Fast-ThinkAct:通过语言化潜规划实现高效的VLA推理
26年1月来自NV的论文“Fast-ThinkAct: Efficient Vision-Language-Action Reasoning via Verbalizable Latent Planning”。视觉-语言-动作(VLA)任务需要在复杂的视觉场景中进行推理,并在动态环境中执行自适应动作。尽管近期关于推理型VLA的研究表明,显式思维链(CoT)可以提高泛化能力,但由于推理过程冗长,其推
26年1月来自NV的论文“Fast-ThinkAct: Efficient Vision-Language-Action Reasoning via Verbalizable Latent Planning”。
视觉-语言-动作(VLA)任务需要在复杂的视觉场景中进行推理,并在动态环境中执行自适应动作。尽管近期关于推理型VLA的研究表明,显式思维链(CoT)可以提高泛化能力,但由于推理过程冗长,其推理延迟较高。本文提出一种高效的推理框架——Fast-ThinkAct,它通过语言化的潜推理实现简洁而高效的规划。Fast-ThinkAct通过向教师学习,并由偏好引导的目标驱动,学习如何高效地运用潜CoT进行推理。该目标旨在调整操作轨迹,从而将语言和视觉规划能力迁移到具身控制中。这使得推理-增强的策略学习能够有效地将简洁的推理与动作执行联系起来。
Fast-ThinkAct 如图所示: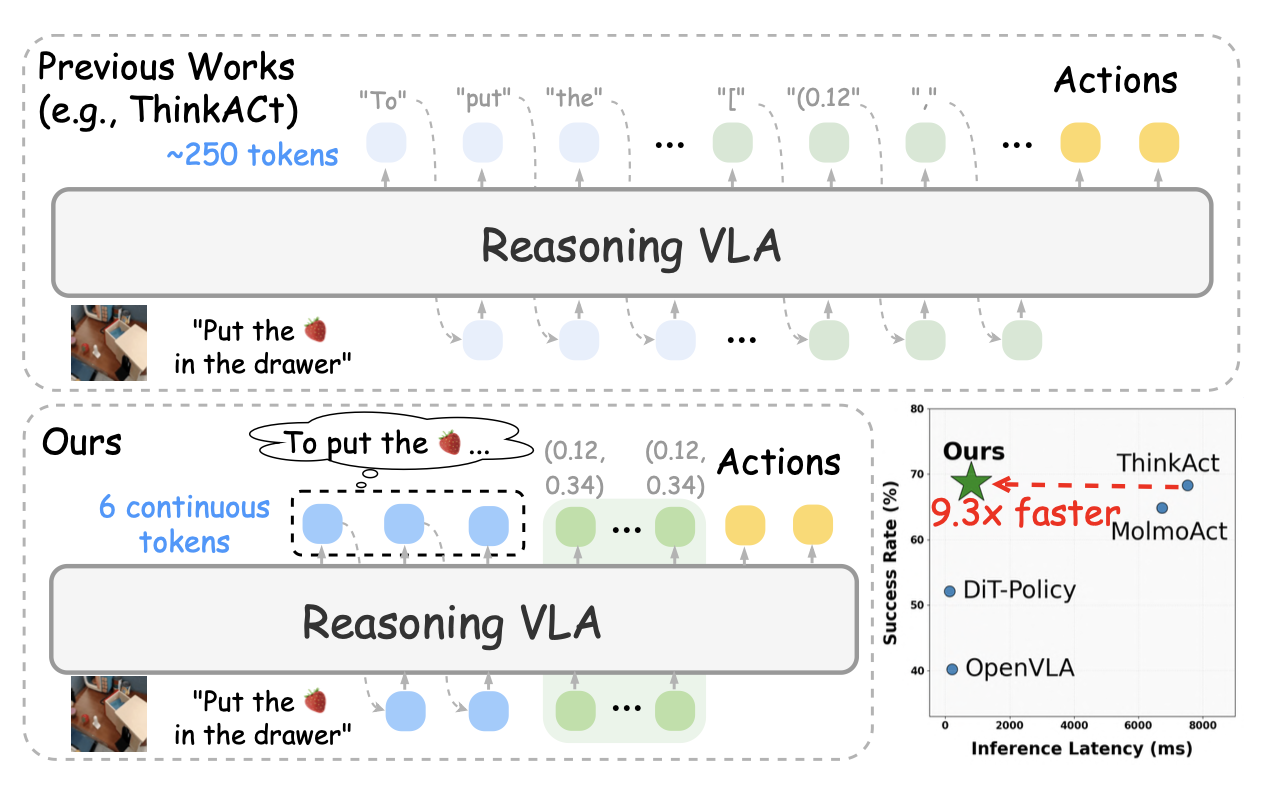
Fast-ThinkAct 概述如图所示:a) 给定观测值 𝑜_𝑡 和指令 𝑙,文本教师 VLM FT_𝜃 生成显式推理链;潜学生 VLM F_𝜃 根据奖励偏好将这些推理链提炼成紧凑的潜tokens z;语言化 LLM 𝒱_𝜓 通过 L_verb 将潜tokens解码为文本,用于基于偏好的学习;同时,L_distill 从教师模型迁移视觉规划能力,空间tokens则通过 L_ans 实现并行视觉轨迹预测,从而确保潜tokens可语言化并基于视觉规划。(b) 推理增强策略学习;动作模型 𝜋_𝜑 使用 L_IL 进行训练,同时冻结潜学生模型 F_𝜃 和状态编码器。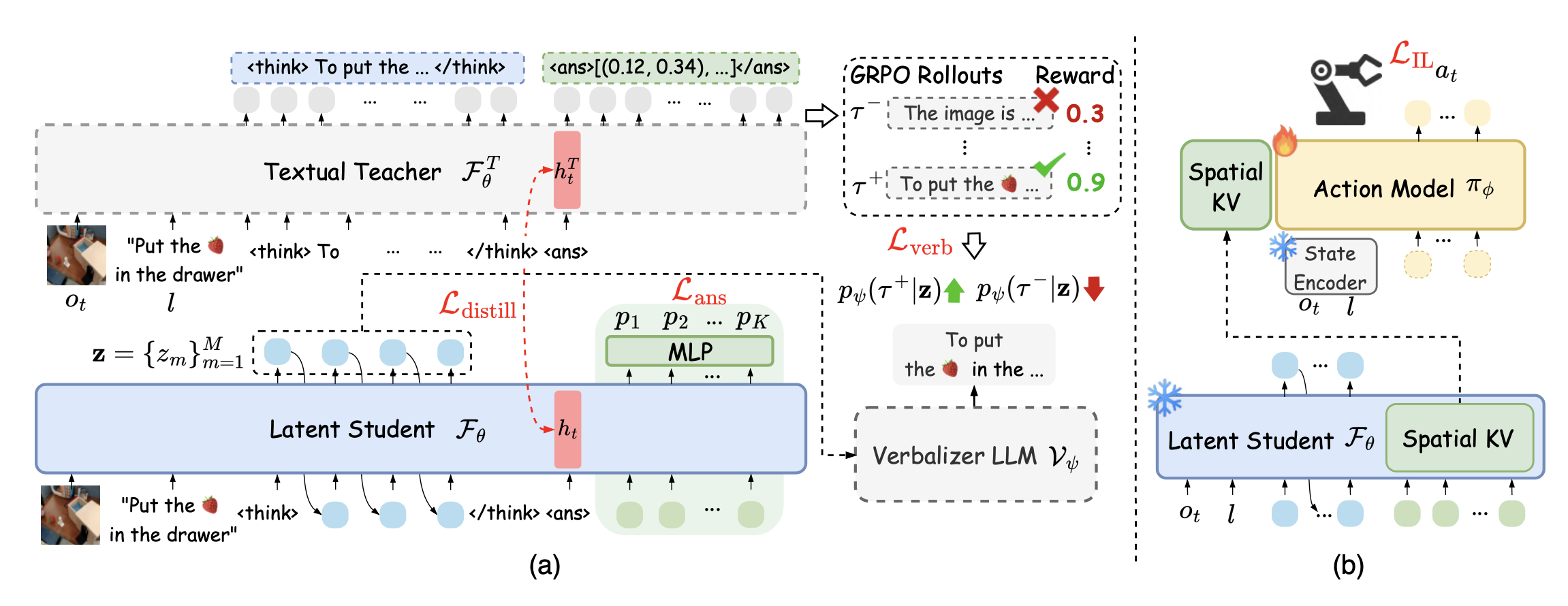
问题描述
首先定义设定和符号。在每个时间步 t,给定一条语言指令 l,模型观察视觉输入 o_t,并生成一个动作块 a_t,该动作块表示为一系列连续的机器人控制向量(例如,单臂机器人为 7 自由度,双手机器人为 14 自由度)。
