机械臂的强化学习驯服指南:从二维画圈到三维群舞
这时候就需要祭出分层强化学习大法,让某些智能体专门负责避障,其他的专注走位。在机器人实验室里,我经常看到机械臂像喝醉的水蛇一样乱扭——这就是传统控制方法的真实写照。别担心,用强化学习调教机械臂其实比驯服哈士奇简单,MATLAB就是我们最好的狗绳。主要内容:采用MATLAB模拟机械臂并使用强化学习控制机械臂到达目标点。主要内容:采用MATLAB模拟机械臂并使用强化学习控制机械臂到达目标点。关键词:n
MATLAB代码:n阶机械臂单、多智能体控制 关键词:n阶机械臂单 多智能体 单智能体 参考文档: 1.《Proximal Policy Optimization Algorithms》 2.《Asynchronous Methods for Deep Reinforcement Learning》 3.《High-Dimensional Continuous Control Using Generalized Advantage Estimation》 仿真平台:MATLAB、SIMULINK 主要内容:采用MATLAB模拟机械臂并使用强化学习控制机械臂到达目标点。 现成代码是二维的,需要三维需定制。
在机器人实验室里,我经常看到机械臂像喝醉的水蛇一样乱扭——这就是传统控制方法的真实写照。别担心,用强化学习调教机械臂其实比驯服哈士奇简单,MATLAB就是我们最好的狗绳。
1. 先给机械臂造个虚拟肉身
用Robotics Toolbox捏个机械臂模型,比乐高积木还简单:
robot = rigidBodyTree;
% 假装是6轴机械臂
for i = 1:6
joint = rigidBodyJoint(['jnt' num2str(i)], 'revolute');
link = rigidBody(['link' num2str(i)]);
setFixedTransform(joint, trvec2tform([0,0,0.3*(i-1)]));
link.Joint = joint;
addBody(robot, link, ['link' num2str(i-1)]);
end
show(robot); % 现在你能看到机械臂在摆pose了这个会扭腰的金属架子,就是我们强化学习的主战场。不过要注意关节限位——别让AI把机械臂拧成麻花。
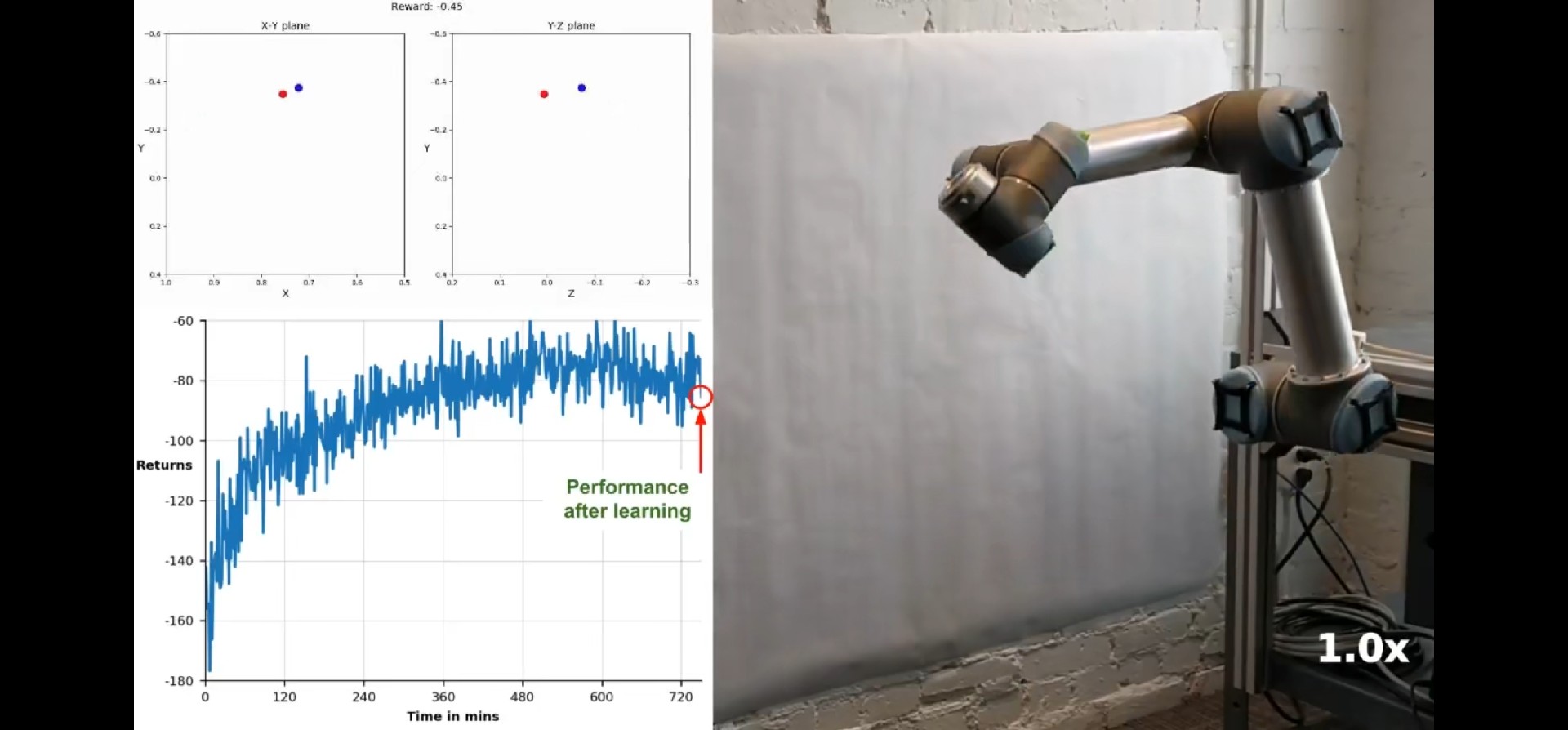
2. 强化学习健身房开张
搭建训练环境才是重头戏,这个类要处理所有物理逻辑:
classdef RobotEnv < rl.env.MATLABEnvironment
properties
TargetPosition = [0.5, 0.5, 0.5]; % 目标点坐标
MaxTorque = 10; % 关节最大扭矩
end
methods
function obs = getObservation(this)
% 获取关节角度、末端坐标等状态信息
jointAngles = getJointPositions(robot);
endPos = getEndPosition(robot);
obs = [jointAngles, endPos];
end
function [reward, done] = step(this, action)
% 执行动作并计算奖励
applyTorque(robot, action); % 施加关节力矩
endPos = getEndPosition(robot);
distance = norm(endPos - this.TargetPosition);
reward = 10/(1 + distance) - 0.1*norm(action);
done = distance < 0.05 || any(abs(action) > this.MaxTorque);
end
end
end奖励函数设计是门玄学——距离奖励占大头,动作惩罚防抽搐。建议多备点咖啡,你会需要反复调整这些参数。
3. 训练智能体的秘密配方
MATLAB代码:n阶机械臂单、多智能体控制 关键词:n阶机械臂单 多智能体 单智能体 参考文档: 1.《Proximal Policy Optimization Algorithms》 2.《Asynchronous Methods for Deep Reinforcement Learning》 3.《High-Dimensional Continuous Control Using Generalized Advantage Estimation》 仿真平台:MATLAB、SIMULINK 主要内容:采用MATLAB模拟机械臂并使用强化学习控制机械臂到达目标点。 现成代码是二维的,需要三维需定制。
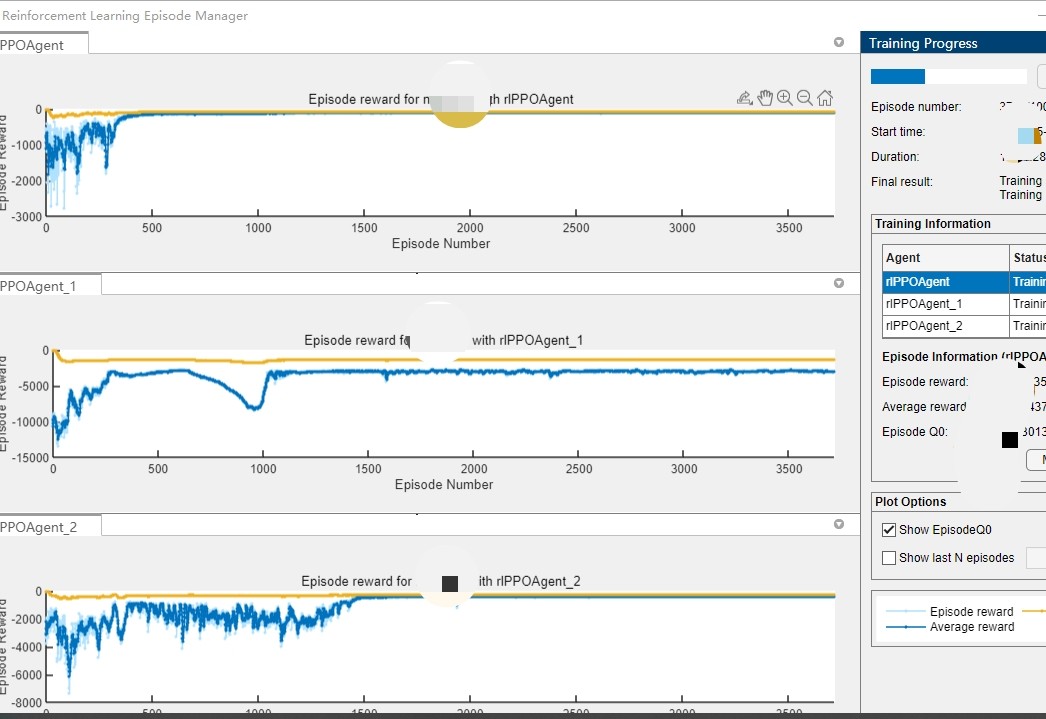
PPO算法配置才是真正的技术活:
actorNet = [
featureInputLayer(12) % 6关节角度+6末端坐标
fullyConnectedLayer(64)
reluLayer
fullyConnectedLayer(6) % 输出6个关节力矩
