VLA-Reasoner:通过在线蒙特卡洛树搜索,增强视觉-语言-动作模型的推理能力
25年9月来自新加坡南洋理工、清华和北邮的论文“VLA-Reasoner: Empowering Vision-Language-Action Models with Reasoning via Online Monte Carlo Tree Search”。视觉-语言-动作模型(VLA)通过规模化模仿学习,在通用机器人操作任务中取得了优异的性能。然而,现有的VLA模型仅限于预测短期的下一步动作,
25年9月来自新加坡南洋理工、清华和北邮的论文“VLA-Reasoner: Empowering Vision-Language-Action Models with Reasoning via Online Monte Carlo Tree Search”。
视觉-语言-动作模型(VLA)通过规模化模仿学习,在通用机器人操作任务中取得了优异的性能。然而,现有的VLA模型仅限于预测短期的下一步动作,由于累积误差,难以处理长程轨迹任务。为了解决这个问题,提出VLA-Reasoner插件框架,该框架通过测试-时规模化(TTS),有效地增强了现有VLA模型预测未来状态的能力。具体而言,VLA-Reasoner对可能的动作轨迹进行采样和展开,其中涉及的动作是生成未来状态的依据,并通过世界模型生成未来状态,从而使VLA-Reasoner能够预测和推理潜在结果,并搜索最优动作。进一步利用蒙特卡洛树搜索(MCTS)来提高在大动作空间中的搜索效率,其中VLA模型的逐步预测作为MCTS的根节点。同时,引入一种基于核密度估计(KDE)的置信度采样机制,以实现在MCTS中进行高效探索,避免冗余的VLA查询。通过离线奖励成形策略评估MCTS中的中间状态,对预测的未来状态进行评分,并通过长期反馈纠正偏差。
VLA-Reasoner 是一个插件框架,它赋予现成的 VLA 算法通过测试-时规模化预测未来状态的能力。提出的 VLA-Reasoner 可以有效缓解 VLA 算法因未考虑未来影响而导致的增量偏差(如图所示)。具体而言,VLA-Reasoner 通过世界模型对可能的动作轨迹进行采样和展开,从而生成未来状态,其中未来状态及其对应的动作能够反映潜变量的结果。