为了解决这个问题,提出 Fast-ThinkAct,一个高效的推理框架,它将高层规划与底层动作执行连接起来。方法采用 VLM F_𝜃 在连续潜空间中进行推理,并集成动作模型 𝜋_𝜑 以生成可执行的动作。具体而言,F_𝜃 通过潜思维链 (CoT) 推理处理观察-指令对 (𝑜_𝑡,𝑙),生成一个紧凑的视觉规划潜变量 𝑐_𝑡,该规划概括视觉空间中的预期轨迹。随后,该 𝑐_𝑡 指导 𝜋_𝜑 预测可执行的动作 𝑎_𝑡。通过将推理过程蒸馏到连续的潜空间而非离散文本,Fast-ThinkAct 显著提高推理效率,并通过更好地保留空间和视觉信息来增强动作表现。
高效的具身推理
为了实现满足具身人工智能任务实时性要求的高效具身推理,目标是将冗长的文本推理轨迹(CoT)压缩成一组紧凑的连续潜表示。然而,将推理轨迹压缩成潜表示极具挑战性,因为潜空间中没有直接的监督信号来指导应该编码哪些推理模式。
基于奖励偏好的可语言化潜CoT
为了应对这一挑战,提出在自然语言空间中进行蒸馏,引入一个语言生成器(verbalizer)LLM,将潜表示解码为可语言化的推理。这种方法将潜学习建立在可解释的文本形式之上,确保学习的潜表示能够忠实地保留底层推理结构。由于教师模型 FT_𝜃 生成的推理轨迹质量参差不齐,采用一种基于偏好的学习框架,该框架利用教师 GRPO 训练的奖励信号来引导潜学生模型 F_𝜃 学习高质量的推理模式,同时抑制低质量的推理模式。
具体而言,采用一种师生框架,其中的文本教师模型 FT_𝜃 首先通过最大化 J_GRPO 来学习显式推理(Shao,2024),其中 𝜏 表示推理轨迹,𝑟_𝜃 (𝜏) = FT_𝜃 (𝜏)/FT_old (𝜏) 是概率比。群体奖励 {𝑅_𝑖} 的优势函数为 A(𝜏)。
该训练过程会生成质量各异的文本CoT,其中优势函数 𝐴(𝜏) 自然地作为质量指标。为了构建用于蒸馏的偏好对,从每个展开组中选择优势最高和最低的词条:𝜏+,𝜏−。
学生模型 F_𝜃 不生成文本tokens,而是通过自回归生成 𝑀 个连续潜向量 z = {𝑧_𝑚} 来进行潜推理,其中 𝑑 是隐层的大小。然后,训练语言生成器 LLM 𝒱_𝜓 将这些潜向量 z 解码为自然语言。训练目标鼓励语言生成器赋予解码高质量推理 𝜏+ 比低质量推理 𝜏− 更高的概率。此方法受 DPO Rafailov (2023)的启发 ,将其表述为由奖励偏好引导的优化:L_verb,其中 𝑝_ref 是参考模型(即没有潜条件反射的 𝒱_𝜓),𝜎 是 sigmoid 函数,𝛽 = 0.1 控制偏好强度。这鼓励学生 VLM F_𝜃 编码由语言生成器解码为高质量推理的潜信息,同时抑制低质量模式。
动作-对齐视觉规划蒸馏
虽然语言生成器的损失使学生 F_𝜃 能够捕捉高层次的推理模式,但它并没有明确保证潜表征编码对具身控制至关重要的视觉规划能力。为了解决这个问题,引入动作对齐视觉规划蒸馏,将教师 F𝑇_𝜃 的空间推理能力传递给学生 F_𝜃。
