DREAMGEN:通过视频世界模型解锁机器人学习中的泛化性
25年6月来自NV、西雅图华大、KAIST、UCLA、UCSD、CalTech、新加坡 NTU、马里兰大学和UT Austin 的论文 “DREAMGEN: Unlocking Generalization In Robot Learning Through Video World Models ”。DREAMGEN 是一个简单而高效的四阶段机器人策略训练流程,它通过神经轨迹(由视频世界模型生成的
25年6月来自NV、西雅图华大、KAIST、UCLA、UCSD、CalTech、新加坡 NTU、马里兰大学和UT Austin 的论文 “DREAMGEN: Unlocking Generalization In Robot Learning Through Video World Models ”。
DREAMGEN 是一个简单而高效的四阶段机器人策略训练流程,它通过神经轨迹(由视频世界模型生成的合成机器人数据)来训练机器人策略,使其能够泛化到不同的行为和环境中。DREAMGEN利用最先进的图像-到-视频生成模型,并将其适配到目标机器人的形态,从而生成在各种环境中执行熟悉或新任务的逼真合成视频。由于这些模型仅生成视频,用潜动作模型或逆动力学模型(IDM)来恢复伪动作序列。尽管DREAMGEN结构简单,但它实现强大的行为和环境泛化能力:一个人形机器人可以在已见和未见的环境中执行22种新的行为,而只需要来自一个环境中单个抓取放置任务的遥操作数据。为了系统地评估该流程,引入DreamGen Bench,一个视频生成基准测试,结果表明基准测试性能与下游策略的成功率之间存在很强的相关性。
