【WAM篇】23:VPP——别真画未来视频了,“预测性视觉表征“才是宝
在级联式 WAM 的"潜在隐式规划"这条线上,有一个绕不开的拦路虎:**像素级视频合成太慢了**。前面 ARDuP 已经在往"潜在空间"挪、想省掉解码回 RGB 的开销,但生成一整段视频依然是个慢动作,离机器人实时闭环控制差得远。**VPP(Video Prediction Policy,视频预测策略)** 在这里给出了一个相当釜底抽薪的答案。它的洞察直白得近乎"投机取巧":**机器人控制根本不需
在级联式 WAM 的"潜在隐式规划"这条线上,有一个绕不开的拦路虎:像素级视频合成太慢了。前面 ARDuP 已经在往"潜在空间"挪、想省掉解码回 RGB 的开销,但生成一整段视频依然是个慢动作,离机器人实时闭环控制差得远。
VPP(Video Prediction Policy,视频预测策略) 在这里给出了一个相当釜底抽薪的答案。它的洞察直白得近乎"投机取巧":机器人控制根本不需要那段画出来的视频本身,它只需要视频扩散模型在"打算去画未来"时、脑子里那份关于"世界将如何演化"的内部理解。于是 VPP 干脆只让视频模型"往前想一步"(一次前向、一步去噪),把它中间层那份富含未来动态的特征抠出来当作策略的输入——而完全不去把视频真的画完。这一招让"先想象、再行动"的规划推理,首次逼近了实时控制的速度。本篇就来讲清楚它是怎么做到的。
一、要解决什么问题:视频规划"想得好",但"想得太慢"
我们先回顾一下级联式 WAM 这条路的老问题。它的标准范式是两阶段:第一阶段用视频生成模型画出"未来该怎么演化"的一整段视频;第二阶段从这段视频里解码出动作。好处是能借力互联网规模预训练的视频大模型,坏处是——
生成一整段高保真视频,要做几十步去噪,慢得要命。 视频扩散模型(VDM,即用扩散方式生成视频的模型)通常要迭代去噪 30 步左右才能出一段清晰视频。这意味着机器人每决策一次就得等上好一阵,控制频率被压到很低(一两赫兹甚至更低),只能做开环或慢悠悠的动作,根本没法做高频闭环的精细操作。这就是综述里反复点名的"延迟税"——预测能力越强,往往交得越多的延迟代价。
但 VPP 的作者退一步想了个更根本的问题:我们费这么大劲把未来视频一像素一像素画出来,下游策略真的需要这些像素吗?
答案多半是否定的。机器人要的不是一段供人观看的高清视频,而是"接下来世界大致会怎么变、我的手该往哪挪"这种指导动作的信息。而这种信息,其实在视频扩散模型"还没真正画完、只是动了一下念头"的中间特征里就已经有了。
打个比方:你问一位经验丰富的台球高手"这一杆该怎么打",他脑子里其实瞬间就有了"白球会撞向哪、目标球会往哪滚"的预判——但他完全没必要把这段动画在脑海里逐帧渲染成 4K 画面才能出杆。那份"对未来走势的直觉判断",才是决策真正依赖的东西。VPP 想抓的,正是视频模型脑子里那份"还没渲染成画面的预判"。
二、核心思想与直觉:把视频模型的"内部预判"当作策略输入
VPP 的核心 idea 一句话概括:
视频扩散模型在海量视频上预训练后,其内部特征天然编码了"物理世界将如何演化"的知识——作者称之为"预测性视觉表征(predictive visual representations)"。VPP 不去做完整的视频生成,而是只跑一次前向、一步去噪,把这份预测性视觉表征抠出来,喂给一个轻量策略头去解码动作。
这里有两个关键概念要讲清楚:
什么是"预测性视觉表征"? 过去机器人常用的视觉编码器(比如靠重建或对比学习训练的 VC-1、Voltron 之类),本质上只编码了"当前这一帧长什么样"的静态信息,对"接下来会怎么动"的动态信息几乎是无视的。而视频扩散模型不一样——它被训练来预测连续多帧的演化,所以它的内部特征里显式地携带了未来若干帧的信息。VPP 抠出来的特征,结构上是一个 (T, H, W) 的张量,其中明确包含"1 个当前步 + (T−1) 个预测的未来步"。这就是"预测性"三个字的由来:它不只看现在,还看未来。
