智源x清华团队推出DKT:秒解透明物体的感知,机器人抓取任务上“质的提升”
随着视频生成模型(Video Diffusion Model,VDM)的最新进展,本工作观察到其在合成与透明物体交互的、物理上合理的视频方面展现出卓越能力,如图 1 第一列所示。本工作的核心洞见在于,这类模型似乎已在隐式层面内化了光传输的物理规律,例如光在透明或半透明材料中的折射与反射过程。随后,巧妙地利用视频生成模型的强先验知识,并结合图像–视频数据集的协同训练策略与 LoRA 训练范式,将视频

1、导读
透明和强反射物体一直是感知系统中的难题:折射、反射与透射效应破坏了立体视觉、ToF 以及纯判别式单目深度方法所依赖的基本假设,导致深度估计中出现空洞,并在时间维度上表现出明显的不稳定性。
为解决此问题,智源研究院联合清华AIR等机构的研究者们提出了一个针对透明和强放射物体的视频深度/法向估计基础模型。该工作首先构建了首个用于透明物体几何估计的视频数据集;随后,巧妙地利用视频生成模型的强先验知识,并结合图像–视频数据集的协同训练策略与 LoRA 训练范式,将视频生成模型重用为针对透明和强反射物体的视频深度/法向估计基础模型。最后,通过大量定量与定性实验以及真实机器人平台实验验证了该方法的有效性。

- 论文链接:https://arxiv.org/abs/2512.23705
- 代码仓库:https://github.com/Daniellli/DKT
- 项目主页:https://daniellli.github.io/projects/DKT/
- 数据集: https://huggingface.co/datasets/Daniellesry/TransPhy3D
- 在线试玩链接: https://huggingface.co/spaces/Daniellesry/DKT
2、动机:
对透明和反射物体进行精确的深度估计是推动三维重建和机器人操作发展的基础。然而,这类物体所固有的物理歧义性对依赖立体匹配的深度感知相机施加了显著限制。尤其是透明物体往往会在深度图中产生缺失区域,从而导致下游任务的性能显著下降。
近期的数据驱动方法试图通过构建涵盖多样光照条件和材料属性的数据集来应对这一挑战,从而近似刻画透明与高光反射物体的视觉特性,并据此训练深度预测模型。然而,此类数据集在多样性方面仍然受限,导致相关方法在真实世界场景中的表现往往不尽理想。本工作推测,这些方法倾向于对其训练所依赖的有限数据集产生过拟合。
为缓解泛化能力不足的问题,近年来的研究逐渐引入预训练视觉编码器(如 DINO),或利用文本到图像的基础模型(如 Stable Diffusion)来训练深度估计网络。尽管这些方法在单帧深度估计精度方面取得了显著提升,但在跨帧序列上仍然缺乏足够的时间一致性。这一局限性对依赖稳定三维感知以支持一致行动策略的下游任务尤为不利,例如机器人操作等。此类任务通常在动态且非结构化的环境中执行,其中鲁棒的感知能力与时间一致的决策机制不可或缺。
随着视频生成模型(Video Diffusion Model,VDM)的最新进展,本工作观察到其在合成与透明物体交互的、物理上合理的视频方面展现出卓越能力,如图 1 第一列所示。本工作的核心洞见在于,这类模型似乎已在隐式层面内化了光传输的物理规律,例如光在透明或半透明材料中的折射与反射过程。基于这一认识,为将上述知识用于透明物体的视频深度估计,本工作从数据与学习两个层面做出了相应贡献。

数据:本工作收集了一个包含多种类别与形态的透明及高反射物体的三维资产库。在此基础上,设计了一套自动化渲染管线,利用这些资产生成物理上合理的场景,并在多样化光照条件与相机运动轨迹下渲染视频数据,从而构建了首个面向透明物体的视频合成数据集 TransPhy3D。该数据集聚焦于透明物体的几何估计问题,有效补充了现有主要针对单帧深度估计的图像数据集。
学习:本工作提出了一种面向视频深度估计的范式转变,将视频深度估计从传统的判别式回归任务转化为视频到视频的条件生成问题。具体而言,本工作采用 LoRA 训练策略,以高效利用视频生成模型中内在的透明与反射物体先验。为充分利用现有的帧级数据集,本工作进一步引入了一种协同训练策略,实现帧级数据与视频数据的联合训练。最终,本工作提出了一个主要面向透明物体视频深度估计的基础模型,称为 DKT。
核心贡献:
- 本文提出了TransPhy3D,首个面向透明物体的视频合成数据集,包含 11,000 段视频和约 132 万帧数据,用于支持视频生成模型的有效微调。
- 通过 LoRA高效微调视频生成模型,充分利用其内在的透明与反射物体相关先验,提出了首个用于透明物体视频深度估计的基础模型 DKT;同时,设计了一种协同训练策略,使模型能够在现有合成图像数据集与 TransPhy3D 构成的混合数据上进行联合训练。
- 本工作在多个公开数据集上以及机器人真机抓取实验上对现有 SOTA 方法进行了系统性的基准评测,实验结果表明,DKT 在深度/法向估计精度以及真实世界机器人实验中均显著优于现有方法。
3、方法简述
3.1.数据

