WholebodyVLA:迈向用于全身运动操控的统一潜VLA
25年12月来自复旦、港大、智元机器人公司和上海创新研究院的论文 "WholebodyVLA: Towards Unified Latent VLA For Whole-body Loco-manipulation Control"。人形机器人需要精确的运动和灵巧的操作才能完成高难度的运动操作任务。然而,现有的模块化或端到端方法在感知操作的运动方面存在不足。这限制机器人的活动范围,使其无法执行大空
25年12月来自复旦、港大、智元机器人公司和上海创新研究院的论文 “WholebodyVLA: Towards Unified Latent VLA For Whole-body Loco-manipulation Control”。
人形机器人需要精确的运动和灵巧的操作才能完成高难度的运动操作任务。然而,现有的模块化或端到端方法在感知操作的运动方面存在不足。这限制机器人的活动范围,使其无法执行大空间运动操作。造成这种情况的原因有两点:(1) 由于人形机器人远程操作数据的匮乏,获取运动操作知识面临挑战;(2) 由于现有强化学习控制器的精度和稳定性有限,难以忠实可靠地执行运动指令。为了获取更丰富的运动操作知识,提出一种统一的潜学习框架,使视觉-语言-动作 (VLA) 系统能够从低成本的、无动作的以自我为中心的视频中学习。此外,还设计一个高效的人类数据采集流程来扩充数据集并扩大应用范围。为了更精确地执行所需的运动指令,提出一种面向运动操作(LMO)的强化学习策略,该策略专门针对精确稳定的核心运动操作(例如前进、转弯和下蹲)而设计。基于这些组件,引入WholeBodyVLA,一个用于人形机器人运动操作的统一框架。WholeBodyVLA能够实现大空间人形机器人运动操作。在AgiBot X2人形机器人上进行全面的实验验证,其性能比之前的基线模型提高21.3%。
运动-操控控制器。为了超越孤立的操作或运动模仿(Cheng et al., 2024; Ji et al., 2024; He et al., 2024; 2025b;a; Ze et al., 2025; Truong et al., 2025; Chen et al., 2025b; Xie et al., 2025; Wang et al., 2025; Cheng et al., 2025; Fu et al., 2025),人们提出许多基于强化学习的全身控制器,其中大多数采用速度跟踪接口,优化指令速度下的每步误差(Ben et al., 2025; Shi et al., 2025; Li et al., 2025a; Zhang et al., 2025a;b; Sun et al., 2025)。