为什么只跑一步就够? 这是 VPP 最反直觉、也最关键的发现。直觉上你可能觉得"去噪步数越多、想得越清楚、表征越好",但 VPP 的消融实验表明:一步去噪得到的表征,就已经足够好用了;多跑一步(两步去噪)几乎不带来性能提升,却让推理时间翻倍。换句话说,对下游控制而言,"把未来想个大概"远比"把未来画清楚"划算。这一步之差,就是从"几十步去噪的慢规划"到"一步前向的快规划"的分水岭。
放到 WAM 分类里,VPP 属于级联式 WAM 下"基于潜在表征的隐式规划"。它和 ARDuP 是同一条线上的同道,但更激进:ARDuP 还在潜在空间里"生成"未来帧,VPP 则连"生成"都省了,只取一次前向的中间特征。综述里那句"VPP 首次让规划推理速度逼近实时控制",说的正是它。
三、方法详解:两阶段架构
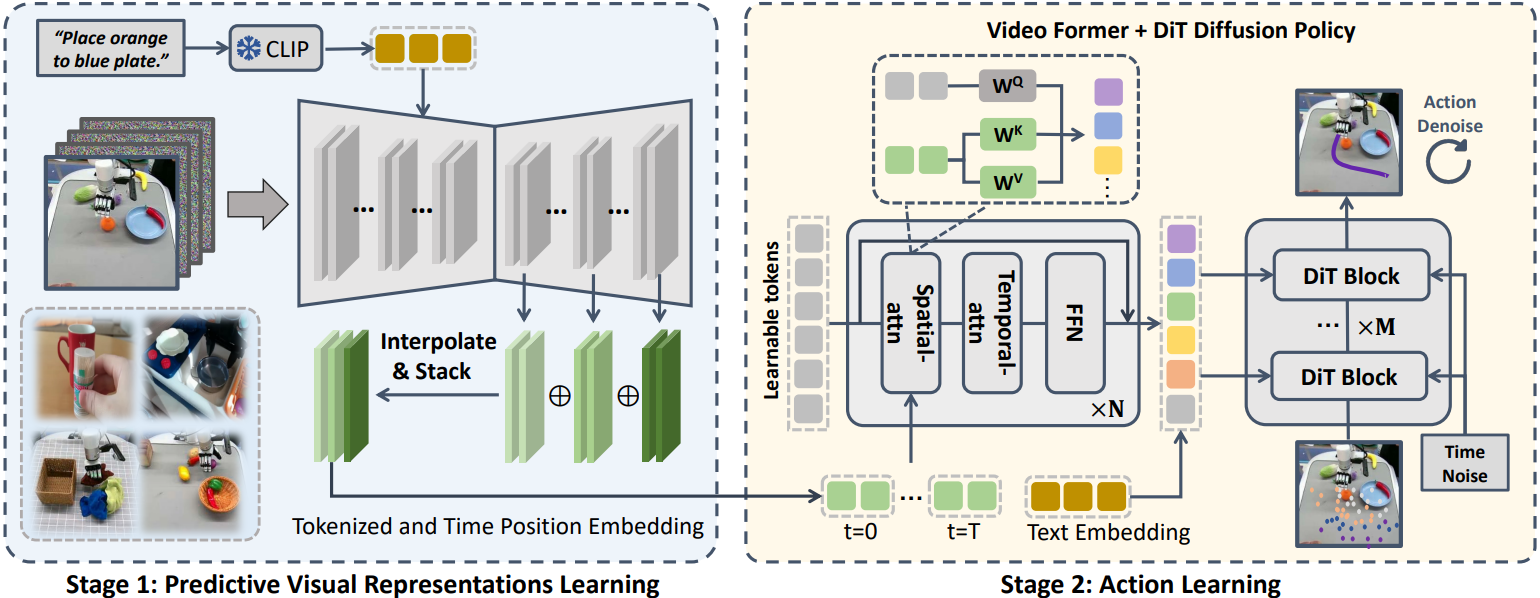
VPP 的整体架构分两个阶段:先把一个视频基础模型微调成会"预测机器人未来"的模型(TVP),再用它的预测性表征去训练一个动作策略。中间还有一个叫 Video Former 的关键组件负责"提纯"特征。我们逐块拆解。
阶段一:微调视频基础模型(TVP)
在干嘛:拿一个在互联网海量视频上预训练好的视频扩散模型,针对机器人操作场景做微调,让它学会"根据指令预测接下来该发生什么"。
怎么做:
- 底座:选用 Stable Video Diffusion(SVD),约 15 亿参数的视频扩散模型。
- 关键改造:原版 SVD 不吃语言,VPP 通过交叉注意力层给它接上 CLIP 语言条件——这样它就能听懂"把杯子放到盘子上"这类指令,按指令预测未来(这个会预测的模型被称为 TVP,Text-guided Video Prediction,文本引导视频预测)。
- 输出分辨率:为了效率,调成 16×256×256(16 帧、256×256)。
- 训练数据:用三类数据按加权比例混合微调——互联网人类操作视频(约 19.1 万条,权重 0.30)、机器人数据集(RT-1、Bridge、BC-Z 等,约 15.5 万条,权重 0.39)、下游任务数据(Calvin、MetaWorld、自采真机数据等,约 2.3 万条,权重 0.31)。
- 训练目标:标准的视频重建损失。
- 成本:在 8 张 A100 上训练 2–3 天。
这一步本质上是在把"互联网视频里学到的通用物理直觉"与"机器人数据里的具体操作"融到一个会预测未来的模型里。
阶段二:抠出"预测性视觉表征"
在干嘛:让微调好的 TVP “往前想一步”,把它脑子里那份未来预判抠出来。
怎么做:
- 拿一个噪声潜在(基本就是白噪声)和当前观测图像
s₀拼在一起,作为输入; - 让 TVP 跑一次前向——注意,不做完整的多步去噪,就这一下;
- 抠出 TVP 在多个上采样层的中间特征;
- 把各层特征插值到统一分辨率后,沿通道维拼接,得到预测性特征
Fp ∈ ℝ^(T×ΣCm×Wp×Hp)。
对多相机系统(比如一个固定机位 + 一个腕部机位),每路相机各自独立地算一份预测性表征。
速度优势:这一次前向大约只要 140–160 毫秒,对应控制频率约 7–10 Hz(在一张消费级 RTX 4090 上)。相比之下,那些要跑 30 步去噪的方法只能做开环或一两赫兹的低频控制。这就是"逼近实时"的硬指标来源。
Video Former:把高维特征"提纯"成定长 token
在干嘛:上一步抠出的预测性特征维度很高,直接喂给策略既慢又冗余。需要一个组件把它压缩成精炼、定长的表征。
