大型视频规划器实现通用机器人控制
25年12月来自MIT、Berkeley和Harvard的论文“Large Video Planner Enables Generalizable Robot Control ”。通用机器人需要能够泛化到各种任务和环境中的决策模型。近期研究通过扩展多模态大语言模型(MLLM)并加入动作输出,构建机器人基础模型,即视觉-语言-动作(VLA)系统。这些研究的动机在于,MLLM的大规模语言和图像预训练可
25年12月来自MIT、Berkeley和Harvard的论文“Large Video Planner Enables Generalizable Robot Control ”。
通用机器人需要能够泛化到各种任务和环境中的决策模型。近期研究通过扩展多模态大语言模型(MLLM)并加入动作输出,构建机器人基础模型,即视觉-语言-动作(VLA)系统。这些研究的动机在于,MLLM的大规模语言和图像预训练可以有效地迁移到动作输出模态。本文探索一种替代范式,即使用大规模视频预训练作为构建机器人基础模型的主要模态。与静态图像和语言不同,视频能够捕捉物理世界中状态和动作的时空序列,这些序列与机器人行为自然契合。构建一个互联网规模的人类活动和任务演示视频数据集,并首次在基础模型规模上训练一个用于生成式机器人规划的开放式视频模型。该模型能够为新的场景和任务生成零样本视频规划,对其进行后处理以提取可执行的机器人动作。通过第三方选择的实际任务和真实机器人实验来评估任务级泛化能力,并验证模型在物理上的成功执行。这些结果共同表明,该模型具有稳健的指令跟踪能力、强大的泛化能力和实际应用可行性。
从视频演示中学习一直是机器人学习领域一个有趣的研究方向[55, 84, 71, 59],部分原因是视频数据丰富。随着视频生成技术的最新进展,研究人员开始探索其在机器人领域的应用。一种研究方向是将视频生成用于视觉策略,其中模型合成成功完成任务的视频来指导控制[26, 51, 8, 56, 2]。另一种研究方向是将视频生成视为一种动力学模型,根据动作输入预测未来的帧[4, 85, 25, 90, 65]。视频世界模型也被用作评估器,它有可能使机器人通过模拟部署更有效地验证和改进其策略[60]。随着最新方法训练出能够联合生成视频和机器人动作的统一模型[47],策略学习和动力学建模之间的界限变得越来越模糊。
给定一个生成的视频,有多种方法可以提取连续的动作。一种方法是在生成的视频基础上学习逆动力学或目标条件策略[26, 82, 39, 57, 89]。另一种方法是直接推断二维或三维场景流以获得动作[44, 17]。相比之下,本文阐述如何利用三维场景重建算法MegaSam[50],然后使用HaMeR[62]和Dex-Retargeting[66]进行手部重建,从而获得动作。