虽然这种模型足以满足巡航需求,但它隐含启动-停止语义,导致不同速度下的步态呈现碎片化,并且对诸如制动精度或航向保真度等阶段性控制能力缺乏有效监控——而这些能力对于移动操作至关重要。上半身的影响通常被建模为与任务无关的噪声或运动片段,这些模型难以反映真实任务(抓取、举起、推动)的结构化惯性耦合,从而限制负载下的稳定性。诸如HOMIE的PD稳定手臂(Ben,2025)、AMO的轨迹优化混合算法(Li,2025a)、FALCON的力课程(Zhang,2025a)、R2S2的技能库(Zhang,2025b)以及ULC的统一残差控制器(Sun,2025)等方法虽然提高了鲁棒性,但也继承了以速度为中心的训练的局限性,导致步态不一致和遥控轨迹不稳定,从而阻碍了低级稳定性和高级VLA策略学习。
人形机器人的高级规划器。此外,强化学习控制器通常缺乏直接处理RGB视觉或语言输入的能力,不足以实现自主任务执行。为了解决这个问题,一项补充性的研究探索人形机器人的高级规划。 LE-VERB(Xue,2025)将潜动词嵌入强化学习(RL)中,用于低级工作流控制(WBC)。其他系统,如R2S2(Zhang,2025b)、Being-0(Yuan,2025)和HEAD(Chen,2025a),则采用由视觉语言模型(VLM)驱动的模块化规划器,将运动和操作作为离散技能进行排序。尽管这些框架在概念上很有吸引力,但它们受到脆弱的技能边界的限制——机器人在运动后经常处于不稳定或无法完成任务的状态——并且依赖于基于云的感知,这引入延迟并削弱实时控制。与此同时,一些初步研究尝试将视觉-语言-动作(VLA)框架扩展到人形机器人。例如,Humanoid-VLA(Ding,2025)侧重于运动,而GR00T(Bjorck,2025)则针对人形机器人的操作;两者都侧重于一种模态,而忽略另一种对于无缝执行运动操作任务至关重要的基本要素。波士顿动力公司的演示(Boston Dynamics,2025)受限于有限的工作空间,却严重依赖于昂贵的全身运动捕捉数据。这些局限性凸显构建统一框架的必要性,该框架能够将视觉和语言与全身控制相结合,从而实现人形机器人无约束的运动操作。
潜动作学习。尽管进展迅速,但当前的机器人数据集仍然远小于视觉和语言领域的数据集。其核心瓶颈在于标注动作轨迹的成本——昂贵的远程操作系统、熟练的操作人员以及大量的采集时间。潜动作学习规避这一问题:它不使用显式的动作标签,而是将帧与帧之间的视觉变化压缩成紧凑的离散token,这些token用于监督从无动作视频中学习策略。代表性方法包括 Genie(Bruce,2024)、LAPA(Ye,2025)、IGOR(Chen,2024)和 UniVLA(Bu,2025b)。这些研究共同表明,丰富的、跨具身、无动作的视频可以转化为有效的监督信号,用于VLA的训练。
