EgoScale——第一视角的2万小时人类标注数据扩展灵巧操作能力(提出人类数据下的缩放定律):先大规模人类预训练,再人机对齐,最后单条示范微调
前言
近期的具身,国内外猛地一塌糊涂
- 国内各种融资,包括且不限于星海图、灵心巧手、智平方、千寻、自变量、银河通用等——这里面 大部分和我司『七月』均有合作,真心祝贺
且有人惊呼:一级市场苦等多年,终于等到了具身智能,^_^ - 而国外的英伟达则各种推出模型,比如过年前推出的DreamZero、过年期间开源的SONIC,再到本文要介绍的EgoScale,真心猛
当然,对于这三者,加上本文,使得本博客内均已解读了
EgoScale,这是一个基于大规模自中心人类数据的人类到灵巧操作迁移框架。作者在超过20, 854 小时带有动作标注的自中心人类视频上训练一个视觉-语言-动作(VLA)模型——其规模比以往工作大了超过20×,并发现了人类数据规模与验证损失之间的对数线性缩放规律
- 该验证损失与下游真实机器人性能高度相关,从而确立了大规模人类数据作为一种可预测的监督信号来源
- 除了规模之外,作者还提出了一种简单的两阶段迁移方案:先进行大规模人类预训练,然后进行轻量的对齐人机中期训练
这使得在仅需极少机器人监督的情况下,实现强大的长时间跨度灵巧操作,且让“一次示范的任务自适应”成为可能
第一部分 EgoScale: Scaling Dexterous Manipulation with DiverseEgocentric Human Data
1.1 引言与相关工作
1.1.1 引言
如原论文所述,最新研究表明,通过在不同形体之间对齐观测或动作,可以将人类数据迁移到机器人上[12-Egomimic,42-Egovla,25-Humanoid policy ~ human policy,24-Egobridge,30-Dexwild]
然而,现有结果在两个方面仍然存在局限
- 第一,大多数方法依赖相对较小的人类数据集,通常只有几十到几百小时的规模
- 第二,许多工作聚焦于机械夹爪或低自由度机械手,这些装置缺乏精细的手指关节运动
因此,目前尚不清楚,人类数据是否能够在大规模场景下为复杂的灵巧操作提供具有实质意义的支持
对此,来自1 NVIDIA、2 University of California, Berkeley、3 University of Maryland的研究者提出了 EgoScale——一个基于大规模自我视角人类数据构建的、可扩展的人到灵巧操作迁移框架
- 其paper地址为:EgoScale: Scaling Dexterous Manipulation with Diverse Egocentric Human Data
其作者包括
Ruijie Zheng1* , Dantong Niu1,2* , Yuqi Xie1* , Jing Wang1 , Mengda Xu1 , Yunfan Jiang1 , Fernando Castañeda1 , Fengyuan Hu1 , You Liang Tan1 , Letian Fu1,2 , Trevor Darrell2 , Furong Huang3 , Yuke Zhu1† , Danfei Xu1† , Linxi Fan1† - 其项目地址为:research.nvidia.com/labs/gear/egoscale
其Github地址为:截止到26年3月初,暂未开源
如下图所示
- 首先,在 20,854 小时的人类自视角视频上,利用手腕运动和重定向的灵巧手动作预训练一种基于流的视觉-语言-动作(VLA)策略
- 在一个轻量级的中期训练阶段,使用对齐的人机数据(以绿色和灰色边界标出的配对)将该表征适配到机器人的感知与控制空间
- 最终得到的策略在下游任务上进行后期训练,从而高效学习灵巧操控,并对未见过的技能实现一次性泛化

更具体而言,其
- 在 20,854 小时的自我视角人类操作数据上进行预训练,这一规模比以往人–机策略迁移研究中使用的数据集大 20 倍以上,并由此发现了一条清晰的缩放律:人类手腕和手部动作预测的验证损失与数据规模呈对数线性关系
- 即用于灵巧操作的人到机器人迁移在根本上是一个与规模相关的现象
这使得能够进行外推:随着人类数据规模的扩大,验证损失持续下降,所学习到的表征泛化能力不断提升
关键的是,该损失与真实机器人在长时域、复杂操控任务上的表现高度相关
综合来看,这些结果确立了大规模人类数据,作为学习灵巧操控策略的一种可扩展且可预测的监督来源
除了规模之外,作者还提出了一种简单而有效的训练方案,使模型具备新的泛化能力
- 使用以相对手腕运动和重定向的高自由度手部关节动作为表示的人类操控行为来监督模型。这一对齐后的动作空间促使模型提取对操控直接有用的信息,而不是只学习与任务无关的视觉特征
- 在预训练之后,通过协同训练引入少量对齐的人机中间训练数据
这些中间训练数据包括人类和机器人在匹配的桌面场景中、以相近视觉视角执行相似操控任务的过程。这种对齐为将预训练表征锚定到机器人的感知与控制空间提供了监督信号
——
重要的是,这一中期训练阶段产生了涌现的一次样本和少样本泛化能力。(使得在后训练阶段中)只需一条或少量机器人示范,策略就能够适应新的灵巧操作任务,而无需进行大量针对具体任务的数据采集
例如,仅使用一条机器人示范,训练好的策略在折叠衬衫任务上的平均成功率最高可达88%,尽管中期训练数据只包含折叠类行为
——————
此外,尽管人类动作是在高自由度灵巧手空间中被监督学习的,所学得的表示仍然可以泛化到在形态上有显著差异的机器人平台上。在搭载三指机械手的 Unitree G1 机器人上,相比于没有人类预训练的基线,人类预训练的策略在两项评估任务上的成功率也都取得了超过30%的绝对提升
1.1.2 相关工作
首先,对于基于人类数据的机器人学习
- 人类示范已被广泛用于扩展机器人学习的规模,早期工作主要利用人类视频进行表征学习或意图推断
17-R3m
36-Masked visual pre-training for motor control
15-Where are we in the search for an artificial visual cortex for embodied intelligence?
