RDT2:探索UMI数据在零样本跨具身泛化中的扩展极限
26年2月来自清华的论文“RDT2: Exploring the Scaling Limit of UMI Data Towards Zero-Shot Cross-Embodiment Generalization”。视觉-语言-动作 (VLA) 模型在通用机器人领域展现出巨大潜力,但目前仍面临数据匮乏、架构效率低下以及无法跨不同硬件平台泛化等问题。RDT2,是一个基于 70 亿参数 VLM 的
26年2月来自清华的论文“RDT2: Exploring the Scaling Limit of UMI Data Towards Zero-Shot Cross-Embodiment Generalization”。
视觉-语言-动作 (VLA) 模型在通用机器人领域展现出巨大潜力,但目前仍面临数据匮乏、架构效率低下以及无法跨不同硬件平台泛化等问题。RDT2,是一个基于 70 亿参数 VLM 的机器人基础模型,旨在支持在新型机器人上进行零样本部署,以完成开放词汇任务。为了实现这一目标,用增强型、与机器人本体无关的通用操作接口 (UMI) 设备收集开源机器人数据集——涵盖不同机器人系列的超过 10,000 小时的演示数据。本文方法采用一种三阶段训练方案,通过残差矢量量化 (RVQ)、流匹配(FM)和蒸馏技术,将离散的语言知识与连续的控制相结合,从而实现实时推理。因此,RDT2能够同时对未见过的物体、场景、指令乃至机器人平台进行零样本泛化。此外,它在灵巧性强、视野范围长且动态的下游任务(例如打乒乓球)中也优于最先进的基线模型。
机器人数据金字塔。机器人学习的数据格局可以被概念化为一个金字塔(Bjorck,2025)。金字塔顶端是远程操作数据,这些数据通过虚拟现实(VR)(Khazatsky,2024;Cheng,2024;Chen,2025a)或主从机械臂(Zhao,2023;Fu,2024;Aldaco,2024)等系统收集,具有最高的保真度,但获取成本也最高。其数据采集通常局限于结构化的实验室环境(Walke et al., 2023; Fang et al., 2023; Khazatsky et al., 2024; O’Neill et al., 2024; Wu et al., 2024),导致训练数据与实际应用之间存在分布上的差距。处于中间位置的是仿真数据(Wang et al., 2023; Li et al., 2023; Mu et al., 2024; Chen et al., 2025b);它成本低廉且可扩展,但存在显著的仿真与实际应用之间的差距,如何生成多样化、交互式和逼真的场景仍然是一个尚未解决的问题(Nasiriany et al., 2024; Ren et al., 2024; Zhang et al., 2025)。