表达、梦想与行动:面向指令驱动机器人操作的学习视频世界模型
26年2月来自复旦大学的论文“Say, Dream, and Act: Learning Video World Models for Instruction-Driven Robot Manipulation”。机器人操作需要预测环境如何响应动作而演变,然而大多数现有系统缺乏这种预测能力,常常导致错误和效率低下。虽然视觉语言模型(VLM)可以提供高层次的指导,但它们无法明确预测未来状态,而现有的
26年2月来自复旦大学的论文“Say, Dream, and Act: Learning Video World Models for Instruction-Driven Robot Manipulation”。
机器人操作需要预测环境如何响应动作而演变,然而大多数现有系统缺乏这种预测能力,常常导致错误和效率低下。虽然视觉语言模型(VLM)可以提供高层次的指导,但它们无法明确预测未来状态,而现有的世界模型要么只能预测较短的时间范围,要么生成空间不一致的帧。为了应对这些挑战,提出一种快速且具有预测性的视频条件动作框架。其方法首先选择并适配一个鲁棒的视频生成模型以确保可靠的未来预测,然后应用对抗蒸馏进行快速、少步骤的视频生成,最后训练一个动作模型,该模型利用生成的视频和真实观测数据来纠正空间误差。大量实验表明,该方法能够生成时间上连贯、空间上精确的视频预测,直接支持精确操作。
世界模型能够预测未来的观测结果(Du et al., 2023; Tian et al., 2024; Zhang et al., 2025a; Li et al., 2025),提供了一种更合适的解决方案。通过预测环境随时间演变的方式,它们提供了丰富的视觉上下文,下游动作模型可以利用这些信息进行明智的决策。尽管世界模型前景广阔,但目前的方法仍面临几个关键的局限性。(1)时间跨度有限:许多模型只能预测未来一小段时间的帧序列,因此需要重复运行才能处理长期任务(Hu et al., 2024)。(2)空间一致性差:预测结果常常受到失真或机器人本体不一致的影响,从而损害空间精度,降低其在精确操作中的实用性。 (3)计算成本高:虽然大型视频生成模型能够实现较高的预测质量,但其迭代特性会带来巨大的计算成本,使得实时部署面临挑战(Jang et al., 2025)。
另一方面,基于扩散的视频生成器虽然能够实现较强的预测质量,但依赖于迭代去噪,而迭代去噪的计算成本很高。诸如蒸馏和对抗训练等技术(Salimans & Ho, 2022; Sauer et al., 2024b; Zhang et al., 2024)可以加速推理,但保持空间和时间上的保真度(这对操作至关重要)仍然是一个挑战。