14-Learning latent plans from play
45-FLARE: Robot learning with implicit world modeling
后续方法使用人类数据来引导规划或高层控制,同时在低层执行上依赖机器人示范
34-Mimicplay: Long-horizon imitation learning by watching human play
43-Visual imitation made easy
44-Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies
18-Llarva: Vision-action instruction tuning enhances robot learning
38-Xskill: Cross embodiment skill discovery
39-Flow as the cross-domain manipulation interface - 更近期的方法利用第一人称感知和 3D 手部跟踪的进展,将人类视频视为密集动作监督。EgoMimic [12]
Qiu 等人 [25-Humanoid policy ~ human policy]
和
DexWild[30]
通过显式对齐在人类和机器人示范上共同训练统一的模仿策略,而 EgoVLA [42] 则在人类手部运动上预训练 VLA 模型,并通过逆运动学和重定向将其迁移到机器人上
————
与此同时,相关工作 [13-Emergence of human to robot transfer in vision-language-action models] 表明,在大规模、多样化、跨体型数据上预训练的 VLA 可以解锁从人到机器人的迁移能力
- 与这些工作形成对比的是,作者的工作专注于在几乎没有机器人监督的情况下进行纯大规模人类预训练,其目标是直接从多样化的人类自我视角视频中同时学习手腕运动和灵巧手部关节动作
- 与主要仅为基于夹爪的平台迁移手腕运动的方法相比,作者的设定保留了对灵巧操作至关重要的丰富手部运动信息
与近年来同样利用手部级监督的方法相比,作者在规模大得多的人类数据上进行预训练,并系统性地表明:扩大人类视频的规模能够在人类验证指标和下游机器人性能上都带来持续一致的提升,从而在先进的多自由度机器人手上实现强大的灵巧操作性能
其次,对于机器人学习中的尺度特性
受在语言和视觉领域中观察到的缩放定律启发,近期工作开始探究类似的原则是否也支配机器人学习
- 从经验上看,大规模机器人数据集和类基础模型的策略表明,增加数据的多样性和覆盖度会提升跨任务和跨环境的鲁棒性与泛化能力
11-Scalable deep reinforcement learning for vision-based robotic manipulation
46-Rt-2
20-OpenX
33-Bridgedata v2
31-Octo
4-Rt-1 - Hu 等人[9-Data scaling laws in imitation learning for robotic manipulation,详见本博客中的解读《机器人领域中的scaling law:清华高阳团队通过复现斯坦福UMI——探讨数据规模化定律(含UMI的复现关键)》]表明,策略泛化随环境和物体多样性近似遵循幂律关系,而额外示范数据的收益则很快饱和,这突出了多样性比原始数据量更为重要
这一结果与既有工作中通过组合多样性来实现高效数据收集的观点
7-Efficient data collection for robotic manipulation via compositional generalization37-Decomposing the generalization gap in imitation learning for visual robotic manipulation
是一致的
与主要扩展机器人自主采集数据规模的先前工作相比,作者展示了:扩展多样的、真实环境中的人类第一视角数据可以在灵巧操作上带来系统性的收益,从而将人类视频确立为一种高效且可扩展的监督信号来源
最后,对于学习灵巧操作
- 灵巧操作已从基于分析和控制的抓取方法发展而来,这些方法对力闭合、接触稳定性和手部运动学进行建模
21-On characterizing and computing three-and four-finger force-closure grasps of polyhedral objects
22-On computing four-finger equilibrium and force-closure grasps of polyhedral objects.
26-From caging to grasping
27-On the synthesis of feasible and prehensile robotic grasps
23-On the manipulability ellipsoids of underactuated robotic hands with compliance
6-Synthesis and optimization of force closure grasps via sequential semidefinite programming
