vtk c++ 图像分割_自动驾驶中基于传感器融合的道路分割

分割是一个计算机视觉很难的任务,主要是语义信息不容易获得。最近深度学习的发展推动了这个领域的突破,即语义分割(semantic segmentation)和实例分割(instance segmentation),还有最近流行的全景分割(Panoptic segmentation)。语义分割是预测每个像素点的语义类别;实例分割预测每个实例物体包含的像素区域;而全景分割是为每个像素点赋予类别和实例 ,生成全局分割。
从一篇2017年综述论文“A Review on Deep Learning Techniques Applied to Semantic Segmentation“总结一下语义分割的方法,如下是该综述总结的方法概括图:
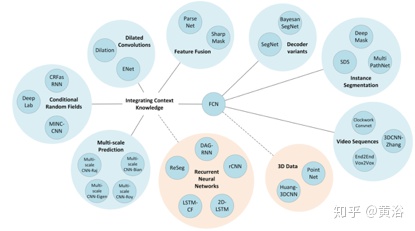
可以说,深度学习在语义分割的工作开始于FCN(fully convolution network),即真正pixel-to-pixel的图像理解。实例分割实际是目标检测和语义分割的结合,其方法基本也是分成两个方向:基于目标检测和基于语义分割;前者以Mask-RCNN为标志,而后者以SGN(Sequential grouping networks)为典型。
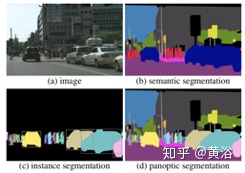
最近提出全景分割的概念,下图比较三个分割的概念区别。可以看出,全景分割是真正意义上的景物理解,也是实例分割和语义分割的互补结果。
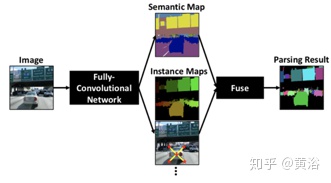
MIT和Google联合发表的论文中提出DeeperLab,可以看成一个这方面的典型方法,下面是其算法的流程图:由一个FCN产生逐像素的语义预测和实例预测,然后通过一个快速算法把这些预测融成在一起得到最后全景分割结果。
在自动驾驶系统中,分割的价值在于,一是高清地图的定位,二是可驾驶道路的识别。
。。。。。。待续
"Estimating Drivable Collision-Free Space from Monocular Video"

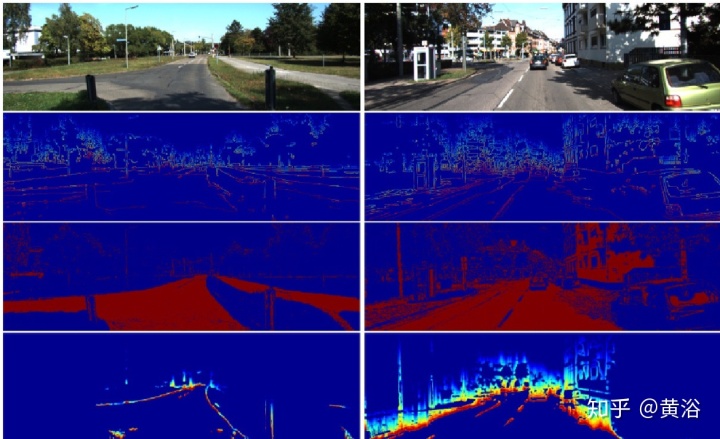

"Minimizing Supervision for Free-space Segmentation"
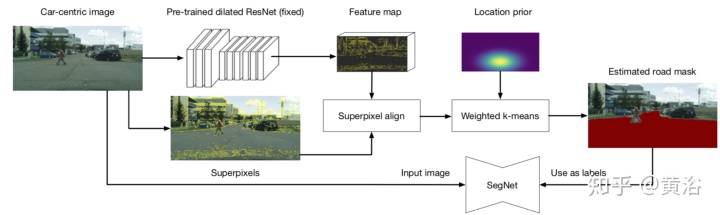
首先,道路区域是比较特别的, 纹理简单,位置也居中。这里提出的方法有一个显著优点就是弱监督下自动分割能力。图示是该方法的概览:从一个预先训练的扩张残差网络(dilated ResNet)提取特征图,采用图像分割的超像素做特征图校准,利用道路位置先验知识进行聚类,最后产生训练一个分割网络SegNet的掩码,期间无需任何手工标注。



