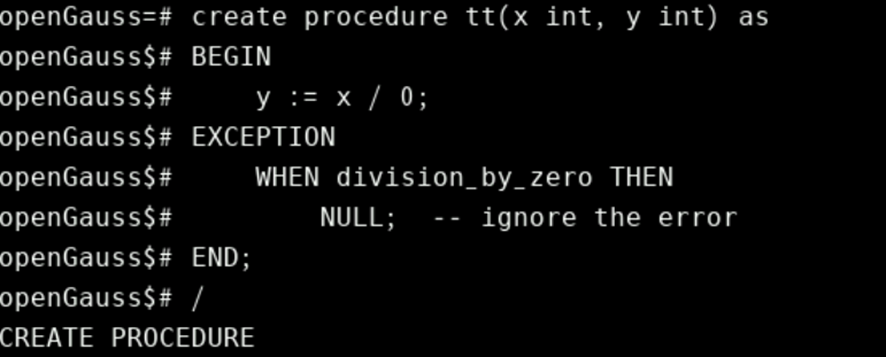
例如下面两个匿名块是等价的(匿名块是Oracle的语法,OpenGauss暂不支持,下面SQL了解即可)
BEGIN
y := x / 0;
EXCEPTION
WHEN division_by_zero THEN
NULL; -- ignore the error
END;
注:在Oracle的PL/SQL中,不允许使用空语句列表,因此在这种情况下需要使用NULL语句。但PL/pgSQL中允许什么都不写来替代NULL语句。但目前OpenGaussDB不支持什么都不写的场景,故还是要用NULL语法。
匿名块和存储过程实现
匿名块是oracle中PLSQL的内容,GaussDB上不确定具有该功能,故此处暂时不做说明。
存储过程是PL/pgSQL的重要功能,其主要目的是把一连串SQL操作进行封装成一个功能模块,用户使用该一组SQL模块时,只需要调用该存储过程的名称即可执行一连串封装的SQL操作。存储过程里的SQL实现对于用户是黑盒。即用户不知道调用的存储过程其中具体的实现过程。存储过程与自定义函数最大的区别是,存储过程没有返回值,函数必须要有RETURN。但是存储过程也可以输出内容和结果,比较调用oracle的兼容包dbe_output.print_line中的输出函数,或者用RAISE输出内容,还有用Output参数来存储要输出的结果。
存储过程可带参数也可以不带参数。如下示例:(其中table需要替换成存在的表名,xxx是查询的where条件,根据具体情况自行修改,也可以省略where条件)
create or replace procedure cursor_function() as
declare
var1 int;
var2 int;
cursor c1 for select va1, va2 from table where xxx;
begin
open c1;
loop fetch c1 into var1, var2;
exit when c1%notfound;
body;
raise notice 'xx%, xx%',var1,var2;
end loop;
close c1;
end;
/
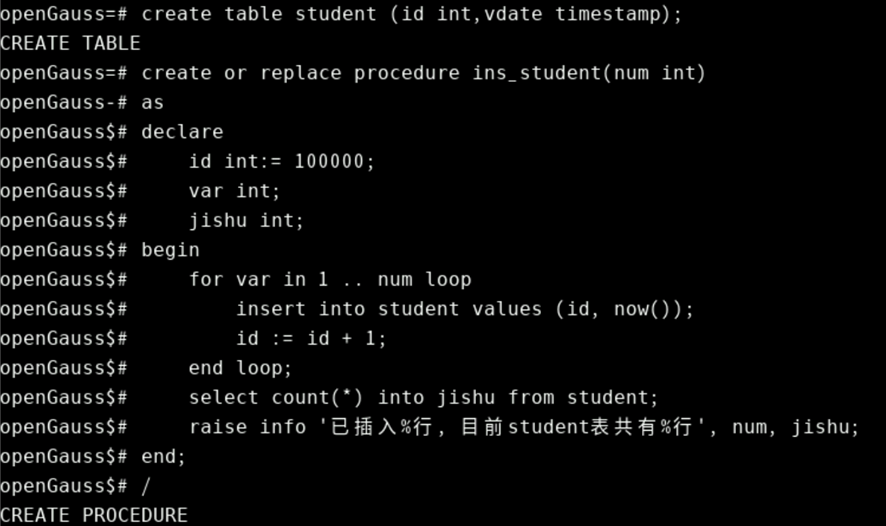
编写存储过程,输入个数,生成student,id从100000开始,starttime是当前时间。示例如下:
create table student (id int,vdate timestamp);
create or replace procedure ins_student(num int)
as
declare
id int:= 100000;
var int;
jishu int;
begin
for var in 1 .. num loop
insert into student values (id, now());
id := id + 1;
end loop;
select count(*) into jishu from student;
raise info '已插入%行, 目前student表共有%行', num, jishu;
end;
/
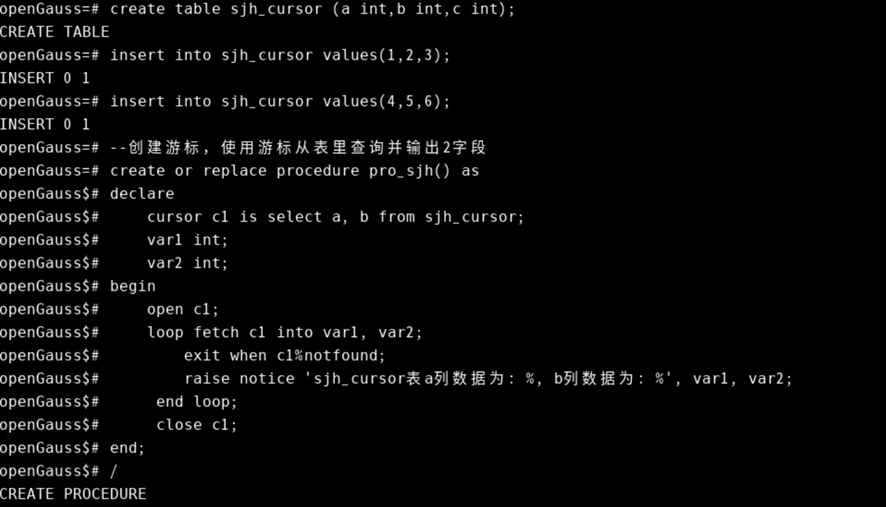
结束游标的存储过程相结合使用,示例如下:
create table sjh_cursor (a int,b int,c int);
insert into sjh_cursor values(1,2,3);
insert into sjh_cursor values(4,5,6);
--创建游标,使用游标从表里查询并输出2字段
create or replace procedure pro_sjh() as
declare
cursor c1 is select a, b from sjh_cursor;
var1 int;
var2 int;
begin
open c1;
loop fetch c1 into var1, var2;
exit when c1%notfound;
raise notice 'sjh_cursor表a列数据为: %, b列数据为: %', var1, var2;
end loop;
close c1;
end;
/
call pro_sjh();
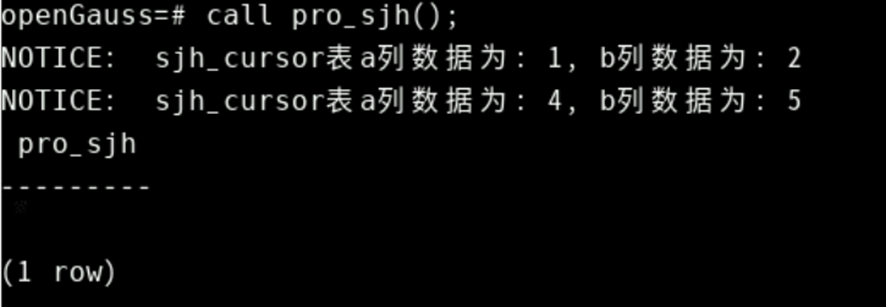
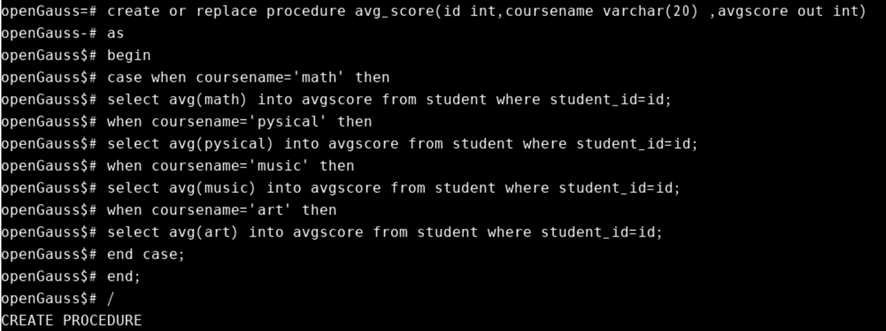
编写存储过程, 输入学号和科目名称, 返回对应的平均成绩,示例如下:
create or replace procedure avg_score(id int,coursename varchar(20) ,avgscore out int)
as
begin
case when coursename='math' then
select avg(math) into avgscore from student where student_id=id;
when coursename='pysical' then
select avg(pysical) into avgscore from student where student_id=id;
when coursename='music' then
select avg(music) into avgscore from student where student_id=id;
when coursename='art' then
select avg(art) into avgscore from student where student_id=id;
end case;
end;
/
游标之数据批量处理
游标用于对 SQL 查询的结果集做批处理读取场景。当SQL查询的结果集数据量过大,一次性读取会导致内存不够缓存。所以出现了游标的功能,用COUSOR对大数据量的结果集中分批处理(例如一次取1000条数据),直到循环多次,批量把结果集里的数据读取完毕。
声明游标变量
PL/pgSQL语法中,所有游标都必须通过游标变量去访问,游标变量是特殊的数据类型 refcursor。游标变量的声明语法如下:
name [ [ NO ] SCROLL ] CURSOR [ ( arguments ) ] FOR query;当关键字 SCROLL 被指定,则游标可以向后滚动处理数据,如果指定了NO SCROLL,则游标向后读取数据将被拒绝。如果没有指定 SCROLL,游标是否自动向后读取数据取决了SQL查询。arguments 如果被指定,则其以逗号分隔以对应 query 查询数据类型的列表,arguments的字段名称将替换掉 query查询中对应的字段名。示例如下:
DECLARE
curs1 refcursor;
curs2 CURSOR FOR SELECT * FROM tenk1;
curs3 CURSOR (key integer) FOR SELECT * FROM tenk1 WHERE unique1 = key;
这3个游标变量都属于 refcursor 数据类型,但curs1能被用于任何Query,curs2已经被绑定了一个完整的query查询,最后的curs3游标绑定了一个参数化的Query(当curs3被打开时,key用一个整形数值替代)。curs1由于没有绑定于任何指定的Query,所以可称之为末绑定的游标变量curs1。
当游标Query使用FOR UPDATE / SHARE(互斥锁 / 共享锁)时,则不能指定关键字SCROLL。对于Query涉及volatile函数时,则推荐使用NO SCROLL。SCROLL的实现场景是游标对Query输出结果集多次读取以保证读取结果的一致性(多次读取的数据内容保持不变),而Query里的volatile函数无法保证这一点。