基于大规模人类远程操作数据训练的机器人基础模型,已展现出通用机器人系统执行灵巧的现实世界任务的巨大潜力[1, 2, 3, 4, 5, 6]。然而,这种范式严重依赖于为每个新任务和环境手动收集远程操作数据,这仍然成本高昂且耗费人力。在仿真环境中生成合成数据提供一种颇具吸引力的替代方案,但它通常需要大量的人工工程,并且在将视觉运动策略部署到物理机器人时会面临仿真与现实之间的差距。为了应对这些挑战,提出DREAMGEN,一种新的合成数据流水线,它利用视频世界模型以最小的人工劳动或工程投入,大规模地创建逼真的训练数据。
DREAMGEN遵循一个简单的四步流程(如图所示),应用最先进的视频生成模型[7, 8, 9, 10, 11, 12](也称为视频世界模型)来生成合成训练数据。该流程旨在适用于不同的机器人、环境和任务。(1) 首先在目标机器人上微调视频世界模型,以捕捉特定机器人的动力学和运动学特征;(2) 使用初始帧对和语言指令提示模型,生成大量机器人视频,捕捉微调过程中获得的熟悉行为以及在未见过的环境中产生的新行为;(3) 然后,用潜动作模型[13]或逆动力学模型(IDM)[14]提取伪动作;(4) 最后,用生成的视频-动作序列对(称为神经轨迹)来训练下游的视觉运动策略。