递归-深度 VLA:基于潜迭代推理VLA模型的隐测试-时计算规模化
26年2月来自斯坦福、慕尼黑工大、西雅图华大和AI2的论文“Recurrent-Depth VLA: Implicit Test-Time Compute Scaling of Vision–Language–Action Models via Latent Iterative Reasoning”。当前的视觉-语言-动作(VLA)模型依赖于固定的计算深度,对简单的调整和复杂的多步操作消耗相同的计
26年2月来自斯坦福、慕尼黑工大、西雅图华大和AI2的论文“Recurrent-Depth VLA: Implicit Test-Time Compute Scaling of Vision–Language–Action Models via Latent Iterative Reasoning”。
当前的视觉-语言-动作(VLA)模型依赖于固定的计算深度,对简单的调整和复杂的多步操作消耗相同的计算资源。虽然思维链(CoT)提示能够实现可变的计算量,但它的内存占用呈线性增长,并且不适用于连续的动作空间。递归-深度VLA(RD-VLA)架构,通过潜迭代细化而非显式的token生成来实现计算自适应性。RD-VLA采用一个递归的、权重绑定的动作头,能够在保持恒定内存占用的情况下支持任意推理深度。该模型使用截断反向传播算法(TBPTT)进行训练,以有效地监督细化过程。在推理阶段,RD-VLA使用基于潜收敛的自适应停止准则动态分配计算资源。在具有挑战性的操作任务上进行的实验表明,循环深度至关重要:单次迭代推理完全失败(成功率为 0%)的任务,在四次迭代后成功率超过 90%,而较简单的任务则很快达到饱和。
RD- VLA如图所示:(左图)以往的推理 VLA(例如 ThinkAct、MolmoAct)在输出空间中生成显式的推理tokens,需要耗费大量资源进行自回归解码。(中图)该方法完全在潜表示空间中进行迭代细化,从而避免token生成的开销。(右图)RD-VLA 在 LIBERO-10 数据集上实现与自回归推理基线相当的性能,同时由于自适应计算的潜推理效率更高,速度显著提升。
