视频生成器是机器人策略
25年8月来自哥伦比亚大学和TRI的论文“Video Generators are Robot Policies”。尽管灵巧操作取得了巨大进展,但当前的视觉运动策略仍然受到两大挑战的根本制约:一是难以在感知或行为分布变化的情况下进行泛化;二是其性能受限于人类演示数据的大小。本文利用视频生成作为机器人策略学习的代理(proxy),以同时解决这两个限制。视频策略(Video Policy)框架,是一个
25年8月来自哥伦比亚大学和TRI的论文“Video Generators are Robot Policies”。
尽管灵巧操作取得了巨大进展,但当前的视觉运动策略仍然受到两大挑战的根本制约:一是难以在感知或行为分布变化的情况下进行泛化;二是其性能受限于人类演示数据的大小。本文利用视频生成作为机器人策略学习的代理(proxy),以同时解决这两个限制。视频策略(Video Policy)框架,是一个结合视频和动作生成的模块化框架,可以进行端到端的训练。结果表明,学习生成机器人行为视频能够以最少的演示数据提取策略,从而显著提高鲁棒性和样本效率。该方法在仿真和真实世界中均展现出对未见过的物体、背景和任务的强大泛化能力。任务的成功与生成的视频密切相关,无动作的视频数据对于泛化到新任务至关重要。通过利用大规模视频生成模型,实现比传统行为克隆(BC)更优异的性能。
如图所示,视频策略(Video Policy)模型展现这一过程。只要视频生成模型能够合成准确的机器人行为视频,那么经过训练的解码器只需极少量的演示数据即可学习将视频映射到机器人可以直接执行的动作。值得注意的是,一个小型解码器即可被训练成泛化到未见过的任务,这表明视频生成模型本身就是策略,而解码器主要充当接口,而非学习任务策略本身。
由于该策略高度依赖于大规模生成模型合成的视频,并且该视频模型已在各种类型的视频上进行训练,因此与现有方法相比,该方法能够以更少的训练数据泛化到新物体、场景和任务。在仿真和实际实验中,与行为克隆方法相比,使用强视频先验可以提高性能。
概述
给定输入场景 v_0 和任务描述 c,视频策略会生成一系列动作 a_t 来完成该任务,其中 k 是机器人末端执行器的动作维度。用一个视频生成器 f,用于合成机器人展开视频 {vˆ_t},作为该策略的骨干;以及一个学习模型 g,用于根据合成帧预测机器人动作 a_t。该架构的优势在于,它整合来自互联网视频的被动预训练,以提供泛化先验信息,以及主动演示,以学习物理世界中强大的策略。通过微调 f 和 g 来生成待执行任务的视频和动作,从而实现这一点。在推理阶段,生成的动作将直接在机器人上执行,以完成操作任务。
架构
为了将视频生成与策略学习相结合,设计去噪扩散架构 f 和 g,它们联合预测未来的视频帧 {vˆ_t} 和动作序列 {a_t}。为此,f 是一个视频 U-Net 网络 μ_θ,g 是一个动作 U-Net 网络α_θ。参见下图的概述。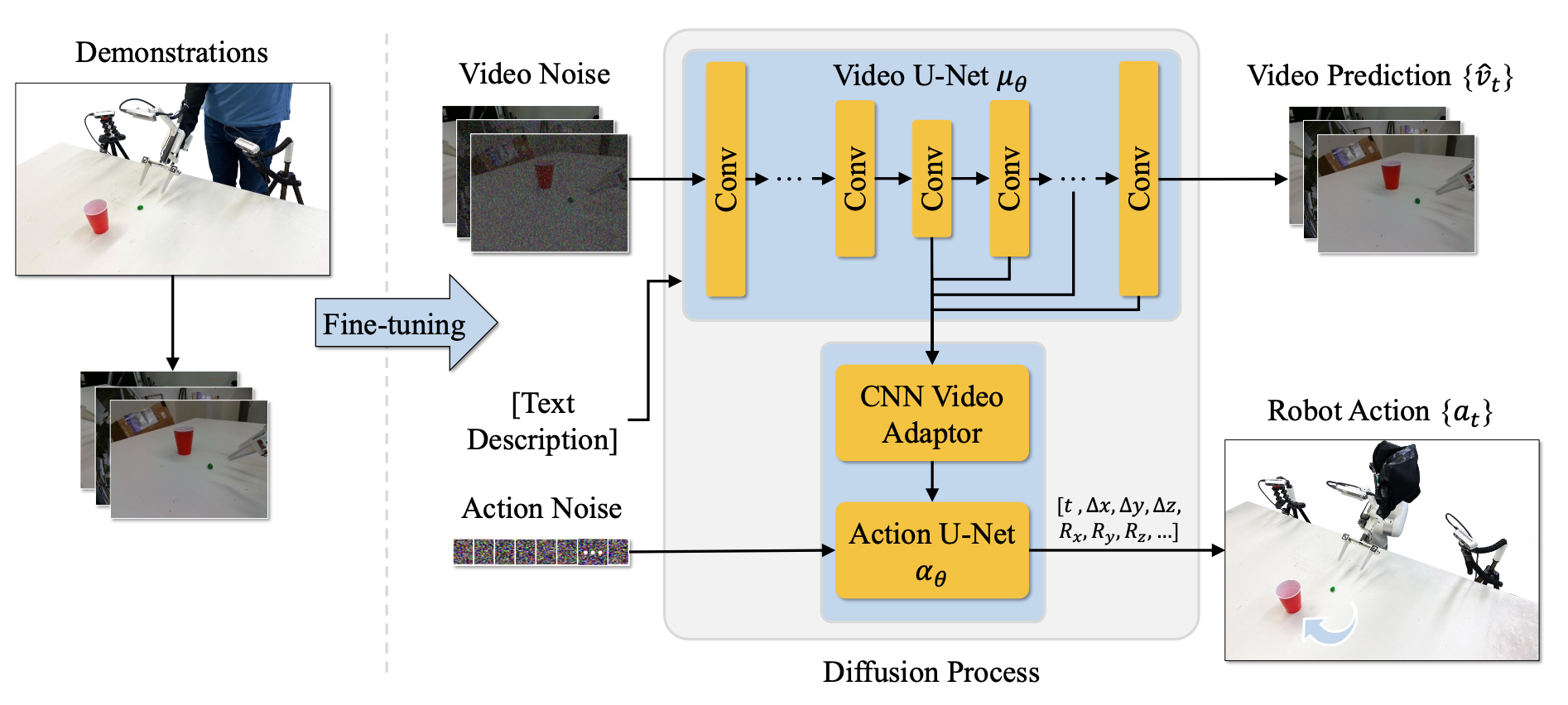