本文提出大型视频规划器(LVP),一个专为机器人操作设计的大规模视频基础模型,以及一个用于将其作为零样本策略部署到真实机器人上的相关框架。另外,构建一个精心整理的、开放互联网规模的人类活动和机器人任务演示视频数据集,经过仔细处理,可用于具身决策和指令执行。最后,做一项严格的任务级泛化评估,使用独立的测试协议和真实机器人实验,系统地评估模型在未见过的环境、任务和具身模型中的泛化能力,如图所示。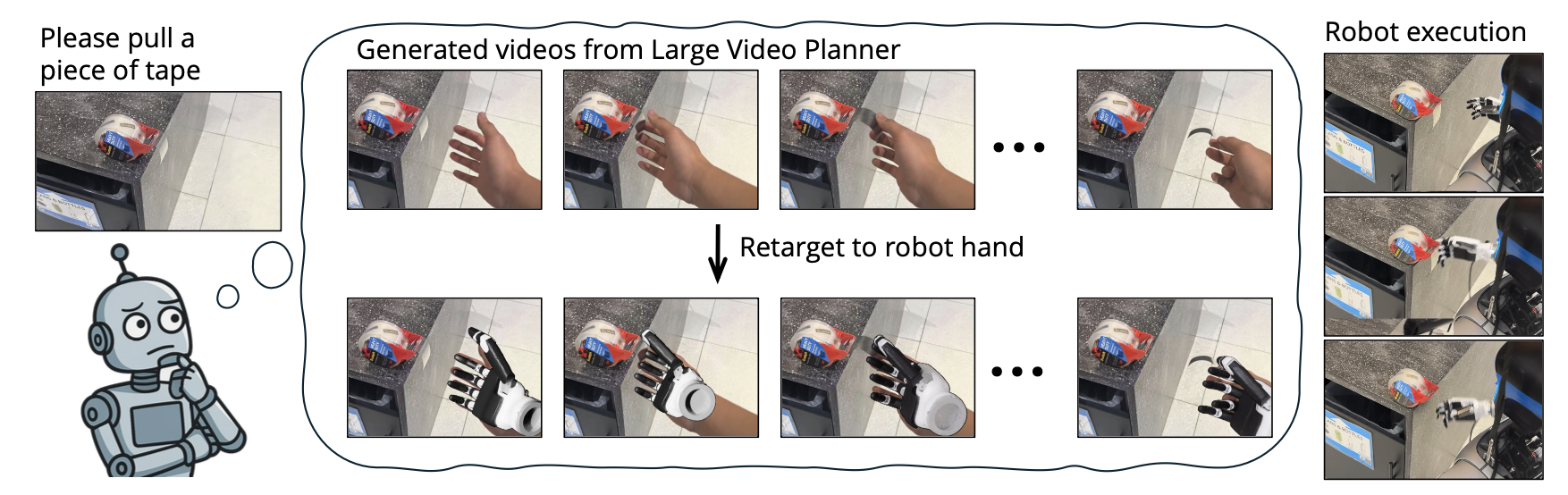
机器人基础模型将观察结果和目标映射到一系列动作。通过两阶段设计来实现这一点:首先进行大型视频规划,然后进行动作提取。假设一个机器人面对着一扇它从未见过的门。它的摄像头捕捉到门把手,同时它的主人发出指令:“打开这扇门。”机器人首先利用视频基础模型来想象一个理性的人会如何完成这项任务——生成一段视频,视频中一只手伸向门把手,转动它,然后推开门。接着,它应用动作提取算法,将这个视觉规划转化为可执行的控制信号,无论是灵巧的五指机械手还是并联机械臂。
LVP:用于生成式规划的视频基础模型
潜扩散。首先根据潜扩散框架[14, 81]构建视频基础模型。用时间因果的三维变分自编码器(VAE)将像素空间中的视频片段压缩成紧凑的低维潜表示x。VAE将每个8×8×4的时空块编码成一个16通道的嵌入,将形状为[1+T, 3, H, W]的输入转换为形状为[1+⌈T/4⌉, 16, ⌈H/4⌉, ⌈W/4⌉]的潜表示,其中T+1是帧数,H和W是空间维度。在进行压缩之前,视频的第一帧会重复4次,以便与单帧图像数据进行协同训练,这对应于T+1中的1。
然后,冻结3D VAE,并在压缩后的潜空间中,使用一个改进的扩散强制transformer[16, 73](如图所示,一个DiT的变型)训练一个特殊的视频扩散模型[72, 37, 52, 63]。按照扩散训练流程,向一个干净的视频潜空间添加高斯噪声,并训练扩散模型来去除这些噪声。在采样时刻,模型从一个预填充噪声的潜空间开始,迭代地对潜空间进行去噪,直到获得一个干净的样本。然后,VAE解码器将该潜空间解码为一个视频样本。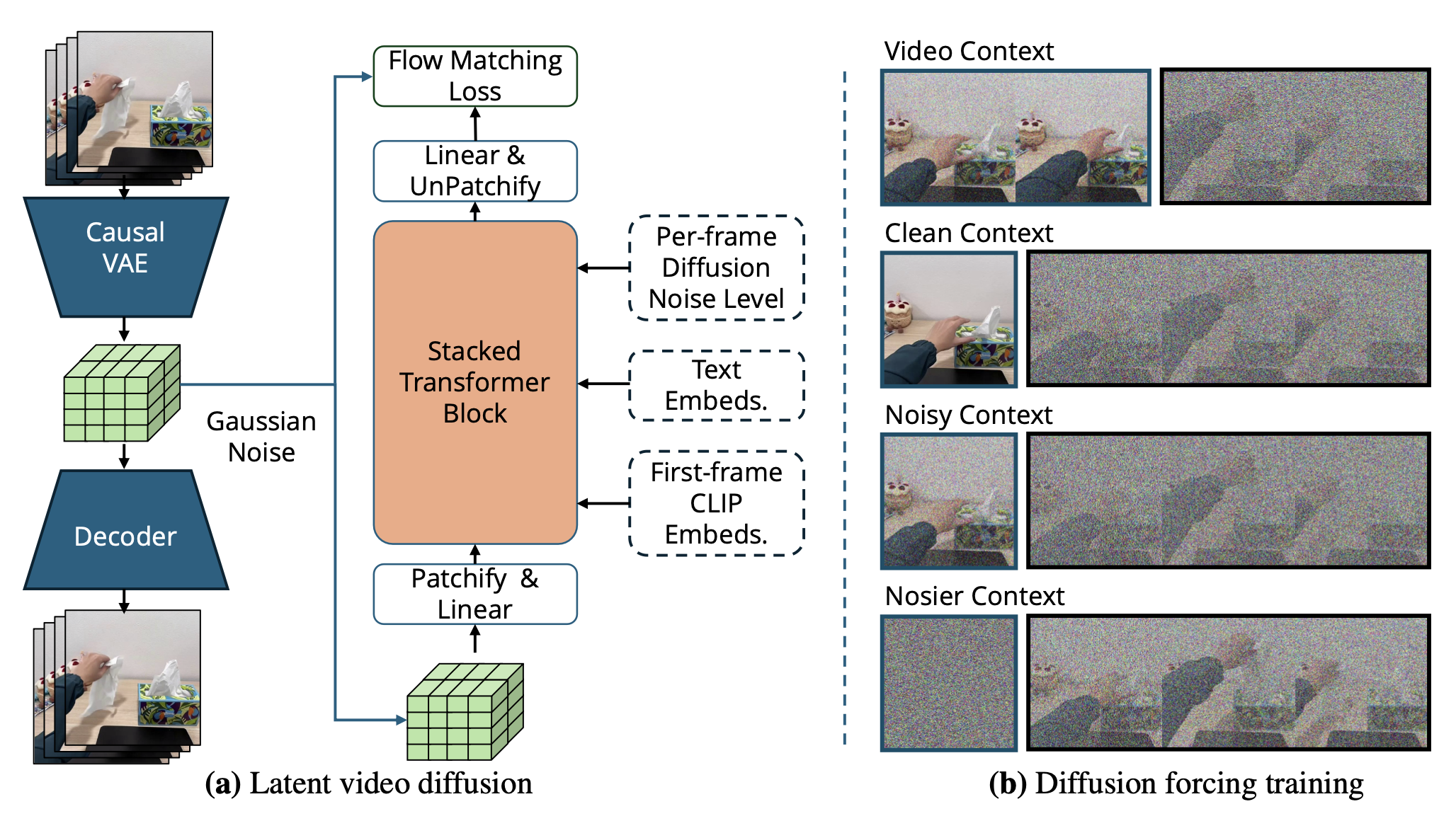
具体来说,用流匹配目标函数[52]来训练这个视频扩散模型。在强调更高噪声水平的偏移调度[28]下,通过向编码视频潜变量z_0添加噪声z_k = (1 − k) z_0 + kε,其中k表示所选噪声水平,ε ∼ N(0,1),z_k是含噪声的潜变量。模型f_θ经过训练,在含噪声的潜变量z_t、条件变量c(包含输入图像和文本指令)以及噪声水平t下预测流ε − z_0,从而最小化匹配损失[52] L = ||f_θ(z_k, c, k) − k(ε − z_0)||_2。
扩散强制transformer。视频扩散模型的一个挑战是时间一致性。在模型中,生成的视频不仅必须与语言指令(文本到视频或t2v)一致,还必须与机器人观测指定的首帧(图像-到-视频 或 i2v)一致。此外,为了生成多阶段视频计划,可能需要将视频生成与多个先前的帧(视频-到-视频 或 v2v)联系起来。传统上,这种联系是通过微调 t2v 模型来实现的,使其能够交叉关注上下文帧的不同区域 [81]。然而,提出使用最近提出的扩散强制框架来更好地满足这一需求。