WholeBodyVLA 为 VLA 模型配备可靠的运动基元,从而能够建立操作的前提条件。它利用统一的潜学习和面向运动操作 (LMO)的强化学习策略,使人形机器人能够完成远距离、大范围的任务。
WholeBodyVLA 的流程如图所示:LAM 模型在操控和感知操控的运动视频上进行预训练,为 VLM 模型提供统一的潜在监督。同时,LMO 强化学习策略经过训练,能够在干扰下实现精确稳定的运动。运行时,VLM 模型将以自我为中心的图像和语言指令编码成潜动作tokens,并以约 10 Hz 的频率解码为 (i) 双臂关节动作和 (ii) 由 LMO 以 50 Hz 的频率执行的运动指令,从而实现鲁棒的全身运动操控。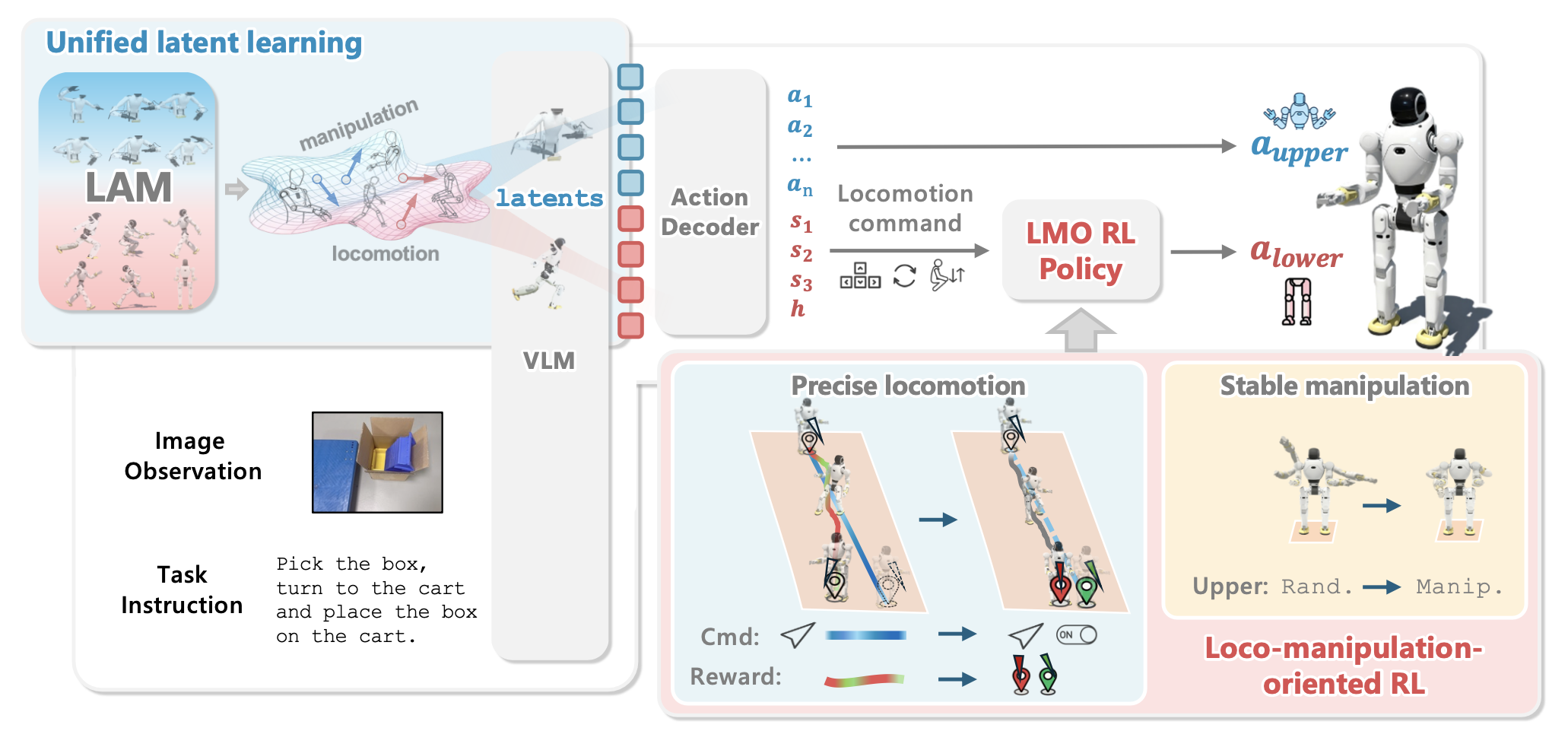
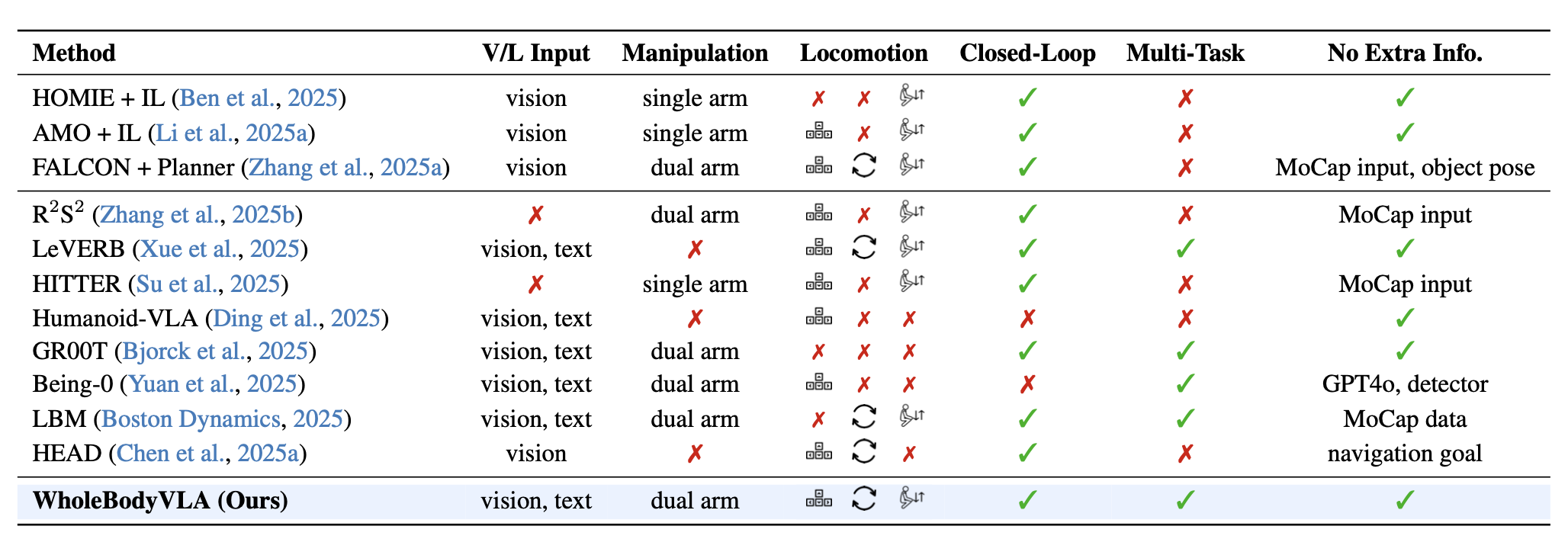
下表所示自主人形机器人控制系统比较:WholeBodyVLA通过全身控制,无需外部模块,即可在现实世界中完成各种移动操作任务。操作任务包括单臂任务和双臂协同任务,而移动任务则涵盖步进(侧向和前后)、转向和下蹲。
统一的潜动作模型
核心思想是利用潜动作模型(LAM)从以自我为中心的动作视频和感知动作的运动视频中学习动作和运动基元,然后监督VLA的训练。然而,直接在混合数据上训练单个LAM模型会产生次优的性能。这是由于两种数据源的模态存在根本差异:在动作视频中,摄像机的姿态几乎是静态的,而在运动视频中,摄像机的姿态则不断变化。这种差异从两个方面降低LAM的训练效果。首先,动作数据中的图像变化主要由手臂运动引起,这使得模型倾向于关注手臂区域;相反,运动数据中的图像变化主要来自相对于移动摄像机的环境运动,迫使模型关注整个场景。这种相互冲突的注意目标阻碍稳定表征的学习。其次,在操作数据中,LAM学习将手臂与环境相对位置的变化编码为手臂运动,而在运动数据中(手臂通常保持在视野内,尤其是在运动操作任务中),同样的相对位置变化是由相机运动引起的。LAM可能会错误地将这些变化解释为手臂运动而非运动,从而导致潜在编码的歧义。因此,分别训练两个LAM:一个用于操作数据的操作LAM和一个用于运动数据的运动LAM。然后,将这两个LAM联合起来,用于监督VLA的训练。
