机器学习(周志华)西瓜书 课后习题4.3 信息熵决策树算法——python实现(包括树的可视化)
·
机器学习(周志华)西瓜书 课后习题4.3 信息熵决策树算法——python实现(包括树的可视化)
算法原理
1.信息熵

2.信息增益

我们所以要做的就是不断地从当前剩余的属性当中选取最佳属性对样本集进行划分。
算法的伪代码

数据集

Python实现
由于基于信息增益的决策树算法一般适用于离散属性,若要处理连续属性则必须将其按照一定规则转为离散属性。所以在接下来的代码实现当中并未处理连续属性
1. 信息熵的计算
def entropy(D):
count=D.shape[0]
Ent=0.0
temp=D['好瓜'].value_counts() #获取剩余的类别数量
for i in temp:
Ent-=i/count*np.log2(i/count)
return round(Ent, 3)
2. 信息增益的计算
def cal_gain(D,Ent,A):
'''
D:剩余的样本集
Ent:对应的信息熵
A:剩余的属性集合
'''
# print("gain:",A)
gain = []
count=D.shape[0]
for i in A:
temp=0
for j in attribute[i]:
temp+=D[(D[i]==j)].shape[0]/count*entropy(D[(D[i]==j)])
# print(temp)
gain.append(round(Ent-temp,3))
# print(i,round(Ent-temp,3))
return np.array(gain)
3.决策树的生成
def same_value(D, A):
for key in A:
if key in attribute and len(D[key].value_counts()) > 1:
return False
return True
# 叶节点选择其类别为D中样本最多的类
def choose_largest_example(D):
count = D['好瓜'].value_counts()
return '是' if count['是'] >= count['否'] else '否'
def choose_best_attribute(D,A):
Ent=entropy(D)
gain=cal_gain(D,Ent,A)
return A[gain.argmax()]
#A:剩余的属性集
def TreeGenerate(D, A):
Count = D['好瓜'].value_counts()
if len(Count) == 1: #情况一,如果样本都属于一个类别
return D['好瓜'].values[0]
if len(A) == 0 or same_value(D, A): #情况二:如果样本为空或者样本的所有属性取值相同,则取类别较多的为分类标准
return choose_largest_example(D)
node = {}
best_attr = choose_best_attribute(D,A) #情况三:选择一个最佳属性作为分类节点
D_size = D.shape[0]
# 最优划分属性为离散属性时
for value in attribute[best_attr]: #对最佳属性当中的每个属性值进行分析
Dv = D[D[best_attr] == value]
if Dv.shape[0] == 0:
node[value] = choose_largest_example(D)
else:
new_A = [key for key in A if key != best_attr]
node[value] = TreeGenerate(Dv, new_A)
return {best_attr: node}
4.树型结构可视化
def drawtree(tree,coordinate,interval):
'''
tree:决策树
coordinate: 当前节点的坐标
interval:分支节点间的间隔
'''
now_A=list(tree.keys())[0]
plt.text(coordinate[0], coordinate[1], now_A, size=20,
ha="center", va="center",
bbox=dict(boxstyle="circle",
ec=(0.5, 0.8, 0.5),
