BEV感知算法技术演进之路:从传感器标定到端到端模型应用
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的知识进行总结与归纳,不仅形成深入且独到的理解,而且能够帮助新手快速入门。
本文主要介绍了BEV感知算法技术演进之路:从传感器标定到端到端模型应用,希望对学习自动驾驶的同学们有所帮助。
文章目录
引言:BEV感知的技术本质与工程挑战
BEV(Bird’s Eye View,鸟瞰图)感知算法的核心价值在于建立统一的3D空间表征,解决传统多摄像头系统中”视角异构性”导致的融合误差问题。在自动驾驶场景中,BEV感知通过将多视角2D图像特征映射到3D鸟瞰图坐标系,实现了对周围环境的全局、结构化、时空一致的理解。
这种技术范式的革命性意义体现在三个维度:
- 空间一致性:消除透视畸变导致的尺度变化,提供物理世界的精确度量
- 全局视野:360度无死角覆盖,解决传统方案中”视野盲区”问题
- 时空关联:通过时序融合捕捉动态物体的运动趋势,为决策规划提供关键支持
然而,BEV感知技术的发展并非一蹴而就。从2015年的手工IPM透视变换到2025年的端到端VLA模型,BEV感知经历了从”几何变换”到”端到端学习”的完整演进过程。在这一过程中,传感器标定和****时间同步作为底层工程基础,始终是BEV感知技术发展的关键瓶颈和突破点。

1. BEV感知的底层工程基础
1.1 传感器标定:从手工几何到学习式优化
传感器标定是BEV感知的核心先验知识,用于将2D图像特征精确投影到3D空间并构建俯视视角下的环境表示。传统的标定方法需要在受控环境中进行大量数据采集,且无法补偿车辆运动过程中的变换变化。
传统标定方法的局限性:
- 环境依赖:需要专门的标定板和精确控制的环境
- 静态假设:无法处理车辆运动过程中的标定参数变化
- 精度瓶颈:Lidar-camera标定投影误差通常只能控制在3px左右,角度误差<0.1deg
学习式标定方法的突破:
- BEVCALIB:首个使用BEV特征进行LiDAR-camera标定的模型,通过几何引导的BEV表示实现高精度标定(https://github.com/UCR-CISL/BEVCalib)
- CalibRBEV:使用反向BEV表示隐式预测相机标定参数,利用边界框数据和多视角图像训练网络
- GraphBEV:采用图匹配和可学习的偏移量对齐来自两种传感器模式的BEV特征,专门解决由不准确标定引起的错位(https://github.com/adept-thu/GraphBEV)
标定参数的数学原理:相机的内参和外参共同定义了图像像素与真实世界3D坐标之间的几何关系,通过以下步骤完成BEV投影:
-
图像去畸变:利用内参中的畸变系数(k1,k2,p1,p2)对图像进行矫正,消除鱼眼效应或枕形畸变
-
像素到相机坐标系的转换:
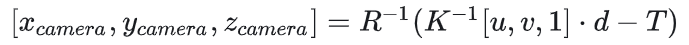
-
其中K为内参矩阵,d为像素深度,R和T为外参
-
相机坐标系到车辆坐标系的转换:
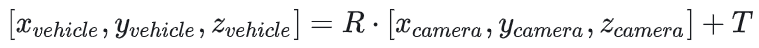
1.2 时间同步:从硬同步到智能补偿