为了提高搜索效率,采用蒙特卡洛树搜索(MCTS)来处理庞大的动作空间,其中 VLA 的逐步预测结果作为根节点的种子。引入一种基于核密度估计(KDE)的置信度分布,该分布从类似专家的先验知识中对 MCTS 中的候选状态进行采样,从而在保持探索性的同时减少冗余的 VLA 查询。由于稀疏的任务反馈仅在episode结束时到达,设计一种离线奖励塑造策略来评估 MCTS 中的中间状态,提供密集的反馈信号,以稳定的长期指导来纠正偏差。 VLA-Reasoner 通过在广阔的动作空间中进行结构化探索并预测当前动作的潜结果,有效提升 VLA 在长时域轨迹任务中的推理能力。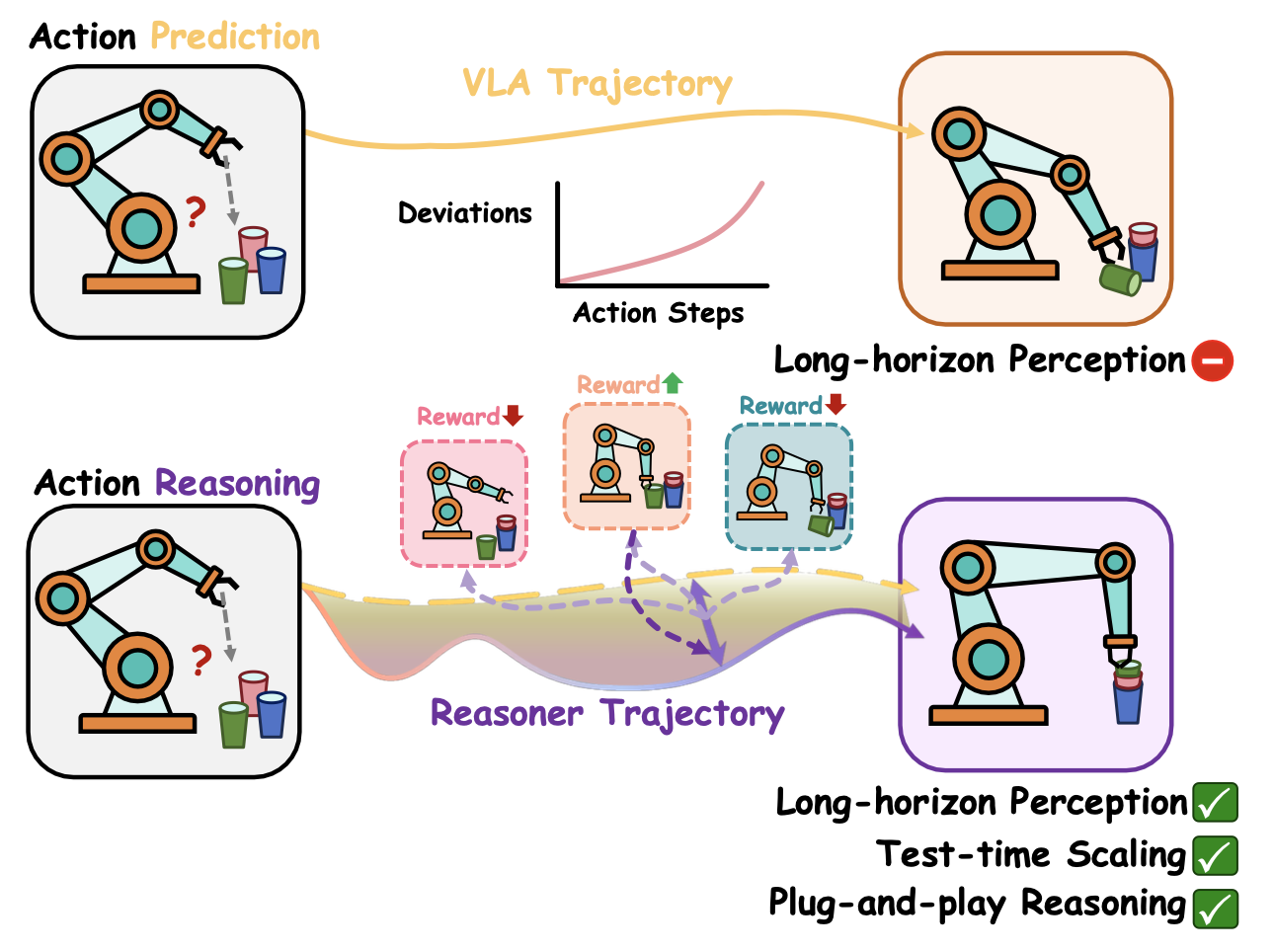
该方法在仿真和真实机器人上均取得显著且稳定的性能提升。在 LIBERO 基准测试中,将 VLA-Reasoner 应用于一个性能一般的基线 VLA,即可使其性能超越其他同类 VLA。在实际部署中,该方法相比于仅经过少量演示微调的常用 VLA,取得更高的成功率,表明其在测试中展现出更强的泛化能力和适应性。
该框架的流程图如图所示: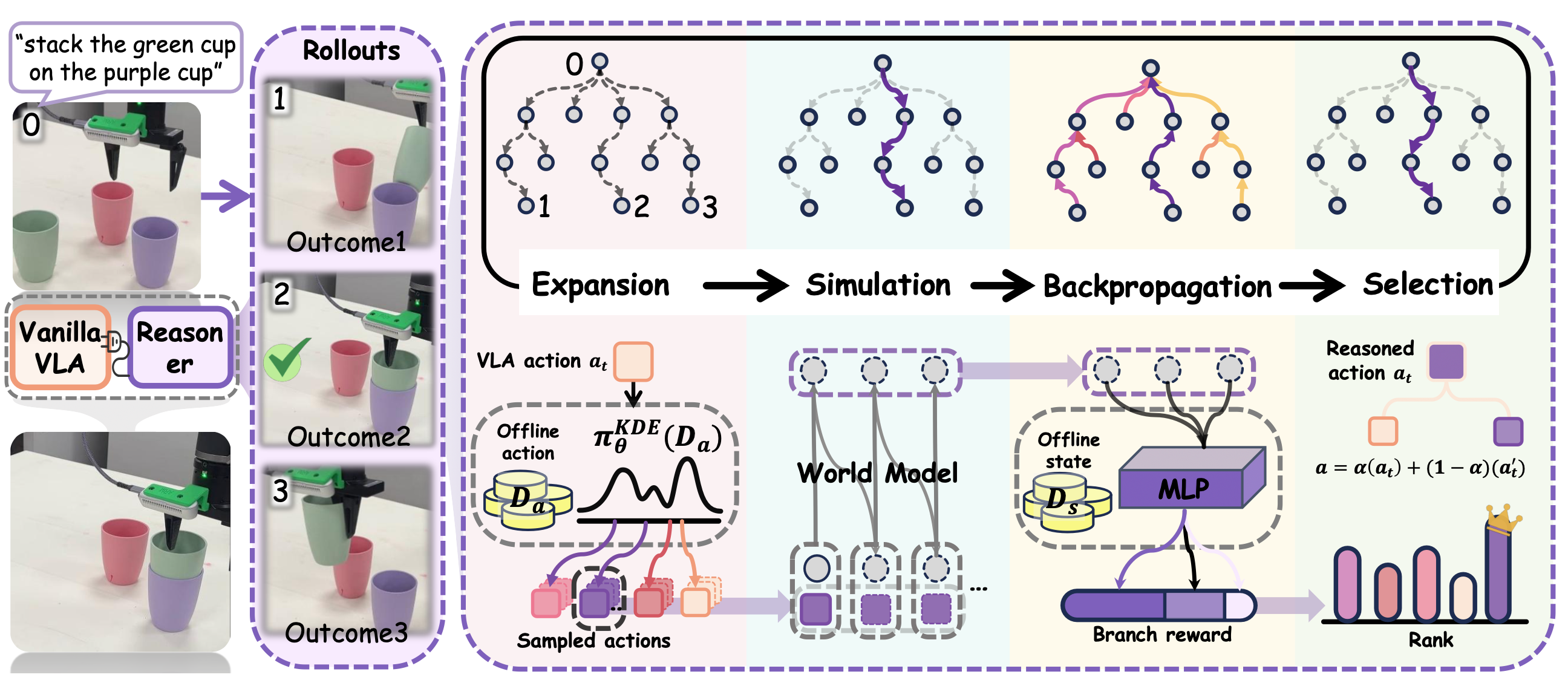
问题陈述
VLA旨在通过将多模态输入(环境状态 o_t 和任务语言指令 l)映射到动作 aVLA_t 来泛化机器人操作。预训练 VLA 的预测可以表示为 aVLA_t = π_θ(o_t, l),其中 θ 表示模型的参数,且参数值固定。由于预测仅依赖于当前状态 o_t,缺乏对未来状态的考虑会导致偏差随时间逐渐增大。
目标是在测试阶段缓解这种偏差,从而能够预测当前动作对未来状态的影响。不直接部署 VLA,而是使用世界模型 W 模拟未来状态,并用奖励 r 对其进行评分。在时间戳 t,将动作 a_t 和状态 o_t 输入到 W 中,并获得下一个状态 o_t+1 的反馈,该过程可以表示为 W(o_t+1 | a_t, o_t)。在采用蒙特卡洛树搜索(MCTS)方式进行仿真后,VLA-Reasoner 会展开一个动作 aReasoner_t。然后,将 a_t 与 VLA-Reasoner 进行交互:
a_t = α (aVLA_t) + (1-α) (aReasoner_t) (1)
