Bench-Push:移动机器人基于推力的导航和操作任务基准测试
25年12月来自Georgia Tech、加拿大 Waterloo大学和Alberta大学的论文“Bench-Push: Benchmarking Pushing-based Navigation and Manipulation Tasks for Mobile Robots”。移动机器人越来越多地部署在包含可移动物体的杂乱环境中,这给传统的交互方式带来挑战,因为传统方法无法实现交互。在这种情况
25年12月来自Georgia Tech、加拿大 Waterloo大学和Alberta大学的论文“Bench-Push: Benchmarking Pushing-based Navigation and Manipulation Tasks for Mobile Robots”。
移动机器人越来越多地部署在包含可移动物体的杂乱环境中,这给传统的交互方式带来挑战,因为传统方法无法实现交互。在这种情况下,移动机器人必须超越传统的避障方式,利用推或轻推策略来完成目标。虽然基于推的机器人技术研究正在蓬勃发展,但评估方法依赖于临时搭建的测试环境,这限制结果的可重复性和交叉比较。为了解决这个问题,Bench-Push是一个用于评估基于推的移动机器人导航和操作任务统一基准测试平台。Bench-Push 包含多个组件:1)一系列全面的模拟环境,涵盖基于推的任务中基本挑战,包括在带有可移动障碍物的迷宫中导航、在冰封水域中进行自主船舶导航、运送箱子和清理区域等,每个任务的复杂程度各不相同;2)用于评估效率、交互工作量和任务完成情况的新型评估指标;以及 3)使用 Bench-Push 在不同环境下评估现有基线示例实现的演示。
Bench-Push 将以模块化设计的 Python 库的形式开源。
Bench-Push 由三个主要部分组成:(i) 环境,(ii) 策略,以及 (iii) 评估指标。
环境:环境是指机器人智体存在的模拟世界,它与 Gymnasium [24] 界面集成。每个环境都通过 MuJoCo [10] 进行 3D 模拟,并通过 Pymunk [11] 进行 2D 模拟,并且具有多种复杂度递增的变型(如图所示)。环境可以独立于训练会话运行,并且用户可以手动操作机器人。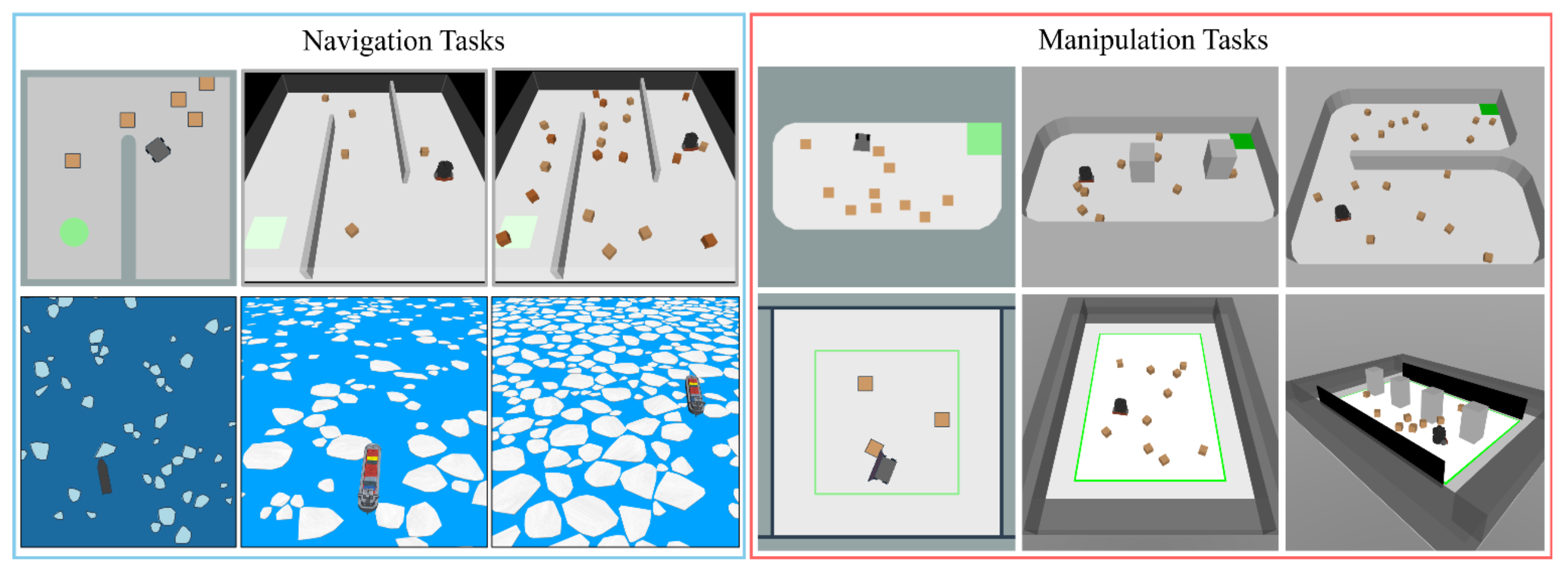
任务:将任务定义为机器人在给定环境中的目标。具体来说,考虑两种类型的任务:
• 导航任务:机器人必须到达目标区域,同时不可避免地会遇到阻碍路径的障碍物。
