强化学习篇---强化学习概述
强化学习是一种让智能体通过试错与环境互动来优化决策的方法。其核心组件包括智能体、环境、状态、动作和奖励,通过观察-行动-反馈循环不断改进策略。算法分为基于价值、基于策略和混合方法三类,能处理长期决策且无需标注数据。典型应用包括游戏AI、机器人控制和推荐系统等,如AlphaGo通过自我对弈超越人类。强化学习的本质是让机器从错误中学习,最终成为特定领域的专家。
强化学习入门指南:让机器学会“吃一堑,长一智”
什么是强化学习?
想象你在训练一只小狗:
-
小狗坐下 -> 你给零食(奖励)
-
小狗乱叫 -> 你不理它(无奖励)
-
小狗拆家 -> 你批评它(惩罚)
慢慢地,小狗学会了“坐下有好处,拆家没好处”。
强化学习就是让计算机程序(智能体)像小狗一样,通过与环境互动、不断试错,学会做出最优决策的方法。
生活中的强化学习例子
| 场景 | 智能体 | 环境 | 动作 | 奖励 |
|---|---|---|---|---|
| 学骑自行车 | 你 | 道路+自行车 | 调整方向/蹬脚踏 | 不摔倒(+1) / 摔倒(-10) |
| 玩游戏 | 玩家 | 游戏世界 | 移动/攻击 | 得分(+),掉血(-) |
| 投资股票 | 投资者 | 股市 | 买入/卖出 | 赚钱(+),亏钱(-) |
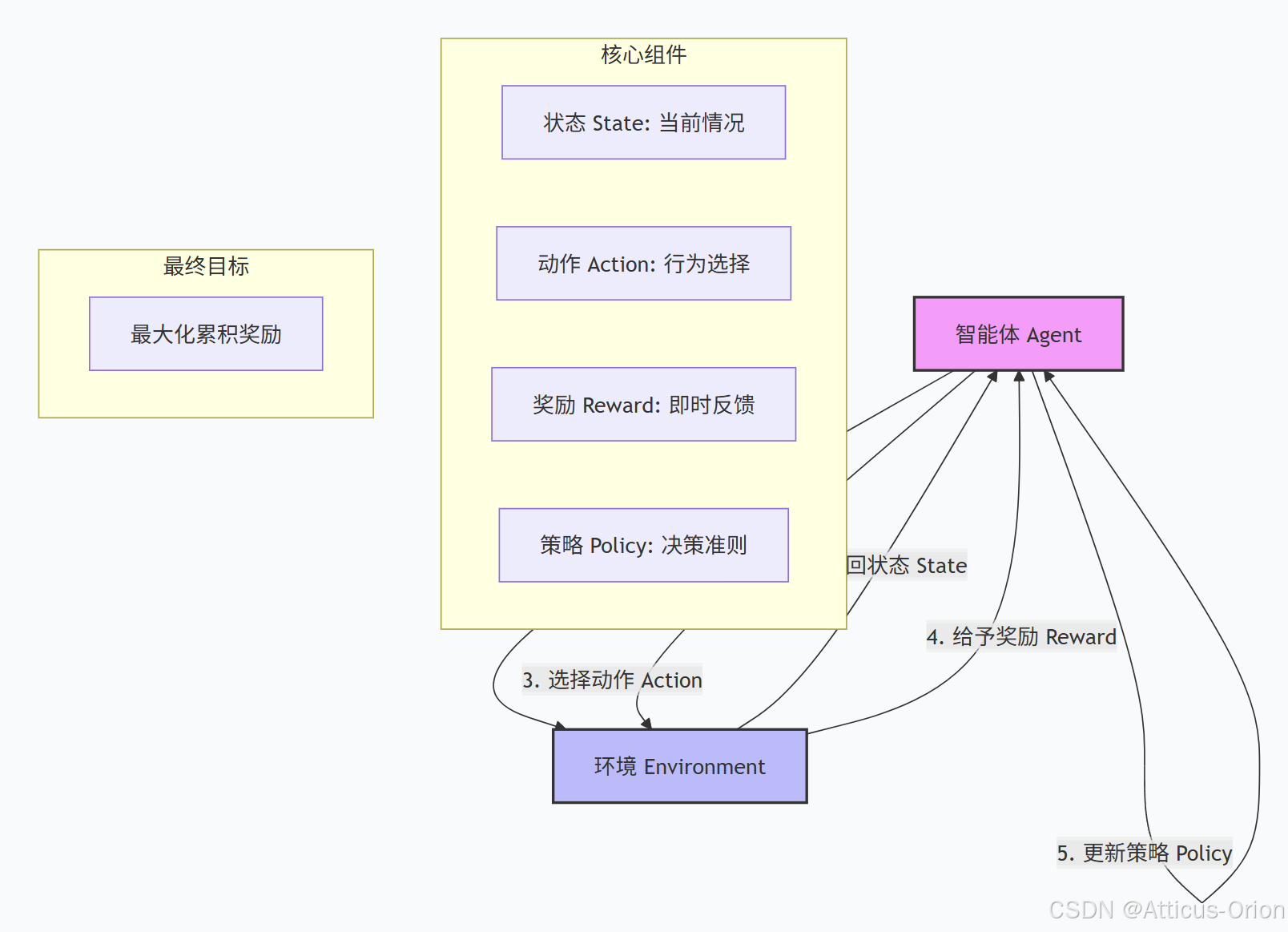
强化学习的核心组件
强化学习有5个关键组成部分,就像舞台剧的5个角色:
1. 🎭 智能体(Agent)
“做决策的主角”
-
是学习的主体,比如游戏AI、机器人、推荐系统
-
它的目标是获得最多的累积奖励
2. 🌍 环境(Environment)
“智能体生存的世界”
-
智能体与之交互的一切外部事物
-
比如游戏画面、物理世界、用户行为
3. 📊 状态(State)
“当前时刻的快照”
-
描述环境在某一时刻的情况
-
比如:游戏中角色的位置、血量、周围敌人
4. 🎮 动作(Action)
“智能体可以做的选择”
-
智能体在某个状态下可以采取的行动
-
比如:向左走、向右走、跳跃、开火
5. 🏆 奖励(Reward)
“即时的反馈信号”
-
执行动作后环境给智能体的分数
-
可以是正的(奖励)或负的(惩罚)
-
关键:奖励是即时的,但目标是最大化长期总奖励
核心循环过程
1. 智能体观察当前状态 S 2. 智能体选择动作 A 3. 环境响应动作,给出新状态 S' 和奖励 R 4. 智能体根据奖励调整策略 5. 重复1-4步
核心概念深度理解
策略(Policy):智能体的决策手册
-
是什么:从状态到动作的映射函数
-
通俗理解:就是智能体的“行为准则”
-
例子:
-
如果看到红灯(状态),就停车(动作)
-
如果肚子饿(状态),就去找吃的(动作)