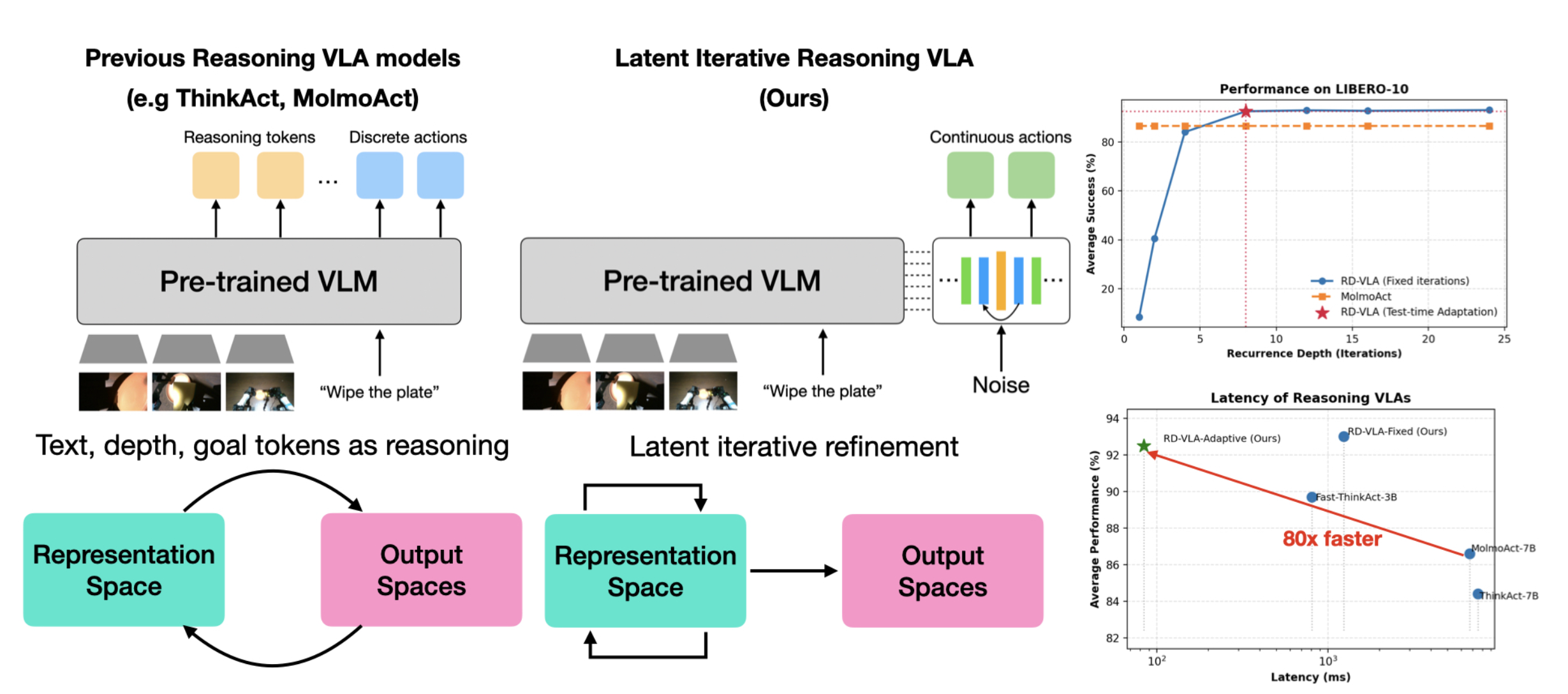
RD-VLA框架旨在将计算深度与预训练视觉-语言骨干网络的固定架构约束解耦。标准的视觉语言架构通常使用固定深度的多层感知器(MLP)头或在输出空间中使用计算密集型的迭代过程,例如扩散或流匹配动作头[4],而RD-VLA则将计算负担转移到连续潜流形内运行的权重绑定递归transformer核心。这种设计允许模型通过将递归模块展开到任意深度r来扩展其测试时的计算能力,从而实现基于任务复杂度的动态计算分配(如图所示)。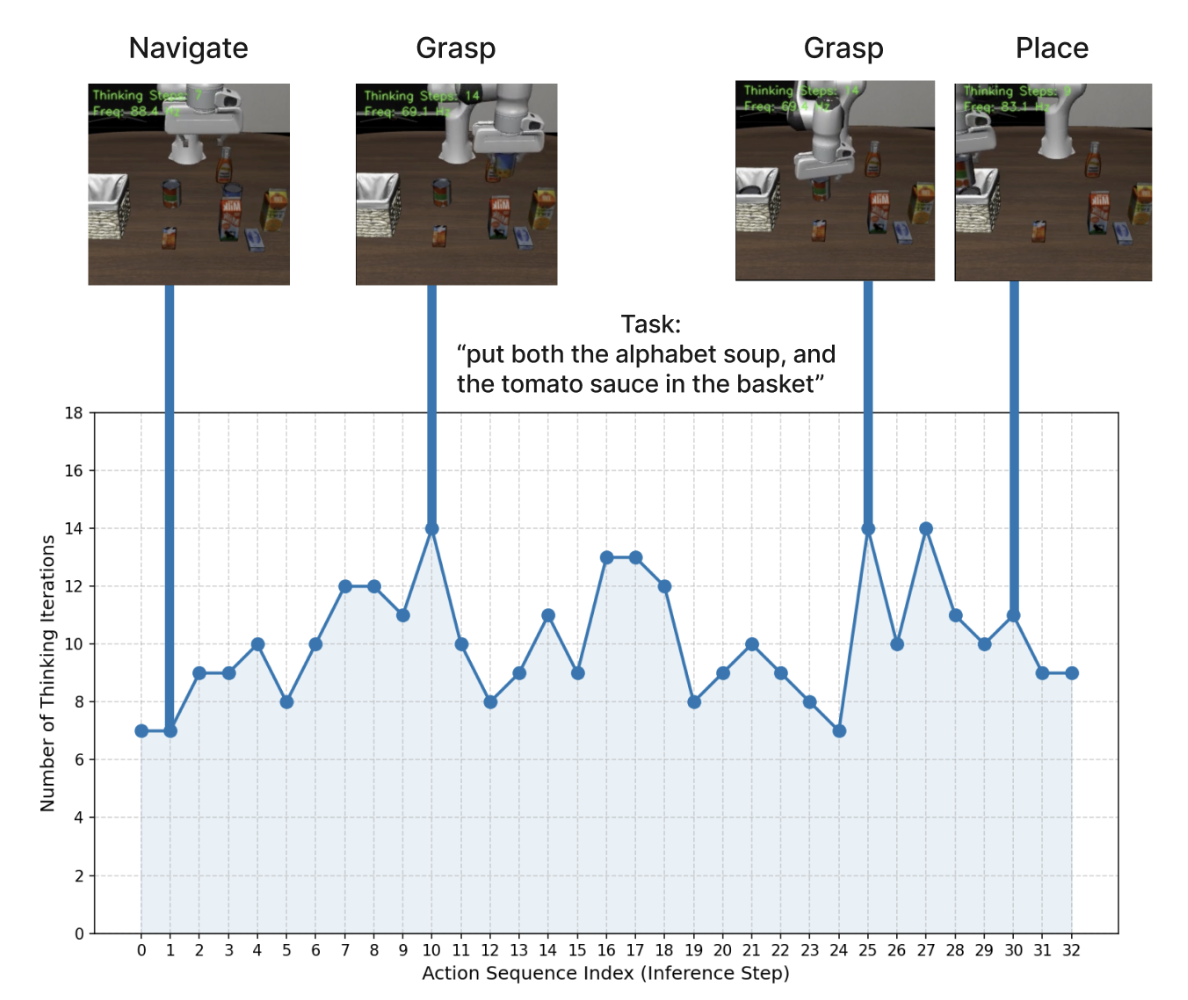
结合自适应停止准则,RD-VLA 能够基于每个样本动态分配计算资源,从而为推理阶段的高精度机器人控制提供可扩展且资源高效的框架。RD-VLA 通过权重绑定递归核心,利用隐式潜空间推理来支持测试-时计算规模化的 VLA 模型。此外,这种任务相关的收敛行为,所需的展开深度自然地从执行上下文中涌现,反映所执行动作的底层复杂性。
架构骨干和token流
RD-VLA 动作头是一个模块化框架,其设计与骨干无关,能够与任何生成密集潜表示的视觉-语言模型 (VLM) 集成。本工作用基于 MiniVLA [2] 的 Qwen2.5-0.5B [47, 40] 的 VLM 来实例化该框架,该 VLM 采用 Prismatic [21] 的训练方案,并融合 MiniVLA [2] 中的 DINOv2 [33] 和 SigLIP [50] 的冻结视觉编码器。