打开游标
语法1:
OPEN unbound_cursorvar [ [ NO ] SCROLL ] FOR query;该语法操作是打开游标去执行游标绑定的Query查询。游标必须已经声明的refcursor变量,Query查询必须是SELECT,或返回元组的其他内容(例如EXPLAIN)。
示例如下:
OPEN curs1 FOR SELECT * FROM foo WHERE key = mykey;语法2:
OPEN unbound_cursorvar [ [ NO ] SCROLL ] FOR EXECUTE query_string
[ USING expression [, ... ] ];
该游标变量被打开并指定的Query查询去执行。
OPEN curs1 FOR EXECUTE format('SELECT * FROM %I WHERE col1 = $1',tabname) USING keyvalue;此用例中,通过Query中函数format()写入表名,col1的值是通过USING插入的,因此这不需要引用。
语法3:
OPEN bound_cursorvar [ ( [ argument_name := ] argument_value [, ...] ) ];这种方法是游标在声明时,已经绑定了动态SQL,而在打开游标时,需要对该游标适配具体的参数值,使其在动态SQL中被替换掉。这种方法下,SQL计划一直保存在缓存中,直到游标执行结束。这种方法不能指定关键字SCROLL和NO SCROLL,因为游标的滚动行为已经确定。该语法3与语法2的EXECUTE关键字并不等价。
游标的参数值用两种方法传递:位置和命名。用参数位置表示时,所有参数都是按顺序指定的。在参数命名法中,使用 := 指定每个参数的名称,将其与参数表达式分开。
如下示例:
OPEN curs2;
OPEN curs3(42);
OPEN curs3(key := 42);
下面示例中的curs4,效果与上面curs3一样。
DECLARE
key integer;
curs4 CURSOR FOR SELECT * FROM tenk1 WHERE unique1 = key;
BEGIN
key := 42;
OPEN curs4;
使用游标
通过上面语法打开游标后,用 FETCH 语句来操作它。当PL/pgSQL函数要批量返回数据时,可以让函数返回refcursor值,调用函数对游标进行操作。refcursor变量值只能引用打开的游标,直到事务结束时被隐匿的关闭。
FETCH
语法如下:
FETCH [ direction { FROM | IN } ] cursor INTO target;FETCH从游标中检索下一行(在指示的方向上)到目标中,该目标可能是行变量、记录变量或逗号分隔的简单变量列表,就像SELECT INTO一样。如果没有合适的行,则将目标设置为NULL(s)。与SELECT INTO一样,可以检查特殊变量,以查看是否获取了行。如果没有获得行,则光标定位在最后一行之后或第一行之前,具体取决于移动方向。
方向子句可以是SQL FETCH命令中允许的任何变体,但可以读取多行的变体除外;例如,它可以是NEXT、PRIOR、First、Last、ABSOLUTE count、RELATION count、Forward或backward。省略方向与指定NEXT相同。在使用计数的表单中,计数可以是任何整数值表达式(与SQL FETCH命令不同,SQL FETCH命令只允许使用整数常量)。需要向后移动的方向值很可能会失败,除非游标是用SCROLL选项声明或打开的。
游标必须是引用打开的游标入口的refcursor变量的名称。示例如下:
FETCH curs1 INTO rowvar;
FETCH curs2 INTO foo, bar, baz;
FETCH LAST FROM curs3 INTO x, y;
FETCH RELATIVE -2 FROM curs4 INTO x;
MOVE
语法如下:
MOVE [ direction { FROM | IN } ] cursor;关键字MOVE在不检索任何数据的情况下重新定位游标。MOVE的原理与FETCH类似,其不同在于MOVE只重新定位光标,而不返回移动到的行。而SELECT INTO 通过指定变量FOUND能够检测其移动的位置是否在数据集中,避免发生错误。如果没有指定的drection,则游标会移到数据集最后一行的下一行位置,或者第一行的前面,其取决于指定的drection。
MOVE curs1;
MOVE LAST FROM curs3;
MOVE RELATIVE -2 FROM curs4;
MOVE FORWARD 2 FROM curs4;
UPDATE/DELETE WHERE CURRENT OF
语法如下:
UPDATE table SET ... WHERE CURRENT OF cursor;
DELETE FROM table WHERE CURRENT OF cursor;
当游标位于表的某一元组时,则使用该语法,游标指定的元组可以被修改更新或者删除元组。如果要限制游标查询,则应该使用FOR UPDATE。
UPDATE foo SET dataval = myval WHERE CURRENT OF curs1;关闭游标
语法如下:
CLOSE cursor;对打开的游标执行关闭操作,可以理解为游标资源的释放。但该操作应该在事务结束之前,对游标进行释放。如果在事务结束时没有关闭游标,则结束事务时也会自动对游标进行关闭操作。
示例如下:
CLOSE curs1;通过游标批量处理结果集
PL/pgSQL函数返回一个游标时,在处理大数据集时,返回多行或者多列比较高效。
下面示例中,游标名称被调用者指定的用法:
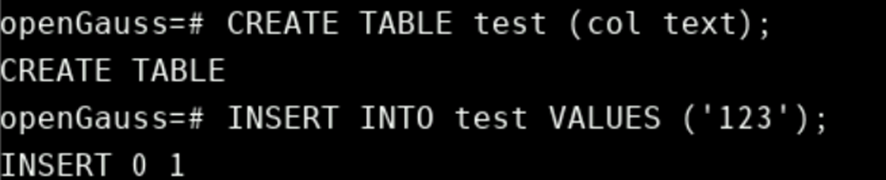
DORP TABLE IF EXISTS test;
CREATE TABLE test (col text);
INSERT INTO test VALUES ('123');
CREATE FUNCTION reffunc(refcursor) RETURNS refcursor AS '
BEGIN
OPEN $1 FOR SELECT col FROM test;
RETURN $1;
END;
' LANGUAGE plpgsql;
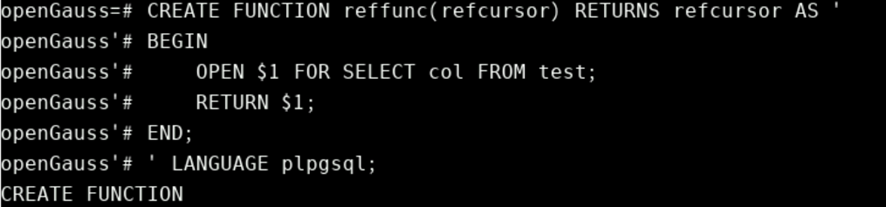
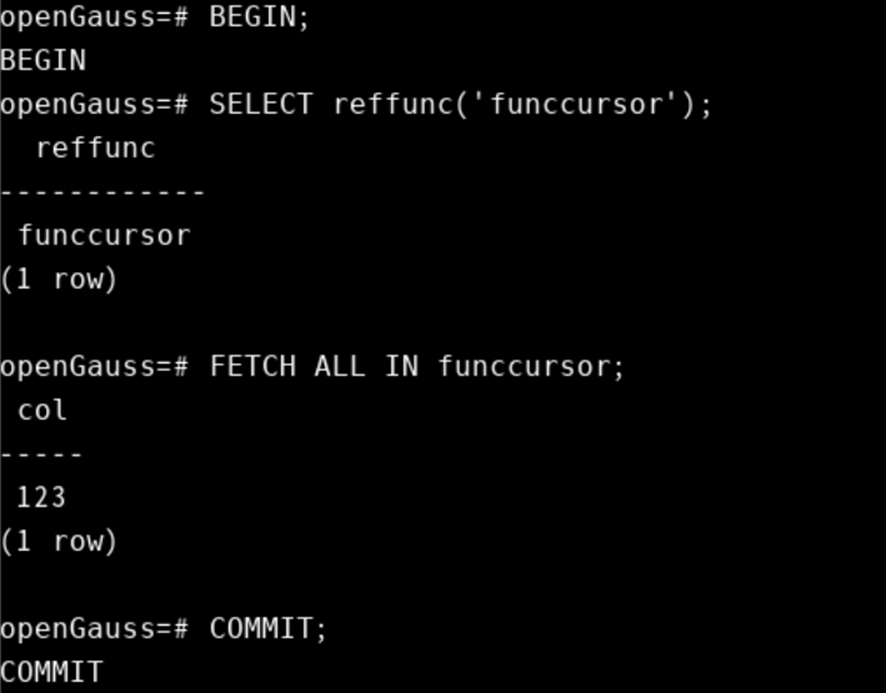
BEGIN;
SELECT reffunc('funccursor');
FETCH ALL IN funccursor;
COMMIT;
游标名称自动生成的用例:
-- 此处自行创建用例表test
DROP TABLE IF EXISTS test;
CREATE TABLE test(col int);
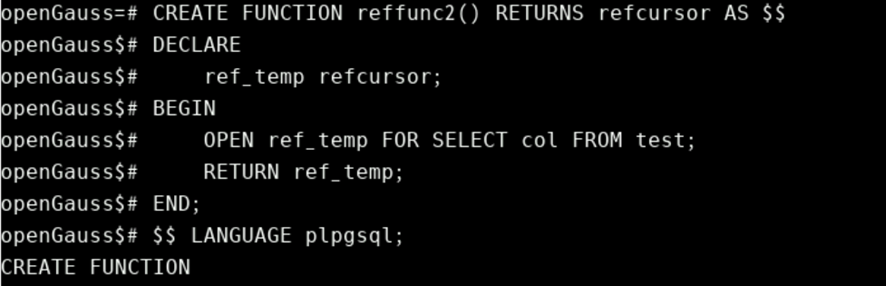
CREATE FUNCTION reffunc2() RETURNS refcursor AS $$
DECLARE
ref_temp refcursor;
BEGIN
OPEN ref_temp FOR SELECT col FROM test;
RETURN ref_temp;
END;
$$ LANGUAGE plpgsql;
-- need to be in a transaction to use cursors.
