汽车VLA技术全解析:从原理到应用,再到未来趋势
前言:随着自动驾驶技术向高阶演进,端到端架构成为行业突破的关键方向,而VLA(Vision-Language-Action,视觉-语言-动作)模型作为“端到端+VLM”架构的终局形态,正重新定义智能汽车的技术边界。本文将从技术概述、工作原理、车型应用、性能体验、未来趋势五个维度,全面拆解汽车VLA技术,助力开发者、从业者快速掌握核心知识点。
一、汽车VLA技术概述

1.1 概念定义与技术定位
汽车VLA(Vision-Language-Action,视觉-语言-动作)模型,是一种将视觉感知、自然语言理解与动作控制统一到同一框架的人工智能模型,在自动驾驶领域代表了端到端技术的下一阶段。
VLA的核心在于以统一的多模态表示与训练框架,打通“看—懂—做”三环节:模型直接接收图像/视频等感知输入与自然语言任务指令,经过联合表征与时空推理,输出可执行的物理世界控制量(如车辆转向与纵向控制命令)。
核心亮点:VLA实现了视觉感知、语言推理、动作决策三合一,是深度耦合的端到端智能体系,标志着人工智能在自动驾驶领域从“感知驱动”向“认知驱动”的跨越。
从技术定位来看,VLA被视为自动驾驶大模型2.0时代的核心技术,是通往L4级别自动驾驶的关键跳板,顺应自动驾驶从模块化走向通用大模型的趋势,有望加速汽车从辅助驾驶走向高阶自动驾驶的演进,并为未来机器人和通用人工智能奠定基础。
1.2 技术架构与核心组件
VLA模型采用“三模态输入-统一表征-动作输出”的端到端架构,核心由输入层、特征编码层(视觉/语言/动作)、跨模态融合层、动作决策层、输出层组成,各组件分工明确、协同工作:
-
视觉编码器(眼睛):感知基石,接收摄像头等传感器输入,将像素数据转化为“视觉令牌”(特征)。当前主流方案为ViT(Vision Transformer)及其变体,其中CLIP/SigLIP和DINOv2是VLA领域最受青睐的两种ViT模型,提供核心视觉感知能力。
-
语言编码器(大脑):基于GPT、LLaMA等大型语言模型构建,负责解析自然语言指令、场景描述和任务目标,不仅理解字面含义,还能捕捉隐含意图和上下文关系。
-
动作解码器(手脚):将感知与推理转化为实际车辆操作,当前最受青睐的方案是基于扩散的Transformer——Diffusion模型擅长建模复杂多模态动作分布,可精准输出控制指令。
-
跨模态融合机制(核心创新):实现视觉与语言数据的对齐,常见策略为Token级融合——将视觉特征投影映射后,与文本Token级联形成单一序列,输入大语言模型统一处理。
1.3 与传统汽车技术的对比优势
传统自动驾驶采用模块化流水线(感知→预测→规划控制),依赖大量人工设计规则,模块间接口固定、误差易累积;而VLA打破模块壁垒,将感知、理解、决策融为一体,核心优势体现在4个方面:
-
泛化性更强:基于海量多样数据训练,具备优秀的分布外泛化能力,在一个城市学到的经验可迁移到其他城市,甚至跨平台(汽车→机器人)复用。
-
语义理解与决策合理性更高:依托语言模型,不仅能检测物体,还能理解场景语义和因果关系(如识别车辆左转灯→预判并线、行人伸手→预判过马路)。
-