与传统视频扩散模型对所有token添加统一噪声水平不同,扩散强制 [16] 发现,在不同帧上使用不同噪声水平训练视频扩散模型具有额外的优势,即灵活性和展开稳定性。由于所有噪声水平在训练期间都是随机的,因此在测试时可以通过选择所需的噪声水平来灵活地控制联系。
为了以统一的目标学习 i2v 和 v2v,采用扩散强制,并对上下文帧和生成的帧应用不同的噪声水平。如图 (b) 所示,给定一个基于固定数量潜帧的扩散Transformer (DiT),首先从 {0, 1, 2, …, 6} 个潜帧中随机采样一个历史长度,将视频分割成历史片段和未来片段。然后,为每个片段应用独立的噪声水平,并将生成的带噪视频输入到模型中,其他所有设置保持不变。例如,如果在训练时对第一帧或前几帧添加零噪声,模型会将其视为完全可见的上下文帧并学习基于该帧进行条件化;如果历史帧具有中间噪声水平,模型会将其视为部分信息并学习对分布外上下文帧的鲁棒性。这样可以通过在采样时将噪声水平设置为 0,灵活地选择基于干净的第一帧或多个历史帧进行条件化。
这种方法不仅消除对可变长度上下文token的额外交叉注意机制,而且无需架构更改即可与现有的 DiT 模型权重兼容。参考 Song [73]的研究,简单地将不同噪声水平的嵌入向量分配给DiT架构中的不同token,而不是统一分配。这能够在预训练的视频基础模型WAN 2.1 14B [81]的权重之上训练一个扩散强制模型。与WAN 2.1 14B的做法类似,交叉关注第一帧的CLIP特征以及UMT5 [19]编码器提取的文本嵌入向量。由于扩散强制能够以更简洁的方式实现上下文帧条件化,因此移除WAN用于图像条件化的掩码和引导通道。
利用历史引导增强时间一致性。除了灵活的条件化和与现有权重的兼容性之外,设计还可以通过启用扩散强制[16, 73]中的特殊采样技术来显著增强上下文一致性。
无分类器引导 (CFG) [36] 已被证实能够提高视觉生成模型的视觉质量和条件化依从性。WAN 2.1 采用一种文本 CFG,它结合文本条件扩散模型和无条件扩散模型的输出。然而,这种方法仍然会导致运动保真度不佳和图像条件化较弱。
LVP 采用历史引导 [73],这是一种 CFG 变型,可以对任意数量的上下文帧进行引导。令 x_k 表示噪声水平为 k 的未来片段,c_text 表示任务指令。由于模型是使用扩散强制训练的,因此可以灵活地根据采样时提供的历史片段 x_hist 来设定条件,将其噪声水平设置为零,无论是单帧还是上下文视频。
类似地,可以将上下文帧的噪声级别设置为最大值,以完全掩盖上下文帧并获得无条件得分。为了进行历史引导,用组合评分进行采样。正如基于文本的CFG 可以增强对文本指令的遵循度一样,历史引导可以增强对上下文图像的遵循度。在采样过程中,将历史引导和基于文本的 CFG 相结合,通过使用评分进行采样,生成同时遵循文本和上下文帧的视频。
与传统的基于文本引导相比,这种组合引导技术可以显著提高规划质量,通过很强指令遵循生成物理上可行的规划。
