智元 D1 强化学习sim-to-real系列 | Robot Lab 基于 Isaac Lab 的机器人强化学习使用(四)
摘要 Robot Lab是基于NVIDIA Isaac Lab构建的机器人强化学习扩展库,提供标准化训练环境。该项目采用分层架构,包含Application、Simulation、World、Stage和Scene五个核心概念,其中Scene负责管理向量化图元实现并行训练。文档详细介绍了Isaac Sim的操作快捷键,涵盖基本操作、视野控制、物体变换、选择操作、场景层级管理、仿真控制等六大类功能,
1. 项目简介
Robot Lab 是一个基于 NVIDIA Isaac Lab 构建的机器人强化学习扩展库,专注于为各类机器人提供标准化的强化学习训练环境。该项目允许开发者在独立的环境中进行开发,而无需修改核心 Isaac Lab 仓库。对应ISaac lab 使用需要你参考并学习。然后可以参考Isaac Sim|操作界面指南,ISAAC SIM安装与软件实践学习(二)—用户界面与工作流程,Nvidia Isaac Sim图形界面 入门教程 2024(3)学习操作。最全的资料还是我们之前讲到的isaacsim官方教程以及isaaclab翻译版本
NVIDIA的机器人平台主要由两大核心组件构成,它们之间是层级关系:基础仿真平台Isaac Sim,以及构建于其上的机器人学习应用框架Isaac Lab。要精通 Isaac Sim,必须理解其分层架构中的五个核心概念。
- Isaac Sim 是什么? 它是一个通用的机器人模拟器,提供了高保真的物理引擎(PhysX)和照片级的渲染技术(RTX)。其核心任务是构建和模拟一个精确、逼真的虚拟环境,包括机器人模型、传感器数据和物理交互。
- Isaac Lab 是什么? 它是一个专为机器人学习(特别是强化学习)设计的开源框架。它本身不是一个模拟器,而是利用Isaac Sim提供的环境来进行大规模的AI模型训练。
- Application (App):这是最高层级的管理者,负责所有资源的生命周期,包括启动和销毁仿真进程。即使用户在无头模式(headless)下运行,App 依然是整个程序的总控制器。
- Simulation (Sim):Sim 负责定义虚拟世界的“规则”,例如物理定律(如重力方向)、时间步长(dt)以及渲染频率。它将时间的每一步划分为不同的子步骤(如physics_step和render_step),并掌管着 World 对象。
- World:World 为仿真提供了空间背景,定义了笛卡尔坐标系的原点和单位。所有关于尺寸和距离的问题都在 World 的参考系内得以解答。
- Stage:Stage 是世界的“组成结构”。它以通用场景描述(Universal Scene Description, USD)为基础,将仿真中的所有元素(如机器人、灯光、摄像机)表示为一个层级化的树状结构。这个结构中的每一个节点都是一个图元(Prim)。
- USD 图元(Prim):Prim 是 USD 场景的基本构建块,可以理解为一个容器。每个 Prim 都有一个唯一的路径(例如/World/MyRobot/Gripper),并包含定义其特性的属性(Attributes)(如颜色、大小)和与其他 Prim 的关系(Relationships)(如材质指定)。例如,一个“树”的 Prim 可以有“高度”和“颜色”等属性,同时与一个“地面”Prim 建立关系,以表明其种植位置。父级 Prim 的属性可以被其子级继承,从而实现复杂的场景组合。
- Scene:Scene 是 Isaac Lab 中一个至关重要的概念,它管理着 Stage 上所有与向量化(vectorization)相关的图元。这些被管理的图元(如机器人、桌子、待抓取物体)被称为仿真实体(simulation entities)。当用户指定需要创建多个环境副本时,Scene 会自动在 Stage 上克隆这些实体,并将它们放置在不同的坐标位置,从而实现在单一世界和舞台上进行大规模并行训练。
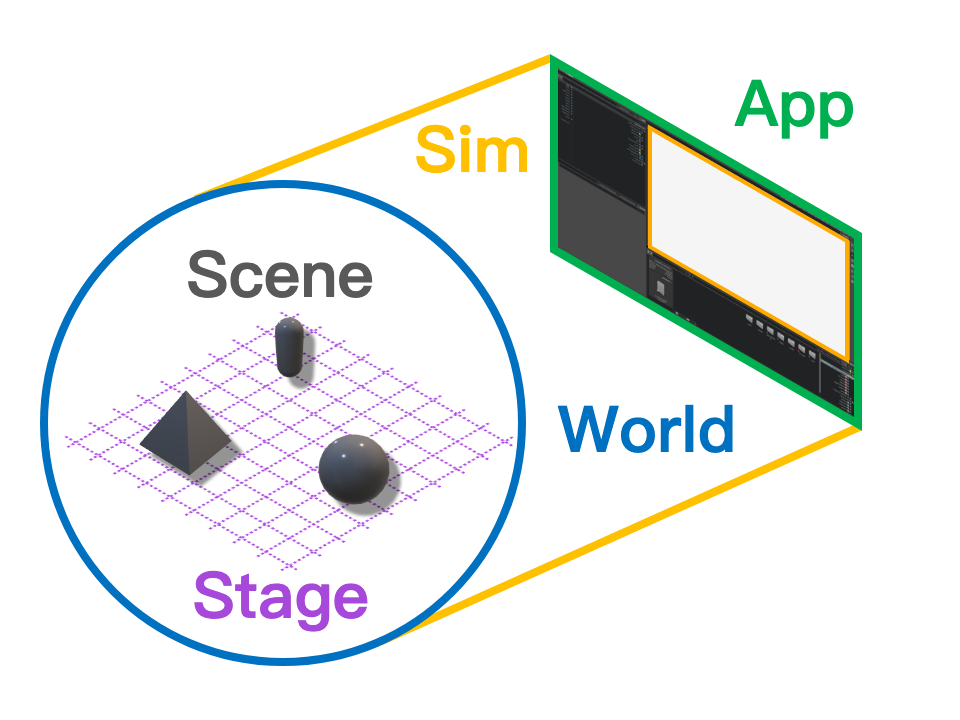
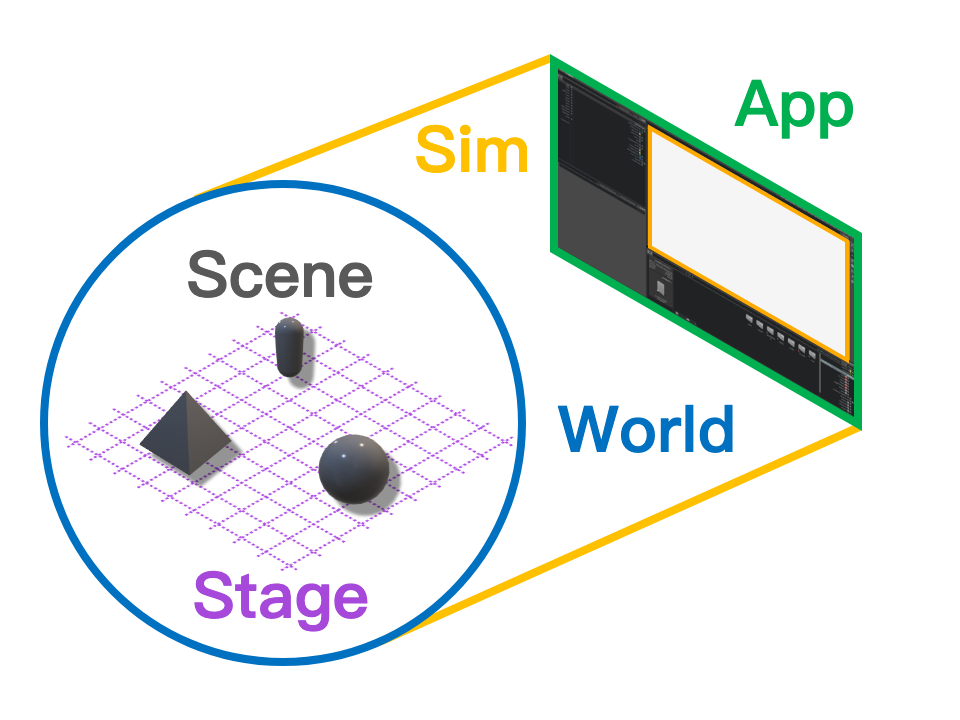
1.1 Isaac Sim 操作快捷键参考
以下是 Isaac Sim 中常用的操作快捷键,帮助您更高效地使用仿真环境:
基本操作
| 类型 | 键位 | 效果 |
|---|---|---|
| 基本操作 | 鼠标左键 | 选中物体 |
| 基本操作 | ESC | 取消选中 |
| 基本操作 | Ctrl + Z | 撤销上一步操作 |
| 基本操作 | Ctrl + Y / Ctrl + Shift + Z | 重做操作 |
| 基本操作 | Ctrl + S | 保存当前场景 |
| 基本操作 | Ctrl + O | 打开场景 |
| 基本操作 | Ctrl + N | 新建场景 |
| 基本操作 | Delete | 删除选中的物体 |
| 基本操作 | Ctrl + D | 复制选中的物体 |
| 基本操作 | Ctrl + C | 复制 |
| 基本操作 | Ctrl + V | 粘贴 |
| 基本操作 | Ctrl + X | 剪切 |
视野操作
| 类型 | 键位 | 效果 |
|---|---|---|
| 视野操作 | 鼠标左键点击目标 + F | 聚焦于选中的物体(Frame Selected) |
| 视野操作 | 不选中目标 + F | 聚焦于整个场景(Frame All) |
| 视野操作 | 鼠标左键 + Alt(或鼠标中键) | 旋转视野(绕选中物体或场景中心) |
| 视野操作 | 鼠标右键 + Alt | 缩放视野(Zoom) |
| 视野操作 | 鼠标中键(滚轮按下) | 平移视野(Pan) |
| 视野操作 | 鼠标滚轮 | 放大/缩小视野 |
| 视野操作 | 鼠标右键 + W | 镜头向前移动(第一人称模式) |
| 视野操作 | 鼠标右键 + S | 镜头向后移动(第一人称模式) |
| 视野操作 | 鼠标右键 + A | 镜头向左移动(第一人称模式) |
| 视野操作 | 鼠标右键 + D | 镜头向右移动(第一人称模式) |
| 视野操作 | 鼠标右键 + Q | 镜头向下移动(第一人称模式) |
| 视野操作 | 鼠标右键 + E | 镜头向上移动(第一人称模式) |
| 视野操作 | Numpad 0-9 | 切换预设视角 |
物体操作与变换
| 类型 | 键位 | 效果 |
|---|---|---|
| 变换操作 | W(或 T) | 切换到平移模式(Translate) |
| 变换操作 | E(或 R) | 切换到旋转模式(Rotate) |
| 变换操作 | R(或 Y) | 切换到缩放模式(Scale) |
| 变换操作 | Q | 切换到选择模式(取消变换工具) |
| 变换操作 | Shift + 拖拽 | 在特定轴上进行精确移动 |
| 变换操作 | Ctrl + 拖拽 | 启用吸附功能(Snap) |
| 变换操作 | Ctrl + Shift + 鼠标左键拖拽 | 对物体施加力(Apply Force,用于物理交互测试) |
| 变换操作 | Alt + 拖拽 | 复制并移动物体 |
选择操作
| 类型 | 键位 | 效果 |
|---|---|---|
| 选择操作 | Ctrl + 鼠标左键 | 多选/取消选择单个物体(Add/Remove from Selection) |
| 选择操作 | Shift + 鼠标左键 | 范围选择(连续选择) |
| 选择操作 | Ctrl + A | 全选当前层级的所有物体 |
| 选择操作 | Ctrl + Shift + A | 取消全选 |
| 选择操作 | 双击物体 | 选择物体及其所有子物体 |
场景层级操作
| 类型 | 键位 | 效果 |
|---|---|---|
| 层级操作 | Ctrl + G | 将选中物体组合成组(Group) |
| 层级操作 | Ctrl + Shift + G | 取消组合(Ungroup) |
| 层级操作 | Ctrl + P | 设置父级(Parent) |
| 层级操作 | Alt + P | 清除父级(Unparent) |
| 层级操作 | H | 隐藏选中的物体 |
| 层级操作 | Alt + H | 显示所有隐藏的物体 |
| 层级操作 | Ctrl + H | 隐藏未选中的物体 |
仿真控制
| 类型 | 键位 | 效果 |
|---|---|---|
| 仿真控制 | 空格键 | 播放/暂停仿真 |
| 仿真控制 | Ctrl + 空格 | 单步执行仿真(Step) |
| 仿真控制 | Ctrl + Shift + 空格 | 停止仿真并重置 |
| 仿真控制 | . (句号) | 前进一帧 |
| 仿真控制 | , (逗号) | 后退一帧 |
窗口与界面
| 类型 | 键位 | 效果 |
|---|---|---|
| 界面操作 | Ctrl + Shift + Space | 最大化/还原当前视口 |
| 界面操作 | Ctrl + Tab | 在打开的标签页之间切换 |
| 界面操作 | F1 | 打开帮助文档 |
| 界面操作 | F11 | 全屏模式 |
| 界面操作 | ` (反引号/波浪线键) | 打开/关闭控制台(Console) |
调试与可视化
| 类型 | 键位 | 效果 |
|---|---|---|
| 调试操作 | Ctrl + Shift + D | 切换调试绘制(Debug Draw) |
| 调试操作 | Ctrl + Shift + C | 显示/隐藏碰撞体(Collision Meshes) |
| 调试操作 | Ctrl + Shift + B | 显示/隐藏边界框(Bounding Boxes) |
| 调试操作 | Ctrl + Shift + W | 显示/隐藏线框模式(Wireframe) |
| 调试操作 | Ctrl + Shift + L | 切换照明模式 |
相机操作
| 类型 | 键位 | 效果 |
|---|---|---|
| 相机操作 | Ctrl + Shift + C | 从当前视角创建相机 |
| 相机操作 | Ctrl + [ | 切换到上一个相机 |
| 相机操作 | Ctrl + ] | 切换到下一个相机 |
| 相机操作 | Shift + F | 进入飞行模式(Fly Mode) |
脚本与编辑器
| 类型 | 键位 | 效果 |
|---|---|---|
| 脚本编辑 | Ctrl + Shift + P | 打开命令面板(Command Palette) |
| 脚本编辑 | Ctrl + Shift + E | 打开脚本编辑器(Script Editor) |
| 脚本编辑 | Ctrl + Enter | 执行选中的脚本代码 |
| 脚本编辑 | Ctrl + / | 注释/取消注释代码行 |
搜索与导航
| 类型 | 键位 | 效果 |
|---|---|---|
| 搜索操作 | Ctrl + F | 在场景中搜索物体 |
| 搜索操作 | Ctrl + Shift + F | 在整个项目中搜索 |
| 搜索操作 | Ctrl + L | 跳转到指定行 |
视口与显示模式
| 类型 | 键位 | 效果 |
