(极好的机器学习案例)机器学习 入门实操~~
由于我悟性不高,一般学习一个新的东西,对于初见的一些概念,很难理解其意。我总是喜欢先找个实实在在的例子,跟着跑一遍,看看流程、结果。然后再回过头来学习里面的种种算法和规则。我且称之为菜鸟学习法。我们不得不面对的是,现在机器学习、深度学习这些新的学习范式,已经闯入多个领域,也在颠覆这些领域。感觉就像当年VASP等成熟软件的兴起一样,主流的商业软件淘汰了很多自己写代码算做量子计算的学者。接下来,机器学
菜鸟学习法
由于我悟性不高,一般学习一个新的东西,对于初见的一些概念,很难理解其意。我总是喜欢先找个实实在在的例子,跟着跑一遍,看看流程、结果。然后再回过头来学习里面的种种算法和规则。我且称之为菜鸟学习法。
我们不得不面对的是,现在机器学习、深度学习这些新的学习范式,已经闯入多个领域,也在颠覆这些领域。
感觉就像当年VASP等成熟软件的兴起一样,主流的商业软件淘汰了很多自己写代码算做量子计算的学者。接下来,机器学习的引入,各种新的软件也许马上会成为下一个“VASP”,手握资源的各路大佬都在抢占地盘。
抱歉,扯远了,我们回到学习机器学习的第一个阶段,代码测试:
案例链接
https://nbviewer.org/github/hackingmaterials/matminer_examples/blob/main/matminer_examples/machine_learning-nb/bulk_modulus.ipynb
数据集来源
数据来源于数据集 matminer,具体使用参考官网
https://hackingmaterials.lbl.gov/matminer
以及文档:
https://hackingmaterials.lbl.gov/matminer/dataset_summary.html
部分代码简单说明
1. 加载和处理数据集
from matminer.datasets.convenience_loaders import load_elastic_tensor
df = load_elastic_tensor() # loads dataset in a pandas DataFrame object
-
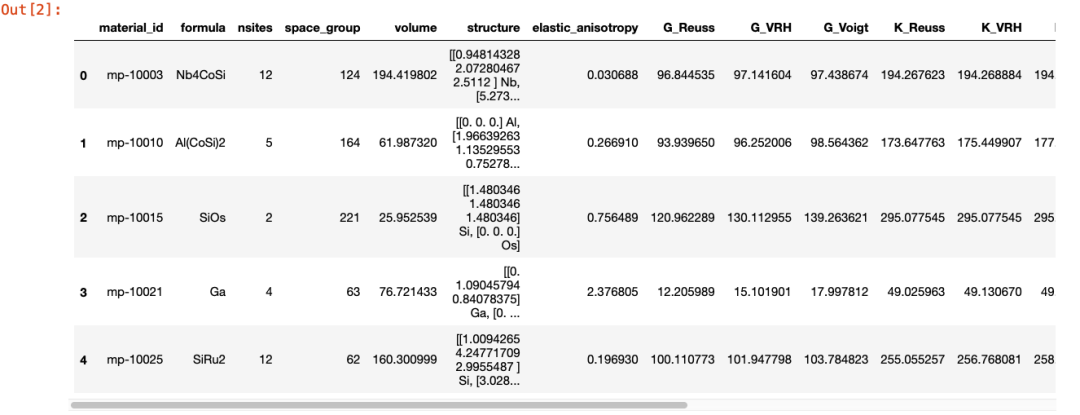
显示数据的开头部分使用head方法
df.head()
-
显示数据的列
df.columns

-
去掉不需要的列
unwanted_columns = ["volume", "nsites",
"compliance_tensor","elastic_tensor",
"elastic_tensor_original", "K_Voigt",
"G_Voigt", "K_Reuss", "G_Reuss"]
df = df.drop(unwanted_columns, axis=1)## 去掉不需要的列
df.head() #此时再观察一下这个数据集

-
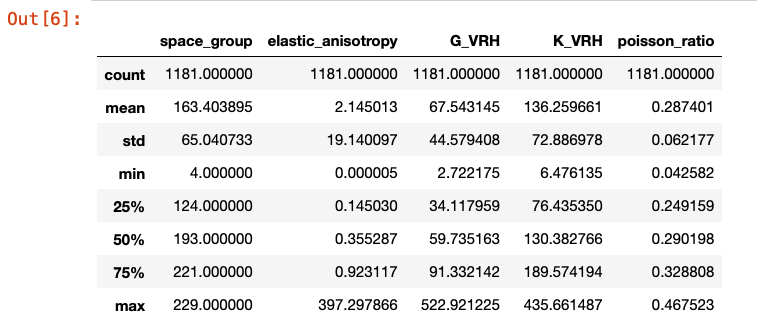
数据的描述性统计
df.describe()
2. 添加描述符(特征化)
-
组成成分的特征化
from matminer.featurizers.conversions import StrToComposition
df = StrToComposition().featurize_dataframe(df, "formula")
df.head()