BEGIN;
SELECT reffunc2();
reffunc2
--------------------
<unnamed cursor 1>
(1 row)
FETCH ALL IN "<unnamed cursor 1>";
COMMIT;
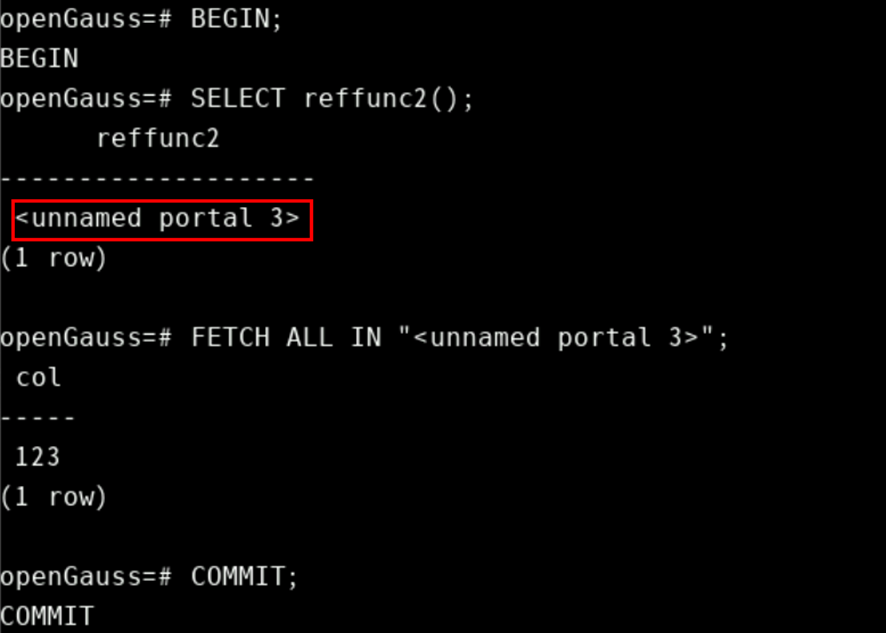
红框中根据实际内容而改变。
下面用例展示,从函数中返回多个游标的用法:(注:根据Function实际,创建前需要建表table_1和table_2)
-- 此处简单创建用例表table_1, table_2
create table table_1(id int);
create table table_2(id int);
CREATE FUNCTION myfunc(refcursor, refcursor) RETURNS SETOF refcursor AS $$
BEGIN
OPEN $1 FOR SELECT * FROM table_1;
RETURN NEXT $1;
OPEN $2 FOR SELECT * FROM table_2;
RETURN NEXT $2;
END;
$$ LANGUAGE plpgsql;
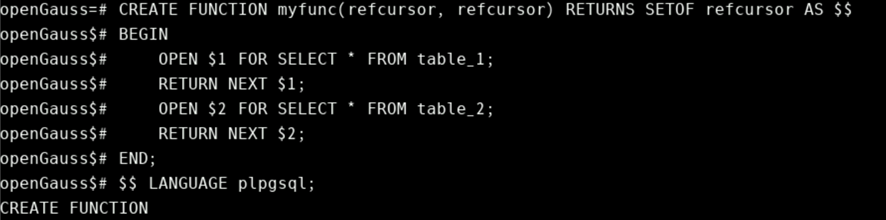
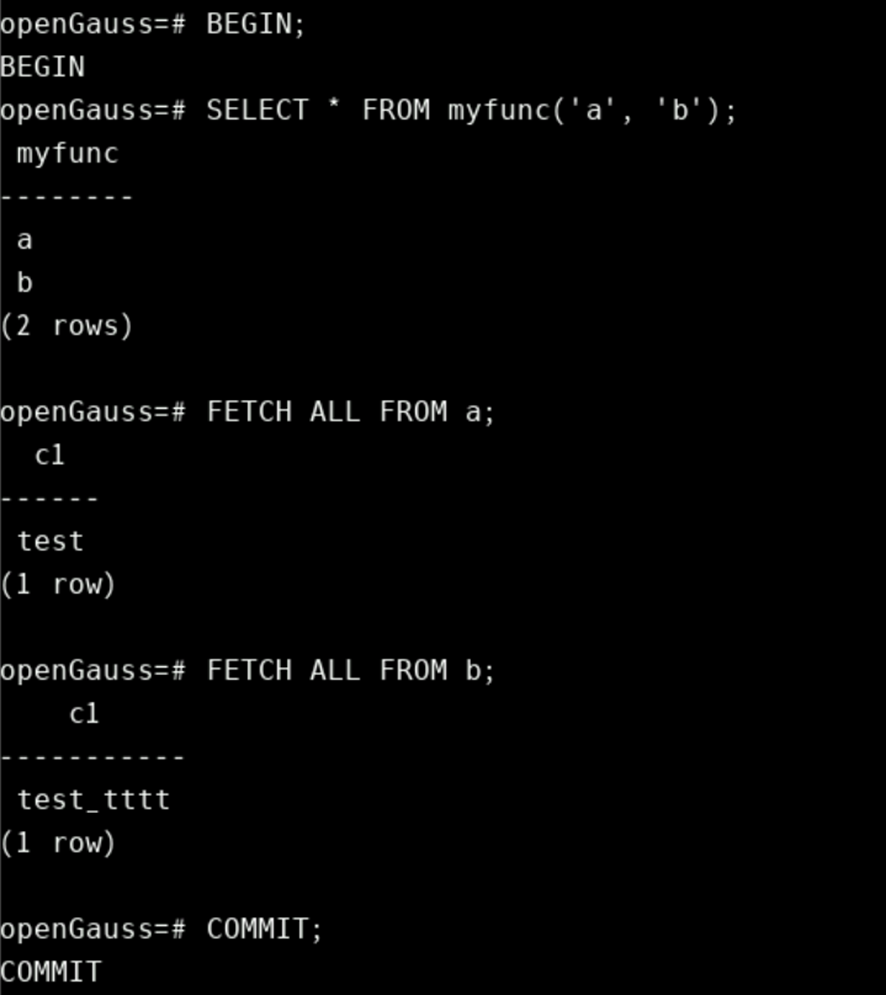
-- need to be in a transaction to use cursors.
