别再瞎折腾AI工具了!手把手教你用LangGraph构建网络安全AI代理
用个现实例子说明白:同样是让订东京机票,大模型聊天机器人只会说:“这里有一些订票小贴士…”查你日历看有没有空搜索航班比价订最优选项加到你日历发确认信息给你AI代理会自主行动完成目标。LangGraph代理需要以特定方式定义工具。count: int@tool"""使用Subfinder(在Docker中运行)枚举子域名。使用证书透明度、DNS数据集和网络档案。"""文档字符串很重要,大模型决定是否
引言
最近AI代理的话题炒得很火,说是能像人一样自主思考、规划和行动。但这玩意儿到底是啥?咋构建?
今天我就用LangGraph框架,从零教你搭一个网络安全AI代理,不用你懂AI/ML,只要会点Python就行。
先上张图感受一下:

在聊AI代理之前,咱得先明白大模型的局限性。毕竟大模型是AI代理的基础。
大模型本质上就是个文本预测器,生成文本很在行。跟它聊天你会觉得像在跟人说话,但它没法像人一样执行操作。
比如你让ChatGPT帮你订去东京的机票,它最多给你规划行程,没法真的订票、帮你占日历这些实际操作。
什么是AI代理?
用个现实例子说明白:
同样是让订东京机票,
-
大模型聊天机器人只会说:“这里有一些订票小贴士…”
-
而AI代理会:
- 查你日历看有没有空
- 搜索航班
- 比价
- 订最优选项
- 加到你日历
- 发确认信息给你
AI代理会自主行动完成目标。
每个AI代理都有三个核心部分:


ReAct框架:AI代理如何思考
在聊构建工具之前,咱得先明白AI代理咋思考的。
你不能光给大模型一堆工具就指望它能自己玩明白。它需要一个结构化的思考方式。
这就是ReAct框架的用武之地。ReAct代表Reasoning + Acting,是AI代理最常用的框架。
核心思路
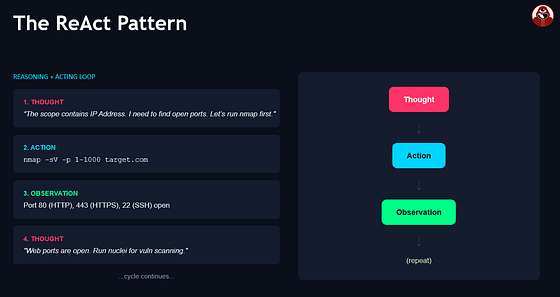
ReAct很简单:代理遵循思考→行动→观察→重复的循环。
- 思考:代理分析下一步该做啥
- 行动:执行操作(通常是调用工具)
- 观察:查看操作结果
- 重复:根据观察结果,再次思考决定下一步
直到代理觉得有足够信息给出最终答案。
具体例子
比如你问代理:“scanme.nmap.org有哪些开放端口?”
ReAct代理会这么处理:
用户:scanme.nmap.org有哪些开放端口?
思考:我需要找到这个主机的开放端口。先解析域名获取IP地址,然后查Shodan的端口信息。
行动:dns_lookup
行动输入:{“domain”: “scanme.nmap.org”}
观察:{“ip”: “45.33.32.156”, “record_type”: “A”}
思考:好,有IP了。现在查这个IP在Shodan上的开放端口。
行动:shodan_host_lookup
行动输入:{“ip”: “45.33.32.156”}
观察:{“ports”: [22, 80, 9929, 31337], “services”: […]}
思考:现在有开放端口了,可以给最终答案。
最终答案:scanme.nmap.org (45.33.32.156) 开放了以下端口:
- 22 (SSH)
- 80 (HTTP)
- 9929 (未知)
- 31337 (Elite)
看到没?代理不是瞎调用工具,而是有逻辑地思考、行动、观察、再思考。
为什么这很重要
ReAct模式强大之处在于,它给大模型提供了结构化分解复杂任务的方法。
没有它,你让大模型"找这个域名的开放端口",它要么胡编乱造,要么说"我做不到"。
有了ReAct,大模型学会了有条理地使用工具,逐步积累知识直到能回答问题。
ReAct背后的提示词
ReAct其实是通过精心设计的提示词实现的。系统提示词告诉大模型如何格式化推理:
你是一个有以下工具的助手:
{tool_descriptions}
使用工具时,必须用这个格式:
思考:[你关于下一步做什么的推理]
行动:[工具名称]
行动输入:[工具输入,JSON格式]
收到工具输出后,会显示为:
观察:[工具输出]
继续这个思考/行动/观察循环,直到有足够信息回答。然后回复:
思考:我现在有足够信息回答。
最终答案:[你的回答]
代理框架(LangChain、LangGraph等)会解析这个输出,执行工具,然后把观察结果反馈给大模型进行下一轮迭代。
现在的大模型API(OpenAI、Anthropic、DeepSeek)原生支持函数调用,大模型会输出结构化的JSON工具调用,不用再解析文本了。LangGraph在底层会利用这一点。
进化史:从原生API到LangGraph