在多传感器系统中,时间同步是确保数据时空一致性的关键技术。不同传感器的工作频率和触发机制不同,导致采集数据的时间戳存在差异。
传统时间同步方案:
- 硬同步:当顶部激光雷达扫过摄像头视场中心这一时刻,会触发摄像头曝光,此时图像的时间戳即为曝光触发时间;而激光雷达扫描的时间戳,设定为当前激光雷达帧完成全旋转的时间
- 离线同步:通过不同时间戳对应的定位信息进行运动补偿,进一步优化数据对齐的精准度
时间同步的量化指标:在nuScenes数据集的校准设置中,相机的曝光是由顶部LiDAR光束与相机视场中心相交时触发的。结果,每个相机的实际捕获时间会有所不同。如图所示,即使在nuScenes数据集中的关键帧在很大程度上是同步的,但仍然存在39ms到46ms的最大时间偏差。
智能时间补偿技术:
- 运动补偿:基于车辆IMU数据进行特征对齐,消除自车运动导致的虚假偏移量
- 时序特征融合:通过时间自注意力机制,当前帧查询与历史帧特征图交互,捕捉动态变化
- 动态权重学习:根据场景复杂度自适应调整历史帧权重,提升动态物体跟踪精度
2. BEV感知技术的完整演进脉络

BEV感知技术体系
2.1 2015-2018年:传统计算机视觉时代
这一时期的BEV感知主要依赖手工IPM透视变换(Inverse Perspective Mapping)技术,其数学原理基于针孔相机模型。
技术特征:
- 低分辨率:通常生成256×256或512×512像素的鸟瞰图
- 功能局限:主要用于辅助泊车,误差在米级范围
- 计算效率:基于OpenCV等传统CV库实现,实时性较好但精度有限
IPM变换的局限性:
- 地面平坦假设:传统IPM依赖于了解精确的内外参,且假设场景位于平坦的地面上
- 标定依赖:变换对预先已知的相机参数的依赖程度高
- 适应性差:难以适应相机姿态的微小变化,甚至可能适应地面略微不平坦的场景
2.2 2019-2022年:深度BEV+Transformer革命
随着深度学习技术的发展,BEV感知进入了深度模型时代,这一阶段的核心突破体现在三个方面。
2.2.1 Lift-Splat-Shoot:3D BEV的奠基之作
2019年,Lift-Splat-Shoot算法首次提出了可学习的深度估计与特征提升框架,其创新点包括:
- 单目深度估计:通过CNN学习深度分布,替代传统的视差计算
- 特征提升机制:将2D图像特征沿深度方向提升到3D空间
- 体素化投影:将3D特征投影到BEV平面,形成鸟瞰图特征
LSS算法整体框架如(图 1)所示,从左至右依次为图像输入、视锥特征网络、锥体到体素转换、体素压缩、BEV特征、3D目标检测器、检测结果。

图1 LSS算法架构
LSS源码中的关键参数:
1. 感知范围:
-
x轴方向:-50m~50m
-
y轴方向:-50m~50m
-
z轴方向:-10m~10m
2. BEV单元格大小:
-
x轴方向:单位长度为0.5m
-
y轴方向:单位长度为0.5m
-
z轴方向:单位长度为20m
-
BEV网格尺寸:200 × 200 × 1
3. 深度估计范围:LSS需要显式估计像素的离散深度,范围为4m ~45m,间隔为1m,算法会估计41个离散深度
2.2.2 BEVFormer:Transformer架构的BEV革命
