mimic-video:机器人控制的可泛化视频-动作模型,超越VLA模型
25年12月来自mimic robotics公司、微软苏黎世、ETH和加州Berkeley分校的论文“mimic-video: Video-Action Models for Generalizable Robot Control Beyond VLAs”。目前用于机器人操作的主流视觉-语言-动作模型(VLA)都基于在大型但彼此独立静态网络数据上预训练的视觉-语言骨干网络。因此,尽管语义泛化能力有
25年12月来自mimic robotics公司、微软苏黎世、ETH和加州Berkeley分校的论文“mimic-video: Video-Action Models for Generalizable Robot Control Beyond VLAs”。
目前用于机器人操作的主流视觉-语言-动作模型(VLA)都基于在大型但彼此独立静态网络数据上预训练的视觉-语言骨干网络。因此,尽管语义泛化能力有所提升,但策略必须完全依靠机器人轨迹隐式推断复杂的物理动力学和时间依赖性。这种依赖关系造成巨大的数据负担,需要持续收集大量专家数据来弥补其缺乏内在物理理解的不足。虽然视觉-语言预训练能够有效地捕捉语义先验知识,但它对物理因果关系却视而不见。一种更有效的范式是利用视频在预训练阶段同时捕捉语义和视觉动态,从而将低级控制任务独立出来。为此,引入 Mimic-Video,一种视频-动作模型(VAM),它将预训练的互联网规模视频模型与基于流匹配的动作解码器相结合,该解码器以视频模型的潜表示为条件。该解码器充当逆动力学模型(IDM),从视频空间动作轨迹的潜表示中生成低级机器人动作。该方法在模拟和真实世界的机器人操作任务中均达到最先进的性能,样本效率比VLA模型提高 10 倍,收敛速度提高 2 倍。
将视频预测应用于机器人控制已有悠久的历史,其主要动机是希望通过视觉预见能力实现规划。早期的一些开创性工作,例如 Oh [39]、Watter [51]、Fragkiadaki [18]、Finn [17] 以及 Finn & Levine [16] 的研究,都展示了视频预测如何增强物理交互。随着生成模型日趋成熟,能够生成高清、连贯的长视频内容 [40, 53],近期的研究探索了视频生成与策略学习的多种集成方式。近年来,将动作条件视频模型(世界模型)用于策略学习的方法得到广泛应用。世界模型可以通过“想象”动作序列的结果来帮助在运行时选择更优的动作序列 [1, 43],或者用作学习的模拟器,用于评估和类似 DAGGER [47] 的方法 [20, 48]。