咱要用LangGraph构建AI代理,先得明白为啥用它。
一开始大家直接用大模型API构建代理,得手动调用API、解析响应、可能还要再调用,写了一堆重复代码。
后来LangChain横空出世,改变了AI应用的构建方式。它提供了预构建的常见任务组件。
比如你想让代理记住之前的对话或搜索文档,需要向量数据库。用原生API你得:
- 把文本转换成嵌入向量
- 搭建Pinecone或Chroma等向量数据库
- 写代码存储和检索嵌入向量
- 处理相似度搜索逻辑
LangChain把这些都封装成了简单可重用的组件。不用写50行样板代码,一行就够:
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
# 搞定 - LangChain处理剩下的
vectorstore = Chroma.from_documents(documents, OpenAIEmbeddings())
results = vectorstore.similarity_search("你的查询")
LangChain处理推理循环、工具执行和消息管理,还提供了向量数据库、文档加载器和常用工具的预构建集成。
为啥不用LangChain?
LangChain上手快,但代理变复杂后就会遇到瓶颈:
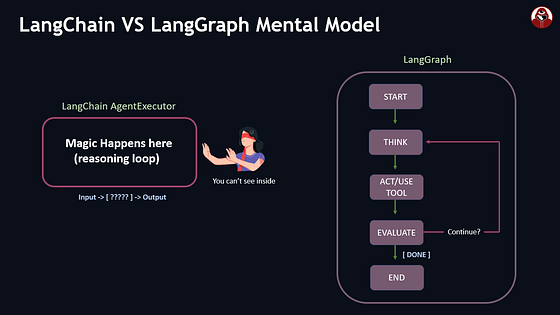
问题1:黑盒
LangChain的AgentExecutor在内部运行循环。你调用.invoke()得到结果,但中间发生了啥?调用了哪些工具?代理为啥做那个决定?很难调试,因为执行过程对你隐藏了。
问题2:控制流有限
如果你想让代理:
- 运行主动扫描前请求人工批准
- 并行运行多个工具
- 根据中间结果走不同路径
- 重试特定步骤而不重启一切
用AgentExecutor要么不可能,要么需要丑丑的变通方案。
问题3:没有内置持久化
如果你构建了OSINT AI代理,运行10分钟调查到一半脚本崩溃了。用基础LangChain,你得从头再来。没法轻易保存代理状态然后恢复。
问题4:多代理协调
现代AI应用 often 需要多个专业代理协同工作。比如一个找子域名的侦察代理,一个检查CVE的漏洞代理,一个总结发现的报告代理。让这些在LangChain中协调需要大量自定义代码。
LangGraph登场
LangGraph由LangChain同一团队创建,专门解决这些问题。核心思路简单但强大:把代理的执行流显式定义为图。
不再是隐藏的循环,你定义:
- 节点:做工作的函数(调用大模型、运行工具、处理数据)
- 边:节点间的执行流
- 状态:在节点间传递并自动保存的数据
用LangGraph,你显式定义这个流:
from langgraph.graph import StateGraph, START, END
builder = StateGraph(AgentState)
# 添加节点
builder.add_node("think", reasoning_function)
builder.add_node("act", tool_execution_function)
builder.add_node("evaluate", check_if_done_function)
# 定义执行流
builder.add_edge(START, "think")
builder.add_edge("think", "act")
builder.add_conditional_edges(
"act",
should_we_continue, # 你的决策函数
{"yes": "think", "no": END}
)
graph = builder.compile()
快速比较
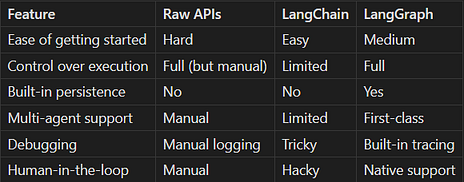
对于简单的RAG聊天机器人,LangChain的AgentExecutor完全够用。但对于需要精确控制、持久化和多个协调代理的复杂工作流,LangGraph是正确选择。
理解LangGraph基础
在构建OSINT代理前,咱先理解LangGraph的核心概念。
概念1:状态
状态就是一个Python字典(或TypedDict),保存代理需要的所有信息。它在节点间传递,随着代理工作而更新。
from typing import TypedDict, Annotated
from langgraph.graph.message import add_messages
class AgentState(TypedDict):
messages: Annotated[list, add_messages] # 对话历史