具体来说,借鉴Genie(Bruce,2024)和UniVLA(Bu,2025b)的方法,采用VQ-VAE架构(Van Den Oord,2017),并在DINOv2(Oquab,2024)特征的基础上构建编码器。给定连续帧 (o_t, o_t+k),LAM 编码器 E 首先输出一个连续的潜向量 z_t = E_i(o_t, o_t+k),然后将其量化到学习码本中最近的条目:ci_t = argmin ||z_t − c||_2。索引 i ∈ {mani, loco} 分别表示操作 LAM 和运动 LAM。为了训练编码器 i 和码本 i,LAM 解码器 i 接收前一帧和量化后的潜动作,并训练其重构后一帧 o_t+k = D_i(o_t, c_t)。重构通过最小化标准 VQ-VAE 损失进行优化。在预训练潜动作模型(LAM)之后,训练视觉-语言-动作(VLA)策略π_θ,使其能够根据视觉观察和任务语言,通过交叉熵损失函数联合预测两种类型的潜动作,从而最大化:
max π_θ (cmani_t, cloco_t | o_t, l), (1)
其中 l 代表语言指令。这种统一的预测方式促使模型学习运动和操作如何在单一的、连贯的动作空间中相互作用,以支持任务执行。
最后,为了在人形机器人上运行,引入一个轻量级解码器 f,将潜动作转化为机器人特定的命令:a_t = f(ˆcmani_t ,ˆcloco_t, s_t),其中 s_t 是机器人状态。该解码器生成 (i) 上半身关节角度和 (ii) 指示要执行的动作的运动命令。该命令由 LMO 强化学习策略转换为下半身扭矩。通过这种分工,VLA 提供统一的潜决策,解码器将其转化为特定于身体的控制信号,RL 策略确保稳定执行——在实践中实现全身运动操控。
感知操作的运动数据采集。为了进一步扩大统一潜学习的收益,提出利用大量易于采集的、以人类为中心、感知操作的运动视频。设计一个以人类为中心的数据采集流程,其特点包括:(1)低成本、高效率,仅需一名操作员佩戴头戴式摄像头,避免了昂贵的动作捕捉或远程操作;(2)覆盖类人基本动作,操作员应执行所有类型的运动,例如前进、转身和下蹲;(3)目标导向执行,操作员应执行与潜操作目标相符的运动,确保运动数据与运动-操作学习直接相关。
本文设计一个简单而高效的数据采集流程,仅需一名操作员佩戴摄像头即可完成数据采集。采集过程中,用两种类型的摄像头:(1)Intel RealSense D435i RGB-D 摄像头;(2)GoPro 摄像头,后者提供更大的视野范围 (FOV),从而能够采集更适合模型学习的运动数据。操作员将摄像头佩戴在头部,并执行各种运动操作任务。对于操作环节,操作员无需实际执行物体交互;只需识别潜在的可操作物体并靠近直至接触即可。对于运动环节,指示操作员执行各种动作,例如前进、转身和下蹲。如图展示数据采集流程的示意图: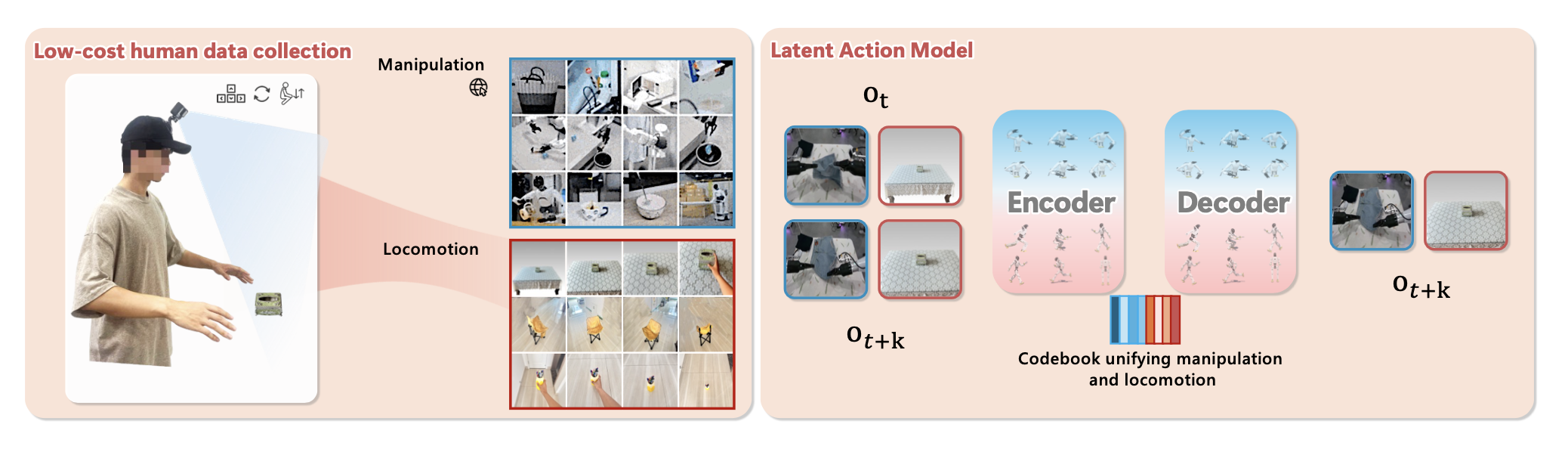