其基础是庞大的互联网视频库(Ye et al., 2024; Yang et al., 2025; Luo et al., 2025; Feng et al., 2025)。尽管数据量丰富,但这些数据结构混乱且噪声较大,最重要的是,缺乏监督策略训练所需的明确动作标签(McCarthy et al., 2025)。
在自然语言处理和计算机视觉领域,已有充分研究表明,增加数据集的规模和多样性可以提高模型的泛化能力(Kaplan et al., 2020; Zhai et al., 2022)。然而,目前将这一原则应用于远程操控机器人领域尚不切实际。机器人硬件的高昂成本使得并行数据采集,进而大规模数据收集,变得极其昂贵。此外,这些系统缺乏便携性,导致数据采集主要局限于实验室或工厂环境,严重限制所采集数据的多样性和实际应用价值。硬件异构性加剧数据匮乏的问题,因为在一个机器人平台上采集的数据通常与其他平台不兼容,从而形成孤立且无法互操作的数据集。
根据先前的研究(Chen et al., 2022; Chi et al., 2023),人类数据展现出显著的多模态性,因此需要学习动作分布而非确定性映射的模型。这就需要在离散和连续动作表示之间做出选择,二者各有优缺点。离散方法与预训练的虚拟逻辑模型(VLM)的概率输出自然契合,但存在量化误差和自回归采样效率低下的问题。相反,扩散模型等连续方法虽然采样效率更高,但训练收敛速度较慢(Pertsch et al., 2025),并且存在破坏VLM内部离散知识的风险(Deng et al., 2025)。因此,一个关键的挑战是如何综合两种范式的优势。此外,机器人任务对实时性能的要求使得大规模VLA的有效部署成为一个巨大的障碍。
本文RDT2是一个用于机器人零样本部署的基础模型之一,能够处理开放词汇任务。RDT2基于预训练的7B级向量学习模型Qwen2.5-VL(Bai,2025)构建,并配备专门的动作头和三阶段训练策略,用于从大规模机器人数据中学习。为了快速收敛,在第一阶段,用残差向量量化(RVQ)(Van Den Oord,2017;Esser,2021;Lee,2022)将连续的机器人动作编码为离散的tokens,然后通过最小化交叉熵损失来训练VLM。这也能避免在预训练过程中破坏以离散概率形式存储的知识。在第二阶段,为了提高表达能力和效率,采用动作专家模型来建模连续概率,并使用流匹配损失对其进行训练。在第三阶段,提出一种简单而有效的蒸馏损失,并将动作专家模型蒸馏成一个单步生成器,从而实现了超快的推理速度。