fc=(0.5, 0.9, 0.5),
)
)
split_num=len(tree[now_A].values())
next_coordinate=coordinate-[(split_num-1)*interval,5]
for i in tree[now_A]:
plt.plot([coordinate[0],next_coordinate[0]],[coordinate[1],next_coordinate[1]])
plt.text((coordinate[0]+next_coordinate[0])/2,(coordinate[1]+next_coordinate[1])/2,s=i,size=15)
if tree[now_A][i] in labels:
plt.text(next_coordinate[0], next_coordinate[1],tree[now_A][i] , size=20,
ha="center", va="center",
bbox=dict(boxstyle="circle",
ec=(0.5, 0.5, 0.8),
fc=(0.5, 0.5, 0.9),
)
)
else:
drawtree(tree[now_A][i],next_coordinate,interval-4)
next_coordinate+=[interval*2,0]
实验结果
字典形式存储的决策树
{‘纹理’: {‘清晰’: {‘根蒂’: {‘蜷缩’: ‘是’, ‘稍蜷’: {‘色泽’: {‘青绿’: ‘是’, ‘乌黑’: {‘触感’: {‘硬滑’: ‘是’, ‘软粘’: ‘否’}}, ‘浅白’: ‘是’}}, ‘硬挺’: ‘否’}}, ‘稍糊’: {‘触感’: {‘硬滑’: ‘否’, ‘软粘’: ‘是’}}, ‘模糊’: ‘否’}}
可视化结果
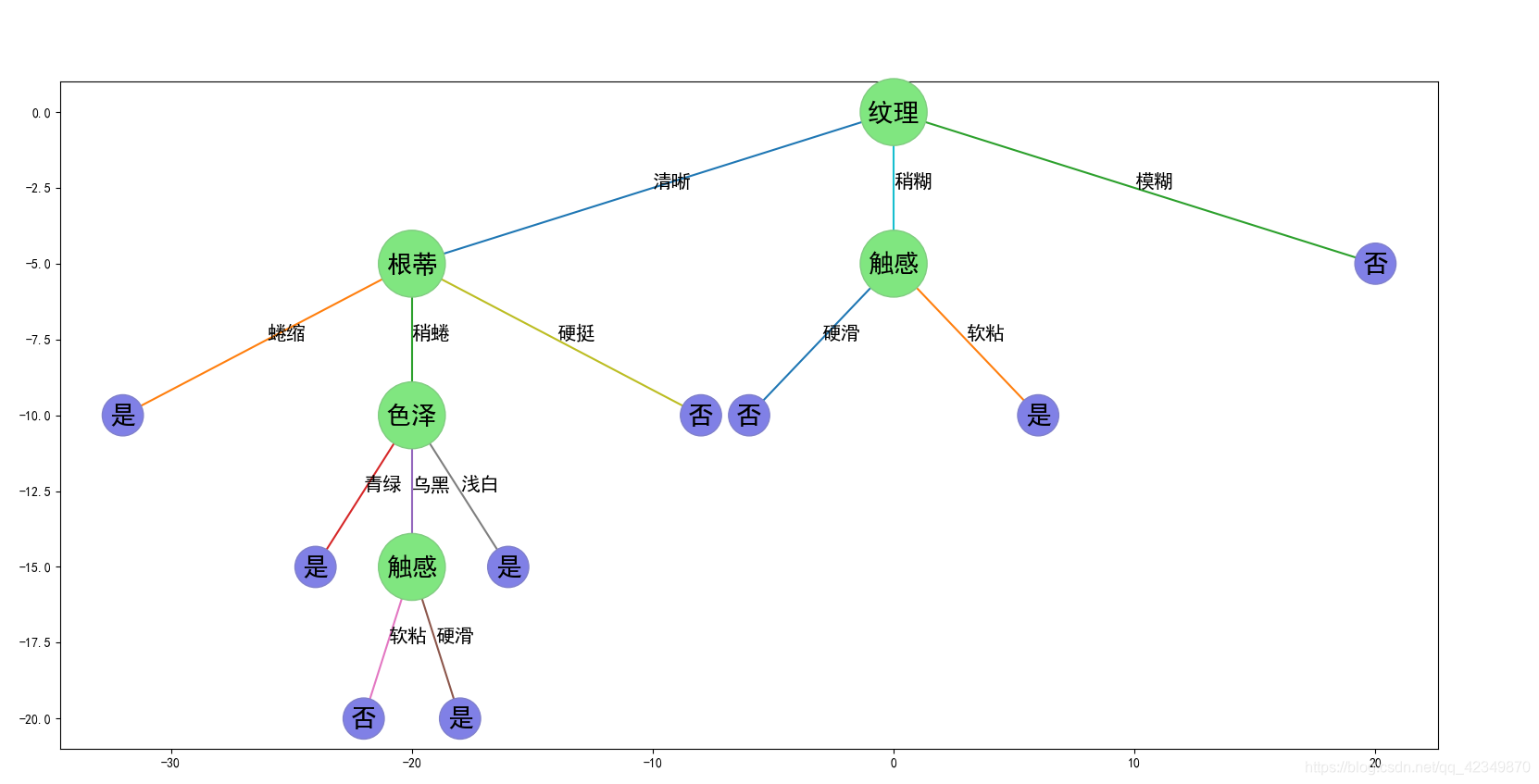
最后附上完整代码
import numpy as np
import pandas as pd
import math
import matplotlib.pyplot as plt
attribute={
"色泽":['青绿','乌黑','浅白'],
"根蒂": ['蜷缩', '稍蜷', '硬挺'],
"敲声": ['浊响', '沉闷','清脆'],
"纹理": ['清晰', '稍糊', '模糊'],
"脐部": ['凹陷', '稍凹', '平坦'],
"触感": ['硬滑', '软粘'],
# "密度":[],
# "含糖率":[],
}
#用来正常显示中文
plt.rcParams['font.sans-serif']=['SimHei']
#用来正常显示负号
plt.rcParams['axes.unicode_minus']=False
labels=['是','否']
def loaddata(dir):
data=pd.read_excel(dir)
return data
def entropy(D):
count=D.shape[0]
Ent=0.0
temp=D['好瓜'].value_counts() #获取剩余的类别数量
for i in temp:
Ent-=i/count*np.log2(i/count)
return round(Ent, 3)
def cal_gain(D,Ent,A):
'''
D:剩余的样本集
Ent:对应的信息熵
A:剩余的属性集合
'''
# print("gain:",A)
gain = []
count=D.shape[0]
for i in A:
temp=0
for j in attribute[i]:
temp+=D[(D[i]==j)].shape[0]/count*entropy(D[(D[i]==j)])
# print(temp)
gain.append(round(Ent-temp,3))
# print(i,round(Ent-temp,3))
return np.array(gain)
def same_value(D, A):
for key in A:
if key in attribute and len(D[key].value_counts()) > 1:
return False
return True
# 叶节点选择其类别为D中样本最多的类
def choose_largest_example(D):
count = D['好瓜'].value_counts()