指令交互与可解释性更好:天生支持自然语言指令(如“前方红绿灯右转”“前方便利店停车”),还能实时输出决策原因,提升用户信任度。
-
端到端统一训练优势:感知、预测、规划控制融合到同一网络,统一训练避免多模块误差累积,提升整体性能上限和鲁棒性。
二、汽车VLA工作原理深度解析
2.1 系统架构与技术机制
VLA模型本质是视觉语言模型(VLM)与端到端模型的结合体,核心采用“V(视觉)→L(语言)→A(动作)”串行统一架构,将原本分离的系统重构为统一模型:
接收图像数据与人类指令(如“安全左转”)后,在同一模型内部完成“空间智能→语言智能→行动策略”的全链路处理,直接输出方向盘、油门、刹车的具体控制信号,或机器人的7D动作参数。
系统工作流程可简化为3步:
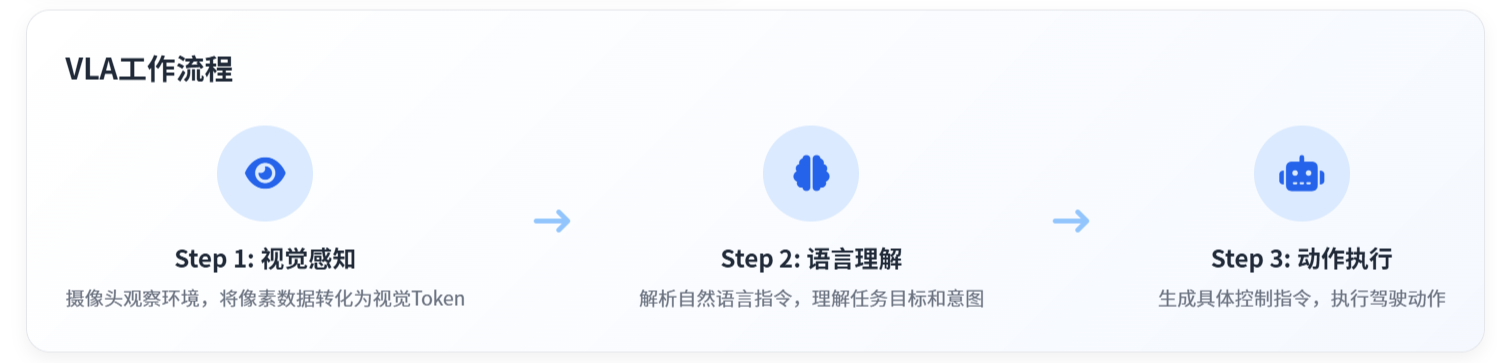
1. 视觉感知:摄像头获取环境数据,ViT将像素转化为有语义的视觉Token; 2. 语言理解:语言编码器解析自然语言指令,捕捉任务目标与隐含意图; 3. 动作执行:动作解码器将视觉+语言的融合信息,转化为可执行的动作序列。
2.2 感知、决策与控制流程
VLA系统的端到端特色,在感知、决策、控制全流程中体现得淋漓尽致,具体流程如下:
-
多模态输入采集:收集三类数据流——视觉观测(RGB-D图像等)、自然语言指令、车辆实时状态信息(关节角度、速度等)。
-
感知阶段:图像经ViT处理生成视觉Token(如一幅RGB-D图像生成400个视觉Token),再通过交叉注意力模块融合,生成包含语义、意图、情境的512维共享表示。
-
决策阶段:通过统一神经网络架构,融合视觉感知、语言理解、动作生成三大能力,联动分析环境与指令,形成决策意图(Action Token/Planning Token)。
-
控制执行阶段:动作解码器解析决策意图,输出具体控制指令;智能体执行指令后,环境状态改变,重复“感知-决策-执行”闭环,直至完成任务或达到最大步数。
2.3 关键技术与算法原理
VLA技术的核心的是“跨模态融合+动作生成”,依托Transformer架构,融合多种关键算法,解决感知、决策、部署中的核心难题:
-
多模态融合技术:除了Token级融合,还有交叉注意力融合——视觉与语言编码器各自处理模态数据,通过交叉注意力层交换信息,实现多轮关联推理。
-
扩散模型技术:基于扩散的Transformer是主流动作解码器方案,通过“迭代去噪”,在决策意图的引导下,将随机噪声还原为最优动作轨迹。
-
推理增强技术:将VLM/LLM升级为自动驾驶决策核心,赋予模型“思考”能力,输出动作前可进行解释、预测和长时程推理,提升决策合理性。
-
量化与优化技术:解决车载部署算力瓶颈,如理想汽车将22亿参数MindVLA经稀疏优化,等效为2亿激活参数,适配Orin X芯片,实现100ms级推理速度。
三、汽车VLA在不同车型的应用分析
3.1 乘用车应用案例
3.1.1 豪华车型应用情况
豪华车型是VLA技术的率先落地场景,核心代表为理想、长城魏牌:
-
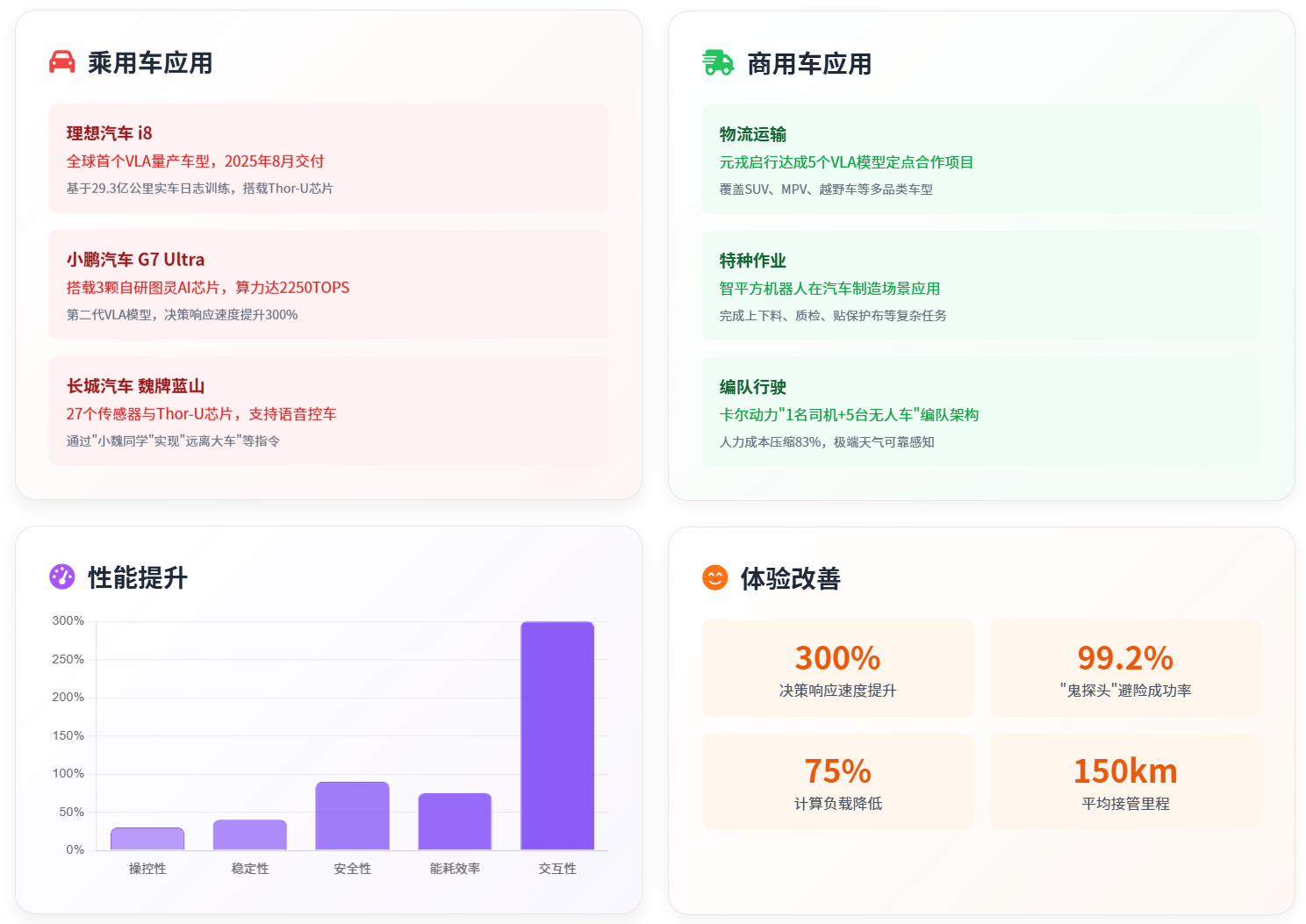
