πRL:基于流的VLA模型在线RL微调
26年1月来自清华、北大、中科院自动化所、CMU、无问芯穹和中关村学院的论文“πRL: Online RL Fine-tuning for Flow-based Vision-Language-Action Models”。视觉-语言-动作 (VLA) 模型使机器人能够理解并执行来自多模态输入的复杂任务。尽管最近的研究探索使用强化学习 (RL) 来自动化大规模监督微调 (SFT) 中繁琐的数据收集
26年1月来自清华、北大、中科院自动化所、CMU、无问芯穹和中关村学院的论文“πRL: Online RL Fine-tuning for Flow-based Vision-Language-Action Models”。
视觉-语言-动作 (VLA) 模型使机器人能够理解并执行来自多模态输入的复杂任务。尽管最近的研究探索使用强化学习 (RL) 来自动化大规模监督微调 (SFT) 中繁琐的数据收集过程,但由于流匹配产生的难以处理的动作对数似然,将 RL 应用于大规模基于流 VLA(例如 π0、π0.5)仍然具有挑战性。 πRL 包含两种技术方法:(1) 流噪声方法将去噪过程建模为一个离散时间马尔可夫决策过程 (MDP),并带有一个可学习的噪声网络以精确计算对数似然。(2) 流随机微分方程 (Flow-SDE) 将去噪与智体-环境交互相结合,构建一个两层 MDP,并采用常微分方程到随机微分方程的转换来实现高效的 RL 探索。
在线强化学习微调VLA模型
近年来,研究越来越关注如何利用在线强化学习来提升VLA模型的性能和泛化能力。例如,基于OpenVLA-OFT和GRPO的SimpleVLA-RL(Li,2025a)证明强化学习可以改善数据稀缺情况下VLA模型的长期规划。RL4VLA(Liu,2025a)使用基于阶段的稀疏奖励,对PPO、GRPO和直接偏好优化(DPO)(Rafailov,2023)进行了实证评估。RLinf-VLA(Yu,2025;Zang,2025)为VLA模型的可扩展强化学习训练提供一个统一高效的框架。这些工作证明强化学习微调VLA模型的有效性。