虽然以往的研究主要集中于将视频世界模型用作实时规划器[15, 16, 17, 18, 19],但DREAMGEN则将其视为合成数据生成器,从而释放其强大的先验信息,用于物理推理、自然运动和语言基础构建。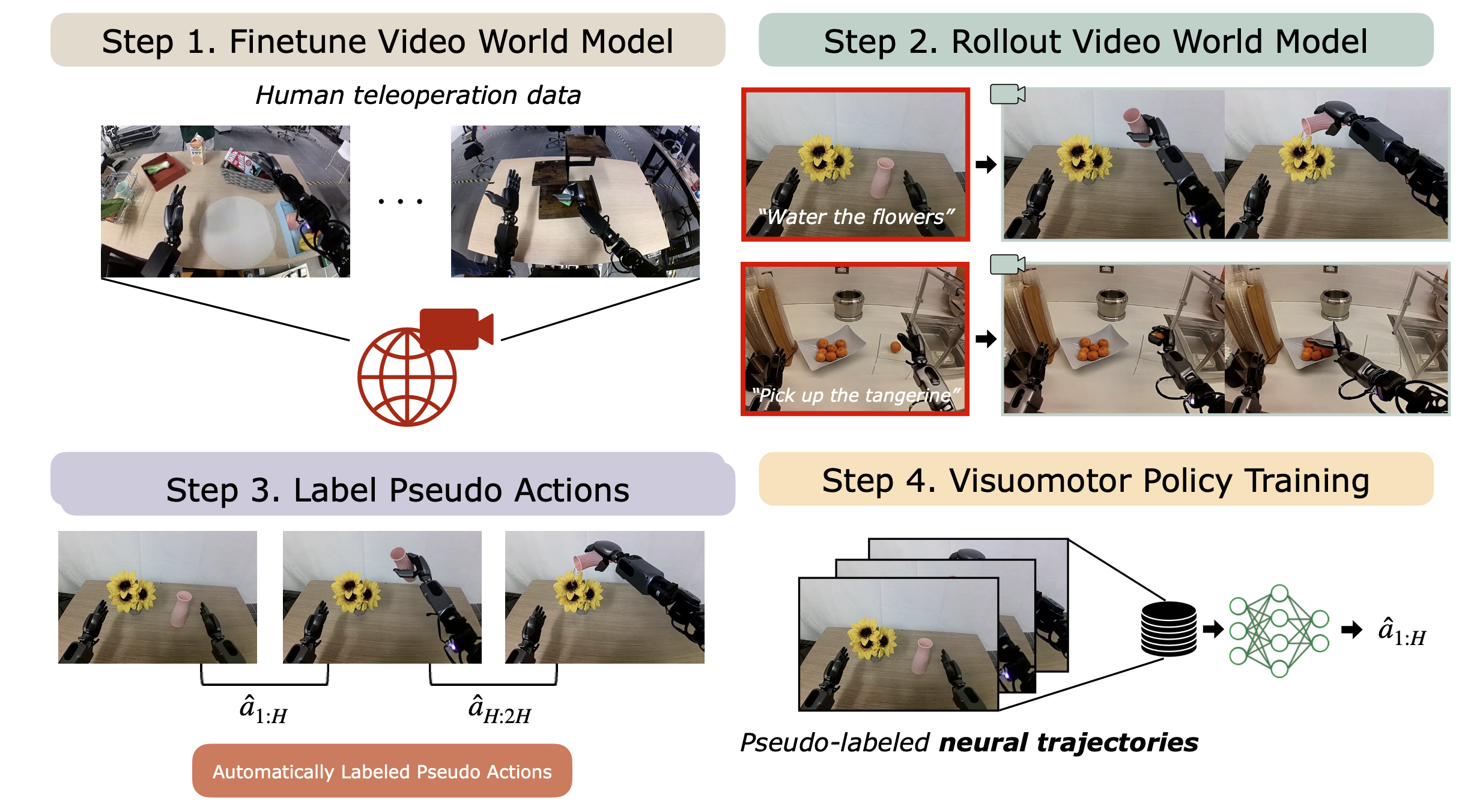
首先,研究DREAMGEN在已有远程操作数据的任务中生成额外训练数据的应用,包括仿真和真实世界。在仿真中,将DREAMGEN应用于RoboCasa基准测试[20],并将合成数据规模扩大至原始人类演示数据的333倍。结果表明,随着神经轨迹数量的增加,策略性能呈对数线性提升(如图所示)。在真实世界中,在Fourier GR1、Franka Emika和SO-100机器人上验证了方法,涵盖9个不同的任务,证明了流程在不同机器人上的灵活性,并能够应对一些难以仿真的灵巧性任务,例如折叠毛巾、擦拭液体、使用锤子和舀取M&M巧克力豆。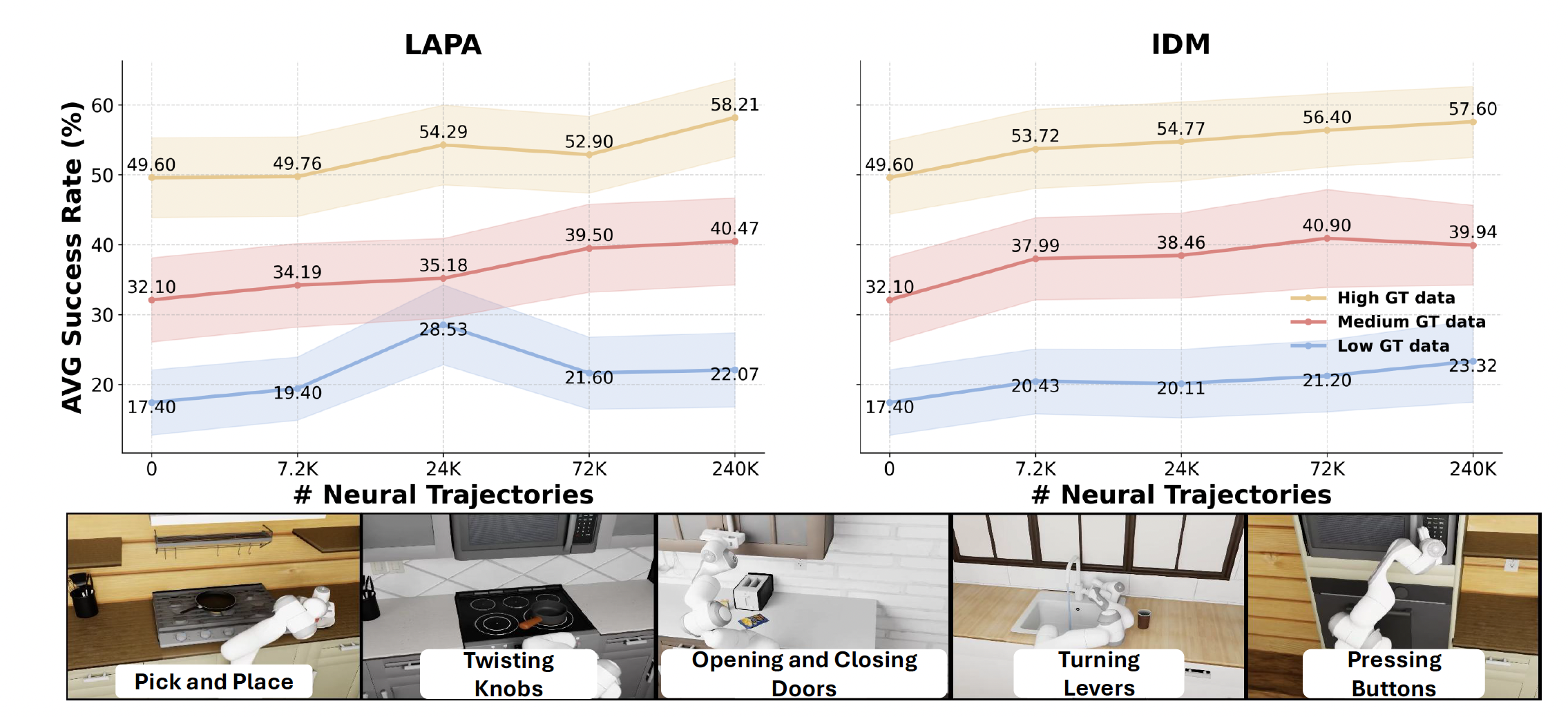
DREAMGEN 解锁两项关键泛化能力:行为泛化和环境泛化。在行为泛化方面,使 GR1 人形机器人能够执行 22 种新行为,例如倾倒、打开/关闭铰接式物体以及操作各种工具。需要注意的是,原始的远程操作数据集仅包含抓取-和-放置动作,不包含其他动词。在环境泛化方面,用来自 10 个新环境的初始帧来提示视频世界模型(该模型仅在一个环境中进行微调)。这能够仅使用来自单一环境中单一任务的远程操作数据,训练出可泛化到全新行为和场景的视觉运动策略。