];
criticNet = [
featureInputLayer(12)
fullyConnectedLayer(128)
reluLayer
fullyConnectedLayer(1)
];
agentOpts = rlPPOAgentOptions(...
'ExperienceHorizon', 512,...
'ClipFactor', 0.2,...
'EntropyLossWeight', 0.01);
agent = rlPPOAgent(actorNet, criticNet, agentOpts);网络结构不要搞太复杂,三明治结构够用了。注意学习率要设成动态调整的,建议用Adam优化器保平安。
4. 当机械臂开始群魔乱舞
多智能体版本其实就是在玩排列组合:
multiEnv = MultiRobotEnv([env1, env2, env3]); % 三个机械臂环境
agents = [agent1, agent2, agent3];
% 重点在于设计协同奖励
function teamReward = calculateTeamReward(individualRewards)
% 既要自己表现好,又要不挡队友路
teamReward = sum(individualRewards) - collisionPenalty;
end共享观测数据时要小心信息过载,建议每个智能体只关注自己周围3米范围的状态。
5. 升维作战的生存法则

从二维升级三维不是简单的坐标扩展:
% 原二维观测空间
observationInfo = rlNumericSpec([6 1]);
% 三维版本需要增加z轴坐标
observationInfo3D = rlNumericSpec([12 1]); % 6关节+XYZ位置+XYZ姿态
% 动作空间也要增加俯仰自由度
actionInfo3D = rlNumericSpec([6 1], 'LowerLimit',-10,'UpperLimit',10);动力学模型要重新校核,建议先用Simulink做碰撞检测。重力补偿别忘了z轴分量,否则机械臂会像断了线的木偶。
当第一个机械臂颤颤巍巍碰到目标点时,你会感受到老父亲般的欣慰。不过别高兴太早——真正的挑战是如何让三个机械臂在三维空间里跳集体舞还不打结。这时候就需要祭出分层强化学习大法,让某些智能体专门负责避障,其他的专注走位。记住,调参就像熬中药,文火慢炖才能出效果。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)