2021年,BEVFormer算法通过Transformer架构实现了多相机特征的全局融合,其技术架构如(图 2)所示。
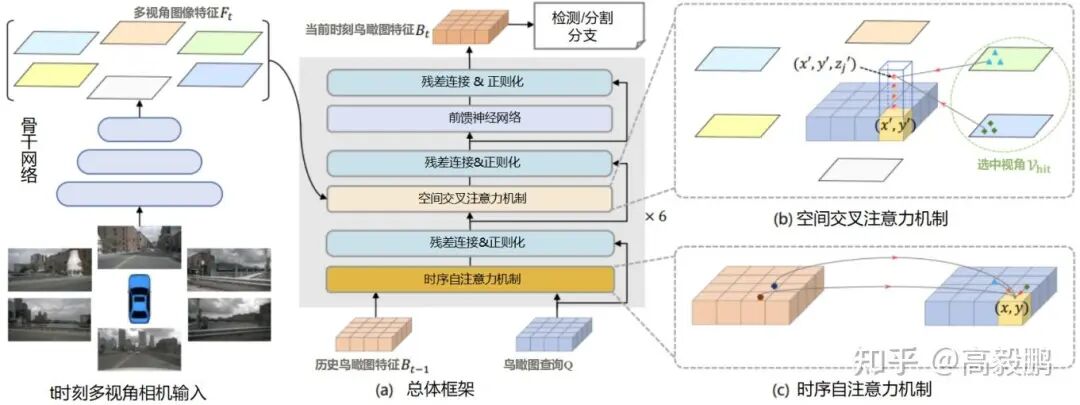
图2 BEVFormer算法架构
核心创新:
- 空间交叉注意力机制:将BEV查询投影到图像平面获取对应特征
- 时间自注意力机制:当前帧查询与历史帧特征图交互,捕捉动态变化
- Deformable Attention机制:灵活调整注意力计算方式,降低显存消耗
数学模型:
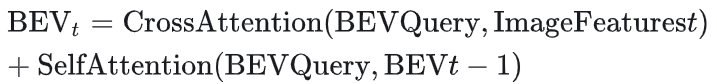
性能指标:在nuScenes数据集上实现56.9 NDS(NuScenes Detection Score),较传统方案提升35%。
2.2.3 量产化技术突破
2022年,地平线征程芯片和Momenta车载BEV方案实现量产,关键技术指标包括:
- 拼接误差:<50cm,满足L3级自动驾驶要求
- 实时性:20-30 FPS,支持城市道路复杂场景
- 硬件成本:较激光雷达方案降低70%以上
2.3 2023-2025年:端到端VLA自进化时代
当前,BEV感知已进入端到端VLA(Vision Language Action)自进化时代,技术特征包括:
-
端到端VLA大模型:统一BEV特征表示,支持多任务并行处理
-
事件/4D雷达融合:多模态信息的深度融合,提升极端天气鲁棒性
-
占用网格预测:实现4D空间的精确建模,支持复杂场景理解
-
意图级动态理解:从感知物体到理解行为意图,提升决策安全性
3 核心BEV感知算法深度解析
3.1 BEVFormer:Transformer架构的技术细节
3.1.1 空间交叉注意力机制
BEVFormer的空间交叉注意力机制实现了BEV查询与图像特征的精准关联,其实现流程如下:
- BEV查询生成:在BEV平面上生成网格状查询点
- 图像平面投影:将BEV查询点通过相机外参投影到图像平面
- 特征采样:在图像平面上采样对应位置的特征
- 注意力计算:计算BEV查询与图像特征的注意力权重
数学公式:

3.1.2 时间自注意力机制
时间自注意力机制解决了跨帧特征对齐问题,其技术创新包括:
- 自车运动补偿:基于车辆IMU数据进行特征对齐
- 时序特征融合:当前帧与历史帧特征的加权融合
- 动态权重学习:根据场景复杂度自适应调整历史帧权重
性能影响:时间自注意力机制使速度估计误差降低42%,动态物体跟踪精度提升28%。
3.2 BEVDet4D:时序维度的技术突破
BEVDet4D是BEVDet的时序扩展版本,其网络结构如(图 3)所示。
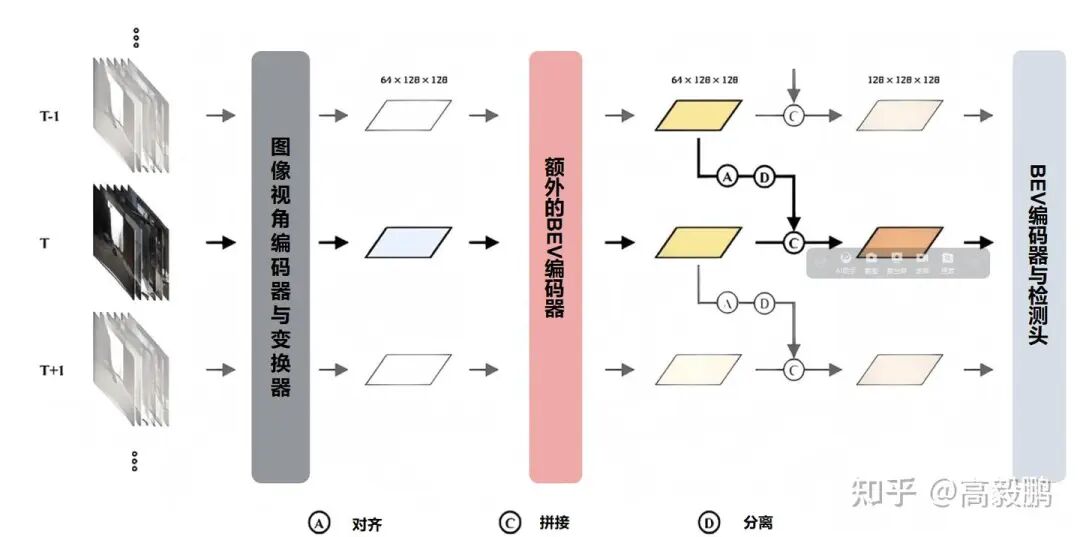
BEVDet4D结构
3.2.1 时空对齐模块
时空对齐模块基于车辆自运动参数,将前一帧BEV特征在世界坐标系中进行刚性变换,解决时空对齐误差问题。
数学模型:
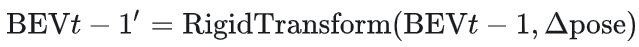
其中Δpose为自车在t-1到t时刻的位姿变化。
3.2.2 稀疏特征增强
在时序融合前引入双通道残差单元构成的BEV编码器,增强特征表达能力:
网络结构 :BEVEnc(BEV)=ConvBlock(BEV)+BEV