|---|---|---|
| 视口模式 | Numpad 1 | 前视图(Front View) |
| 视口模式 | Numpad 3 | 右视图(Right View) |
| 视口模式 | Numpad 7 | 顶视图(Top View) |
| 视口模式 | Numpad 0 | 切换到相机视图 |
| 视口模式 | Numpad . | 聚焦到选中物体 |
| 视口模式 | Numpad / | 隔离选中物体(只显示选中对象) |
| 视口模式 | Numpad 5 | 切换正交/透视投影模式 |
| 显示模式 | Z | 切换渲染模式(线框/实体/材质预览) |
| 显示模式 | Alt + Z | 切换透明显示模式 |
| 显示模式 | Shift + Z | 切换材质预览/渲染视图 |
网格与对齐
| 类型 | 键位 | 效果 |
|---|---|---|
| 网格操作 | G | 显示/隐藏网格(Grid) |
| 网格操作 | Ctrl + G(长按) | 显示网格设置 |
| 对齐操作 | Alt + X | 对齐到X轴 |
| 对齐操作 | Alt + Y | 对齐到Y轴 |
| 对齐操作 | Alt + Z | 对齐到Z轴(与透明显示不同,需查看上下文) |
| 吸附操作 | Shift + Tab | 切换吸附模式(顶点/边/面) |
时间轴与动画
| 类型 | 键位 | 效果 |
|---|---|---|
| 时间轴 | Home | 跳转到时间轴起始帧 |
| 时间轴 | End | 跳转到时间轴结束帧 |
| 时间轴 | 左箭头 | 上一帧 |
| 时间轴 | 右箭头 | 下一帧 |
| 时间轴 | Shift + 左箭头 | 快退(10帧) |
| 时间轴 | Shift + 右箭头 | 快进(10帧) |
| 动画 | I | 插入关键帧(Insert Keyframe) |
| 动画 | K | 删除关键帧 |
属性与面板
| 类型 | 键位 | 效果 |
|---|---|---|
| 面板操作 | N | 显示/隐藏属性面板(Properties Panel) |
| 面板操作 | T | 显示/隐藏工具栏 |
| 面板操作 | Ctrl + Shift + T | 打开/关闭所有面板 |
| 属性编辑 | Tab | 在属性字段间切换焦点 |
| 属性编辑 | Enter | 确认属性值修改 |
| 属性编辑 | Esc | 取消属性值修改 |
截图与录制
| 类型 | 键位 | 效果 |
|---|---|---|
| 截图 | F12 | 截取当前视口(保存到默认路径) |
| 截图 | Ctrl + F12 | 截图并选择保存位置 |
| 截图 | Alt + F12 | 截取整个窗口 |
性能与统计
| 类型 | 键位 | 效果 |
|---|---|---|
| 性能监控 | Shift + ~ | 显示/隐藏帧率(FPS)和性能统计 |
| 性能监控 | Ctrl + Shift + I | 显示/隐藏统计信息面板 |
| 性能监控 | Ctrl + Alt + P | 性能分析器(Profiler) |
物理与仿真调试
| 类型 | 键位 | 效果 |
|---|---|---|
| 物理调试 | Ctrl + Shift + P(长按) | 显示物理调试信息 |
| 物理调试 | P | 暂停/恢复物理模拟(不影响渲染) |
| 物理调试 | Ctrl + R | 重置物理场景 |
| 碰撞检测 | Ctrl + Shift + V | 显示/隐藏速度矢量 |
Layer(层)操作
| 类型 | 键位 | 效果 |
|---|---|---|
| 层操作 | M | 移动到图层(Move to Layer) |
| 层操作 | Shift + M | 添加到图层(Add to Layer) |
| 层操作 | Ctrl + M | 管理图层 |
测量与工具
| 类型 | 键位 | 效果 |
|---|---|---|
| 测量工具 | Ctrl + Shift + M | 激活测量工具(Measure Tool) |
| 标注工具 | Ctrl + Shift + N | 添加注释/标注 |
其他实用快捷键
| 类型 | 键位 | 效果 |
|---|---|---|
| 刷新 | F5 | 刷新视口/重新加载资源 |
| 刷新 | Ctrl + F5 | 强制刷新并清除缓存 |
| 聚焦 | . (句号,在3D视口中) | 聚焦到鼠标位置 |
| 重复操作 | Shift + R | 重复上一次操作 |
| 快速保存 | Ctrl + Shift + S | 另存为(Save As) |
| 导出 | Ctrl + E | 快速导出选中内容 |
| 导入 | Ctrl + I | 快速导入文件 |
提示:
- 不同操作系统和配置可能略有差异(Mac 上 Ctrl 通常对应 Cmd 键)
- 在 Isaac Sim 的
Edit > Preferences > Keyboard Shortcuts中可以查看和自定义所有快捷键 - 建议在训练前熟悉这些快捷键,可以显著提升工作效率
- 使用
F1键可以随时访问官方帮助文档 - **Numpad(数字小键盘)**在视角切换中非常重要,如果笔记本没有数字小键盘,可以在设置中重新映射这些快捷键
- 某些快捷键可能需要在特定上下文(如3D视口激活状态)下才能使用
2. 支持的机器人
2.1 四足机器人 (Quadruped)
| 机器人 | 环境 ID | 制造商 |
|---|---|---|
| ANYmal D | RobotLab-Isaac-Velocity-Rough-Anymal-D-v0 |
ANYbotics |
| Unitree Go2 | RobotLab-Isaac-Velocity-Rough-Unitree-Go2-v0 |
Unitree |
| Unitree B2 | RobotLab-Isaac-Velocity-Rough-Unitree-B2-v0 |
Unitree |
| Unitree A1 | RobotLab-Isaac-Velocity-Rough-Unitree-A1-v0 |
Unitree |
| Deeprobotics Lite3 | RobotLab-Isaac-Velocity-Rough-Deeprobotics-Lite3-v0 |
Deeprobotics |
| Zsibot ZSL1 | RobotLab-Isaac-Velocity-Rough-Zsibot-ZSL1-v0 |
Zsibot |
| MagicLab Dog | RobotLab-Isaac-Velocity-Rough-MagicLab-Dog-v0 |
MagicLab |
2.2 轮式机器人 (Wheeled)
| 机器人 | 环境 ID | 制造商 |
|---|---|---|
| Unitree Go2W | RobotLab-Isaac-Velocity-Rough-Unitree-Go2W-v0 |
Unitree |
| Unitree B2W | RobotLab-Isaac-Velocity-Rough-Unitree-B2W-v0 |
Unitree |
| Deeprobotics M20 | RobotLab-Isaac-Velocity-Rough-Deeprobotics-M20-v0 |
Deeprobotics |
| DDTRobot Tita | RobotLab-Isaac-Velocity-Rough-DDTRobot-Tita-v0 |
DDTRobot |
| Zsibot ZSL1W | RobotLab-Isaac-Velocity-Rough-Zsibot-ZSL1W-v0 |
Zsibot |
| MagicLab Dog-W | RobotLab-Isaac-Velocity-Rough-MagicLab-Dog-W-v0 |
MagicLab |
2.3 人形机器人 (Humanoid)
| 机器人 | 环境 ID | 制造商 |
|---|---|---|
| Unitree G1 | RobotLab-Isaac-Velocity-Rough-Unitree-G1-v0 |
Unitree |
| Unitree H1 | RobotLab-Isaac-Velocity-Rough-Unitree-H1-v0 |
Unitree |
| FFTAI GR1T1 | RobotLab-Isaac-Velocity-Rough-FFTAI-GR1T1-v0 |
FFTAI |
| FFTAI GR1T2 | RobotLab-Isaac-Velocity-Rough-FFTAI-GR1T2-v0 |
FFTAI |
| Booster T1 | RobotLab-Isaac-Velocity-Rough-Booster-T1-v0 |
Booster |
| RobotEra Xbot | RobotLab-Isaac-Velocity-Rough-RobotEra-Xbot-v0 |
RobotEra |
| Openloong Loong | RobotLab-Isaac-Velocity-Rough-Openloong-Loong-v0 |
Openloong |
| RoboParty ATOM01 | RobotLab-Isaac-Velocity-Rough-RoboParty-ATOM01-v0 |
RoboParty |
| MagicLab Bot-Gen1 | RobotLab-Isaac-Velocity-Rough-MagicLab-Bot-Gen1-v0 |
MagicLab |
| MagicLab Bot-Z1 | RobotLab-Isaac-Velocity-Rough-MagicLab-Bot-Z1-v0 |
MagicLab |
提示: 所有环境都支持
Rough(崎岖地形)和Flat(平地)两种地形配置
3. 环境准备
3.1 步骤 1: 安装 Isaac Lab
参考我之前的文章从Isaac到强化学习训练: Isaac Sim 与 Isaac Lab 安装指南(2025年12月 · 全系显卡适配)
3.2 步骤 2: 安装 Robot Lab
# 1. 克隆 Robot Lab(在 IsaacLab 目录外)
cd ~
git clone https://github.com/fan-ziqi/robot_lab.git
cd robot_lab
# 2. 激活 Isaac Lab 环境
conda activate isaaclab
# 3. 安装 Robot Lab 扩展
python -m pip install -e source/robot_lab
# 4. 验证安装
python scripts/tools/list_envs.py
如果安装成功,你会看到所有可用环境的列表。
深入理解:安装配置详解
当你运行 python -m pip install -e source/robot_lab 时,实际上是在执行一个可编辑模式安装(editable install)。让我们深入分析安装过程中涉及的关键配置文件。
setup.py - 安装脚本
