【论文阅读】Guide, Think, Act: Interactive Embodied Reasoning in Vision-Language-Action Models
本文提出了一种名为GTA-VLA的框架,允许人类通过简单的点、框或轨迹等视觉提示来引导机器人的思考过程,从而解决机器人视觉理解错误或环境复杂导致的任务失败问题。
快速了解部分
基础信息(英文):
1.题目: Guide, Think, Act: Interactive Embodied Reasoning in Vision-Language-Action Models
2.时间: 2026.05
3.机构: Futian Laboratory, Harbin Institute of Technology, IDEA, etc.
4.3个英文关键词: VLA, Chain-of-Thought, Interactive Perception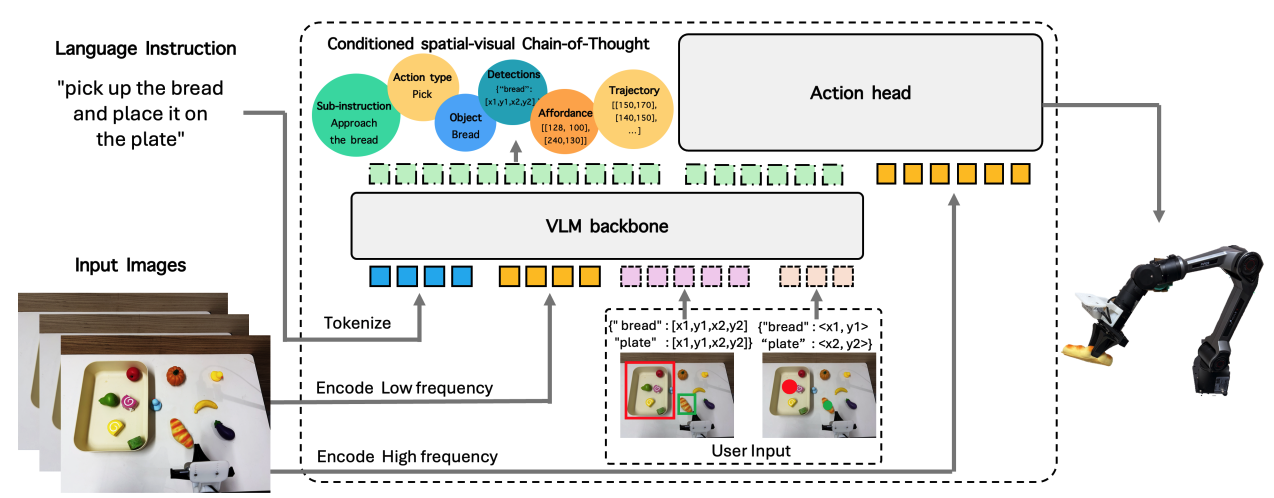
1句话通俗总结本文干了什么事情
本文提出了一种名为GTA-VLA的框架,允许人类通过简单的点、框或轨迹等视觉提示来引导机器人的思考过程,从而解决机器人视觉理解错误或环境复杂导致的任务失败问题。
研究痛点:现有研究不足 / 要解决的具体问题
现有VLA模型多采用“感知即行动”的直接映射,缺乏透明度且难以纠正错误;虽然引入了思维链(CoT)提高了可解释性,但其推理过程是封闭的,无法有效融入人类的空间指导来修正错误或消除视觉歧义。
核心方法:关键技术、模型或研究设计(简要)
提出了GTA-VLA框架,包含“引导(Guide)-思考(Think)-行动(Act)”三个阶段。通过引入可选的视觉先验(如点、框、轨迹)作为条件输入,结合结构化的空间视觉思维链,使机器人推理过程可被人类通过视觉信号干预和修正。
深入了解部分
作者想要表达什么
作者旨在证明,机器人的推理过程不应仅依赖内部模型,而应开放接口接受人类的外部空间指导。通过将人类的视觉提示(如指点目标)直接融入模型的思维链中,可以在保持自主性的同时,大幅提升机器人处理未知环境、视觉歧义和任务失败恢复的能力。
相比前人创新在哪里
- 交互式推理:不同于以往仅靠语言指令或完全自主的CoT,本文允许在推理阶段直接注入人类的视觉先验(点、框、轨迹),使模型“可被引导”。
- 结构化思维链:设计了包含任务分解、视觉定位和机器人动作草图的结构化CoT,比自由格式的CoT更可控且易于与视觉信号对齐。
- 异步架构:将耗时的VLM推理与快速的动作生成解耦,实现了在低频推理指导下高频动作执行的系统,兼顾了逻辑思考与实时控制。
解决方法/算法的通俗解释
想象机器人是一个正在学开车的学员(VLM大脑)配合一个专业的副驾驶教练(人类)。
- Guide(引导):教练不需要大声嚷嚷,只需要在挡风玻璃(视觉画面)上用手指点一下要抓的物体(Affordance Point)或者画个框,这就是“视觉先验”。
- Think(思考):学员看到教练的指点后,脑子里开始过一遍流程:“我要抓那个物体(任务分解) -> 它在画面的左下角(视觉定位) -> 我要这样移动手去够它(动作草图)”。这个思考过程是结构化的,且必须参考教练的指点。
- Act(行动):学员把刚才想好的“动作草图”交给手脚(快速动作模块),手脚不需要等脑子想完每一步细节,而是拿着草图直接流畅地执行动作。
解决方法的具体做法
- 输入端:在标准的图像和语言指令外,增加了一个可选的“空间先验”输入通道,支持点、框、轨迹三种形式。