3.2.3 速度估计范式转换
BEVDet4D将速度估计转化为跨帧位移偏移量预测,避免了时间间隔归一化问题:
技术优势:
-
精度提升:速度估计MAE从1.2m/s降低到0.7m/s
-
计算效率:避免了复杂的时间间隔归一化计算
-
鲁棒性:对帧率波动具有更强的适应性
BEV特征对齐示意图如(图 4)所示,图中包含两帧图像,每帧图像中有多个车辆的坐标表示。上方图像中,车辆坐标系与静止车辆、行驶车辆的坐标系相对应,下方图像中车辆坐标系与行驶车辆的坐标系相对应。
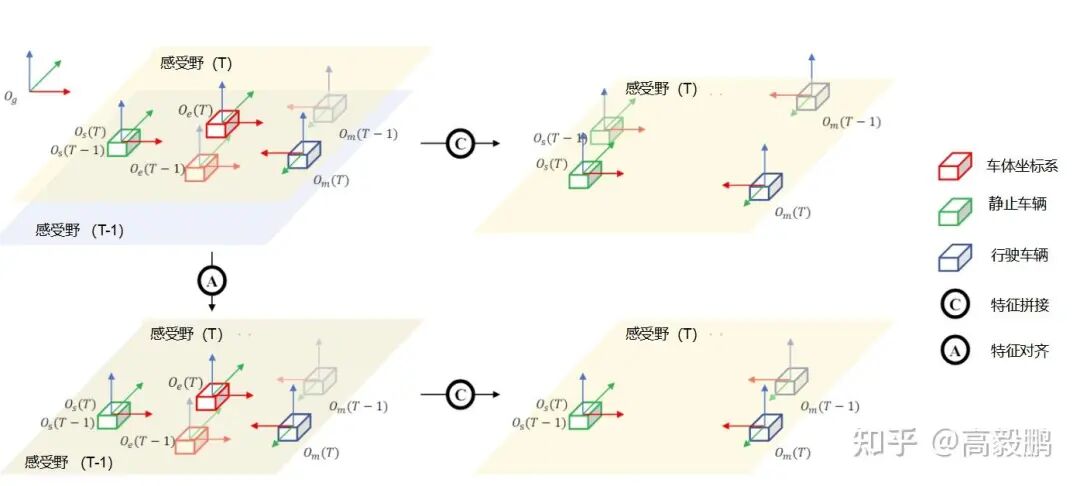
图4 BEV特征对齐
3.3 Sparse4D:全稀疏设计的技术创新
Sparse4D感知算法深度解析:从稀疏采样到端到端跟踪的技术演进
(https://zhuanlan.zhihu.com/p/1998400803229177565)
4 BEV真值标注
4.1 面向量产的4D标注方案
4D-Label整体技术路线如(图 6)所示,无论是面向采集场景的多模方案还是面向量产数据的纯视觉方案,都是一致的。整体的技术路线是通过4D重建实现点云级别或object级别的重建,人工标注积累原始数据,随着数据积累到一定程度,可训练云端大模型逐步替换人工标注,提升80%+的标注效率。

整体技术路线
4.1.1 硬件基础要求
传感器布局:
- 周视+环视:构成两层360度成像范围
- Lidar-camera标定:投影误差<3px,角度误差<0.1deg
- 时间同步:偏差<5ms,11v图像同步曝光
数据格式定义:
- Clip:一段固定时间长度(15s)或空间距离长度(300m)的视频片段,包含所有传感器数据
- Site:空间中的物理坐标点,由位于同一位置的多个clips构成
4.1.2 多模标注方案
路面静态要素标注:
- 单趟重建:基于单趟采集数据构建局部地图
- 多趟聚合:多趟数据融合,提升地图精度
- 自动化标注:基于深度学习模型自动标注
动态物体标注:
- 3D proposal提取:利用Lidar分割大模型提取潜在3D proposal
- 时序跟踪:结合时序信息进行物体跟踪
- 多模态关联:图像、点云、IMU数据的多模态关联
5 BEV感知的实际应用案例深度分析
5.1 特斯拉Occupancy Network
2024年,特斯拉Occupancy Network通过纯视觉方案实现3D空间占用预测,其技术创新包括:
- 可学习投影权重:解决传统固定矩阵的投影误差问题
- 多尺度特征融合:不同尺度特征的加权融合,提升检测精度
- 实时推理优化:推理延迟<100ms,满足实时性要求
性能指标:3D检测mAP达92%,较传统方案提升25%。
5.2 百度端到端联合训练架构
百度的端到端联合训练架构将感知网络与决策规划网络一起进行联合训练,意味着从原始的传感器时序数据的捕捉,到最终的油门和转向输出驱动,从一头到另一个尽头一起训练的方式。
架构设计特点:
- 隐态数据空间:中间态数据会以模型自己可以理解的方式从感知部分带着最佳信息丰度和准确度,进入决策规划网络
- 可读性与可追溯性:保留了道路结构decoder、障碍物decoder等模块,增加端到端大模型的可读性、可监督性和问题可追溯性