如 Figure 2 上部分所示,数据资产包含两部分:一是从BlenderKit 网站搜集的 category-rich资产,包括多样化的玻璃、高光泽度的物体和纹理,二是基于超二次曲面方程表征的shape-rich 资产。后者的纹理来自前者。Shape-rich 资产的特点在于,每个资产由多个超二次曲面方程进行表征,并可通过调整方程参数生成不同形状,例如 Figure 2 右上角所示的高脚杯。
在构建数据资产之后,本工作随机采样 M 个资产,并通过 Blender 内置物理引擎使其从上方自由下坠,从而形成具有不同摆放位置与遮挡关系的多样化场景。随后,沿所有资产的中心采样圆形相机轨迹,并对轨迹施加正弦扰动,以生成多样化的相机运动路径。最后,采用 Blender 内置的 Cycles 渲染引擎进行高质量渲染。
最终,本工作构建了首个面向透明与高反射物体的视频几何估计数据集 TransPhy3D。该数据集共包含 11,000 个场景,每个场景渲染 120 帧视频,总计 1,320,000 帧图像。
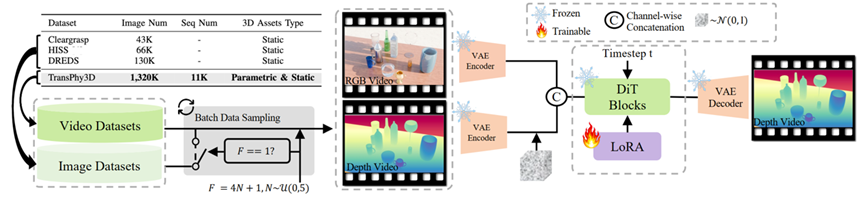
3.2.方法
3.2.1.视频生成模型基座
本工作基于 WAN-2.1,其整体架构主要由两部分组成:VAE 以及包含若干 DiT-blocks 的 Diffusion-Transformer(本文不讨论 Text-Encoder)。其中,VAE 负责将 RGB 视频编码至隐空间,并将隐空间中的视频隐变量解码回 RGB 视频;Diffusion-Transformer 则用于对给定的噪声隐变量执行去噪过程。
WAN 采用 Flow-Matching 框架对去噪过程进行建模。在训练阶段,给定图像/视频隐变量 x 1 x_1 x1 、从标准高斯分布 x 0 ∼ N ( 0 , 1 ) x_0 \sim \mathcal{N}(0,1) x0∼N(0,1) 中采样的随机噪声,以及从均匀分布 t ∼ U ( 0 , 1 ) t \sim \mathcal{U}(0,1) t∼U(0,1) 中采样的时间步,首先根据下式计算得到中间状态 x t x_t xt :
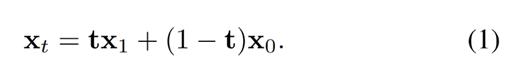
并将其输入至 Diffusion Transformer得到预测velocity。随后,通过下式构造对应的真值 velocity:
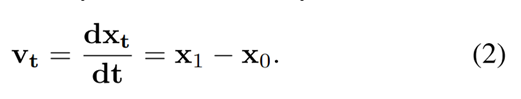
训练过程中所采用的损失函数为模型预测的 velocity 与真值 velocity 之间的均方误差。
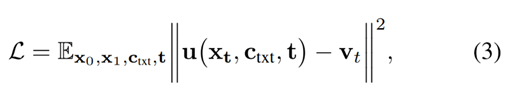
3.2.2.训练范式
如 Figure 3左侧 所示,为了提升训练效率并降低数据管线中的渲染负担,本文提出了一种图像与视频数据集的协同训练策略。具体而言,首先通过下式计算一个常量F。
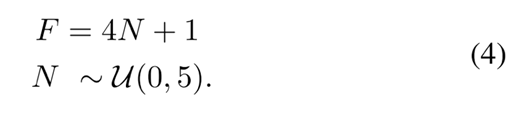
该F用于表示一个批次的数据里的视频长度。相同长度的视频才能组成一个批次。如果F等1, 该批次的数据会同时从视频数据集TransPhy3D和图像数据集ClearGrasp, HISS, DREDS采样。反之, 则只从视频数据集采样。 通过这种简单的批次构建策略, 本工作高效地将图像数据集也利用上。
而后,算法管线如 Figure 3·右侧 所示:将 RGB 视频 与 深度视频 同时编码至隐空间,分别得到 x 1 c x_1^c x1c 和 x 1 d x_1^d x1d。随后,根据公式 (1) 对 x 1 d x_1^d x1d 加噪得到 x t d x_t^d xtd。接着,将 x t d x_t^d xtd 与 x 1 c x_1^c x1c 沿通道维度进行拼接(concat),并作为 DiffusionTransformer 的输入。训练损失被定义为模型预测的 velocity 与真值 velocity 之间的均方误差。
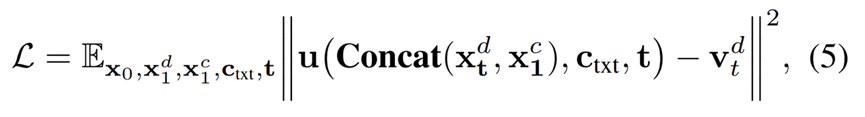
其中, c t x t c_{txt} ctxt表示固定的文本特征编码,Concat 表示沿通道维度的特征拼接操作。
为高效利用视频生成模型中关于透明与反射物体的强大先验,本文在训练过程中仅对 Diffusion Transformer 中引入的少量 LoRA 参数进行优化,其余参数均保持冻结,不参与训练。
4、实验结果
4.1. 与现有最先进方法对比
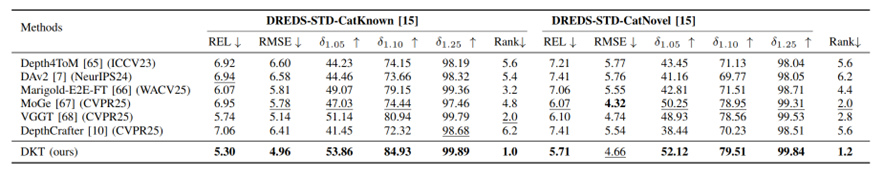
如下图所示, 本工作在真实数据集ClearPose, DREDS-STD-CatKnown, DREDS-STD-CatNovel以及新构建的未参与训练的仿真数据集TransPhy3D-Test均大幅超越前最优方法,包括图像深度估计算法DepthAnythingV2(DAv2), 视频深度估计算法(DepthCrafter)等。