怎么做:Video Former 用一组可学习的查询 token Q(形状是 T×L,即"时间 × 固定维度"),通过注意力把高维特征聚合成定长 token:
- 逐帧空间注意力:对每一帧,让查询 token 去注意该帧多路相机(固定机位 + 腕部机位)的特征;
- 跨帧时间注意力:再在帧与帧之间做时间注意力,配合前馈层;
- 输出聚合后的 token
Q'',作为下游策略的条件。
这一步的价值在消融里很明显(见第四节):去掉 Video Former 不仅性能掉,推理延迟还会暴涨 3 倍——因为策略得直接啃高维特征了。
打个比方:预测性表征是一大堆杂乱的"未来线索碎片",Video Former 就是个干练的秘书,把这些碎片整理成几条"重点摘要"递给决策者,既快又抓得住要害。
动作头:以"预测性表征"为条件的扩散策略
在干嘛:拿到提纯后的未来表征 token,解码出机器人该执行的动作序列。
怎么做:动作头是一个扩散策略(Diffusion Policy):
- 通过交叉注意力,以 Video Former 输出的 token
Q''和语言嵌入为条件; - 学习对动作序列去噪:损失形如
ℒ_diff = 𝔼‖D_ψ(a_k, l_emb, Q'') − a_0‖²; - 推理时生成动作块(10 步的动作序列),动作去噪只需 10 步。
整个策略头本质上是一个"以预测的未来表征为条件的隐式逆动力学模型"——它学的是"在预测的未来里,机器人该怎么动才能把手挪到位"。这里藏着 VPP 泛化能力的秘密(后面会讲):策略只需隐式地在"预测空间"里追踪机器人自身的运动,而不必显式建模物体语义或背景。
核心公式与逻辑梳理
VPP 的所有反直觉判断——“不必真画视频”、“一步去噪就够”、“多层特征拼起来比只取最后一层好”——都能在它的几个核心公式里找到对应。把它们串起来看,整套架构就从一组离散名字变成一条数据流。
方法逻辑链(五步):
- 微调 TVP:在 SVD 上挂 CLIP 文本条件,用人类视频 + 机器人数据 + 下游任务数据的加权混合训出一个会按指令预测未来的视频扩散模型 VθV_\thetaVθ;
- 一次性前向:拿当前观测 s0s_0s0 和一份噪声潜在 xt′x'_txt′ 喂给 VθV_\thetaVθ,只跑一次前向、一步去噪;
- 抠多层特征拼成 FpF_pFp:把上采样路径上若干层的中间激活插值到同一分辨率、沿通道维拼接,得到预测性视觉表征;
- Video Former 提纯:用一组可学习查询 token QQQ,先逐帧空间注意力融合多视角,再跨帧时间注意力,输出定长 token Q′′Q''Q′′;
- 扩散策略动作头:以 Q′′Q''Q′′ 和语言为条件,对动作序列做 10 步扩散去噪,输出动作块。
核心公式:
(1) TVP 微调损失(多数据集加权)
LD=Ex0∼D, ϵ, t∥ Vθ(xt,lemb,s0)−x0 ∥2,Lvideo=λHLDH+λRLDR+λCLDC \mathcal{L}_\mathcal{D} = \mathbb{E}_{x_0 \sim \mathcal{D}, \, \epsilon, \, t} \bigl\|\, V_\theta(x_t, l_\text{emb}, s_0) - x_0 \,\bigr\|^2, \qquad \mathcal{L}_\text{video} = \lambda_H \mathcal{L}_{\mathcal{D}_H} + \lambda_R \mathcal{L}_{\mathcal{D}_R} + \lambda_C \mathcal{L}_{\mathcal{D}_C} LD=Ex0∼D,ϵ,t Vθ(xt,lemb,s0)−x0 2,Lvideo=λHLDH+λRLDR+λCLDC