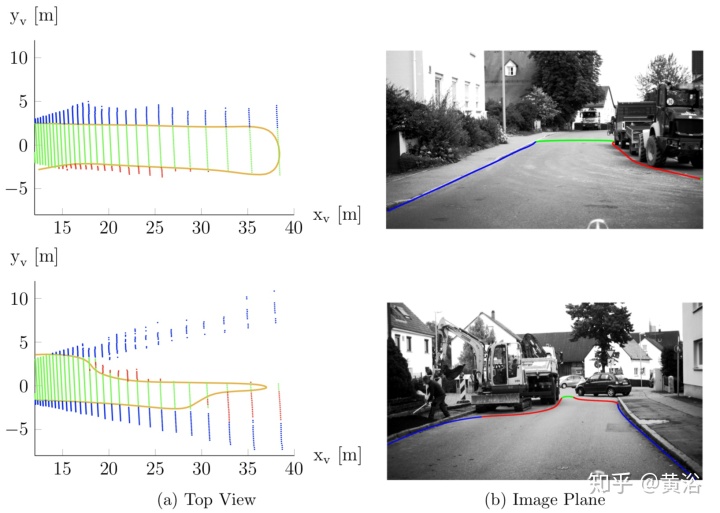
"Modeling of Drivable Free Space with Fused Camera Data for Autonomous Driving"

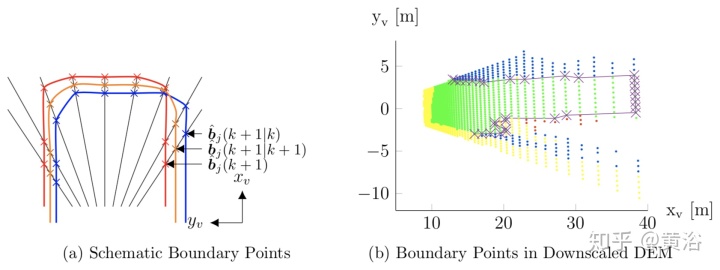
Note: Digital Elevation Maps (DEM)
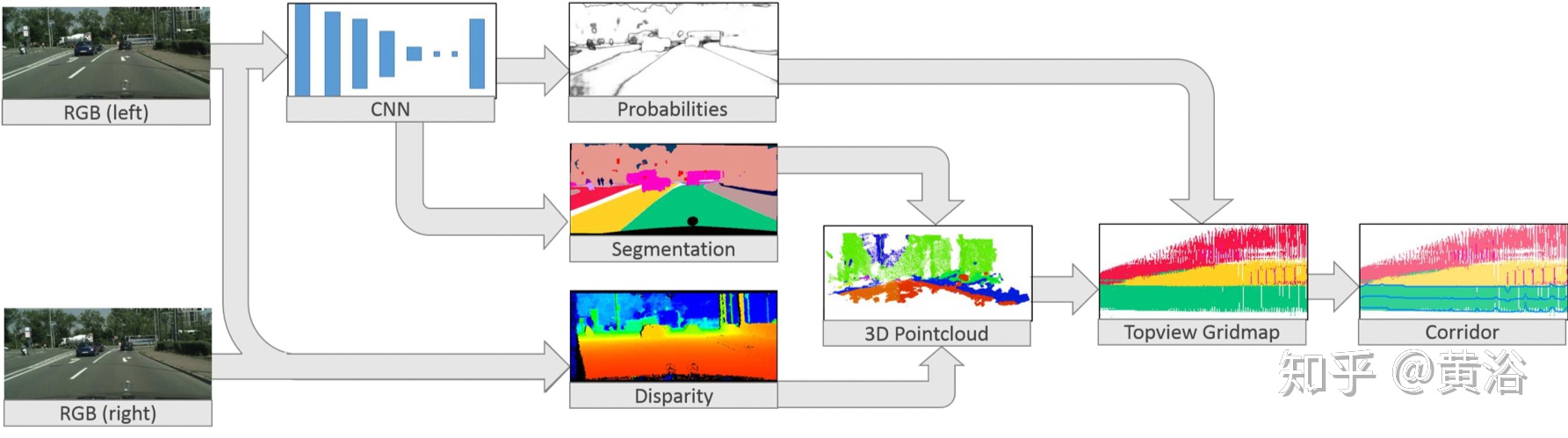
"Perception Pipeline for Mapless Driving on an Ego-Lane Corridor"


