【论文阅读】StereoVLA: Enhancing Vision-Language-Action Models with Stereo Vision
本文提出了一种名为StereoVLA的模型,通过引入双目立体视觉,显著增强了机器人视觉语言动作模型(VLA)的空间感知和操作精度。
快速了解部分
基础信息(英文):
1.题目: StereoVLA: Enhancing Vision-Language-Action Models with Stereo Vision
2.时间: 2025.12
3.机构: Galbot, Peking University, The University of Hong Kong, Institute of Automation. Chinese Academy of Sciences, Beijing Academy of Artificial Intelligence, Xiamen University Malaysia
4.3个英文关键词: Stereo Vision, VLA, Geometric-Semantic Feature Extraction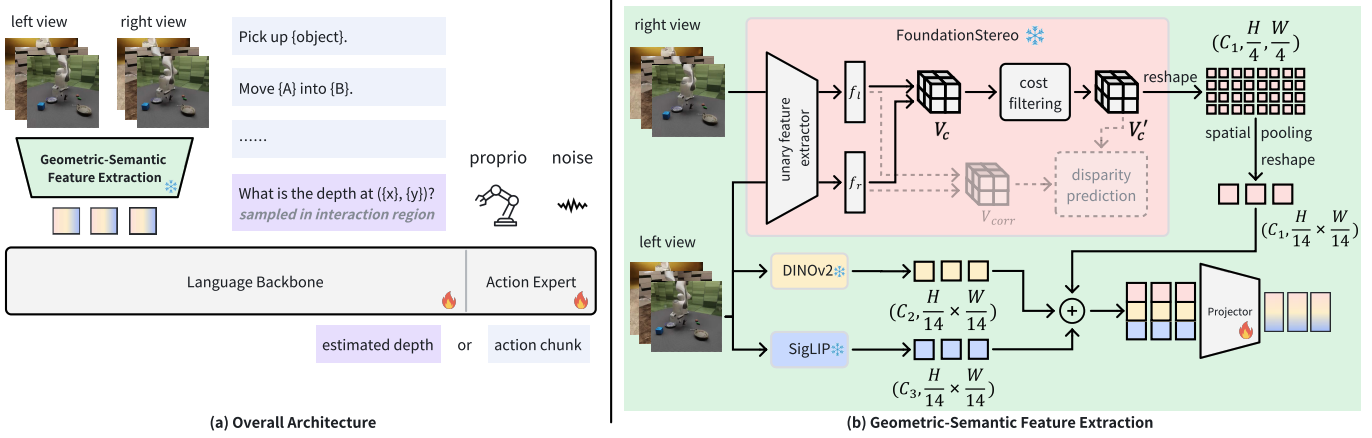
1句话通俗总结本文干了什么事情
本文提出了一种名为StereoVLA的模型,通过引入双目立体视觉,显著增强了机器人视觉语言动作模型(VLA)的空间感知和操作精度。
研究痛点:现有研究不足 / 要解决的具体问题
现有的VLA模型大多依赖单目RGB相机,缺乏精确的几何空间感知能力,导致机器人在抓取、放置等精细操作上表现不佳;而引入额外的深度传感器或腕部相机又会增加硬件复杂度或导致视野受限。
核心方法:关键技术、模型或研究设计(简要)
提出了一种“几何-语义特征提取”模块,融合了双目视觉的几何特征和单目视觉的语义特征,并引入了一个辅助的“交互区域深度估计”任务来训练模型关注关键空间细节。
深入了解部分
作者想要表达什么
作者旨在证明,通过模仿人类的双目视觉机制,可以在不增加过多硬件负担的情况下,为VLA模型提供丰富的几何线索,从而解决机器人操作中“看得见但摸不准”的痛点,实现更鲁棒、更精准的控制。
相比前人创新在哪里
- 首次系统性地将立体视觉引入VLA领域:不同于以往VLA主要使用单目或多视角(非立体)相机,本文专门针对立体视觉设计了特征提取方案。
- 独特的特征融合策略:没有简单地将左右图像拼接输入,而是利用视觉基础模型分别提取“几何特征”和“语义特征”进行融合,兼顾了空间精度和语言理解能力。
- 交互区域深度估计辅助任务:设计了一个新的训练任务,强制模型只关注夹爪和物体交互区域的深度信息,提高了训练效率和对关键空间细节的敏感度。
解决方法/算法的通俗解释
想象一下,模型现在有了“两只眼睛”(立体视觉)。作者设计了一个特殊的“大脑回路”(几何-语义特征提取),让模型既能通过两只眼睛的微小差别算出物体的远近(几何),又能看清单个物体是什么(语义)。同时,为了让模型更专注,还专门训练它去预测夹爪附近物体的深度(交互区域深度估计),就像人眼在抓东西时会特别聚焦于手和物体的距离一样。
解决方法的具体做法
- 几何特征提取:使用FoundationStereo模型处理左右图像,提取经过滤波处理的成本体积(filtered cost volume)作为几何特征,捕捉空间结构。
- 语义特征提取:使用SigLIP和DINOv2模型处理左图像,提取高层语义和视觉细节。
- 特征融合:将几何特征的空间分辨率调整到与语义特征一致,然后在通道维度上进行拼接,输入给大语言模型。
- 辅助任务训练:在训练时,除了预测动作,还要求模型预测夹爪与目标物体交互区域内的点的深度值,以此增强模型的空间理解。
基于前人的哪些方法
- FoundationStereo:用于提取立体视觉的几何特征。
- PrismaticVLM:借鉴了其使用SigLIP和DINOv2提取语义特征的方法。
- InternLM-1.8B:作为大语言模型骨干。
- GraspVLA:借鉴了其数据生成方式、部分训练策略(如渐进式动作生成)以及辅助的2D边界框预测任务。
实验设置、数据、评估方式、结论
- 数据:由于缺乏现成的大规模立体视觉机器人数据集,作者使用MuJoCo和Isaac Sim生成了500万条合成的抓取和放置轨迹,并加入了GRIT数据集。
- 评估方式:在真实机器人上测试,包括通用任务、不同角度的条状物体抓取、中小物体抓取。设置了严格的评价标准(单次尝试、无粘手策略、完全完成才算成功)。
- 结论:StereoVLA在立体视觉设置下显著优于现有的VLA基线模型(如GraspVLA-S, π0.5-S),在通用任务上成功率高出33%,且对相机姿态变化具有很强的鲁棒性。
提到的同类工作
- OpenVLA:早期的VLA模型,依赖单目图像。
- π0.5:支持多视角(如前+腕),但未专门针对立体视觉优化。
- GraspVLA:大规模合成预训练VLA,主要针对前+侧视角。
- SpatialVLA:尝试引入深度信息,但基于单目估计深度。
- 3D-VLA / PointVLA:引入3D点云或深度信息的VLA模型。
和本文相关性最高的3个文献
- **GraspVLA **:本文主要的基线模型之一,作者借鉴了其数据合成方法和部分架构设计,是本文对比和改进的重要对象。
- **FoundationStereo **:本文几何特征提取的核心基础模型,用于从立体图像中提取密集的几何信息。
- **PrismaticVLM **:本文语义特征提取方法的来源,提供了SigLIP和DINOv2的使用方案。
我的
- 深度相机存在透明物体估计不准的问题,所以将立体视觉引入VLA。输入双目图像。对相机姿态变化更鲁棒。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 2
2 0
0- 0



 已为社区贡献73条内容
已为社区贡献73条内容

所有评论(0)