BEGIN;
SELECT * FROM myfunc('a', 'b');
FETCH ALL FROM a;
FETCH ALL FROM b;
COMMIT;
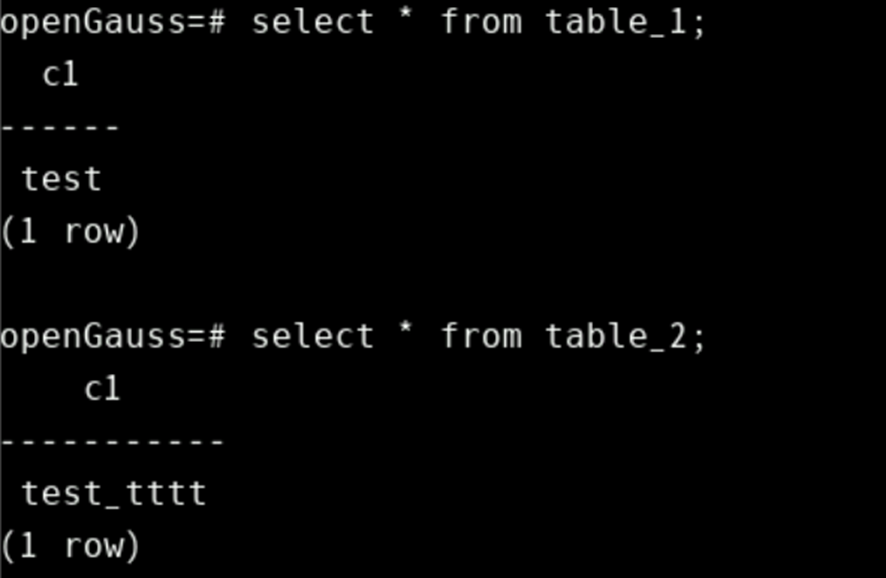
注:首先要确保上面自定义函数中调用的表table_1和table_2存在,此处该两张表都是text字段类型。如下所示
使用LOOP循环体从游标中获取结果集
使用FOR关键字的LOOP循环体,用迭代变量获取游标返回的元组数据,循环处理游标中的数据结果。语法如下:
[ <<label>> ]
FOR recordvar IN bound_cursorvar [ ( [ argument_name := ] argument_value [, ...] ) ] LOOP
statements
END LOOP [ label ];
这里使用的游标必须已经绑定到Query,并且不能是已经被打开的游标变量。FOR语句会自动打开游标,并在循环退出时自动关闭游标。当FORLOOP使用带参数的游标时,则必须使用表达式的实际参数值。其方式与OPEN方式相同。
自定义函数实现
PL/pgSQL中自定义函数非常常见。通常用CREATE FUNCTIONA表示该操作。函数必须要有返回值RETURNS。其它与存储过程内容一致。但当函数没有要返回的结果时,可以只写RETURN; 表示返回NULL。
自定义函数其他章节已经有过多介绍和示例,此处不再过多说明。
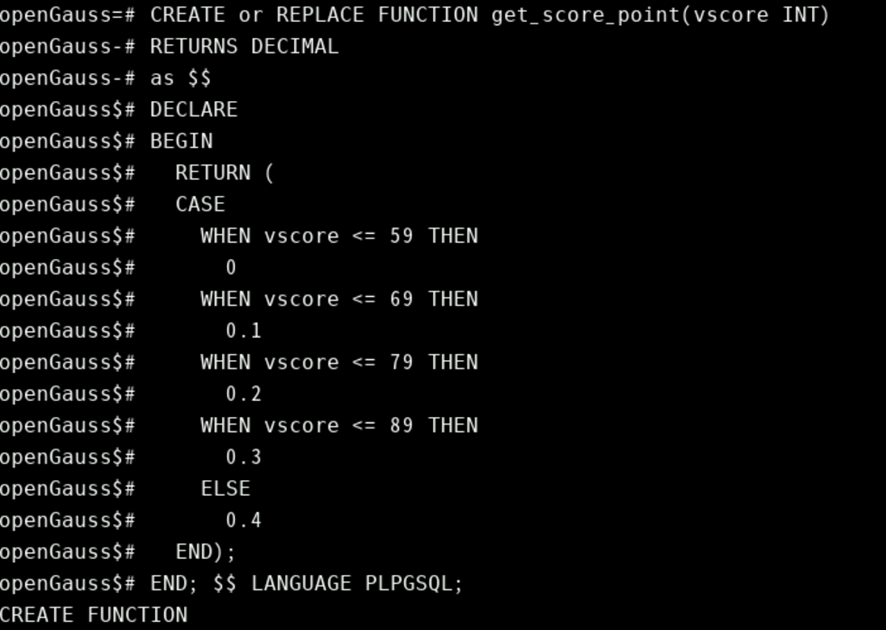
示例:(函数get_score_point根据输入的vscore成绩分数返回对应的绩点)
CREATE or REPLACE FUNCTION get_score_point(vscore INT)
RETURNS DECIMAL
as $$
DECLARE
BEGIN
RETURN (
CASE
WHEN vscore <= 59 THEN
0
WHEN vscore <= 69 THEN
0.1
WHEN vscore <= 79 THEN
0.2
WHEN vscore <= 89 THEN
0.3
ELSE
0.4
END);
END; $$ LANGUAGE PLPGSQL;
示例:(函数add_mask根据SQL查询对部分字段脱敏,调用dbe_output.print_line输出元组数据)
CREATE OR REPLACE FUNCTION add_mask(id1 TEXT, id2 TEXT) RETURNS TEXT AS $$
DECLARE
var1 TEXT;
var2 int;
cursor c1 is select case when id::text = id2 then '***' else id::text end as id, ranking from (select id, dense_rank() over(order by sum_point desc) as ranking from
(select id,get_score_point(math)+get_score_point(art)+get_score_point(phy) as sum_point from stu)) where id::text = id1;
BEGIN
open c1;
loop fetch c1 into var1, var2;
exit when c1%notfound;
return dbe_output.print_line('学号是:'||var1||', 排名是:'||var2);
end loop;
close c1;
END;
$$ LANGUAGE PLPGSQL;
该用例中使用了dbe_output.print_line函数包,是GaussDB的兼容Oracle的商业特性,此处opengauss会报该函数不存在。故可忽略。
触发器实现
TRIGGER
当数据库中表数据被改变或者发生数据库事件(events)时,可定义触发器函数,触发对应的操作。触发器函数与自定义函数类似,不同的是触发器函数返回的是触发器return trigger。
数据变更触发器
一般触发器函数是没有参数且返回触发器类型,但是触发器函数有自己的默认参数。其默认参数有12个,这里主要介绍常用的两个:NEW和OLD,其都是record数据类型。NEW参数主要用于行级操作的INSERT/UPDATE触发器。OLD参数主要用于行级操作的UPDATE/DELETE触发器。
下面示例,当表的一个元组插入或更新时,当前用户名和时间则会被写入元组last_user和last_date字段。并检查employee表的name字段是否被给定和salary的数据是否正确。
CREATE TABLE emp (
empname text,
salary integer,
last_date timestamp,
last_user text
);
CREATE FUNCTION emp_stamp() RETURNS trigger AS $emp_stamp$
BEGIN
-- Check that empname and salary are given
IF NEW.empname IS NULL THEN
RAISE EXCEPTION 'empname cannot be null';
END IF;
IF NEW.salary IS NULL THEN
RAISE EXCEPTION '% cannot have null salary', NEW.empname;
END IF;
-- Who works for us when they must pay for it?
IF NEW.salary < 0 THEN
RAISE EXCEPTION '% cannot have a negative salary', NEW.empname;
END IF;
-- Remember who changed the payroll when
NEW.last_date := current_timestamp;
NEW.last_user := current_user;
RETURN NEW;
END;
$emp_stamp$ LANGUAGE plpgsql;
CREATE TRIGGER emp_stamp BEFORE INSERT OR UPDATE ON emp
FOR EACH ROW EXECUTE FUNCTION emp_stamp();
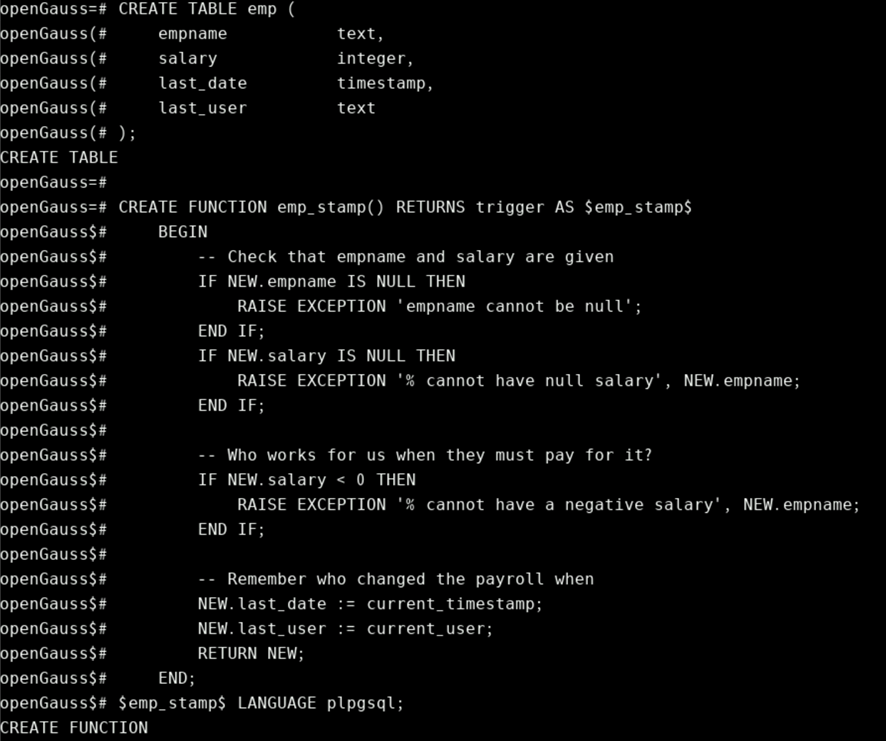

下面示例表示,当表emp元组的任何insert,update或者delete时,其记录都将被写到emp_audit表中。当时的时间和用户名也一并被写入。
CREATE TABLE emp (
empname text NOT NULL,
salary integer
);
CREATE TABLE emp_audit(
operation char(1) NOT NULL,
stamp timestamp NOT NULL,
userid text NOT NULL,
empname text NOT NULL,
salary integer
);
CREATE OR REPLACE FUNCTION process_emp_audit() RETURNS TRIGGER AS $emp_audit$
BEGIN
--
-- Create a row in emp_audit to reflect the operation performed on emp,
-- making use of the special variable TG_OP to work out the operation.