其中α 表示注入强度,用于控制两个动作之间的平衡。aReasoner_t 将未来影响融入决策,提供长远指导,而最终的动作 a_t 则代表部署期间执行的决策。
在线蒙特卡洛树搜索
VLA-Reasoner 的关键在于,利用由可能的动作轨迹和相应状态组成的树状结构进行引导式定向搜索,并通过与世界模型的交互来实现推理。本文采用 MCTS 方式进行高效的树搜索,并在测试阶段将 MCTS 适配到一个简单的实现中。在每个步骤 t,VLA-Reasoner 执行以下四个步骤:(a)扩展,(b)模拟,(c)反向传播,以及(d)选择。MCTS 过程中索引为 i 的节点记为状态 o_i,该节点的奖励记为 r_i。生成该节点的对应动作记为 a_i。
a)扩展:扩展步骤旨在扩展选定的节点 o_i(初始状态为根节点,为了便于理解,此处到“选择”的上标略作模糊处理),以生成其子节点。由于动作与新状态的生成直接相关,采用 Top-k 策略,从分布 π_θ 中采样一组动作 A = {a_1, a_2, …, a_k}。对于动作 a_i,其扩展可以表示为:
样本:Ã_i = {a(n)} ∼ π_θ,
前 k 个样本:ATop-k_i = arg min sum(||a − a_i||_2 (2)
其中,ATop-k_i 是从随机生成的大样本集 ~A_i 中扩展的候选动作,这些动作在欧氏距离上与 a_i 最接近。(此处 k 相对于 N 而言较小)。
b) 模拟:为了明确评估这些采样动作的影响,用学习的动作感知世界模型 [31] 作为骨干网络来模拟未来状态,以预测基于动作的视觉状态。模拟公式如下:
o_i+1 =W(a_i, o_i) (3)
其中,世界模型在给定动作 a_i 和状态 o_i 的情况下展开下一个状态 o_i+1。实验中将机器人动作嵌入到其潜空间中,并在一个小型机器人数据集上进行微调,从而对齐多模态输入以生成合理的转换。
c) 反向传播:当树搜索满足截断条件时,MCTS 会自底向上地更新节点的值,从每个叶节点到根节点。节点 o_i 的总值为 Q(o_i),它通过结合访问次数 N(a_i) 的成本来平衡。总值和访问次数更新如下: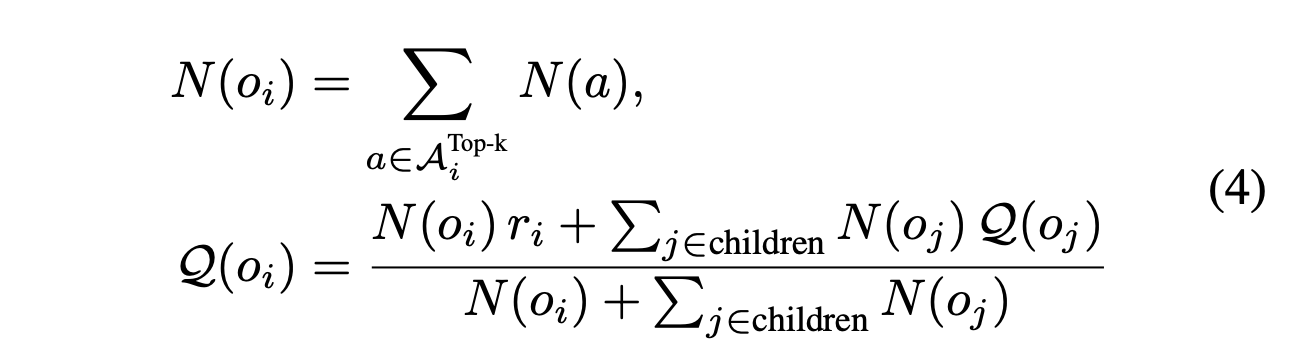