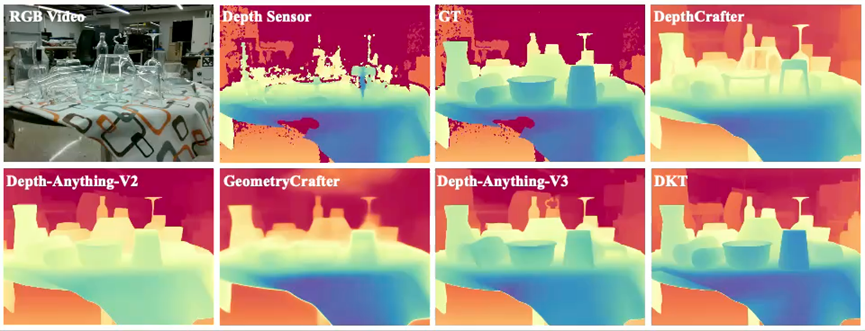
如下列所示,DKT实现了最优的透明物体深度召回率以及最平滑的深度。更多定性结果参考本工作的项目主页以及欢迎通过在线Demo进行试玩。



4.2. 消融实验
训练策略: 如下图所示,LoRA 训练策略能够较好地避免灾难性遗忘,从而实现更优的性能表现。在确定训练策略后,本文进一步对模型参数规模进行扩展,最终获得了性能最优的模型。

