GigaBrain-0——通过世界模型GigaWorld增强VLA的泛化能力:基于RGBD输入建模,及通过具身CoT增强推理能力
前言
25年11月底,我便关注到了GigaBrain-0这个模型
- 当时还在微信上对该公司的联创说
“朱总,你们这个看着,效果不错啊,准备研究下 你们的论文先” - 朱总说
已经开源,欢迎试用,且在智元轮式上,跑过了
且该GigaBrain-0可对标π0.5,至于之所以加个“可”字,是为了表明该模型发布的目的,也不是为了对标π0.5而发布的,且该GigaBrain-0还是有很多并不同于π0.5的创新之处
顺带,今年我司工作的重点之一是:加深与每一个本体厂商的合作关系,期待与本体厂商共同推动中国具身的更快落地
第一部分 GigaBrain-0: A World Model-Powered Vision-Language-Action Model
1.1 引言、相关工作、GigaBrain-0 模型
1.1.1 引言
VLA模型旨在通过将视觉输入、自然语言指令和运动控制整合到一个统一框架中,弥合符号推理与具身行动之间的鸿沟
- 然而,训练这类模型通常依赖于来自真实世界机器人交互的大规模数据集,而这类数据的采集不仅成本高昂、耗时漫长,而且在多样性和可扩展性方面也受到限制
- 且物理数据收集的低效性构成了发展鲁棒的通用机器人系统的一项根本瓶颈,而这类系统需要能够在广泛的环境、物体和任务配置下稳定运行
为克服这些局限,来自GigaBrain Team (alphabetical order)的研究者提出 GigaBrain-0
- 论文地址:GigaBrain-0: A World Model-Powered Vision-Language-Action Model
作者:Angen Ye, Boyuan Wang, Chaojun Ni, Guan Huang, Guosheng Zhao, Haoyun Li, Jie Li,
Jiagang Zhu, Lv Feng, Peng Li, Qiuping Deng, Runqi Ouyang, Wenkang Qin, Xinze Chen, Xiaofeng Wang, Yang Wang, Yifan Li,
Yilong Li, Yiran Ding, Yuan Xu, Yun Ye, Yukun Zhou, Zhehao Dong, Zhenan Wang, Zhichao Liu, Zheng Zhu - 项目地址:gigabrain0.github.io
GitHub地址:github.com/open-gigaai/giga-brain-0
具体而言,这是一种新型的 VLA 基础模型,它利用由世界模型生成的数据,在提高泛化能力和数据效率的同时,降低对高成本真实世界机器人数据的依赖

通过在如图 1 所示、由世界模型生成的合成但逼真的轨迹上进行训练,GigaBrain-0 得以访问海量且多样的经验集合,其中包括物体材质、颜色、光照和视角等方面的变化,远远超出物理方式可收集的范围
且该方法还通过两个框架层面的创新
- RGBD 输入建模和具身思维链(Chain-of-Thought, CoT)监督——进一步提升了策略的鲁棒性
通过引入深度信息,模型能够更充分地理解三维几何结构和空间布局,这对于实现精确操作至关重要 - 与此同时,具身 CoT框架鼓励模型生成中间推理步骤,如操作轨迹和子目标规划,从而模拟支撑人类问题求解的认知过程
这种结构化推理使模型能够有效处理长时程任务以及需要持续注意力和序列决策的精细动作
1.1.2 相关工作
首先,对于VLA而言
在机器人领域,开发能够理解高层指令并在多样化物理环境中高效运行的通用机器人操作策略,仍然是一个基本挑战
- 以往的方法
Karamcheti et al., 2023,即Language-driven representation learning for robotics