到从数据中获取接触丰富行为的学习
1-Learning dexterous in-hand manipulation
40-Dexumi - 后续工作引入了抓取可供性、接触图和手–物体交互场等结构化表示,以更好地刻画灵巧操作中的几何与物理特性
3-Contactgrasp: Functional multi-finger grasp synthesis from contact
5-Ganhand:Predicting human grasp affordances in multi-object scenes.
10-Hand-object contact consistency reasoning for human grasps generation
41-Cpf: Learning a contact potential field to model the hand-object interaction
32-Grasp’d: Differentiable contact-rich grasp synthesis for multi-fingered hands - 更近期的方法旨在通过统一的感知与控制来学习具有良好泛化能力的多手指操作策略
28-Unigrasp: Learning a unified model to grasp with multifingered robotic hands
35-Learning diverse and physically feasible dexterous grasps with generative model and bilevel optimization
然而,由于动作空间维度高、机器人数据采集成本高以及当前灵巧手硬件能力有限,扩展灵巧操作的规模仍然具有挑战
作者的工作利用带有稠密手部跟踪的自我视角人类视频作为替代监督来源,表明人类手部运动为提升机器人灵巧操作提供了可迁移的信号
1.2 EgoScale的完整方法论
作者的目标是从大规模第一人称视角人类视频中学习表征,并能直接用于灵巧机器人的控制。在这一设定下存在两个核心挑战
- 首先,人类示范存在噪声,且缺乏与之成对的机器人动作数据
- 其次,人类与机器人的具身形式在运动学结构和控制接口上存在显著差异
作者的方法(图1)通过两个设计选择来应对上述挑战
- 首先在纯人类数据上进行预训练,使用从第一人称视角视频中提取的手腕运动和手部关节姿态作为显式监督,迫使模型学习具有物理意义的动作表征
- 随后,作者在中期训练阶段引入少量对齐的人机数据,将这些表征与可执行的机器人控制对齐,而无需大规模的成对示范数据
总体而言,这种两阶段设计将数据规模与具身形式对齐解耦,从而实现从大规模人类数据集到灵巧机器人操作的有效迁移
1.2.0 人类动作表示
首先,对于原始传感器流
每个人体示范由头戴式相机捕获的自我视角RGB 观测组成,并包含由现成感知管线估计得到的相机运动和人手姿态
有意思的是,这个设计,跟之前PI的第一人称数采有相似之处,详见《PI发布的Human to Robot数采工作——头戴iPhone且手戴两相机采集数据:混合数据中像“用机器人数据一样”用人类数据,而无需显式对齐》

作者将这些原始感知信号转换为适用于大规模预训练和下游机器人执行的统一动作表示
- 令
表示世界坐标系
表示时刻
的相机坐标系
估计得到的相机位姿表示为 - 人手姿态由21 个关键点建模,每个关键点在相机坐标系中表示为刚体变换
,其中
对应手腕
世界坐标系下的手腕位姿由给出
其次,对于手腕级手臂运动
- 为了获得对全局相机运动不变的运动指令,作者使用相邻时间步之间的相对手腕运动来表示手臂运动
给定动作片段中的时间步 - 这种相对末端执行器形式消除了对绝对相机位姿的依赖,并以一种物理上有意义的方式捕捉局部手臂运动
同样的表示在人体示教和机器人执行中共享,作为跨形体学习的主要手臂级动作抽象
最后,对于手部关节动作
- 为了实现手指级别的控制,作者采用一种基于优化的流程,将 21 个真人手部关键点重定向到灵巧机器人手的关节空间中,并强制满足关节范围和运动学约束
- 作者的默认选择是 Sharpa 手 [29] 的 22-DoF 手部动作空间,它在预训练期间保留了人类手指的关节动作,同时与目标机器人的控制接口保持一致
尽管这种表示是基于高自由度(high-DoF)机械手定义的,且下文稍后将展示,所学模型可以有效迁移到自由度更低的机器人手上
1.2.1 人类数据来源与处理
第一阶段,大规模第一人称人类预训练数据
- 作者在一个大规模的第一人称人类活动数据集混合体上预训练模型,这些数据集总计包含 20,854 小时的视频。其中大部分由自然环境中的第一人称记录构成,涵盖多样的真实世界环境(如家庭、工业、零售和教育场景),覆盖 9,869 个场景、6,015 个任务和43,237 个对象,并提供了对长尾的广泛覆盖
————
且所有录制数据均使用自我视角的 RGB 相机以 30 FPS 进行采集。采用现成的 SLAM和手部姿态估计算法流程来恢复相机运动和人手轨迹
