首次用AI Agent的思路来研究VLN,实现3B小模型端侧实时部署
在RxR-CE验证集上的对比显示,AgentVLN以仅3B的微小参数量,在成功率(SR)上全面碾压了参数量高达7B甚至8B以上的现有最先进模型(如InternVLA-N1、DualVLN等),真正实现了轻量化与高性能的完美结合。在这个框架中,视觉语言模型(VLM)被彻底“升维”成了只负责高层调度的“大脑”,它不再死磕底层的空间几何计算,而是像一个成熟的Agent一样,根据当前的环境主动去调用底层的

用AI Agent的思路来研究VLN,会得到什么?
——AgentVLN
目录
上图来自于南京航空航天大学、山东大学与浙江大学的研究团队提出的极具Agent思维的全新范式——AgentVLN。
在这个框架中,视觉语言模型(VLM)被彻底“升维”成了只负责高层调度的“大脑”,它不再死磕底层的空间几何计算,而是像一个成熟的Agent一样,根据当前的环境主动去调用底层的“感知技能库”和“规划技能库”。
这种解耦不仅让大模型从繁重的底层控制中解放出来,更带来了一个令人惊艳的结果:
仅仅使用一个3B参数的轻量级模型,AgentVLN就在多个导航基准测试中击败了参数量远大于它的先进模型,甚至在算力受限的真实四足机器人上实现了端侧实时部署,为轻量化、模块化的具身智能体指明了一条极具潜力的道路。
01 即插即用的“技能包”
当人类在一个陌生的商场里寻找一家餐厅时,我们的大脑并不需要精确计算每一步迈出多少厘米,而是根据看到的标识和空间布局,做出“往前走到尽头右转”的高层决策;具体的避障和行走动作则交由小脑和身体的本能来完成。
AgentVLN正是借鉴了这种人类的认知模式。摒弃了让大模型直接输出底层控制指令的传统做法,转而采用了“VLM-as-Brain”的架构。
在这个框架中,VLM(AgentVLN-3B)扮演着中央控制器的角色,它只负责理解自然语言指令、观察当前环境,并从一个即插即用的“技能库”中挑选合适的技能来执行。
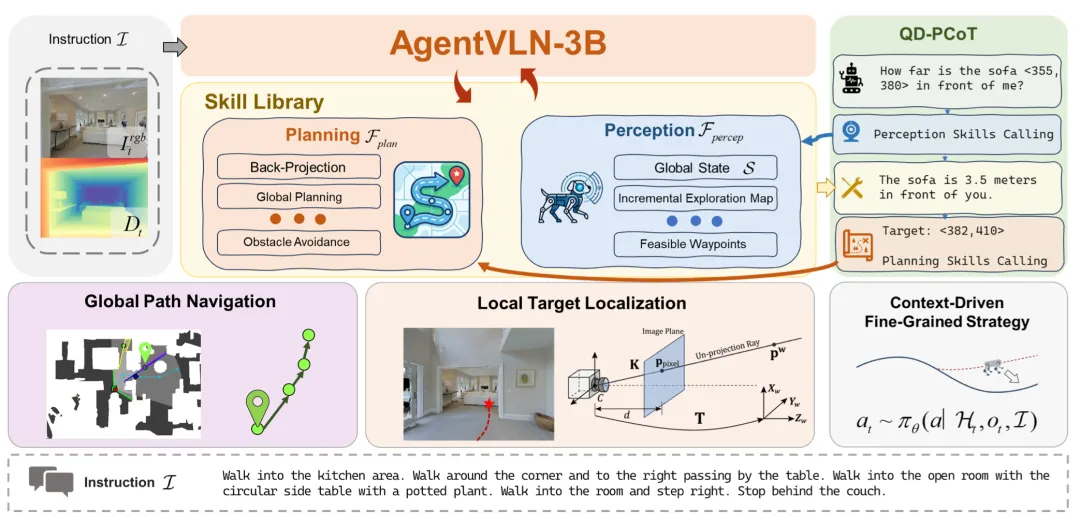
▲图1 | AgentVLN框架总览。
这个技能库包含了感知技能(如构建全局地图、获取可行路径点)和规划技能(如全局路径规划、局部避障)。
通过这种解耦设计,AgentVLN不仅大幅减轻了VLM处理底层三维几何信息的认知负担,还赋予了系统极强的泛化能力——如果需要更换传感器(比如从相机换成激光雷达),只需更新底层的感知技能包,而无需重新训练整个“大脑”。
02 技术亮点
亮点一:跨空间表示映射,填平2D与3D的鸿沟
在具身导航中,VLM通常只能理解二维图像,但机器人却要在三维世界中移动。
为了弥合这种维度上的割裂,AgentVLN提出了“跨空间表示映射”机制。
简单来说,底层感知模块会将三维空间中可行的路径点,通过逆透视投影,精准地“画”到VLM看到的二维图像上。
这样一来,VLM在图像上选择的目标点,就能瞬间转化为三维世界中真实的物理坐标。这一机制让导航成功率(SR)直接飙升了21.1%。
亮点二:QD-PCoT,让机器人主动“提问”消除尺度幻觉
由于单目相机缺乏深度信息,VLM常常会产生“尺度幻觉”,比如把远处的一个小盒子误认为近处的一个大箱子。
为了解决这个问题,AgentVLN引入了查询驱动的感知思维链(QD-PCoT)。当VLM面对复杂的局部环境时,它不再盲目瞎猜,而是主动向感知技能库发起“提问”,获取目标物体的精确几何深度。
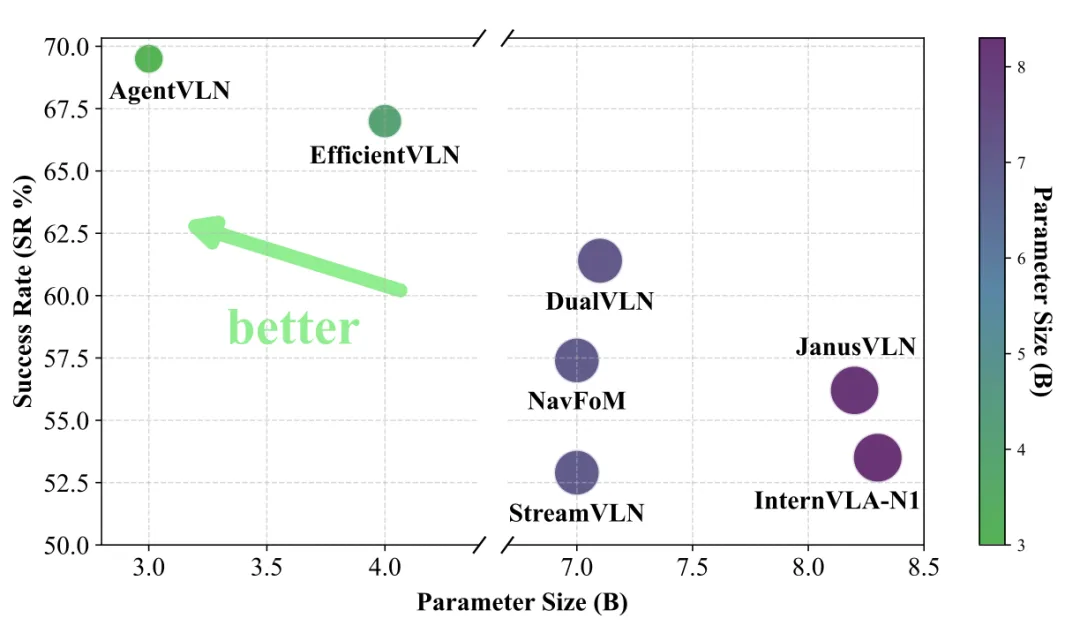
▲图2 | 性能与参数量的极致平衡。在RxR-CE验证集上的对比显示,AgentVLN以仅3B的微小参数量,在成功率(SR)上全面碾压了参数量高达7B甚至8B以上的现有最先进模型(如InternVLA-N1、DualVLN等),真正实现了轻量化与高性能的完美结合。
结合深度信息和自然语言提示,VLM能够准确推断出目标的像素坐标,彻底消除了二维视觉带来的深度模糊。
亮点三:上下文驱动的细粒度策略,长途跋涉不迷路
在长距离导航中,微小的误差往往会不断累积,最终导致任务失败。
AgentVLN设计了一种上下文感知的自校正机制。
当机器人在狭窄的通道中穿行,或者遇到严重的视觉遮挡时,VLM会自动切换到细粒度的原子动作(如微调角度、小步移动),不断修正轨迹。