• 操作任务:机器人必须将环境中的物体推到所需的位置。
策略:策略是一组用于控制机器人在特定环境中运行的规则。它以环境观测数据作为输入,并输出机器人动作。在 Bench-Push 中,提供几个基准策略作为用户的参考实现,这些策略列于下表中。
指标:指标是用于评估策略在给定环境中完成任务的有效性的分数。
Bench-Push环境
机器人智体的动作、观察结果和奖励,如表所示。
- 带有可移动障碍物的迷宫导航(迷宫):
现有的基于推式导航的研究通常采用类似迷宫的环境,这些环境具有封闭的矩形空间和墙壁 [17]、[6]、[4]。这些环境模拟许多真实世界室内场景的常见结构布局,例如办公室和医院。受此启发,引入迷宫环境,该环境具有静态迷宫结构,障碍物随机初始化。移动机器人智体是 TurtleBot3 Burger,其任务是从起始位置导航到目标位置,同时最小化路径长度和障碍物碰撞次数。环境的变化包括不同的迷宫结构、障碍物大小、位置和密度。
该环境中的机器人被配置为以恒定的前进速度移动,并从策略中接收角速度作为动作输入。在每个时间步,机器人进行局部自我中心观测,该观测包含四个通道,分别对应于:(i) 静态障碍物占用情况,(ii) 可移动障碍物占用情况,(iii) 机器人足迹,以及 (iv) 源自目标的距离变换 (DT)(目标 DT)。如图显示一个观测示例。机器人因靠近目标而获得奖励,因与障碍物碰撞而受到惩罚,并在到达目标时获得最终奖励。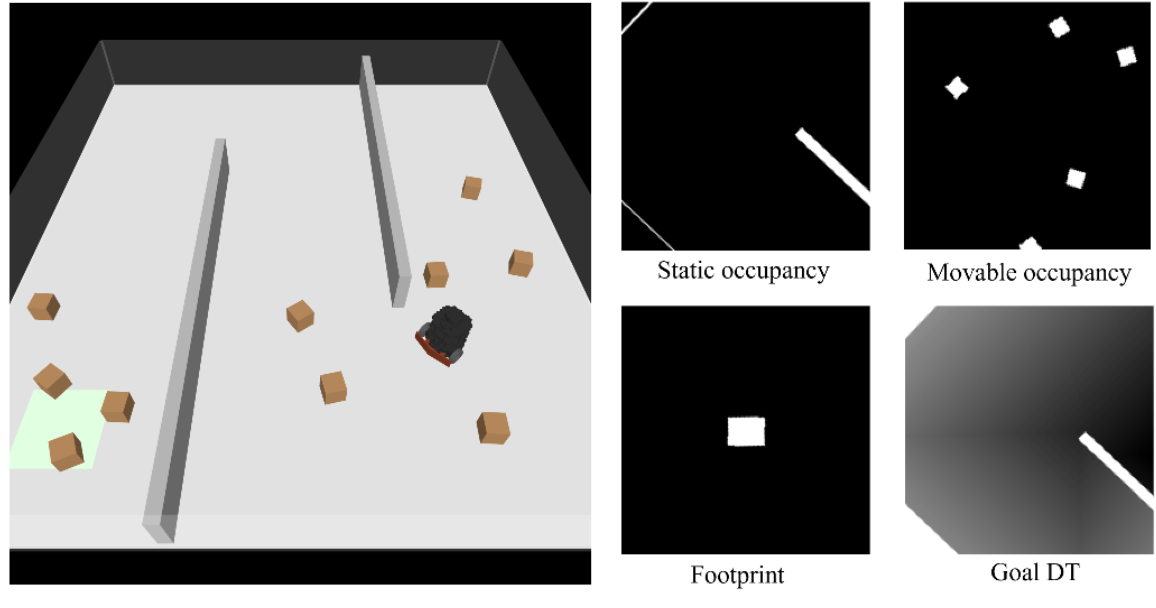
2) 冰水环境下的自主船舶导航(Ship-Ice):
为了确保更广泛的适用性,将模型从以迷宫(Maze)为代表的结构化室内环境扩展到实际的机器人场景。近期研究的一个显著例子是自主水面航行器(ASV)在冰封水域中的导航[14][15]。该领域面临着与迷宫不同的挑战,例如不规则障碍物、密集聚集和流体动力学等。因此,引入Ship-Ice环境,该环境模拟一艘自主船舶在冰封水道中航行的情况。船舶的任务是在尽量减少与水道中破碎浮冰碰撞的同时,到达前方的水平目标线[14]。这些浮冰是凸多边形,冰浓度在0%到50%之间变化。
Ship-Ice模型能够以真实世界的比例模拟船舶导航。采用海洋研究专家预生成的冰场,同时也允许用户即时生成冰场。由于MuJoCo本身不支持流体动力学,用作用于所有物体的线性和二次阻力组合,在xy平面上近似模拟冰场。船舶尺寸、质量、阻力系数和冰块大小等相关参数均基于[14]。