流模型的强化学习微调
将强化学习与流模型相结合是超越模仿学习局限性的一种很有前景的方法。为此,Flow-GRPO(Liu,2025b)将确定性常微分方程 (ODE) 转换为等价的随机微分方程 (SDE),从而实现随机性探索。在此基础上,后续的 Mix-GRPO(Li,2025b)和 TempFlow-GRPO(He,2025)等方法通过混合 ODE-SDE 展开进一步加速训练。ReinFlow(Zhang,2025)将可学习噪声注入流路径,并将其转换为具有易于处理似然函数的离散时间马尔可夫过程,从而实现稳定的策略梯度更新。流策略优化 (FPO)(McAllister,2025)将策略优化重新定义为最大化条件流匹配损失的优势加权比。
πRL框架
πRL框架旨在利用在线强化学习算法对基于流的VLA进行微调。为了解决流匹配中难以处理的对数似然估计问题,提出两种解决方案。Flow-Noise方案将可学习的噪声网络集成到去噪过程中,并将该阶段建模为离散时间马尔可夫决策过程(MDP),以实现精确的对数似然估计。Flow-SDE方案将常微分方程(ODE)去噪过程转换为随机微分方程(SDE),同时保持探索过程中等价的边缘分布,并构建一个两层MDP,将去噪过程与策略-环境交互耦合起来。在构建MDP并计算出精确的对数似然后,πRL通过近端策略优化(PPO)(Schulman,2017)进行进一步优化。如图所示: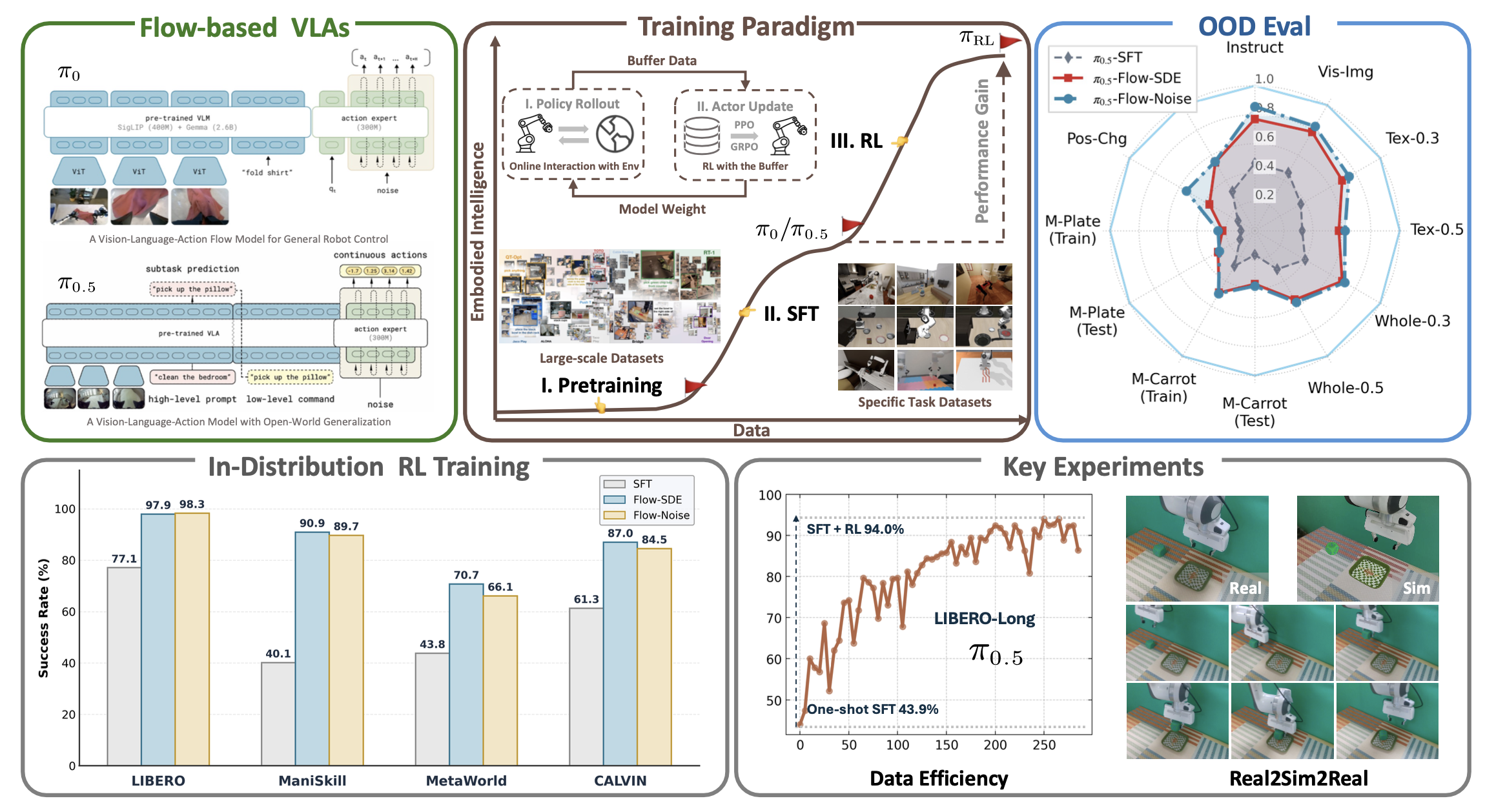
问题描述
将任务建模为一个马尔可夫决策过程(MDP),其由一个元组 M = (S, A, P_0, P_ENV, R_ENV, γ) 定义。状态 s_t 定义为机器人观测值 o_t,P_0 表示初始状态分布。给定状态,流策略预测一个动作 a_t ∼ π(· | s_t) ,从而产生状态转移 s_t+1 ∼ P_ENV(· | s_t, a_t) 和奖励 R_ENV(s_t, a_t)。目标是学习一个策略 π_θ,使其在 T + 1 的时间范围内最大化预期的 γ 折扣回报。