--
IF (TG_OP = 'DELETE') THEN
INSERT INTO emp_audit SELECT 'D', now(), current_user, OLD.*;
ELSIF (TG_OP = 'UPDATE') THEN
INSERT INTO emp_audit SELECT 'U', now(), current_user, NEW.*;
ELSIF (TG_OP = 'INSERT') THEN
INSERT INTO emp_audit SELECT 'I', now(), current_user, NEW.*;
END IF;
RETURN NULL; -- result is ignored since this is an AFTER trigger
END;
$emp_audit$ LANGUAGE plpgsql;
CREATE TRIGGER emp_audit
AFTER INSERT OR UPDATE OR DELETE ON emp
FOR EACH ROW EXECUTE FUNCTION process_emp_audit();
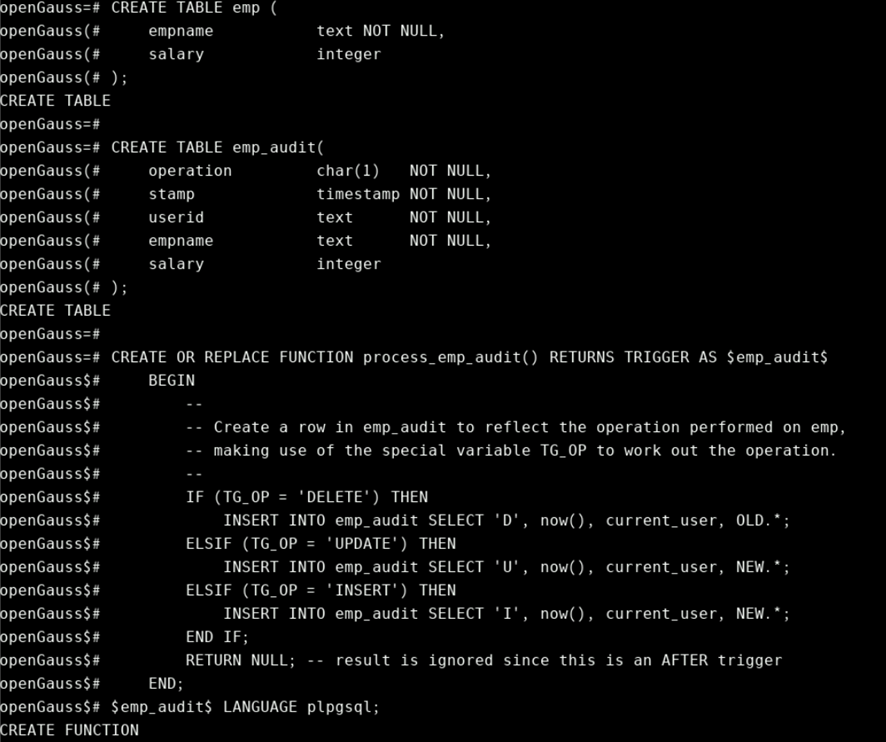

示例:
CREATE TABLE emp (
empname text PRIMARY KEY,
salary integer
);
CREATE TABLE emp_audit(
operation char(1) NOT NULL,
userid text NOT NULL,
empname text NOT NULL,
salary integer,
stamp timestamp NOT NULL
);
CREATE VIEW emp_view AS
SELECT e.empname,
e.salary,
max(ea.stamp) AS last_updated
FROM emp e
LEFT JOIN emp_audit ea ON ea.empname = e.empname
GROUP BY 1, 2;
CREATE OR REPLACE FUNCTION update_emp_view() RETURNS TRIGGER AS $$
BEGIN
--
-- Perform the required operation on emp, and create a row in emp_audit
-- to reflect the change made to emp.
--
IF (TG_OP = 'DELETE') THEN
DELETE FROM emp WHERE empname = OLD.empname;
IF NOT FOUND THEN RETURN NULL; END IF;
OLD.last_updated = now();
INSERT INTO emp_audit VALUES('D', current_user, OLD.*);
RETURN OLD;
ELSIF (TG_OP = 'UPDATE') THEN
UPDATE emp SET salary = NEW.salary WHERE empname = OLD.empname;
IF NOT FOUND THEN RETURN NULL; END IF;
NEW.last_updated = now();
INSERT INTO emp_audit VALUES('U', current_user, NEW.*);
RETURN NEW;
ELSIF (TG_OP = 'INSERT') THEN
INSERT INTO emp VALUES(NEW.empname, NEW.salary);
NEW.last_updated = now();
INSERT INTO emp_audit VALUES('I', current_user, NEW.*);
RETURN NEW;
END IF;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER emp_audit
INSTEAD OF INSERT OR UPDATE OR DELETE ON emp_view
FOR EACH ROW EXECUTE FUNCTION update_emp_view();
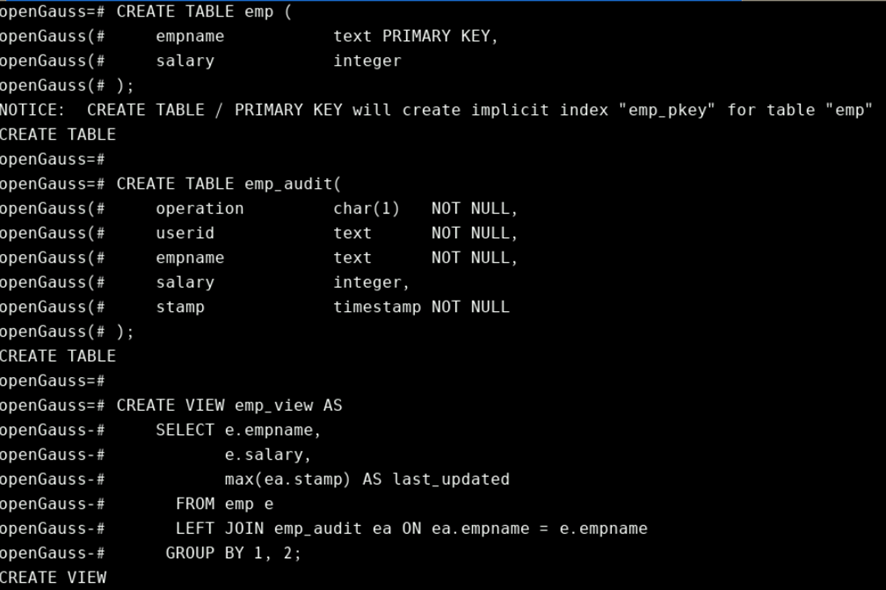
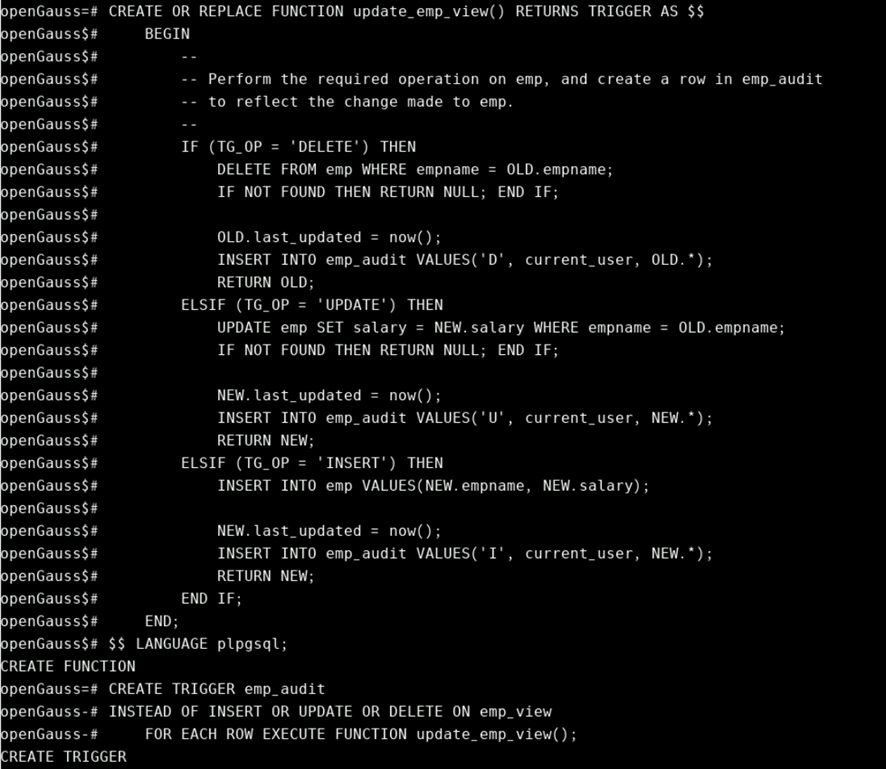
示例 :
--
-- Main tables - time dimension and sales fact.