为了应对数据规模挑战,采用 UMI(Chi,2024),这是一个可移植的框架,能够实现可扩展的、实际环境中的数据采集。UMI 使用带有视觉和跟踪器的手持设备记录 6 自由度末端执行器的姿态和夹爪的宽度。当安装物理特性一致的夹爪时,从 UMI 数据中学习的策略可以部署到不同的机械臂上,因为视觉和结构上的差异在不同装置之间被最小化。如图展示从设计到部署的 UMI 解决方案。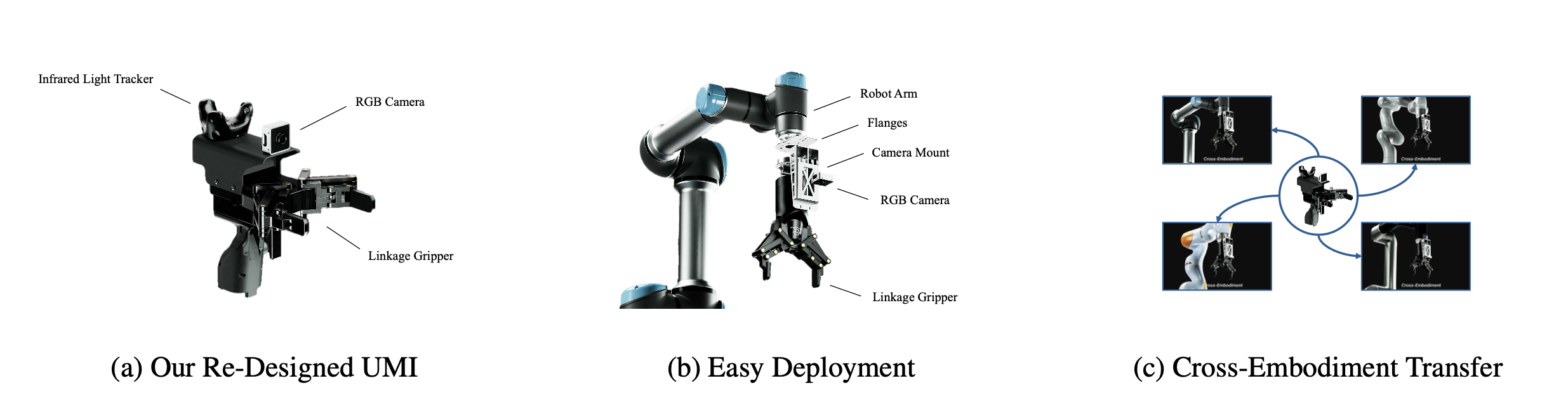
UMI 的重新设计。然而,原始的 UMI 硬件缺乏大规模实际环境数据采集所需的可靠性。为了解决这个问题,对整个系统进行重新设计(图 a),以最大限度地提高结构刚度,确保无漂移的红外跟踪,并增强在复杂环境中的操作灵活性。如表所示。 这些改进解决关键的姿态不一致和可达性限制问题,显著提高数据保真度。
如图所示数据采集和部署的硬件配置:
大规模 UMI 数据集。得益于这些硬件进步,我整理迄今为止最大的开源 UMI 数据集之一,包含超过 10,000 小时的操作数据,涵盖 100 多个家庭。数据集完全在自然环境中采集,涵盖广泛的非结构化环境和复杂的人类行为,为通用策略学习提供强大的基础。
如图所示:在家庭环境中,定义50多项任务,涵盖各种日常操作活动,例如拾取和放置、倾倒、擦拭、摇晃、搅拌和整理。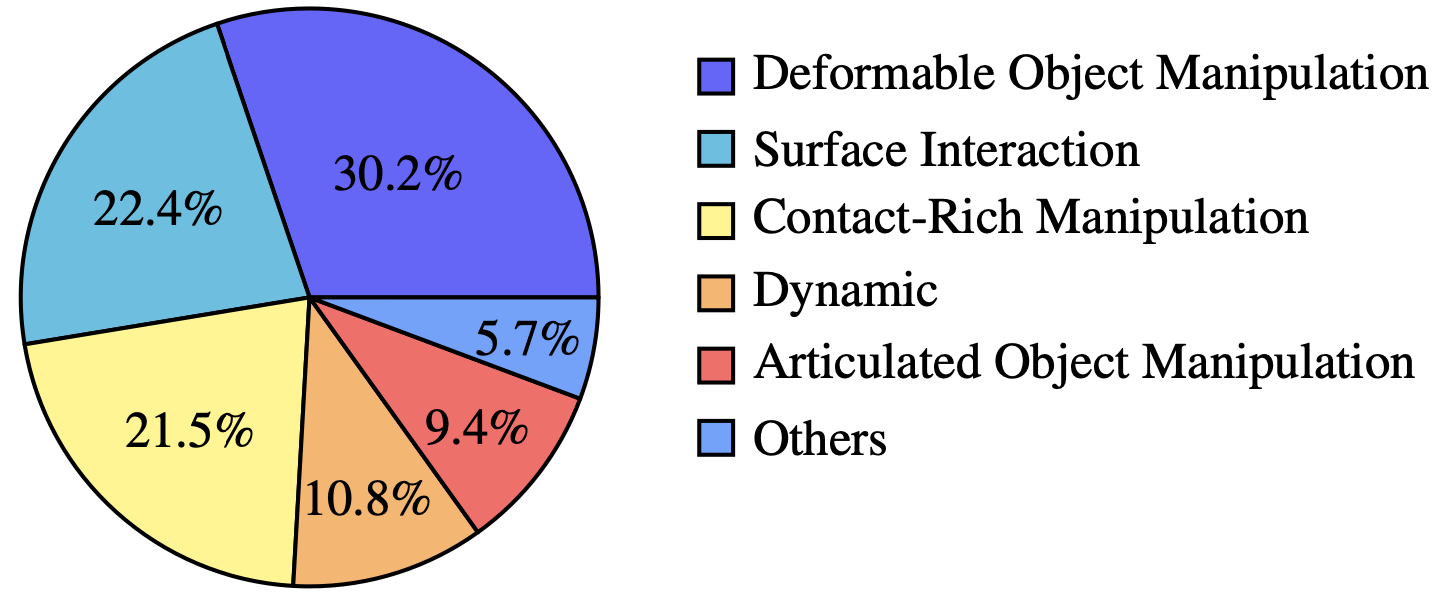
在每次记录过程中,数据收集员都会收到一份简要说明(如表所示),并使用家中常见的物品完成任务。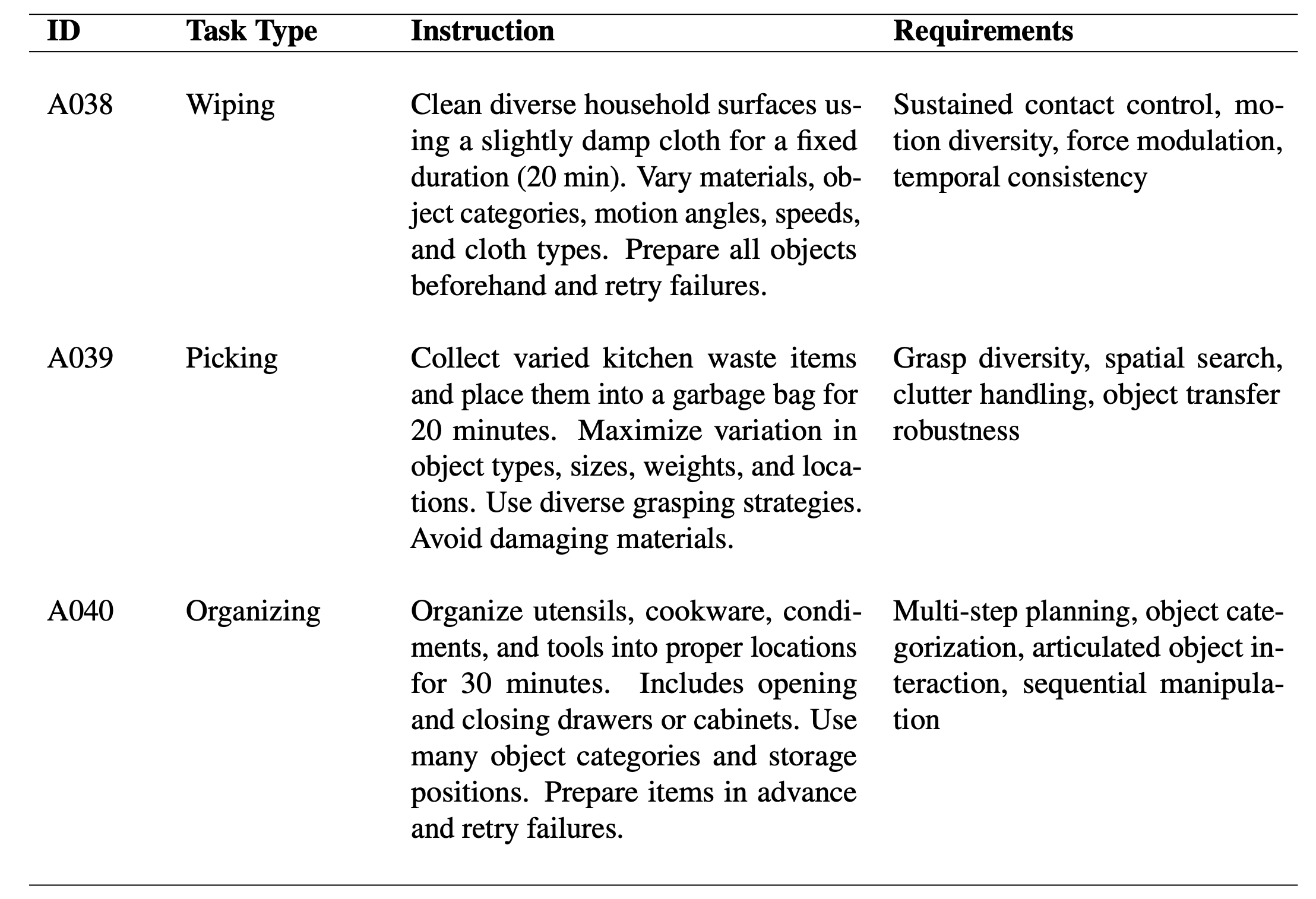
本文引入RDT2,这是一个VLA模型,其训练流程如图所示,分为三个阶段。在第一阶段用RVQ将连续动作空间离散化为tokens,并通过标准的交叉熵损失函数训练VLM骨干网络。随后,在第二阶段冻结VLM骨干网络,并训练一个基于扩散的动作专家,利用流匹配损失函数生成连续动作。这种混合方法结合离散化和扩散的优势,有效地解决建模多模态动作分布的挑战。最后,为了解决机器人任务的实时性难题,第三阶段将多步动作专家简化为一个高效的单步生成器,从而使大规模VLA模型能够快速推理。
第一阶段
如前所述,扩散模型在视觉语言动作(VLA)训练中存在两个主要问题:收敛速度慢以及预训练视觉语言模型(VLM)中离散概率知识的退化。为了缓解这些问题,选择在扩散训练之前,先使用交叉熵损失对VLM主干网络进行预训练,这与其原始训练目标一致。这有助于有效地保留模型宝贵的预训练知识,并使其受益于在训练过程中添加的视觉语言数据。实验证实,与从一开始就直接使用扩散损失进行训练相比,这种离散化的预训练阶段显著加快了VLA模型的收敛速度。