尽管由于数据采集不受约束,这些估计结果存在噪声,但数据在规模和多样性上的优势,为学习可迁移的动作表征提供了有效的监督,并且随着数据量的增加,这些表征持续提升下游任务的性能 - 此外,为了补充这种大规模但噪声较多的监督,作者又额外引入了829小时的EgoDex数据集[8]。该数据集使用Apple Vision Pro采集,具备精确的手腕和手部追踪
EgoDex涵盖了194种涉及日常物体的桌面操作任务,并提供更高精度的运动学信号,在保持可扩展性的同时,有助于为预训练提供稳定的锚点
第二阶段:人机对齐的中期训练数据
为了进一步弥合人类示范与机器人执行之间的具身鸿沟,作者引入了一个更小的数据集,其中同时包含人类和遥操作机器人的数据
随后将表明,该数据集对于将预训练表示锚定到机器人的感知与动作空间至关重要
该数据集包含344 个桌面操作任务,每个任务约有30 条人类轨迹和5 条机器人轨迹,总计约50 小时的人类数据和仅4 小时的机器人数据
- 如图2a 所示,人类示范使用与机器人相同的相机配置进行采集,视角匹配且内参经过标定,确保不同域之间的视觉观测可以直接对比
其中,一台头戴相机和两台腕部相机分别记录第一人称视角和腕部视角- 人手运动使用与机器人遥操作相同的动作捕捉系统进行记录:
Vive 追踪器提供手腕位姿(3D 位置和朝向)
而Manus 手套记录完整的手部内部姿态,共25 个关节变换
所有运动信号都与视频流同步
与阶段 I 中使用的大规模但不受约束的数据相比,该数据集规模要小得多,但在具身对齐方面是明确设计的
它聚焦于与机器人工作空间和运动学相匹配的桌面任务,从而使预训练期间学到的抽象人类动作能够被落实为可执行的机器人控制
总体来看,阶段 I 和阶段 II 将规模与对齐解耦:阶段 I 提供多样性与语义层面的奠基,阶段 II 则为下游部署提供精确的人机对应关系
1.2.2 模型架构
如图2b 所示,作者的模型采用与GR00T N1 [19] 相似的基于流的VLA 架构
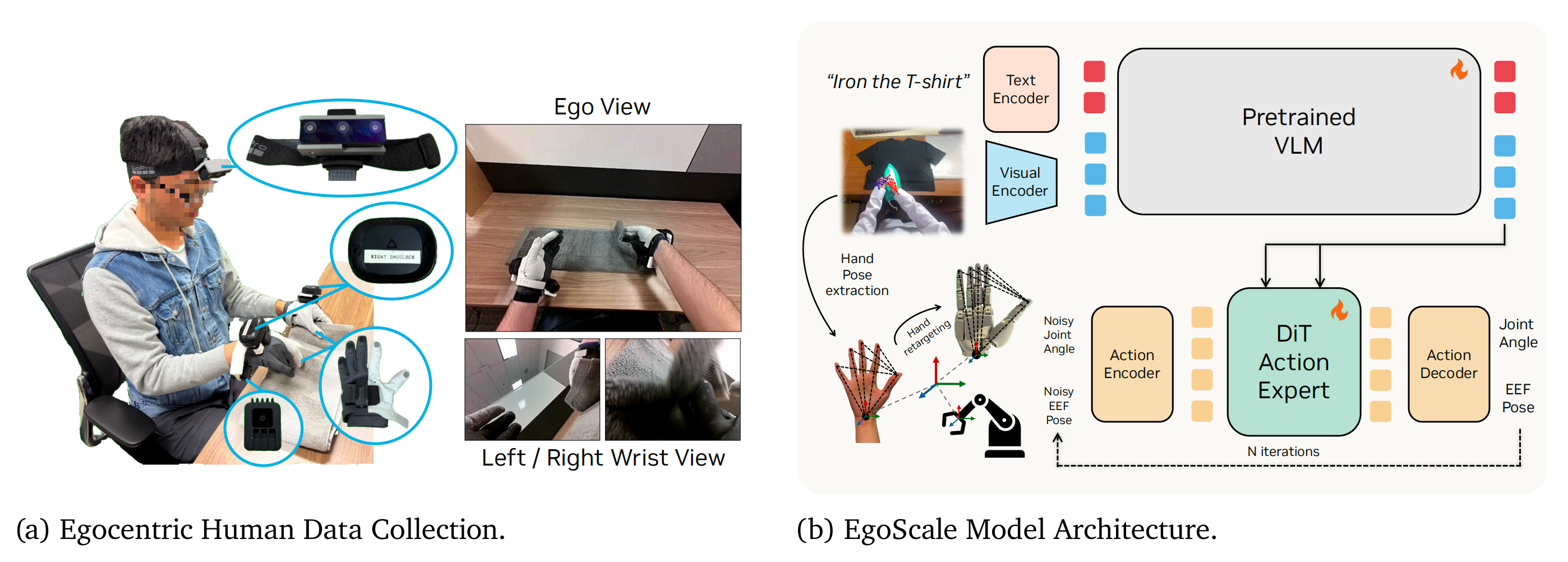
- 在每个时间步
,该观测由一幅图像和一条语言指令组成,并将其编码为视觉-语言嵌入
。随后,模型利用流匹配目标预测一段未来动作
- 对于机器人数据,模型以机器人本体感知状态
为条件,而人类演示并不提供此类信号。在没有本体感知的情况下,作者用一个可学习的占位符标记替换
为适应具有不同状态和手部动作空间的多种机器人形态,遵循GR00T N1 [19],作者在输入和输出接口处使用轻量的、以形态为条件的MLP 适配器
具体来说,这些适配器对特定形态的本体感知状态进行编码并对手部动作进行解码,而相对手腕运动预测、视觉-语言骨干网络以及DiT 动作专家则完全共享
在实践中,该机制仅用于少量额外的机器人形态(例如,配备三指手的G1)
————
说白了,面对不同的机器人,视觉语言及动作预测部分 不用做特定处理、不变
但对不同机器人的本体感知状态,则需要特定的编码、解码
1.2.3 三阶段的训练策略:人类预训练、中期对齐训练、后训练
作者使用一个三阶段的训练流程
- 在阶段I(人类预训练)中
作者在100K 步内使用20K 小时的自我视角人类数据进行训练,利用256 个GB200 GPU,采用8,192 的全局批大小和学习率5 × 10−5 ,完全解冻VLA 模型的每一个参数以吸收大规模数据 - 然后在阶段II(对齐的中期训练)中
作者在对齐的人机交互数据集上训练50K 步,批大小为2,048,学习率为3 × 10−5 ,在仅更新视觉编码器和DiT 动作专家的同时冻结视觉-语言骨干网络,以将表征锚定到机器人的感知和控制上 - 在阶段III(后训练)中
作者在特定任务的机器人示范上进行微调,训练10 K 步,批大小为512,学习率为3 × 10−5
————
在后训练期间,如果使用了中期训练则冻结视觉编码器,否则将其解冻,以在需要时适应新的具身形式
1.2.4 机器人系统与控制
现实世界实验是在配备“22自由度的Sharpa灵巧机械手 ”的Galaxea R1 Pro 仿人机器人上进行的。系统图请参见附录 B
- 双臂轮式仿人系统 Galaxea R1 Pro
作者将底座和躯干固定,只专注于双臂操作:在相对末端执行器空间中控制两条 7 自由度手臂,其中动作用于指定位置和姿态的增量变化,并与人类示教中采用的腕部姿态表示保持一致,从而实现直接的人机对齐 - 22 自由度灵巧手
作者为机器人配备了具备 22 个自由度并支持关节空间控制的 Sharpa Wave 机械手,其中动作直接指定目标关节角度,从而实现精确的关节操控,并保留重定向的人类手部运动的细粒度结构 - 感知系统
作者使用三台 RGB 相机:一台头戴式相机,提供与人类视频一致的自我中心第一人称视角;以及两台安装在每只手腕内侧、面向手掌的手腕相机,用于捕捉近距离的手-物体交互,并提供对精细灵巧操作至关重要的细致视觉反馈
1.3 实验
如原论文所述,在本节中,作者希望通过实验回答以下研究问题:
- RQ1:与从零开始训练或仅使用具身对齐数据训练相比,大规模第一视角人类预训练是否能提升后续灵巧操作任务的性能?
- RQ2:人类预训练数据的规模如何影响表征质量和真实机器人性能?
- RQ3:中期训练在促进小样本适应以及对新任务的泛化方面起到什么作用?
- RQ4:在人类预训练的表征能否迁移到运动学特性和控制接口截然不同的机器人形态上?
- RQ5:在预训练过程中对人类动作表征的选择会如何影响下游的灵巧操作?