与迷宫环境类似,船舶以恒定的前进速度运动,并接收角速度作为动作输入。船舶的观测方式与迷宫类似,但增加一个通道,该通道将船舶的航向编码为一条单像素宽的线。该通道有助于船舶围绕浮冰群进行精细化移动。船舶的奖励函数结合与浮冰碰撞的惩罚、鼓励接近目标线的航向奖励以及到达目标的终点奖励。
- 将箱子运送到容器(箱子-运送):
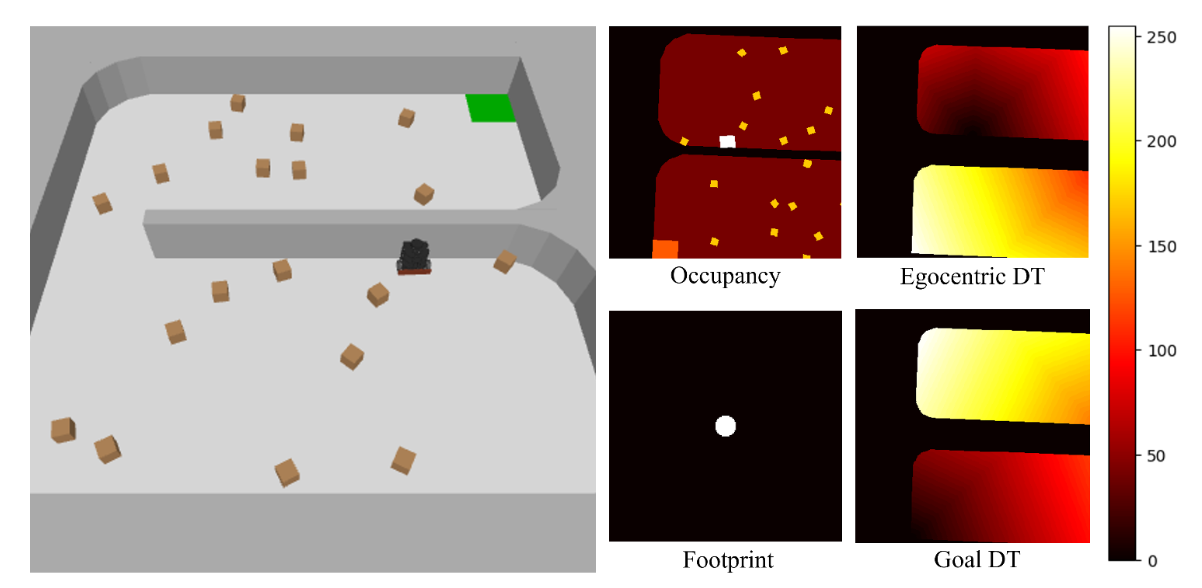
现有的基于推力的操作主要集中于两种策略:一是推力动作的接触级控制[18][19],二是将所有物体移动到目标位置的任务级策略[5][20],还有一些方法介于两者之间[26]。所有这些方法的共同点在于要求机器人将物体沿期望的方向或轨迹推向目标。受此启发,在此引入箱子-运送。箱子-运送环境由一组可移动的箱子和一个指定的容器组成。与迷宫任务类似,机器人智体是TurtleBot3 Burger。机器人的任务是使用非抓取式机械臂(例如,前保险杠)将所有箱子运送到容器中。箱子和机器人的起始位置在环境中随机生成。通过添加静态障碍物(例如柱子)以及改变可移动体的数量和大小,可以实现更多变化。
每一步,机器人都会接收一个方向作为其动作输入,并沿该方向行进一段固定距离。机器人的观察以自身为中心,包括:(i) 环境中静态和可移动物体的占用情况(以不同值编码);(ii) 机器人的占地面积;(iii) 来自机器人的决策时间(自我中心决策时间);以及 (iv) 来自目标容器的决策时间(目标决策时间)。如图展示环境和相应的机器人观察。机器人需要将可移动体(棕色箱子)推向目标容器(浅绿色方块)。机器人将箱子推向目标容器或成功运送箱子会获得奖励,而与静态障碍物碰撞或将箱子推离目标容器则会受到惩罚。
- 区域清空(区域清空):
区域清空环境由一组可移动的箱子和一个清空区域组成。机器人智体是 TurtleBot3 Burger。机器人的任务是从该清空区域内移除箱子,移除的箱子的最终位置没有限制。可以通过改变待移除物体的数量、静态障碍物的数量以及工作空间限制(例如,靠近边界的墙壁阻挡清空区域)来创建该环境的各种变体。
区域清空任务中机器人的动作和观察与箱子运送任务相同,不同之处在于目标距离变换现在是相对于清空区域的开放边界计算的。奖励函数也与箱子运送任务类似,当机器人将清空区域内的任何物体移动到更靠近边界的位置,以及将箱子推出边界时,都会获得奖励。
Bench-Push 实现
Bench-Push 采用模块化架构设计,支持灵活的定制和易用性。该基准测试平台采用单行安装设计,方便研究人员快速上手。
- 附加功能和可配置性:
除了前面列出的动作空间外,Bench-Push 还允许直接控制 Turtle-Bot3 Burger 在迷宫、箱子配送和区域清理任务中的轮速,从而实现更精细的底层控制。此外,该机器人可以配备三个可互换的前保险杠(内弯收集器、直边推杆、外弯导航保险杠)。这些保险杠可以用于不同的任务,并产生不同的交互效果。最后,在真实的室内环境中,机器人经常会遇到平放在地面上的物体(例如沙发、桌子、包)和更容易移动的带轮物体(例如办公椅)。为了在概念上体现这一挑战,迷宫、箱子配送和区域清理环境可以同时包含无轮和带轮的箱子,并展现出不同的交互动态。
- 简化的二维仿真:
前面给出的所有环境均可通过 Pymunk 2D [11] 进行简化仿真。二维版本提供轻量级仿真,其中所有物体和交互均通过凸平面多边形建模,使其成为快速试点研究的理想选择。Ship-Ice 的二维版本使用与 [14] 中类似的模型船比例,且不包含流体动力学。二维和三维环境之间的详细比较可在项目存储库中找到。
- Gymnasium 集成:
将所有环境集成到 Gymnasium [24] 接口中,以标准化策略开发和评估。该实现支持通过脚本级配置或命令行参数来设置各种环境参数。
- 可扩展策略类:
Bench-Push 提供一个标准化的、可扩展的策略模板,以简化新算法的集成。该模板遵循即插即用的理念:用户只需在策略类中实现所需的 API 即可。Bench-Push 随后会处理推理、评估和日志记录过程。
例如,Bench-Push 提供成熟基线的参考实现。这些示例演示如何集成 Stable Baselines 3 [27] 中的常用强化学习算法,以及如何集成专门的或最先进的方法。
指标
评估上述任务的策略的指标如下。这些指标的灵感来源于[9],旨在捕捉机器人的任务效率和交互努力。考虑一个质量为m_0的机器人,它按照策略确定的路径行进。令O = {o_1,…,o_K} 为环境中K个可移动物体的集合,这些物体可能由于机器人的运动而移动。令每个物体i ∈ {1,…,K} 的质量和路径长度分别为m_i和l_i。由于导航和操作本质上是不同的任务,Bench-Push为每类任务提供一组不同的指标。
- 导航指标:提供两个指标来评估导航策略:任务效率得分 E_nav 和交互努力得分 I_nav。
- 操作指标:与导航指标不同,操作任务的指标必须包含机器人为完成任务而操作物体所需的最短路径长度和所需努力。还会比较机器人可能仅部分完成任务的路径,例如,将四个盒子中的两个推入容器。为了有效地捕捉这些路径,提出三个指标:(i)任务成功率 S_manip,(ii)效率评分 E_manip,以及(iii)交互努力评分 I_manip。
Bench-Push提供的基准算法,旨在验证Bench-Push的可扩展性,并为未来的研究提供参考。