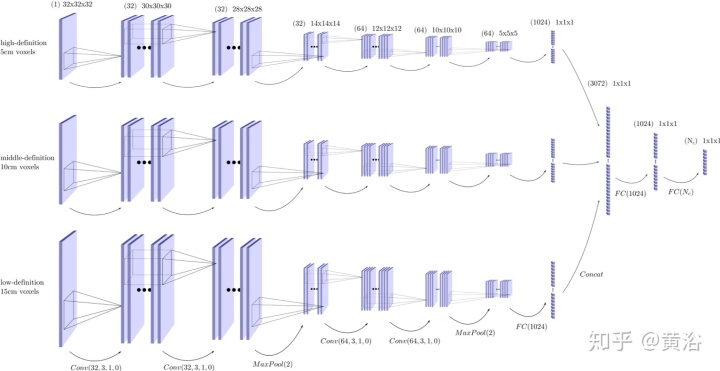
“Classification of Point Cloud for Road Scene Understanding with Multiscale Voxel Deep Network“



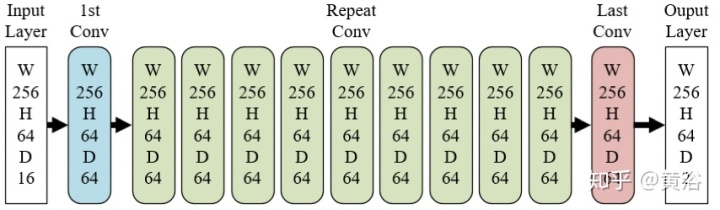
"Real-Time Road Segmentation Using LiDAR Data Processing on an FPGA"