target: str # 我们在调查什么
findings: dict # 收集的结果
current_step: str # 工作流中的位置
Annotated[list, add_messages]告诉LangGraph当多个节点修改同一字段时如何合并更新。add_messages是内置的reducer,会追加新消息而不是替换整个列表。
概念2:节点
def enumerate_subdomains(state: AgentState) -> dict:
target = state["target"]
# 实际工作
subdomains = run_subfinder(target)
# 只返回变化的部分
return {
"findings": {**state["findings"], "subdomains": subdomains},
"current_step": "enumeration_complete"
}
注意我们只返回想要更新的字段。LangGraph会处理与现有状态的合并。
概念3:边
边定义节点间的执行流。有两种类型:
普通边 — 总是从A到B:
builder.add_edge("enumerate", "probe") # 枚举后总是探测
条件边 — 根据状态选择下一个节点:
def decide_next_step(state: AgentState) -> str:
if len(state["findings"].get("subdomains", [])) > 0:
return "probe"
else:
return "report" # 没找到,直接报告
builder.add_conditional_edges("enumerate", decide_next_step)
概念4:图
把所有东西拼起来:
from langgraph.graph import StateGraph, START, END
builder = StateGraph(AgentState)
# 添加节点
builder.add_node("enumerate", enumerate_subdomains)
builder.add_node("probe", probe_services)
builder.add_node("report", generate_report)
# 添加边
builder.add_edge(START, "enumerate")
builder.add_conditional_edges("enumerate", decide_next_step)
builder.add_edge("probe", "report")
builder.add_edge("report", END)
# 编译成可运行的图
graph = builder.compile()
可视化效果:
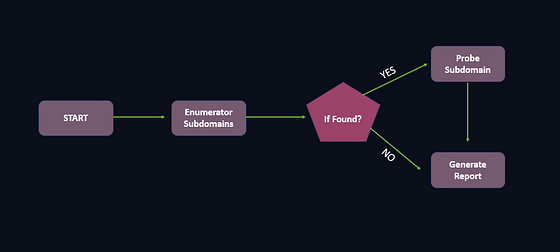
概念5:检查点(持久化)
这是LangGraph的杀手级特性。添加检查点后,每次状态转换都会自动保存:
from langgraph.checkpoint.memory import MemorySaver
checkpointer = MemorySaver() # 开发时用内存
graph = builder.compile(checkpointer=checkpointer)
# 用thread_id跟踪执行
config = {"configurable": {"thread_id": "osint-job-001"}}
result = graph.invoke({"target": "example.com"}, config)
为啥重要?
- 崩溃后恢复:脚本死了?用相同的thread_id重新运行,它会从上次中断的地方继续。
- 调试:检查执行中任何点的状态。
- 审计跟踪:对于安全工作,你有每一步操作的完整记录。
构建我们的OSINT代理
现在咱来真的。创建一个多代理OSINT系统,它能:
- 接收目标域名
- 枚举子域名(使用Subfinder)
- 查询Shodan获取暴露的服务
- 识别技术(使用WhatWeb)
- 生成发现报告
完整代码在GitHub上:https://github.com/dazzyddos/OSINT_AI_Agent
咱来看看架构和关键部分。
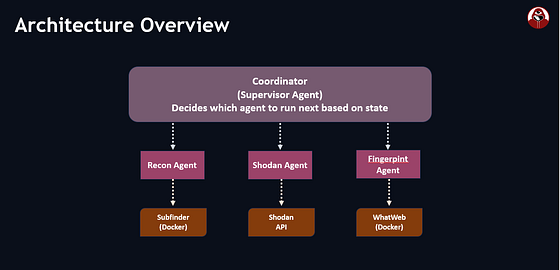
每个专业代理都有特定工具的访问权限。协调器按顺序编排它们,将一个阶段的发现传递给下一个阶段。
为啥用Docker装工具?
