两阶段强化学习实践
离线强化学习:这部分前期已经写过一篇文章,可参考《几种强化学习算法输出的Q值的可视化(hil-serl/td3+bc/td3+bc+distributional)》里面的工作2.1,基于笔者选择了跟gr-rl一样的离线技术方案:td3+bc,训练出了一个critic模型,此模型输出的Q值可视化后在趋势上,值的大小上都符合预期。海量数据的监督预训练:gr-rl/pistar0.6,这两个工作都是经过
本文原始发表在知乎,格式会更规正一些,可参考:《两阶段强化学习实践》
样本效率指的是智能体(Agent)从环境中学习最优策略时,需要多少交互数据(样本)才能达到目标性能。它是强化学习(RL)中最重要的指标之一。笔者基于纯在线强化学习hil-serl算法复现过两个案例,《具身智能hil-serl强化学习算法在lerobot机械臂上复现》和《具身智能hil-serl强化学习算法在lerobot机械臂上复现-案例2》分别human in the loop持续两小时和八小时,虽然可能存在操作方法的低效,但相关经验也表明,对于复杂的场景试图只用在线的强化学习算法去学习是不太现实的,可能需要大量的时间和资源成本。
最近看到了一些影响力较大的论文,如pistart0.6/gr-rl/ConRFT等,都是采用多阶段联合训练的方式进行,在最后阶段才会上在线强化学习。关于gr-rl/pistar0.6:一些信息可参考:《关于gr-rl与pi-0.6(π₀.₆)的一些想法》,关于ConRFT可参考:《td3+bc与conrft强化学习算法总结》。基于对这些工作的理解,笔者把这些阶段抽象为下面几个阶段:
海量数据的监督预训练:gr-rl/pistar0.6,这两个工作都是经过了海量的具身,多任务的数据的监督学习,具备了基本的视觉,动作,语言的多模态能力。gr-rl针对具体的目标任务,也会在此预训练的基础之上进行行为克隆的监督微调。
离线强化学习:
gr-rl使用了td3+bc离线强化学习算法,在少量目标任务数据之上学习一个critic模型,这个模型可以充当一个任务进度提示器,可以对一些可能存在噪声的人工数据进行filter,过滤掉人工操作中犹豫,低效的片段。然后用filter后的数据再进行监督微调。任务成功率在这个阶段可以提升15.9%。
而pistar0.6也是先训练出一个critic模型,它使用的是较为传统的监督学习的方法,critic模型的输出类似gr-rl中critic模型的效果,供下阶段使用。注意pistar0.6并没有强化学习的方法,而是监督学习的方法,但训练出来的模型有点类似于强化学习中critic模型的效果,作者说这个方法“简单,稳定”,但同时也承认与强化学习的方法相比,可能是“次优的”。
ConRFT使用了CalQL+BC离线强化学习算法,与td3+bc类似的思路,只是算法选型的不同。
在线强化学习:
gr-rl基于上面阶段的critic模型,最后增加了一个在线强化学习阶段,在真机环境下进行闭环的优化与修正,在线RL训练使整体成功率提升了10.6%。
pistar0.6采取了“离线-在线”循环反复的一个模式,本质上模拟了一个“准在线”的模式。
ConRFT可以经过45-90分钟的在线强化学习后,任务成功率可达96%以上
笔者基于对上面工作的理解,复现了一个两个阶段的强化学习的过程:
在模型设计方面,没有使用像gr-rl/pistar0.6这种大型的VLA模型,而是较为简单的resnet图像特征提取+MLP输出动作这种小型网络,具体模型设计可参考文章:《强化学习Actor/Learner框架介绍(lerobot版)》中“网络设计”章节。
在工程实现方面,是基于hil-serl的Actor/Learner双进程的架构进行适配修改,具体也可以参考上面这篇文章。
在强化学习算法设计上,参考了gr-rl中的td3+bc+distributional的方案,但笔者经过实验,输出时没有输出分布,而还是直接输出Q值的方式,即td3+bc。在线强化学习阶段也是参考gr-rl,直接使用td3算法,即去掉了bc。
两阶段的强化学习过程如下:
离线强化学习:这部分前期已经写过一篇文章,可参考《几种强化学习算法输出的Q值的可视化(hil-serl/td3+bc/td3+bc+distributional)》里面的工作2.1,基于笔者选择了跟gr-rl一样的离线技术方案:td3+bc,训练出了一个critic模型,此模型输出的Q值可视化后在趋势上,值的大小上都符合预期 。
在线强化学习:在离线输出的策略和critic模型基础之上,进行继续在线训练。在线数据缓冲区使用离线阶段所使用的232个episode数据进行初始化,离线数据缓冲区使用人工采集的30个episode数据进行初始化。
经过了1小时的在线过程,就可以看到一个比较好的效果了,其中训练指标曲线图如下。共进行了两次,其中深色的是笔者明确了人工操作规范(即3次人工操作+3次策略生成循环进行数据采集的模式)后较为顺利的一次,浅色的是有点凭着感觉走,所以感觉训练过程中效果有所下降,就中断了。其中深色的这次,可以看出比较平稳一些。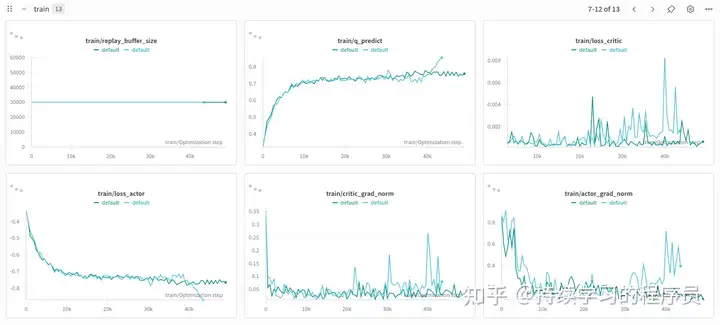