理想汽车(理想i8):全球首个将VLA司机大模型装车的车企,2025年8月随旗舰纯电i8交付,9月全量推送。
-
数据闭环:90%实车日志(29.3亿公里)+10%生成式仿真,DriveDreamer4D世界模型单日仿真30万公里;
-
算力基建:13 EFLOPS云端集群训练,车端搭载Thor-U芯片(700 TOPS),实现“车-站-云”三级算力协同;
-
用户体验:VLA辅助驾驶使用率提升3倍,泊车使用率提升2.1倍,单次最长行驶超420公里。
-
-
长城魏牌(蓝山智能进阶版):搭载27个传感器与Thor-U芯片,176%算力冗余保障流畅运行,支持“远离大车”“帮我起步”等语音控车指令,严格限定驾驶员权限。
3.1.2 经济型车型应用情况
吉利、小鹏等企业推动VLA技术下沉,实现智驾平权:
-
吉利汽车:依托“星睿智算中心2.0”(23.5 EFLOPS算力集群),极氪001 FR通过VLA实现“无图城区NOA”,复杂路口通过率达98.7%;计划2026年将与Mobileye合作的VLA方案,搭载于15万元级车型。
-
小鹏汽车:第二代VLA模型计划2026年Q1量产,搭载于2026款P7+、G7、X9等车型,单颗芯片有效算力2250 TOPS,推理效率提升12倍。
3.1.3 新能源汽车应用特点
新能源汽车的电动平台、高智能化集成度,与VLA技术高度契合,优势显著:
-
电动平台优势:电控系统高度集成,线控底盘控制精准,如小鹏G7 Ultra搭载3颗自研图灵AI芯片,两颗用于VLA,整车算力2250TOPS,支持车端大模型实时运行。
-
智能化集成度高:设计之初适配智能化需求,小鹏第二代VLA在广州老城区,可处理13种高难度场景,平均接管里程150公里(上一代的13倍)。
-
软件定义汽车特性:可通过OTA持续优化,如理想OTA 8.2版本,优化VLA驾驶平顺性,解决拥堵跟车顿挫、刹车生硬问题。
3.2 商用车与特种车辆应用
VLA在商用车领域的应用,聚焦物流运输、特种作业、编队行驶等场景,潜力巨大:
-
物流运输:元戎启行基于DeepRoute IO 2.0平台,达成5个VLA模型定点合作,首批量产车即将入市,依托近10万辆量产车型积累场景数据。
-
特种作业:智平方机器人爱宝在东风柳汽应用,完成上下料、车门质检、贴保护布等多步骤复杂任务,提升效率与灵活性。
-
编队行驶:卡尔动力采用“1名司机+5台无人车”架构,依托VLA技术和32传感器冗余,人力成本压缩83%,实现极端天气可靠感知。
3.3 不同驱动形式车辆的技术适配
VLA技术可适配多种驱动形式车辆,根据车辆特性优化适配方案:
|
驱动形式 |
适配特点 |
代表案例 |
|---|---|---|
|
纯电动车型 |
电控系统集成度高,线控底盘灵活,高算力平台支撑VLA运行 |
小鹏G7 Ultra、理想i8 |
|
混合动力车型 |
需协调发动机与电机协同控制,对控制算法要求更高 |
暂无量产案例,多家车企在研 |
|
传统燃油车型 |
电控集成度低,需升级改造现有系统 |
奇瑞猎鹰900智驾系统(VLA+世界模型) |
|
氢燃料电池车型 |
电控系统类似纯电动车,零排放适配智能交通趋势 |
暂无量产案例,技术适配中 |
四、汽车VLA带来的性能提升与体验变革