我们不在机器上直接安装Subfinder、WhatWeb等工具,而是在Docker容器中运行它们。这样:
- 隔离 — 工具不会搞乱你的主机系统
- 可重现 — 每次都是相同环境,没有依赖冲突
Docker执行包装器核心:
# tools/docker_runner.py
class DockerToolRunner:
"""在Docker容器中执行侦察工具"""
def __init__(self, image: str = "osint-tools:latest"):
self.client = docker.from_env()
self.image = image
def run_command(self, command: str, timeout: int = 300) -> tuple[str, str, int]:
"""在Docker容器中运行命令"""
container = self.client.containers.run(
self.image,
command=f"/bin/bash -c '{command}'",
detach=True,
remove=False,
mem_limit="512m", # 限制内存
cpu_quota=50000, # 限制CPU
)
result = container.wait(timeout=timeout)
stdout = container.logs(stdout=True, stderr=False).decode()
stderr = container.logs(stdout=False, stderr=True).decode()
container.remove()
return stdout, stderr, result["StatusCode"]
然后特定工具方法就很简单了:
def run_subfinder(self, domain: str) -> list[str]:
"""运行Subfinder枚举子域名"""
stdout, _, _ = self.run_command(f"subfinder -d {domain} -silent")
return [line.strip() for line in stdout.split("\n") if line.strip()]
def run_whatweb(self, url: str) -> dict:
"""运行WhatWeb识别技术"""
stdout, _, _ = self.run_command(f"whatweb '{url}' --log-json=/dev/stdout")
return self._parse_whatweb_output(stdout)
为LangGraph定义工具
LangGraph代理需要以特定方式定义工具。我们使用LangChain的@tool装饰器,用Pydantic模型定义结构化输出:
# tools/subdomain_tools.py
from langchain_core.tools import tool
from pydantic import BaseModel, Field
class SubdomainResult(BaseModel):
domain: str
subdomains: list[str]
count: int
@tool
def enumerate_subdomains(domain: str) -> SubdomainResult:
"""
使用Subfinder(在Docker中运行)枚举子域名。
使用证书透明度、DNS数据集和网络档案。
"""
runner = get_docker_runner()
subdomains = runner.run_subfinder(domain)
return SubdomainResult(
domain=domain,
subdomains=sorted(set(subdomains)),
count=len(subdomains)
)
文档字符串很重要,大模型决定是否使用这个工具时会看它。要具体说明工具做什么、返回什么。
共享状态
所有代理共享一个在图中传递的公共状态。这样一个代理的发现就能被下一个代理使用:
# agents/state.py
from typing import TypedDict, Annotated
from langgraph.graph.message import add_messages
class OSINTState(TypedDict):
# 目标
target: str
# 大模型对话历史
messages: Annotated[list, add_messages]
# 发现(由每个代理填充)
subdomains: list[str]
shodan_hosts: list[dict]
technologies: list[dict]
# 工作流控制
completed_phases: list[str]
# 输出
report: str
Annotated[list, add_messages]告诉LangGraph当多个节点更新消息列表时如何合并,它会追加而不是替换。
创建专业代理
每个代理都使用LangGraph的create_react_agent辅助函数创建。关键是系统提示词,它塑造代理的推理方式:
# agents/recon_agent.py
from langgraph.prebuilt import create_react_agent
def create_recon_agent():
llm = ChatOpenAI(model="gpt-4o", temperature=0)
system_prompt = """你是一名侦察专家。
你的任务是发现目标域名的子域名。
指令:
1. 使用enumerate_subdomains查找子域名
2. 寻找有趣的模式:
- 管理面板(admin., manage., administrator.)
- 开发环境(dev., staging., test.)
- API(api., graphql.)
3. 总结你的发现
这是被动侦察 - 我们不直接接触目标。"""
return create_react_agent(
model=llm,
tools=[enumerate_subdomains],
state_modifier=system_prompt
)
Shodan和指纹代理遵循相同模式,只是工具和提示词针对各自专业定制。
协调器:把一切连接起来
协调器是整个系统的大脑。它是一个LangGraph StateGraph,决定下一个运行哪个代理:
# agents/coordinator.py
from langgraph.graph import StateGraph, START, END
from langgraph.types import Command
def create_coordinator():
recon_agent = create_recon_agent()
shodan_agent = create_shodan_agent()
fingerprint_agent = create_fingerprint_agent()
def supervisor_node(state: OSINTState) -> Command:
"""决定下一个应该行动的代理"""
completed = state.get("completed_phases", [])
if "recon" not in completed:
return Command(goto="recon_node")
elif "shodan" not in completed:
return Command(goto="shodan_node")
elif "fingerprint" not in completed:
return Command(goto="fingerprint_node")
else:
return Command(goto="report_node")
def recon_node(state: OSINTState) -> dict:
"""运行子域名枚举"""
result = recon_agent.invoke({
"messages": [("user", f"Find subdomains for: {state['target']}")]
})
# 从工具结果中提取子域名
subdomains = parse_subdomains_from_messages(result["messages"])
return {
"subdomains": subdomains,
"completed_phases": state.get("completed_phases", []) + ["recon"]
