RL-VLA3:通过完全异步加速强化学习 VLA
26年2月来自天津大学、北大、清华、京东科技和澳大利亚Swinburne U of Tech的论文“RL-VLA3: Reinforcement Learning VLA Accelerating Via Full Asynchronism”。近年来,视觉-语言-动作(VLA)模型已成为构建通用具身智能的关键途径,但其训练效率却成为一大瓶颈。尽管现有的基于强化学习的训练框架(例如 RLinf)能够
26年2月来自天津大学、北大、清华、京东科技和澳大利亚Swinburne U of Tech的论文“RL-VLA3: Reinforcement Learning VLA Accelerating Via Full Asynchronism”。
近年来,视觉-语言-动作(VLA)模型已成为构建通用具身智能的关键途径,但其训练效率却成为一大瓶颈。尽管现有的基于强化学习的训练框架(例如 RLinf)能够提升模型的泛化能力,但它们仍然依赖于同步执行,导致在环境交互、策略生成(rollout)和模型更新(actor)阶段出现严重的资源利用不足和吞吐量限制。为了克服这些挑战,本文提出并实现一种全异步的策略训练流水线——RL-VLA3,涵盖从环境交互、策略生成(rollout)到模型更新(actor)的整个异步流程。该框架系统地借鉴大型模型强化学习中的异步优化思想,设计一个多层次的解耦架构。这包括环境交互和轨迹收集的异步并行化、策略生成的流式执行以及训练更新的解耦调度。
与监督学习范式不同,强化学习允许智体探索专家数据流形之外的区域,从而促进发现对零样本泛化至关重要的鲁棒错误恢复策略(Li et al., 2025)。然而,将强化学习应用于VLA模型面临着系统性的挑战:大多数现有研究规模有限且分散在不同的平台上,缺乏支持大规模多样化实验的统一框架。同时,VLA 的强化学习训练需要与环境进行持续交互,而这些交互通常通过模拟器实现。这些模拟器会与模型训练和推理争夺内存和计算资源,进一步增加了系统优化的难度。
RLinf(Zang et al., 2025)作为业界首个开源的 VLA 强化学习框架,通过设计统一的接口、支持多种类型的模拟器和算法,以及引入灵活的 GPU 分配策略(例如共置、分离和混合配置),提供关键的基础设施。然而,其训练流程本质上受限于同步执行范式,未能充分利用异构计算集群的并行处理能力。模拟器交互、策略生成和模型更新之间的串行依赖性导致计算资源闲置和吞吐量瓶颈,限制训练效率的进一步提升。在当前大模型强化学习的实践中,异步训练机制(Han et al., 2025; Fu et al., 2025; Team et al., 2025; Sheng et al., 2025)已被证明能够显著提高训练效率和系统吞吐量,相关研究也催生了各种成熟的异步优化策略。然而,在VLA模型强化学习训练领域,此类异步训练方法仍未得到充分探索和应用。
为了弥合这些差距,本文基于现有的统一框架,系统地引入异步训练和推理机制。借鉴大模型强化学习中的异步优化思想,设计一种三级异步执行架构 RL-VLA3,包括异步环境交互和轨迹收集、流式异步策略生成执行以及解耦的训练更新调度。这些机制显著减少组件间的等待时间,实现计算资源的持续饱和利用。
异步训练和推理
