1X世界模型:评估比特而不是原子
25年6月来自加州硅谷AI公司1X的论文“1X World Model: Evaluating Bits, not Atoms”。1X 世界模型 (1XWM) 是一种生成式视频世界模型,能够预测机器人未来的观测结果和任务级状态值。训练 1XWM,使其能够根据动作指令准确预测接触情况和全身操作,这是首个针对全身人形机器人的世界模型。1X 世界模型实现精确的动作控制能力,能够在相同的观测条件下比较不同
25年6月来自加州硅谷AI公司1X的论文“1X World Model: Evaluating Bits, not Atoms”。
1X 世界模型 (1XWM) 是一种生成式视频世界模型,能够预测机器人未来的观测结果和任务级状态值。训练 1XWM,使其能够根据动作指令准确预测接触情况和全身操作,这是首个针对全身人形机器人的世界模型。1X 世界模型实现精确的动作控制能力,能够在相同的观测条件下比较不同的策略。1XWM 作为评估器的准确性,会随着自主策略运行数据的增加而提高,并展示世界模型与真实世界评估之间的高度相关性。进一步展示 1XWM 在不同人形机器人任务中的预测准确性迁移能力。借助 1XWM 作为评估引擎,可以快速迭代检查点选择、架构比较和长尾数据集的构建。
1X 世界模型能够:
- 快速迭代架构决策。
- 从训练过程中选择最佳检查点。
- 在生产环境中整理长尾场景数据集,并基于这些数据集重新评估模型。
- 通过高效的训练-评估周期,大规模优化机器人策略。
解决评估问题是朝着在通用环境和非结构化家庭环境中部署实际机器人迈出的重要一步。对于机器人技术而言,将训练时指标(例如预测轨迹与专家轨迹之间的均方误差)与实际性能相关联是一种不可靠的替代方法。
在不同的家庭环境中全面评估人形机器人的策略性能需要数天到数周的时间。对于一个策略检查点,需要数百到数千个样本才能收集到具有统计意义的指标。鉴于一轮训练可以生成数十个候选检查点,在 1X 规模下全面评估训练的模型将变得极其昂贵。因此,必须仔细选择要发送到真实世界进行全面评估的模型。可靠的离线评估将极大地提高模型实验的效率。
架构
1XWM 是一种生成式视频模型,它可以根据图像状态和输入动作预测未来状态。为了生成任务级别的评估分数,该模型会预测生成未来状态的状态值。
将视频片段分割成长度为四秒的图像帧序列。用时间图像编码器将初始帧编码到潜空间中。同时,对输入动作进行编码,并将这两种编码都输入到模型主干网络中,该网络预测代表整个四秒视频片段的潜状态。给定这些潜状态,解码未来帧的图像并预测状态值。通过在潜空间中进行操作,能够对来自多个实体(包括 EVE 和 NEO)的动作空间进行联合训练。
该管道对视频分辨率具有灵活性。在实践中,用 256 × 256 和 512 × 512 分辨率的数据进行训练。用网络规模的视频数据进行预训练,并使用 1X 机器人数据进行后训练。后训练数据集包含远程操作和自主任务片段,用二元成功值对其进行标注,并将这些值插值到状态值标签(Gokmen [2023])。
如图所示:1X 世界模型由视觉编码器、动作编码器、主干网络以及用于视频和状态值的解码器组成。基于成功标签进行监督训练的状态值预测,能够评估输入动作的质量。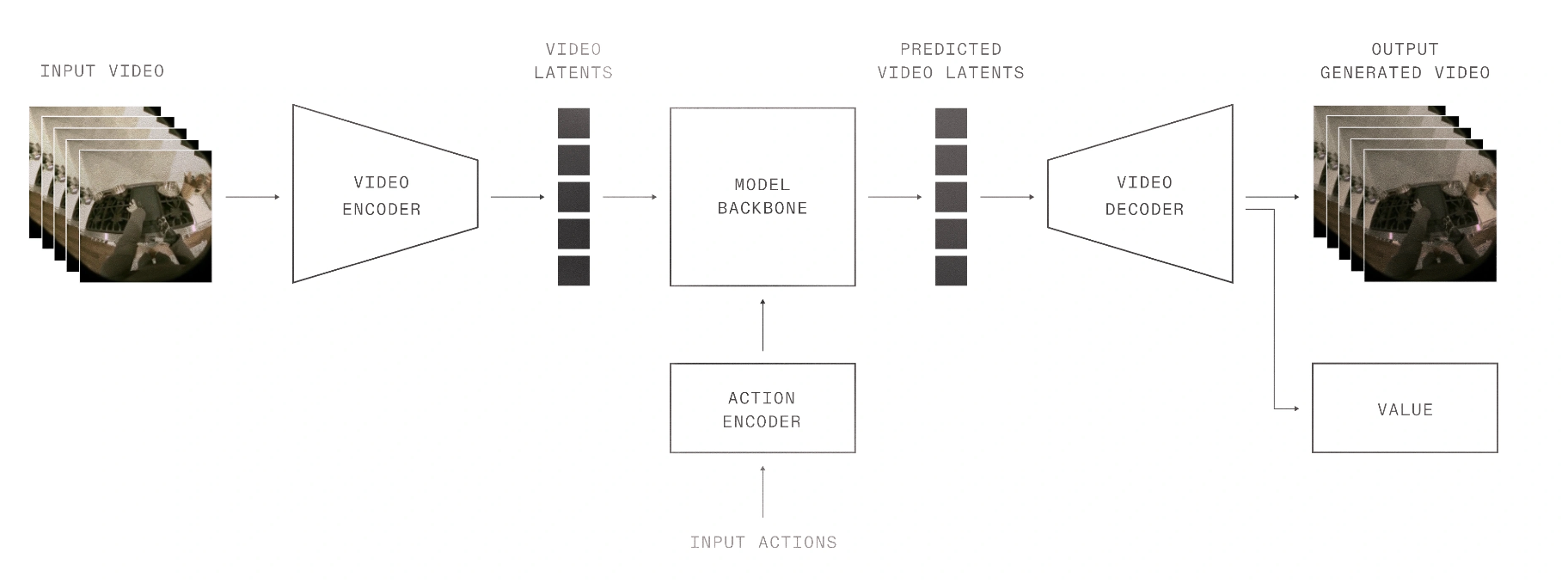
用于动作可控性的视频生成模型
大多数视频生成模型都是文本-到-视频(T2V)模型,使用语言提示来生成视频,并可选地使用一个或多个参考帧进行指导。然而,用于模拟机器人策略的世界模型需要具备动作可控性,由精确的机器人轨迹而非“拿起杯子”或“擦拭台面”之类的模糊指令来控制。此外,世界模型应该根据物理定律对智能体的动作做出反应。
如图所示,1XWM 为 NEO 生成四种不同的未来场景,所有场景都从相同的初始帧开始,包括拿起杯子、擦拭台面、向后退一步以及弹奏虚拟空气吉他,每个场景都分支成各自逼真的结果。
为了展示 1XWM 的动作可控性和物理一致性,下图将生成的未来场景与真实场景进行比较。为世界模型提供一些真实视频的初始帧以及后续的动作轨迹。从这个锚点开始,1XWM 模拟执行这些精确动作的后果,包括门和布料在台面上擦拭等物体的物理运动。


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 16
16 0
0- 0



 已为社区贡献185条内容
已为社区贡献185条内容

所有评论(0)