1.3.0 实验设置
首先,对于任务本身而言
为了评估策略性能,作者设计了图3中所示的五个高度灵巧的操作任务

除“Shirt Rolling”外,每个任务都提供了 100 个由远程操控机器人完成的示范。“Shirt Rolling”是一个可变形物体操作任务,对控制精度的要求较低,因此作者仅使用 20 个示范
- 任务 I Shirt:Shirt Rolling
机器人双手协同配合,交替折叠并卷起一件 T 恤,使其呈圆柱形,然后将其放入篮子中 - 任务 II Card:卡片分类
机器人使用手指摩擦并从紧密叠放的牌堆中分离出单张卡片,然后根据颜色将其精确插入到正确的卡槽中 - 任务 III Tong:灵巧工具使用
使用夹子搬运水果。机器人首先从工具箱中抓取一把夹子,然后用它夹起一个水果并放置到目标位置 - 任务 IV 瓶子:拧开瓶盖
机器人抓取并持续旋转一个小瓶盖,将其从瓶子上取下。作者在四个不同尺寸的瓶子上收集示范数据,每个瓶子包含 25 条轨迹 - 任务 V 注射器:注射器液体转移
这是最具挑战性的任务,要求机器人拾取一支注射器,从试管 A 中抽取液体,将其注入试管 B 中,然后将注射器丢入垃圾桶
该任务涉及长时序、多步骤推理,对液体抽取和注入过程中的空间对齐精度要求极高,并需要对注射器活塞进行灵巧操作
其次,对于评价指标
- 为评估策略性能,作者为每种方法使用两个随机训练种子进行训练
随后,对每个训练完成的策略检查点,且在 10 次试验中评估其表现;但对于 Task III——灵巧工具使用,作者在四个不同的瓶子实例上,对每个瓶子进行 4 次试验,总计进行 16 次评估试验 - 为保证不同评估运行之间的一致性,作者采用一种基于图像叠加(image-overlay)的初始化流程:向执行评估的机器人提供目标初始场景配置的视觉叠加图像,以减少初始条件的差异
对于每个任务,作者同时记录任务的绝对成功率以及细粒度的任务完成评分
1.3.1 大规模人类预训练是实现高性能灵巧操作策略的关键
为评估大规模人类预训练和对齐中期训练对策略学习效率的影响,作者比较了四个检查点:
- 从头训练的模型
- 仅在用于中期训练的对齐人机玩耍数据集上进行预训练的模型
- 在大规模人类数据上预训练的模型
- 先在人类数据上预训练、再在对齐人机数据上进行中期训练的模型
对于每个检查点,作者同时报告任务完成得分和绝对成功率
结果汇总如图4所示『比较在人类预训练 + 训练中期引入、人类预训练以及无预训练三种设置下,五个灵巧操作任务在两种评估指标上的表现』
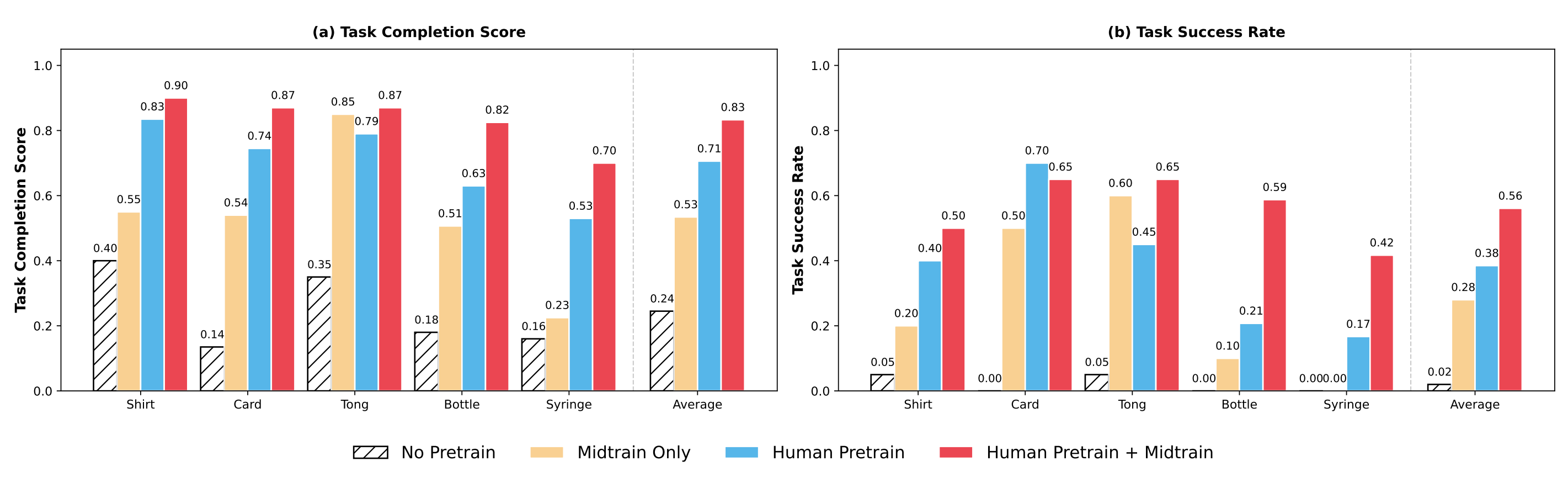
- 在所有任务中,相较于从头训练,人类预训练始终带来显著的性能提升,使平均任务完成率提高了超过55%
- 值得注意的是,即使在包含噪声、无约束、且既未与具体任务对齐也未与传感器对齐的大规模人类预训练条件下,其在大多数任务上的表现已经优于仅在中期训练阶段进行训练的基线方法
这表明,人类示范的大规模与多样性为灵巧操作提供了强有力的归纳偏置,即便在缺乏精确具身性对齐的情况下也是如此 - 最后,将人工预训练与少量对齐的中期训练相结合可以获得整体上最优的性能,这表明二者具有互补效应:
大规模的人类数据提供了通用的操作结构,而中期训练则将这些表征锚定到可执行的机器人控制上
1.3.2 策略性能随「预训练」数据规模扩展
作者研究自视角人类预训练数据的规模如何影响下游真实机器人操作性能,并分析这种行为如何体现在离线人类动作预测指标上