主要考虑非动作条件视频模型。一类方法完全在像素空间生成未来视频,并通过非参数方法(例如跟踪安装在末端执行器上的特定工具 [29])或学习的基于像素逆动力学模型 [14, 15] 来获取动作。CoT-VLA [56] 使用预训练的视觉-语言模型(VLM)生成图像,并在一个自回归序列中生成子目标图像和动作。另一类方法在训练过程中学习视频建模,但不在动作采样阶段进行视频预测;Unified World Models [59] 从头开始学习一个模型,该模型可以灵活地用作策略、视频预测模型或正向/逆向动力学模型;LAPA [54] 微调 VLM 以预测“潜动作”(当前图像与未来图像之间差异的编码),并在后续训练阶段仅重训练输出层以预测动作。FLARE [58] 将中间 VLA 表示与未来的视觉语言嵌入对齐,隐式地联合建模视频和动作。类似地,Video Policy [30] 显式地建模视频-动作联合分布,并将策略模型以中间视频模型表示为条件,但关键在于它无法有效地采样边缘动作分布。
本文提出的方法与大多数现有工作不同,它直接将控制建立在互联网规模视频模型的丰富潜先验知识之上,而不是从头开始训练或依赖像素级重建。此外,通过对轻量级逆动力学模型进行中间噪声潜状态的条件化处理,避免完整视频生成所需的计算成本以及启发式跟踪的脆弱性。这能够构建一个可扩展的端到端框架,有效地将广泛的物理理解迁移到下游操作任务中,从而显著减少对昂贵的大规模机器人演示的依赖。
Mimic-video 是一种通用机器人策略,它将生成式视频预训练与基于流匹配的控制相结合,从而建立一类视频-动作模型(VAM)的新方法。在一系列不同的机器人平台上评估了方法,涵盖从标准的单臂操作到双臂灵巧任务,并在模拟基准测试和具有挑战性的真实世界环境中都展现最先进的性能。
在这项工作中,与目前最先进的视觉-语言模型(VLM)骨干网络中常用的内部表示相比,预训练视频模型骨干网络中产生的内部表示更适合下游机器人学习任务。直观地说,视频模型可以联合建模图像、物理动力学以及视觉动作规划。在这些表示上训练的策略有效地将动作解码器的作用简化为一个简单的转换器(translator),将视觉动作规划映射到低维机器人动作轨迹。如果这一假设成立,那么视频-动作模型(VAM)的大部分学习工作将集中在大型视频预训练和微调阶段,而动作解码器的训练(这一步骤需要昂贵的高质量机器人远程操作数据)将变得轻量化且数据高效。
以下进行一项“预言机”案例研究(如图所示)来验证这一论断,在该研究中,将机器人控制任务中预测未来状态的难度与执行未来状态的难度分离开来。具体来说,在视频表示之上训练一个动作解码器,并在不同的条件设置下评估其性能。比较在以下两种情况下解码器的成功率:一种是解码器以预测的视频潜表示为条件,这些潜表示来自标准现成的视频模型或在机器人数据上微调的视频模型;另一种是解码器以从真实未来视频帧中提取的“预言机”潜表示为条件。
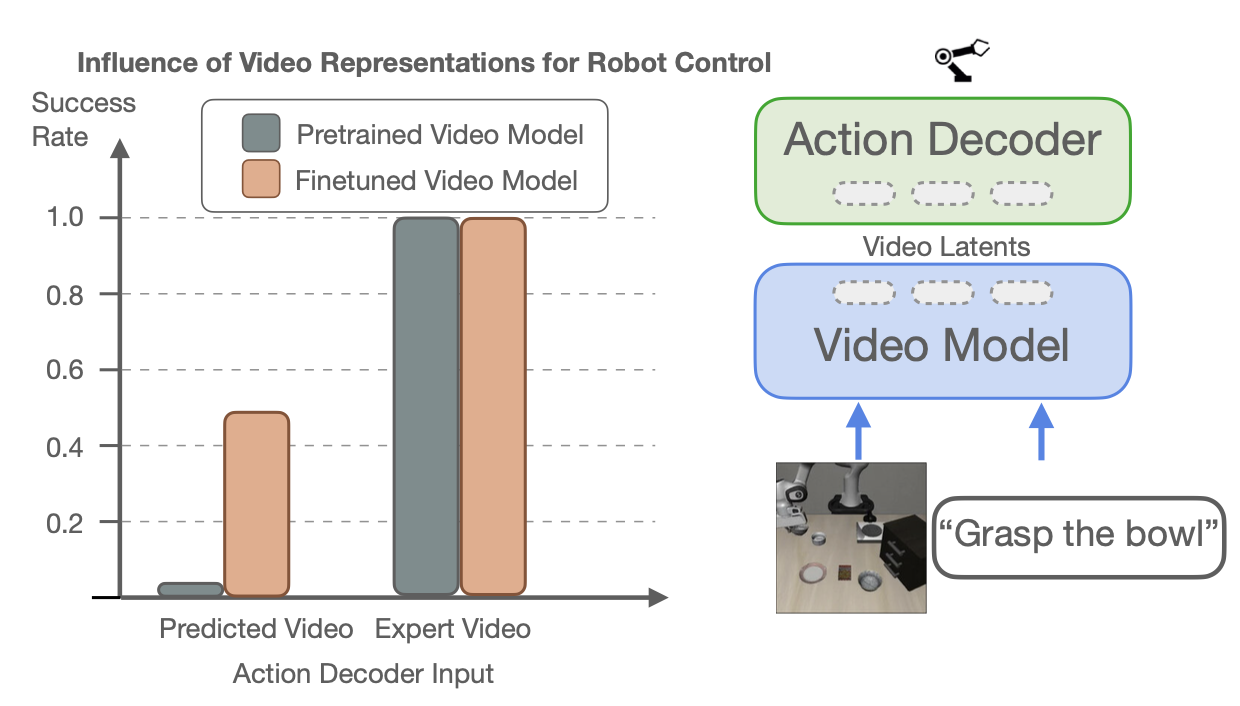