return '是' if count['是'] >= count['否'] else '否'
def choose_best_attribute(D,A):
Ent=entropy(D)
gain=cal_gain(D,Ent,A)
return A[gain.argmax()]
#A:剩余的属性集
def TreeGenerate(D, A):
Count = D['好瓜'].value_counts()
if len(Count) == 1: #情况一,如果样本都属于一个类别
return D['好瓜'].values[0]
if len(A) == 0 or same_value(D, A): #情况二:如果样本为空或者样本的所有属性取值相同,则取类别较多的为分类标准
return choose_largest_example(D)
node = {}
best_attr = choose_best_attribute(D,A) #情况三:选择一个最佳属性作为分类节点
D_size = D.shape[0]
# 最优划分属性为离散属性时
for value in attribute[best_attr]: #对最佳属性当中的每个属性值进行分析
Dv = D[D[best_attr] == value]
if Dv.shape[0] == 0:
node[value] = choose_largest_example(D)
else:
new_A = [key for key in A if key != best_attr]
node[value] = TreeGenerate(Dv, new_A)
return {best_attr: node}
#决策树可视化
def drawtree(tree,coordinate,interval):
'''
tree:决策树
coordinate: 当前节点的坐标
interval:分支节点间的间隔
'''
now_A=list(tree.keys())[0]
plt.text(coordinate[0], coordinate[1], now_A, size=20,
ha="center", va="center",
bbox=dict(boxstyle="circle",
ec=(0.5, 0.8, 0.5),
fc=(0.5, 0.9, 0.5),
)
)
split_num=len(tree[now_A].values())
next_coordinate=coordinate-[(split_num-1)*interval,5]
for i in tree[now_A]:
plt.plot([coordinate[0],next_coordinate[0]],[coordinate[1],next_coordinate[1]])
plt.text((coordinate[0]+next_coordinate[0])/2,(coordinate[1]+next_coordinate[1])/2,s=i,size=15)
if tree[now_A][i] in labels:
plt.text(next_coordinate[0], next_coordinate[1],tree[now_A][i] , size=20,
ha="center", va="center",
bbox=dict(boxstyle="circle",
ec=(0.5, 0.5, 0.8),
fc=(0.5, 0.5, 0.9),
)
)
else:
drawtree(tree[now_A][i],next_coordinate,interval-4)
next_coordinate+=[interval*2,0]
dir="E:/xiguashu/3.0a.xlsx"
data=loaddata(dir)
D=data.drop(columns=['编号','密度','含糖率'],inplace=False)
# D_train=data.sample(frac=0.7)
# print(data[(data['色泽']=='青绿')])
tree=TreeGenerate(D,D.columns[:-1])
drawtree(tree,initial_coordinate,10)
plt.show()
如需转载,请注明出处!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)