从像素到诊断:神经网络革新CT与MRI医疗影像分析
在现代化放射科的读片室里,一位特殊的“新同事”正在悄然改变医生的工作模式。它不知疲倦,速度惊人,能在数秒内处理完数百张影像切片;它目光敏锐,能够捕捉到人眼容易忽略的细微病灶——它就是基于深度学习的人工智能辅助诊断系统。
过去十年,以卷积神经网络(CNN)为代表的深度学习技术,彻底改变了医学影像分析的面貌。从肺癌早筛到脑肿瘤分割,从急诊卒中检测到肝脏病灶量化,AI正在成为放射科医生不可或缺的得力助手。这篇博客将深入探讨神经网络在CT、MRI影像病灶检测中的应用原理、技术进展、临床实践与未来挑战。
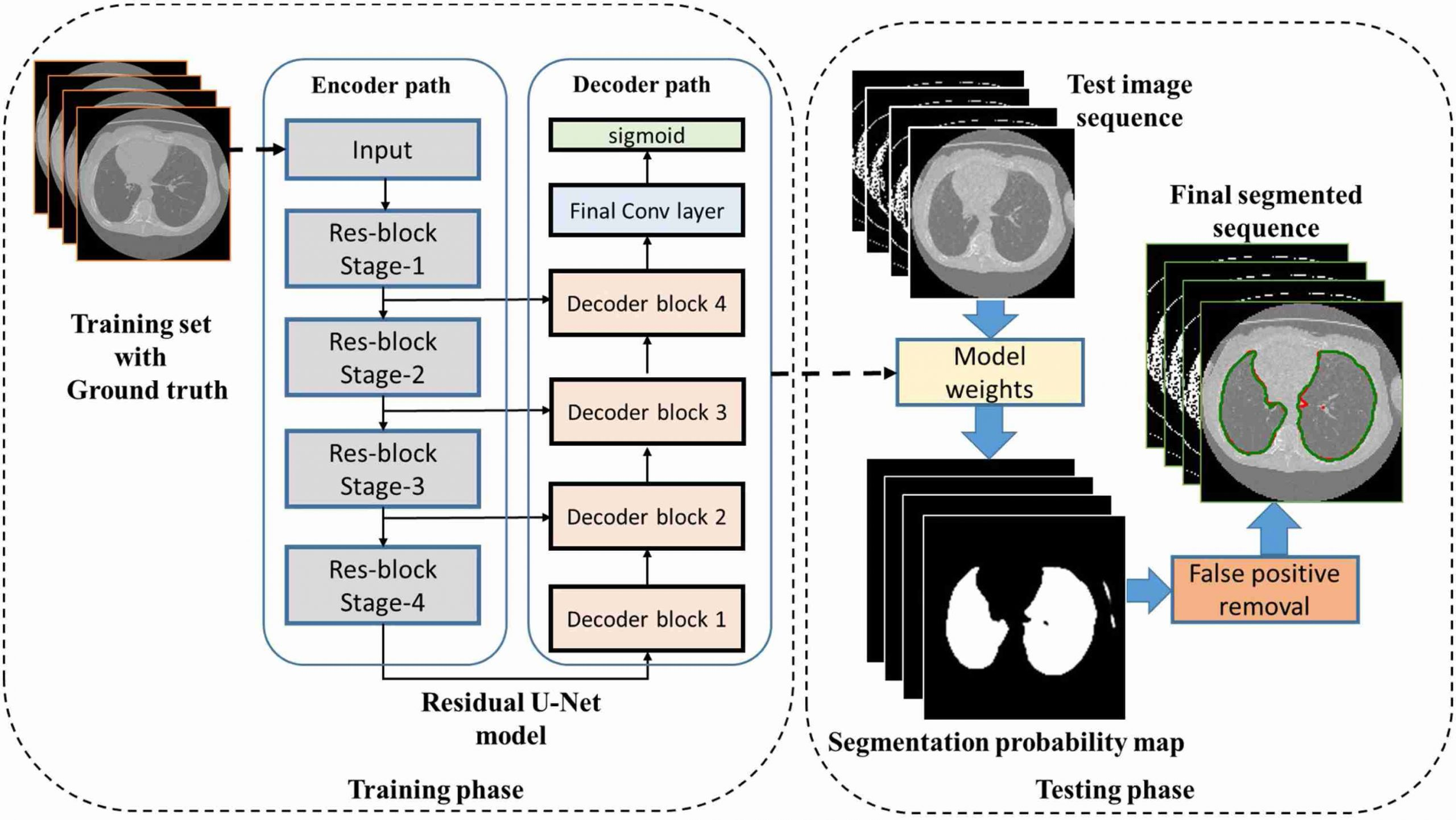
一、技术基石:卷积神经网络如何“看懂”医学影像
要想理解AI如何帮助医生发现病灶,首先需要明白它如何“看懂”那些灰度图像。与自然图像不同,医学影像具有高分辨率、三维结构、低对比度等特点,这对算法提出了特殊要求。
1.1 从视觉皮层到卷积层
卷积神经网络的设计灵感来源于生物视觉皮层。当我们看一张图片时,大脑首先检测边缘、线条等低级特征,然后组合成形状、纹理等中级特征,最终识别出物体等高级语义概念。CNN通过堆叠多个卷积层,模拟了这一层次化的特征提取过程。
在医学影像分析中,这一特性尤为宝贵。早期的卷积层可能学习识别组织边缘、血管纹理;中间的层能够组合出器官轮廓、结节形态;深层的网络则能判断病灶的良恶性、区分肿瘤类型。
1.2 二维与三维:维度带来的挑战
CT和MRI扫描生成的是三维体积数据——由数百张连续切片组成的立体图像。处理这类数据主要有两种策略:
二维方法将每一张切片视为独立图像进行分析,优点是计算效率高、可以利用ImageNet等大规模自然图像预训练模型,但缺点是忽略了相邻切片之间的空间连续性。
三维方法使用3D卷积核直接处理体积数据,能够捕捉病灶在空间中的立体形态和相邻组织关系,尤其适合检测球形结节或不规则肿块。但三维CNN参数量巨大,需要更强的计算资源和更多的训练数据。
法国古斯塔夫·鲁西医院的一项研究展示了三维CNN的威力:研究者基于平扫脑部CT开发了一个3D-CNN模型,用于识别脑转移瘤患者。该模型在验证集上的平均准确率达到98.3%,曲线下面积同样达到0.983,展现出了卓越的鉴别能力。
1.3 编码器-解码器:从分类到分割
分类任务只能回答“图像中有没有病灶”,而临床实践往往需要更精确的答案——“病灶在哪里,边界如何”。这就引入了分割任务。
U-Net架构是医学影像分割的里程碑式设计。它采用对称的编码器-解码器结构:编码器逐步下采样提取语义特征,解码器上采样恢复空间分辨率,同时通过跳跃连接将编码器的底层细节信息传递给解码器。这种设计使得网络既能理解“这是什么”,又能定位“它在哪”,成为后续众多医学分割模型的基石。