规模效应:虽然通过微调来最小化域差距可以提高使用预测视频时的性能,但无论底层骨干网络是否在目标分布上进行过微调,以预言机潜表示为条件都能获得接近完美的成功率。值得注意的是,这一发现表明,高质量的预训练视频模型骨干网络为动作解码提供极其丰富的表示,这些表示本身就足以使用在少量低级动作微调数据上训练的解码器完美地解码低级动作规划。因此,VAM 中策略学习的负担有效地从低级动作解码转移到视频模型的预训练和微调阶段。
引入 Mimic-Video,一种生成式视频-动作模型 (VAM),能够对视频和机器人动作的联合分布进行建模。架构耦合两个条件流匹配 (CFM) 模型:一个预训练的、语言条件化的视频骨干网络和一个轻量级的动作解码器,该解码器以视频模型的潜表示为条件,充当逆动力学模型 (IDM)。
预备知识:流匹配
视频和动作预测组件均使用流匹配框架 [31] 进行训练,通过构建连续归一化流 [6] 来建模数据分布 p_0(x0)。用条件最优传输路径
xτ =(1−τ)x0+τε, τ ∈[0,1]
该路径在干净数据 x0(τ = 0 时)和高斯噪声 ε ∼ N (0, I)(τ = 1 时)之间进行插值,以定义条件概率路径 p_τ(xτ| x0)。该模型参数化一个估计器 v_θ,用于估计难以处理的边缘生成向量场
u_τ(xτ)=E_p(x0 | xτ) u_τ(xτ |x0)
其中 u_τ (xτ | x0) := dxτ/dτ = ε−x0 被称为条件生成向量场,并且可以很容易地计算样本 x0 和 ε 的值。流匹配的强大之处在于通过回归 u_τ (xτ | x0) 来学习 v_θ,即 L_CFM,其中期望值在流时间 τ 分布 T 计算,在 [31] 中 分布T 是 U ([0, 1]),而在本文 T 将取不同的值。
推理是通过将学习的场 v_θ 从 τ = 1 积分到 τ = 0 来恢复 ˆx0 ∼p_0。关键的是,这个连续时间参数 τ 允许定义部分的去噪(在中间 τ > 0 处停止),这是方法的核心。
架构设计
形式上,目标是学习一个通用机器人策略 π(A_t | o_t, l),该策略根据包含多个 RGB 图像 I_t′ 和本体感受状态 q_t 的观测值,预测一系列动作 A_t = [a_t,…,a_t+H_a−1],其中 o_t = [I_t−H_o+1,…, I_t, l, q_t]。
模型由两个基于流匹配的模型组成,这两个模型使用定义的目标函数 L_CFM 进行训练。令 z0_t 为视频编码序列,A0_t 为干净的动作块:
视频模型:v_φ (z0_past, zτ_v_future, l, τ_v) 产生 p_φ (z0_future | z0_past, l)。
动作策略:π_θ (Aτ_a_t, q_t, hτ_v, τ_a, τ_v) 产生动作分布 p_θ (A0_t | q_t, hτ_v_t, τ)。