为了高效部署并降低延迟,访问次数受到限制,因为它是主要的推理成本。为了克服这个问题,通过从分布中自然导出的概率密度来估计采样动作(而不是状态 o_i)的访问次数。
d) 选择:此步骤旨在选择兼顾搜索质量和效率的首选节点。选择依据两个因素:节点 o_i 的值 Q(o_i) 和访问次数 N(o_i)。本文采用置信上限 (UCB) 策略 [32]。选择公式如下: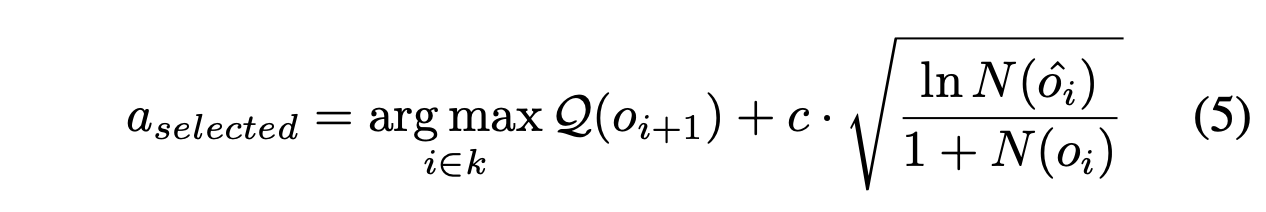
其中 c 是约束探索的常数(例如,1/√2),oˆ_i 表示 o_i 的父节点。UCB策略能够在搜索过程中平衡探索和利用。选择UCB得分最高的节点。
这四个步骤在一轮迭代中重复进行,每次迭代以真实状态和动作作为输入。整个过程构建一个独立的当前机器人状态蒙特卡洛树,因为使用世界模型来指导状态转换。生成这样的树结构相当于找到一个优化的动作搜索空间,可以从中筛选出最佳候选动作。然后,根据公式(1)将该候选动作注入到VLA预测中。由于VLA总能预测出次优动作,对VLA的迭代进行稀疏蒙特卡洛树搜索(MCTS),这样既能显著提高效率,又能提升动作质量。
高效采样的分布
为了扩展进行高效采样,利用核密度估计 (KDE) 对离线数据中操作的分布进行建模。KDE 是一种非参数方法来估计随机变量的概率密度函数,它基于历史数据生成可能有效的各种操作候选。对于操作数据集 {a_1, a_2, …, a_n},KDE 可以表示为: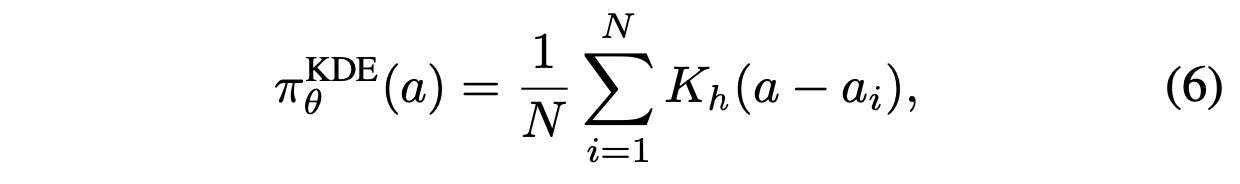
其中 K 是核函数(这里使用高斯核),h 是控制估计密度平滑度的带宽参数,θ 表示上述涉及的超参。
然后,可以通过 a_i ∼ πKDE_θ(·) 高效地对分布进行采样。由于 KDE 返回概率密度 p_i = πKDE_θ(a_i),可以将其视为大规模采样情况下(及其对应状态)动作被访问频率的蒙特卡罗估计。实际上,这为访问次数提供一个软先验,即 N(a) ∝ p(a),这对于高效的反向传播至关重要。
对于输出动作块(例如,一系列动作)的策略,调整 KDE 算法以对动作块进行采样。将每个动作块视为一个独立的实体,并对整个动作块应用 KDE 算法,从而能够采样多样化且有效的动作序列。为了避免过长的动作块冲淡细粒度的修正并影响 KDE 算法的性能,修改所使用的策略,使其以可控大小的动作块(例如,小于 8 个)展开,同时仍然能够受益于序列级的提议。