--
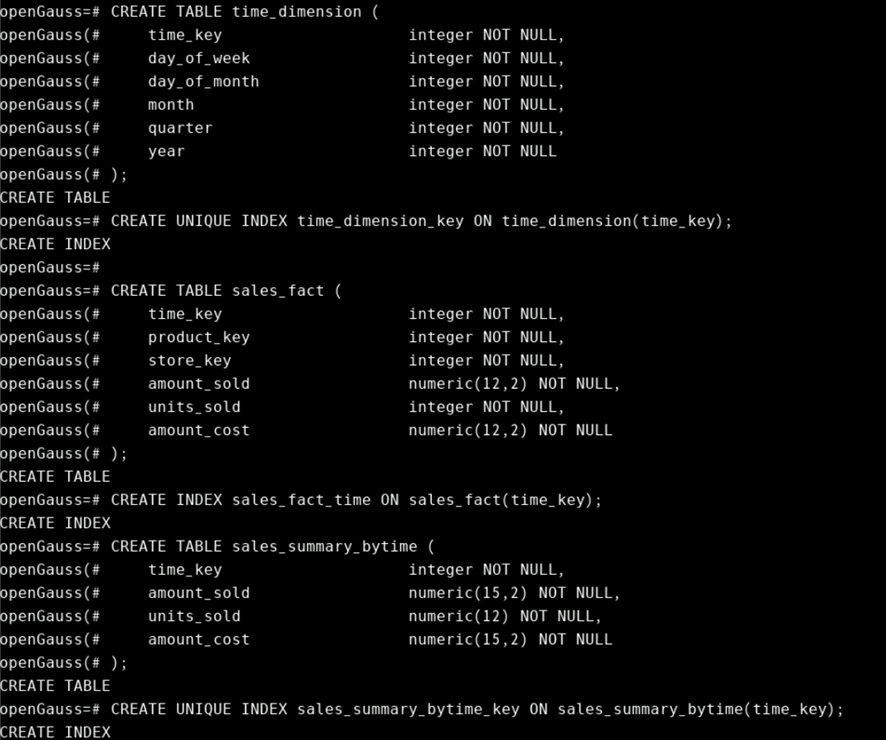
CREATE TABLE time_dimension (
time_key integer NOT NULL,
day_of_week integer NOT NULL,
day_of_month integer NOT NULL,
month integer NOT NULL,
quarter integer NOT NULL,
year integer NOT NULL
);
CREATE UNIQUE INDEX time_dimension_key ON time_dimension(time_key);
CREATE TABLE sales_fact (
time_key integer NOT NULL,
product_key integer NOT NULL,
store_key integer NOT NULL,
amount_sold numeric(12,2) NOT NULL,
units_sold integer NOT NULL,
amount_cost numeric(12,2) NOT NULL
);
CREATE INDEX sales_fact_time ON sales_fact(time_key);
--
-- Summary table - sales by time.
--
CREATE TABLE sales_summary_bytime (
time_key integer NOT NULL,
amount_sold numeric(15,2) NOT NULL,
units_sold numeric(12) NOT NULL,
amount_cost numeric(15,2) NOT NULL
);
CREATE UNIQUE INDEX sales_summary_bytime_key ON sales_summary_bytime(time_key);
--
-- Function and trigger to amend summarized column(s) on UPDATE, INSERT, DELETE.
--
CREATE OR REPLACE FUNCTION maint_sales_summary_bytime() RETURNS TRIGGER
AS $maint_sales_summary_bytime$
DECLARE
delta_time_key integer;
delta_amount_sold numeric(15,2);
delta_units_sold numeric(12);
delta_amount_cost numeric(15,2);
BEGIN
-- Work out the increment/decrement amount(s).
IF (TG_OP = 'DELETE') THEN
delta_time_key = OLD.time_key;
delta_amount_sold = -1 * OLD.amount_sold;
delta_units_sold = -1 * OLD.units_sold;
delta_amount_cost = -1 * OLD.amount_cost;
ELSIF (TG_OP = 'UPDATE') THEN
-- forbid updates that change the time_key -
-- (probably not too onerous, as DELETE + INSERT is how most
-- changes will be made).
IF ( OLD.time_key != NEW.time_key) THEN
RAISE EXCEPTION 'Update of time_key : % -> % not allowed',
OLD.time_key, NEW.time_key;
END IF;
delta_time_key = OLD.time_key;
delta_amount_sold = NEW.amount_sold - OLD.amount_sold;
delta_units_sold = NEW.units_sold - OLD.units_sold;
delta_amount_cost = NEW.amount_cost - OLD.amount_cost;
ELSIF (TG_OP = 'INSERT') THEN
delta_time_key = NEW.time_key;
delta_amount_sold = NEW.amount_sold;
delta_units_sold = NEW.units_sold;
delta_amount_cost = NEW.amount_cost;
END IF;
-- Insert or update the summary row with the new values.
<<insert_update>>
LOOP
UPDATE sales_summary_bytime
SET amount_sold = amount_sold + delta_amount_sold,
units_sold = units_sold + delta_units_sold,
amount_cost = amount_cost + delta_amount_cost
WHERE time_key = delta_time_key;
EXIT insert_update WHEN found;
BEGIN
INSERT INTO sales_summary_bytime (
time_key,
amount_sold,
units_sold,
amount_cost)
VALUES (
delta_time_key,
delta_amount_sold,
delta_units_sold,
delta_amount_cost
);
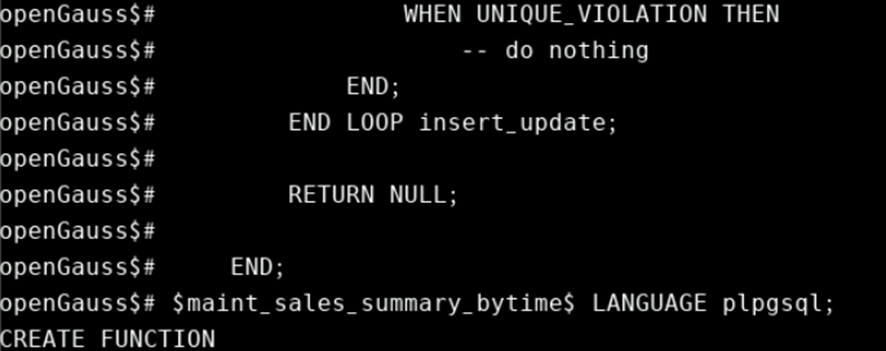
EXIT insert_update;
EXCEPTION
WHEN UNIQUE_VIOLATION THEN
-- do nothing
END;
END LOOP insert_update;
RETURN NULL;
END;
$maint_sales_summary_bytime$ LANGUAGE plpgsql;
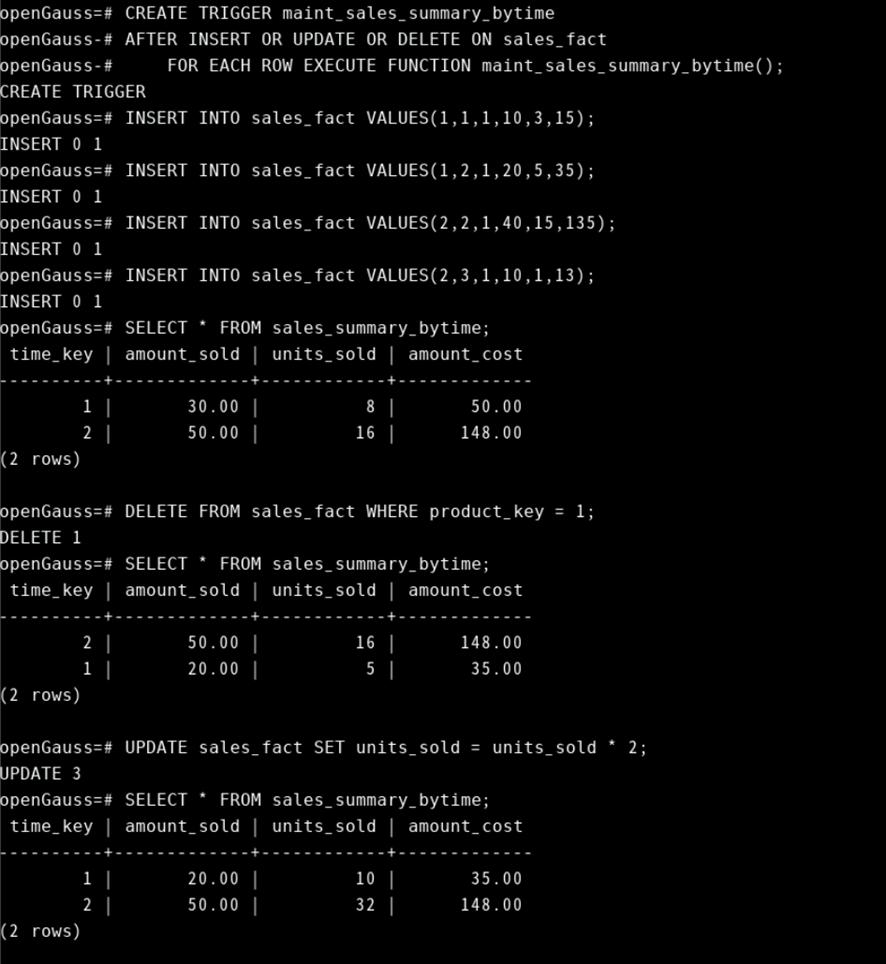
CREATE TRIGGER maint_sales_summary_bytime
AFTER INSERT OR UPDATE OR DELETE ON sales_fact
FOR EACH ROW EXECUTE FUNCTION maint_sales_summary_bytime();
INSERT INTO sales_fact VALUES(1,1,1,10,3,15);
INSERT INTO sales_fact VALUES(1,2,1,20,5,35);
INSERT INTO sales_fact VALUES(2,2,1,40,15,135);
INSERT INTO sales_fact VALUES(2,3,1,10,1,13);
SELECT * FROM sales_summary_bytime;
DELETE FROM sales_fact WHERE product_key = 1;
SELECT * FROM sales_summary_bytime;
UPDATE sales_fact SET units_sold = units_sold * 2;
SELECT * FROM sales_summary_bytime;
示例:(下面示例中new_table和old_table需要替换)
CREATE TABLE emp (
empname text NOT NULL,
salary integer
);
CREATE TABLE emp_audit(
operation char(1) NOT NULL,
stamp timestamp NOT NULL,
userid text NOT NULL,
empname text NOT NULL,
salary integer
);
CREATE OR REPLACE FUNCTION process_emp_audit() RETURNS TRIGGER AS $emp_audit$
BEGIN
--
-- Create rows in emp_audit to reflect the operations performed on emp,
-- making use of the special variable TG_OP to work out the operation.