其中,hτ_v = v(k)_φ(z0_past, zτ_v_future, l, τ_v) 是在流时间 τ_v 时,对“带噪声”的视频输入 zτ_v_future 调用视频模型后,从视频模型第 k 层提取的隐状态向量。
该架构如图所示:
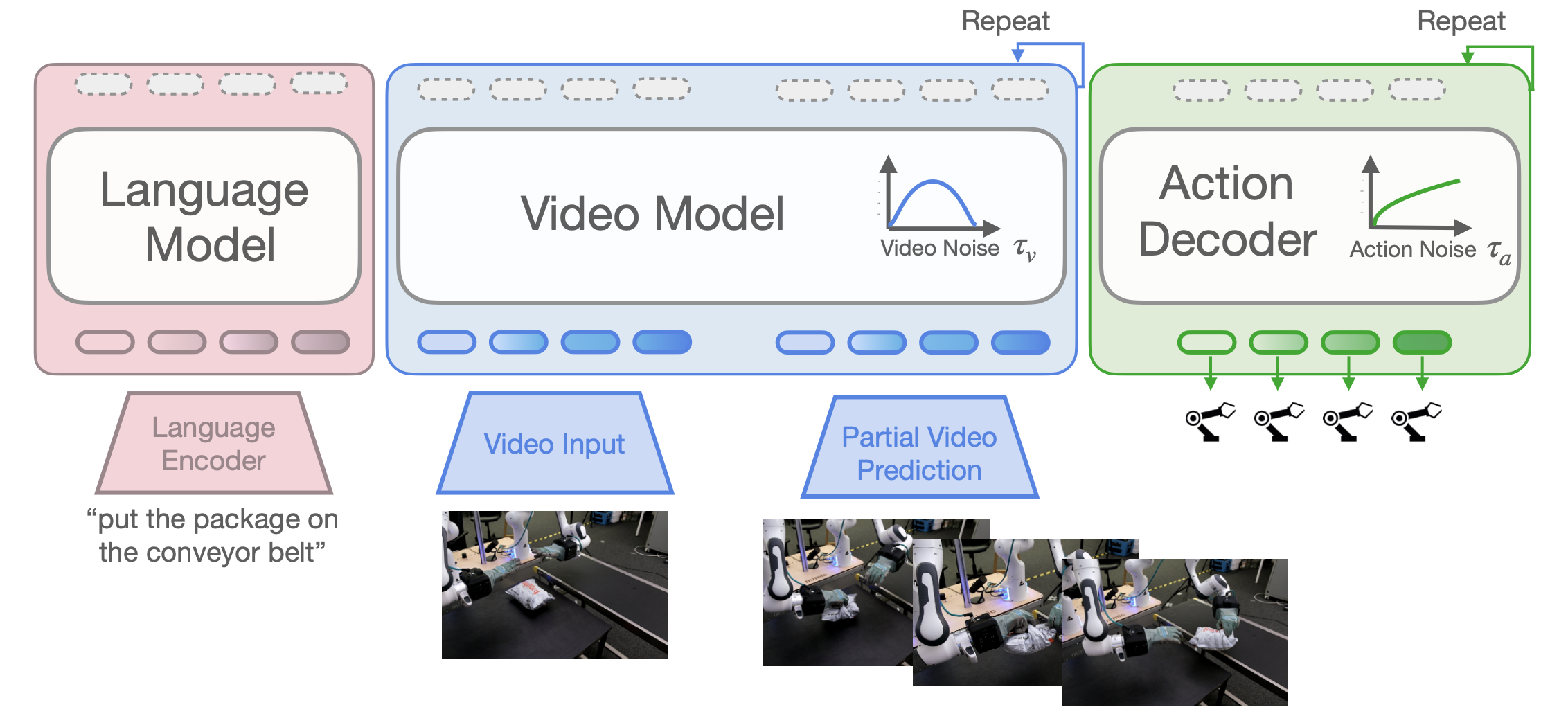
视频模型
虽然视频动作模型公式可以实例化任何基于流匹配的视频模型,但在实践中,用 Cosmos-Predict2 [38, 37] 作为基础模型。Cosmos-Predict2 是一个开源的 2B 潜扩散transformer (DiT) [41] 模型,它处理由一个预训练的 3D token化器编码的视频帧序列。模型的输入是来自上下文前缀(用 5 帧)的干净潜块嵌入与代表未来待生成帧的“噪声”潜块的拼接。每个transformer层交替执行以下操作:(1) 对整个视频序列进行自注意;(2) 对由 T5 [44] 编码的语言指令进行交叉注意;(3) 一个两层 MLP。
动作解码器
动作解码器实例化为一个 DiT,它通过两个独立的 MLP 网络对机器人的本体感觉状态 q_t 和一系列未来机器人动作 A_t 进行编码,并将它们连接起来形成动作解码器的序列。用学习的绝对位置编码为每个token添加时间信息。在训练过程中,随机地将编码本体感觉状态的软token替换为学习的掩码token,以防止在低维观测上过拟合。每个动作解码器层由以下部分组成:(1) 对中间视频模型表示 hτ_v 的交叉注意机制,(2) 对动作序列的自注意机制,以及 (3) 一个两层的 MLP。每个组件都通过一个残差路径进行旁路,并且每个组件的输出都通过 AdaLN [41] 进行调制,其中 AdaLN 投影的输入是视频和动作流时间 τ_v 和 τ_a 的低秩双线性仿射编码。
动作采样
为了实现实时控制,将推理建模为从边际动作策略中进行高效采样。虽然 mimic-video 原则上能够从联合视频-动作分布中进行采样,但可以通过绕过完整视频重建的计算成本,更高效地从边际动作分布中进行采样。因此,提出了一种部分去噪策略,该策略从中间流状态中提取语义特征,而无需解析细粒度的像素细节。推理动作采样过程在算法 1 中描述。给定图像观测值 o_t,将视频流场从高斯噪声积分到中间流时间 τ_v。这产生一个部分去噪的潜状态 zτ_v_future,它保留足够的结构信息来指导策略。用视频模型的前 k 层处理该状态,并将得到的激活值作为条件信息传递给动作解码器。动作解码器随后执行完整的去噪过程,生成一组机器人动作 A0_t。

在推理阶段,τ_v 是一个自由超参。其最优值取决于任务,但实验证明,它通常接近 1(高噪声)。在 τ_v = 1 的特殊情况下,只需对计算密集型的视频骨干网络进行一次前向传播即可生成一组动作(算法 1 中的第 3 行变得冗余),从而在实验中实现实时推理。 τ_v = 1 是一个很好的默认值,它平衡策略性能和推理速度。