首先,作者使用 1k、2k、4k、10k 和 20k 小时的人类数据对模型进行预训练。为隔离第二阶段中期训练的影响,作者将每个检查点直接在下游任务上进行后续训练,并评估其性能
- 如图5(右)所示『训练(post-training)后下游机器人的性能,以平均任务完成得分度量,随着人类数据规模的增加而持续提升』
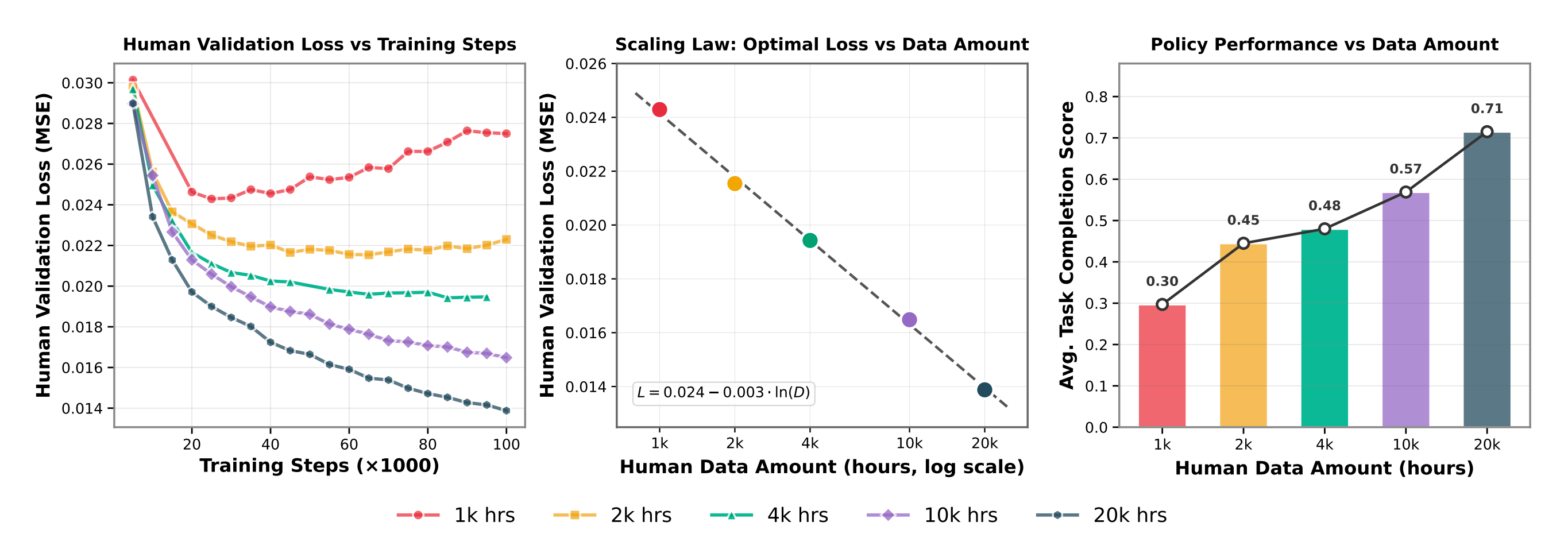
增加人类预训练数据量会在下游机器人性能上带来稳定且显著的提升。平均任务完成度从 1k 小时时的 0.30 单调上升到 20k 小时时的 0.71,在已探索的范围内没有出现饱和迹象 - 这些结果表明,即便人类示范数据存在噪声、缺乏约束且未与具体任务对齐,大规模人类数据仍然能为灵巧操作提供越来越强的先验
为了更好地理解这一趋势,作者研究预训练数据规模如何影响所学动作表征的质量。且在一个留出的真人视频验证集上评估每个预训练模型,该验证集由 2,000 个自我中心视角(egocentric)episode组成
在评估时,作者为每条轨迹随机采样 20 个时间步;在每个时间步,从 flow-matching 策略中抽取 16 个样本,对预测的动作块取平均,并计算其与真实手腕和手部动作之间的均方误差
其次,图5(左)展示了在不同数据规模下,人类验证损失随训练步数变化的情况
- 使用较小数据集(1k–2k小时)训练的模型在初期会降低验证损失,但随后会出现损失趋于平稳甚至升高的情况,这表明模型对有限的行为多样性产生了过拟合
- 相比之下,使用较大数据集(10k–20k 小时)训练的模型在整个训练过程中表现出稳定、单调的改进,没有出现过拟合的迹象
最后,令人惊讶的是,当作者将收敛时达到的最优验证损失与数据规模作图(图5 中间)时
可以观察到一个极其干净的对数线性标度规律:
- 其中
表示人类预训练数据的小时数。拟合曲线达到了0.9983 的
,表明在对数空间中存在几乎完美的线性关系。关键在于,这种离线尺度扩展行为对真实机器人性能具有很强的预测性
- 在人类验证损失与不同数据规模下的下游任务完成情况之间存在紧密对应关系,这确立了前者作为具身控制能力的有效指标,而不仅仅是一个纯粹的离线度量指标
综合来看,这些结果表明,用于灵巧操作的有效人机迁移在本质上是一个尺度扩展现象
- 在作者探索的范围内,增加人类数据会以可预测的方式降低验证损失,并带来相应的机器人性能提升,且没有出现收益递减的证据
- 且作者表示,尽管不对超出测量范围的情况进行外推,但这一趋势表明,随着人类数据规模和模型容量的持续增大,仍然存在巨大的余地以获得进一步的性能提升
1.3.3 对齐的「人机中期训练」使一次性迁移成为可能
如原论文所述,作者评估在机器人监督极其有限的情况下,对齐的人机中期训练是否能够支持对先前未见过技能的学习
从一个以人类数据预训练的模型出发,作者在对齐的 play 数据集上进行中期训练,并在新任务上进行后训练,此时只使用每个任务一条机器人的示范,并辅以对齐的人类示范
Starting from a human-pretrained model, we apply mid-training on the aligned play dataset and post-train on new tasks using only a single robot demonstration, supplemented by aligned human demonstrations.
