毕业设计:基于深度学习的协同过滤推荐系统 人工智能
毕业设计:基于深度学习的协同过滤推荐系统通过结合深度学习和协同过滤技术,我们利用大规模用户行为数据和物品特征信息,构建了一个端到端的神经网络模型。该模型能够自动学习用户和物品的表示,捕捉潜在的兴趣和语义关联,并提供个性化的推荐服务。对于计算机专业、软件工程专业、人工智能专业、大数据专业的毕业生而言,提供了一个具有挑战性和创新性的研究课题。无论您对深度学习技术保持浓厚兴趣,还是希望探索机器学习、算法
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的协同过滤推荐系统
设计思路
一、课题背景与意义
推荐系统是互联网应用中重要的一环,为用户提供个性化的推荐服务,帮助用户发现感兴趣的内容。然而,传统的协同过滤推荐系统存在冷启动、数据稀疏性等问题,限制了其准确性和推荐效果。基于深度学习的协同过滤推荐系统通过利用深度神经网络的强大模型表达能力,能够挖掘更丰富、更复杂的用户兴趣和物品语义信息,提高推荐的准确性和个性化程度。因此,研究和设计基于深度学习的协同过滤推荐系统具有重要的理论意义和实际应用价值
二、算法理论原理
2.1 基于近邻的协同过滤算法
协同过滤算法是推荐系统中最重要的思想之一。基于近邻的协同过滤算法是目前最广泛应用的方法之一,它通过寻找与目标用户或物品兴趣相似的其他用户或物品,来进行推荐。其中,基于用户的协同过滤算法通过找到与目标用户兴趣相似的其他用户,利用他们的评价或行为数据预测目标用户对未评价或未购买的物品的兴趣程度,并进行推荐。基于用户的协同过滤算法需要依赖用户的历史行为数据。通过比对不同用户的消费记录,找到具有相似消费行为的用户,可以推断它们具有较高的相似性。然后,根据这种相似性,将一个用户未购买但相似用户购买过的物品推荐给该用户。
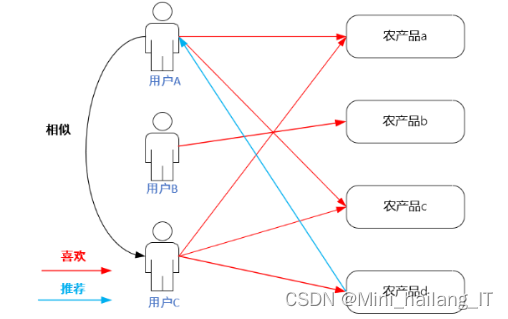
基于物品的协同过滤算法在思想上与基于用户的协同过滤算法相似,但其重点在于计算物品之间的相似度。这种算法可以解决物品冷启动问题,特别适用于推广销量较低或曝光较少的农产品。由于农产品通常具有相对稳定的属性和特征,物品的相似性更容易捕捉。基于物品的协同过滤算法能够提供多样化的推荐结果,让用户接触到更广泛的农产品品种并提供更多选择。
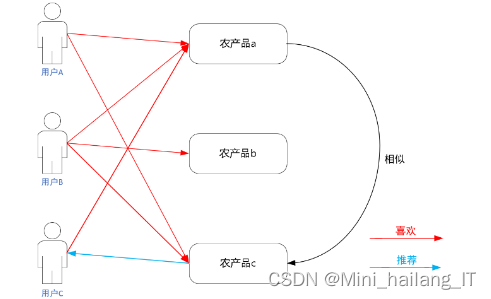
2.2 基于模型的协同过滤算法
基于模型的协同过滤算法通过构建和学习推荐模型来进行推荐。与基于近邻的协同过滤算法不同,基于模型的方法不直接依赖于用户或物品之间的相似性,而是通过对用户行为和物品特征进行建模,利用机器学习、深度学习等技术来预测用户对物品的喜好。这种方法可以从大量的用户和物品数据中学习用户的喜好信息,并将这些信息作为生成个性化推荐的依据。
基于模型的协同过滤算法可以利用不同的技术,如联规则算法和聚类算法,来分析用户的评分记录和建立用户和物品之间的关系模型。此外,它也可以应用于社交网络中的推荐,通过利用用户的关系数据,如好友关系,来生成用户的推荐内容,从而帮助用户扩大社交圈。
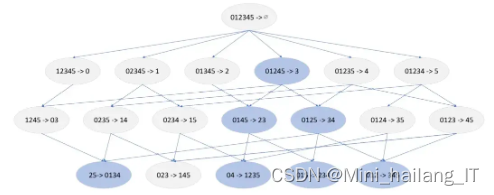
改进后的算法是一种混合推荐算法,通过融合Apriori算法和Item-CF算法的特点,解决协同过滤算法中的数据稀疏性问题。该算法首先利用Apriori算法挖掘频繁项集,补充用户行为信息,然后使用Item-CF算法计算物品相似度,填充用户-物品评分矩阵,以提升推荐效果。通过这种融合的方式,APICF算法能够更好地适应用户的实际需求,并缓解由于数据稀疏性导致的推荐预测问题。
三、检测的实现
3.1 实验环境
实验环境使用Windows操作系统,并利用Python作为主要的编程语言进行算法和模型的实现。使用PyTorch作为深度学习框架,构建和训练神经网络模型。借助Pandas等库,完成数据的加载、处理和转换。这样的实验环境提供了一个方便和高效的平台,用于开发和测试算法系统。
3.2 模型训练
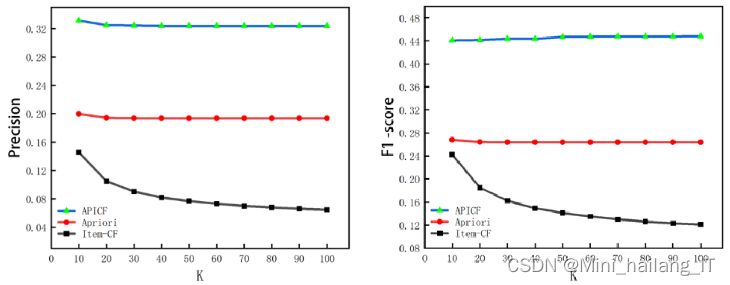
在本次实验中,为了评估推荐算法的效果,主要使用准确率、召回率和F1值这三个指标。这些指标是在TopN推荐任务中常用的评估指标。准确率衡量了推荐列表中与用户实际喜好相符的比例,召回率评估了算法能够找到多少用户喜欢的物品,而F1值综合考虑了准确率和召回率的平衡性。通过对这三个指标的分析,可以更全面地了解算法的性能和推荐效果。