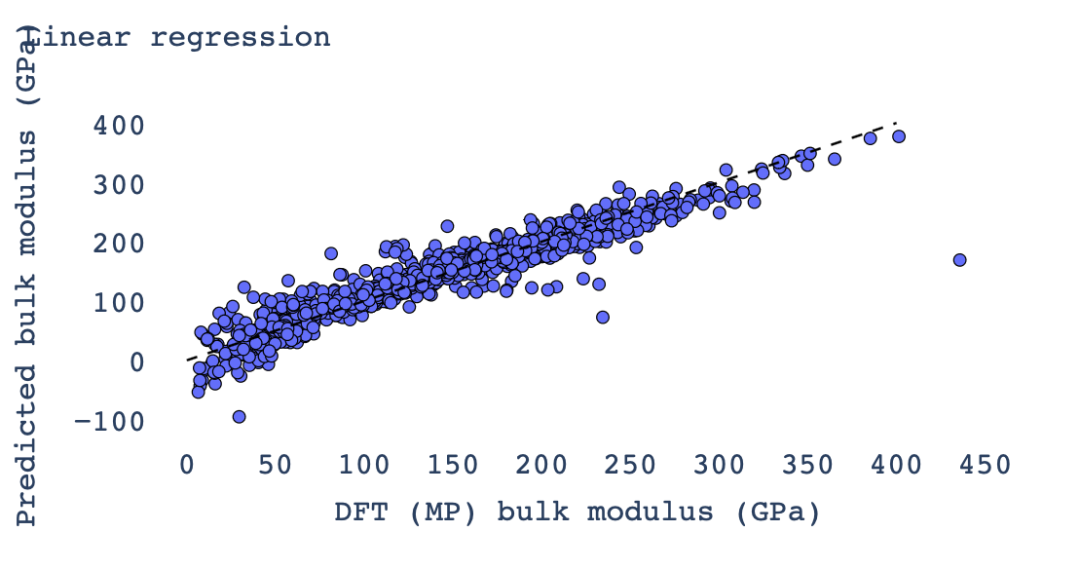
3. 线性回归
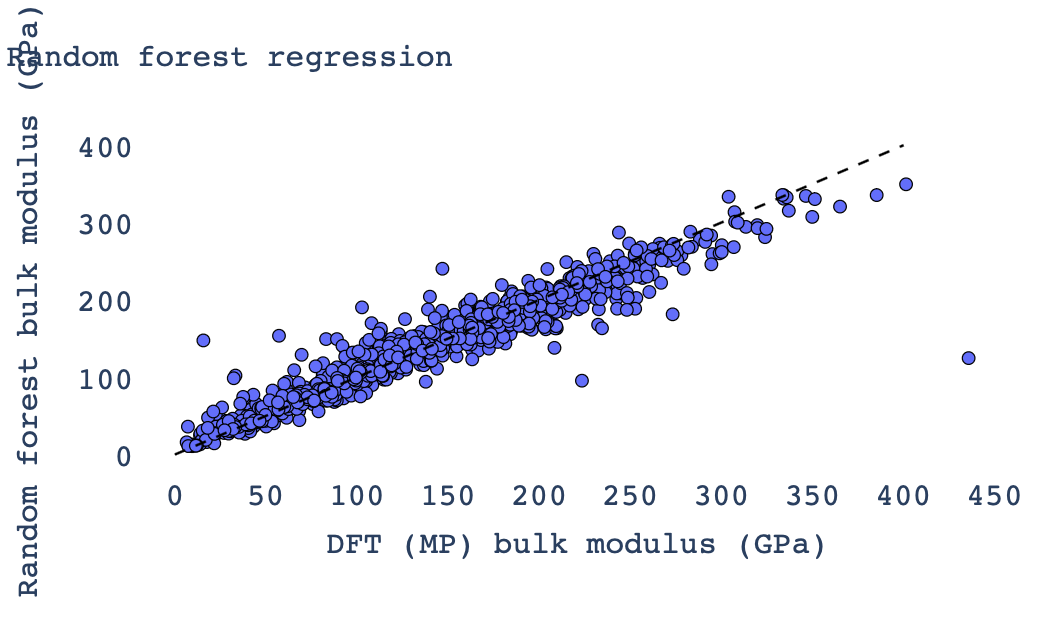
4. 随机森林
参考
大师兄科研网
https://mp.weixin.qq.com/s/U99hAXOsNob1sgAehIED3A
库的安装
一般直接使用pip install 库名
就可以安装对应的库,我在自己电脑测试,使用pip install 比conda install这个方法好用。
简洁版测试代码下载
链接:https://pan.quark.cn/s/3b550442f061
ChatGPT 快问快答
或者读者也可以在ChatGPT里快问快答的形式学习简单的案例,也是一个不错的尝试。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)