基于图像-到-视频的稳定视频扩散 (SVD) [12] 架构,通过交叉注意机制,将视频 U-Net模型 μ_θ 条件化为任务 c 的文本描述 CLIP [10] 嵌入 φ©。在第二个数据流中,将 VAE 编码的图像 z_0 = VAE(v_0) 与视频的编码噪声帧 z_1, …z_t 逐通道拼接(用 SVD 中的冻结 VAE)。
扩展该架构,使用动作 U-Net α_θ 来解码动作,该动作 U-Net 的条件化为来自视频去噪网络的中间特征。在每个去噪步骤 i 中,从视频 U-Net 的解码器层中提取五个等间距的隐层嵌入(第 9、14、17、20 和 23 层)。这些时空特征通过 CNN 适配器,在去噪步骤 i 中将潜嵌入转换为单向量 h_i。该向量作为全局条件输入,输入到一维 CNN U-Net 模型 α_θ 中,该 U-Net 改编自扩散策略 [2],然后通过以下公式生成机器人动作序列 {a_t}:
{a_t} = α_θ(a_i, i, h_i)
此过程在每个去噪步骤 i 中重复进行,将视频和动作预测紧密结合,从而实现动作和视频的同步生成。
学习
视频策略的训练分为两个阶段:首先训练视频模型进行视频预测,然后训练动作模型进行行为克隆,训练数据集为专家演示数据集 D = 「d_1,…,d_n」。每个演示 d_i 包含场景视频观测 {v_t}、任务文本描述 c 以及相应的机器人动作 {a_t}。
视频模型 μ_θ 的训练目标是最小化目标函数 L_video,动作模型 α_θ 的训练目标是最小化目标函数 L_action。由于希望视频网络凭借其大量的预训练来驱动策略,而 α_θ 仅负责解码机器人动作,因此阻止 L_action 的梯度反向传播到 μ_θ。正如在实验中所展示的,这显著提高性能。
视频策略训练完成后,通过提供场景的初始视觉观测 v_0 和任务描述 c 来部署它。然后,该模型联合生成预测视频帧序列{vˆ_t}和相应的机器人动作序列{a_t}。随后,预测动作{a_t}直接用于控制机器人的末端执行器以执行操作任务。
实现细节
用三个摄像头(一个安装在机械臂上,另外两个分别位于场景两侧)作为视频观测输入。这三个视角沿时间维度拼接,使得 v_t,模型训练用于预测每个摄像头视角的 8 帧(总共 24 帧)。对于 Libero10 基准测试,采用略有不同的设置,使用智体和机械臂的摄像头视角进行训练,以预测每个摄像头视角的 12 帧。为了与预训练的 SVD 模型预期输入保持一致,在序列开头填充一个摄像头帧,最终所有模型的帧数均为 25 帧。在训练过程中,将视频预测的学习率设置为 1e−5,动作预测的学习率设置为 5e−5。
仿真实验设置和基线
用 RoboCasa [51] 和 Libero10 [52] 仿真基准测试对视频策略进行定量评估,这些基准测试涵盖了总共 34 个操作任务。对于每个任务,两个基准测试都提供了 50 个人类演示。在 RoboCasa 基准测试中,演示视频以 256×256 像素的分辨率回放。对于 Libero10,演示视频被调整为相同的分辨率。仿真基准测试的动作空间定义为 a_i,其中包括机械臂的 6 自由度姿态以及表示机械臂打开或关闭状态的标量值。对于 RoboCasa 评估,遵循 [51] 中概述的评估协议;具体而言,每个任务在五个不同的 RoboCasa 场景中执行总共 50 次 rollout 进行评估。对于 Libero10 评估,遵循 [49] 中的评估协议。