用于多阶段规划的自回归扩展。由于灵活的历史条件化,模型可以扩展先前生成或捕获的视频。该模型最多支持 24 帧(VAE 空间中的 6 个潜在帧)作为上下文。可以迭代地重复视频扩展,以生成多阶段视频规划。
训练详情。分两个阶段训练模型,以逐步提高其视觉规划能力和视觉质量:
• 继续预训练。从 Wan I2V 14B 权重开始,舍弃处理额外掩码和图像引导通道的权重。用完整数据集训练 6 万步,批大小为 128,总共训练 2000 亿个 token。在此阶段,模型能够捕捉丰富的动态信息和较强的指令执行能力,但生成的视频经常出现过大镜头运动,这会影响其在机器人上的流畅部署。
• 低镜头运动微调。为了减少不必要的镜头运动,从 Ego4D、Epic-Kitchens 和 Panda 数据集中筛选出一个较小的子集,选择平均光流幅度更低的片段,并额外进行 1 万步的微调。此阶段有效地抑制镜头漂移,提高整体的时间平滑度和视觉稳定性。
整个训练过程使用 128 个 H100 SXM5 GPU,耗时约 14 天。
LVP-1M:人类与机器人动作视频数据集
训练用于具身规划的视频基础模型需要大量数据,这些数据应侧重于多样化的物体交互,并配以以动作为中心的文本标注。这与用于内容创作的视频生成的标准视频数据集[45, 81]形成对比,后者通常更注重美学质量、电影镜头或对视觉外观和元素的密集描述,而非动作本身。为此制作LVP-1M数据集,这是一个包含140万个短视频的多样化高质量数据集,这些短视频展示人类或机器人与物体的交互,每个视频都配有多个以动作为中心的文本标注。
视频来源。鉴于视频数据的丰富性,从现有数据集中获取原始视频,然后添加自己的高质量标注。为了确保场景、任务和具身性的广泛多样性,将机器人远程操作视频和人类活动视频相结合。
首先,用视频基础模型广泛采用的网络爬虫数据。选择 Pandas 70M [18] 作为视频源,进行深度过滤。这些互联网规模的数据集包含各种视频,这些视频经过视觉质量过滤并添加视觉内容字幕。它们提供至关重要的规模和多样性,涵盖无数的任务、场景和物体。然而,这些视频中只有一小部分能够以足够的分辨率捕捉与物体进行详细手部交互的过程,更不用说几乎没有机器人参与。
第二个视频源来自以自我为中心的人类活动数据集。这些中等规模的数据集包含许多标注的人-物交互,具有一定的多样性,但由于摄像机的移动,通常存在较大的背景运动。此外,这些数据集中的原子动作标注时长仍然从几秒到几分钟不等。选择从 Ego4D [34]、Epic Kitchens [22] 和 Something-something [33] 数据集中提取视频,然后进行深度过滤、帧对齐和重新添加字幕。
第三个视频源来自机器人数据集,这些数据集包含远程操控机器人执行任务的场景。虽然这些视频提供关于机器人形态的知识,涵盖从平行爪夹爪到灵巧多指手的各种类型,但它们通常存在视觉质量差、帧率不齐以及多样性不足的问题。此外,描述任务的简短字幕往往缺失,许多视频的字幕模糊不清,例如“抓取”,甚至根本没有字幕。因此,选择 Bridge [80]、Droid [42]、Language Table [58] 和 AgiBot-World [15] 这几个数据集,因为它们具有丰富的字幕和帧对齐功能。