二、核心任务:检测、分割与分类的协同
在CT和MRI影像分析中,神经网络主要执行三类核心任务,它们相互配合,构成完整的辅助诊断链条。
2.1 病灶检测:从候选区域到精准定位
目标检测任务旨在图像中定位所有可能的病灶并标出边界框。YOLO(You Only Look Once)系列算法因其实时检测能力,在医学影像领域获得广泛关注。
印度的一项研究将CNN与YOLOv11及SAM(Segment Anything Model)相结合,用于脑肿瘤诊断。该混合框架中,YOLOv11负责实时定位肿瘤区域,SAM则通过生成详细的掩模来细化肿瘤边界。在包含896张MRI脑部图像的数据集上,模型取得了94.2%的准确率和96.5%的平均精度均值(mAP50),证明了该方法在早期脑肿瘤诊断中的有效性。
肺结节检测是另一个典型应用场景。肺癌是全球癌症相关死亡的首要原因,CT图像中肺结节的准确检测对早期诊断至关重要。研究者提出的KansNet框架,将Kolmogorov-Arnold网络与CNN相结合,并设计了自适应特征融合模块和多切片分区通道注意力模块,增强了网络处理微小特征的能力。在LUNA16公开数据集上,该方法的CPM(Competition Performance Metric)得分达到90.32%,超越了其他检测算法。
2.2 图像分割:勾勒病灶的精确边界
如果说检测是画个框告诉医生“这里有问题”,分割则是精确勾勒出病灶的每一寸边界。这对于手术规划、放疗剂量计算和疗效评估至关重要。
肝脏肿瘤分割是研究最活跃的领域之一。一篇发表于2025年的综述系统梳理了基于深度学习的肝脏CT图像肿瘤分割方法,分析了超过100篇相关研究。研究者指出,精确的肿瘤分割对于治疗反应评估(如RECIST标准)、手术切除计划和放疗剂量投送具有决定性意义——过多的辐射会损伤周围健康组织,增加放射性肝病和复发的风险。
然而,肝脏肿瘤分割面临诸多挑战:肿瘤在形状、纹理、大小和位置上的高度异质性,邻近器官的相似灰度,模糊的肿瘤边界,以及不同设备采集条件的差异,都使得精确分割变得困难。这推动了更强大网络架构的出现。
2.3 分类与预测:超越人眼的深层特征
除了定位和勾勒病灶,深度学习还能提取人眼无法直接量化的影像特征,用于疾病诊断和预后预测。这正是影像组学与深度学习结合的价值所在。
同济医院朱文珍教授团队的一项研究堪称典范。急性缺血性脑卒中发病24小时内,CT平扫往往难以显示肉眼可见的变化,导致夜间急诊或缺乏磁共振设备的基层医院极易漏诊。该团队构建了一个两阶段深度学习模型,在“CT阴性、MRI阳性”的患者影像上训练,实现了在平扫CT上自动定位和定性隐匿性缺血病灶。