--
IF (TG_OP = 'DELETE') THEN
INSERT INTO emp_audit
SELECT 'D', now(), current_user, o.* FROM old_table o;
ELSIF (TG_OP = 'UPDATE') THEN
INSERT INTO emp_audit
SELECT 'U', now(), current_user, n.* FROM new_table n;
ELSIF (TG_OP = 'INSERT') THEN
INSERT INTO emp_audit
SELECT 'I', now(), current_user, n.* FROM new_table n;
END IF;
RETURN NULL; -- result is ignored since this is an AFTER trigger
END;
$emp_audit$ LANGUAGE plpgsql;
CREATE TRIGGER emp_audit_ins
AFTER INSERT ON emp
REFERENCING NEW TABLE AS new_table
FOR EACH STATEMENT EXECUTE FUNCTION process_emp_audit();
CREATE TRIGGER emp_audit_upd
AFTER UPDATE ON emp
REFERENCING OLD TABLE AS old_table NEW TABLE AS new_table
FOR EACH STATEMENT EXECUTE FUNCTION process_emp_audit();
CREATE TRIGGER emp_audit_del
AFTER DELETE ON emp
REFERENCING OLD TABLE AS old_table
FOR EACH STATEMENT EXECUTE FUNCTION process_emp_audit();
事件触发器
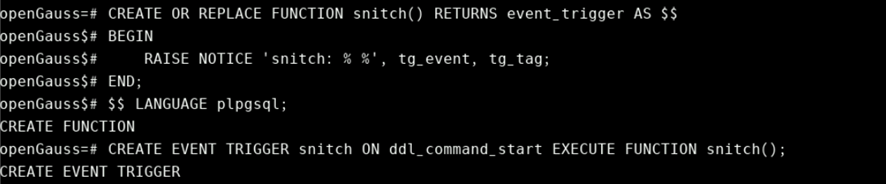
事件触发器即当有event发生时,触发对应的操作,该类触发器函数的默认参数有两个:TG_EVENT text和TG_TAG text。示例如下:
CREATE OR REPLACE FUNCTION snitch() RETURNS event_trigger AS $$
BEGIN
RAISE NOTICE 'snitch: % %', tg_event, tg_tag;
END;
$$ LANGUAGE plpgsql;
CREATE EVENT TRIGGER snitch ON ddl_command_start EXECUTE FUNCTION snitch();
打印输出说明
存储过程打印输出结果集
存储过程没有Return变量,因此存储过程结束时也没有Return语句。此场景下,如果要提前结束其运行过程,则使用没有表达式的Return语句。如果该存储过程有Output输出参数,则其会返回最终结果。
PL/pgSQL的函数,存储过程,Do匿名块都可以内部调用存储过程。Output参数与Call调用的处理方式不同。存储过程的每个Out 或者 InOut 参数必须对应Call语句中的一个变量,存储过程返回的任何值都将由输出参数返回结果。
CREATE PROCEDURE triple(INOUT x int)
LANGUAGE plpgsql
AS $$
BEGIN
x := x * 3;
END;
$$;
DO $$
DECLARE myvar int := 5;
BEGIN
CALL triple(myvar);
RAISE NOTICE 'myvar = %', myvar; -- prints 15
END;
$$;
存储过程中输出参数对应的变量可以是简单数值,也可以是复合数值,但目前Output 参数不能是数组元素。
注意 raise 多用于调试 :
RAISE LEVEL ... LEVEL 有6种错误级别: debug, log, info, notice, warning, exception(默认)
RETUN
return 字段 || ‘,’ || 字段;
语法如下:
RAISE [ level ] 'format' [, expression [, ... ]] [ USING option = expression [, ... ] ];
RAISE [ level ] condition_name [ USING option = expression [, ... ] ];
RAISE [ level ] SQLSTATE 'sqlstate' [ USING option = expression [, ... ] ];
RAISE [ level ] USING option = expression [, ... ];
RAISE ;
例如:
RAISE NOTICE 'Calling cs_create_job(%)', v_job_id;变量v_job_id将会替换掉%。
RAISE unique_violation USING MESSAGE = 'Duplicate user ID: ' || user_id;示例:
-- 编写add_mask(id1,id2)函数,当id1是当前查询用户时,显示正常ID,如果不是则显示为-- id2
create or replace function add_mask(id1 text, id2 text)
returns text as $$
declare
var1 text;
begin
select current_user into var1;
if var1 = id1 then
return 'current user is ' || id1;
else
return 'current user is ' || id2;
end if;
end;
$$ language plpgsql;
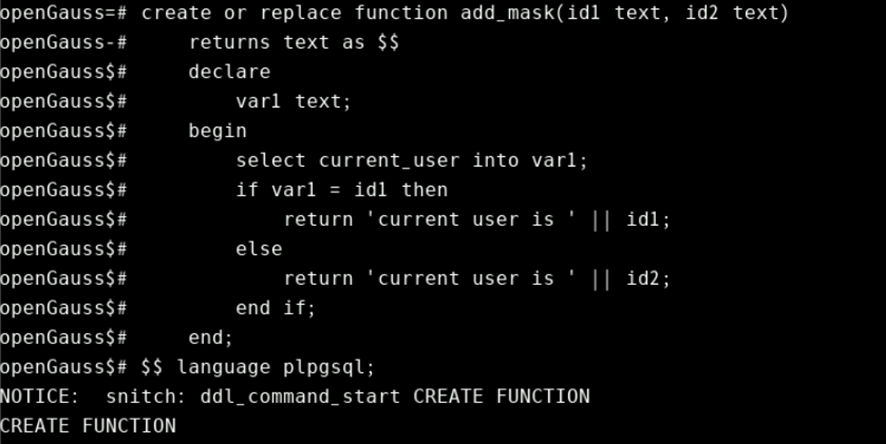
函数输出结果集
RETURN语句
自定义函数可以声明返回任意数据集,可通过RETURN NEXT,RETURN QUERY,RETURNS TABLE,RETURNS SETOF。
语法如下:
RETURN expression;函数用RETURN语句终止运行并返回结果给调用者。这种形式用于不返回结果集合的PL/pgSQL函数。
在返回标量类型的函数中,表达式的结果将自动转换为函数的返回类型。但要返回复合(行)值,则必须编写一个表达式精确地返回所请求的列集,该方法需要显式构造。
如果函数声明了参数输出值,那么函数 return 后不跟表达式,将返回当前值给输出参数变量。如果将函数声明为返回 void 类型,则可以使用 return 语句提前退出函数,return后面不能写表达式。
函数的返回值不能为undefined。如果PL/pgSQL控制块执行到函数的顶层块的末尾而未命中return语句,则将发生运行报错。但是,此限制不适用于带有输出参数的函数和返回void的函数。在这些情况下,如果顶级块完成,则自动执行return语句。
例如:
-- functions returning a scalar type
RETURN 1 + 2;
RETURN scalar_var;
-- functions returning a composite type
RETURN composite_type_var;
RETURN (1, 2, 'three'::text); -- must cast columns to correct types
RETURN NEXT和RETURN QUERY
语法如下:
RETURN NEXT expression;
RETURN QUERY query;
RETURN QUERY EXECUTE command-string [ USING expression [, ... ] ];
当PL/pgSQL函数被声明返回SETOF sometype时,则存储过程的实现略有不同。
在该场景下,RETURN NEXT 或 RETURN QUERY 返回的一系列结果集,用 RETURN 不带参数的语句来声明函数执行结束。RETURN NEXT 既可以表示标题数据类型,也可以表示复合数据类型。而对于复合数据类型,RETURN NEXT 将返回结果整个表的结果集。RETURN QUERY 是将QUERY的执行结果集返回给函数结果集。在函数的单个返回结果集中,RETURN NEXT 和 RETURN QUERY 可以混合使用,该场景下函数的结果集将以串联方式展现。而一个无参数的 RETURN语句则会控制函数的执行结束以达到控制函数执行流程的结果。
RETURN QUERY 有一个 RETURN QUERY EXECUTE 的变量,它用于指向SQL的动态执行结果。参数表达式可通过 WITH 插入到 QERUY 字符串里,其方法与 EXECUTE 方法相同。
如果声明函数时没给Output参数,则在使用Reutrn Next时不应该跟表达式。当有多个Output参数时,函数则应该声明返回SETOF。如下面RETURN NEXT的用例:
CREATE TABLE foo (fooid INT, foosubid INT, fooname TEXT);
INSERT INTO foo VALUES (1, 2, 'three');
INSERT INTO foo VALUES (4, 5, 'six');