所有实验均在原型人形机器人平台 Agibot X2(如图所示)上进行。该机器人每条手臂具有 7 个自由度,末端执行器为 Omnipicker 机械臂;腰部提供 1 个自由度;每条腿具有 6 个自由度,支持多种全身运动。为了实现以自我为中心的感知,在机器人头部安装一台 Intel RealSense D435i RGB-D 摄像头,为运动和操作任务提供同步的 RGB 数据流。通过物理机器人远程操作采集训练和评估数据。MetaQuest Pro 头显提供以自我为中心的上半身 VR 远程操作,而运动指令则通过操纵杆发出。三个任务中的每一个都执行 50 次,以获得不同的训练轨迹。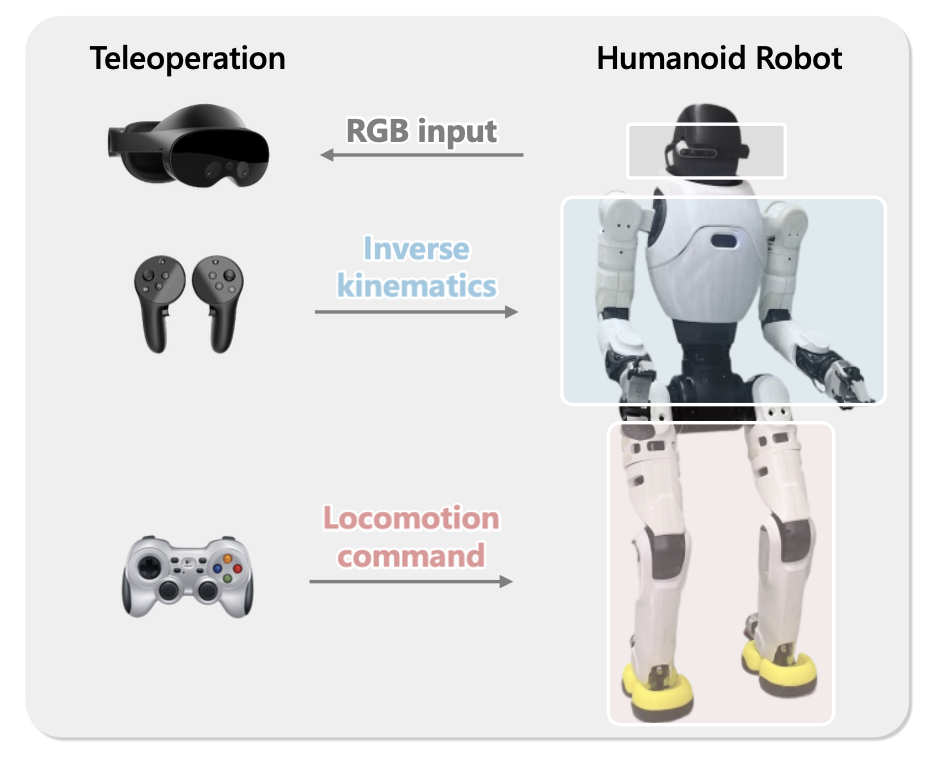
面向运动操作的强化学习策略
如前所述,运动操作中的一个主要失败模式是高层决策与底层执行之间的不一致。这个问题主要源于现有强化学习控制器中使用的连续随机速度跟踪目标——这些目标旨在实现广泛的运动,而非运动操作所需的稳定、可靠的启停和方向控制。这里一种面向运动操作(LMO)的强化学习框架,用离散命令接口取代速度跟踪,从而实现了更精确的执行。
观测空间。该策略仅依赖于本体感受的自我中心状态,并具有一个短历史堆栈:O_t = [u_t, ω_t, g_t, q_t, q̇_t, a_t−1],其中包括基座角速度、重力矢量、关节状态和先前的动作。这种紧凑的设计避免对特殊环境信息的依赖,同时又足以保证闭环稳定性。
离散指令接口。将下肢控制建模为目标条件调节,其中策略在保持平衡的同时执行离散的高级指令。在每个时间步,规划器生成一个指令 u_t = [s_x, s_y, s_ψ, h⋆] ∈ {−1, 0, 1},其中 s_x、s_y 和 s_ψ 分别表示前进、侧向和转弯的离散指示符,h⋆ 指定站姿高度。与基于速度的建模方法不同,接口强制执行显式的启动-停止语义,并降低轨迹方差,从而改进强化学习控制器和高级规划器的训练过程。
参考成形。由于输入是三元标志,为每个轴指定一个目标速度幅度 vgoal_k ≥0,其符号由意图 s_k 决定。为了避免突然加速,方向意图通过一个平滑的门控函数进行处理:
vref_k(t) = vgoal_k tanh α(s_k −s ̄_k (t)) , s ̄_k (t)←(1−λ)s ̄_k (t−1)+λs_k, (2)