▲图3 | 图中所示为一项长距离室内VLN任务,AgentVLN通过优秀的上下文自我监测校正,能够保持导航规划以及全局任务记忆的长期稳定,从而轻松cover各种长距离的复杂导航
这种粗细结合的策略,使得系统在长距离任务中的导航误差(NE)显著降低。
03 实验与表现
在权威的连续环境视觉语言导航基准(R2R-CE和RxR-CE)上,AgentVLN展现出了良好的表现。
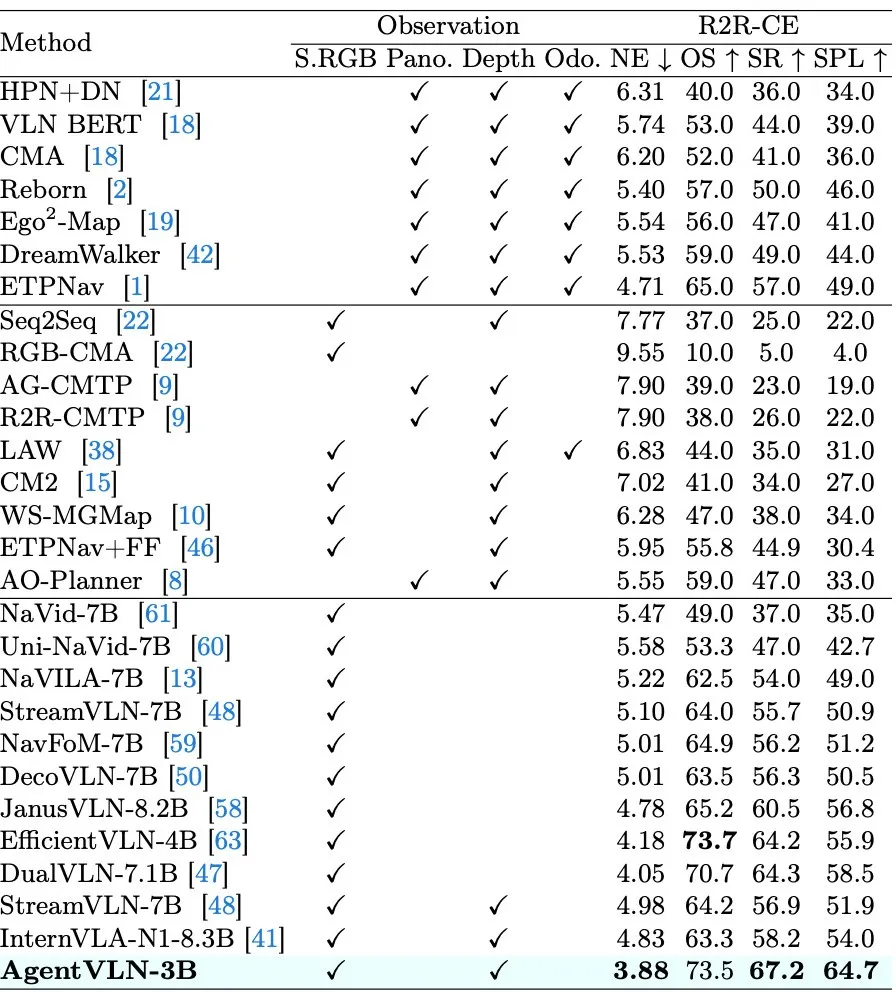
▲图4 | 在R2R-CE的未见环境测试中,AgentVLN-3B实现了73.5%的成功率(SR)和64.7%的路径长度加权成功率(SPL)。相比于参数量庞大的InternVLA-N1-8.3B模型,AgentVLN在参数量缩减了近三分之二的情况下,成功率反而高出了10.2个百分点,SPL更是高出了10.7个百分点
仿真室内环境实验。图中展示了AgentVLN在复杂室内场景中的导航过程。
- 绿色圆点代表感知技能提供的可行路径点;
- 红色圆圈则是模型精准预测的下一步目标。
即使在穿越狭窄门框或面对视觉遮挡时,模型依然能输出精细的调整动作,确保无碰撞地抵达终点。