Nair et al., 2022,即R3m: A universal visual representation for robot manipulation
Radford et al.,2021,即CLIP模型
Xiao et al., 2022,即Masked visual pre-training for motor control
侧重于利用异构数据集来学习丰富且可迁移的表征,从而在复杂和未见场景中增强策略的鲁棒性
受大型语言模型进展的启发,VLA 框架
Bjorck et al., 2025,即Gr00t n1
Black etal., 2024,即π0
Cheang et al., 2025,即Gr-3 technical report
Doshi et al., 2024,即Scaling cross-embodied learning
Intelligence et al., 2025,即π0.5
Kim et al., 2024,即Openvla
Liet al., 2024,即Cogact
Liu et al., 2024,即Rdt-1b
O’Neill et al., 2024,即Open x-embodiment
Pertsch et al., 2025,即Fast_π0
Qu et al., 2025,即Spatialvla
Team etal., 2024,即Octo
Wang et al., 2024,即Scaling proprioceptive-visual learning,利用异构预训练 Transformer 扩展本体感知视觉学习
作为一种前景可观的范式逐渐兴起,通过扩展模型容量和数据规模,以提升在不同任务和机器人形态之间的泛化能力
这类模型通常构建在预训练视觉—语言模型
Alayrac et al., 2022,即Flamingo
Bai et al., 2025,即Qwen2.5-vl technical report
Beyer et al., 2024,即Paligemma
Liu et al., 2023,即Visual instruction tuning,著名的 LLaVA 模型,通过指令微调提升 VLM 性能
Peng et al.,2023,即Kosmos-2: Grounding multimodal LLMs to the world
之上,利用多模态输入来生成动作序列,可以通过自回归的 token 预测
或者通过基于 flowmatching 的连续动作建模
Lipman et al.,2022,即Flow matching for generative modeling,提出了流匹配理论,为生成式建模提供了新方向
Liu,2022,即Rectified flow,一种改进生成模型传输路径的数学方法
从纯粹的视觉到动作架构转向具有语义基础的、以语言为条件的策略,显著拓展了可实现行为的范围 - 为支撑此类数据需求巨大的模型,研究者日益依赖跨具身形式(cross-embodiment)数据集
Dasari etal.,2019,Robonet: Large-scale multi-robot learning
Ebert et al.,2021,即Bridge data: Boosting generalization
Khazatsky et al.,2024,即Droid: A large-scale in-the-wild robot manipulation dataset
O’Neill et al.,2024,即
Walke et al.,2023,即Bridgedata v2
将来自异构机器人平台的公开日志与大型专有数据集相结合
例如
Bjorck et al.,2025
Blacket al.,2024
Cheang et al.,2025
Intelligence et al.,2025
中使用的那些数据
尽管性能有所提升,这种对大规模真实世界交互数据的依赖在可扩展性和成本方面引发了实际顾虑
其次,对于世界模型作为数据引擎
近期在世界模型方面的进展