4.1 车辆性能提升
4.1.1 操控性与稳定性提升
VLA通过算法优化,显著提升车辆操控平顺性与稳定性,实测数据如下:
-
转向精度:OTA 8.2版本后,转向动作细腻度提升30%,连续弯道转向控制误差降低67%;
-
跟车平顺性:加减速度平顺性提升40%,拥堵跟车无顿挫,停车无突兀感;
-
极端场景表现:冰雪窄路等场景,可实现类人老司机稳定控车,无多余动作。
4.1.2 安全性与可靠性增强
VLA的语义理解与预判能力,大幅提升行车安全性,核心数据的亮点:
-
事故避免率:理想汽车数据显示,一般事故避免/缓解率下降30%,重大事故达90%;
-
复杂场景避险:小鹏第二代VLA,“鬼探头”等高发场景避险成功率达99.2%,可预判“球滚出→有孩子追跑”等隐含风险;
-
防御性驾驶:路口、小区出入口等场景,自动减速至20km/h左右,预判行人、车辆横穿风险。
4.1.3 能耗效率优化
通过模型优化与硬件协同,VLA实现能耗与计算效率双重提升:
-
计算效率:小鹏Fast Drive VLA技术,计算负载降低75%,节省大量电量;
-
轻量化优化:MiniVLA(1B参数)每天工作8小时仅耗0.5度电,比云端部署省70%能耗;MedVLA经4bit量化+LoRA微调,功耗降50%;
-
自适应节能:同济大学AC²-VLA框架,响应速度提升1.79倍,能耗降低70%,三合一省电模式可将计算能耗降至30%以下。
4.2 驾驶体验改善
VLA从交互、辅助、泊车、长途等多维度,重构驾驶体验:
-
语音交互体验:自然语言控车更便捷,如长城VLA支持“远离大车”“帮我起步”,融合视觉与语言理解,感知潜在危险;
-
智能辅助体验:高速领航可自动跟车、变道、调整车速,减轻驾驶疲劳;
-
泊车体验:精准完成侧方、垂直泊车,无猛打方向,比人工泊车更标准;
-
长途驾驶体验:小鹏内部测试显示,长途高速几乎无需人工干预,减少“误触发”(如不因树叶飘过紧急刹车),提升流畅度。
4.3 用户体验的多维度改善
VLA不仅优化功能体验,更构建用户与车辆的信任关系,核心改善点:
-
交互方式革新:自然语言对话控车,指令更直观,无需学习复杂操作;
-
个性化体验:记忆用户驾驶偏好,支持“先左转再右转”等组合指令,预演路口冲突提升通过率;
-
安全信任提升:CoT思维链可视化,中控屏实时显示决策推理过程,让用户理解系统行为;
-
全场景适应:精准识别潮汐车道、可变车道,破解桥洞、公交车遮挡等盲区,支持简单指令端侧响应、复杂指令云端解析。
五、汽车VLA未来发展趋势与技术融合

5.1 技术演进路径
VLA技术发展分为短期、中期、长期三个阶段,路径清晰:
-
短期(2025-2026年):低速场景(停车场、园区)上线VLA功能,采用“VLA+规则算法”并行架构;城市道路完整应用需1-2年迭代,理想汽车计划2025年底搭建训练强化闭环,力争超越特斯拉。
-
中期(2026-2028年):VLA与世界模型在“具身智能”框架下融合,构建通用驾驶智能体;模型压缩、蒸馏技术推动VLA向经济型硬件普及。
-
长期(2028年后):引入“物理一致性检查”,决策后通过轻量级世界模型验证安全性;最终收敛为“物理-语义融合大模型”,既理解交通规则,也能预测物理场景变化(如标志是否会被风吹倒)。