利用策略梯度代理surrogate(Williams,1992),可以根据采样轨迹近似计算收益期望的梯度,其中优势函数 A(s_t, a_t) = Q(s_t, a_t) − V (s_t) 衡量动作值 Q(s_t,a_t) 相对于状态值 V (s_t) 的相对优势,为策略更新提供低方差信号。
基于流的视觉-语言-动作模型
本文设计一种基于流的视觉-语言-动作模型 π_θ,用于将包含 RGB 图像、语言token和机器人本体感觉的观测数据映射到 H 个未来动作序列 A_t = [a_t,0 , …, a_t,H −1 ],其表达式为 p(A_t |o_t )。在该模型中,视觉语言模型 (VLM) 从视觉和语言输入中提取特征,而流匹配专家则负责生成动作。具体而言,该模型学习一个条件向量场 v_θ,该向量场将标准高斯噪声分布转换为目标动作 A_t。这是通过最小化条件流匹配 (CFM) 损失来实现的,该损失将预测向量场 v_θ 与真实向量场 u 对齐。这里,条件概率路径 q(Aτ_t |A_t) 在流匹配中,由动作 A_t、随机噪声 ε ∼ N (0, 1) 和连续时间 τ ∈ [0, 1] 生成带噪声的动作 Aτ_t = τA_t + (1 − τ)ε。对于这条特定路径,对应的真实向量场定义为 u(Aτ_t | A_t) = A_t − ε。
在推理过程中,首先对噪声向量 A0_t ∼ N (0, I ) 进行采样,然后基于前向欧拉方法,通过对学习的向量场 v_θ 进行固定步数的积分,进一步迭代地细化该噪声向量,从而生成动作序列:Aτ+δ_t = Aτ_t + v_θ(Aτ_t, o)·δ。