为了应对这些挑战,提出一种名为 Dream4manip 的框架,该框架由 Say、Dream 和 Act 三个部分组成,它将高保真视频世界模型与上下文相关的条件动作模型相结合,用于指令驱动的机器人操作。方法遵循三个核心原则:Say 部分学习一个鲁棒的、基于视频的世界模型,该模型能够捕捉任务相关的动态信息;Dream 部分通过与帧率无关的视频预测,实现对未来结果的、与视频长度无关的想象;Act 部分将想象的轨迹视为基于真实观测的上下文示例,从而生成可执行的动作。
任务目标是利用学习的世界模型实现快速、长时域的机器人操作。如图所示,框架将高保真度的基于视频世界模型与通过上下文条件训练的动作模型相结合。该方法包含三个阶段:(1)选择并适配适用于机器人领域的鲁棒世界模型;(2)提炼适配后的模型以实现高效的少步去噪;(3)利用想象轨迹和真实轨迹训练上下文条件动作模型。这些组件共同构成一个基于世界模型的、能够快速执行的操作策略。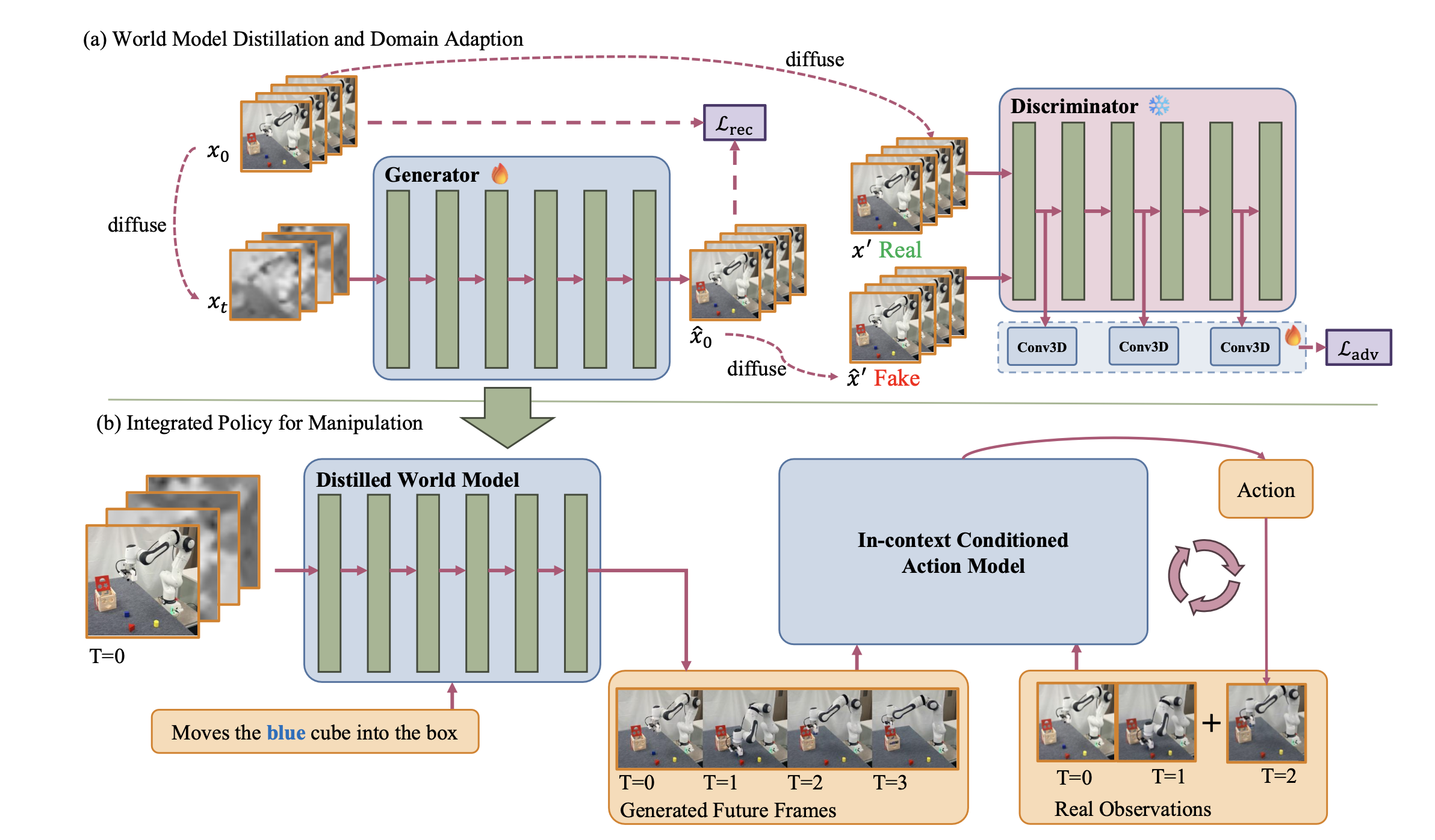
Say:世界模型
选择
核心思想:选择一个能够保持空间一致性和任务相关动态的世界模型。
基于具身决策的关键指标(具身一致性、任务完成率和空间参照能力)对几种最新的视频生成模型进行基准测试。基于这些评估,选择 COSMOS-PREDICT2 作为世界模型的骨干。尽管该模型性能优异,但在新场景、未见过的摄像机视角或不同的具身情况下,其性能可能会下降,因此需要进行域自适应和蒸馏。
域自适应和蒸馏
引入一种潜空间对抗损失,以实现少步去噪,从而在保持预测保真度的同时降低计算成本。即使是最先进的视频生成模型,在部署到新环境中时也可能产生空间不一致性。为了解决这个问题,首先进行域适应,将世界模型与目标机器人域对齐。然后,结合潜对抗监督和重构损失对适应后的模型进行蒸馏,从而得到一个既鲁棒又计算高效的世界模型,便于快速操作。
去噪公式。令 x_0 表示一个 16 维编码的视频潜帧。COSMOS-PREDICT2 中的扩散transformer T_θ 根据辅助信息 cond,从带噪声的输入 x_t 预测去噪后的潜帧 xˆ_0。xcond_t 表示 x_t 的条件版,其中第一帧被干净的潜帧替换,用于图像-到-视频的生成。噪声水平 σ_t 在蒸馏训练和推理过程中使用不同的策略进行采样。
少步蒸馏的噪声调度。为了减少去噪步骤,从离散集合 {σ_1,…,σ_T_g } 中采样 σ_t,p 是一个超参数,用于控制对低噪声水平的重视程度。参数 T_g 的选择与蒸馏模型中目标去噪步骤数相匹配;除非另有说明,否则设置 T_g = 8。
给定采样的噪声水平 σ_t,构建一个含噪的潜变量 x_t ∼N(x_0,σ_t),并应用去噪公式来获得去噪后的预测 xˆ_0。