-
价值函数(Value Function):预测未来收益
-
是什么:评估当前状态或动作的好坏程度
-
通俗理解:“直觉”或“第六感”
-
两种类型:
-
状态价值 V(s):在这个状态,未来总共能得多少分
-
动作价值 Q(s,a):在这个状态做这个动作,未来总共能得多少分
-
探索 vs 利用:永恒的权衡
-
探索:尝试没做过的动作(可能发现更好的选择)
-
利用:选择已知最好的动作(稳妥但可能错失良机)
-
类比:去餐厅吃饭
-
探索 = 尝试新菜品(可能惊艳,也可能难吃)
-
利用 = 点自己爱吃的(稳定但可能错过新美味)
-
强化学习算法分类
强化学习算法
├── 基于价值的方法 (Value-Based)
│ └── 学习动作的价值,选价值最高的
│ └── 例子:Q-learning, DQN
├── 基于策略的方法 (Policy-Based)
│ └── 直接学习应该怎么做,不计算价值
│ └── 例子:Policy Gradient
└── 演员-评论家方法 (Actor-Critic)
└── 结合上述两者:演员做动作,评论家评价
└── 例子:A3C, PPO
Mermaid总结框图
一个简单例子:走迷宫
假设一个机器人在迷宫中找出口:
| 时间 | 状态 | 动作 | 奖励 | 新状态 |
|---|---|---|---|---|
| t=1 | 在入口 | 向前走 | 0 | 通道中 |
| t=2 | 通道中 | 左转 | 0 | 死胡同 |
| t=3 | 死胡同 | 后退 | -1 (惩罚) | 通道中 |
| t=4 | 通道中 | 右转 | +10 (找到出口) | 终点 |
机器人通过多次尝试,最终学会:
-
“看到死胡同 -> 后退”(从惩罚中学习)
-
“看到出口方向 -> 前进”(从奖励中学习)
为什么强化学习如此强大?
-
无需标注数据:不需要人告诉机器“应该怎么做”,只需要告诉它“做得好不好”
-
能处理长期决策:当前动作可能影响未来很长时间的收益
-
可以超越人类:AlphaGo就是通过自我对弈(强化学习)战胜了人类冠军
实际应用场景
-
游戏AI:AlphaGo、Dota 2 AI、自动驾驶仿真
-
机器人控制:机械臂抓取、四足机器人行走
-
推荐系统:抖音推荐、商品推荐
-
资源调度:电梯调度、数据中心节能
-
金融交易:自动股票交易策略
一句话总结:强化学习就是让智能体通过与环境“摸爬滚打”,从错误中学习,最终成为某个领域的“专家”。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 14
14 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)