在训练1小时后的checkpoint上做了一些评测,可以看出成功的episode(图二,四,六,八)在Q值趋势性上基本没有问题的。与离线强化学习输出的critic模型相比,整体的Q值偏大。因为训练时间并不长,所以预计持续进行优化增强后,Q值应该可以有所下降。(关于Q值趋势可参考对比:《几种强化学习算法输出的Q值的可视化(hil-serl/td3+bc/td3+bc+distributional)》)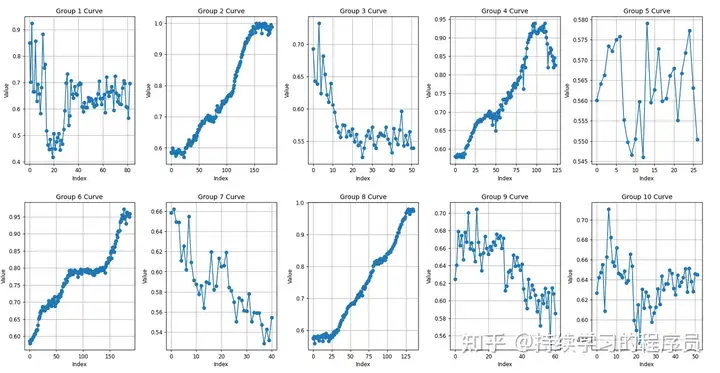
结论:
离线2.5h+在线1h就可以获得一个较好的策略效果,与hil-serl纯在线需要8小时相比,效率得到了极大的提升。
附录:
代码地址:
https://github.com/hxdoit/lerobot.git,切换到分支:td3_bc_online
经过td3_bc的offline RL学习后,需要加载训练出来的actor/critic模型继续进行online RL训练,online在offline的基础之上做了少量代码修改:
将以前删除的双buffer缓冲区加上了,一个缓冲区存储人工采集的数据和训练过程中人工接管的数据,另一个缓冲区存储策略自动生成的数据,这两部分数据在训练每step时会各取50%。笔者理解人工数据代表较优质的数据,策略自动生成的数据在没有收敛时,会次优一些,另外还包括大量的失败(负样本)数据,二者混合参与训练,这样正负样本的数据都会比较均衡,训练会更快,效果会更好。
另外一点,在online时把bc行为克隆的监督信号去掉了,online因为动作有探索性,所以不需要bc。
第一次运行需要改几行代码:
主要目的是加载我们指定的数据集和模型参数,但又不能走正常的resume逻辑。如果后续再resume就把这些修改去除就可以。
— a/rl_train_config.json
+++ b/rl_train_config.json
@@ -1,7 +1,7 @@
{
- “output_dir”: “/home/ubuntu/Downloads/embodient/lerobot/lerobot/outputs/train/2026-01-24/21-36-11_default/”,
- “output_dir”: null,
“job_name”: “default”,
- “resume”: true,
- “resume”: false,
— a/src/lerobot/policies/factory.py
+++ b/src/lerobot/policies/factory.py
@@ -385,7 +385,7 @@ def make_policy(
)
policy_cls = get_policy_class(cfg.type)
- cfg.pretrained_path = “/home/ubuntu/Downloads/embodient/lerobot/lerobot/outputs/train/2026-01-24/21-36-11_default/checkpoints/last/pretrained_model”
+++ b/src/lerobot/rl/learner.py
@@ -929,7 +929,7 @@ def initialize_replay_buffer(
ReplayBuffer: Initialized replay buffer
“”"
- if not cfg.resume:
-
if False and not cfg.resume:
return ReplayBuffer(
capacity=cfg.policy.online_buffer_capacity,
device = device,
@@ -940,7 +940,7 @@ def initialize_replay_buffer(logging.info(“Resume training load the online dataset”)
dataset_path = os.path.join(cfg.output_dir, “dataset”)
- #dataset_path = os.path.join(“/home/ubuntu/Downloads/embodient/lerobot/lerobot/outputs/train/2026-01-19/11-07-22_default”, “dataset”)
- dataset_path = os.path.join(“/home/ubuntu/Downloads/embodient/lerobot/lerobot/outputs/train/2026-01-19/11-07-22_default”, “dataset”)

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)