- 符号说明:x0x_0x0 是数据集 D\mathcal{D}D 里的一段干净视频潜在,xtx_txt 是给它加了 ttt 步噪声的版本,ϵ\epsilonϵ 是加进去的噪声;VθV_\thetaVθ 是 SVD 微调后的视频扩散网络,预测的是去噪后的 x0x_0x0(论文采用 vvv-/x0x_0x0-prediction 风格);lembl_\text{emb}lemb 是 CLIP 文本嵌入,s0s_0s0 是当前观测;DH,DR,DC\mathcal{D}_H, \mathcal{D}_R, \mathcal{D}_CDH,DR,DC 分别是人类视频、机器人公开数据、下游任务数据;λ⋅\lambda_\cdotλ⋅ 是各数据集的权重(论文里大致 0.30/0.39/0.31)。
- 这条式子在做什么:让 VθV_\thetaVθ 学会"根据指令和当前画面,把未来帧从噪声里反推回来"。三路数据加权是关键——既要互联网视频里的通用物理直觉,也要机器人数据里的本体姿态先验,还要下游任务数据里的具体场景细节。
(2) 预测性视觉表征 FpF_pFp 的抠取
Lm=Vθ(xt′,lemb,s0)(m)∈RT×Cm×Wm×Hm,Fp=concat(L0′,L1′,…,Lm′; dim=1) L_m = V_\theta(x'_t, l_\text{emb}, s_0)_{(m)} \in \mathbb{R}^{T \times C_m \times W_m \times H_m}, \qquad F_p = \text{concat}\bigl(L'_0, L'_1, \dots, L'_m;\, \dim=1\bigr) Lm=Vθ(xt′,lemb,s0)(m)∈RT×Cm×Wm×Hm,Fp=concat(L0′,L1′,…,Lm′;dim=1)
- 符号说明:xt′x'_txt′ 是一份噪声潜在(基本上就是白噪声);Vθ(⋅)(m)V_\theta(\cdot)_{(m)}Vθ(⋅)(m) 表示取 VθV_\thetaVθ 上采样路径第 mmm 层的中间激活;LmL_mLm 的四个维度分别是"时间帧数 TTT、通道 CmC_mCm、宽 WmW_mWm、高 HmH_mHm";Lm′L'_mLm′ 是把 LmL_mLm 插值到统一空间分辨率后的版本;concat(⋅;dim=1)\text{concat}(\cdot; \dim=1)concat(⋅;dim=1) 是沿通道维拼接;FpF_pFp 就是最终的"预测性视觉表征"张量。
- 这条式子在做什么:这是 VPP 全文最精髓的一行——视频模型不必把未来真的画完,只要跑一次前向,它在去噪路径上的中间激活就已经携带了"接下来世界会怎么演化"的丰富信息。多层拼接是因为:浅层抓的是局部纹理与运动,深层抓的是物体级语义,拼起来既懂"哪里在动"也懂"动的是什么"。
(3) Video Former:空间 + 时间双注意力提纯
Q′={ Spat-Attn(Q[i], (Fpstatic[i], Fpwrist[i])) }i=0T,Q′′=FFN(Temp-Attn(Q′)) Q' = \bigl\{\, \text{Spat-Attn}\bigl(Q[i],\, (F_p^\text{static}[i],\, F_p^\text{wrist}[i])\bigr) \,\bigr\}_{i=0}^{T}, \qquad Q'' = \text{FFN}\bigl(\text{Temp-Attn}(Q')\bigr) Q′={Spat-Attn(Q[i],(Fpstatic[i],Fpwrist[i]))}i=0T,Q′′=FFN(Temp-Attn(Q′))