- Agarwal et al., 2025,即Cosmos world foundation model platform,NVIDIA 提出的用于物理 AI 的 Cosmos 基础平台
- Alhaija et al., 2025,即Cosmos-transfer1: Conditional world generation,研究具有自适应控制的条件世界生成
- Assran et al.,2025,即V-jepa 2,利用视频模型实现自监督的预测与规划
- Jang et al., 2025,即Dreamgen: Unlocking generalization,通过视频世界模型解锁机器人学习的泛化能力
- Jiang et al., 2025,即Galaxea open-world dataset
- Kong et al., 2024,即Hunyuanvideo,腾讯开发的混元视频生成大模型框架
- Liao et al., 2025,即Genie envisioner
- Wang etal., 2025,即Wan: Open and advanced large-scale video generative models
推动了一个趋势:利用合成数据来缩小具身智能中的仿真到现实(sim-to-real)鸿沟(Zhu et al., 2024)
- 在自动驾驶等领域,生成模型愈发被用于模拟复杂交通场景,相应的方法包括
Gao et al., 2023,2024,即Magicdrive,具有 3D 几何控制的街道视图生成模型,以及Vista,高保真且具备控制能力的驾驶世界模型
Hu et al., 2023,Gaia-1,Wayve 开发的自动驾驶生成式世界模型
Ni et al., 2024, 2025,即Recondreamer,用于驾驶场景重建的世界模型;以及econdreamer-rl,利用扩散重建增强强化学习
Ren etal., 2025,即Cosmos-drive-dreams,规模化的合成驾驶数据生成技术
Russell et al., 2025,即Gaia-2,可控的多视角驾驶视频生成模型
Wang et al., 2024,即Drivedreamer,致力于实现真实世界驱动的驾驶世界模型
Zhao et al., 2024, 2025,即DriveDreamer4D / Recondreamer++ / DriveDreamer-2,一系列关于 4D 驾驶场景表示和 LLM 增强视频生成的系列研究
在机器人领域,由于数据采集常常受限于硬件条件和人工成本,生成式世界模型提供了一种颇具前景的替代方案
包括
Du et al., 2023,即Learning universal policies via text-guided video generation,展示了通过文本引导的视频生成学习通用策略
Feng et al., 2025,即Generalist bimanual manipulation,基于视频扩散模型的通用双臂操作
Jang et al., 2025
Yang et al.,2023,即Learning interactive real-world simulators,研究如何学习可交互的真实世界模拟器
Zhou et al., 2024,即Robodreamer,用于机器人想象力的组合式世界模型
在内的一系列工作利用自然语言提示生成合理的未来轨迹,然后通过逆动力学估计将其转换为低层控制信号 - 为提高合成输出的结构保真度,TesserAct和 Robot4DGen提出了一种统一的多模态生成框架,可同步生成 RGB 帧、深度图、表面法线或 3D 点云流
这使得构建时间一致的 4D 重建成为可能,相较仅在 RGB 视频上训练的模型,显著推动了策略学习
通过诸如背景修复
Fang et al., 2025,即Rebot: Scaling robot learning,通过视频合成实现“真-虚-真”的规模化机器人学习