潜对抗蒸馏。为了加速迭代去噪过程,引入一种潜对抗损失,该损失鼓励在少量去噪步骤下获得高保真度的预测。如上图所示,用来自 COSMOS-PREDICT2 的预训练扩散transformer (DiT) 权重初始化判别器 D,并添加几个轻量级的 3D 卷积头来增强判别器。这些卷积头作用于中间 DiT 特征图,生成像素级的得分图。在训练过程中,冻结 DiT 主干网络,仅优化新增的卷积头,使判别器对于干净的潜变量 x_0 输出接近 1 的得分,对于去噪后的预测值 xˆ_0 输出接近 -1 的得分。
在将 x_0 或 xˆ_0 传递给判别器之前,通过采样 σ′ 来注入额外的噪声,使得 log(σ′) ∼ N (0, 1),然后扩散这两个潜变量,分别得到 x′ 和 xˆ′。这种设计选择是基于以下事实:预训练的 DiT 经过优化,能够处理带噪声的输入,并且在中等噪声下比在干净的潜变量下展现出更稳定、信息更丰富的特征。
重构损失和域自适应。保留 COSMOS-PREDICT2 原始训练目标中的重构损失 L_rec,以促进域自适应,其中权重因子放大噪声样本的贡献,从而鼓励在各种噪声水平下进行精确去噪。其中,加权因子会放大噪声较大样本的贡献,从而在各种噪声水平下实现精确去噪。
总之,生成器 L_G 通过优化组合目标来提炼,其中两个组件是判别器 D 的对抗目标 LD_adv (注:生成器 G 的对抗目标 LG_adv)和重构损失L_rec。
在同一次训练迭代中,还应用重构损失来执行域自适应。具体来说,采样一个噪声水平 σ,使得 log(σ) ∼ N (0, 1),相应地扩散干净的潜变量 x_0,并计算原始潜变量 x_0 和相应的去噪预测 xˆ_0 之间的重构损失。该辅助目标在保留生成先验的同时,进一步将世界模型与目标机器人域对齐。
Dream:与长度无关的世界想象
核心思想:压缩轨迹并生成与执行长度无关的视频。
提出一种与长度无关的想象机制,该机制将任意长度的轨迹压缩成一组固定的关键帧,从而实现整体的、与帧率无关的视频生成。与以往将视频帧与底层动作步骤严格对齐的方法(Du et al., 2023; Yang et al., 2023; Zhou et al., 2024)不同,该洞见是:机器人操作本质上是一个低频预测问题,为每个动作步骤生成一帧是不必要的、冗余的,并且计算成本很高。
为了解决这个问题,通过均匀时间采样将任意长度的机器人执行轨迹压缩成固定数量的关键帧。
然后,对视频扩散模型进行微调,使其学习一种与帧率无关的视频生成能力,从而能够对整个执行过程进行整体想象,而无需依赖具体的执行时长。这使得模型能够在保持计算效率的同时,预测长期结果。
Act:上下文条件动作模型
核心思想:将想象的轨迹视为上下文示例,以指导动作预测。
即使使用最先进的视频生成模型,蒸馏世界模型也可能偶尔出现空间误差。为了解决这个问题,将想象的轨迹视为用于动作预测的上下文示例,而不是严格的指令(Vuong,2025),从而使动作模型能够基于真实观测进行预测,并纠正生成视频中的错误。
