【论文自动阅读】TT-VLA:通过Test-Time RL实现动态可变VLA
本文提出了一种名为TT-VLA的框架,让机器人在执行任务的过程中(测试时),利用即时的环境反馈(进度奖励)实时微调自己的策略,从而在遇到从未见过的环境变化时能自我调整并完成任务。
这是一份基于你上传的论文《On-the-Fly VLA Adaptation via Test-Time Reinforcement Learning》的详细解读。
快速了解部分
基础信息(英文):
- 题目: On-the-Fly VLA Adaptation via Test-Time Reinforcement Learning
- 时间: 2026.01 (arXiv: 2601.06748)
- 机构: University of Missouri-Kansas City, Hong Kong University of Science and Technology (Guangzhou), U.S. Naval Research Laboratory, Lamar University, Meta AI, Rochester Institute of Technology
- 3个英文关键词: Vision-Language-Action (VLA), Test-Time Training (TTT), Reinforcement Learning (RL)
1句话通俗总结本文干了什么事情
本文提出了一种名为TT-VLA的框架,让机器人在执行任务的过程中(测试时),利用即时的环境反馈(进度奖励)实时微调自己的策略,从而在遇到从未见过的环境变化时能自我调整并完成任务。
研究痛点:现有研究不足 / 要解决的具体问题
现有的VLA模型主要依赖监督微调(SFT)或训练时的强化学习(RL),一旦部署后策略就固定了。这导致机器人在面对现实世界中动态变化的环境(如物体位置改变、视觉干扰、新指令等)时,缺乏自主适应能力,容易失败。
核心方法:关键技术、模型或研究设计(简要)
核心方法是测试时强化学习(TT-VLA)。它利用一个预训练的进度估计器(Progress Estimator)提供密集的奖励信号,驱动一个无需价值函数(Value-free)的PPO算法,在推理过程中实时更新机器人的动作策略。
深入了解部分
相比前人创新在哪里
- 测试时在线适应:不同于以往只在训练阶段更新参数,本文实现了在推理(测试)阶段直接在线微调策略。
- 无需重置的RL:设计了一种适合测试时的强化学习机制,不需要像传统RL那样频繁重置环境,也不需要昂贵的价值函数网络。
- 即时奖励机制:放弃了传统的长期折扣回报(GAE),改用基于单步进度的即时奖励,更适合实时决策。
解决方法/算法的通俗解释
想象一个机器人正在考试(执行任务)。传统方法是考前突击(训练),考场上不能改答案(策略固定)。TT-VLA则允许机器人在考试过程中,每做一步就根据这一步是否离目标更近(进度奖励)来微调自己的解题思路(策略),从而即使遇到没复习过的题(新环境)也能现场学会怎么做。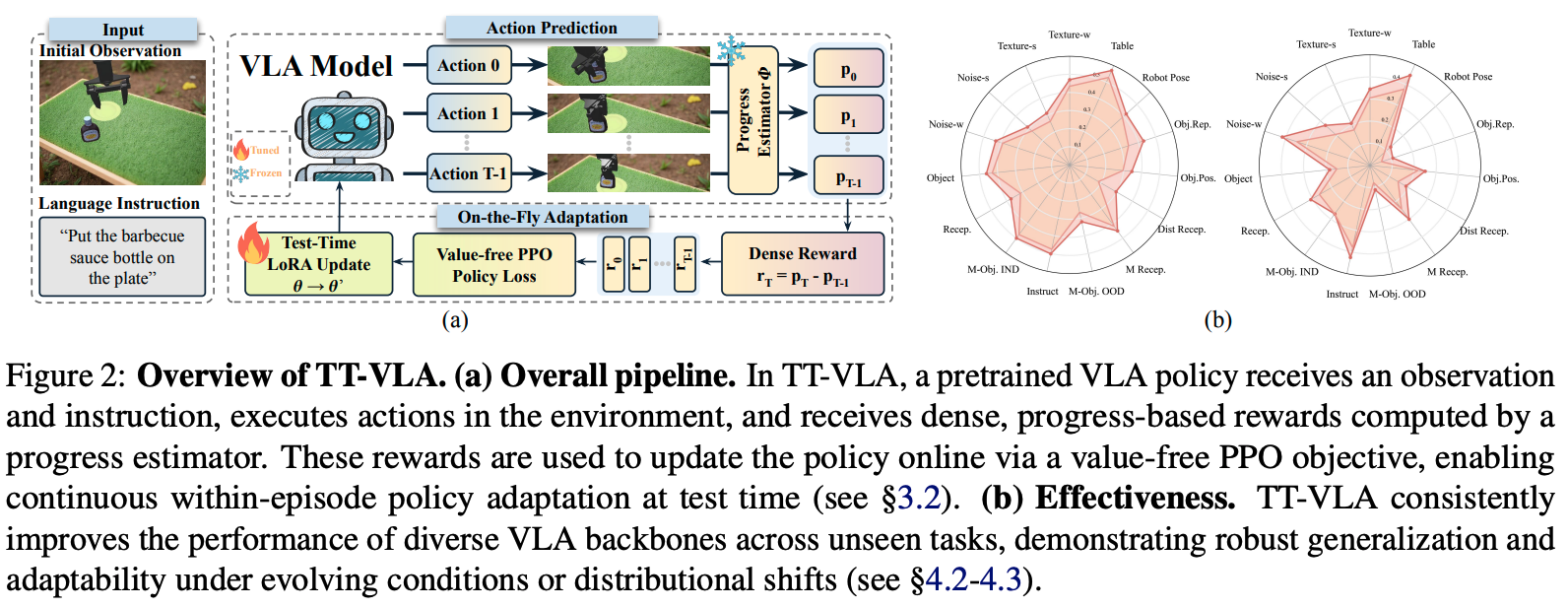