Yuan et al., 2025,即Roboengine,支持机器人语义分割和背景生成的即插即用增强方案
等技术改变环境纹理
以及视频到视频翻译方法
Alhaija et al., 2025,即
Dong et al., 2025,即Emma: Generalizing real-world robot manipulation,利用生成式视觉转换泛化机器人操作策略
Li et al., 2025,即Mimicdreamer,对齐人类和机器人演示以实现规模化 VLA 训练
Liu et al., 2025
Wang etal., 2025
Xu et al., 2025,即Egodemogen,生成新型第一视角演示以增强视角鲁棒性
对视觉动态进行风格化或自适应变换,可以进一步提升场景多样性
值得注意的是,GigaBrain-0利用世界模型的生成能力,在纹理、材质、光照、物体摆放和相机视角等方面产生高度多样化的数据,为训练 VLA 模型提供了丰富且具有良好泛化性的数据源
1.1.3 GigaBrain-0 模型
GigaBrain-0 是一个端到端的 VLA 模型,在给定视觉观测和高层语言指令的情况下,它会对具身场景进行推理,生成符合指令的动作序列,用于控制轮式双臂机器人(例如Agilex、G1)
为了提高对提示的遵从度并实现更平滑的动作生成,如图 2 所示,GigaBrain-0 采用了 mixture-of-transformers(Liang et al., 2024)架构

- GigaBrain-0 接收 RGB-D 输入以增强空间感知能力,并输出具身思维链(EmbodiedCoT)作为中间表示,从而加强面向操作任务的具身推理
- 在训练过程中,GigaBrain-0 采用 Knowledge Insulation
详见此文《π0.5的KI改进版(已部分开源)——知识隔离:让VLM在不受动作专家负反馈的同时,输出离散动作token,并根据反馈做微调,而非冻结VLM》的介绍
——————
来防止动作预测和 Embodied CoT 生成这两个优化过程之间的相互干扰
它利用预训练视觉语言模型VLM PaliGemma2对多模态输入进行编码,并采用带有 flow matching的动作 Diffusion Transformer(DiT)来预测动作片段
这种混合架构使语义理解与连续动作生成得以解耦但又协同运行
- 在训练过程中,作者引入 Knowledge Insulation,以缓解连续动作空间学习对 VLM 语义推理能力的干扰
此外,作者在 VLM 头部加入了离散动作 token 预测-即FAST_π0,从而显著加速预训练的收敛 - 为了增强空间推理能力,作者在预训练过程中引入RGB-D 数据
给定形状为的输入张量
作者首先对输入进行归一化,并使用SigLIP 提取视觉特征
为了将SigLIP 适配为RGB-D 输入,作者在其第一层卷积层中为深度通道扩展了以零初始化的卷积核
这在保留预训练的 RGB 特征提取的同时,实现了深度感知的表示学习
————
值得注意的是,在整个 GigaBrain-0 的训练过程中,SigLIP 始终保持完全可训练,从而可以针对具身 RGB-D 感知进行自适应微调
在训练期间,作者随机丢弃深度通道(用零填充替换),以确保在推理阶段与仅包含 RGB 的输入保持兼容 - 受大型语言模型中 Chain-of-Thought(CoT)推理方式的启发,作者提出 Embodied CoT,用于提升 GigaBrain-0 在具身环境中的推理能力
不同于标准 LLM,GigaBrain-0 会显式生成中间推理 token,包括:
1)操作轨迹:末端执行器路径在图像平面上的二维投影,用 10 个均匀采样的关键点表示
2)子目标语言:对中间目标的自然语言描述
3)离散动作 token:用于加速后续基于 DiT 的连续动作片段预测(算是受FAST_π0的启发)训练收敛的离散表示