如图所示,动作模型同时接收生成的未来帧和真实的历史观测数据。这种设计使得模型能够通过不断地将预测结果与实际观测数据联系起来,从而纠正生成视频中存在的空间误差。在功能上,该模型的运行方式类似于下一个token 预测器:给定一个以生成帧形式呈现的执行示例,它会输出执行后能够产生符合示例中所示一般模式的真实世界观测结果的动作。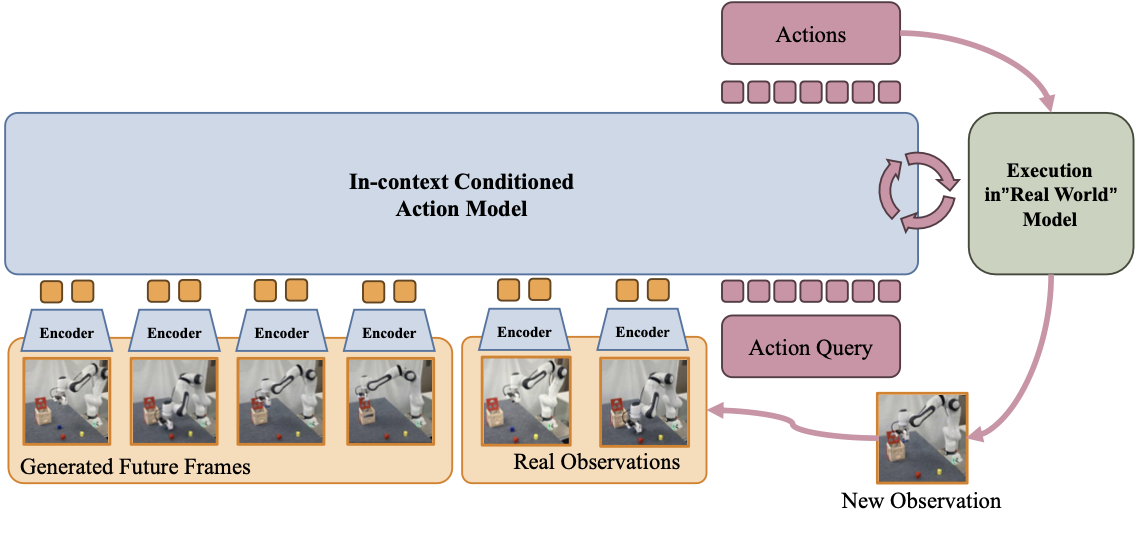
实验设置。分两个阶段评估方法。首先,用特定任务的指标,测试四个基线视频生成模型(Cosmos-2B、Cosmos-14B、Cosmos-Droid 和 Wan-14B)的零样本空间参考能力,从而评估世界模型,并选择最适合领域自适应的模型。在自适应和对抗蒸馏之后,通过真实世界的定性分析进一步验证改进效果。其次,在模拟任务和真实世界任务中执行部署,以评估提出的策略在引导鲁棒且精确操作方面的有效性。
模拟基准。在评估整个策略时,在 LIBERO 基准测试(Liu,2023)上进行闭环评估。对于 LIBERO 基准测试,每个任务套件包含约 500 个训练样本(具体而言:空间任务 433 个,物体任务 456 个,目标任务 436 个,长任务 389 个)和 10 个测试子任务样本。在评估过程中,每个测试样本执行 50 次,因此每个测试套件总共运行 500 次。
实际环境设置。为了评估方法在实际环境中的有效性,搭建一个如图所示的物理机器人实验平台。该平台采用 Franka 7 自由度机械臂作为操作主体。平台上安装一台 Intel RealSense D435 摄像头,用于以第三人称视角观察机器人。远程操作数据由 3Dconnexion SpaceMouse 采集。
实现细节。对于世界模型,基于 cosmos-predict2 训练模型。采用 FusedAdamW 作为优化器,学习率为 2 -14.5。使用 lambda 线性调度器,预热步数为零,单周期长度为 1000 步,fmax = 0.6,fmin = 0。训练采用基于 FSDP 的分布式并行化,上下文并行大小设置为 2,并启用指数移动平均 (EMA) 以稳定收敛。世界模型在 LIBERO 基准数据集上训练 10000 次迭代,而真实世界模型训练 1000 次迭代。训练动作模型时,用 Qwen2.5 初始化 VLM,并使用 LoRa 对 VLM 主干网进行参数高效的微调,排序为 64。训练在 8 个 GPU 上进行,总批大小为 128。在训练过程中,将世界模型生成的未来视频预测作为额外的上下文输入,并从历史视频片段中均匀抽取 8 帧作为条件上下文。学习率设置为 2 × 10−4,训练总步数为 20,000。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 24
24 0
0- 0



 已为社区贡献211条内容
已为社区贡献211条内容

所有评论(0)