5.2 与其他前沿技术的融合趋势
5.2.1 与人工智能技术的融合
-
大语言模型融合:统一空间智能、语言智能、行为策略,让车辆成为高阶移动智能终端;
-
推理能力增强:推理VLA将视觉、语言、动作与逐步推理结合,提升复杂决策能力;
-
多模态融合深化:充分利用视觉、语言、动作模态信息,提升复杂场景理解与应对能力。
5.2.2 与自动驾驶技术的协同发展
-
L4级突破:VLA作为关键跳板,推动L4级自动驾驶落地;小鹏“一套模型、多维落地”,实现汽车、Robotaxi、机器人跨场景复用;
-
训练闭环建设:理想汽车从“数据闭环”转向“云端世界模型训练+车端VLA部署”,提升模型迭代效率;
-
训练方案升级:行为克隆+逆强化学习+强化学习,将成为自动驾驶模型训练主流方案。
5.2.3 与新能源技术的结合
-
电动平台协同:新能源汽车高算力平台(如小鹏图灵AI芯片),为VLA提供硬件支撑;
-
能源管理优化:VLA通过预测性驾驶、优化控制,帮助新能源汽车提升续航;
-
智能化集成:OTA升级持续优化VLA性能,契合软件定义汽车趋势。
5.3 应用场景拓展与市场前景
VLA技术应用场景持续拓展,形成“车-机器人-智能生态”的广阔布局:
-
智能座舱融合:小鹏“智能座舱智驾合流超级智能体”,融合VLA与VLM,去掉语言转译环节,决策响应速度提升300%;
-
跨平台应用:“一套权重,多端部署”,同一VLA模型可驱动无人驾驶车、工业机器人、家庭服务机器人;
-
产业生态构建:车企(特斯拉、华为)用同一VLA架构,驱动自动驾驶车辆与人形机器人,更换“动作头”即可适配不同场景;
-
技术开源与合作:小鹏第二代VLA商业开源,首发客户为大众汽车,加速技术普及。
未来拓展方向:高阶辅助驾驶(L2+)进化、自动代客泊车(AVP)革新、车路协同(V2X)质变、边缘计算优化、联邦学习应用、量子计算赋能。
六、结论与展望
汽车VLA技术作为自动驾驶领域的革命性创新,实现了视觉感知、语言理解、动作控制的深度融合,完成了从“感知驱动”向“认知驱动”的范式转变,是通往L4级自动驾驶的关键,也是智能化时代汽车行业的核心竞争力。
目前,VLA技术已在乘用车、商用车等领域实现量产落地,理想、小鹏、长城、吉利等企业持续推动技术迭代与普及,不仅带来车辆性能的全方位提升(操控、安全、能耗),更重构了用户驾驶体验,建立了人-车信任关系。
展望未来,VLA将与人工智能、新能源、车路协同等技术深度融合,短期实现低速场景规模化应用,中期推动L4级自动驾驶落地,长期形成“物理-语义融合大模型”,构建“车-机器人-智能生态”的全新格局。
尽管VLA仍面临算力、安全性、法规等挑战,但随着轻量化模型、边缘计算、联邦学习等技术的发展,这些难题将逐步破解。未来5-10年,VLA技术有望全面普及,为人类带来更安全、智能、便捷的出行体验,推动汽车行业进入真正的智能化时代。
创作不易,觉得有帮助的话,欢迎点赞、收藏、评论,关注我了解更多自动驾驶与汽车智能化前沿技术!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)