source/robot_lab/setup.py 是 Python 包的安装脚本,负责定义包的元数据和依赖关系:
# Copyright (c) 2024-2025 Ziqi Fan
# SPDX-License-Identifier: Apache-2.0
"""Installation script for the 'robot_lab' python package."""
# ============================================================
# 导入必要的模块
# ============================================================
import os
import toml # 用于读取 TOML 格式的配置文件
from setuptools import setup # Python 包的安装工具
# ============================================================
# 获取当前脚本(setup.py)所在的目录路径
# ============================================================
# __file__ 是当前脚本的文件路径
# os.path.realpath() 解析符号链接,获取真实路径
# os.path.dirname() 获取文件所在的目录
EXTENSION_PATH = os.path.dirname(os.path.realpath(__file__))
# ============================================================
# 读取 extension.toml 文件中的元数据
# ============================================================
# extension.toml 包含包的版本、作者、描述等信息
# 使用 toml.load() 解析 TOML 文件并返回字典
EXTENSION_TOML_DATA = toml.load(os.path.join(EXTENSION_PATH, "config", "extension.toml"))
# ============================================================
# 定义安装时需要自动安装的依赖包列表
# ============================================================
INSTALL_REQUIRES = [
# -------------------- 基础依赖 --------------------
"psutil", # 系统和进程监控工具
# 用途:监控 CPU、内存、GPU 使用情况,训练时显示资源占用
"colorama", # 跨平台终端彩色输出库
# 用途:美化命令行输出,为日志添加颜色(错误红色、警告黄色等)
"xacrodoc", # URDF/Xacro 机器人描述文件处理工具
# 用途:解析和处理机器人模型的 URDF/Xacro 文件
# -------------------- AMP 运动模仿相关 --------------------
"numpy", # 数值计算基础库
# 用途:数组运算、矩阵计算、处理运动数据
"pandas", # 数据分析和处理库
# 用途:读取和处理 CSV 格式的运动捕捉数据
"pinocchio", # 高性能机器人动力学库(C++ + Python 绑定)
# 用途:正向/逆向运动学计算、动力学仿真、运动重定向
# 在 BeyondMimic 中用于将人类动作映射到机器人
# -------------------- 强化学习框架 --------------------
"cusrl[all]", # 自定义强化学习框架
# [all] 表示安装所有可选依赖(torch, tensorboard, wandb 等)
# 用途:提供 PPO、SAC 等强化学习算法实现
]
# ============================================================
# 执行包安装配置
# ============================================================
setup(
# -------------------- 基本信息 --------------------
name="robot_lab", # 包名,安装后可通过 import robot_lab 导入
packages=["robot_lab"], # 要安装的 Python 包列表
# -------------------- 作者和维护者信息 --------------------
# 从 extension.toml 中读取
author=EXTENSION_TOML_DATA["package"]["author"], # 作者名
maintainer=EXTENSION_TOML_DATA["package"]["maintainer"], # 维护者名
url=EXTENSION_TOML_DATA["package"]["repository"], # 项目主页 URL
# -------------------- 版本和描述 --------------------
version=EXTENSION_TOML_DATA["package"]["version"], # 版本号 (如 2.3.0)
description=EXTENSION_TOML_DATA["package"]["description"], # 简短描述
keywords=EXTENSION_TOML_DATA["package"]["keywords"], # 关键词列表
# -------------------- 依赖和许可 --------------------
install_requires=INSTALL_REQUIRES, # 安装时自动安装的依赖列表
license="Apache License 2.0", # 开源许可证类型
# -------------------- 包配置选项 --------------------
include_package_data=True, # 包含 MANIFEST.in 中指定的非 .py 文件
# 如配置文件 (.yaml, .toml)、模型文件 (.usd, .urdf) 等
python_requires=">=3.10", # 要求 Python 版本至少为 3.10
# Isaac Lab 需要 Python 3.10 或更高版本
# -------------------- 分类标签 --------------------
# 用于在 PyPI 上分类和搜索
classifiers=[
"Natural Language :: English", # 自然语言:英语
"Programming Language :: Python :: 3.10", # 支持 Python 3.10
"Programming Language :: Python :: 3.11", # 支持 Python 3.11
"Isaac Sim :: 4.5.0", # 兼容 Isaac Sim 4.5.0
"Isaac Sim :: 5.0.0", # 兼容 Isaac Sim 5.0.0
"Isaac Sim :: 5.1.0", # 兼容 Isaac Sim 5.1.0
],
# -------------------- 打包选项 --------------------
zip_safe=False, # 不要将包压缩为 .egg zip 文件
# False 表示以目录形式安装,保持文件结构
# 这对于包含非 Python 文件(如 USD 模型)的包很重要
)
关键要点分析:
| 配置项 | 说明 |
|--------|------|--------|
| name="robot_lab" | 包名,安装后可通过 import robot_lab 导入 |
| install_requires | 自动安装的依赖列表 |
| python_requires=">=3.10" | 要求 Python 3.10+ |
| include_package_data=True | 包含非 .py 文件(如配置文件、模型文件) |
| zip_safe=False | 不打包为 zip,保持文件结构(重要!) |
让我们深入了解每个依赖项的作用:
基础依赖
| 包名 | 版本要求 | 用途 | 安装大小 |
|---|---|---|---|
| psutil | 最新 | 监控系统资源(CPU、内存、GPU) 在训练时显示资源使用情况 |
~500 KB |
| colorama | 最新 | 跨平台终端彩色输出 美化日志和错误信息 |
~30 KB |
| xacrodoc | 最新 | 解析和处理 URDF/Xacro 机器人描述文件 用于机器人模型加载 |
~100 KB |
运动模仿依赖(BeyondMimic)
| 包名 | 版本要求 | 用途 | 安装大小 |
|---|---|---|---|
| numpy | 最新 | 数值计算基础库 处理运动数据、张量操作 |
~20 MB |
| pandas | 最新 | 数据处理和分析 读取/处理 CSV 格式的运动数据 |
~40 MB |
| pinocchio | 最新 | 高性能机器人动力学库 用于运动重定向、正/逆运动学计算 |
~50 MB |
Pinocchio 特别说明:
- 基于 C++ 实现,性能极高
- 支持 URDF、USD 等多种格式
- 提供正向/逆向运动学、动力学计算
- 在 BeyondMimic 中用于将人类动作映射到机器人
强化学习框架
| 包名 | 版本要求 | 用途 | 安装大小 |
|---|---|---|---|
| cusrl[all] | 最新 | 自定义强化学习框架 提供 PPO、SAC 等算法实现 |
~10 MB |
cusrl 的可选依赖:
# [all] 会安装以下所有可选依赖:
- torch # PyTorch 深度学习框架(通常已由 Isaac Lab 安装)
- tensorboard # 训练可视化
- wandb # 实验跟踪(可选)
- gym # 环境接口(已被 gymnasium 替代)
3. 快速开始
3.1 示例 1: 训练四足机器人(Unitree Go2)
3.1.1 训练
# 激活环境
conda activate isaaclab
# 进入 robot_lab 目录
cd ~/robot_lab
# 开始训练(无头模式,适合服务器)
python scripts/reinforcement_learning/rsl_rl/train.py \
--task=RobotLab-Isaac-Velocity-Rough-Unitree-Go2-v0 \
--headless \
--num_envs 4096