解决方法的具体做法
- 进度估计:使用一个冻结的辅助模型(VLAC)来评估当前任务完成了多少(0到1之间),无需人工标注。
- 计算奖励:奖励值 = 当前进度 - 上一步进度。如果动作让任务更接近目标,奖励为正,反之为负。
- 策略更新:使用PPO算法,但去掉了价值网络(Value-free),直接用上述的进度奖励来更新VLA模型的参数(通过LoRA),每执行几步更新一次。
基于前人的哪些方法
- VLA基础模型:基于现有的预训练VLA模型(如Nora, OpenVLA等)作为骨干。
- PPO算法:基于近端策略优化(Proximal Policy Optimization)框架,但进行了简化以适应测试时场景。
- VLAC模型:使用了预训练的Vision-Language-Action-Critic模型来预测任务进度。
实验设置、数据、评估方式、结论
- 实验设置:在ManiSkill 3仿真环境和真实的Franka Research 3机械臂上进行实验。
- 数据:使用了包含未见过的执行变化(如物体移动)、视觉变化(如纹理干扰、噪声)和语义变化(如新物体、新指令)的任务。
- 评估方式:计算任务成功率(Success Rate),并与基线模型(Nora, OpenVLA等)进行对比。
- 结论:TT-VLA在所有基线模型和任务类别中均显著提升了性能。例如在OpenVLA上,面对未见过的干扰物和视觉噪声,成功率提升了10%-40%以上,证明了其强大的泛化和自适应能力。
提到的同类工作
- EVOLVE-VLA:同样是测试时训练,但使用GRPO算法,计算开销大,不适合实时机器人控制。
- TLM (Test-time Language Modeling):基于自监督(困惑度最小化)的方法,在VLA任务中效果不佳,因为它只关注表示一致性,而非任务完成。
- TTRL (Test-time Reinforcement Learning):基于共识的伪标签奖励,在VLA动作空间中难以有效工作。
和本文相关性最高的3个文献
- RL4VLA / OpenVLA-RL:本文的基准模型来源,也是对比实验的主要基础,定义了仿真实验的任务设置。
- VLAC:本文核心组件“进度估计器”的来源,用于生成密集的奖励信号。
- EVOLVE-VLA:最接近的同类工作,本文在讨
论部分重点对比了该方法,指出了其计算效率低的缺点并提出了更轻量级的解决方案。
我的
TT-VLA 的核心局限在于它试图在无法重置的物理世界中,用有限的算力,基于可能有偏差的奖励信号,进行高风险的在线自我改造。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 7
7 0
0- 0



 已为社区贡献58条内容
已为社区贡献58条内容

所有评论(0)