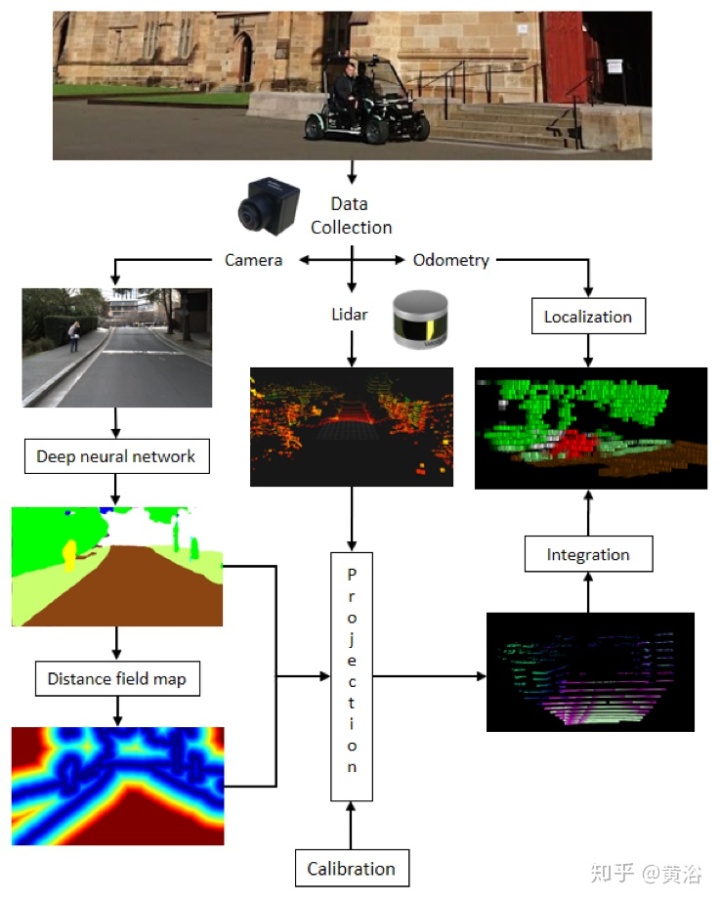
"Fusing Lidar and Semantic Image Information in Octree Maps"
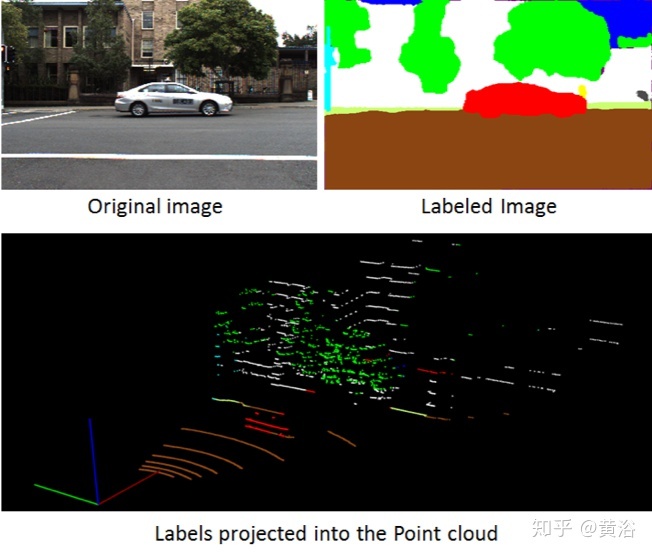
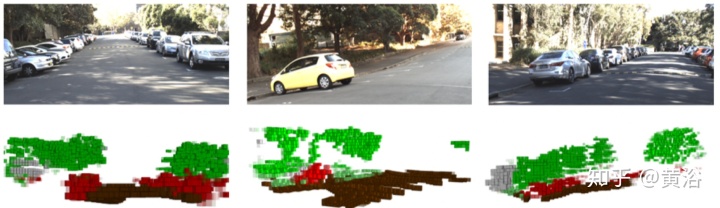
"Sensor Fusion for Semantic Segmentation of Urban Scenes"
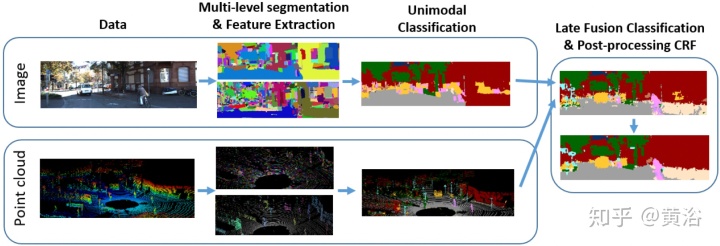