实验通过改变最近邻个数(K)来比较Item-CF算法、Apriori算法和混合推荐算法(APICF)在推荐效果上的差异。初始时,最近邻个数K为10,并每次递增10,直到测试到K值为100为止,得到了10个评测指标数据。通过对比这三种算法的推荐效果,可以得出结论。这样的实验设计可以提供关于不同K值下算法性能的详细比较,帮助评估算法在不同情况下的推荐准确率、召回率和F1值等指标。
相关代码示例:
# 定义神经协同过滤模型
class NeuralCollaborativeFiltering(nn.Module):
def __init__(self, num_users, num_items, embedding_dim):
super(NeuralCollaborativeFiltering, self).__init__()
self.user_embedding = nn.Embedding(num_users, embedding_dim)
self.item_embedding = nn.Embedding(num_items, embedding_dim)
self.user_bias = nn.Embedding(num_users, 1)
self.item_bias = nn.Embedding(num_items, 1)
def forward(self, user_ids, item_ids):
user_embeddings = self.user_embedding(user_ids)
item_embeddings = self.item_embedding(item_ids)
user_bias = self.user_bias(user_ids).squeeze(1)
item_bias = self.item_bias(item_ids).squeeze(1)
dot_product = torch.sum(user_embeddings * item_embeddings, dim=1)
predictions = dot_product + user_bias + item_bias
return predictions
# 实例化模型,定义损失函数和优化器
model = NeuralCollaborativeFiltering(U, I, embedding_dim=8)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
def train(model, train_loader, criterion, optimizer):
model.train()
for user_ids, item_ids in train_loader:
predictions = model(user_ids, item_ids)
target = ratings[user_ids, item_ids]
loss = criterion(predictions, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 评估模型
def test(model, test_loader):
model.eval()
with torch.no_grad():
correct = 0
total = 0
for user_ids, item_ids in test_loader:
predictions = model(user_ids, item_ids)
target = ratings[user_ids, item_ids]
predicted_rating = torch.round(predictions)
total += target.size(0)实现效果图样例:




创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!
最后

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 29
29 0
0- 0



 已为社区贡献102条内容
已为社区贡献102条内容

所有评论(0)