从教师模型中提取空间推理能力,该教师模型通过轨迹级奖励(例如,目标完成和轨迹对齐,Huang (2025))进行训练,以实现基于上下文的视觉规划。通过最小化编码视觉规划的 token的隐状态之间 L2 距离来对齐轨迹级表征:L_distill,其中 h𝑇_𝑡 和 h_𝑡 分别是来自教师模型(对应于 𝜏+)和学生模型的隐状态。
为了实现高效的并行轨迹预测,与自回归生成冗长路径点文本序列 {p_k}(当 𝐾 = 5 时被token化为 60-70 个tokens)的文本教师模型不同,学生模型使用附加到推理潜序列的 𝐾 个可学习空间tokens {s_i},并将每个输出隐状态h′(s_i) 同时通过多层感知器 (MLP) 投影到一个路径点p_i,其和真实路径点pˆ_i 的差即损失L_ans。训练目标 F_𝜃 结合所有三个组成部分:L_ans,L_verb和L_distill。通过这一统一框架,学生模型 F_𝜃 能够执行简洁而富有表现力的潜推理,并高效地生成视觉轨迹规划。
推理增强策略学习
在学生视觉-语言模型 F_𝜃 执行紧凑的潜推理并通过空间tokens生成视觉轨迹规划后,利用这些表示来指导基于扩散transformer的动作模型 𝜋_𝜑(例如,RDT Liu (2024))进行动作预测。为了将高层视觉规划与低层动作生成连接起来,将编码在与空间tokens对应的KV缓存中的视觉潜规划 𝑐_𝑡 连接到动作模型。
具体来说,从早期 VLM 层的空间token LV缓存中提取视觉潜规划 𝑐_𝑡(因为 F_𝜃 的层数比 𝜋_𝜑 多),并将其与动作模型状态编码器中的KV对连接起来。然后,动作模型的交叉注意机制会同时关注视觉规划上下文和状态观测。用动作标注的机器人数据进行后训练,方法是冻结 F_𝜃 和状态编码器,仅更新 𝜋_𝜑,并采用模仿学习目标:
L_IL(𝜑) = l (𝜋_𝜑(𝑜_𝑡, 𝑙, 𝑐_𝑡), 𝑎ˆ_𝑡) ,
其中 l 表示扩散策略的去噪目标,𝑎ˆ_𝑡 是真实动作。通过这种后训练,动作模型能够有效地将紧凑潜推理的视觉规划转化为底层机器人动作。
学习策略和推理
训练策略。用预训练的 VLM 上的 SFT 和 CoT-SFT 算法,从同一个检查点初始化教师 FT_𝜃 和学生 F_𝜃。教师模型使用 GRPO 进行训练,并采用动作对齐奖励(Huang,2025),而学生模型则使用 L_student 进行训练,以将推理压缩成紧凑的潜变量。然后,将训练的 F_𝜃 与动作模型 𝜋_𝜑(初始化自 Liu,2024)连接起来。具体方法是:在大规模机器人数据上,冻结 F_𝜃 和状态编码器,同时使用 L_IL 更新潜投影器和 𝜋_𝜑。对于目标环境的适应(例如 LIBERO,Liu,2023;RoboTwin2.0,Chen,2025),用特定环境的演示数据进行微调。