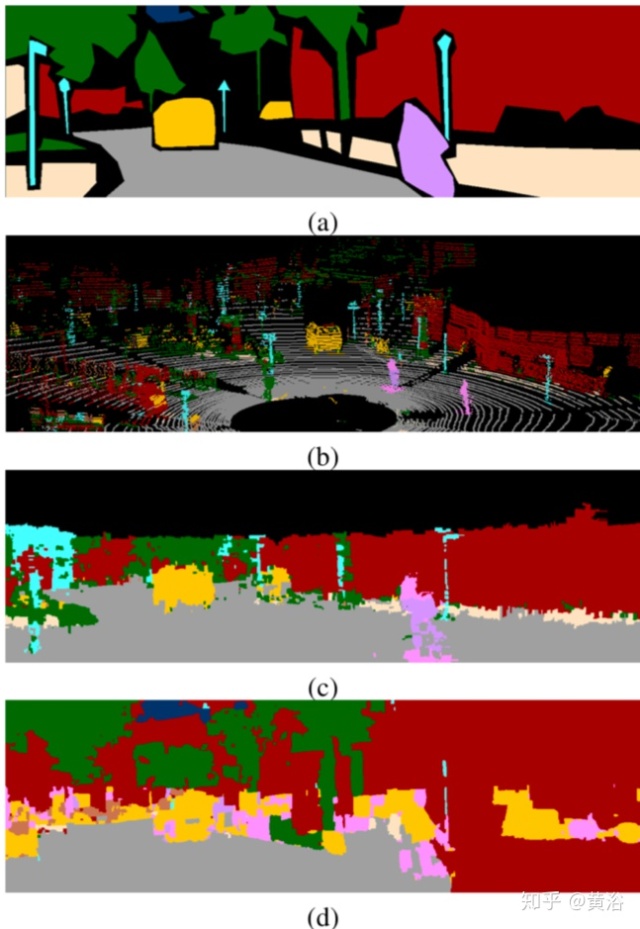

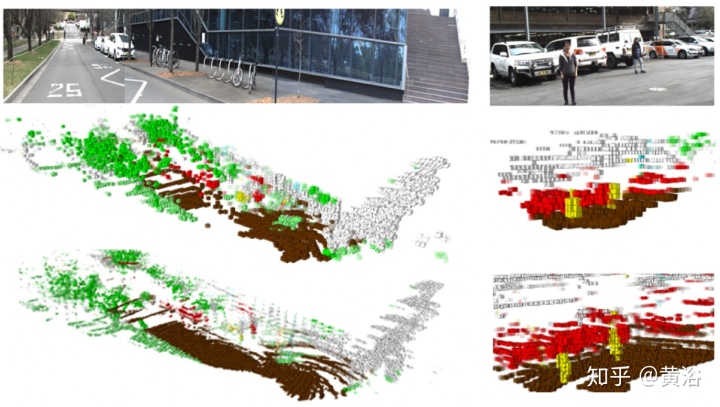
"Fusion Based Holistic Road Scene Understanding"

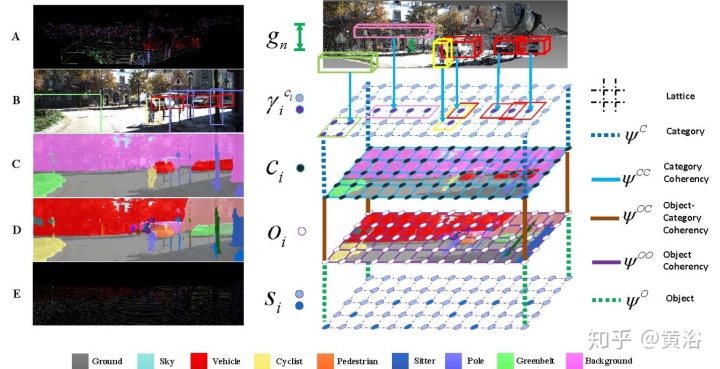
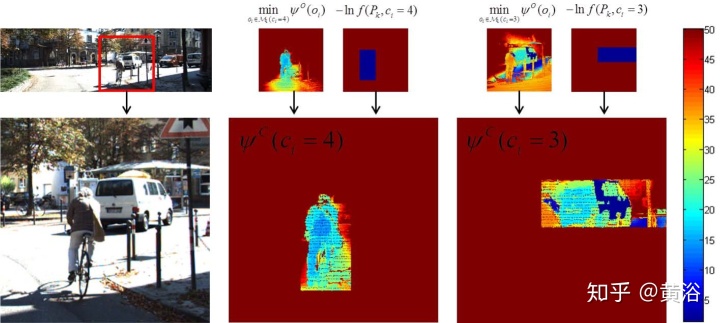

"Road detection based on the fusion of Lidar and image data"


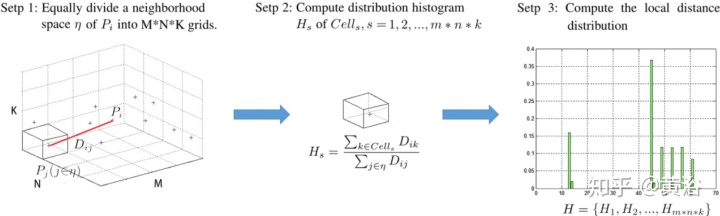

"Fusing Geometry and Appearance for Road Segmentation"