这代表着真正的从零到一的改进——仅基于抓取放置任务训练的 GR00T N1 模型在大多数全新行为和环境实验中成功率为 0%,而 DREAMGEN 模型在已见环境中的新行为成功率达到 43.2%,在完全未见的环境中达到 28.5%。这些实证结果指向一种无需大量人工演示即可实现可扩展机器人学习的新范式。
视频世界模型微调
在初始阶段,基于人机远程操控机器人的轨迹对视频世界模型进行微调。这种自适应方法使模型能够学习机器人的物理约束和运动能力。为了避免遗忘先前的网络视频知识,默认使用LoRA[21] 来进行不同的视频世界模型微调。在微调这些模型时,考察指令跟踪和物理跟踪这两个指标,以确定视频世界模型是否已针对目标机器人领域进行最优自适应。对于大多数后续机器人实验,用 WAN2.1 [9] 作为基础视频世界模型。对于训练数据集中存在多个视角的情况(例如 RoboCasa [20] 和 DROID [22]),将这些视角拼接成一个 2×2 的网格(其中一个网格为黑色像素),并对视频世界模型进行微调。注:每个视频世界模型和微调数据对所需的最佳微调量各不相同。
视频世界模型部署
在目标机器人实例上完成视频世界模型的微调后,用不同的初始帧和语言指令生成合成机器人视频。对于仿真实验,从模拟器中采集新的初始帧,并为每个任务随机化目标物体或环境的位置。对于真实世界实验,手动采集新的初始帧,同时随机化目标物体的位置。对于环境泛化实验,也采集新环境的初始帧,但仅限于训练从单个环境采集的视频世界模型。最后,手动生成用于行为泛化实验的新行为提示,并将所有候选提示都包含在视频基准测试中。