冻结视觉编码器为每幅图像观测生成 256 个视觉token(腕部和主摄像头各 512 个),这些tokens被投影到通过 LoRA 微调的 Qwen2-0.5B(24 层)LLM 骨干网络中。遵循 OpenVLA-OFT [23] 的架构设计原则,用一组 64 个专门学习的潜嵌入来增强 VLM 输入序列。这些tokens作为特殊的接地占位符,在 LLM 的前向传播过程中关注多模态上下文。
VLM 执行后,提取隐状态并将其划分为两个不同的集合:
• 任务/视觉表示 (h_vis):捕获空间和语义场景信息。
• 潜特定表示 (h_lat):从潜tokens位置提取,以提供压缩的、任务对齐的特征。
这些表示组合起来形成一个静态条件流形。具体来说,每次迭代 k 的递归头 R_θ 通过交叉注意机制关注一个拼接的上下文向量 [h(24)_vis+lat; p],从而有效地将潜推理过程锚定在观察和高层语义tokens之上。
递归深度架构
引入一个框架,将计算深度与预训练视觉语言骨干网络的固定架构约束解耦。虽然标准的 VLA 架构通常使用固定深度的头,但 RD-VLA 将计算负担转移到一个在连续潜流形中运行的权重绑定递归 Transformer 核心。遵循 Huggin 的方法 [14],将架构划分为一个功能三元组:前奏(Prelude)、递归核心(recursive core)和尾声(Coda)(如图所示)。 Prelude 和 Coda 作为非递归接口层,负责将表征映射到专用的潜流形,该潜流形针对迭代推理进行了优化。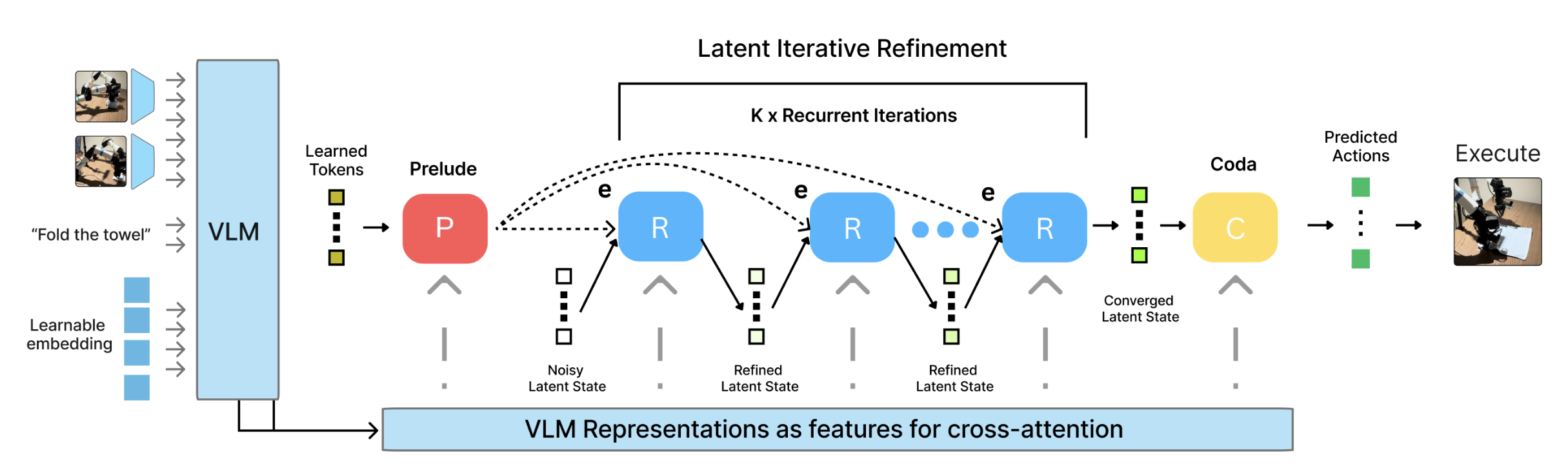
该过程始于 Prelude (P_φ),这是一个非递归接口,它接收 K = 8 个已学习的查询。首先,K 个查询相互进行双向关注。然后,通过对 VLM 的中间层视觉特征 h(12)_vis+lat 执行交叉注意,Prelude 将这些查询转换为一个基于基础的潜流形。
与此同时,从高熵截断正态分布初始化一个潜在暂存区 S,作为推理过程的演化状态。这种带噪声的初始化将 S 转换为一个空白工作区,模型必须对其进行迭代的“清理”和细化。这确保模型学习到一个稳定的细化算子,而不是过拟合到特定的初始状态。
