具身智能学习(Task2--视觉感知与手眼协调)
我的理解是,物体(标定定位板)上画了一些严格的格子(刻度是固定的),这个根据刻度在摄像头上显示的所占像素的多少,就可计算出物体(标定定位板)在摄像头坐标系中的3d坐标了。这样,摄像头看到的物体-->定位到物体的摄像头坐标系位置-->转换为机械臂基座坐标系-->机械臂就可抓取物体了。手眼标定(Hand-Eye Calibration)是机器人视觉应用中的一个基础且关键的问题,主要用于统一视觉系统与机
Task2开始了3D定位的学习--手眼标定

下面链接是教程的链接地址:
|
Task02:视觉感知与手眼协调,计算机视觉在机器人中应用,手眼标定算法实现,深度估计与3D重建 对应: 1.课程02-机器人基础和控制、手眼协调:该章节涵盖了“机器人基础”(运动学)和“控制”(PID算法)。 every-embodied/02-机器人基础和控制、手眼协调/Hand-Eye Calibration.md at main · datawhalechina/ai-hardware-r 2.课程04-具身场景的计算机视觉、3D重建:该章节涵盖了“计算机视觉”和“3D重建/深度估计” every-embodied/04-具身场景的计算机视觉、3D重建 at main · datawhalechina/every-embodied |