- 符号说明:Q∈RT×LQ \in \mathbb{R}^{T \times L}Q∈RT×L 是一组可学习的查询 token,第一维是时间、第二维是固定的 LLL;Fpstatic[i],Fpwrist[i]F_p^\text{static}[i], F_p^\text{wrist}[i]Fpstatic[i],Fpwrist[i] 是固定机位与腕部机位在第 iii 帧的预测性特征;Spat-Attn\text{Spat-Attn}Spat-Attn 是空间交叉注意力(让查询去注意多机位的视觉键值);Temp-Attn\text{Temp-Attn}Temp-Attn 是时间自注意力(让不同帧之间互相沟通);FFN\text{FFN}FFN 是前馈网络;Q′′Q''Q′′ 是输出的精炼 token,是策略真正的输入。
- 这条式子在做什么:先在每一帧内部把多个相机的"未来线索"融成一个紧凑向量,再让不同帧之间彼此对齐时间走势。相当于"先把每个时刻看清楚,再把时间脉络捋顺"。这一步消融显示去掉它推理慢 3 倍、性能掉 11%——它真正起的是"为策略喂一份好嚼的浓缩汤"的作用。
(4) 扩散策略动作头损失
Ldiff(ψ;A)=Ea0, ϵ, k∥ Dψ(ak,lemb,Q′′)−a0 ∥2 \mathcal{L}_\text{diff}(\psi; A) = \mathbb{E}_{a_0, \, \epsilon, \, k} \bigl\|\, D_\psi(a_k, l_\text{emb}, Q'') - a_0 \,\bigr\|^2 Ldiff(ψ;A)=Ea0,ϵ,k Dψ(ak,lemb,Q′′)−a0 2
- 符号说明:a0a_0a0 是真值动作序列(10 步动作块),aka_kak 是加了 kkk 步噪声后的动作;DψD_\psiDψ 是动作头(一个小的扩散策略网络),通过交叉注意力以 lembl_\text{emb}lemb 和 Q′′Q''Q′′ 为条件;预测目标是干净动作 a0a_0a0。
- 这条式子在做什么:把"动作生成"也做成扩散——好处是天然能拟合多模态动作分布(同一情形下多种走法)。注意这里它是以预测的未来表征 Q′′Q''Q′′ 为条件的,本质上是一个"在预测的未来里学逆动力学"的策略——这正是 VPP 泛化到新物体的根:物体语义留给视频模型预测,策略只学"在预测里追踪自己的手该怎么挪"。
四式串起来,VPP 的完整逻辑就是:VθV_\thetaVθ 学会预测未来(式 1)→ 一次前向取中间激活(式 2)→ Video Former 压浓缩(式 3)→ 扩散动作头去噪出动作(式 4)。整条链路里"想未来"只跑一次、"动作去噪"只跑 10 步,这就是它能逼近实时的全部秘密。
四、实验怎么做·结果说明了什么
VPP 在两个仿真、两个真机基准上做了系统评测,并配了相当扎实的消融。
CALVIN ABC→D:长程任务大幅领先
CALVIN ABC→D 是个考验泛化的基准——在没见过的环境里零样本完成 5 个连续串联的任务,指标是"平均完成的任务数(越接近 5 越好)"。
| 方法 | 平均任务长度 |
|---|---|
| GR-1(此前 SOTA) | 3.06 |
| VPP | 4.33 |
相对提升约 41.5%。更狠的是数据效率:VPP 只用 10% 的训练数据就拿到 3.25,而 GR-1 用同样 10% 数据只有 1.41。
(注:综述里提到的"18.6% 相对提升"是 VPP 论文摘要中相对当时 SOTA 的概括口径,而论文正文里与 GR-1 的对照更细化到了上面这个 4.33 vs 3.06。两者并不矛盾,只是对比对象和口径不同。)
MetaWorld(50 任务):稳定超越