# 或者使用 GUI 模式(适合本地开发)
python scripts/reinforcement_learning/rsl_rl/train.py \
--task=RobotLab-Isaac-Velocity-Rough-Unitree-Go2-v0 \
--num_envs 512
参数说明:
--task: 环境 ID--headless: 无头模式(不显示 GUI)--num_envs: 并行环境数量(根据 GPU 显存调整)
训练日志保存在 logs/rsl_rl/<task_name>/<timestamp> 目录。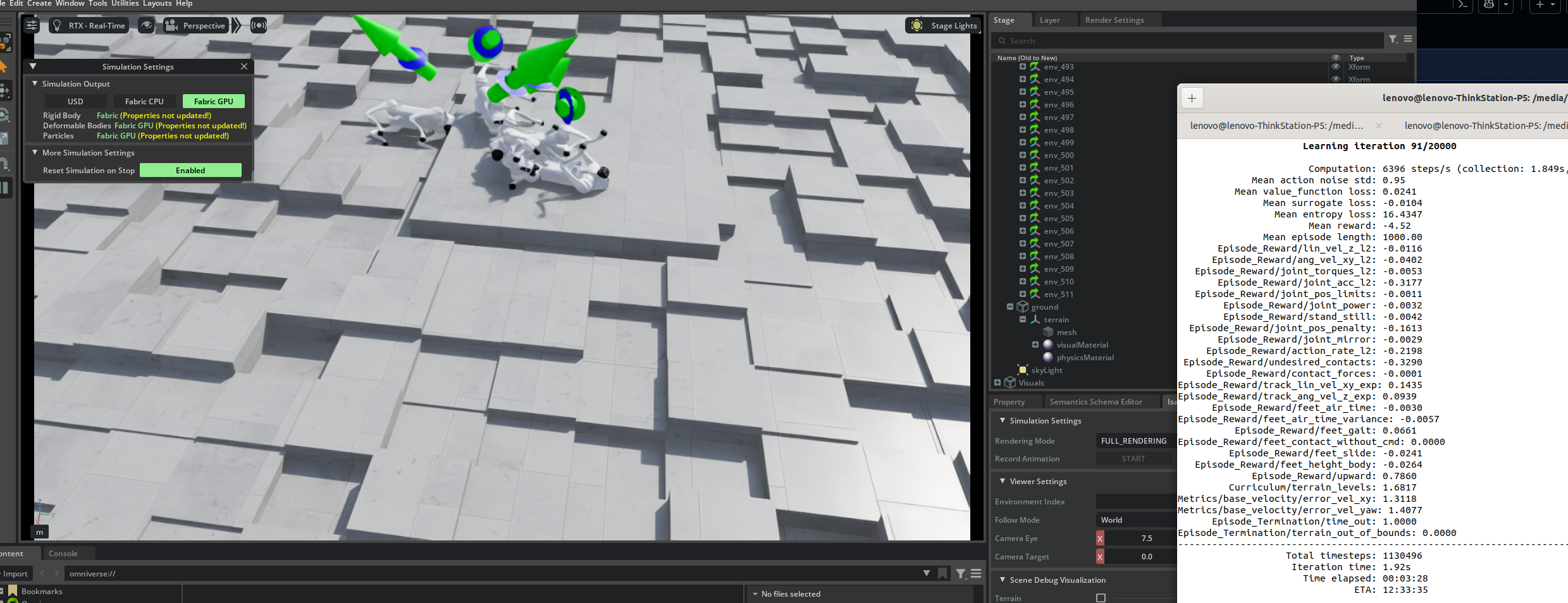
3.1.2 监控训练
在新终端中启动 TensorBoard:
cd ~/robot_lab
tensorboard --logdir=logs
在浏览器中打开 http://localhost:6006 查看训练曲线。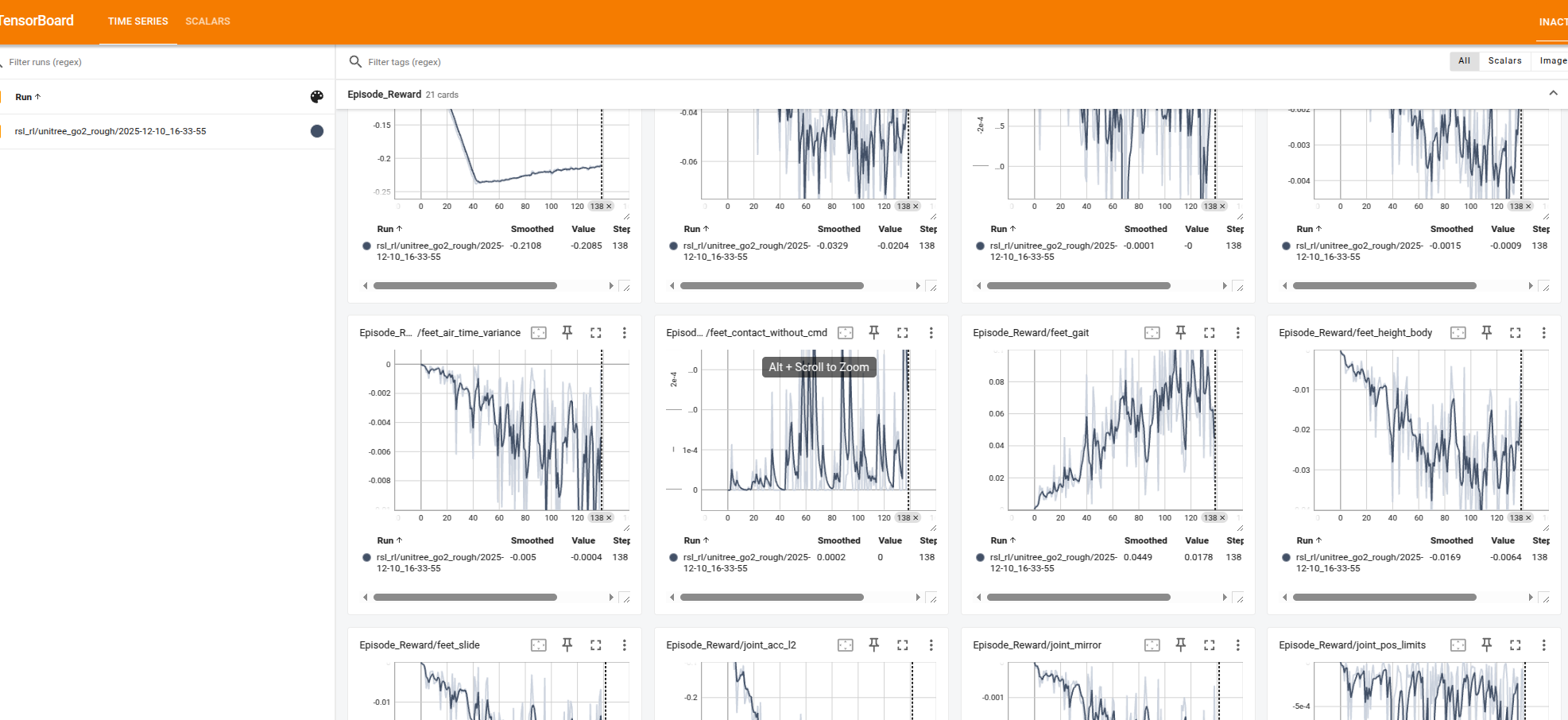
3.1.3 测试策略
# 测试训练好的策略
python scripts/reinforcement_learning/rsl_rl/play.py \
--task=RobotLab-Isaac-Velocity-Rough-Unitree-Go2-v0 \
--checkpoint /media/bigdisk/robot_lab/logs/rsl_rl/unitree_go2_rough/2025-12-10_16-33-55/model_2400.pt \
--num_envs 64
# 使用键盘控制单个机器人
python scripts/reinforcement_learning/rsl_rl/play.py \
--task=RobotLab-Isaac-Velocity-Rough-Unitree-Go2-v0 \
--checkpoint /media/bigdisk/robot_lab/logs/rsl_rl/unitree_go2_rough/2025-12-10_16-33-55/model_2400.pt \
--num_envs 1 \
--keyboard
键盘控制按键:
====================== ========================= ========================
命令 正向按键 反向按键
====================== ========================= ========================
X 轴移动 Numpad 8 / Arrow Up Numpad 2 / Arrow Down
Y 轴移动 Numpad 4 / Arrow Right Numpad 6 / Arrow Left
Z 轴旋转 Numpad 7 / Z Numpad 9 / X
====================== ========================= ========================
3.1.4 录制视频
# 录制 200 帧的视频(需要安装 ffmpeg)
python scripts/reinforcement_learning/rsl_rl/play.py \
--task=RobotLab-Isaac-Velocity-Rough-Unitree-Go2-v0 \
--num_envs 4 \
--video \
--video_length 200
视频保存在 logs/rsl_rl/<task_name>/videos/ 目录。
3.2 示例 2: 训练人形机器人(Unitree G1)
3.2.1 基础速度控制
# 训练
python scripts/reinforcement_learning/rsl_rl/train.py \
--task=RobotLab-Isaac-Velocity-Rough-Unitree-G1-v0 \
--headless
# 测试
python scripts/reinforcement_learning/rsl_rl/play.py \
--task=RobotLab-Isaac-Velocity-Rough-Unitree-G1-v0
强化学习实现运动控制的基本流程为:
Train → Play → Sim2Sim → Sim2Real
Train:在 Isaac Lab 任务上并行仿真训练策略(默认无界面更快)
Play:加载训练好的 checkpoint 在仿真中回放/可视化
Sim2Sim:把导出的策略放到其它仿真器(例如 Mujoco)验证迁移
Sim2Real:把策略部署到实物机器人(需调试模式/安全防护)
3.2.2 模仿策略学习
# 下载 LAFAN1 数据集(已重定向到 Unitree G1)
# 从 HuggingFace 下载:https://huggingface.co/datasets/lvhaidong/LAFAN1_Retargeting_Dataset
# 或使用自己的 .csv 运动数据
步骤 2: 转换运动数据
# 将 CSV 转换为 NPZ 格式
python scripts/tools/beyondmimic/csv_to_npz.py \
-f path/to/motion.csv \
--input_fps 60 \
--headless
# 预览运动
python scripts/tools/beyondmimic/replay_npz.py \
-f path/to/motion.npz
步骤 3: 训练模仿策略
# 训练
python scripts/reinforcement_learning/rsl_rl/train.py \
--task=RobotLab-Isaac-BeyondMimic-Flat-Unitree-G1-v0 \
--headless
# 测试(同时播放 2 个不同的动作)
python scripts/reinforcement_learning/rsl_rl/play.py \
--task=RobotLab-Isaac-BeyondMimic-Flat-Unitree-G1-v0 \
--num_envs 2
3.3 示例 3: AMP 舞蹈动作学习
对抗性运动先验(AMP)可以学习更自然的运动模式。
# 训练(使用 skrl 框架)
python scripts/reinforcement_learning/skrl/train.py \
--task=RobotLab-Isaac-G1-AMP-Dance-Direct-v0 \
--algorithm AMP \
--headless
# 测试(32 个机器人同时跳舞)
python scripts/reinforcement_learning/skrl/play.py \
--task=RobotLab-Isaac-G1-AMP-Dance-Direct-v0 \
--algorithm AMP \
--num_envs 32
4. 高级功能
4.1 多 GPU 训练
4.1.1 单机多卡
# 使用 2 个 GPU 训练
python -m torch.distributed.run \
--nnodes=1 \
--nproc_per_node=2 \
scripts/reinforcement_learning/rsl_rl/train.py \
--task=RobotLab-Isaac-Velocity-Rough-Unitree-Go2-v0 \
--headless \
--distributed
4.1.2 多机多卡
主节点(IP: 192.168.1.100):
python -m torch.distributed.run \
--nproc_per_node=2 \
--nnodes=2 \
--node_rank=0 \
--rdzv_id=123 \
--rdzv_backend=c10d \
--rdzv_endpoint=localhost:5555 \
scripts/reinforcement_learning/rsl_rl/train.py \
--task=RobotLab-Isaac-Velocity-Rough-Unitree-Go2-v0 \
--headless \
--distributed
从节点(IP: 192.168.1.101):
python -m torch.distributed.run \
--nproc_per_node=2 \
--nnodes=2 \
--node_rank=1 \
--rdzv_id=123 \
--rdzv_backend=c10d \
--rdzv_endpoint=192.168.1.100:5555 \
scripts/reinforcement_learning/rsl_rl/train.py \
--task=RobotLab-Isaac-Velocity-Rough-Unitree-Go2-v0 \
--headless \
--distributed
4.2 对称性数据增强
利用机器人的对称性提升训练效率:
# 训练 ANYmal D(使用对称性增强)
python scripts/reinforcement_learning/rsl_rl/train.py \
--task=RobotLab-Isaac-Velocity-Rough-Anymal-D-v0 \
--headless \
--agent=rsl_rl_with_symmetry_cfg_entry_point \
--run_name=ppo_with_symmetry \
agent.algorithm.symmetry_cfg.use_data_augmentation=true
# 测试
python scripts/reinforcement_learning/rsl_rl/play.py \
--task=RobotLab-Isaac-Velocity-Rough-Anymal-D-v0 \
--agent=rsl_rl_with_symmetry_cfg_entry_point \
--run_name=ppo_with_symmetry
4.3 教师-学生蒸馏
将复杂策略压缩到轻量级网络:
# 步骤 1: 训练教师网络
python scripts/reinforcement_learning/rsl_rl/train.py \
--task=RobotLab-Isaac-Velocity-Flat-Anymal-D-v0 \
--headless \
--run_name=teacher
# 步骤 2: 蒸馏到学生网络
python scripts/reinforcement_learning/rsl_rl/train.py \
--task=RobotLab-Isaac-Velocity-Flat-Anymal-D-v0 \
--headless \
--agent=rsl_rl_distillation_cfg_entry_point \
--load_run teacher \
--run_name=student
# 步骤 3: 测试学生网络
python scripts/reinforcement_learning/rsl_rl/play.py \