- 基于输入注入的潜迭代推理:核心迭代细化发生在循环核心 (R_θ) 中,这是一个权重绑定的 Transformer 模块。为了保持表征稳定性并防止模型在长时间展开过程中失去对物理观测的把握(表征崩溃),采用一种持久的输入注入策略。在每个步骤 k,递归模块同时观察暂存区 S_k−1 的当前状态和 Prelude 提供的静态基础 S_pre。
具体来说,对于每次迭代 k = 1…r,将前一次暂存状态 S_k−1 与沿特征维度固定的 S_pre 连接起来,形成一个二维上下文。然后通过学习的适配器将其映射回这个流形维并进行归一化。然后通过权重绑定递归块更新这个暂存状态。
与 Prelude 类似,在本次更新中,R_θ 首先对 K 执行双向自注意,然后执行门控交叉注意,其中查询源自 x_k,K/V源自一个串联的条件流形 [h(24)_vis+lat; p]。该流形由 64 个任务对齐的潜tokens和来自 VLM 最后一层的 512 个视觉tokens以及机器人当前的本体感觉 p 组成。
2) Coda 和动作投影:一旦递归达到所需的深度 r,收敛的暂存区 S_r 将由非递归的 Coda (C_ψ) 处理。Coda 将表征移出潜流形,关注自身和高级 VLM 特征 (h(24)_vis+lat) 来执行最终的解码过程。最后,输出投影层将这些精细化的特征映射到机器人的动作空间。这种架构确保任何中间状态 S_k 都是有效的表示,而 S_k+1 则代表动作计划的更精细的迭代。
- 随机递归训练:为了促进收敛到与初始化深度无关的稳定状态,在训练过程中从重尾对数正态泊松分布中采样迭代次数 N。其采用 TBPTT 算法,其中梯度仅在最后 d = 8 次迭代中传播,而之前的迭代则在梯度分离的情况下计算。这迫使网络学习如何从任何噪声初始化迭代地将暂存状态细化为稳定的流形,从而确保 S_k+1 是 S_k 的更精细版。这使得模型能够在推理过程中动态扩展计算能力而无需重新训练。