为在模型表达能力与推理效率之间取得平衡,作者放弃在轨迹预测中使用自回归解码。取而代之的是,作者在视觉-语言模型(VLM)中引入 10 个可学习的轨迹 token 作为辅助输入
在特征提取阶段,这些 token 通过双向(非因果)注意力与完整的视觉上下文进行交互,从而能够对整个场景进行整体的空间推理。随后得到的输出轨迹 token 被送入一个轻量级的 GRU 解码器,用于回归末端执行器操作轨迹在 2D 像素空间中的坐标
相比之下,subgoal language 和离散 action tokens 以自回归方式生成,并通过标准的 next-tokenprediction 进行监督
所有组件——包括 trajectory regression、基于语言的 subgoals、离散 action tokens,以及由 Diffusion Transformer (DiT) 预测的连续动作片段(continuous action chunks)——都在统一的目标函数下进行联合优化:
其中
表示训练数据集
是流匹配时间步
是高斯噪声
是用于流匹配的加噪动作片段
是逐token 的掩码,用于指示位置
是否属于CoT 推理流(子目标语言或离散动作)
和
分别表示预测的和真实的二维轨迹关键点
是一个用于平衡轨迹回归损失的超参数
值得注意的是,作者并没有手动为语言和动作预测项分配损失权重,因为 Knowledge Insulation(Driess et al.,2025)本身就可以防止它们的优化过程相互干扰,从而使每个分支能够独立学习
1.2 GigaBrain-0 数据
对于视觉-语言-动作(Vision-Language-Action, VLA)模型而言,训练数据的多样性至关重要(Shiet al.,2025)
- 尽管已有众多公开数据集(Bu et al.,2025;O’Neill et al.,2024;Wu et al.,2024),但在场景变化或任务复杂度方面往往仍显不足,难以支撑模型获得强健的泛化能力
真实世界的机器人数据采集则面临运营成本高、规模化效率低以及环境多样性受限等问题,因为大多数部署场景往往只是从同一小范围的场景中反复采样 - 最新研究进展(Bjorck等2025-即π0.5;Jang 等2025-即DreamGen)表明,world model(世界模型)可以高效生成多样且逼真的训练数据,用于增强VLA的能力
在GigaBrain-0 中,作者进一步拓展了这一范式,集成了更广泛谱系的世界模型生成数据源。如表1所示,GigaBrain-0 相较于现有的 VLA 方法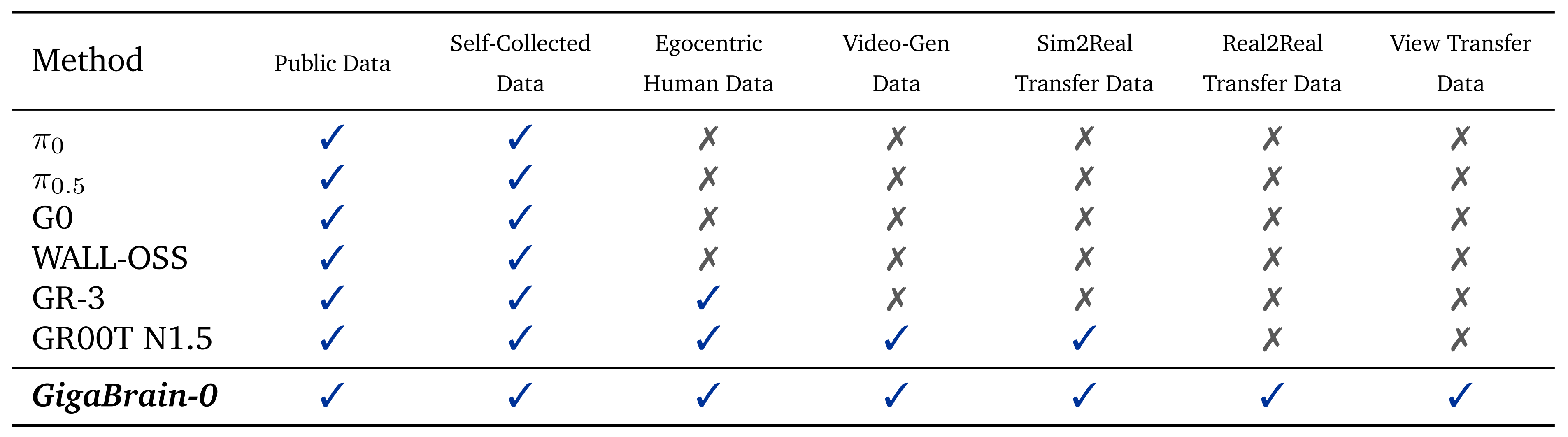
Bjorck 等2025,即π0.5
Black 等2024,即π0
Cheang 等2025,即GR-MG
Intelligence 等2025,即π0.6
Jiang 等2025,即BEHAVIOR Robot Suite
Zhai 等2025,即Retrieval with Learned Similarities
利用了更加多样化的数据源
这种扩展的数据多样性在显著降低对真实机器人采集数据依赖的同时,提升了模型的泛化能力。下文将对每一种数据源作详细说明
1.2.1 真实世界数据
首先,对于数据来源
作者的真实世界数据语料库整合了公开可用的数据集以及基于自研机器人平台采集的专有数据
- 公开来源的数据集包括 AgiBotWorld (Bu et al., 2025)、RoboMind(Wu et al.,2024) 和 Open X-Embodiment (O’Neill et al.,2024),它们共同为操作与移动任务提供基础覆盖
- 此外,作者在总面积为 3100 m² 的场地中,基于 Agilex Cobot Magic 平台(199 小时)和 AgiBot G1 平台(983 小时)共采集了 1182 小时的专有数据,覆盖工业、商业、办公、居住以及实验室五大类环境
这些环境进一步细分为 14 种具体的真实场景,包括超市、酒店大堂、咖啡店、奶茶店、便利店、餐厅、仓储物料搬运区、工业装配线、茶水间、私人住宅、公寓室内、会议室、办公工位以及实验室