为了便于交叉熵训练,采用 RVQ(Van Den Oord,2017;Esser,2021;Lee,2022)进行离散化,因为它具有很高的压缩效率。
为了缓解臭名昭著的码本崩溃问题,在RVQ训练过程中采取多项措施,包括降低码本维度(Yu,2021)、用余弦相似度代替欧氏距离(Yu,2021)、通过指数移动平均(EMA)平滑码本更新(Razavi,2019)以及每隔固定周期重启不活跃的码本条目(Zeghidour,2021)。在相同的量化误差水平下,这样RVQ可以将动作块压缩成更少的tokens,从而显著加快大型VLA的收敛速度。
选择7B Qwen2.5-VL(Bai,2025)作为VLA骨干网,利用其在大规模视觉语言语料库上的广泛预训练。将各种模态投影到一个统一的潜空间进行学习:视觉和语言通过 Qwen 编码器进行投影,动作通过 RVQ 模型进行投影。保留词汇表中出现频率最低的 1024 个词条来表示这些动作tokens。VLA 模型在UMI 数据集和一小部分视觉-语言数据的复合数据集上进行了 12.8 万次迭代的训练,训练目标为下一个token预测。
第二阶段
为了提高推理效率,超越自回归模型,引入第二阶段的训练。在这一阶段,冻结第一阶段预训练的 VLA 主干模型,并训练一个专门的动作专家模型。该专家模型是RDT-1B(Liu,2024)的4亿参数变型,它通过将多头注意力机制(MHA)(Vaswani,2017)替换为分组查询注意机制(GQA)(Ainslie,2023)来优化速度。它通过扩散过程生成连续动作,该过程以冻结的VLA骨干网络编码的自然语言和图像表示为条件。具体而言,该动作专家利用交叉注意机制来融合VLA骨干网络每一层的潜特征。动作专家由流匹配损失(Lipman,2022)监督。
此外,由于模型主干 VLA(·) 在积分过程中保持不变,仅计算一次。在实验中,随机初始化动作专家,并在 UMI 数据集上对其进行 66K 次迭代训练,同时冻结 VLA 骨干网络(在第一阶段训练)。
第三阶段
动作生成过程需要对每个动作块进行五次连续的前向传播,这会带来相当大的推理开销。这种延迟对于动态性要求高的任务(例如乒乓球)来说是一个实际的瓶颈。为了克服这一限制,采用扩散蒸馏(Salimans & Ho, 2022; Chen et al., 2023)将第二阶段中训练的专家策略转换为单步生成器。技术显著降低模型延迟,使大规模 VLA 能够实现比规模小得多的模型快得多的推理速度。