下表总结视频来源及其关键属性: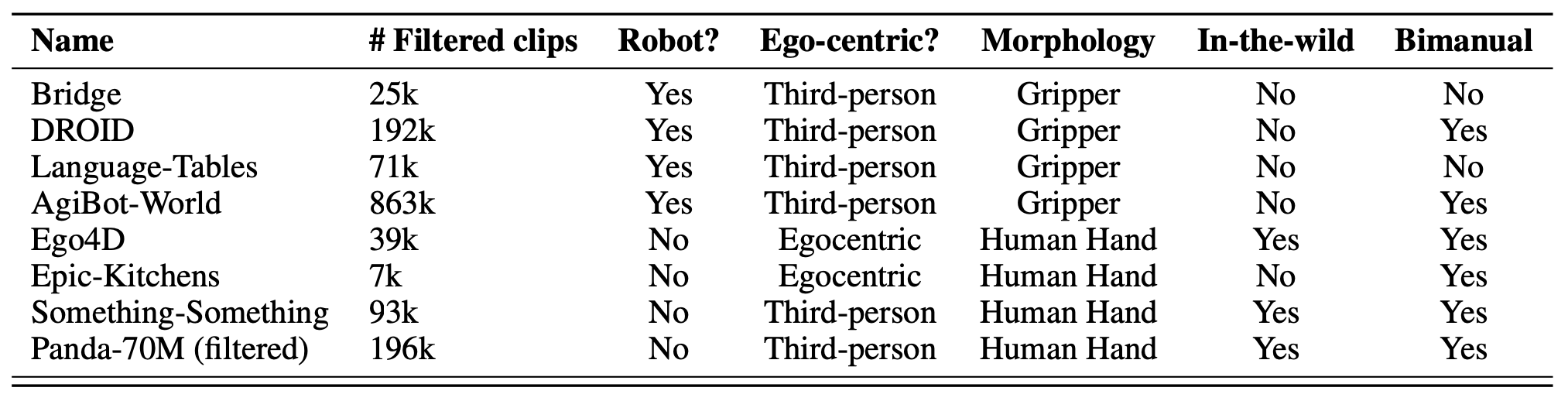
下图 (a) 展示每个数据集的示例,而图(b)展示历史-引导采样:本文的视频扩散采样策略,将有历史数据和无历史数据估计的分数进行线性组合。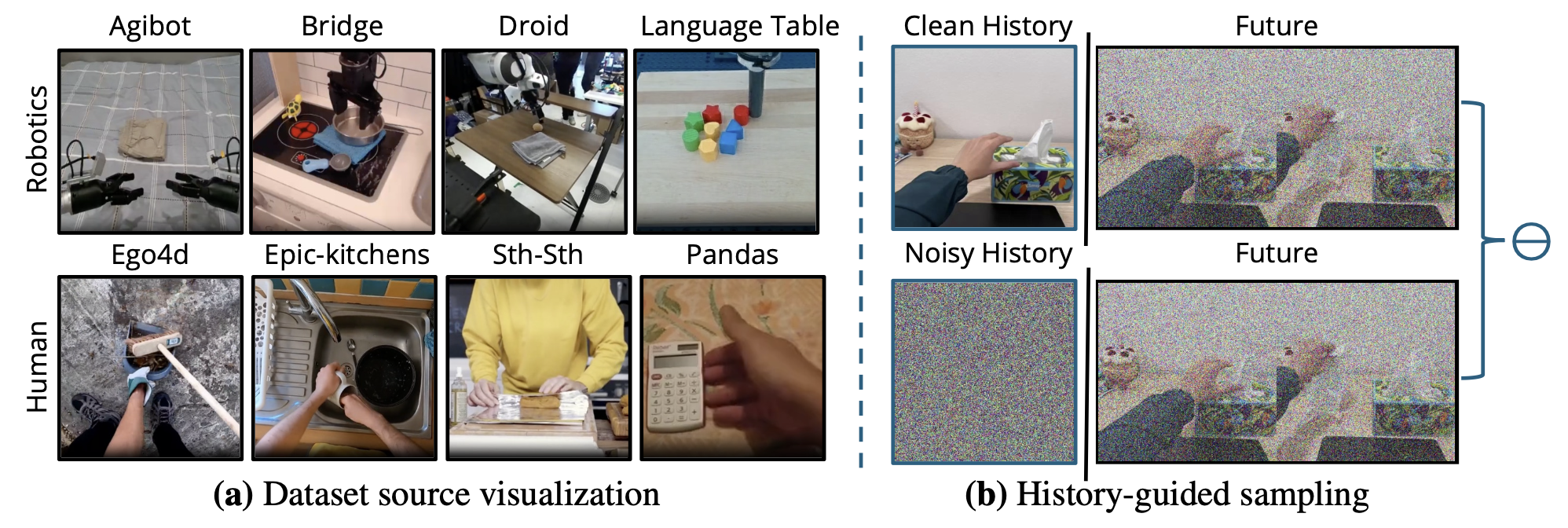
如图所示LVP-1M 数据集的构建流程如下:视频素材来自八个公共数据源,包括四个远程操控机器人数据集和四个以人为中心的活动数据集。采用三个处理阶段:(1)严格的质量和具身性过滤;(2)使用 Gemini 进行动作导向的字幕生成;(3)时间频率对齐以匹配人体运动速度。最终数据集包含 140 万个视频片段,并配有多样化的动作导向型文本字幕。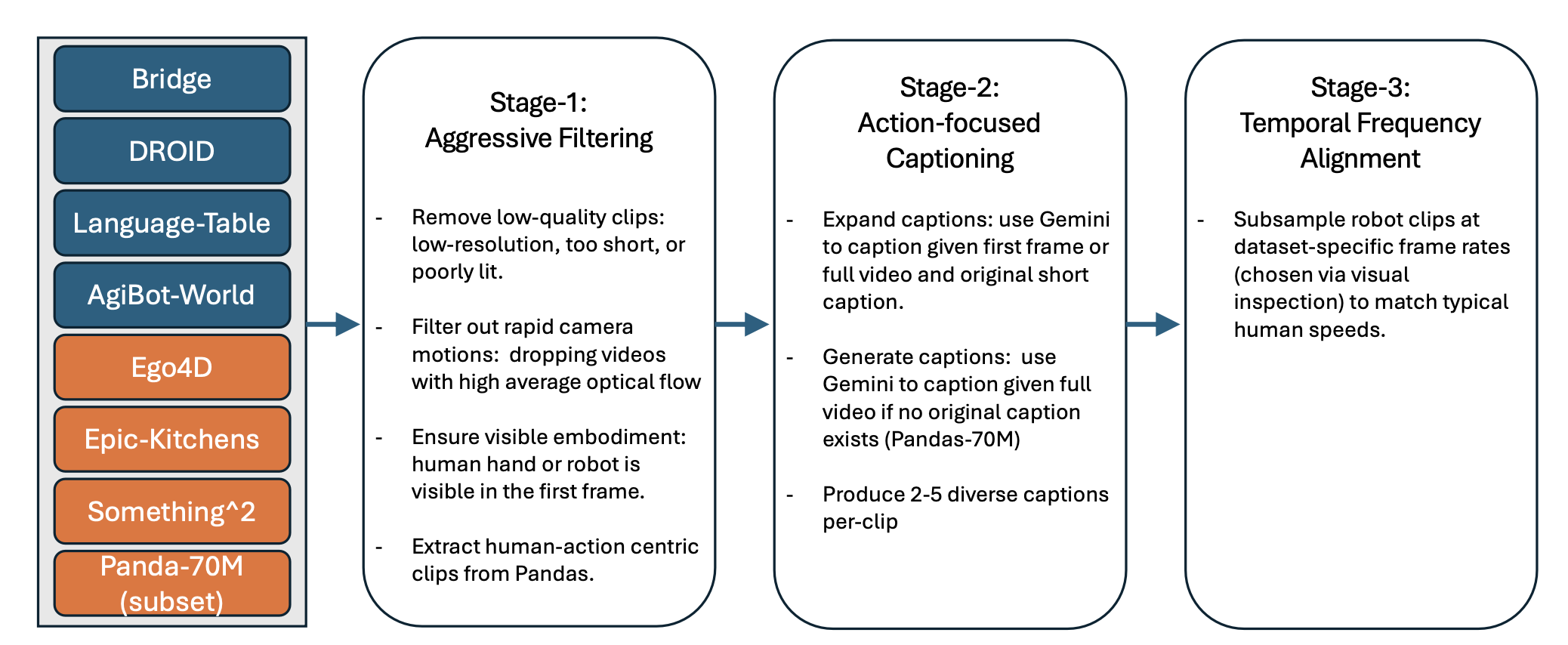
希望模型能够通过从网络爬虫的多样性中学习更好的指令跟踪能力,从以自我为中心的人类活动中学习更好的物体-手交互,以及从机器人数据中学习机器人形态,从而实现协同效应。
时间对齐。训练模型生成 3 秒、16 帧/秒的动作视频,因为这在计算成本和动作粒度之间取得了良好的平衡。然而,不同的数据集中原子动作的片段长度往往不一,从 1 秒到 1 分钟不等。机器人数据集中的动作速度远低于人类执行相同任务的速度,并且帧速率也常常差异巨大,有时甚至低至 5 帧/秒。
与其简单地调整帧速率或将视频片段裁剪到目标长度,将所有片段与人类速度对齐以避免时间不一致至关重要——如果人类通常在 3 秒内完成任务,会对机器人视频进行重采样(通过上采样或加速),使其在 3 秒内完成相同的任务,而不管其原始帧速率或远程操作速度如何。通过目视检查所有数据集来确定合适的子采样率来实现这一目标。如果标注包含多阶段任务,也会将长时程任务分解为原子动作。一些以自我为中心的人类活动数据集已经提供了动作片段标注,但通过在动作的起始点和结束点精确裁剪每个片段来进一步优化它们。正如在后续实验中发现的那样,这种对齐对于增强不同形态之间的迁移至关重要。
质量过滤。在时间对齐之后,首先丢弃低分辨率、过短、过长或光线不足的片段。然后,应用一些额外的过滤器,使模型专注于具身运动规划:
过滤快速的摄像机运动。许多以自我为中心的视频都存在快速的摄像机旋转,导致背景大幅偏移和训练损失过高。这些会分散模型学习有意义前景物体运动的注意力。为了缓解这个问题,用光流统计来过滤视频。
确保具身性可见。为避免歧义,要求第一帧中必须清晰可见主体(手或机器人夹爪)。用目标检测器自动过滤掉主体缺失的片段。
专家运动分析。许多机器人数据集包含次优轨迹,即机器人未能成功完成任务的轨迹。传统的机器人基础模型即使标注了“成功”,也不会过滤此类数据。然而,移除这些失败轨迹至关重要。
过滤 Pandas-70M 子集。执行三阶段的渐进式过滤,从庞大的 Pandas-70M 数据集中提取一个专注于人机交互的子集。首先,用白名单(例如,“抓取”、“拉”)和黑名单(例如,“卡通”、“电子游戏”)对字幕进行基于关键词的过滤。然后,用人体检测器,仅保留在第一帧、中间帧和最后一帧中可见一到四个人的片段。最后,使用 Gemini 进行另一轮过滤。对于每个视频片段,向 Gemini 提出四个问题,以验证该片段是否包含丰富的人类手部动作。