CREATE OR REPLACE FUNCTION get_all_foo() RETURNS SETOF foo AS
$BODY$
DECLARE
r foo%rowtype;
BEGIN
FOR r IN
SELECT * FROM foo WHERE fooid > 0
LOOP
-- can do some processing here
RETURN NEXT r; -- return current row of SELECT
END LOOP;
RETURN;
END;
$BODY$
LANGUAGE plpgsql;
SELECT * FROM get_all_foo();
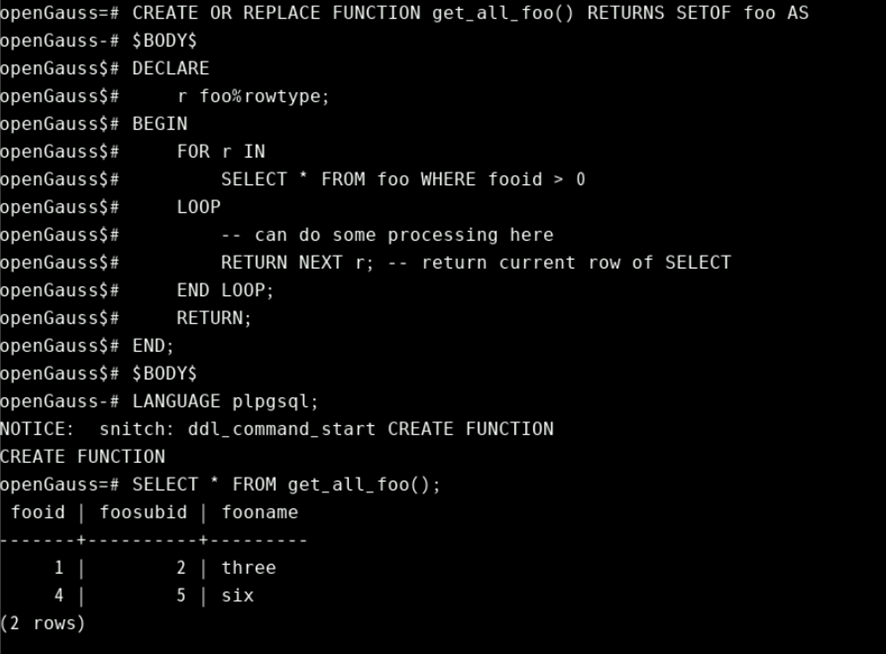
RETURN QUERY用例:(需要提前创建flight表,字段至少包含flightid和flightdate)
CREATE FUNCTION get_available_flightid(date) RETURNS SETOF integer AS
$BODY$
BEGIN
RETURN QUERY SELECT flightid
FROM flight
WHERE flightdate >= $1
AND flightdate < ($1 + 1);
-- Since execution is not finished, we can check whether rows were returned
-- and raise exception if not.
IF NOT FOUND THEN
RAISE EXCEPTION 'No flight at %.', $1;
END IF;
RETURN;
END;
$BODY$
LANGUAGE plpgsql;
-- Returns available flights or raises exception if there are no
-- available flights.
SELECT * FROM get_available_flightid(CURRENT_DATE);
PL/pgSLQ之事务管理
调用存储过程使用CALL关键字,如同调用匿名块使用DO一样。在PL/pgSQL语法中,可以使用COMMIT和ROLLBACK结束事务。使用COMMIT或者ROLLBACK结束事务后,另一个新事务会自动启动。所以没有单独的START TRANSACTION。这些与PL/pgSQL中的BEGIN和END是不同的。
示例如下:(需要创建表test1(a int),其中a字段至少有奇数和偶数值)
CREATE PROCEDURE transaction_test1()
LANGUAGE plpgsql
AS $$
BEGIN
FOR i IN 0..9 LOOP
INSERT INTO test1 (a) VALUES (i);
IF i % 2 = 0 THEN
COMMIT;
ELSE
ROLLBACK;
END IF;
END LOOP;
END;
$$;
CALL transaction_test1();
事务的控制仅受顶层的CALL或DO调用,或者嵌套的CALL或DO调用中可用。如果调用栈为CALL proc1() -> CALL proc2() -> CALL proc3(),那么第二个和第三个过程可以执行事务控制动作。但如果调用栈是CALL proc1() -> SELECT func2() -> CALL proc3(),由于中间有SELECT,那么最后一个过程不能做事务控制。
PL/pgSQL不支持保存点(保存点/回滚到保存点/释放保存点命令)。
在Cursor LOOP中有些特殊注意点:参数如下示例:
CREATE PROCEDURE transaction_test2()
LANGUAGE plpgsql
AS $$
DECLARE
r RECORD;
BEGIN
FOR r IN SELECT * FROM test2 ORDER BY x LOOP
INSERT INTO test1 (a) VALUES (r.x);
COMMIT;
END LOOP;
END;
$$;
CALL transaction_test2();
在非只读的游标循环中不允许使用事务操作(例如UPDATE...Returning)。
常用SQL操作
union all/ union
该语法用于合并两个SELECT查询结果集。union会对两个查询结果集去除重复的数据。而union all不会对结果集去重。
select * from score1 order by chinese limit 10
union
select * from score2 order by chinese limit 10;
select * from score1 order by chinese limit 10
union all
select * from score2 order by chinese limit 10;
dense() rank()
用于对结果集排序。
dense_rank() over([partition by column] order by column desc)-- DENSE_RANK函数为各组内值生成连续排序序号,其中,相同的值具有相同序号
CREATE TABLE dense_rank_t1(a int, b int);
INSERT INTO dense_rank_t1 VALUES(1,1),(1,1),(1, 2),(1, 3),(2, 4),(2, 5),(3,6);
SELECT a,b,DENSE_RANK() OVER(PARTITION BY a ORDER BY b) FROM dense_rank_t1;
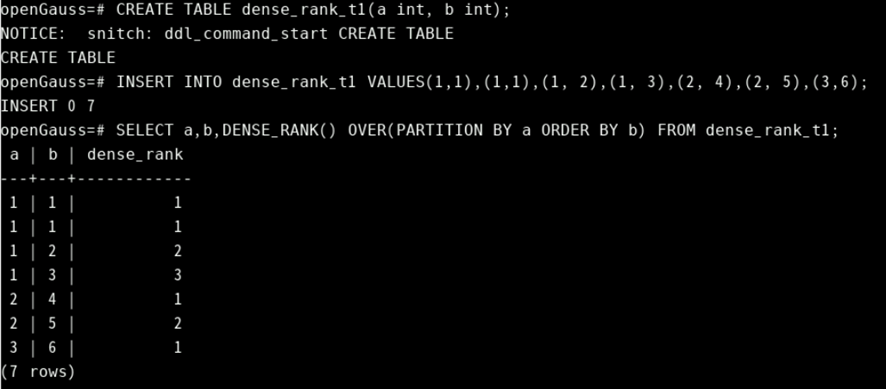
not in/ not exist
查看两个班级相同的科目, 202201班在score2中不存在的成绩, 要求使用not in(考试时详细确认题目要求, 查看是具体哪些科目成绩)
select chinese from score where chinese not in (select chinese from score2);merge into
将目标表和源表中的数据针对关联条件进行匹配, 匹配时对目标表进行update更新操作, 不匹配时对目标表进行insert写入操作
MERGE INTO products p USING newproducts np ON (p.product_id = np.product_id)
WHEN MATCHED THEN
UPDATE SET p.product_name = np.product_name, p.category = np.category WHERE p.product_name != 'play gym'
WHEN NOT MATCHED THEN
INSERT VALUES (np.product_id, np.product_name, np.category) WHERE np.category = 'books';
首字母大写函数initcap
-- family_name跟first_name用'.'拼接,要求首字母大写
select id, initcap(family_name||'.'||first_name), sexmark, grade from su;系统视图的权限查询
select t1.*,rolname from (select datname,(aclexplode(datacl)).grantee, (aclexplode(datacl)).privilege_type from pg_database) t1,pg_roles where grantee=pg_roles.oid and rolname='sjh111' and datname not like '%template%';
-- 查看用户user1和数据库的相关权限,题目提示用pg_database和pg_roles,要求显示数据库名、用户名、数据库的权限(一定要背下来,原题,而且不要去格式美化)
SELECT a.datname, b.rolname, string_agg(a.priv_t, ',')
from (SELECT datname, (aclexplode(COALESCE(datacl, acldefault('d' :: "char", datdba)))).grantee as grantee, (aclexplode(COALESCE(datacl, acldefault('d' :: "char", datdba)))).privilege_type as priv_t
FROM "pg_database"
WHERE datname not like '%template%' ) a,
"pg_roles" b
WHERE (a.grantee = 0 or a.grantee = b.oid)
AND b.rolname = 'user1'
GROUP BY a.datname, b.rolname;
插入一条数据,当主键冲突时将mark改为'F'
语法如下:
INSERT INTO xxx ON DUPLICATE KEY UPDATE expression示例:
insert into su values(2,'tom','jerry','tom','H',63) on duplicate key update mark='F'
DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)