训练
视频-动作模型的训练分两个不同的阶段进行,分别处理不同的参数集。
第一阶段侧重于视频骨干网络。为了使通用骨干网络与机器人任务的特定视觉领域和动态特性相匹配,用低秩适配器(LoRA)[23] 在机器人视频数据集上对其进行微调。这一调整步骤确保模型能够捕捉特定领域的语义,同时保留其预训练的时间推理能力。
第二阶段的重点是在保持视频骨干网络不变的情况下学习动作解码器 π_θ。从头开始训练解码器,以回归动作流场,并以从冻结的骨干网络中提取的视频表征 hτ_v 为条件。至关重要的是,为了确保推理过程中对不同噪声水平的鲁棒性,在每次训练迭代中对独立的流时间 τ_v(视频)和 τ_a(动作)进行采样,如算法 2 中所述。对 T_v 采用与视频预训练相匹配的 logit 正态分布,而对动作采用 T_a(τ_a) ∝ (t_a -0.001)0.5 分布,如 [3] 中所述。这种解耦训练方案使方法比类似的 VLA 基线方法在样本效率上显著提高,收敛速度也更快。

评估设置:通过模拟基准测试 SIMPLER [28] 和 LIBERO [32],以及使用人形机械手进行的真实世界灵巧操作实验来评估 mimic-video 的能力。
SIMPLER 作为真实世界性能的高保真代理(proxy),用于评估在 Widow-X 机器人实体 BridgeDataV2 [50] 数据集上训练的策略。它通过系统辨识和视觉匹配,专门测试策略在现实视觉域偏移下泛化到未知任务的能力。
LIBERO 基准测试使用模拟桌面 Panda 机器人评估精度和多任务能力。重点关注 LIBERO-Goal、-Object、 -Spatial 套件,每个套件包含 10 个不同的任务,每个任务提供 50 个专家演示。这个广泛使用的基准测试评估模型学习精确多任务操作行为的能力。
真实世界灵巧双臂操作。为了在高维、接触丰富的任务上验证 mimic-video,用配备两个 16 自由度“mimic”机械手 [36] 的双臂设置,这些机械手安装在 Panda 机械臂上。观察空间包括全局工作空间视图、四个腕部摄像头和完整的本体感受信息。评估两个长周期任务:包裹分拣(抓取、移交、放置)和胶带存放(抓取、存放、移动盒子)。重要的是,虽然视频骨干网络是在更广泛的 200 小时语料库上进行微调的,但相应的动作解码器是在极其稀缺的任务特定数据上进行训练的:分拣任务仅使用 1 小时 33 分钟(512 episodes),存放任务仅使用 2 小时 14 分钟(480 episodes)。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 20
20 0
0- 0



 已为社区贡献211条内容
已为社区贡献211条内容

所有评论(0)