--task=RobotLab-Isaac-Velocity-Flat-Anymal-D-v0 \
--agent=rsl_rl_distillation_cfg_entry_point \
--load_run student
4.4 恢复训练
# 从最新的检查点恢复训练
python scripts/reinforcement_learning/rsl_rl/train.py \
--task=RobotLab-Isaac-Velocity-Rough-Unitree-Go2-v0 \
--headless \
--resume \
--load_run <run_folder_name>
# 从指定检查点恢复
python scripts/reinforcement_learning/rsl_rl/train.py \
--task=RobotLab-Isaac-Velocity-Rough-Unitree-Go2-v0 \
--headless \
--resume \
--load_run <run_folder_name> \
--checkpoint /path/to/model_5000.pt
4.5 特技动作训练
训练 Unitree A1 倒立:
# 训练
python scripts/reinforcement_learning/rsl_rl/train.py \
--task=RobotLab-Isaac-Velocity-Flat-HandStand-Unitree-A1-v0 \
--headless
# 测试
python scripts/reinforcement_learning/rsl_rl/play.py \
--task=RobotLab-Isaac-Velocity-Flat-HandStand-Unitree-A1-v0
5. 自定义机器人
5.1 项目结构
robot_lab/
├── source/
│ └── robot_lab/
│ ├── assets/ # 机器人资产定义
│ │ ├── __init__.py
│ │ └── unitree.py # Unitree 机器人定义
│ ├── tasks/ # 任务环境
│ │ └── manager_based/
│ │ └── locomotion/
│ │ └── velocity/
│ │ ├── velocity_env_cfg.py # 基础任务配置
│ │ └── config/
│ │ └── unitree_a1/
│ │ ├── __init__.py # 环境注册
│ │ ├── flat_env_cfg.py
│ │ ├── rough_env_cfg.py
│ │ └── agent/ # 训练配置
│ │ ├── rsl_rl_ppo_cfg.py
│ │ └── cusrl_ppo_cfg.py
│ └── ui_extension_example.py
└── scripts/
├── reinforcement_learning/
│ ├── rsl_rl/
│ │ ├── train.py
│ │ └── play.py
│ ├── cusrl/
│ └── skrl/
└── tools/
5.2 添加新机器人的步骤
5.2.1 步骤 1: 定义机器人资产
在 source/robot_lab/assets/ 创建机器人定义文件(例如 my_robot.py):
# ============================================================
# 导入必要的模块
# ============================================================
from omni.isaac.lab.actuators import ActuatorNetMLPCfg, DCMotorCfg # 执行器配置
from omni.isaac.lab.assets.articulation import ArticulationCfg # 关节机器人配置
import omni.isaac.lab.sim as sim_utils # 仿真工具
# ============================================================
# 定义机器人配置
# ============================================================
MY_ROBOT_CFG = ArticulationCfg(
# ========== 生成/加载配置 ==========
spawn=sim_utils.UsdFileCfg(
# USD 文件路径(Universal Scene Description)
# USD 是 NVIDIA Omniverse 的场景描述格式
# 包含机器人的几何形状、质量、惯性等信息
usd_path="/path/to/my_robot.usd",
# 是否激活接触传感器
# True = 机器人可以检测与环境的接触(如脚接触地面)
# 用于计算奖励(如脚接触地面奖励)和终止条件
activate_contact_sensors=True,
# ========== 刚体物理属性 ==========
rigid_props=sim_utils.RigidBodyPropertiesCfg(
# 是否禁用重力
# False = 启用重力(机器人会受到重力影响)
disable_gravity=False,
# 是否保留加速度信息
# False = 不保留(节省内存和计算)
# True = 保留加速度信息(某些高级功能需要)
retain_accelerations=False,
# 线性阻尼系数(空气阻力等)
# 0.0 = 无阻尼
linear_damping=0.0,
# 角阻尼系数(旋转阻力)
# 0.0 = 无阻尼
angular_damping=0.0,
# 最大线速度限制 (m/s)
# 1000.0 = 实际上不限制(非常大的值)
# 可以设置为合理值(如 10.0)以防止物理爆炸
max_linear_velocity=1000.0,
# 最大角速度限制 (rad/s)
# 1000.0 = 实际上不限制
max_angular_velocity=1000.0,
# 最大穿透恢复速度 (m/s)
# 当物体穿透时,物理引擎用此速度将其推出
# 较小的值 (1.0) = 更稳定但可能有轻微穿透
# 较大的值 (10.0) = 快速恢复但可能不稳定
max_depenetration_velocity=1.0,
),
# ========== 关节机器人根属性 ==========
articulation_props=sim_utils.ArticulationRootPropertiesCfg(
# 是否启用自碰撞检测
# False = 机器人的不同部分可以穿透(更快但不真实)
# True = 检测并阻止自碰撞(更真实但更慢)
enabled_self_collisions=False,
# 位置求解器迭代次数
# 更多迭代 = 更精确的物理模拟,但更慢
# 4 = 默认值,适合大多数情况
# 增加到 8-16 可以提高精度(但降低性能)
solver_position_iteration_count=4,
# 速度求解器迭代次数
# 0 = 只求解位置,不单独求解速度
# 1-4 = 更精确的速度计算
solver_velocity_iteration_count=0,
),
),
# ========== 初始状态配置 ==========
init_state=ArticulationCfg.InitialStateCfg(
# 机器人初始位置 (x, y, z) 单位:米
# (0.0, 0.0, 0.6) = 原点上方 0.6 米
# z 值通常设置为机器人站立时的高度
pos=(0.0, 0.0, 0.6),
# 关节初始位置(弧度)
# 使用正则表达式匹配关节名称
joint_pos={
# 髋关节(hip)= 0.0 rad(伸直)
".*_hip_joint": 0.0,
# 大腿关节(thigh)= 0.7 rad(约 40 度)
# 正值 = 向前弯曲
".*_thigh_joint": 0.7,
# 小腿关节(calf)= -1.4 rad(约 -80 度)
# 负值 = 向后弯曲
# 0.7 + (-1.4) = -0.7,形成站立姿态
".*_calf_joint": -1.4,
},
# 关节初始速度(rad/s)
# ".*" = 匹配所有关节
# 0.0 = 静止状态
joint_vel={".*": 0.0},
),
# ========== 执行器配置 ==========
actuators={
# 定义一个名为 "legs" 的执行器组
# 可以有多个组,如 {"legs": ..., "arms": ...}
"legs": DCMotorCfg(
# 使用正则表达式指定该执行器控制的关节
# 列表中的所有关节将使用相同的执行器参数
joint_names_expr=[".*_hip_joint", ".*_thigh_joint", ".*_calf_joint"],
# 力矩限制 (N·m)
# 33.5 = 最大输出力矩
# 应根据真实电机规格设置
effort_limit=33.5,
# 力矩饱和值 (N·m)
# 通常与 effort_limit 相同
# 超过此值将被截断
saturation_effort=33.5,
# 速度限制 (rad/s)
# 21.0 rad/s ≈ 201 RPM
# 应根据真实电机规格设置
velocity_limit=21.0,
# PD 控制器刚度(比例增益)
# 25.0 = 中等刚度
# 更大的值 = 更硬(快速响应但可能震荡)
# 更小的值 = 更软(缓慢响应但更稳定)
stiffness=25.0,
# PD 控制器阻尼(微分增益)
# 0.5 = 轻度阻尼
# 用于减少震荡,提供平滑运动
damping=0.5,
# 摩擦力系数
# 0.0 = 无摩擦(理想情况)
# 可以设置为 0.1-0.5 来模拟真实摩擦
friction=0.0,
),
},
)
5.2.2 步骤 2: 创建任务配置
在 source/robot_lab/tasks/manager_based/locomotion/velocity/config/ 创建机器人配置目录:
mkdir -p source/robot_lab/tasks/manager_based/locomotion/velocity/config/my_robot/agent
理解并行环境与 Interactive Scene
在开始编写配置之前,我们需要理解一个核心概念:强化学习训练需要大量的并行环境来加速学习。
想象一下,如果只有一个机器人在学习走路,它每走一步、摔倒、爬起来,都需要时间。但如果有 4096 个机器人同时在 4096 个独立的环境中练习,AI 就能同时从 4096 个机器人的经验中学习,训练速度提升 4096 倍!这就是 Isaac Lab 中 Interactive Scene(交互式场景)的作用。
Interactive Scene 是什么?