伪动作标注
下图展示 (a) 用于训练 IDM 模型的架构和 (b) 用于训练潜动作模型 (LAPA) 的架构,这两个架构都用于提取生成视频的伪动作标签。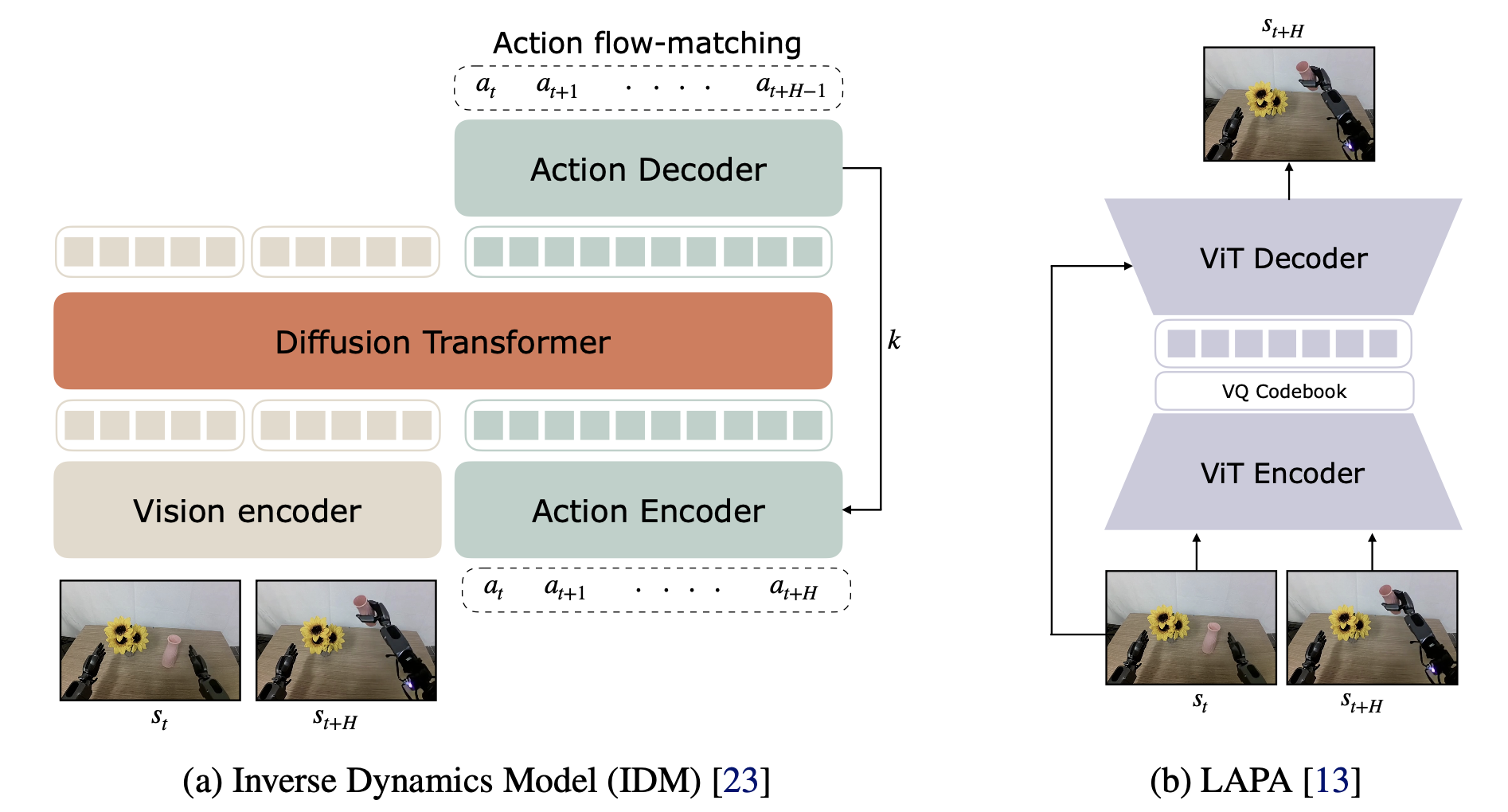
IDM 动作。对于逆动力学模型 (IDM) 架构,用带有 SigLIP-2 视觉编码器的扩散transformer,并使用流匹配(FM)目标进行训练。IDM 基于两帧图像进行训练,以预测图像帧之间的动作块。没有显式地使用任何语言或本体感觉作为输入,希望 IDM 模型仅捕获机器人的动力学。对于 IDM 训练数据,除非另有明确说明,否则使用与训练每个设置的视频世界模型相同的数据集。训练完成后,采用滑动窗口方法进行伪标签标注:IDM 预测 H 个动作,从 aˆ_t 到 aˆ_t+H。接下来,它滑动一个窗口,预测另外 H 个动作,从 aˆ_t+1 到 aˆ_t+1+H,依此类推。
潜动作。对于潜动作,用 LAPA 潜动作模型 [13],该模型采用 Transformer 编码器-解码器架构,并在各种机器人和人类视频上进行训练。该潜动作模型使用 VQ-VAE 目标函数进行训练,以便潜动作能够捕捉视频中两帧之间的视觉变化信息。为了从生成的视频中获得潜动作,以轨迹的当前帧和未来帧(1 秒后)为条件对潜动作模型进行训练。