}
# shodan_node、fingerprint_node、report_node的类似节点...
# 构建图
builder = StateGraph(OSINTState)
builder.add_node("supervisor", supervisor_node)
builder.add_node("recon_node", recon_node)
builder.add_node("shodan_node", shodan_node)
builder.add_node("fingerprint_node", fingerprint_node)
builder.add_node("report_node", report_node)
builder.add_edge(START, "supervisor")
builder.add_edge("recon_node", "supervisor")
builder.add_edge("shodan_node", "supervisor")
builder.add_edge("fingerprint_node", "supervisor")
builder.add_edge("report_node", END)
return builder.compile()
流程是这样的:
START → supervisor → recon_node → supervisor → shodan_node → supervisor → fingerprint_node → supervisor → report_node → END
运行调查
# main.py
def run_osint_investigation(target: str):
coordinator = create_coordinator()
initial_state = {
"target": target,
"messages": [],
"subdomains": [],
"shodan_hosts": [],
"technologies": [],
"completed_phases": [],
"report": ""
}
# 流式查看进度
for event in coordinator.stream(initial_state):
for node_name, output in event.items():
print(f"[+] 完成: {node_name}")
final_state = coordinator.invoke(initial_state)
return final_state["report"]
关键收获
这里的多代理模式很直接:
- 状态 保存所有发现,在节点间传递
- 专业代理 专注于一项任务,使用一组工具
- 监督者 协调工作流,根据已完成的工作路由到代理
- Docker 隔离使侦察工具保持独立和可重现
当前架构扩展性很好,添加新功能(如nuclei扫描)只需:
- 创建包装Docker命令的新工具
- 创建带该工具的新代理
- 在协调器中添加节点
- 添加回监督者的边
为什么用AI?真正的力量在于动态决策
看了我们构建的东西,你可能会想:“这只是线性工作流 — 侦察,然后Shodan,然后指纹识别。我完全可以用简单的Python脚本构建这个,根本不用AI。”
你说得对。对于这个基础版本,硬编码的管道确实可行。
但有趣的是,当工作流不再是线性的时,AI代理的真正力量就显现了 — 当下一步取决于我们刚刚发现的东西时。
想象这个场景:代理在目标上发现开放的8080端口。它探测服务,识别出是Apache Tomcat 9.0.30。现在,智能代理可以:
- 识别 这是一个过时的Tomcat版本,有已知漏洞
- 搜索 Tomcat 9.0.30特有的CVE和默认凭据
- 截图 管理界面,检查
/manager/html是否暴露 - 尝试 默认凭据组合(
tomcat:tomcat,admin:admin) - 如果成功,转向枚举部署的应用
- 如果失败,尝试已知漏洞如Ghostcat(CVE-2020-1938)
这种分支、上下文感知的决策是简单脚本做不到的,却是AI的强项。大模型作为"大脑"实时评估发现,决定最佳前进路径,就像人类渗透测试员一样。
用LangGraph,添加这种智能很简单:更多节点、更多工具,以及让监督者根据代理发现路由的条件边。我们这里构建的架构是基础,同样的模式可以扩展到更复杂的自主评估。
下一步
- 添加人工干预:主动扫描前请求批准
- 添加更多工具/节点:集成Nuclei进行漏洞扫描
- 添加PostgreSQL检查点持久化,供团队使用
- 用Streamlit构建简单的Web界面
评论区互动
我整理了文中提到的所有工具的安装和使用指南,评论区回复「安全工具」,我直接发你完整教程。
你觉得AI代理会在网络安全领域取代人工分析师吗?评论区留下你的看法,咱们好好聊聊。
关注引导
这里是【AI拉呱】,只聊看得懂的AI干货。不想被时代落下?点个关注,咱们这圈子见。
AI时代,信息差就是入场券。关注我,每天为你拆解全球最硬核AI资讯,转发给你的好哥们,一起变强!
AI拉呱-洞察AI前沿
你的文章篇篇是爆款

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)