所采集的任务范围涵盖从基础的抓取与放置操作,到长时程顺序活动、在动态变化布局中的移动操作,以及与可变形物体的交互,如图 3 所示

其次,对于数据标注与处理
对于数据标注,如果采集到的 RGB 帧缺乏深度信息,作者采用 MoGe (Wang etal.,2025) 来生成具有度量尺度的深度图
- 在子目标语言标注方面,作者观察到 VLMs 在将长时间跨度任务准确划分为有意义的子目标时存在困难,而手动分割被证明极其耗时
为了解决这一问题,作者采用一种受(James et al., 2020) 启发的方法,利用夹爪状态转换(例如,打开/关闭、抓取/释放)来自动将轨迹分割为原子子任务
对于每个分割出的子任务,作者使用Qwen-VL-2.5 (Bai et al., 2025) 生成子目标的语言标注 - 为减轻幻觉并确保一致性,作者通过结构化模板和预定义的标准化动作短语词表es (e.g., pick [object], place [object] into [container], open [device]) ,并从精心整理的描述库中选取,来约束标注过程
对于2D 操作轨迹标注,作者将3D 末端执行器坐标投影到头戴相机的图像平面上,从而得到与视觉观测对齐的像素空间运动轨迹
值得注意的是,作者仅对收集数据的一个子集进行标注,并使用完全标注、部分标注以及原始未标注轨迹的混合来训练模型,以在控制标注成本的同时最大化数据利用率 - 为了进一步提高预训练效率并减少冗余,作者在整个语料库上执行去重。对于每个唯一任务,作者最多保留50 条多样化的示范轨迹,在消除几乎相同重复的同时保留行为多样性
该策略提升了样本效率,并促进了更稳健且更具泛化能力的模型学习
1.2.2 世界模型生成的数据
为克服物理数据采集的局限,作者采用世界模型框架 Giga World 来生成多样且在物理上合理的训练序列。GigaWorld 通过多条互补的数据管线合成数据
- Real2Real Transfer
现实世界中由机器人采集的视频,天然受到其拍摄所在物理环境的约束,包括静态背景、固定的光照条件,以及物体材质、纹理和颜色变化有限等问题
为了克服这些局限性并显著增强视觉和语境多样性,作者利用 GigaWorld 来执行 Real2Real 转移:在经过合成改变但物理上合理的视觉环境中重新渲染真实轨迹
具体而言,作者在从真实视频素材中提取的几何和结构先验的条件下,训练基于扩散的视频生成模型(Dong et al., 2025; Liu etal., 2025)
作者采用 VideoDepthAnything(Chen et al., 2025)来估计逐帧深度图,并提取 Canny 边缘图,以保留物体边界和场景结构
这些信号通过一个ControlNet(Zhang et al., 2023)分支作为空间控制条件,从而在保持运动和布局一致性的同时,实现对外观的精确操控
在推理阶段,对于每个真实世界的视频片段,作者通过文本提示改变前景/背景材质、表面纹理、光照条件以及色彩搭配,在保持原始动作语义和空间动态不变的前提下,生成大约 10 个在视觉上彼此差异明显的变体,如图4所示
这种方法在无需额外物理采集的情况下,高效地成倍提升了真实数据的有效多样性
说白了,就是提升模型对不同光照、背景的适应性 - 视角迁移
除了纹理和光照变化之外,跨观测视角的泛化对于实现鲁棒的具身感知同样至关重要(Xing et al., 2025)
为此,作者利用 GigaWorld 的视角泛化能力,在保持三维场景一致性的同时,用新颖的相机视角来增强真实机器人采集的数据
具体而言,为了在视角变化下保证几何一致性,作者利用采集到的深度图将原始 RGB 帧投影到新的视角中
若源数据中缺乏深度信息,则使用 MoGe(Wang et al., 2025)标注具备米制尺度的深度。重投影后的视图不可避免地包含被遮挡或不完整的区域,作者采用一种基于 DiT 的视频补全模型(Xu et al., 2025),在重投影视图条件下对这些区域进行修复