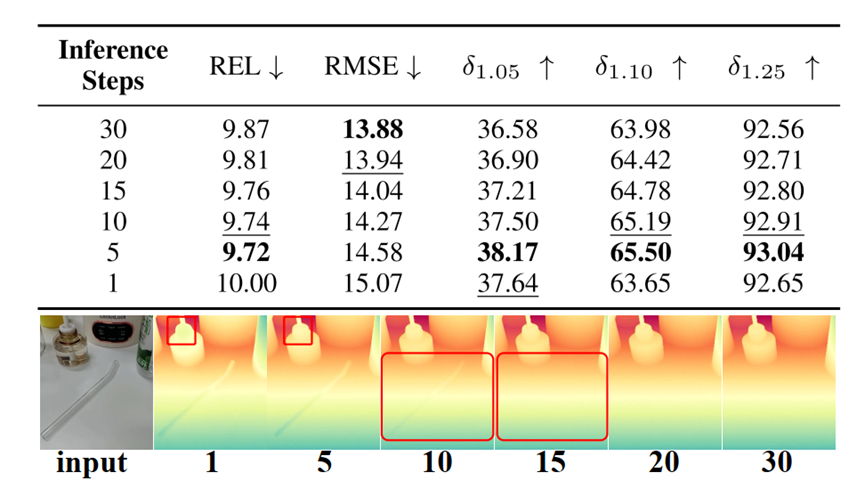
推理步数:如下图所示,去噪步数过少会引入较大的预测误差,而去噪步数过多则容易导致小尺度物体细节的丢失。在不同设置的对比中,采用 5 个去噪步数 能够在精度与细节保留之间取得最佳平衡,从而实现最优性能。
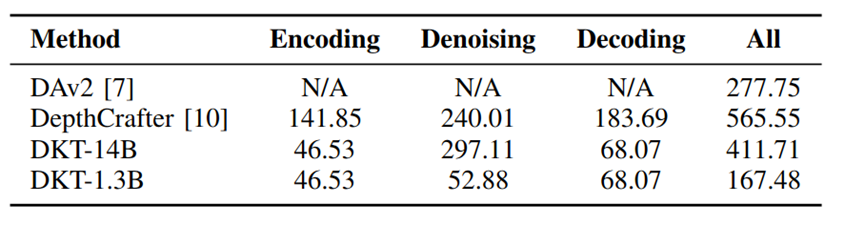
时间效率:时间效率是下游具身任务中最为关键的考量之一。如图所示,本文提出的 DKT-1.3B 在832×480 分辨率下的单帧预测速度达到 167.48 ms/帧,在同类方法中实现了最优运行效率,显著优于 DepthAnythingV2 与 DepthCrafter。
视频法向估计: 为了进一步验证本文所提出方法论的有效性,本工作进一步设计了 DKT-Normal,一个全新的面向透明与反射物体的视频法向估计基础模型。如图和视频所示,DKT-Normal-14B 在 ClearPose 数据集上的定量与定性对比实验中均显著超越了现有最先进的法向估计方法,包括图像法向估计算法 Marigold-E2E-FT 以及视频法向估计算法 NormalCrafter。更多实验结果请参考本文的项目主页及在线 Demo。

4.3. 真机实验
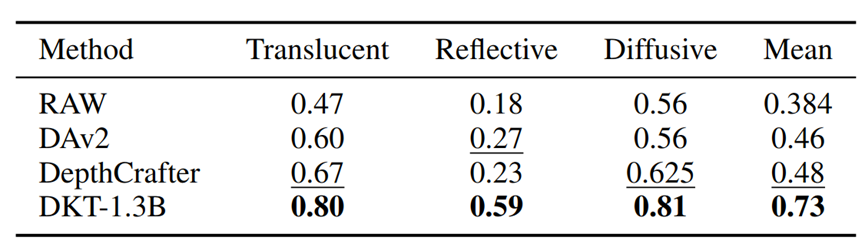
如下图所示,为了进一步验证算法的有效性,本文设计了三种不同的真实机器人实验设置,分别针对反射平面、半透明平面以及漫反射平面上的透明与反射物体抓取任务。


实验结果表明,在上述三种实验设置下,DKT-1.3B 均取得了最优性能,显著优于 DepthAnythingV2 和 DepthCrafter。
4.4. 更多in-the-wild 测试效果展示
4.4.1. 动态场景

4.4.2. 机器人场景

4.4.3. 小物体

4.4.4. 其他
更多实验结果请参考本工作的项目主页以及在线demo。


具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 13
13 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)