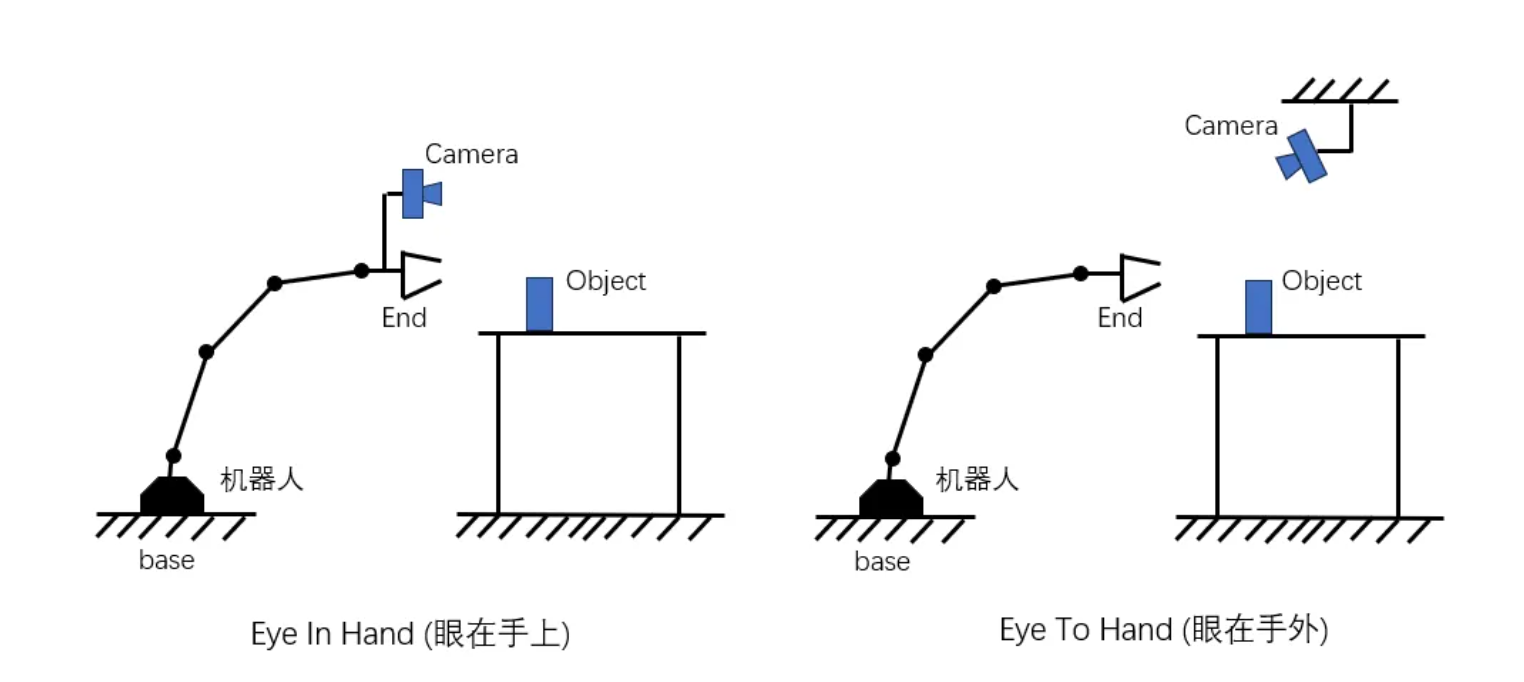
1 手眼标定的定义
手眼标定(Hand-Eye Calibration)是机器人视觉应用中的一个基础且关键的问题,主要用于统一视觉系统与机器人的坐标系,具体来说,就是确定摄像头与机器人的相对姿态关系。
详细内容请看教程。
按照我的理解,说直白一点就是找到“将摄像头坐标系转为机械臂基座坐标系”的转换关系。这样,摄像头看到的物体-->定位到物体的摄像头坐标系位置-->转换为机械臂基座坐标系-->机械臂就可抓取物体了。
那么,由于机械臂是位置是固定的,机械臂夹子在机械臂基座坐标系中的位置可以根据设备的参数进行计算,这个容易理解。但是,物体(标定定位板)在摄像头坐标系的位置是如何知道的呢?我的理解是,物体(标定定位板)上画了一些严格的格子(刻度是固定的),这个根据刻度在摄像头上显示的所占像素的多少,就可计算出物体(标定定位板)在摄像头坐标系中的3d坐标了。
为了方便理解,除了参考教程中的链接,还可参考下面的文章来帮助理解。
https://blog.csdn.net/weixin_29053073/article/details/158055849
2 SAM 分割与单目深度估计:从二维感知到三维理解
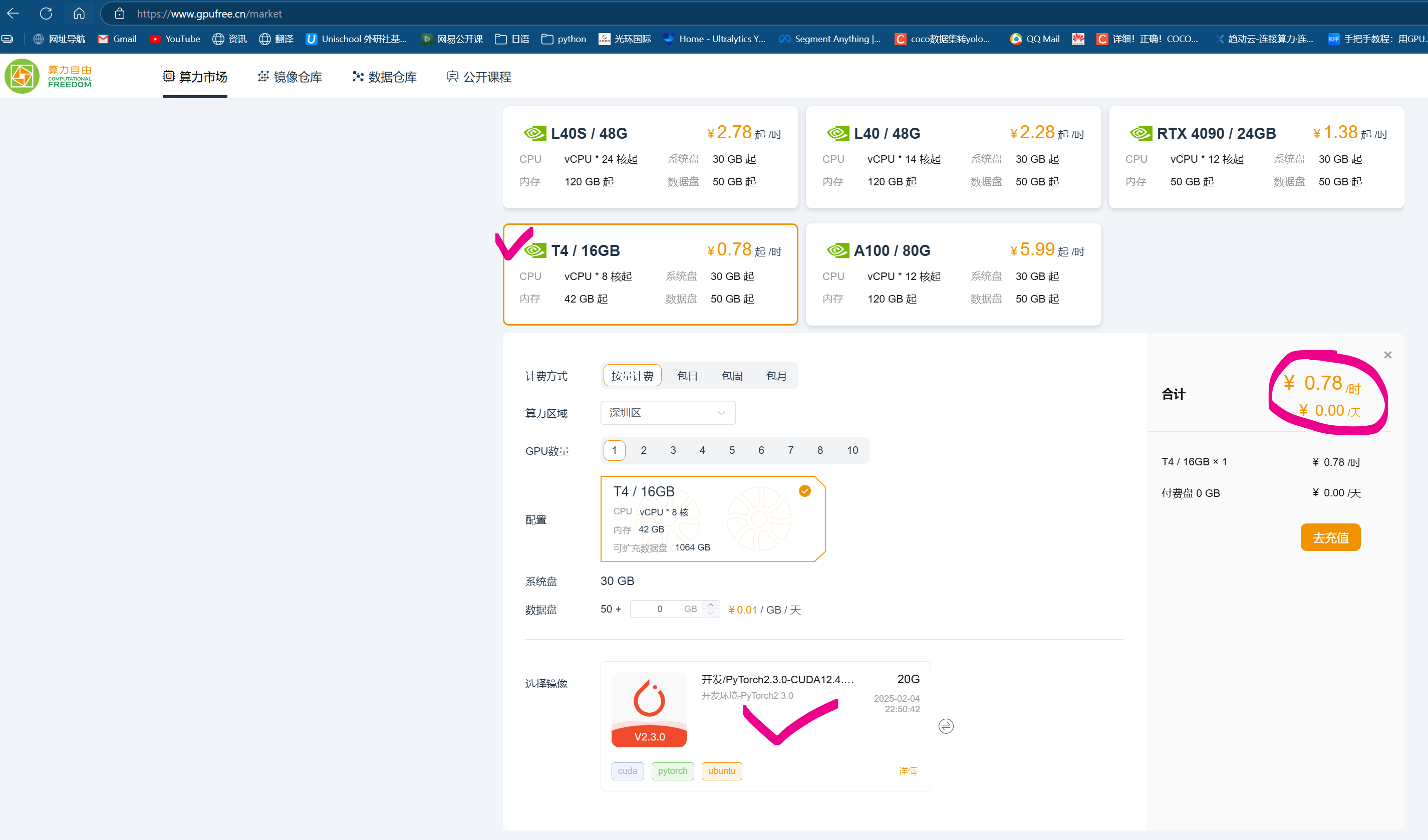