Interactive Scene 是 Isaac Lab 提供的场景管理器,它的核心功能是:
- 定义一次,自动克隆:你只需定义一次场景配置(包括机器人、地面、传感器等),Scene 会自动将这些资产复制到成千上万个环境中
- 智能命名:每个环境都有独立的命名空间(namespace),确保不同环境的物体互不干扰
- 并行仿真:所有环境同时运行,充分利用 GPU 的并行计算能力
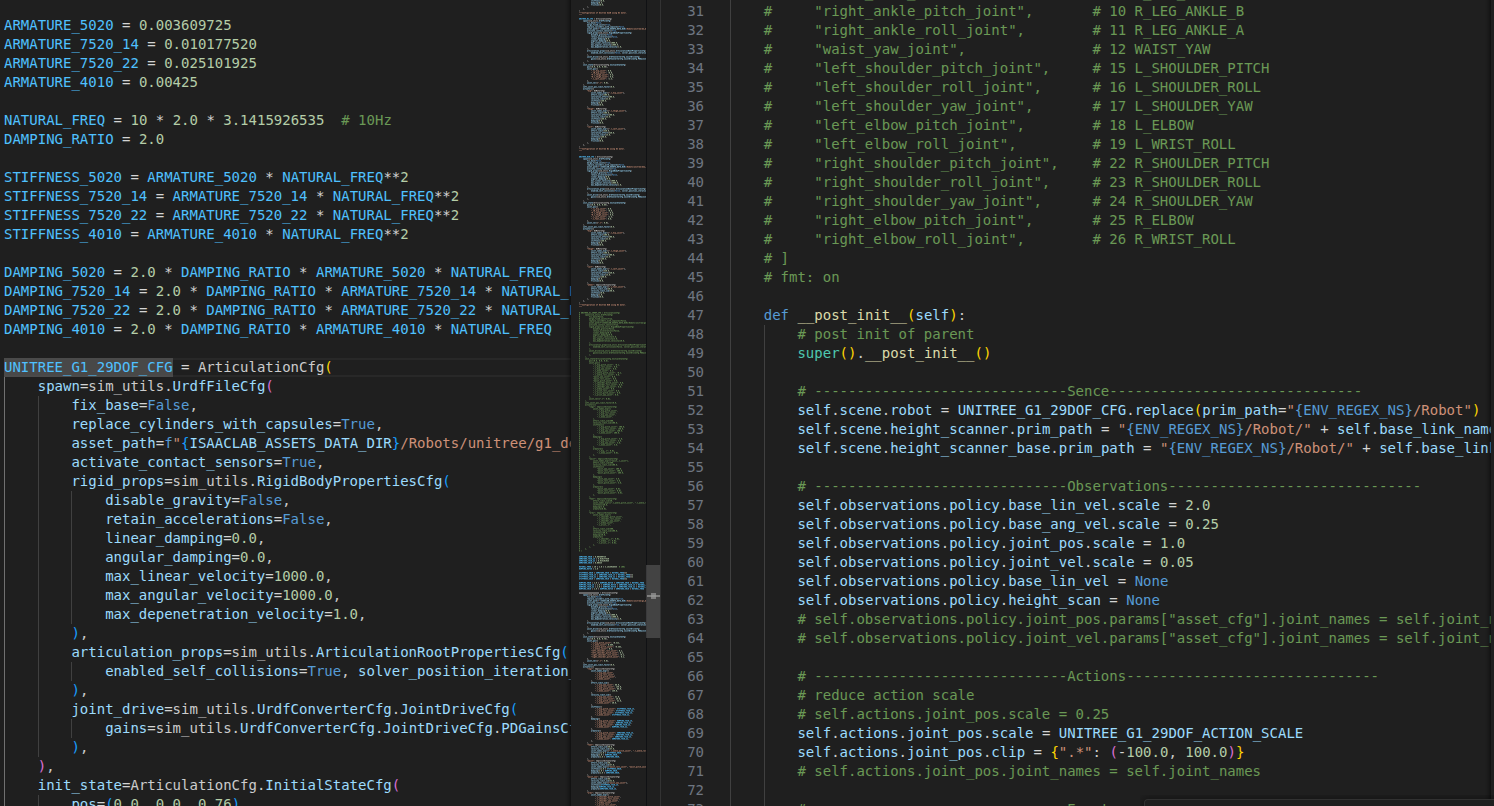
{ENV_REGEX_NS} 魔法变量:实现自动克隆的关键
在配置文件中,你会频繁看到 {ENV_REGEX_NS} 这个特殊的占位符。这是 Isaac Lab 中最重要的概念之一。
{ENV_REGEX_NS} 的作用:
当你写下 prim_path="{ENV_REGEX_NS}/Robot" 时,Isaac Lab 会在创建环境时自动将它替换为每个环境的唯一路径:
# 你写的配置
prim_path="{ENV_REGEX_NS}/Robot"
# Isaac Lab 自动替换(假设创建 4 个环境)
# 环境 0: prim_path="/World/envs/env_0/Robot"
# 环境 1: prim_path="/World/envs/env_1/Robot"
# 环境 2: prim_path="/World/envs/env_2/Robot"
# 环境 3: prim_path="/World/envs/env_3/Robot"
为什么需要 {ENV_REGEX_NS}?
| 资产类型 | 是否需要 {ENV_REGEX_NS} | 原因 |
|---|---|---|
| 机器人 | ✅ 必须使用 | 每个环境的机器人需要独立控制、独立状态(位置、速度、关节角度) |
| 传感器(如高度扫描器) | ✅ 必须使用 | 每个环境的传感器需要独立读取数据 |
| 地面 | ❌ 不需要 | 所有环境共享同一个无限大的平面 |
| 灯光 | ❌ 不需要 | 所有环境共享同一个光源 |
可视化理解(以 4 个环境为例):
/World/ ← USD Stage 根节点
│
├── defaultGroundPlane ← 共享:所有环境使用同一个地面
├── Light ← 共享:所有环境使用同一个灯光
│
└── envs/ ← 环境容器
├── env_0/ ← 环境 0 的命名空间
│ └── Robot ← 环境 0 的机器人(独立)
│ ├── base
│ ├── FR_hip_joint
│ └── ...
│
├── env_1/ ← 环境 1 的命名空间
│ └── Robot ← 环境 1 的机器人(独立)
│
├── env_2/ ← 环境 2 的命名空间
│ └── Robot ← 环境 2 的机器人(独立)
│
└── env_3/ ← 环境 3 的命名空间
└── Robot ← 环境 3 的机器人(独立)
在下面的配置代码中,你会看到:
self.scene.robot = MY_ROBOT_CFG.replace(prim_path="{ENV_REGEX_NS}/Robot")- 为每个环境创建独立的机器人self.scene.height_scanner.prim_path = "{ENV_REGEX_NS}/Robot/" + self.base_link_name- 为每个环境的机器人安装独立的高度扫描器
这种设计使得我们可以用一份配置轻松创建成千上万个并行环境,大幅加速强化学习训练!这个具体的申明,包含ContactSensorCfg 都在source/robot_lab/robot_lab/tasks/manager_based/locomotion/velocity/velocity_env_cfg.py
首先创建 rough_env_cfg.py(包含完整配置):
# Copyright (c) 2024-2025 Your Name
# SPDX-License-Identifier: Apache-2.0
# ============================================================
# 导入必要的模块
# ============================================================
from isaaclab.utils import configclass # Isaac Lab 的配置类装饰器
from robot_lab.assets import MY_ROBOT_CFG # 导入我们定义的机器人配置
from robot_lab.tasks.manager_based.locomotion.velocity.velocity_env_cfg import (
LocomotionVelocityRoughEnvCfg, # 导入基础的速度跟踪环境配置
)
# ============================================================
# 定义崎岖地形环境配置类
# ============================================================
@configclass # 使用 @configclass 装饰器标记这是一个配置类
class MyRobotRoughEnvCfg(LocomotionVelocityRoughEnvCfg):
"""
自定义机器人的崎岖地形速度跟踪环境配置
继承自 LocomotionVelocityRoughEnvCfg 基类
注意:在 Robot Lab 中,Rough 配置是基础配置,包含所有功能
Flat 配置继承自 Rough,然后禁用一些不需要的功能
"""
# ========== 定义关键链接名称 ==========
# 这些名称必须与 USD 文件中的链接名称匹配
base_link_name = "base" # 机器人基座链接名称
foot_link_name = ".*_foot" # 脚部链接名称(使用正则表达式匹配所有脚)
# ========== 定义关节名称列表 ==========
# 四足机器人的 12 个关节(4条腿 × 3个关节/腿)
# FR = 右前腿, FL = 左前腿, RR = 右后腿, RL = 左后腿
joint_names = [
"FR_hip_joint", "FR_thigh_joint", "FR_calf_joint", # 右前腿
"FL_hip_joint", "FL_thigh_joint", "FL_calf_joint", # 左前腿
"RR_hip_joint", "RR_thigh_joint", "RR_calf_joint", # 右后腿
"RL_hip_joint", "RL_thigh_joint", "RL_calf_joint", # 左后腿
]
def __post_init__(self):
"""
后初始化方法,在配置对象创建后自动调用
用于设置机器人特定的配置
"""
# ========== 调用父类的初始化 ==========
# 必须先调用父类初始化,加载默认配置
super().__post_init__()
# ========== 场景配置 ==========
# 设置机器人资产
# replace() 创建配置的副本并修改 prim_path
# {ENV_REGEX_NS} 会被替换为 env_0, env_1, ... env_N
self.scene.robot = MY_ROBOT_CFG.replace(prim_path="{ENV_REGEX_NS}/Robot")
# 配置高度扫描器的位置(用于检测地形高度)
# 安装在机器人基座上
self.scene.height_scanner.prim_path = "{ENV_REGEX_NS}/Robot/" + self.base_link_name
# ========== 观察空间配置 ==========
# 调整观察值的缩放,使其在合适的范围内
# 基座线速度缩放
# 2.0 = 放大 2 倍,使网络更容易学习速度信息
self.observations.policy.base_lin_vel.scale = 2.0
# 基座角速度缩放
# 0.25 = 缩小到 1/4,因为角速度通常比线速度大
self.observations.policy.base_ang_vel.scale = 0.25
# 关节位置和速度缩放
self.observations.policy.joint_pos.scale = 1.0 # 不缩放
self.observations.policy.joint_vel.scale = 0.05 # 缩小到 1/20
# 指定观察的关节
self.observations.policy.joint_pos.params["asset_cfg"].joint_names = self.joint_names
self.observations.policy.joint_vel.params["asset_cfg"].joint_names = self.joint_names
# ========== 动作空间配置 ==========
# 减小动作缩放,使控制更精细
# hip 关节使用更小的缩放(0.125)
# 其他关节使用 0.25
self.actions.joint_pos.scale = {
".*_hip_joint": 0.125, # 髋关节缩放
"^(?!.*_hip_joint).*": 0.25 # 其他关节缩放(使用负向前瞻正则)
}
# 动作裁剪范围
self.actions.joint_pos.clip = {".*": (-100.0, 100.0)}
# 指定控制的关节
self.actions.joint_pos.joint_names = self.joint_names
# ========== 奖励权重配置 ==========
# 调整各项奖励的权重,平衡不同目标
# 根部惩罚
self.rewards.lin_vel_z_l2.weight = -2.0 # 惩罚 Z 方向速度(防止跳跃)
self.rewards.ang_vel_xy_l2.weight = -0.05 # 惩罚俯仰/滚转角速度
self.rewards.flat_orientation_l2.weight = 0 # 不惩罚方向偏差
self.rewards.base_height_l2.weight = 0 # 不惩罚高度偏差(Rough地形下)
# 关节惩罚
self.rewards.joint_torques_l2.weight = -2.5e-5 # 惩罚关节力矩(降低能耗)
self.rewards.joint_acc_l2.weight = -2.5e-7 # 惩罚关节加速度(平滑运动)
# ========== 命令范围配置 ==========
# 定义训练时随机生成的目标速度范围
# 根据机器人的能力调整这些范围
self.commands.base_velocity.ranges.lin_vel_x = (-1.0, 1.5) # X方向: -1~1.5 m/s
self.commands.base_velocity.ranges.lin_vel_y = (-0.5, 0.5) # Y方向: -0.5~0.5 m/s
self.commands.base_velocity.ranges.ang_vel_z = (-1.0, 1.0) # 旋转: -1~1 rad/s
然后创建 flat_env_cfg.py(继承 rough 并禁用某些功能):
# Copyright (c) 2024-2025 Your Name
# SPDX-License-Identifier: Apache-2.0
# ============================================================
# 导入必要的模块
# ============================================================
from isaaclab.utils import configclass # Isaac Lab 的配置类装饰器
from .rough_env_cfg import MyRobotRoughEnvCfg # 导入 Rough 环境配置
# ============================================================
# 定义平地环境配置类
# ============================================================
@configclass # 使用 @configclass 装饰器