需要注意的是,当相机视角发生变化时,尽管机器人关节构型会改变,其末端执行器在功能上仍必须与任务保持一致
作者基于更新后的自体位姿和末端执行器位姿,通过逆运动学(IK)计算新的关节角。得到的关节式机器人的几何结构随后在一个考虑物理的仿真引擎中,利用其 URDF 模型进行渲染,并作为结构条件(Xu et al., 2025)提供给生成模型
为减轻仿真与真实机器人动力学之间可能存在的差异,作者可选地使用可微分物理引擎(Wang etal., 2025)来微调运动的物理合理性,缩小 sim-to-real 物理鸿沟
如图 5 所示『GigaWorld 通过从多种视角重新渲染真实世界采集的数据来实现视角迁移,从而以多样的视角变化丰富数据集』
从单个真实世界的轨迹出发,作者的流程生成了多个视角一致的场景渲染图,其中机器人姿态经过动态调整,既保留了任务语义,又保证了物理可行性 - Sim2Real 迁移
虽然上述方法可以增强真实世界数据,但作者进一步利用仿真资产合成多样化的具身交互序列,从而扩展我们的训练语料库
具体而言,作者在 Isaac Sim(NVIDIA)中构建操作场景,这些场景要么使用来自 EmbodiedGen(Wang et al., 2025)的程序生成资产,要么使用来自诸如 ArtVIP(Jin et al., 2025)等开源仓库的精心整理物体
机器人形态通过 URDF 文件进行定义,末端执行器轨迹则通过 IK 计算,以确保运动在物理上合理可行
为弥合仿真到真实(sim-to-real)的域间差距,尤其是在视觉外观方面,作者采用 GigaWorld 的 Sim2Real Transfer 流水线
该方法在架构上与 Real2Real Transfer 相似,它以从仿真环境导出的深度图为条件,驱动一个基于扩散模型的视频生成器(Dong et al., 2025; Liu et al., 2025)
借助文本提示,作者可以动态修改表面纹理、材质反射率、光照条件以及环境杂乱程度,从而在保留原始场景几何结构和动作语义的前提下,生成具有照片级真实感的渲染结果,如图 6 所示『GigaWorld 通过在纹理、颜色、光照和材质属性等方面对仿真采集的数据进行泛化,从而实现 Sim2Real 迁移,更好地弥合域差距并提升真实感』
至关重要的是,与真实世界数据不同,仿真使得能够对场景参数实现完全控制:且可以系统地改变物体初始位置、相机视角、背景布局,甚至是物理属性(例如摩擦系数、质量),以最大化组合多样性 - 人类视频迁移
人类演示视频已经成为训练具身智能体的一种极具前景的数据来源(Bu etal.,2025;Cheang et al.,2025;Kareer et al.,2025;Wang et al.,2023;Yang et al., 2025),在任务、环境以及交互风格上提供了高度的多样性,其规模和丰富程度远远超过仅依赖机器人数据采集所能达到的水平。
然而,当这些原始人类视频被直接用于机器人学习时,仍然存在显著差距,因为第一人称视频往往受到运动模糊、视角不稳定的影响,并且在人手与机器人末端执行器之间存在视觉外观和运动学上的不匹配
为弥合这一差距,作者利用 GigaWorld 的视频修复(videoinpainting)能力,将大规模第一人称人类视频转换为稳定的、以机器人为中心的演示
具体来说,作者将 EgoDex 数据集(Hoque et al.,2025)中的视频转换为经过稳定化处理、可由机器人执行的序列,并用具有关节结构的机械臂替换其中的人手
具体而言,作者使用 SAM2(Ravi etal.,2024)对每一帧中的人手进行分割并遮罩,且在 EgoDex 中提供的带注释的 3D 手腕位置被视为模拟机械臂的目标末端执行器姿态
The annotated 3D hand wrist positions (provided in EgoDex) are treated as target end-effector poses for a simulated robot arm