现有的 VLA-RL 方法利用诸如 OpenVLA(用于离散动作)和 OpenVLA-OFT(用于连续动作)等基础模型。为了计算动作的对数似然 log π_θ (a_t |s_t ),离散模型(Liu,2025a)对输出 logits 应用 softmax 函数,而连续模型(Li,2025a)则将动作视为高斯分布,并使用预测头来估计方差。对于基于流的 VLA,直接计算精确似然(Hutchinson,1989)在去噪步骤较少的情况下精度不高。此外,其 ODE 采样过程的确定性限制探索性,使得其在强化学习中的实现并非易事。为此,提出 流噪声(Flow-Noise) 和 流- SDE(Flow-SDE) 这两种技术方法,使基于流的 VLA 能够应用于强化学习。
流-噪声算法
受 Reinflow (Zhang et al., 2025) 的启发,将可学习噪声网络融入到流匹配去噪过程中,并在标准单层 MDP 框架内求解该问题。通过将去噪阶段建模为离散 MDP,可以直接计算去噪序列的对数似然,从而实现通过强化学习 (RL) 进行等效策略优化。
随机注入
在流-噪声算法中,用神经网络对噪声调度进行参数化,允许在训练过程中动态学习注入噪声的幅度,从而获得更大的灵活性,如图所示。关注单个环境时间步 t 内的生成过程。为简化符号,省略时间下标 t,例如,记为 Aτ,并将预测速度 v_θ (Aτ , o) 表示为 vτ。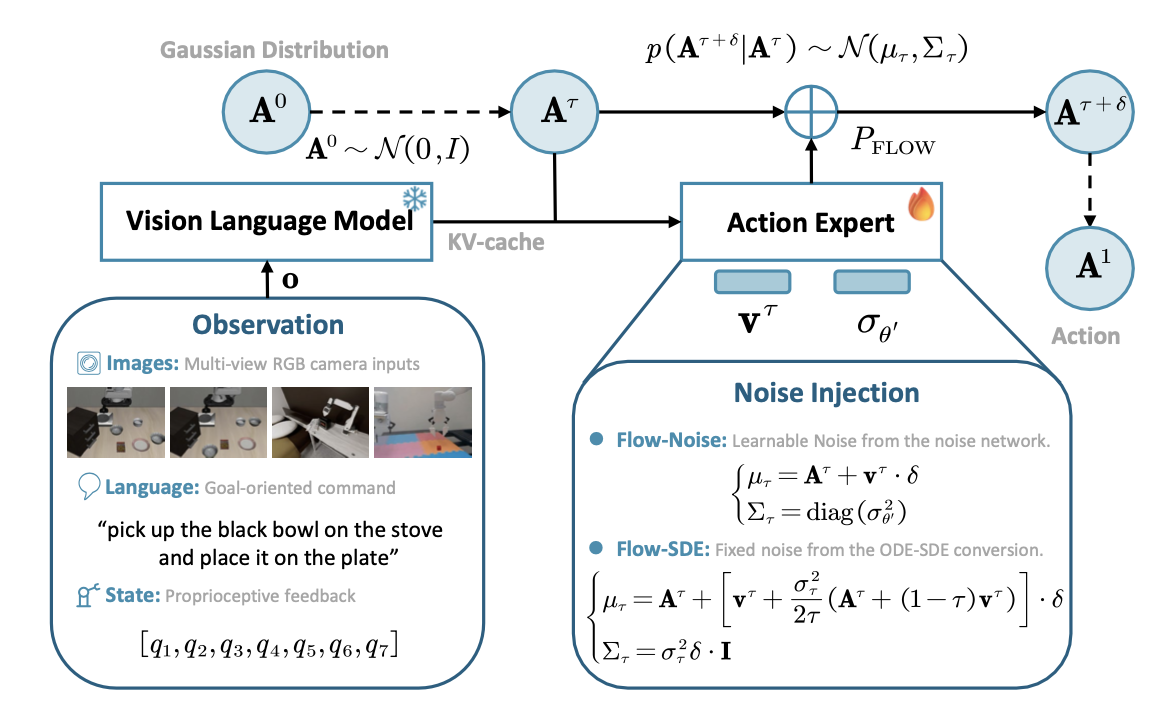
去噪过程中的阶跃过渡被建模为高斯分布 p(Aτ+δ |Aτ ) ∼ N (μ_τ , Σ_τ ),其中均值由原始 ODE 的前向欧拉更新确定,方差由可学习噪声网络 θ′ 控制。这里,σ_θ′(·) 是从噪声注入网络学习的标准差,以动作 Aτ 和观测值 o 为条件。噪声网络与速度网络联合训练,但在微调后被舍弃,从而留下一个确定性的推理策略。
对数似然估计
将策略梯度方法应用于基于流 VLA 的主要挑战,在于最终执行动作的对数似然难以处理。在 Flow-Noise 中,通过将整个去噪过程的联合对数似然的梯度代入策略优化目标来解决这个问题,其理论基础源于 Reinflow(Zhang,2025)。