目前,在 VLA 模型的强化学习后训练中,传统的同步训练机制通常依赖于 GPU 的协同分配策略。这种方法仅在所有部署过程完成后才收集用于策略更新的轨迹数据。尽管这种方法在许多任务中简单稳定,但当轨迹生成时间分布不均,且某些环境交互存在显著的长尾延迟时,就会面临挑战。同步等待机制会导致计算资源闲置,从而显著降低整体训练吞吐量。此外,当在单个GPU上交替加载rollout环境和策略模型时,频繁的上下文切换和数据迁移会引入额外的系统开销,进一步限制训练效率。
为了应对这些挑战,设计并实现一种基于解耦GPU分配策略的异步训练架构。在该架构中,rollout工作进程和actor工作进程部署在不同的GPU设备上,并通过高吞吐量的轨迹数据传输流水线进行通信。一旦任何rollout工作进程完成当前轨迹的生成,它就会立即将该轨迹放入传输队列,并根据当前策略版本继续生成后续轨迹,而无需等待其他正在进行的环境交互。该机制有效避免长尾rollout阻塞对整体进度的影响,使rollout工作节点能够保持近乎连续的轨迹生成。当累积轨迹达到预定义的训练批次大小时,Actor 工作节点会异步地从通信管道中收集这些轨迹,以执行策略优化和参数更新。值得注意的是,在 Actor 进行训练的同时,rollout工作节点会使用预更新的策略权重持续生成新的轨迹,直到 Actor 完成当前参数更新,此时新的策略权重会同步到所有rollout工作节点。这种设计不仅实现训练和生成之间的解耦和并行化,而且保证训练过程的稳定性和数据有效性。
通过这种异步训练机制,本文在 VLA 模型强化学习训练中实现rollout和训练之间高效的管道执行。该框架显著降低了同步等待和资源切换带来的时间开销,提高了系统吞吐量,同时缩短了整体训练周期。它为面向大规模、多任务场景的具身智能研究提供了更高效的训练基础设施。
异步交互策略
在 VLA 模型的强化学习训练中,样本轨迹生成的效率是系统吞吐量的主要瓶颈。传统的 VLA 训练框架通常采用同步批处理并行模式,其中仿真环境和推理模型之间的交互以整个批次为粒度。这种范式引入严格的同步依赖性:
• 环境端长尾效应:全局进度受限于最慢的仿真实例,导致同步开销造成大量计算资源闲置。
• 推理端流水线停滞:大批量推理请求必须完全处理后才能返回到环境,导致环境资源大量闲置。
为了缓解这些问题,本文提出一种细粒度的异步交互策略。该机制以更高的分辨率管理仿真实例,并将环境步骤与模型推理解耦。它允许来自部分环境的就绪请求提前进入推理队列,从而绕过全局同步的要求。
此外,该方法与LLM中使用的“连续批处理”技术有所不同。LLM受益于token-级生成和管理,从而能够在执行过程中动态地插入和删除请求,而VLA模型通常集成扩散模块。由于这些模块中的动作生成过程具有非自回归或多步去噪的特性,因此无法直接应用token-级动态插入。因此,实现一个动态批处理调度器。该调度器使用最大推理批大小(B_max)和最大等待延迟(T_max)作为约束条件:
如果(批大小≥B_max)∨(等待时间≥T_max),触发推理
通过实现此策略,有效地压缩批处理轨迹生成所需的时间,而不会影响模型性能。
流器生成
在异步训练和推理架构中,尽管展开和训练过程已经解耦,但 Actor 仍然需要积累足够数量的轨迹来形成完整的训练批次,这仍然可能导致间歇性的 GPU 空闲。为了充分利用这些等待时间,在训练阶段进一步引入一种细粒度的流水线划分机制。具体来说,将全局训练批次划分为若干个微批次。每当轨迹缓冲区中积累的样本数量达到单个微批次的大小时,Actor 就会启动一次前向和后向计算。所有微批次依次计算完成后,再进行梯度聚合和参数更新。这种设计使得 Actor 可以提前开始部分训练计算,而无需等待整个轨迹批次完全生成,从而有效地屏蔽数据准备时间,显著降低端到端训练延迟,并进一步提高 GPU 利用率和系统吞吐量。