已实现的基线
为了支持通用移动机器人推力研究和特定任务研究,Bench-Push 包含两类基线:(i) 适用于前面所有任务的强化学习 (RL) 基线;(ii) 特定任务基线。强化学习 (RL) 基线包括 Soft Actor-Critic (SAC) [12] 和 Proximal Policy Optimization (PPO) [13]。这些基线使用 Stable Baselines 3 [27] 实现,并在所有任务上进行训练。为了处理图像观测,这两个基线都采用定制的 ResNet18 [28] 骨干网络,移除最后一个线性层作为高维观测编码器,之后连接一个 3 层 MLP 来输出动作或值估计。
除了 RL 基线之外,Bench-Push 还包含一些针对特定任务的策略,对于迷宫任务,基于[25]实现一个快速探索随机树(RRT)规划器,该规划器能够引导机器人穿过可推动障碍物之间的自由空间,但并未考虑障碍物之间的交互特性。其次,对于箱子配送和区域清理任务,采用空间动作地图(SAM)策略[5],该策略专为多目标推动而设计。SAM策略学习输出环境中的一系列路径点,使机器人能够完成以操作为中心的任务。为了实现SAM,将箱子配送和区域清理环境配置为接收环境中的路径点作为动作输入。此外,还加入针对特定任务的基线策略,例如用于运送冰块任务的格子规划[14]和预测规划[15]策略,以及用于区域清理任务的基于广义旅行商问题(GTSP)的策略。这些额外的基线模型在仿真中的评估结果和模型权重已包含在项目库中,供未来研究参考。
物理实验设置
针对迷宫和箱子配送场景分别进行物理机器人实验,以分别代表导航和操作任务。实验平台使用 TurtleBot3 Burger 机器人。视觉系统是一个顶置摄像头,用于跟踪机器人并以 10 Hz 的频率检测物体。机器人需要在不同的任务条件下与 3D 打印的箱子进行交互。
部署在机器人上的策略是在具有相似配置的 Bench-Push 3D 环境中训练的。对于迷宫和箱子配送场景,在仿真中对每种配置进行 20 次测试,在测试平台上进行 3 次测试。通过物理实验,旨在评估将 Bench-Push 训练的策略迁移到真实硬件上的有效性。具体而言,检验任务成功率是否能从仿真迁移到实际场景,以及效率和交互努力方面的行为趋势是否保持一致。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 34
34 0
0- 0



 已为社区贡献211条内容
已为社区贡献211条内容

所有评论(0)