动作生成的推理过程被离散化为 K 个均匀步骤,从而定义一个时间点序列 {τ_0, τ_1, . . . , τ_K}。步长间隔定义为 δ = 1/K,第 k 个点的离散时间步长为 τ_k = k·δ,从 τ_0 = 0 开始,到 τ_K = 1 结束。给定观测值 o,整个去噪序列 A = (A0 , . . . , A1 ) 的精确且易于处理的对数概率如图所示。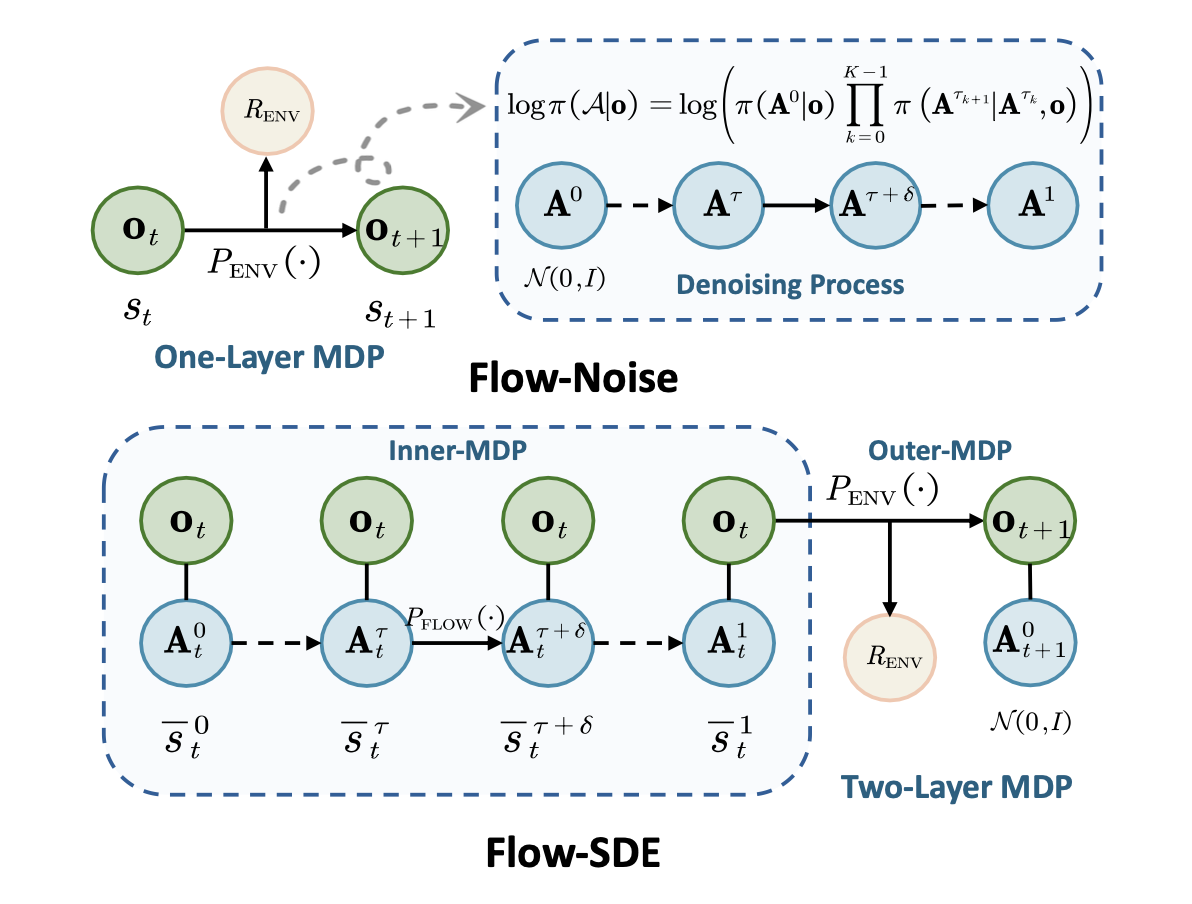
在此基础上,可以在标准的 MDP 框架内处理基于流的策略优化。
流-SDE算法
受 Flow-GRPO (Liu et al., 2025b) 的启发,通过将去噪过程从常微分方程 (ODE) 转换为随机微分方程 (SDE) 来增强随机探索能力。进一步构建一个双层马尔可夫决策过程 (MDP),将去噪过程与策略-环境交互耦合起来,遵循 DPPO (Ren et al., 2024) 的思路,同时利用混合 ODE-SDE 采样技术来加速训练过程。
随机性注入
在 Flow-SDE 中,将确定性 ODE 转换为等价的 SDE,以保持生成动作的边缘概率密度。流匹配(特别是修正流 (Liu et al., 2022))的确定性 ODE 采样轨迹由前向欧拉方法描述:
dAτ =vτdτ
基于概率流常微分方程 (ODE) 和随机微分方程 (SDE) 之间的联系(Song,2020),可以将这个确定性 ODE 转换为等价的 SDE,其中漂移项引入了噪声。
如 Flow-GRPO 中所述,得分函数和速度场之间存在关键联系,关系式为 ∇ log q_τ (Aτ) = − Aτ/τ − (1−τ) vτ /τ。用速度场替换得分函数,并将噪声调度 g(τ) 设置为 σ_τ = a( τ/(1−τ) )0.5(其中 a 控制噪声水平),推导出流匹配采样器的最终 SDE 公式。
离散化该 SDE 表明,转移概率 p(Aτ+δ | Aτ) ∼ N(μ_τ, Σ_τ) 服从各向同性高斯分布。