作为 RoboCasa 的基线模型,用与视频条件策略模型相同的输入和评估环境,在同一数据集上训练统一视频动作 (UVA) [49] 以及(ImageNet 预训练的)基于 ResNet 和 CLIP 的扩散策略变型。对于其他 RoboCasa 和 Libero10 基线,将其与先前几项工作报告的结果进行比较 [53, 54, 49]。
视频模型实现
采用预训练的 SVD 模型,该模型可生成 25 帧的视频序列。在 RoboCasa 实验中,第 1 帧为填充帧,第 2-9 帧对应于机械臂视角,第 10-17 帧对应于左侧摄像头视角,第 18-25 帧对应于右侧摄像头视角。为了使模型能够生成这种多视角视频,根据每个输出帧的视角摄像头修改逐帧图像嵌入。默认情况下,生成的视频每个视角包含 8 帧,并在默认的 RoboCasa 动作空间中表示机器人在 32 步预测范围内的动作(视频使用 4 步长进行下采样)。此设置在仿真和实际实验中均保持一致。在八块 A100 GPU 上对模型进行大约两周的微调,发现进一步训练并未带来性能提升。对于实际应用模型,首先以 256×192 的分辨率进行训练以加快训练速度,随后以更高的分辨率 448×320 进行训练以提升性能。在所有实验的推理过程中,使用 30 个去噪步骤,并保持恒定的无分类器引导(CFG)尺度 2.0。在 A100 GPU 上,生成一个 25 帧的视频(分辨率为 256×256,扩散步骤为 30)大约需要 9 秒。
所有 RoboCasa 实验均遵循标准的 RoboCasa 评估协议,但对视频预测范围的研究除外。
实验环境设置
如图所示数据采集和机器人实验设置。在数据采集过程中,由一名人类演示者使用改装后的机器人夹爪执行任务。在机器人实验中,机器人使用相同的设置执行任务。
演示过程使用安装在左侧、右侧和夹爪上的 RGB 摄像头进行录制。侧视 RGB 摄像头为 Intel RealSense D435,夹爪上的摄像头为 Basler 鱼眼摄像头。夹爪的姿态由 RealSense T265 摄像头跟踪,平行颚张开度通过 ArUco 标记跟踪进行估计。夹爪上安装的单轴力传感器用于测量抓取力。所有传感器的工作频率均为 30 Hz。该模型经过训练,能够根据来自三个摄像头视角的三个 RGB 图像输入,预测未来 32 步的夹爪相对姿态、颚部相对位置和绝对抓取力。在展开过程中,机器人使用阻抗控制,在 32 个预测步骤中的 24 个步骤中跟随预测的夹爪姿态和颚部位置。为了防止机器人抓取力不足的物体,如果在展开过程中预测的夹爪力比实际测量的力大 300 克以上,则会应用一个较小的夹爪闭合修正。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 8
8 0
0- 0



 已为社区贡献182条内容
已为社区贡献182条内容

所有评论(0)