以动作为中心重新打字幕。为了增强模型对指令的理解能力,为每个视频生成多个高质量的字幕。传统上,视频基础模型倾向于使用极其详细的字幕来描述所有视觉元素。一些机器人数据集或以自我为中心的数据集仅包含极其简短的任务描述,例如“拾取”这样的单个词。对于这些视频(例如 DROID、Ego4D),向 Gemini Flash 提供指令和初始帧,以生成更详细、更多样化的字幕。对于缺少任务标注的视频,向 Gemini 提供整个视频片段,并要求其描述主要动作和涉及的物体。
包括重复字幕在内,总共获得 410 万个带字幕的视频片段。为 Gemini 提供简短的描述(例如,“拿起一个杯子”)可以显著提高字幕的准确率,因为 Gemini 对视频的感知能力虽然能够很好地描述静态场景内容,但在处理细微的动作动态方面却存在不足。确保每个视频片段都配有两到五个不同的字幕,其中一些简短,一些则非常详尽,以增强语言多样性并提高训练的鲁棒性。
基于视频规划的机器人动作
给定摄像机观测数据和任务描述,大型视频规划器可以生成人手或机器人夹爪执行任务的视频规划。
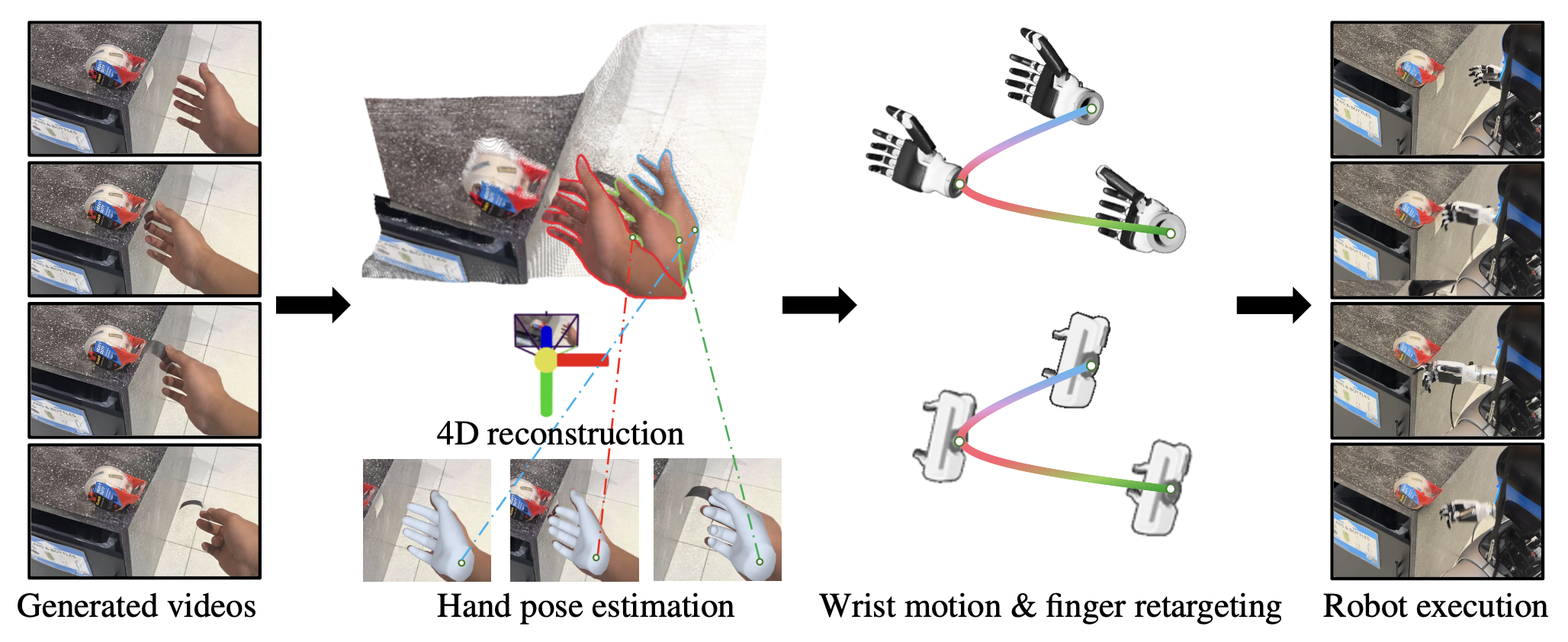
动作提取流程支持将生成的人手视频重定向到灵巧的机械手,甚至是简单的机器人夹爪。然而,本文主要关注一种迁移类型:将人手视频映射到灵巧的机器人手,因为大多数机器人实验都是使用带有灵巧机械手的人形机器人进行的。
人手运动估计。作为运动重定向的第一步,重建一个精确且时间对齐的手部姿态。为此,首先使用基于图像的手部重建模型 HaMeR [62] 独立预测每个视频帧中的手部姿态,然后使用动态场景重建模型 MegaSAM [50] 对预测的人手进行对齐和优化。
逐帧手部姿态估计。对于每个输入帧 I_t,HaMeR 预测 MANO [67] 手部顶点 V_t 和全局腕部方向 R_t (以相机坐标系为基准)。虽然 HaMeR 能够提供精确的手部形状和关节运动信息,但由于缺乏时间一致性保证,其逐帧平移估计值会随时间漂移。
4D 一致性对齐。接下来,对逐帧重建的人手进行平移对齐。具体来说,利用 4D 重建模型 MegaSAM [50],该模型输出逐帧深度图 D_t (u,v)、相机内参 K 和外参 {E_t}。在获得逐帧深度和相机姿态后,将手部像素反投影到 3D 空间,其中手部像素 (u_t, v_t) 是通过投影从 V_t 回归得到的 MANO 腕关节得到的。
保留 HaMeR 的方向 R_t,同时利用反投影的腕部点云来估计 T_t。这增强时间平滑性,解决单目尺度歧义,并显著提高腕部定位的鲁棒性。
时间补全与平滑。深度/像素无效的帧被标记为缺失值,并进行位置线性插值。四元数使用带符号翻转的 SLERP 算法来保持连续性。然后,对位置和四元数分量应用因果 Savitzky-Golay 滤波器(窗口大小为 w,阶数为 d),最后进行重新归一化,记为 Tˆ_R←W,t。