2-1 在“算力自由”平台创建新的环境
选最便宜的T4/16G 0.78元/小时。
2-2 打开Jupyter页面
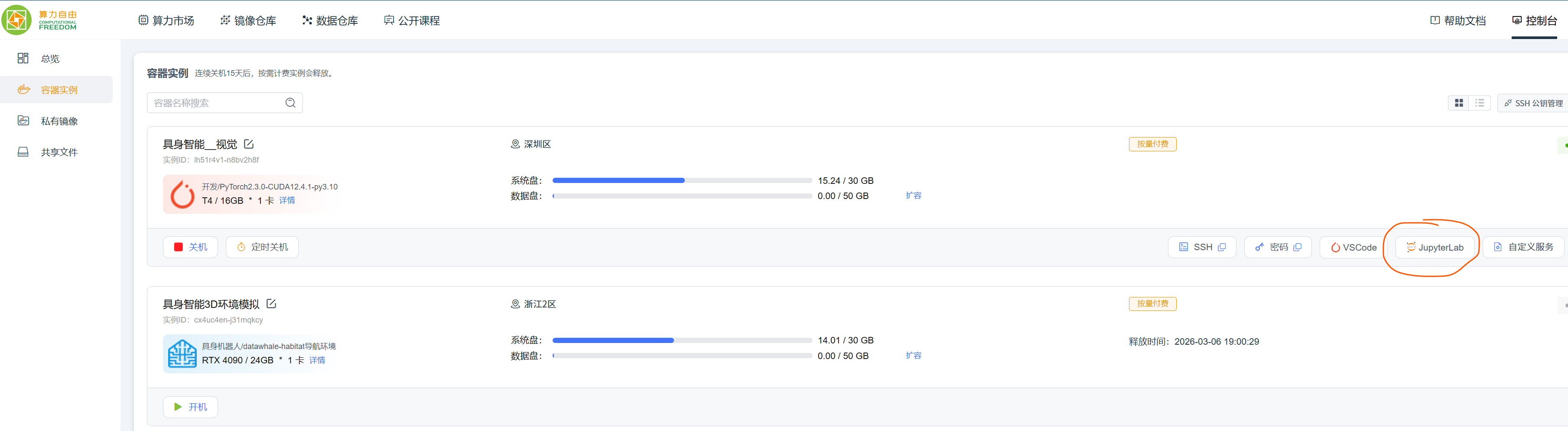
2-3 打开终端

2-4 配置环境(这里是“算力自由”网站租赁虚拟环境的办法)
1.安装segment-anything,时间有点长,耐心等待。
pip install git+https://github.com/facebookresearch/segment-anything.git
2.安装transformers opencv-python matplotlib torch torchvision
pip install transformers opencv-python matplotlib torch torchvision
3.下载SAM 模型权重 (ViT-H),时间较长,耐心等待。
wget 'https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth'
注意⚠️:
①由于镜像环境已经包含opencv了,所以这里不要再重新安装。我重新安装了之后,import cv2总是报错找不到,但是环境里可以查看到已经安装了,这里版本匹配搞了好久都不行!最后就不安装openCV.