结果令人振奋:模型单张图像诊断准确率达89.9%;而放射科医生在AI辅助下,诊断准确率由62%跃升至92%。更值得期待的是,该模型还能虚拟生成DWI影像,实现对早期梗死灶、闭塞血管和缺血半暗带位置与大小的精准呈现——这相当于让AI学会了“脑补”出磁共振上的异常信号,为争取溶栓治疗的黄金时间提供了关键线索。
三、技术前沿:从单模态到多模态,从通用到专用
深度学习在医学影像领域的发展日新月异,以下几个方向尤其值得关注。
3.1 多模态融合:1+1>2的诊断效能
不同影像模态各有优劣:CT对钙化和骨骼显示清晰,MRI对软组织对比度优越,PET反映代谢活性。将这些信息融合起来,能够为诊断提供更全面的视角。
一篇发表于PubMed的综述系统梳理了深度学习方法在多模态肿瘤检测与分类中的应用,涵盖PET-MRI、PET-CT和SPECT-CT等融合方式。研究者讨论了CNN、YOLO、孪生网络、融合模型、注意力模型和生成对抗网络等多种架构在多模态分析中的应用。多模态融合不仅能提高检测准确性,还能增强模型的鲁棒性——当某一模态图像质量不佳时,其他模态仍能提供有效信息。
3.2 新型网络架构:超越传统CNN
尽管CNN仍是医学影像分析的主流架构,但研究者正不断引入新的网络设计。
Vision Transformers(ViT)将自然语言处理中的Transformer架构引入计算机视觉,通过自注意力机制捕捉图像中的长距离依赖关系。在医学影像中,这有助于理解病灶与周围器官的整体关系。
Kolmogorov-Arnold Networks(KAN)是一种受经典Kolmogorov-Arnold表示定理启发的神经网络架构。前文提到的KansNet首次将KAN引入肺结节检测领域,通过部分注意力模块将全局表示学习能力融入CNN,展现了KAN在医学影像分析中的巨大潜力。
MILENet则针对现有编码器-解码器网络中跳跃连接的局限性,提出了一种多尺度交互与局部增强的桥接网络。通过在腹部CT、心脏MRI和内窥镜图像等多个数据集上验证,该网络在多尺度特征对齐和局部细节增强方面取得了最先进的性能。
3.3 基础模型与少样本学习
医学影像标注需要专业知识和大量时间,数据稀缺一直是制约深度学习应用的主要瓶颈。近年来,基础模型和少样本学习为解决这一问题提供了新思路。
Meta开源的Segment Anything Model(SAM)是一个基于超过10亿掩模训练的图像分割基础模型。研究者正积极探索如何将SAM适配到医学影像领域——或是通过微调,或是将其与专用医学模型结合,如前述YOLO+SAM的脑肿瘤分割研究。
少样本学习和自监督学习允许模型从少量标注数据或无标注数据中学习有效的特征表示,这对于罕见病诊断或特定设备适配具有重要意义。
四、临床实践:AI如何融入真实工作流程
在探讨了技术之后,我们需要回到一个根本问题:AI系统如何真正帮助临床医生和患者?