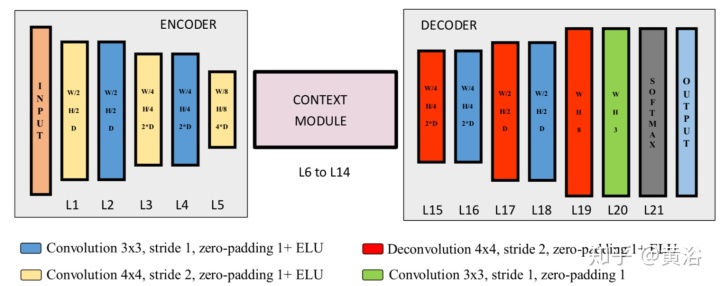
"LIDAR-Camera Fusion for Road Detection Using Fully Convolutional Neural Networks"
讨论通过深度学习将激光雷达和摄像头结合做道路检测。该方法会将3D点云先投影到图像平面,然后上采样得到致密的深度图像。该方法训练多个全卷积网络 (FCNs) 以不同方式完成道路检测:单个传感器工作或者三个融合方式,即前融合、后融合和交叉融合。前/后融合一般是在某个网络深度层集成信息,而交叉融合的FCN网络是直接从数据学习如何集成信息,其方法是训练一个在激光雷达分支和摄像头分支之间的交叉接头。
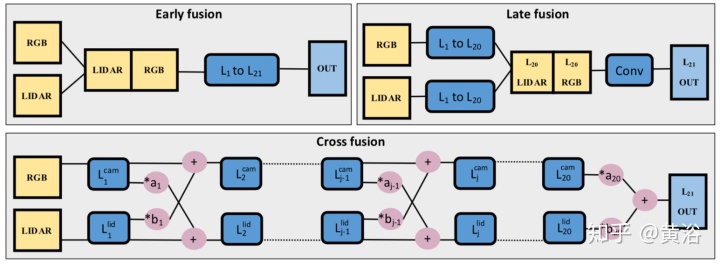
三种融合机制:1) 前融合. 传感器数据直接合并成2) 后融合. 在layer 20,输出的结果在数据的深度维度合并,通过一个卷积层完成高层融合. 3) 交叉融合. 两个分支通过一个可训练的标量交叉接头连接在一起,即系数aj,bj, 深度层j ∈ {1, . . . , 20}. 在给定深度,会根据图示的操作对每层输入(摄像头数据和激光雷达数据)进行计算,
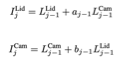




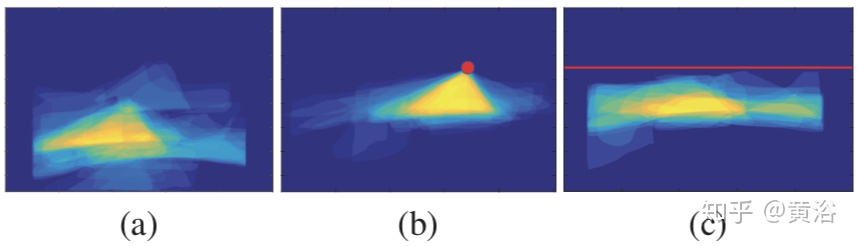
"Detecting Drivable Area for Self-driving Cars: An Unsupervised Approach"
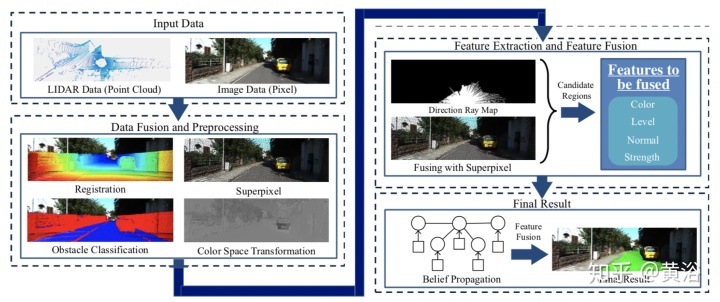
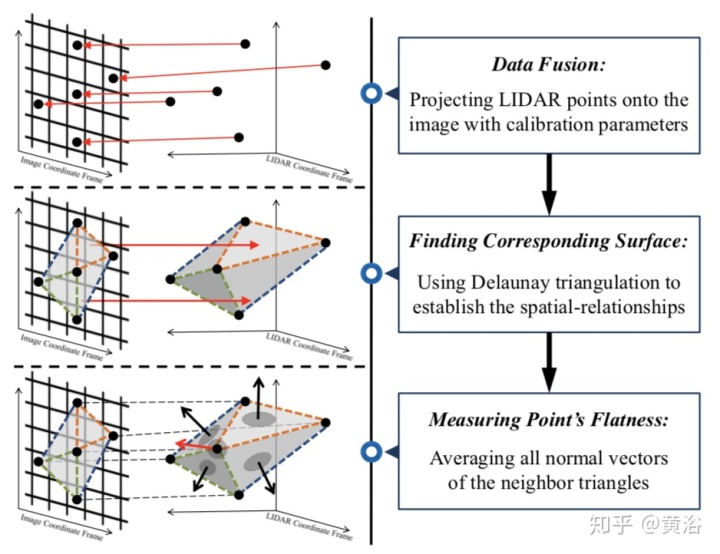
。。。待续。。。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)