MDP 建模
在 Flow-SDE 中,将流匹配的去噪过程与环境交互耦合起来。具体来说,将去噪过程中定义的内部 MDP 嵌入到具有环境 M_ENV 的高层外循环 MDP 中,从而构建双层 MDP,其分量是根据环境时间 t 和去噪时间 τ 定义的。
状态 s̄τ_t = (o_t, Aτ_t) 是观测值 o_t 和动作状态 Aτ_t 的元组。
动作 āτ_t 定义为内循环中下一个采样去噪后的动作,也是外循环中执行的动作。
转换 P-(s̄τ_t′ |s̄τ_t, āτ_t) 定义了状态的演化方式。
对于 τ < 1,内循环转换 P_FLOW(·) 发生在不同的去噪后动作状态之间,其中观测值 o_t 保持不变,下一个动作状态由 āτ_t = Aτ+δ_t 设定。
对于 τ = 1,最终动作 a ̄τ_t = A1_t 与外环环境相互作用,根据环境动力学 P_ENV(·) 产生新的观测值 o_t+1。同时,动作状态从标准正态分布 A0_t+1 ∼N(0, I) 重置。
奖励 R(s̄τ_t, āτ_t) 仅在去噪过程完成且与环境交互完成后授予:
在双层 MDP 框架内,估计动作对数似然 log π(a_t | s_t) 的问题转化为估计 log π(āτ_t | s̄τ_t) 的问题,由于转移具有高斯特性,因此该估计值易于计算。
混合 ODE-SDE 采样
双层 MDP 模型显著扩展时间范围,增加训练难度和计算成本。为了缓解这个问题,采用一种混合 ODE-SDE展开策略(Li,2025b;He,2025)。在每个步骤 t,随机采样一个去噪时间 τ_t 用于随机 SDE 探索,同时将剩余的去噪步骤视为确定性 ODE 更新。具体来说,策略作用于状态 s̄τ_tt = (o_t, Aτ_tt);随后,环境包装器执行剩余的 ODE 步骤和环境转换,最终在新的采样时间 τ_t+1 得到下一个状态 s̄τ_t+1_t+1 = (o_t+1, Aτ_t+1_t+1)。这种方法有效地缩短 MDP 的时间范围,同时保持与原始双层框架的理论一致性。