对于 k ∈ {x, y, ψ},其中 s ̄_k 是指数平滑的标志。这种设计确保可预测的开/关转换,并减少振荡。
两阶段课程。采用两阶段训练方案,首先学习基本的运动技能,然后将其专门化为精确稳定的运动操控。
第一阶段(基本步态学习)。对于每个轴 k ∈ {x, y, ψ},如果 s_k ̸= 0,则采样目标速度幅度 vgoal_k ∼ U([0, vmax_k]),其符号由 s_k 决定;否则 vgoal_k = 0。对于上半身,遵循 HOMIE 算法(Ben,2025),手臂跟踪以固定间隔重采样并插值以实现平滑运动的姿态目标,同时通过一个课程因子逐步放宽关节限制,使腿部逐渐承受更强的扰动。此阶段使策略能够发展出防止跌倒的基本步态,为后续的优化提供稳定的基础。
第二阶段(精度和稳定性)。第二阶段通过专门的优化进一步提高运动操作级别的精度和稳定性。在运动方面,将每个轴的巡航速度固定为常数 (vgoal_k = v ̄_k),以标准化巡航并抑制在没有偏航意图时出现的非预期航向漂移(起始/结束时的 s_ψ = 0 不应引起偏航)。方向精度通过末端偏差来衡量:
J_dir = | wrap( ψ_end − ψ_start) |, (3)
其中,当任意轴的标志从 0 翻转到 ±1 时,一个episode开始;当标志返回 0 且基座稳定时,episode结束。最小化 E[J_dir] 可以确保精确的启动、稳定的巡航和一致的制动。在操作方面,通过从 Agibot-World (Bu et al., 2025a) 中采样短的机械臂运动片段,将其插值成连续信号,并以不同的速率重放这些信号并添加轻微噪声,来注入真实的扰动。这迫使腿部补偿结构化的惯性耦合,而非非结构化的扰动。此外,对于静止阶段(s_x = s_y = s_ψ = 0),添加静止惩罚项,以抑制不必要的腿部动作:
J_stand = ||aleg_i||2, (4)
这些设计共同实现了稳定、可重复的步态和可靠的全身协调,避免速度跟踪目标常常导致的运动模式碎片化。
设置
硬件、任务和数据采集。用 Agibot X2 人形机器人原型(7 自由度手臂,配备 Omnipicker 夹爪;6 自由度腿部;1 自由度腰部;以及一个以自我为中心的 Intel RealSense D435i 摄像头)进行评估。三个任务全面测试机器人的运动操作能力:(i)装袋——抓取纸袋,侧身走到纸箱旁,蹲下并将纸袋放入纸箱;(ii)装箱——蹲下抓取纸箱,转身并将其放置在推车上;(iii)推车——抓取 50 kg 的推车把手并稳定地向前推动。这些任务共同评估双臂协调性、蹲下精度、转弯精度以及重载下的稳定性。