扩散蒸馏。对于高动态性任务,用定义的回归目标,将动作专家蒸馏为具有参数 θ′ 的单步生成器。参数θ 已在第二阶段预训练并在此阶段保持不变,模型主干VLA(·) 也保持不变,而 θ′ 可训练,其初始值由 θ 初始化。与以往的蒸馏方法不同,生成过程 F(·) 在训练过程中实时计算,而不是在数据准备阶段预生成。这种方法在可接受的计算开销下具有显著优势。生成低维动作非常高效(只需几个集成步骤),生成低维动作非常高效(只需几个集成步骤),这与需要数百个步骤的图像或视频生成形成鲜明对比。同时,它还显著降低蒸馏策略过拟合预生成数据的风险,而过拟合是基于回归的蒸馏方法中常见的陷阱。
训练详情如下。
平台和数据管道
用 PyTorch(链接至 PyTorch 代码库)和 DeepSpeed(链接至 DeepSpeed 代码库)来实现训练框架,以支持高效的分布式训练。基础设施的核心组件是使用高吞吐量的 WebDataset(链接至 WebDataset 代码库)流式传输。将所有数据集转换为 POSIX tar 分片,并利用重采样模式,从而实现无周期限制的无限数据流传输。训练过程中,用 wds.RandomMix 动态混合来自异构数据源的数据,从而可以实时调整不同数据集的采样权重。
第一阶段:VQ 预训练
在第一阶段,将 Qwen2.5-VL 骨干网络与机器人领域进行对齐。该模型使用标准的交叉熵目标函数进行训练,以预测离散化的动作token。
为了确保稳健的视觉表示,应用一套全面的图像增强技术。利用标准的颜色抖动(亮度、对比度、饱和度、色调)以及一系列随机图像损坏,包括高斯/拉普拉斯噪声注入、运动模糊和JPEG压缩伪影。
训练过程中,采用余弦学习率调度器,并在最后8000次迭代中采用指数衰减进行退火处理。
第二阶段:连续动作专家
在第二阶段,冻结VQA骨干网络,并使用条件流匹配(CFM)优化RDT动作专家。
训练配置。在训练过程中,用Logistic正态分布(μ = 0,σ = 1)而非均匀分布对时间步长t进行采样。这在经验上将训练资源集中在流轨迹中最复杂的区域(t ≈ 0.5)。为了监控收敛情况,每2500步使用完整的多步积分在预留的验证集上评估模型。报告动作均方误差 (MSE)、末端执行器位置均方误差 (MSE)、旋转测地线误差和夹爪宽度均方误差 (MSE),并基于聚合验证误差选择检查点。
第三阶段:单步蒸馏
为了实现高频推理,将第二阶段的策略蒸馏为一个单步生成器。将第二阶段的模型冻结为教师模型,并训练一个学生模型副本,使其在一次前向传播中回归教师模型的多步输出。学生模型以 t = 0 为条件,并最小化其预测速度与教师模型有效轨迹之间的均方误差 (MSE)。
实现细节。