class MyRobotFlatEnvCfg(MyRobotRoughEnvCfg):
"""
自定义机器人的平地速度跟踪环境配置
继承自 MyRobotRoughEnvCfg,禁用崎岖地形相关功能
在 Robot Lab 中,Flat 配置通过继承 Rough 配置,
然后禁用不需要的功能(如地形生成器、高度扫描器等)
"""
def __post_init__(self):
"""
后初始化方法,在配置对象创建后自动调用
禁用 Rough 环境中的地形相关功能
"""
# ========== 调用父类的初始化 ==========
# 先执行 Rough 配置的所有设置
super().__post_init__()
# ========== 修改地形为平地 ==========
# "plane" = 平坦的无限平面
self.scene.terrain.terrain_type = "plane"
# 禁用地形生成器(不需要生成崎岖地形)
self.scene.terrain.terrain_generator = None
# ========== 禁用高度扫描器 ==========
# 平地不需要扫描地形高度
self.scene.height_scanner = None
# 从观察空间中移除高度扫描数据
self.observations.policy.height_scan = None
self.observations.critic.height_scan = None
# ========== 禁用地形课程学习 ==========
# 平地不需要课程学习
self.curriculum.terrain_levels = None
# ========== 调整奖励配置 ==========
# 在平地上,可以启用基座高度奖励
# 将传感器配置设为 None(使用真实高度而非扫描高度)
self.rewards.base_height_l2.params["sensor_cfg"] = None
# ========== 自动禁用权重为0的奖励 ==========
# 如果是 MyRobotFlatEnvCfg 类(而非子类),
# 自动禁用所有权重为 0 的奖励项以提高性能
if self.__class__.__name__ == "MyRobotFlatEnvCfg":
self.disable_zero_weight_rewards()
配置继承关系说明:
LocomotionVelocityRoughEnvCfg (Isaac Lab 基类)
↑
│ 继承
│
MyRobotRoughEnvCfg (完整配置:地形生成、高度扫描、所有传感器)
↑
│ 继承并禁用部分功能
│
MyRobotFlatEnvCfg (简化配置:平地、无高度扫描)
5.2.3 步骤 3: 配置训练参数
在 agent/ 目录创建 rsl_rl_ppo_cfg.py:
# Copyright (c) 2024-2025 Your Name
# SPDX-License-Identifier: Apache-2.0
# ============================================================
# 导入必要的模块
# ============================================================
from isaaclab.utils import configclass # Isaac Lab 的配置类装饰器
from isaaclab_rl.rsl_rl import (
RslRlOnPolicyRunnerCfg, # 在线策略训练器配置(PPO 是在线策略算法)
RslRlPpoActorCriticCfg, # Actor-Critic 神经网络配置
RslRlPpoAlgorithmCfg, # PPO 算法超参数配置
)
# ============================================================
# 定义崎岖地形环境的 PPO 训练配置(基础配置)
# ============================================================
@configclass # 使用 @configclass 装饰器标记这是一个配置类
class MyRobotRoughPPORunnerCfg(RslRlOnPolicyRunnerCfg):
"""
自定义机器人崎岖地形环境的 PPO 训练器配置
注意:与环境配置一致,Rough 配置是基础配置
Flat 配置继承自 Rough 配置
"""
# ========== 训练器基本参数 ==========
# 每个环境的采样步数
# 24 = 每次收集 24 步数据后进行一次策略更新
# 总样本数 = num_steps_per_env × 环境数量
# 例如:24 × 4096 = 98,304 个样本/次更新
num_steps_per_env = 24
# 最大训练迭代次数
# 20000 = 训练 20000 次策略更新(崎岖地形需要更多训练)
# 总训练步数 = max_iterations × num_steps_per_env × 环境数量
# 例如:20000 × 24 × 4096 ≈ 1.97B 步
max_iterations = 20000
# 模型保存间隔
# 100 = 每 100 次迭代保存一次模型检查点
# 保存的模型可用于恢复训练或部署
save_interval = 100
# 实验名称
# 用于组织日志和保存的模型
# 格式:logs/rsl_rl/{experiment_name}/{timestamp}/
experiment_name = "my_robot_rough"
# ========== Actor-Critic 神经网络配置 ==========
policy = RslRlPpoActorCriticCfg(
# 初始化噪声标准差
# 1.0 = 在训练初期为动作添加较大噪声,促进探索
# 随着训练进行,噪声会逐渐减小
init_noise_std=1.0,
# Actor 观察归一化
# False = 不对 actor 的输入观察进行归一化
# 如果观察已经在环境中缩放过,通常设为 False
actor_obs_normalization=False,
# Critic 观察归一化
# False = 不对 critic 的输入观察进行归一化
critic_obs_normalization=False,
# Actor(策略网络)隐藏层维度
# [512, 256, 128] = 三层隐藏层,从512逐渐降到128
# 输入: 观察空间 → 512 → 256 → 128 → 输出: 动作空间
# 更大的网络 = 更强的表达能力,但训练更慢
actor_hidden_dims=[512, 256, 128],
# Critic(价值网络)隐藏层维度
# 通常与 Actor 保持相同或相似的结构
# 输入: 观察空间 → 512 → 256 → 128 → 输出: 状态价值
critic_hidden_dims=[512, 256, 128],
# 激活函数
# "elu" = Exponential Linear Unit,比 ReLU 更平滑
# 其他选项: "relu", "tanh", "leaky_relu"
activation="elu",
)
# ========== PPO 算法超参数配置 ==========
algorithm = RslRlPpoAlgorithmCfg(
# 价值损失系数
# 1.0 = 价值损失和策略损失同等重要
# total_loss = policy_loss + value_loss_coef × value_loss - entropy_coef × entropy
value_loss_coef=1.0,
# 是否使用截断的价值损失
# True = 使用 PPO 的 clipped value loss,更稳定
# False = 使用普通的 MSE loss
use_clipped_value_loss=True,
# PPO 截断参数(epsilon)
# 0.2 = 限制策略更新幅度在 [1-0.2, 1+0.2] = [0.8, 1.2]
# 防止策略更新过大导致性能崩溃
# 较小的值 (0.1) = 更保守的更新
# 较大的值 (0.3) = 更激进的更新
clip_param=0.2,
# 熵正则化系数
# 0.01 = 鼓励策略保持一定随机性,促进探索
# 较大的值 (0.1) = 更多探索
# 较小的值 (0.001) = 更少探索,更确定的策略
entropy_coef=0.01,
# 每次更新的学习轮数
# 5 = 每次收集数据后,用这批数据训练 5 个 epoch
# 更多轮次 = 更充分利用数据,但可能过拟合
num_learning_epochs=5,
# Mini-batch 数量
# 4 = 将收集的数据分成 4 个 mini-batch 进行训练
# batch_size = (num_envs × num_steps_per_env) / num_mini_batches
# 例如:(4096 × 24) / 4 = 24,576
num_mini_batches=4,
# 学习率
# 1.0e-3 = 0.001,Adam 优化器的学习率
# 较大的值 (1e-2) = 更快学习,但可能不稳定
# 较小的值 (1e-4) = 更稳定,但学习较慢
learning_rate=1.0e-3,
# 学习率调度策略
# "adaptive" = 根据 KL 散度自动调整学习率
# "linear" = 线性衰减
# "constant" = 保持不变
schedule="adaptive",
# 折扣因子(gamma)
# 0.99 = 非常重视未来奖励
# 决定了算法的"远见"程度
# 较大 (0.999) = 更长远的规划
# 较小 (0.9) = 更注重短期奖励
gamma=0.99,
# GAE lambda 参数
# 0.95 = 在偏差和方差之间取得平衡
# 用于计算优势函数(Advantage function)
# 较大 (0.99) = 更低偏差,更高方差
# 较小 (0.9) = 更高偏差,更低方差
lam=0.95,
# 期望的 KL 散度
# 0.01 = 当 KL 散度超过此值时,降低学习率
# KL 散度衡量新旧策略的差异
# 用于自适应学习率调度
desired_kl=0.01,
# 梯度裁剪阈值
# 1.0 = 当梯度范数超过 1.0 时进行裁剪
# 防止梯度爆炸,提高训练稳定性
max_grad_norm=1.0,
)
# ============================================================
# 定义平地环境的 PPO 训练配置(继承自 Rough)
# ============================================================
@configclass # 使用 @configclass 装饰器
class MyRobotFlatPPORunnerCfg(MyRobotRoughPPORunnerCfg):
"""
平地环境的训练配置
继承自 MyRobotRoughPPORunnerCfg,只修改迭代次数和实验名称
与环境配置的继承关系保持一致:
- Rough 是基础配置(包含所有参数)
- Flat 继承并修改部分参数
"""
def __post_init__(self):
"""
后初始化方法,在配置对象创建后自动调用
修改平地环境特定的参数
"""
# ========== 调用父类的初始化 ==========
# 先执行 Rough 配置的所有设置
super().__post_init__()
# ========== 修改训练迭代次数 ==========
# 减少迭代次数
# 5000 = 平地环境更简单,不需要太多训练
# 相比 Rough 的 20000 次,减少了 75%
self.max_iterations = 5000
# ========== 修改实验名称 ==========
self.experiment_name = "my_robot_flat"
配置继承关系说明:
RslRlOnPolicyRunnerCfg (RSL-RL 基类)
↑
│ 继承
│
MyRobotRoughPPORunnerCfg (完整配置:所有超参数)
↑
│ 继承并修改部分参数
│
MyRobotFlatPPORunnerCfg (简化配置:更少迭代次数)
为什么这样设计?