机器人手指运动重定向。给定前一模块估计的人手姿态,设计支持多指灵巧手和平行爪夹爪的重定向模块。
为了将机器人手指关节的运动目标映射到人手,使用 Dex-Retargeting [66]。该方法首先使用基于 RGB 的检测器提取人手关键点,然后通过求解 DexPilot 式的优化目标函数,将这些关键点映射到机器人关节构型。由此生成机器人手指关节角度 qR_t,从而实现对人类关节操作的精细模仿。
导出每帧的腕关节 ˆpR_W,t、ˆqR_W,t 和 Tˆ_R←W,t,以及机器人关节 {qR_t},并附带元数据(关节名称、自由度)。通过在仿真环境中渲染机器人手部运动来进行定性检查。
真实机器人执行。给定先前模块估计的人类手腕轨迹 {P_t} 和机器人手指关节轨迹 {q_t}(均以第一帧视频的相机坐标表示),目标是在物理机器人上执行相应的运动。首先将手腕姿态旋转到机器人控制坐标系中,然后利用得到的手腕平移和姿态来求解手臂的逆运动学 (IK)(使用 cuRobo[74]),同时手指轨迹直接驱动机器人手部关节的运动。
相机到机器人的对齐。令 C_0 表示第一台相机的坐标系,M 表示 MANO 手部坐标系,R 表示机器人控制坐标系。通过外部标定将恢复的手腕姿态从 C_0 对齐到 R。实际上,这简化为应用一个固定的旋转 M,该旋转统一 C_0 和 R 的轴。然后,组装腕部位姿 T_R←W,t 及其四元数参数化 qR_W,t用于下游控制。
机器人腕部和手指执行。利用以 R 表示的腕部轨迹,用 cuRobo[74] 求解逆运动学 (IK) 问题,并获得符合 {pR_W,t , RR_W,t } 的手臂关节轨迹。同时,手指关节序列 {q_t} 直接发送到机器人手部控制器。最后,机器人控制 API 执行这些同步的手臂和手部轨迹以完成任务。
如图所示从视频到动作的流程:给定一段描绘人手执行任务的视频,首先在三维空间中重建并跟踪该手部(第二列);然后,将重建的手部运动重新定向到灵巧的机械手或机械臂(第三列);最后,将重定向的轨迹转换到机器人的控制坐标系中,并在现实世界中执行(最右列)。
传统上,机器人基础模型的评估任务与训练集中的任务类似——例如,在学习大量的拾取和放置轨迹后,在随机位置拾取略有不同的物体;或者在学习大量的T恤折叠数据后,学习折叠T恤[12, 43, 83]。这些称为物体级和配置级泛化。它们是迈向零样本模型的激动人心的一步,但任务描述中的“动词”仅限于“拾取”或“折叠”等小范围的动词。
本文感兴趣的是一种更强的泛化类型——零样本任务级泛化:评估模型是否能够执行从未遇到过的截然不同任务。
第三方选择任务
真正的任务级泛化能力应该允许任何人在任何环境下提出任务,而无需事先了解模型的能力。为此,通过众包方式收集第三方参与者的测试数据,邀请他们提出日常生活中常见的操作任务。每位参与者需完成以下步骤:(1)提出一个人类只需3-5秒即可完成的简短操作任务;(2)拍摄一张包含手和目标物体的场景照片;(3)撰写一份简短的任务描述;(4)保持任务的多样性和挑战性,并在任务和场景的选择上发挥创意。