自适应计算
利用模型的特性,在推理阶段实现一种自适应计算机制。不指定固定的迭代次数,而是利用模型自身的内部收敛性作为推理确定性的代理(proxy)。定义一个基于连续迭代动作分布之间的 Kullback-Leibler (KL) 散度的停止准则。通过在动作空间中使用均方误差 (MSE) 来近似 KL 散度,推理循环在步骤 k∗ 处终止,当满足以下条件时:
||ak − ak−1||2_2 < δ
其中 a_k 是步骤 k 的预测动作块,δ 是收敛阈值(例如,1e−3)。这使得模型能够自我调节:对于简单的动作立即终止,而对于复杂的情况则分配更多的计算资源。
自适应执行
自适应计算决定递归的持续时间。同时,自适应执行决定要执行的动作数量。需要深度递归环(k∗ > 8)的情况通常对应于高度不确定的状态。在这些情况下,执行大量的动作是危险的,因为初始规划中的微小误差会随着时间的推移而累积。
其提出两种策略,将推理深度与动作执行相结合。
- 基于阈值的自适应执行:该方法使用二元推理阈值 τ 来调节执行范围。假设迭代次数越多,认知不确定性就越高。因此,如果收敛需要 k∗ > τ 步,将执行范围截断为较短的 H_short 以减少累积误差,同时保留 H_long 用于置信度较高的预测 (k∗ ≤ τ)。
- 线性衰减执行:为了提供连续的扩展机制,实现一种线性衰减调度,该调度根据推理深度的倒数来减少执行范围。给定一个基本迭代预算 τ_base,对于收敛所需的每额外迭代,执行范围 H_exec 都会减少一步。这种方法迫使智体随着计算需求的增加而更频繁地重规划,在复杂状态下优先考虑安全性而非效率。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 36
36 0
0- 0



 已为社区贡献211条内容
已为社区贡献211条内容

所有评论(0)