且考虑两个任务 Fold Shirt 和 Unscrewing Water Bottles,这两项任务都未出现在中期训练数据中
- 对于 Fold Shirt 任务,作者提供 1 个机器人示范以及 100 个对齐的人类示范
- 对于 Unscrewing WaterBottles 任务,且使用三种几何形状不同的水瓶来评估在物体变化上的泛化能力,每个水瓶都提供 1 个机器人示范和 100 个对齐的人类示范
如图6 所示,在这种一次性设置中,省略大规模人类预训练或对齐中期训练的模型都会失败『对齐的中期训练使得涌现的一次性迁移成为可能。在后训练阶段,策略在每个任务上仅基于单条机器人示范进行训练,同时配合对齐的人类示范(每个物体100条轨迹)』

- 相比之下,Pretrain + Midtrain 模型在Fold Shirt 任务上取得0.88 的成功率,在Unscrewing Water Bottles 任务上取得0.55 的成功率,展示了强大的小样本泛化能力
- 失败通常是部分性的:对于衬衫是折叠不完全,对于瓶子则是在取下瓶盖后难以稳定保持抓取
这些结果表明,对齐的中期训练实现了一种迁移形式,而这种迁移不会单独由人类预训练或具身性特定数据所产生
且作者认为,这种泛化之所以成为可能,是因为在中期训练任务与评估任务之间存在共享的运动结构。尽管物体和具体任务实例差异很大,中期训练数据仍使模型接触到常见的运动基元,从而使这些行为即便只通过一次目标机器人的示范也能够实现迁移
1.3.4 人类预训练实现跨形体迁移
如原论文所说,除了双手桌面操作与高自由度灵巧手之外,作者还展示了人类预训练能够学习可迁移的动作表示,并推广到新的机器人本体
- 人类预训练将动作表示为相对的SE (3) 末端执行器运动,并结合由Sharpa 手定义的22 自由度灵巧手关节空间
尽管该动作空间是通过一个特定的机器人手来实例化的,但它也可以作为一种运动先验,编码可复用的抓取与操作基元,例如张手、闭合以及协调的手指关节运动,从而可以迁移到其他机器人手上 - 为了评估跨本体的泛化能力,作者引入了一个在结构上有显著差异的机器人平台:Unitree G1,它具有更短的机械臂、缩小的可达工作空间,以及一个7 自由度的三指手,从而导致明显不同的运动学特性
作者在两个任务上评估后训练策略的性能
- 在第一个任务“Pen in Bin”中,G1 机器人使用左臂打开垃圾桶,然后用右手拾起一支笔并将其放入垃圾桶中
- 在第二个任务 Dish in Rack:机器人被展示桌面上的三个盘子,需要执行一个从右向左的传递动作,将餐具放置到架子上
——
在执行过程中,策略预测上半身的目标命令,而下半身的平衡与运动由单独训练的 Homie『2-详见本博客中的解读《HOMIE——遥操类似ALOHA主从臂的外骨骼驾驶舱收集数据:通过上肢模仿学习和全身控制RL训练自主策略》』 策略处理,该策略输出下半身关节命令