经过这一步骤,收集到大约200个任务,其中包括一些分布范围极窄的任务,例如“在加油站”,以及一些分布范围极窄但难度较高的任务,例如“冲马桶”或“撕胶带”。然而,一些志愿者仍然提交低质量的数据,例如模糊的照片或枯燥乏味的任务。为了确保质量,另一组第三方标注员筛选掉不符合指令或与现有机器人数据集中已涵盖的基本桌面抓取和推送任务相似的样本。筛选后,保留100个高质量任务,每个任务包含一张观察图像和一段指令文本。随后,使用Gemini软件对指令文本进行进一步完善,生成更详细的任务描述。
设计一个四级评估指标,用于衡量指令执行、运动规划可行性和物理真实性。
(1) 正确接触:手部与指定物体在正确位置接触。失败包括接触错误的物体或未接触。
(2) 正确结束状态:最后一帧达到指令目标(忽略运动质量)。
(3) 任务完成:正确接触和正确结束状态,且运动流畅自然(允许存在轻微的物理瑕疵)。
(4) 完美任务完成:任务完成时,物理效果完美无瑕,且无任何明显的瑕疵。最高级别包含所有先前的标准,并额外评估物理一致性和视觉保真度。
级别 1-2 测试理解能力和指令执行能力——模型是否正确理解指令并与正确的物体进行交互。级别 3 评估模型是否能够生成完整且运动流畅的视频规划。级别 4 进一步衡量物理真实性和整体视觉保真度。
真实世界机器人操作评估
在真实的机器人平台上评估从视频生成到动作重定向和执行的完整流程。
任务。在两种不同的机器人形态上进行实验:一种是配备平行爪夹爪的 Franka Emika 机械臂,另一种是配备 Inspire 灵巧手的 G1 机械臂。每个平台都针对不同的操作能力进行了测试。对于灵巧手,进一步评估一些具有挑战性的新任务,例如开门、开箱和舀咖啡豆。
• 配备平行爪夹爪的 Franka 机械臂。该任务组侧重于可以用简单的双指抓取完成的操作任务,例如物体拾取和放置、积木堆叠和瓶子移动。这些任务强调在有限的驱动力下进行抓取检测和稳健的轨迹执行。 A组作为标准基准,而C组主要关注分布外任务集,这些任务集包含训练视频数据集中未见过的场景。
• 具有灵巧手的类人机器人:该任务集旨在实现需要多自由度的精细灵巧操作。任务包括手内旋转、工具使用(例如,笔书写或螺丝刀插入)以及不规则物体的精确放置。这些任务旨在检验方法将复杂的人类手部关节动作迁移到机器人手上的能力。
基线模型:将方法与几个最先进的视觉-语言-动作基线模型进行比较:
• π0 [10]:通过加载已发布的检查点并按照标准使用协议直接测试π0模型在基准任务上的泛化能力来评估该模型。
• OpenVLA [43]:用 OpenVLA 及其已发布的检查点作为基准,评估其在任务集上的性能,而无需进行额外的微调。
注:π0 和 OpenVLA 与多指灵巧手设置不兼容,因此仅在平行夹爪任务上进行测试。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 40
40 0
0- 0



 已为社区贡献209条内容
已为社区贡献209条内容

所有评论(0)