策略优化
算法
给定已构建的流策略 MDP,目标是学习策略 π_θ 的最优参数 θ∗,以最大化预期折扣回报 J(π_θ)。为此,应用广泛采用的策略梯度算法 PPO 来优化该策略。
π-系列模型(Black,2024;Intelligence,2025)采用基于块的方法生成动作。具体而言,该策略针对每个观测值输出一个包含 H 个未来动作的完整序列 A_t = [a_t,0, …, a_t,H −1]。在这种方法中,将整个序列视为一个宏步骤,并将其对应的奖励 R_t = sum(r_t,j) 定义为每一步奖励 r_t,j 的总和, 在 RLinf-VLA 中,称为块-级公式(Zang,2025)。
为了有效地指导策略更新,PPO 采用广义优势估计 (GAE)(Schulman,2015)来计算优势的低方差估计。其中V(·) 是从判别器网络导出的状态值函数,γ 是折扣因子,λ 是平衡优势估计中偏差和方差之间权衡的参数。
PPO 将策略更新限制在一个较小的置信域内,以防止出现大的、不稳定的更新。其目标函数为 J(π_θ),其中由超参数 ε 控制的裁剪函数将比值 ρ_t(θ) 限制在区间 [1 − ε, 1 + ε] 内,以确保训练稳定性。其中ρ_t(θ) 是更新策略与旧策略之间的概率比。
评价器设计
借鉴 VLA-PPO 的工作(Zang,2025;Liu,2025a),采用如图所示的共享 Actor-Critic 架构进行内存高效的值预测。然而,两种基于流的 VLA 对本体感受状态的处理方式不同:在 π0 中,状态被输入到动作专家模型中;而在 π0.5 中,状态与提示嵌入融合到 VLM 中。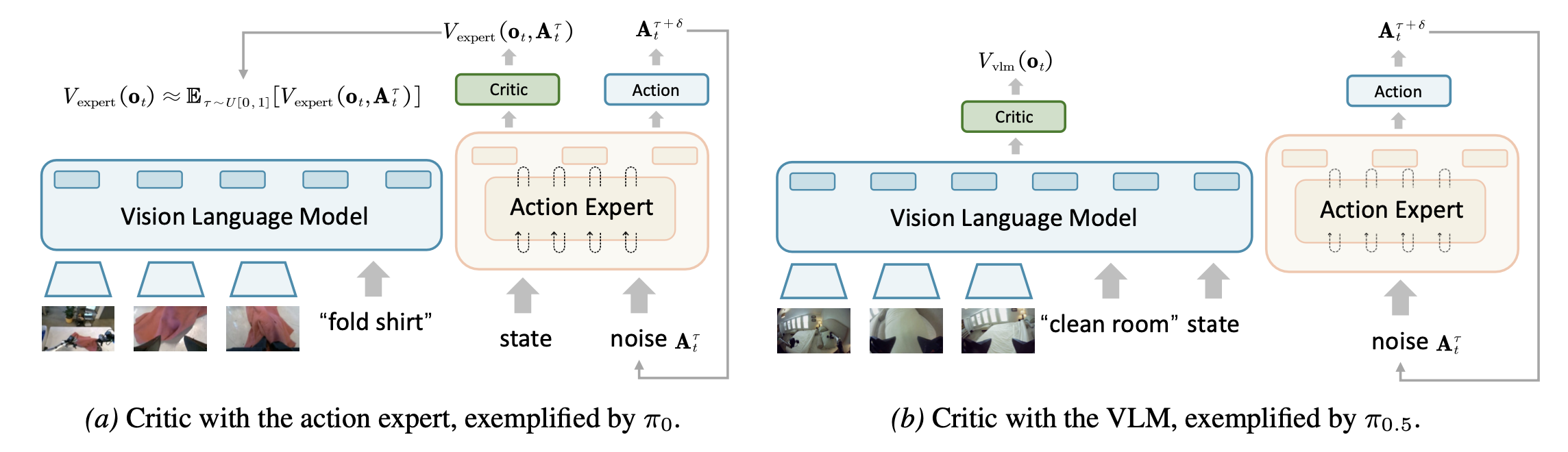
为此,对于 π0.5 变体,将评价器网络直接连接到 VLM 的输出,从而提供基于整合的图像、语言和状态输入的值估计 V_vlm(o_t)。相反,对于 π0 变体,由于耦合的输入结构,实现值预测并非易事,因为动作专家需要同时接收带噪声的动作 Aτ_t 和状态。为此,通过对整个去噪轨迹上的值估计进行平均来近似 V_expert(o_t),