与之前的实验相同,作者为每种方法使用两个随机种子进行训练。对于每个种子,对得到的策略进行 10 次试验评估,并报告跨这两个种子的平均策略得分和成功率
如图 7 所示,在中期训练阶段引入包含 G1 embodiment 游戏数据的数据混合物,相较于仅在相同的 G1 embodiment 专用数据上训练得到的检查点,在两个 G1 操作任务上都带来了显著的性能提升
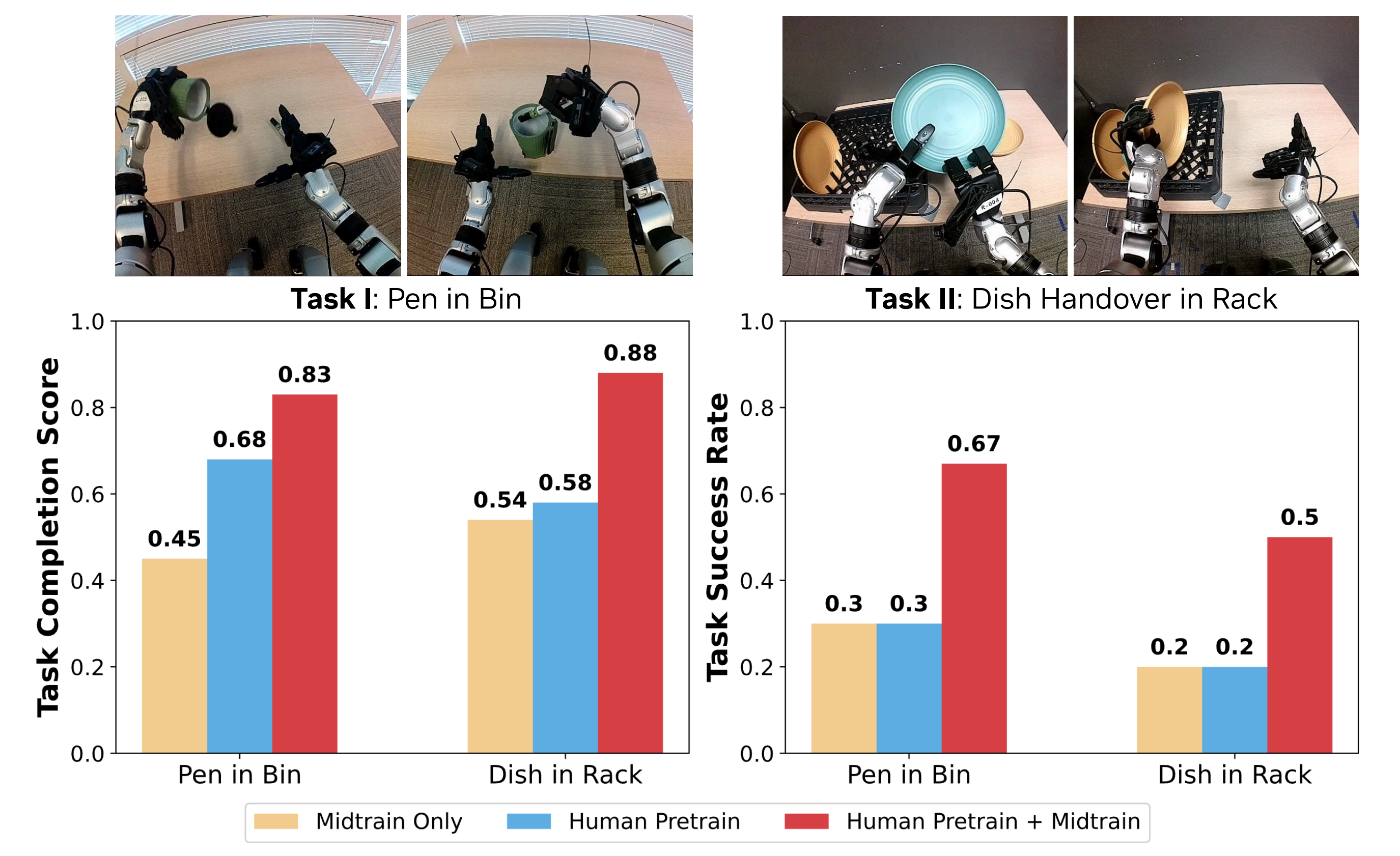
- 关键的是,这种提升并不能仅仅归因于对 G1 轨迹暴露次数的增加:在缺乏先前人类数据预训练的情况下,直接在同一 G1 数据集上进行预训练并微调的策略,无法达到相当的成功率
- 作者宣称,根据经验观察,作者还发现,基于人类数据进行预训练的策略在行为表现上更加平滑、连贯
总之,这些结果表明,EgoScale 预训练学得了一种可复用的操作结构,该结构可以在不同形体之间迁移,而中期训练则将这一结构适配到 G1 的传感与控制接口
1.3.5 面向人类预训练的手部动作空间设计
作者研究在预训练过程中,人手动作表征方式的选择如何影响下游的灵巧操作性能。作者的默认设置使用 22-DoF 的灵巧关节动作空间来表征人手运动,并将其与两种替代方案进行比较:
- 一种 wrist-only 表征,它去除了所有手指层级的监督
- 一种 fingertip-based 表征 [42],该表征预测手腕和指尖在 SE(3) 中的轨迹,然后通过一个 MLP 映射为机器人关节指令
如图 8 所示——针对不同的人类预训练动作表征,在各个任务上的任务完成得分
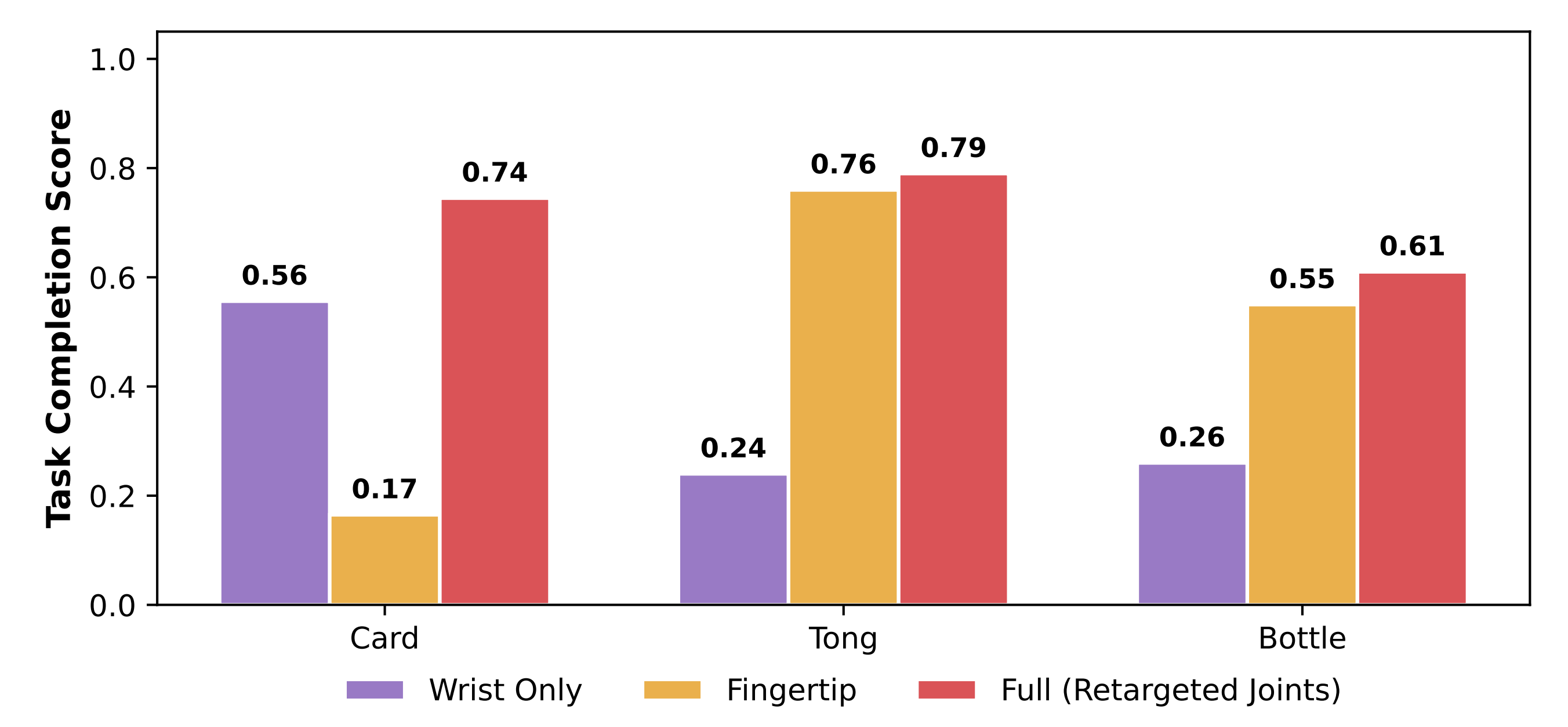
- 动作表示对任务性能有着显著影响。仅腕部的表示在所有任务上表现不佳,尤其是在那些需要精确手指关节运动和接触时序的任务中(例如,Tongs、Cards)
在这些情况下,策略经常对工具夹持过松或在不稳定的高度上抓取,或者过早闭合手部,从而导致错失接触或接触脆弱不稳 - 基于指尖的表示能够提供更丰富的几何监督,并在某些任务上提升性能,但整体仍然不够稳定。一旦指尖位姿存在细微误差,在映射后往往会产生不合理的关节配置,从而在对接触高度敏感的任务(例如 Cards 和 Bottle)中导致抓取不稳定或接触丢失
相比之下,使用重定向后的关节空间手部动作进行预训练,则在所有任务上都表现出最稳定的一致性
因此,作者在大规模人类预训练中选择重定向后的关节空间手部动作,作为一种实用且有效的方案
// 待更

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 14
14 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)