- 模型架构:
- VLM Backbone (Qwen3-VL-2B):负责“Guide”和“Think”。它接收视觉先验,生成结构化的思维链(任务->视觉->机器人动作草图)。
- Flow-Matching Action Head:负责“Act”。它以高频率运行,接收VLM生成的最新思维链隐状态和本体感知信息,输出具体的动作片段。
- 异步运行:VLM以低频率(约2Hz)更新思维链,动作头以高频率(约10Hz)执行动作,减少了大模型解码延迟对控制的影响。
- 数据构建:利用自动化流水线,将现有的机器人数据集(如OXE, DROID)转化为带有模拟视觉先验和结构化思维链的训练数据(Interact-306K)。
基于前人的哪些方法
- VLA Models:基于标准的Vision-Language-Action模型架构,如OpenVLA, RT-2等。
- Embodied CoT:借鉴了具身思维链(如ECoT, Mind2Hand, MolmoAct)的思想,将推理过程显式化。
- Visual Prompting:利用了类似SAM、T-Rex2等模型的视觉提示(Visual Prompting)能力,用于空间定位。
- Flow-Matching:采用了Flow-Matching策略作为动作头,用于生成连续的动作片段。
实验设置、数据、评估方式、结论
- 数据:构建了Interact-306K数据集,基于Open X-Embodiment (OXE), DROID, RoboMind等,并合成了视觉推理标注。
- 基准测试:
- 标准测试:在LIBERO和SimplerEnv上评估自主性能。
- 新基准:提出了SimplerEnv-Plus,专门测试视觉、物体、语言等方面的分布外(OOD)鲁棒性。
- 评估方式:成功率(Success Rate)。
- 结论:
- 自主性能:在SimplerEnv上达到81.2%的SOTA成功率。
- 鲁棒性:在SimplerEnv-Plus的OOD测试中显著优于基线(61.4% vs 52.3%)。
- 交互有效性:在存在歧义或失败的情况下,人类通过简单的视觉指点(点或框)可以显著提升成功率,平均挽回了20%的失败案例。
提到的同类工作
- OpenVLA:开源的VLA模型,作为主要对比基线。
- π0 / π0.5:Vision-Language-Action Flow模型,强调泛化能力。
- ECoT (Embodied Chain-of-Thought):将思维链引入具身智能的代表作。
- SAM / T-Rex2:交互式分割和检测模型,提供了视觉提示的技术基础。
和本文相关性最高的3个文献
- MolmoAct: Action reasoning models that can reason in space. (2025)
- π0.5: A vision-language-action model with open-world generalization. (2025)
- SimplerEnv: Evaluating real-world robot manipulation policies in simulation. (2024)
我的
- VLM里引入CoT思考。这种范式很多paper已经做了。提出来一个新数据集可以试一下。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 3
3 0
0- 0



 已为社区贡献73条内容
已为社区贡献73条内容

所有评论(0)