此外,在典型的VLA训练场景中,单个训练步骤所需的时间通常远小于生成相应轨迹所需的展开时间。为了实现计算资源的均衡利用,系统地分析并动态调整异步框架中展开工作节点和执行节点之间的GPU资源分配比例。实验表明,通过将二者之间的GPU分配比例调整为3:1、2:1或1:1等配置,可以显著改变各阶段的执行时间分布。当两个进程的时间成本接近平衡时,训练和展开进程可以在异步流水线中实现近乎完全的计算掩蔽,从而优化系统整体利用率。
实验设置
模型。评估几个预训练的VLA,包括基于扩散的模型:GR00T N1.5(Bjorck,2025)和 π 系列(π0 和 π0.5)(Black,2024),以及自回归模型 OpenVLA-OFT(Kim,2025)。参考 Zang(2025)的研究,对 OpenVLA-OFT 进行调整,使其能够预测一组动作而非单个动作。这种异构模型的选择能够验证方法在不同 VLA 架构和动作预测范式下的通用性和鲁棒性。
基准测试。考虑两种强化学习(RL)训练环境:LIBERO(Liu,2023)和 ManiSkill(Mu,2021)。两者都广泛用于评估预训练的VLA模型和训练后算法。对于LIBERO,主要使用LIBERO-100中的LIBERO-10任务划分,该任务侧重于机器人终身决策。对于ManiSkill,侧重于使用不同物体和容器进行抓取和放置任务。
这些环境之间的一个关键区别在于它们的并行化设计:LIBERO依赖于CPU多进程,而ManiSkill使用GPU张量并行化。正如Zang(2025)所指出的,这些不同的并行化方法会导致不同的最优强化学习策略。
实现和基线。实现基于RLinf(Zang,2025),该框架将强化学习训练划分为三种类型的工作节点:环境节点、Rollout节点和Actor节点。修改所有三种工作节点类型,并引入额外的通信通道以支持异步执行。如图所示: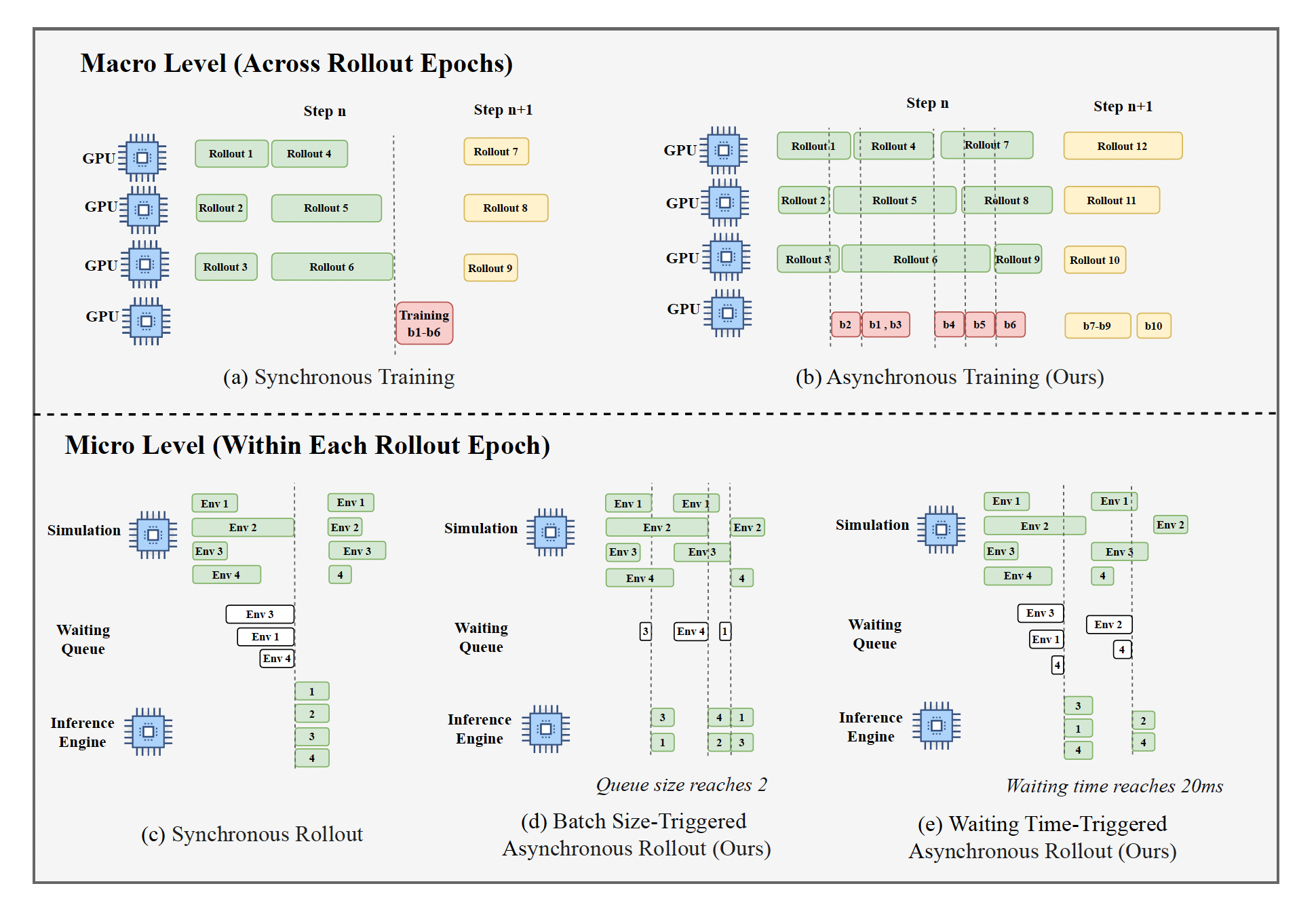
将其与 RLinf 支持的两种分布式训练策略进行比较:
• 同地部署:所有三种类型的工作节点都位于同一设备上,这意味着所有设备同时执行环境交互、模型部署或模型训练。
• 分离式部署:工作节点位于不同的 GPU 设备上,但模型训练和部署仍然保持顺序同步。
对于分离式策略,除非另有说明,否则将环境和部署工作节点位于同一组设备上,并将 Actor 工作节点位于另一组设备上。
为了严格评估性能,在 8 到 256 个 GPU 的 GPU 集群上进行实验。对于分离式策略,进一步探索不同工作节点类型之间的 GPU 分配比例。
评估指标。由于主要目标是在对最终性能影响最小的情况下加速训练,因此评估系统吞吐量和训练成功率曲线。
目前,VLA 模型尚无标准化的吞吐量指标。由于 VLA 模型通常预测的是可变大小的动作块,因此语言建模的指标无法直接应用。为此,本文使用单位时间内环境状态计算的次数来衡量系统的整体效率。对于训练成功率曲线,我们采用 VLA 模型的标准评估协议。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 4
4 0
0- 0



 已为社区贡献192条内容
已为社区贡献192条内容

所有评论(0)