| 方法 | 平均成功率 |
|---|---|
| GR-1 | 57.4% |
| VPP | 68.2% |
分难度看,简单任务(28 个)81.8%、中等(11 个)49.3%、困难(11 个)52.6%。
真机:从机械臂到灵巧手
- Franka Panda 机械臂(30+ 任务、6 大类):见过的任务 85.6%,未见过的物体/背景 73.7%。
- 灵巧手(100+ 任务、13 大类):见过的任务 74.9%,未见过的任务 60.5%,工具使用类(勺子、锤子、电钻、移液器)68.0%。在这类复杂灵巧操作上,VPP 相对最强基线 GR-1 的提升约 31.6%——这正是综述引用的那个数字。
灵巧手是出了名的难(自由度高、接触复杂),VPP 能在上面拿到这种成绩,很能说明"预测性表征"对富接触操作是真有帮助。
消融:每个设计都"掐过水分"
VPP 的消融做得很到位,几乎逐一证明了每个组件的必要性:
1. 预测性表征 vs 其他编码器(CALVIN 平均任务长度):
| 编码器 | 预训练方式 | 平均长度 |
|---|---|---|
| VDM(VPP) | 视频生成 | 4.33 |
| Stable-VAE | VAE 重建 | 2.58 |
| VC-1 | MAE 重建 | 1.23 |
| Voltron | MAE + 语言 | 1.54 |
结论一目了然:唯有"视频生成式预训练"才能捕到操作所需的预测性动态,靠重建/对比学的静态编码器差得远。
2. 视频预训练与互联网数据的作用:
| 配置 | 平均长度 |
|---|---|
| 完整 VPP | 4.33 |
| 去掉互联网数据 | 3.97 |
| 去掉 Calvin 视频 | 3.31 |
| 不用 SVD 预训练(从头训) | 1.63 |
从头训练直接暴跌 62%——预训练底座 + 互联网操作数据,两者都不可或缺。
3. Video Former 的必要性:
| 配置 | 平均长度 | 延迟 |
|---|---|---|
| 完整 VPP | 4.33 | ~140ms |
| 去掉 Video Former | 3.86 | ~450ms |
去掉它:性能掉约 11%,延迟还涨 3 倍。
4. 多层特征聚合 vs 只取最后一层:4.33 vs 3.60,多层聚合带来约 20% 提升。
5. 去噪步数:一步 4.33 vs 两步 4.19——一步足矣,多去噪只是白白翻倍耗时。这正是 VPP "实时"的理论支点。
6. 单视角:只用固定机位(无腕部视角)也能拿到 3.58,仍超过此前用双视角 + 深度的 SOTA 方法。
泛化机制:为什么能迁移到没见过的物体
VPP 对训练里没出现过的物体(网球、可乐瓶、勺子)展现出很强的零样本迁移。作者把原因归为两点:
- 互联网规模预训练:视频大模型见过亿万视频,对新物体也能脑补出合理的未来;
- 隐式逆动力学:低层策略学的是"在预测的未来里追踪机器人自身的运动",不需要显式建模物体的语义或背景。
这种"把物体语义交给视频模型预测、把动作执行交给策略追踪"的解耦,正是它泛化的根基。
五、亮点与为什么重要
VPP 的贡献可以拎成几条:
- 提出"预测性视觉表征"这一概念,并证明它优于传统编码器。 它揭示了一个重要事实:视频扩散模型的内部特征本身就是绝佳的、带未来动态的机器人状态表征——这把视频大模型的价值,从"会画视频"重新定位到了"懂物理演化"。
- “一步前向取特征"替代"多步去噪生成视频”,把规划推理推到 7–10 Hz。 这是对级联式 WAM "延迟税"的一次有力反击,首次让"先想象、再行动"逼近实时控制。
- Video Former 的特征提纯,兼顾性能与速度。 多层聚合 + 时空注意力,把高维预测特征压成好用的定长 token。