推理过程。F_𝜃 通过紧凑的潜推理处理 (𝑜_𝑡, 𝑙),并通过 𝐾 个空间tokens生成视觉轨迹。从空间token的KV缓存中提取的视觉潜规划𝑐_𝑡,用于指导𝜋_𝜑预测动作𝑎_𝑡。推理仅需要F_𝜃和𝜋_𝜑;语言生成器𝒱_𝜓仅在训练期间使用,也可选择性地用于提高可解释性。
实验设置
实现细节。用 Qwen2.5-VL 3B(Bai,2025)作为 VLM 骨干网络。SFT 阶段运行 1 个 epoch,批大小为 64,学习率为 1e−5,随后使用相同的超参进行 15K 次迭代的 CoT-SFT 训练。对于师生训练,FT_𝜃和 F_𝜃均从 CoT-SFT 检查点初始化,并使用批大小为 128 和学习率为 1e−6 进行 4,500 次迭代的训练。教师模型使用 GRPO 算法(Shao,2024)进行优化,并结合动作对齐的视觉奖励(Huang,2025)和问答式奖励。在学生训练的前 3000 次迭代中,用标准的语言模型损失函数训练语言生成器 𝒱_𝜓,然后在剩余的 1500 次迭代中切换到 L_verb。对于推理增强策略学习,用 DiT-Policy(Chi,2023)初始化 𝜋_𝜑,该模型在 OXE 数据集上预训练(O’Neill,2024),用于 SimplerEnv;并使用 RDT(Liu,2024)初始化 𝜋_𝜑,用于 LIBERO 和 RoboTwin2.0。线性投影将 VLM 的 KV 缓存调整到动作模型的维度(DiT-Policy 为 1024,RDT 为 2048)。训练运行 2 万次迭代,批大小为 256,学习率为 1e−4。所有扩散超参均与相应动作模型的参数一致。所有实验均在配备 80 GB 显存的 16 个 NVIDIA A100 GPU 上进行。
训练数据集和评估基准。对于推理型 VLM 训练,用 Lee (2025) 标注的单臂视觉轨迹和来自 AIST 数据集 Motoda (2025) 的双臂视觉轨迹,以及来自 PixMo Deitke (2024)、RoboFAC Lu (2025)、RoboVQA Sermanet(2024)、ShareRobot Ji (2025)、EgoPlan Chen (2023) 和 Video-R1 Feng (2025) 的 QA 任务。对于推理增强型策略学习,用来自 OXE 数据集 O’Neill (2024)的动作数据。 遵循 OpenVLA Kim (2024) 的方法,在使用 DiT-Policy 进行训练时,以及在使用 RDT 进行训练时,使用来自静态 Aloha 数据集 Shi (2023) 和 Zhao (2023) 的双手动数据进行数据增强。