基线。将 WholeBodyVLA 与一些具有代表性的模块化流程进行比较,包括导航辅助模块化设计基线、VLA 框架 GR00T N1.5 (Bjorck,2025) 和 OpenVLA-OFT (Kim,2025)。这两个框架均经过调整,能够输出双臂关节动作以及与 WholeBodyVLA 相同的离散运动指令(由LMO 控制器执行)。此外,还比较设计的简化版本,这些版本要么移除/替换 LMO,要么修改了统一潜学习(无 LAM、仅操作 LAM 或在混合数据上使用单个共享 LAM)。
GR00T(含LMO)。GR00T N1.5(Bjorck,2025)是一款最新的VLA模型,支持全身控制。为了公平起见,对其输出进行调整:GR00T不再直接预测下肢关节,而是预测运动指令,然后由LMO控制器执行这些指令。这使得GR00T的高级推理能力与低级运动稳定性问题隔离开来。
OpenVLA-OFT(含LMO)。由于架构和模型大小的差异可能会影响与GR00T的比较,进一步评估OpenVLA-OFT(Kim,2025),它与WholeBodyVLA共享相同的Prismatic-7B初始化。OpenVLA-OFT经过训练,可以预测上肢关节动作和运动指令,并由与本文系统相同的LMO控制器执行。
模块化设计。为了模拟模块化流程,用佩戴FPV头显的远程操作员替换导航模块。操作员仅通过手持操纵杆控制移动,无需参与数据采集过程,完全依赖任务指令和场景信息。导航结束后,控制权移交给WholeBodyVLA进行操作,在此期间操作员完全无法操作;操作完成后,控制权返回给操作员。这确保公平的比较,并为模块化流程提供一个接近理想上限的基准。
训练方案。遵循标准的 VLA 流程,即先进行大规模预训练,然后进行真实机器人微调。对于 WholeBodyVLA,预训练分为两个步骤:第一阶段,在大规模的以自我为中心的操控和感知操控的运动视频上分别预训练操控和运动的 LAM 模型;第二阶段,使用 LAM 编码作为伪动作标签,在同一语料库上训练 VLA 模型来预测这两种潜动作。对于 VLA 基线模型(GR00T、OpenVLA-OFT),用它们公开发布的预训练模型。在微调阶段(第三阶段),所有方法均使用相同的 Agibot-X2 远程操作轨迹进行训练,涵盖所有任务。LMO 控制器及其基于速度的基线模型(Ben,2025)在仿真环境中分别进行训练,并在远程操作数据采集和最终部署期间保持不变。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 46
46 0
0- 0



 已为社区贡献211条内容
已为社区贡献211条内容

所有评论(0)