②torch的安装上官网找到对应的安装,命令安装。
2-5 打开Juoyter编辑页面

2-6 代码修改
1.原代码运行Loading Depth Model...时一直报错,连接不上hugginface网站。
原因是大陆很多地区不能正常访问huggingface网站,这里要设置一下镜像源。
就是下面这两行代码。
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
2.由于租赁的虚拟环境是没有桌面显示的,所以不能通过点击图片获取坐标,没有图片交互的能力(用Task1那个带桌面的镜像环境,没搞懂怎么把代码文件复制进去,放弃了)。所以,这里使用了代替方法,就是通过手动输入代替通过鼠标点击获取(因为试了很久没有实现通过鼠标点击获取,我又妥协了!)
第一步:将目标保存为带有坐标轴数据的图片,便于观察坐标,后面手动输入。
import cv2
import numpy as np
# 配置图片路径
IMAGE_PATH = "test_image.jpg" # 替换为你的图片路径
OUTPUT_GRID_IMAGE = "coordinate_grid.jpg" # 生成的坐标参考图
# 读取并调整图片大小(固定800x600,坐标范围X:0-800, Y:0-600)
img = cv2.imread(IMAGE_PATH)
if img is None:
raise FileNotFoundError(f"图片文件不存在:{IMAGE_PATH}")
# 固定尺寸,确保坐标范围统一
target_size = (800, 600)
img = cv2.resize(img, target_size)