πRL 基准测试。在四个广泛应用的机器人操作基准测试集上进行实验:LIBERO (Liu et al., 2023)、ManiSkill (Tao et al., 2024)、MetaWorld (McLean et al., 2025) 和 CALVIN (Mees et al., 2022)。
基于流的VLA。主要实验基于 π0 和 π0.5 模型。此外,对 GR00T 进行实验,验证算法可以应用于其他基于流的VLA模型。
GR00T N1.5。基于 GR00T N1.5 模型(Bjorck,2025)进行额外的实验。该模型是一个专为通用人形机器人推理和操作而设计的基础模型。其架构集成针对空间定位和物理推理优化的 Eagle 2.5 VLM(Chen,2025)以及用于动作去噪的扩散transformer头部(Peebles & Xie,2023)。它通过专用头实现多具身兼容性,支持诸如带有灵巧手或夹爪的人形机器人以及单臂机械臂等配置。
关于评论器的实现,通过将评论器网络直接与动作头部集成,估计整个去噪轨迹上的值函数。完整的框架如图所示。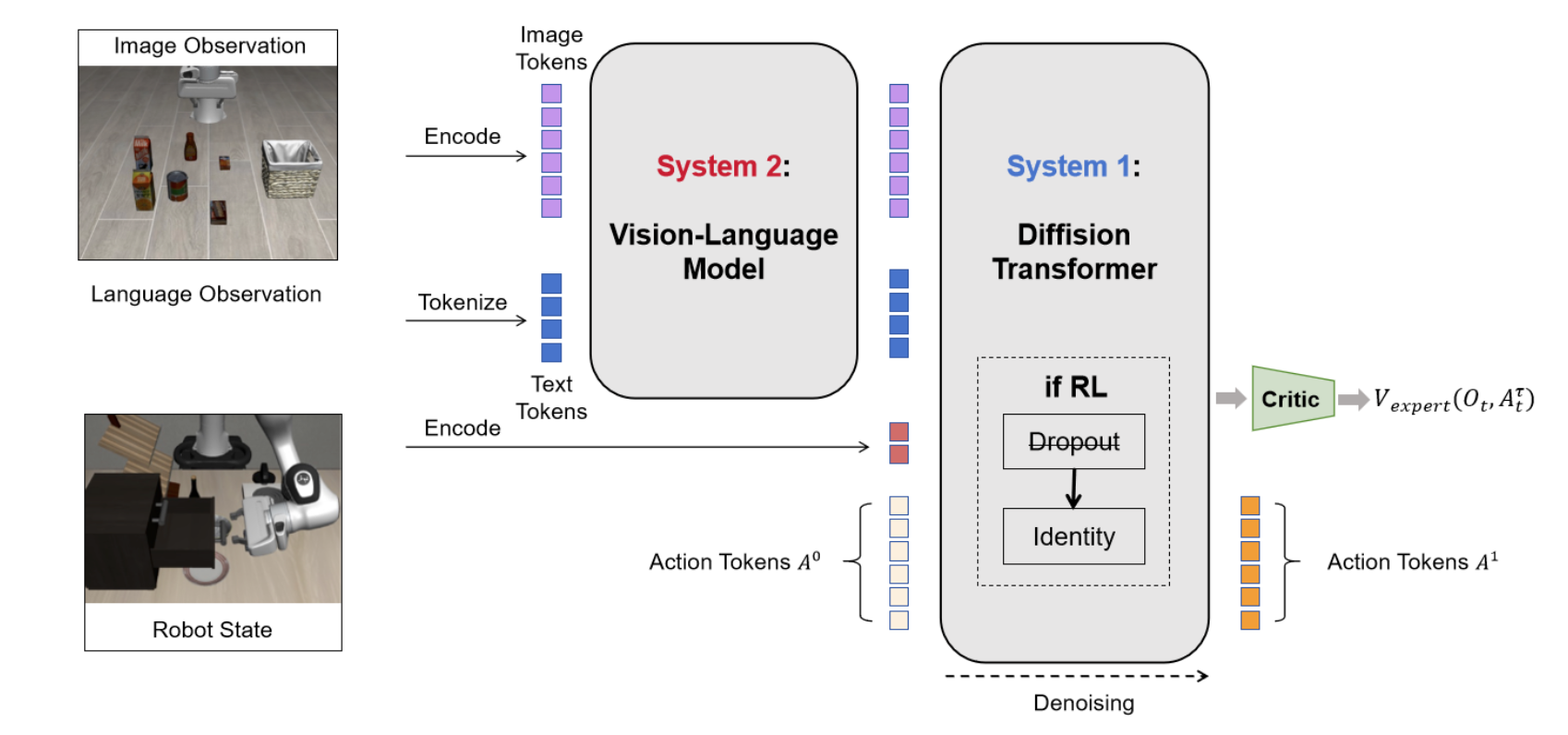
GR00T基准测试。在 LIBERO 的四个操作任务套件中评估 GR00T 模型的性能:空间、物体、目标和长任务。
实现细节。与 π0 实现类似,首先在专家演示上进行 SFT 训练。在 SFT 阶段,按照官方设置对整个模型进行微调。在随后的 RL 阶段,仅对动作专家模型进行微调,同时保持视觉-语言模型参数不变。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 30
30 0
0- 0



 已为社区贡献209条内容
已为社区贡献209条内容

所有评论(0)