将 RDT2 与两个基线模型进行比较:π0.5 和 π0-FAST(Black ,2024;Pertsch ,2025;Intelligence ,2025)。用官方 OpenPI 代码库实现这两个基线模型(OpenPI 代码库链接)。为了确保公平比较,没有修改架构,仅修改配置文件和检查点路径。
对于 π0.5,用标准的基于流公式。在配备 8 个 GPU 的单个节点上训练该模型 20,000 步,每个 GPU 的批大小为 32。配置遵循官方 π0.5 设置,采用离散状态输入、24 维动作范围和 32 维动作空间。用 Gemma-300M 权重初始化动作专家,并使用 Gemma-2B 初始化语言骨干。训练使用 bfloat16 精度、AdamW 优化器和 1.0 的梯度裁剪。
对于 π0-FAST,按照标准的 FAST 流程,使用与策略相同的 RVQ 动作数据集训练 FAST token化器。训练完成后,固定token化器并将其用于策略训练。在配备 8 个 GPU 的单个节点上训练策略 30,000 步,每个 GPU 的批大小为 32。其他优化器和调度器设置与 π0.5 相同。对每个基线模型进行训练,直至每个任务稳定收敛。
零样本配置。在零样本实验中,直接评估预训练模型在未见过的任务上的泛化能力,无需任何后续更新。用从第一阶段(RDT2-VQ 变体,在 UMI 数据集上训练 12.8 万步)或第二阶段(RDT2-FM 变体,动作专家模型,在 UMI 数据集上训练 6.6 万步)获得的模型权重,这些权重均仅在大规模 UMI 数据集上训练。此设置不涉及任何特定任务的数据,因此可以仅基于模型的预训练知识来评估其处理新指令、对象和场景的能力。
微调配置。所有微调实验均从第一阶段的检查点初始化,该检查点在 UMI 数据集上预训练了 12.8 万步。视觉语言骨干网络保持不变。考虑了两个变型:RDT2-FM 和 RDT2-UltraFast。针对每个下游任务分别对这两个变型进行微调。
• RDT2-FM:用流匹配目标函数对该变型进行微调。在配备 8 个 GPU 的单节点上训练 5 万步,全局批大小为 96。超参数与第二阶段训练一致。
• RDT2-UltraFast:为了获得该变型,首先使用微调后的 RDT2-FM 模型。然后,执行一致性蒸馏,将其转换为单步生成器。蒸馏持续 2 万步,使用相同的硬件(1 个节点,8 个 GPU)和批大小(96)。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 39
39 0
0- 0



 已为社区贡献211条内容
已为社区贡献211条内容

所有评论(0)