基于视觉的奖励塑造
奖励可以反映任务进度。为了评估模型生成状态的奖励,遵循视觉观察的变化是进度关键指标的理念 [33]。一种直接的方法是测量这种变化并直接从图像帧中导出奖励。然而,操作轨迹通常是密集的。为了减少冗余并保留有意义的变化,对离线数据集中的图像序列进行下采样。这确保连续帧包含足够的变化,同时保留大部分的进展信息。基于下采样后的序列,通过 0 到 1 之间的线性插值来分配相对的真实值奖励。例如,在一个 10 帧的序列中,第 5 帧的奖励值为 5/9。
为了实现高效且一致的评分,用具有冻结 ImageNet 预训练权重的 ResNet-34 [34] 作为视觉编码骨干网络,然后进行一个使用均方误差 (MSE) 损失的两层多层感知器 (MLP) 训练。训练目标可以表示为: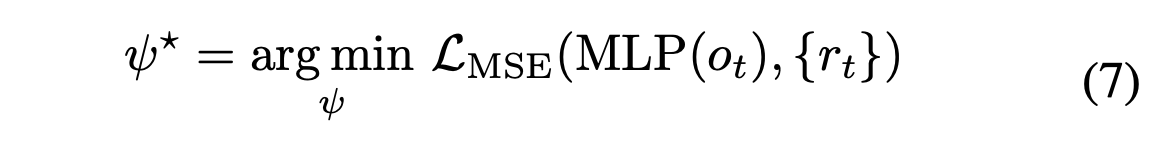
其中奖励由 r_t = MLP(o_t) 生成。凭借简洁而高效的设计(网络训练时间不到 30 分钟),该设计能够实现精确的反馈,从而提升性能。
VLA-Reasoner 的伪代码如下所示(算法 1)。除世界模型外,其他组件均使用与微调 VLA 相同的数据集进行训练。对于世界模型,还额外收集一小部分故障演示数据,以对其进行微调,从而更好地预测故障情况。

VLA推理器在仿真中的应用
a) 实验设置:用三种流行的通用机器人策略组合来评估方法:OpenVLA,一个参数规模为70亿的VLA模型[1];Octo-Small[3],一个结合扩散头用于动作预测的Transformer模型,参数规模为2700万;SpatialVLA,一个参数规模为40亿的空间增强型VLA模型[40]。遵循iVideoGPT[31]的架构来训练一个动作-觉察的世界模型,其参数规模为6亿。所有训练阶段(包括KDE估计和奖励塑造)都依赖于从仿真器生成的相同公开数据集。对于世界模型,还补充使用从预训练VLA自身部署过程中收集的一小部分故障演示数据,使模型能够在部署过程中捕获这些故障。在执行过程中,OpenVLA 和 Octo 每次随机生成 1 个动作,而 SpatialVLA 每次随机生成 4 个动作组成一个动作块。选择 LIBERO [35] 和 SimplerEnv [36] 进行仿真。