在四个具身推理基准测试和三个机器人操作基准测试上评估 Fast-ThinkAct。对于具身推理,用 EgoPlan-Bench2 Qiu (2024)(多项选择题的准确率)、RoboVQA Sermanet (2024)(基于 Papineni (2002) 的 BLEU 分数)、OpenEQA Majumdar (2024) 和 RoboFAC Lu (2025)(两者均使用基于 LLM 的评分)。值得注意的是,RoboVQA 和 RoboFAC 包含从真实机器人捕获的视频。对于机器人操作,用 SimplerEnv(Li,2024)进行评估,该模型与实际性能具有很强的相关性;LIBERO(Liu,2023)涵盖包括长时域场景在内的各种操作任务;RoboTwin2.0(Chen,2025)则用于复杂的双手操作。
如下是训练算法总结:
实现细节
语言生成器模型 𝒱_𝜓 由一个小语言模型 Qwen3-0.6B 初始化,并在每一层插入交叉注意层,以对潜 CoT z 进行条件化。在学生模型训练中,前 3000 次迭代中,将语言化损失 L_verb 替换为语言建模损失,并使用 𝜏+ 作为真实值,以使 𝒱_𝜓 与潜表示 z 对齐。然后,冻结 𝒱_𝜓,并在剩余的 1500 次迭代中使用 L_verb。学生模型的 F_𝜃 在这两个阶段都进行优化。对于公式中的路径点预测, 每个 𝑝_𝑖 以 [𝑥_single, 𝑦_single, 𝑥_left, 𝑦_left, 𝑥_right, 𝑦_right] 的格式编码坐标,其中前两个维度用于单臂机器人,后四个维度用于双臂机器人。对于真实值 𝑝ˆ_𝑖,根据机器人类型填充相应的维度,并在计算 L_ans 时屏蔽未使用的维度。对于 GRPO 训练,遵循 ThinkAct Huang (2025) 的配置,使用 展开(rollout) 大小 𝑁 = 5。遵循 Lee (2025),将轨迹中的路径点数量设置为 𝐾 = 5,用 𝑀 = 6 个潜推理tokens。
在推理增强策略学习过程中,对于 SimplerEnv Li(2024)的评估,为了确保与先前的工作 Kim(2024)和 Lee(2025)进行公平比较,用在相同 OXE 数据集 O’Neill(2024)和 Kim(2024)上预训练的 DiT-Policy Chi(2023)初始化 𝜋_𝜑,并使用相同的 OXE 数据进行推理增强策略学习。对于 LIBERO Liu(2023)和 RoboTwin2.0 Chen(2024)的评估,用 RDT Liu (2024) 初始化 𝜋_𝜑,该 RDT 在 RoboTwin2.0 上表现出色;用 OXE O’Neill (2024) 和静态 ALOHA 数据集 Shi (2023);Zhao (2023) 进行策略学习。该方法进一步增强 RDT 在这两个基准数据集上的操控能力。使用不同的动作模型也表明,其方法与底层动作模型的选择无关。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 31
31 0
0- 0



 已为社区贡献211条内容
已为社区贡献211条内容

所有评论(0)