- 与环境配置一致:Rough 是基础,Flat 是简化
- 代码复用:避免重复定义相同的超参数
- 易于维护:修改共同参数只需改 Rough 配置
- 符合项目规范:与 robot_lab 中所有机器人的配置方式一致
5.2.4 步骤 4: 注册环境
在 config/my_robot/__init__.py 注册环境:
# Copyright (c) 2024-2025 Your Name
# SPDX-License-Identifier: Apache-2.0
# ============================================================
# 导入必要的模块
# ============================================================
import gymnasium as gym # Gymnasium 是 OpenAI Gym 的升级版,用于注册和管理环境
from . import agents # 导入 agents 子模块(包含训练配置)
# ============================================================
# 注册 Gym 环境
# ============================================================
# ========== 注册平地环境 ==========
gym.register(
# 环境 ID(唯一标识符)
# 命名规则:项目名-仿真器-任务-地形-机器人-版本
# 例如:RobotLab-Isaac-Velocity-Flat-My-Robot-v0
id="RobotLab-Isaac-Velocity-Flat-My-Robot-v0",
# 入口点:指定环境类的位置
# "isaaclab.envs:ManagerBasedRLEnv" 表示:
# - 模块:isaaclab.envs
# - 类:ManagerBasedRLEnv(基于管理器的强化学习环境)
entry_point="isaaclab.envs:ManagerBasedRLEnv",
# 禁用环境检查器
# True = 跳过 Gymnasium 的环境合规性检查
# Isaac Lab 环境已经过充分测试,跳过检查可以加快启动速度
disable_env_checker=True,
# 关键字参数:传递给环境构造函数的参数
kwargs={
# ========== 环境配置入口点 ==========
# __name__ = 当前模块名(如:robot_lab.tasks....config.my_robot)
# f"{__name__}.flat_env_cfg" = robot_lab....my_robot.flat_env_cfg
# :MyRobotFlatEnvCfg = 导入该模块中的 MyRobotFlatEnvCfg 类
#
# 格式:模块路径:类名
# 这样可以延迟导入(lazy import),提高启动速度
"env_cfg_entry_point": f"{__name__}.flat_env_cfg:MyRobotFlatEnvCfg",
# ========== RSL-RL 训练配置入口点 ==========
# agents.__name__ = agents 子模块的名称
# 指向我们定义的 PPO 训练配置类
# 训练脚本会使用这个配置来初始化 RSL-RL 训练器
"rsl_rl_cfg_entry_point": f"{agents.__name__}.rsl_rl_ppo_cfg:MyRobotFlatPPORunnerCfg",
# ========== CusRL 训练配置入口点(可选)==========
# 如果你实现了 CusRL 配置,可以添加这个入口点
# CusRL 是一个实验性的强化学习框架
# "cusrl_cfg_entry_point": f"{agents.__name__}.cusrl_ppo_cfg:MyRobotFlatTrainerCfg",
},
)
# ========== 注册崎岖地形环境 ==========
gym.register(
# 环境 ID(包含 "Rough" 表示崎岖地形)
id="RobotLab-Isaac-Velocity-Rough-My-Robot-v0",
# 使用相同的环境类
entry_point="isaaclab.envs:ManagerBasedRLEnv",
# 禁用环境检查器
disable_env_checker=True,
# 指向崎岖地形的配置
kwargs={
# 崎岖地形的环境配置
# 使用 MyRobotRoughEnvCfg(启用程序化地形生成)
"env_cfg_entry_point": f"{__name__}.rough_env_cfg:MyRobotRoughEnvCfg",
# 崎岖地形的 RSL-RL 训练配置
# 使用 MyRobotRoughPPORunnerCfg(更多迭代次数)
"rsl_rl_cfg_entry_point": f"{agents.__name__}.rsl_rl_ppo_cfg:MyRobotRoughPPORunnerCfg",
# 崎岖地形的 CusRL 训练配置(可选)
# "cusrl_cfg_entry_point": f"{agents.__name__}.cusrl_ppo_cfg:MyRobotRoughTrainerCfg",
},
)
# ============================================================
# 使用方法
# ============================================================
# 注册后,可以通过以下方式创建环境:
#
# 1. 在 Python 代码中:
# import gymnasium as gym
# env = gym.make("RobotLab-Isaac-Velocity-Flat-My-Robot-v0")
#
# 2. 使用命令行训练(RSL-RL):
# python scripts/reinforcement_learning/rsl_rl/train.py \
# --task=RobotLab-Isaac-Velocity-Flat-My-Robot-v0
#
# 3. 使用命令行训练(CusRL,如果实现了):
# python scripts/reinforcement_learning/cusrl/train.py \
# --task=RobotLab-Isaac-Velocity-Flat-My-Robot-v0
注册顺序说明:
在 Robot Lab 中,通常先注册 Flat 环境,再注册 Rough 环境。这是因为:
- Flat 环境更简单,适合初期测试
- 用户通常先在平地训练,再迁移到崎岖地形
- 保持与项目其他机器人配置的一致性
多框架支持:
Robot Lab 支持多个强化学习框架:
- RSL-RL(推荐):ETH Zurich 的 PPO 实现,性能稳定
- CusRL(实验性):自定义强化学习框架
- skrl(高级):支持 AMP 等高级算法
每个框架都需要相应的配置入口点。如果你只使用 RSL-RL,可以省略其他框架的入口点。
5.2.5 步骤 5: 验证和训练
# 验证环境已注册
python scripts/tools/list_envs.py | grep "My-Robot"
# 开始训练
python scripts/reinforcement_learning/rsl_rl/train.py \
--task=RobotLab-Isaac-Velocity-Flat-My-Robot-v0 \
--headless
调优技巧
-
观察空间调整
- 增加关键传感器信息(IMU、关节状态)
- 使用历史缓冲提供时序信息
- 适当的归一化和缩放
-
奖励函数设计
- 平衡任务目标(速度跟踪)和约束(能耗、稳定性)
- 使用指数奖励处理非线性目标
- 避免奖励稀疏或过于密集
-
超参数调整
- 根据任务复杂度调整网络大小
- 增加环境数量加速训练(受 GPU 限制)
- 调整学习率和 PPO clip 范围
-
域随机化
- 添加质量、摩擦力、电机参数的随机化
- 模拟传感器噪声
- 提升 Sim2Real 迁移性能
6. 常见问题
6.1 安装问题
Q: 提示找不到 Isaac Sim
A: 确保已正确安装 Isaac Sim,并设置环境变量:
export ISAAC_SIM_PATH="/path/to/isaac-sim"
Q: pip 安装失败
A: 尝试升级 pip 和 setuptools:
python -m pip install --upgrade pip setuptools wheel
python -m pip install -e source/robot_lab
6.2 训练问题
Q: GPU 内存不足(OOM)
A: 减少并行环境数量:
python scripts/reinforcement_learning/rsl_rl/train.py \
--task=<ENV_NAME> \
--num_envs 1024 # 从 4096 减少到 1024
Q: 训练速度慢
A: 检查以下几点:
- 使用无头模式(
--headless) - 增加并行环境数
- 使用更强的 GPU
- 检查 CPU 瓶颈(增加 worker 数量)
Q: 奖励不收敛
A: 常见原因:
- 奖励函数设计不合理
- 超参数需要调整
- 观察空间不足
- 任务过于复杂(尝试简化任务)
6.3 仿真问题
Q: 机器人穿透地面或抖动
A: 调整物理参数:
rigid_props=sim_utils.RigidBodyPropertiesCfg(
max_depenetration_velocity=1.0, # 减小此值
),
articulation_props=sim_utils.ArticulationRootPropertiesCfg(
solver_position_iteration_count=8, # 增加迭代次数
solver_velocity_iteration_count=2,
),
Q: 仿真不稳定
A: 降低时间步长:
self.sim.dt = 0.005 # 从 0.01 降低到 0.005
6.4 部署问题
Q: 如何部署到真实机器人?
A: 使用 rl_sar 项目,它提供:
- Gazebo 仿真验证
- 真实机器人部署接口
- ROS/ROS2 集成
6.5 Pylance 找不到模块
A: 在 .vscode/settings.json 添加路径:
{
"python.analysis.extraPaths": [
"${workspaceFolder}/source/robot_lab",
"/path/to/IsaacLab/source/isaaclab",
"/path/to/IsaacLab/source/isaaclab_assets",
"/path/to/IsaacLab/source/isaaclab_tasks"
]
}
6.6 清理 USD 缓存
仿真会在 /tmp 生成大量临时文件:
# 清理所有 USD 缓存
rm -rf /tmp/IsaacLab/usd_*
# 清理特定日期的缓存
rm -rf /tmp/IsaacLab/usd_2024*
7. 参考链接

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 7
7 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)