# 创建坐标网格图
img_with_grid = img.copy()
# 1. 绘制水平/垂直网格线(每50像素一格,方便估坐标)
grid_step = 50 # 网格间距
color_grid = (200, 200, 200) # 浅灰色网格
thickness_grid = 1
# 绘制垂直线(X轴)
for x in range(0, target_size[0], grid_step):
cv2.line(img_with_grid, (x, 0), (x, target_size[1]), color_grid, thickness_grid)
# 标注X坐标(每100像素标一次,避免太密)
if x % 100 == 0:
cv2.putText(
img_with_grid,
str(x),
(x + 5, 25), # 坐标文本位置
cv2.FONT_HERSHEY_SIMPLEX,
0.7, # 字体大小
(0, 255, 0), # 绿色标注
2 # 字体粗细
)
# 绘制水平线(Y轴)
for y in range(0, target_size[1], grid_step):
cv2.line(img_with_grid, (0, y), (target_size[0], y), color_grid, thickness_grid)
# 标注Y坐标(每100像素标一次)
if y % 100 == 0:
cv2.putText(
img_with_grid,
str(y),
(5, y + 25),
cv2.FONT_HERSHEY_SIMPLEX,
0.7,
(0, 255, 0),
2
)
# 2. 添加说明文字
cv2.putText(
img_with_grid,
"X: 0-800 (水平) | Y: 0-600 (垂直)",
(20, target_size[1] - 20),
cv2.FONT_HERSHEY_SIMPLEX,
0.8,
(255, 255, 0), # 黄色
2
)
# 保存坐标参考图(无窗口,直接存文件)
cv2.imwrite(OUTPUT_GRID_IMAGE, img_with_grid)
print(f"✅ 坐标参考图已保存:{OUTPUT_GRID_IMAGE}")
print(f"📌 图片尺寸:800x600,坐标范围:X(0-800),Y(0-600)")
print(f"💡 查看这张图片,找到目标物体的大致X/Y坐标(比如:物体中心在X=450, Y=300)")运行后得到带坐标系的图片,便于后面定位物体的坐标,然后手动输入坐标。

第二步:加载模型
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
import numpy as np
import torch
import cv2
import matplotlib.pyplot as plt
from segment_anything import sam_model_registry, SamPredictor
from transformers import DPTImageProcessor, DPTForDepthEstimation
from PIL import Image
# --- 配置 ---
SAM_CHECKPOINT = "sam_vit_h_4b8939.pth"