▲图5 | 仿真室内环境机器人VLN任务可视化
在真实世界中,研究团队将AgentVLN部署在了一台配备Intel RealSense相机的Unitree Go2四足机器人上。
得益于其轻量级的架构,AgentVLN完全摒弃了对云端算力的依赖,在Jetson边缘计算平台上就实现了实时的本地推理,在真实的室内外环境中均展现出了卓越的避障和导航能力。

▲图6 | 走向真实世界的具身智能体。无论是在光线复杂的室内办公区,还是在结构非结构化的室外草地和道路上,搭载AgentVLN的四足机器人都能准确理解“穿过草地之间的路径”、“停在蓝色广告牌前”等自然语言指令,并迅速规划出安全平滑的物理轨迹。
04 总结与延伸
AgentVLN通过将高层语义推理与底层几何感知合理分工,即便是3B的小模型,也能在复杂的物理世界中展现出优异的表现。
这种“大脑+技能库”的模块化范式,为未来具身智能体的规模化部署提供了一条极具潜力的可行路径。
REF
论文标题:AgentVLN: Towards Agentic Vision-and-Language Navigation
论文作者:Zihao Xin, Wentong Li, Yixuan Jiang, Ziyuan Huang, Bin Wang, Piji Li, Jianke Zhu, Jie Qin, Shengjun Huang
论文链接:https://arxiv.org/abs/2603.17670
项目主页:https://github.com/Allenxinn/AgentVLN

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 5
5 0
0- 0



 已为社区贡献89条内容
已为社区贡献89条内容

所有评论(0)