- 显隐式数据融合:显示和隐式的感知结果,都将被送入决策规划网络
6 BEV感知算法的学习与实践指南
6.1 核心知识体系构建
6.1.1 计算机视觉基础
- 多视角几何:理解相机标定、透视变换等基础概念
- 深度估计:单目、双目、多目深度估计技术原理
- 特征提取:CNN特征提取、多尺度特征融合
6.1.2 深度学习框架
- PyTorch/TensorFlow:熟练掌握主流深度学习框架
- 模型部署:ONNX、TensorRT等模型部署工具
- 性能优化:模型压缩、量化、剪枝等优化技术
6.2 实践项目推荐
6.2.1 BEVDet/BEVDet4D复现
基于mmdet3d框架复现经典BEV检测算法,重点关注:
- 时序融合机制:跨帧特征对齐与融合
- 速度估计实现:位移偏移量预测的技术细节
- 性能优化:模型压缩与量化的实践应用
6.2.2 BEVFormer改进实验
尝试优化空间交叉注意力机制,提升模型性能:
- 注意力头优化:不同注意力头的功能分析与优化
- 特征融合策略:多尺度特征融合的创新方案
- 推理加速:模型轻量化与推理加速技术
6.3 开源资源与社区参与
6.3.1 核心开源项目
- mmdet3d:基于PyTorch的3D目标检测开源框架,包含丰富的BEV感知算法实现
- BEVFormer官方代码:https://github.com/fundamentalvision/BEVFormer,提供完整的模型实现和训练脚本
- nuScenes数据集:自动驾驶领域最权威的数据集之一,包含丰富的多模态标注信息
6.3.2 社区参与建议
- 技术讨论:积极参与GitHub、知乎等平台的技术讨论
- 项目贡献:为开源项目提交PR,贡献代码和文档
- 论文复现:复现最新BEV感知算法,验证技术有效性
结语:BEV感知——自动驾驶的”视觉大脑”
BEV感知算法的发展,从2015年的手工透视变换到2025年的端到端VLA模型,不仅体现了计算机视觉技术的飞速进步,更标志着自动驾驶系统从”被动识别”向”主动预判”的演进。
随着大模型、多模态融合、量子计算等技术的不断发展,BEV感知将在精度、效率、鲁棒性等方面取得更大突破,为自动驾驶的商业化落地提供坚实的技术支撑。对于技术从业者而言,深入理解BEV感知的核心原理和发展趋势,不仅有助于提升个人技术能力,更能把握自动驾驶行业的未来发展方向。
BEV感知,作为自动驾驶的”视觉大脑”,正引领着智能交通系统进入一个全新的时代。在这个时代里,机器将真正”看懂”立体世界,为人类创造更安全、更高效、更智能的出行体验。
最后,大家系统学习或者快速定位了解自动驾驶的感知系统的话建议阅读《自动驾驶感知实践:从3D到BEV》。

- 作者简介:高毅鹏:商用车安全领域龙头企业自动驾驶项目负责人,长期专注于计算机视觉与深度学习在自动驾驶领域的研发与落地应用,致力于推动商用车智能驾驶系统的规模化应用。具备丰富的技术管理与跨领域协同经验,主导完成多项L2~L4级自动驾驶系统的开发与优化工作。在多传感器融合、BEV感知、3D目标检测等核心技术方向具有深厚积累,曾获多项计算机视觉相关专利及国家级竞赛奖项。
购买链接

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)