- 跨仿真与真机、从机械臂到灵巧手全面验证,且消融扎实。 40%+ 的长程任务提升、31.6% 的灵巧操作提升,配上逐组件的消融,说服力很强。
对后续工作的深远意义在于:VPP 是 WAM 综述里那个核心反思——“显式的像素预测,真的是物理接地所必需的吗?世界建模的好处会不会主要来自训练时的辅助梯度、而非推理时真去画未来?”——的一个有力实证。它强烈暗示:与其在推理时重建高维像素,不如直接利用视频模型内部那份预测性表征。这恰恰为后来 JEPA 式"潜在预测"范式(在抽象潜在空间预测未来、绕开像素瓶颈)铺了路。
六、局限与未解
从论文内容可推断出几处局限:
- 预训练成本不低:视频模型微调要在 8 张 A100 上跑 2–3 天,门槛偏高。
- 多相机才有最佳性能:单视角虽仍超 SOTA,但会从 4.33 掉到 3.58,最佳表现仍需多机位配合。
- 聚焦操作域:微调是针对机器人操作场景优化的,尚未覆盖移动操作等更广的形态。
- 真机评测范围有限:只在 Franka 机械臂和灵巧手上验证,未涉及移动底盘等其他本体。
更深一层的开放问题(也是综述点出的):下游控制究竟需要多高的预测保真度? VPP 用"一步足矣"给出了一个偏低的经验答案,但这背后"任务自适应预测保真度"的理论边界,仍待探索。
七、在 WAM 谱系中的位置
把 VPP 放回 WAM 的分类树:它属于级联式 WAM 下"基于潜在表征的隐式规划",是这条线上最具标志性的工作之一。
- 承上:相对像素式的 UniPi、以及在潜在空间里仍"生成"未来帧的 ARDuP,VPP 更进一步——连"生成"都不做了,只取一次前向的预测性中间特征。它把"潜在隐式规划"推到了"几乎不付生成代价"的极致。
- 同类对照:综述把 VPP 列为该分支的开篇代表,与之并列的还有 S-VAM(用自蒸馏弥合效率与保真度)、LAPA/villa-X(从无标注视频学潜在动作)、MWM(用语义掩码替代 RGB 预测以抗扰动)。它们都在回答同一个问题——“如何绕开像素级合成的瓶颈”,VPP 的答案是"取内部表征、只想一步"。
- 启下:VPP 对 JEPA 式潜在预测范式(VLA-JEPA 等)有直接的启发意义——既然推理时不必真画未来,那么干脆在抽象潜在空间里做"预测对齐"也许就够了。它和本系列下一篇 VILP(同样走潜在规划,但坚持"生成完整潜在视频序列"且主打多视角同步与极致推理速度)形成了一组有趣的对照:一个连生成都省了、只取特征,一个把生成压到潜在空间但仍把视频画完——两种思路在"效率 vs 显式预测"的天平上各押一端。
八、参考
- 论文标题:Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations(VPP)
- 出处:ICML 2025(Spotlight);arXiv:2412.14803
- arXiv:https://arxiv.org/abs/2412.14803
- 项目主页:https://video-prediction-policy.github.io/
- 代码:https://github.com/roboterax/video-prediction-policy
- 关键基准:CALVIN ABC→D、MetaWorld、真机 Franka Panda、真机灵巧手
注:本文为基于该论文公开信息的学习性解读,方法与基准名称均保留英文原名以便检索;具体数字以原论文为准。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 6
6 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)