对于 LIBERO,用 4 个任务套件:空间任务、物体任务、目标任务和长时任务。每个套件包含 500 个专家演示,分布在 10 个语言条件化任务中,每个任务有 50 个变体,旨在评估策略在不同空间配置、物体类型、目标和长时任务序列中的泛化能力。在 SimplerEnv 中,使用 WidowX 机器人执行 4 个代表性任务:1. 积木:将绿色积木堆叠在黄色积木上;2. 勺子:将勺子放在毛巾上;3. 胡萝卜:将胡萝卜放在盘子上;4. 茄子:将茄子放入黄色篮子中。用 OpenVLA-SFT 来指代在公开的 LIBERO 数据集上微调的 OpenVLA 模型。所有训练过程都在一台配备 6 个 NVIDIA RTX 6000 GPU 的服务器上进行。
真实环境部署
a) 实验设置:为了评估 VLA-Reasoner 在真实机器人环境下的性能,设计并测试 5 个真实世界任务,并将方法部署在两款先进的 VLA 模型上:一款是开源的流行模型 OpenVLA-7B [1],另一款是具有局部微调功能的高级商业模型 π0-FAST [41]。训练阶段使用相同的数据集,并且为每个任务收集 10 个失败案例,以补充世界模型的训练。每次推理后,OpenVLA 预测下一个动作,而 π0-FAST 则预测接下来的 5 个动作。用固定的 Galaxea-A1 机械臂进行评估。图像由一个侧向固定摄像头和一个腕部固定摄像头提供(由于 OpenVLA 不支持腕部图像输入,因此未使用腕部固定摄像头)。真实世界推理在 NVIDIA RTX 4090 GPU 上进行。如图所示实验装置:
对于每个评估任务,收集 20 次演示,主要物体的初始位置略有随机化。设计 5 个任务,分别测试受试者的身体感知能力、操作精度和长远理解能力。这些任务包括:
- 积木:将绿色立方体叠放在蓝色立方体上。
- 水果:摘下葡萄并放入篮子中。
- 单杯:将绿色杯子叠放在紫色杯子上。
- 双杯:将绿色杯子和粉色杯子叠放在紫色杯子上。
- 圆圈:绕着杯子画圈。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 17
17 0
0- 0



 已为社区贡献211条内容
已为社区贡献211条内容

所有评论(0)