用预量化连续嵌入作为潜动作,遵循 GR00T N1 [5] 的方法。下表给出用于训练潜动作模型的确切训练数据混合。潜动作的一个优点是,在训练潜动作模型时,它不需要目标机器人本体的真实动作。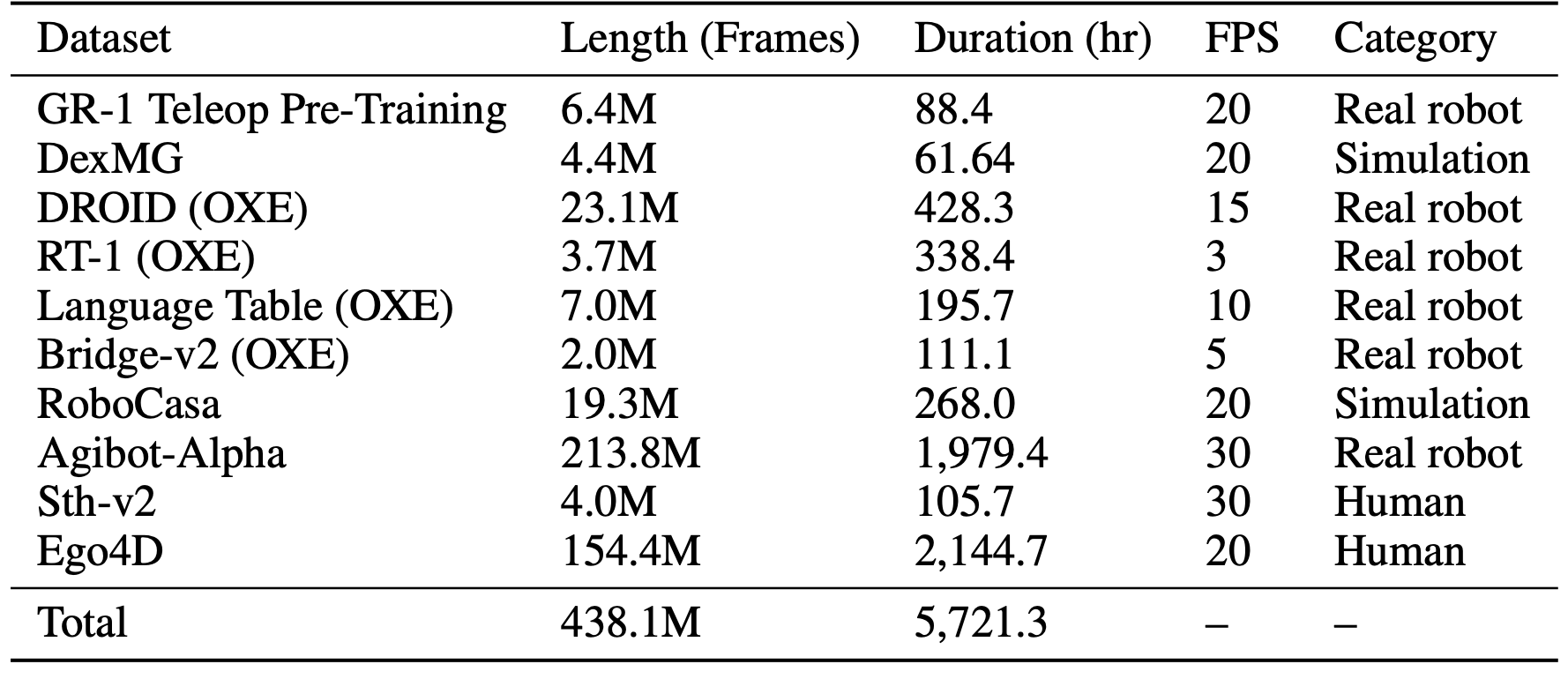
基于神经轨迹的策略训练
最后,利用 DREAMGEN 生成的神经轨迹,以语言指令和图像观测为条件,训练视觉运动机器人策略。由于神经轨迹不包含状态信息,将状态信息赋值为零。更具体地说,给定图像观测值 o_t 和任务指令 i_t,训练策略生成 aˆ_t:t+H,其中 aˆ_t:t+H 可以是潜动作,也可以是IDM 标记的动作。由于神经轨迹与底层机器人策略架构无关,展示 DREAMGEN 在为三种不同的视觉运动策略模型(扩散策略 [24]、π0 [2] 和 GR00T N1 [5])生成合成训练数据方面的有效性。
提出两种基于神经轨迹的训练方案:与真实世界轨迹协同训练,以及仅使用 IDM 标记的动作进行神经轨迹训练。当使用真实轨迹对神经轨迹进行协同训练时,协同训练的采样比例为 1:1。对于 GR00T N1 模型,通过使用不同的动作编码器和解码器,将两种类型的轨迹视为独立的实现。在行为和环境泛化实验中,仅使用神经轨迹进行策略训练。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 11
11 0
0- 0



 已为社区贡献211条内容
已为社区贡献211条内容

所有评论(0)