4.1 AI医生的角色:辅助而非替代
首先要明确的是,当前阶段的AI并非要取代放射科医生,而是扮演强大的辅助者角色。AI的“看”本质上是基于海量数据的模式识别和概率预测,它缺乏人类医生的临床经验、逻辑推理能力以及对患者整体病史、症状和体征的综合把握。
同济医院朱文珍教授强调,AI的分析结果必须由放射科医生进行最终审核和验证,并结合患者的具体临床背景做出最终诊断。医生始终是诊断决策的最终责任人和掌控者。
4.2 临床价值的具体体现
在具体临床场景中,AI系统主要在三方面创造价值:
提升检出率:AI能精准检测肺部CT中毫米级微小结节、乳腺钼靶的早期钙化灶、脑部MRI微小缺血灶,为早诊早治提供关键线索。KansNet在肺结节检测中实现的90%以上CPM得分,意味着更多早期肺癌患者有机会被及时发现。
提供量化依据:AI可自动勾画肿瘤并精确计算体积变化,测量冠脉钙化积分评估心血管风险,量化脑萎缩程度。这种客观、可重复的量化分析,对于疗效评估和预后判断至关重要。
优化工作流程:AI能在数秒内完成大批量影像初筛,在急诊场景中快速识别脑出血、气胸等危急征象,显著提升救治效率;还能智能识别高风险病例并优先推送,优化工作流程。卒中患者的每一分钟都关系到数百万神经元的存活,同济医院研究中AI辅助带来的30%准确率提升,意味着更多患者能够在溶栓时间窗内获得有效治疗。
4.3 挑战与局限
尽管前景光明,深度学习在医学影像分析中的应用仍面临诸多挑战:
数据依赖:AI模型的性能高度依赖于训练数据的质量和代表性。数据标注错误、病例选择偏倚、设备型号差异都可能导致模型泛化能力不足。肝脏肿瘤分割的综述特别指出,公开数据集的有限性和标准化不足是制约模型发展的重要因素。
可解释性:深度学习模型常被视为“黑箱”,医生难以理解模型为何做出特定判断。这阻碍了临床信任的建立。研究者正通过Grad-CAM、SHAP等技术生成热力图,突出模型关注的图像区域,或设计内在可解释的模型架构,为临床决策提供更透明的依据。
监管与合规:医疗AI产品作为三类医疗器械,需通过严格的临床试验和监管审批。美国FDA、欧洲药品管理局和欧盟AI法案都提出了透明度、生命周期监测等要求,这对开发实践提出了更高标准。
五、未来展望:影像诊断的智能化新时代
站在2026年回望,医学影像AI已经走过了从概念验证到临床落地的关键十年。展望未来,以下几个方向值得期待:
多模态信息深度融合:AI将不仅分析多种影像数据,还将整合电子病历、基因组学、病理组学等多源信息,为诊断提供更全面的视角,推动个性化诊疗的实现。
从诊断走向预测:通过深入分析影像特征,AI有望预测疾病的发展趋势、治疗效果以及患者的长期预后。影像组学与深度学习结合,可能挖掘出目前未知的预后生物标志物。
联邦学习与隐私保护:为解决医疗数据隐私问题,联邦学习允许在不同机构间分布式训练模型而无需共享原始数据。这将在保护患者隐私的同时,利用多中心数据提升模型泛化能力。
边缘计算与实时辅助:随着模型轻量化技术的发展,AI辅助诊断将能部署在CT/MRI设备边缘,实现扫描即诊断的实时辅助,进一步缩短急诊响应时间。
结语
从像素到诊断,是一条漫长而奇妙的旅程。当放射科医生在屏幕上移动鼠标、查看AI勾勒出的病灶轮廓时,他/她所调用的不仅是算法输出的结果,更是背后千万份已标注影像凝结的集体智慧。
AI医生并非科幻电影中的角色,它是一行行代码,是一个个卷积核,是无数研究者、工程师和临床医生共同努力的结晶。它不会取代人类医生,但会与医生并肩作战,共同致力于让影像诊断变得更快速、更精准、更早期——最终惠及每一位寻求健康答案的患者。
在医学影像分析这片沃土上,深度学习的故事才刚刚开始。随着技术的持续演进和临床应用的不断深入,我们有理由相信,AI与医生的协同将为人类健康带来更多可能。
参考文献
-
Paul Jeyaraj M. Automated Brain Tumor Segmentation using Hybrid YOLO and SAM[J]. Current Medical Imaging, 2025.
-
Zhou S, et al. MILENet: Multi-scale Interaction and Locally Enhanced Bridging Network for Medical Image Segmentation. 2025.
-
同济医院. “看不见”的卒中病灶用AI锁定[N/OL]. 同济医院官网, 2025-12-25.
-
KansNet: Kolmogorov–Arnold Networks for lung nodule detection[J]. Biomedical Signal Processing and Control, 2025, 103: 107358.
-
Felefly T, et al. A 3D Convolutional Neural Network Based on Non-enhanced Brain CT to Identify Patients with Brain Metastases[J]. Journal of Imaging Informatics in Medicine, 2025, 38(2): 858-864.
-
Deep Learning in Medical Image Analysis: A Comprehensive Review[J]. Computers, Materials and Continua, 2025.

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 42
42 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)