作者通过IK 求解对应的关节角,然后使用具备物理感知能力的仿真引擎渲染机器人的 URDF 模型
该渲染出的手臂几何作为作者基于扩散的生成器(Li et al., 2025)的结构条件,从而确保机器人外观在运动学上合理且在视觉上前后一致
如图 7 所示『GigaWorld 支持以自我视角的人类视频迁移,通过将第一人称的人手动作转换为机器人操作场景,有效地将人类示范映射为机器人可执行的任务』
输出是对原始人类示范进行稳定化并具身到机器人上的版本,在消除视觉和运动学领域差异的同时,保留了任务意图和空间关系 - 基于逆动力学建模的视频生成
给定一张输入图像,GigaWorld 可以在不同文本提示条件下生成多样化的具身机器人操作视频,如图 8 所示『GigaWorld 可以在不同文本提示下,从相同的初始帧生成多样化的未来轨迹,从而用新颖的操作序列扩充数据集』
此外,作者利用逆动力学模型(Inverse Dynamics Models, IDM)(Jang 等,2025)从这些生成的视频中推断相应的机器人动作序列,并将其作为具身操作任务的合成训练数据 - 多视角视频生成
在具身操作场景中,通常会部署多个摄像机(例如头戴式和腕戴式摄像机)从不同视角捕捉操作环境,这就产生了在时间和空间上保持一致的多视角视频生成需求
为此,GigaWorld 采用了(Donget al., 2025; Liu et al., 2025; Zhao et al., 2025) 中的多视角建模方法,即将来自多个视角的噪声图连接起来,作为扩散模型的输入
这一设计在不修改原始扩散架构的前提下,实现了仅依赖少量微调数据的一致多视角视频生成
如图9 所示『GigaWorld 能生成多视角一致的视频,从而实现具备三维感知的训练,并提升下游任务中的空间推理能力』
GigaWorld 能够生成多样但在几何上保持一致的多视角视频,展现出很强的跨视角一致性和场景保真度 - 生成效率
视频扩散模型(Alhaija et al., 2025; Kong et al., 2024; Wang et al., 2025)存在生成效率低的问题,通常需要耗费数十分钟才能合成包含数百帧的高分辨率视频
为了加快推理速度,GigaWorld 采用了 NATTEN(Hassani 等人,2023 年)作为标准自注意力机制的一种计算效率更高的替代方案
此外,GigaWorld 利用 step distillation(Yin et al.,2024),将去噪过程从数十步压缩为单步生成
结合 FP8 精度推理,这些优化相较于基线扩散模型在视频生成上总体实现了超过 50× 的加速 - 生成数据质量检测
生成视频不可避免地包含幻觉或伪影,这可能会降低下游训练性能
为缓解这一问题,GigaWorld 引入了一套全面的质量评估流水线,从多个维度对生成视频进行评估:几何一致性(Liu et al., 2025)、多视角一致性(Liu et al., 2025)、文本描述对齐度(Azzolini et al., 2025)以及物理合理性(Azzolini et al., 2025)
每个视频都会被赋予一个综合质量评分,用于判断其是适合用于预训练、微调,还是应当被丢弃
上述所有模型与训练细节都将在即将发布的 GigaWorld 技术报告中得到充分阐述
// 待更
第二部分 GigaWorld-0详解
- 其paper地址为:GigaWorld-0: World Models as Data Engine to Empower Embodied AI
- 其项目地址为:giga-world-0.github.io
其github地址为:github.com/open-gigaai/giga-world-0
// 待更

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 21
21 0
0- 0



 已为社区贡献76条内容
已为社区贡献76条内容

所有评论(0)