IMAGE_PATH = "test_image.jpg"
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"设备: {device}")
# --- 加载模型 ---
sam = sam_model_registry["vit_h"](checkpoint=SAM_CHECKPOINT).to(device)
predictor = SamPredictor(sam)
depth_processor = DPTImageProcessor.from_pretrained("Intel/dpt-large")
depth_model = DPTForDepthEstimation.from_pretrained("Intel/dpt-large").to(device)
depth_model.eval()第三步:手动输入坐标数据(例如输入:490,100),显示深度图片。
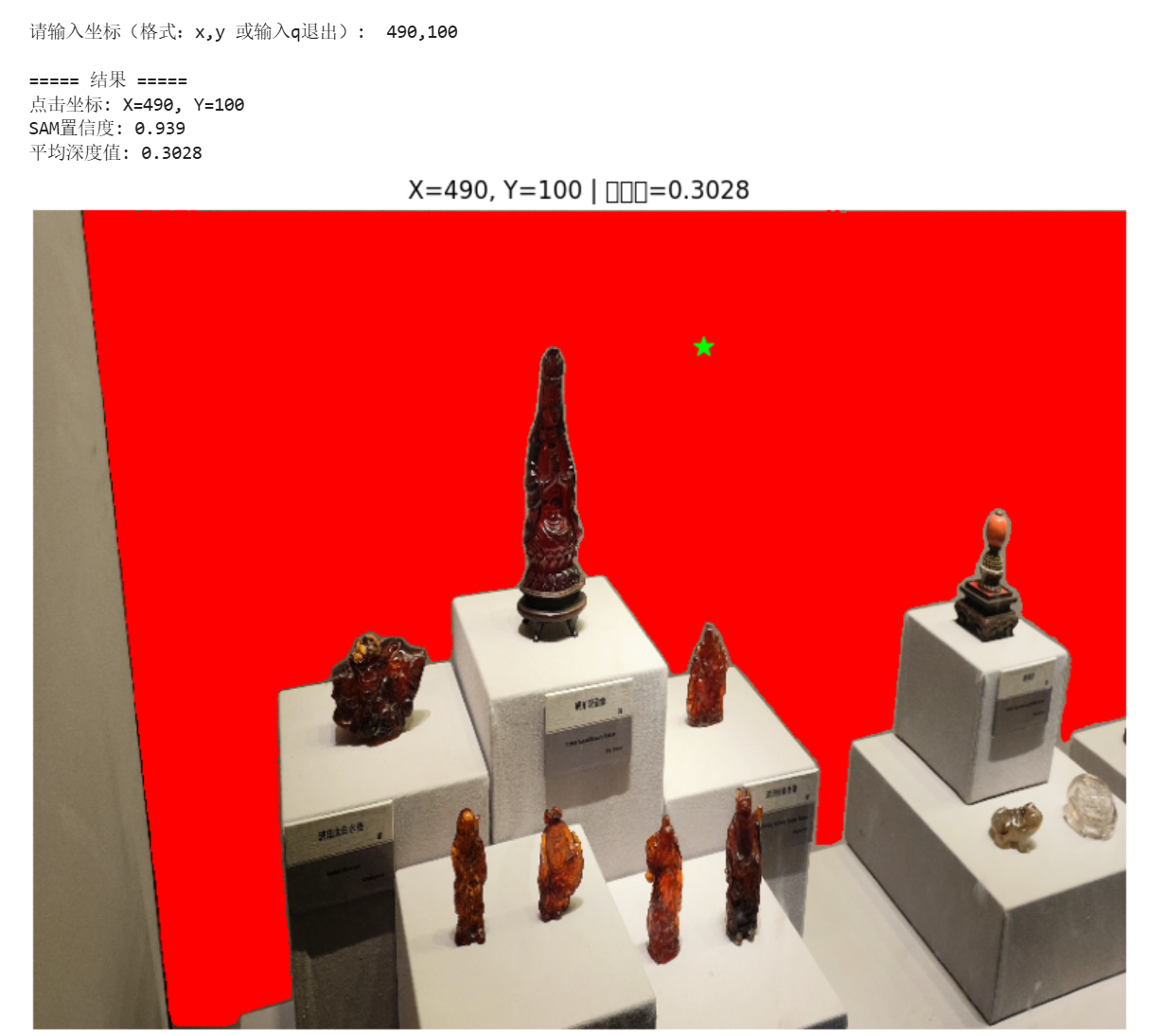
PS:下面是在本地环境运行结果的录屏(可以通过鼠标点击操作):
获取SAM+深度分析
3 抓取注意力热图
这个直接在上面的环境运行就可以,但是这结果感觉不太行呢!感觉什么图识别的结果都是在中间向周围扩散。下图一个是识别“cat”,一个是识别“cup”结果一模一样。
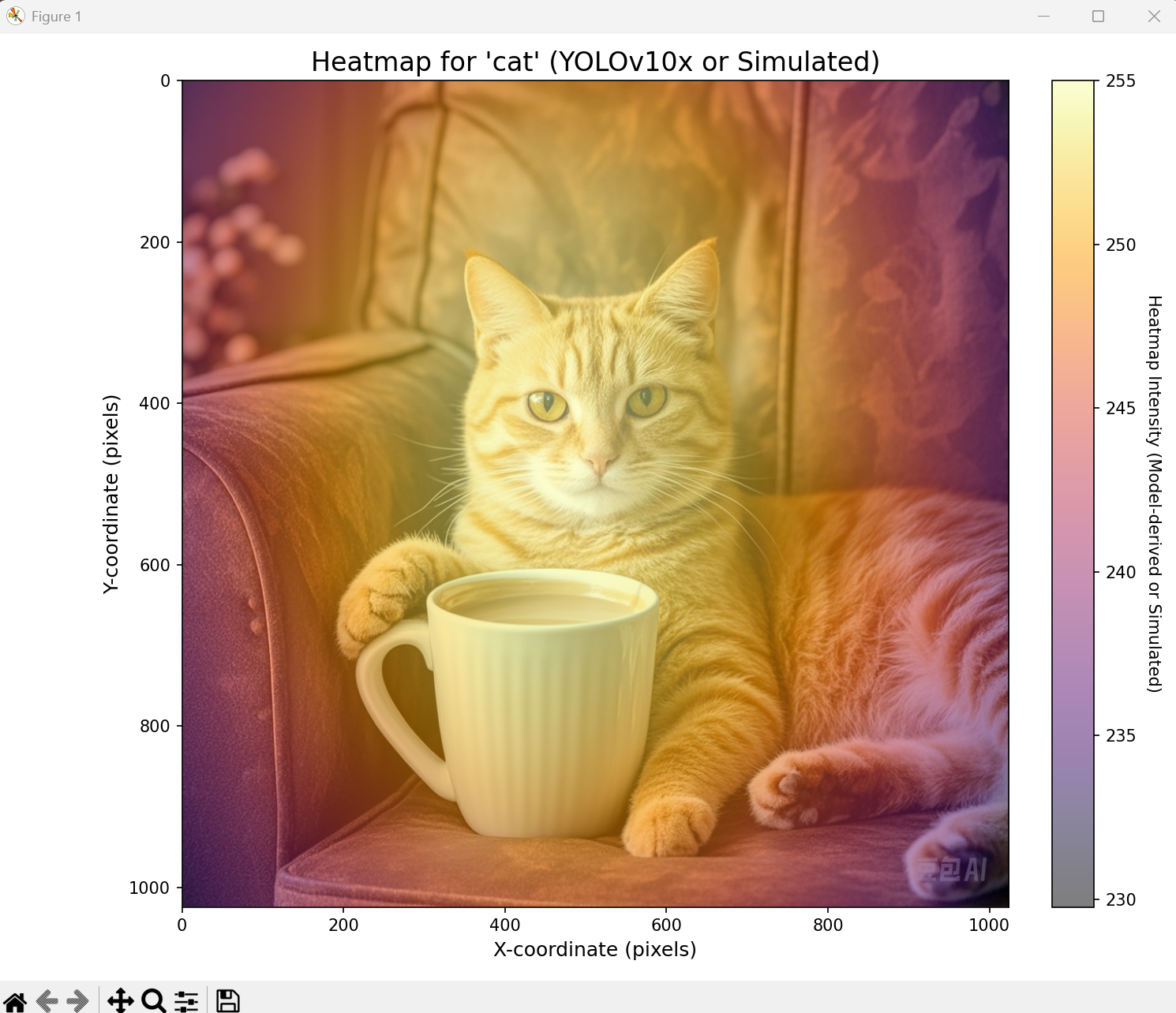
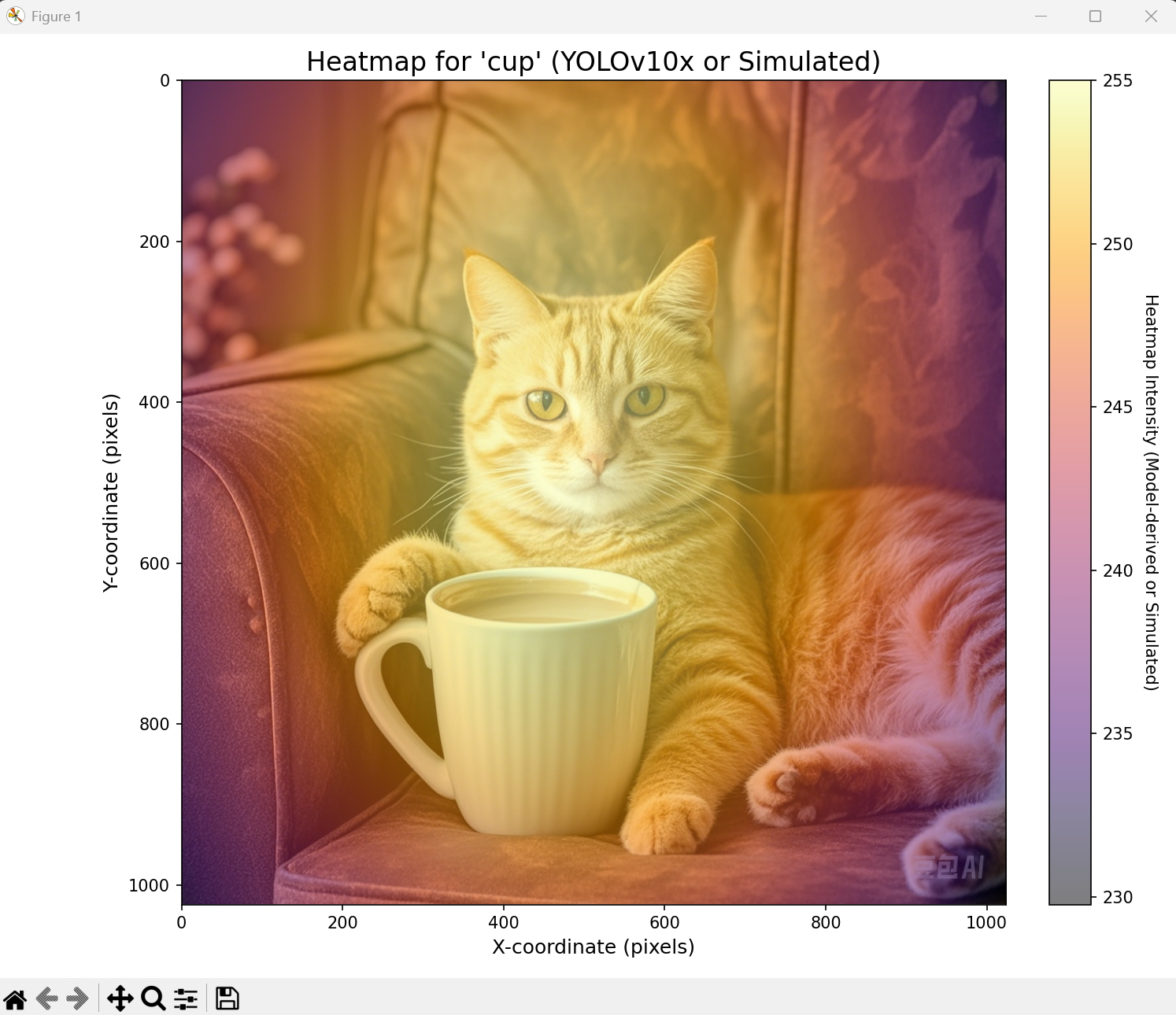

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)