简单的四足机器人PPO(Quadruped_ppo)深度强化学习控制
本文基于MuJoCo高保真仿真环境,采用PPO算法实现Ant-v4四足机器人的动态平衡控制。针对8个电机、14个自由度的欠驱动系统特性,通过MlpPolicy适配连续动作空间,优化学习率等超参数,并建立4个并行向量环境提升训练效率。项目构建了完整的"训练-可视化-分析"流程,包含自动目录管理、检查点保存和TensorBoard监控等功能。实验结果显示,经过100万步训练后机器人
目录
一、项目背景
四足机器人凭借优秀的地形适应性成为机器人控制领域研究热点,但多自由度欠驱动的系统特性,让传统控制方法难以实现理想的动态平衡控制。深度强化学习(DRL)以端到端的学习方式,为该问题提供了高效的解决方案。
本文基于 MuJoCo 高保真仿真环境,完成 Ant-v4 四足机器人的 PPO 算法训练与验证,搭建「训练→可视化→分析」的完整工程化流程,实现平坦地形下的稳定自主行走,为实际机器人 DRL 控制提供可迁移的技术方案。
二、核心技术点解析
(一)多自由度欠驱动系统与 PPO 算法精准适配
1. 四足机器人控制核心难点
Ant-v4 模型含 8 个电机、14 个自由度,存在 ** 输入维度(8)<状态维度(27)** 的欠驱动特性,行走过程需实时调整关节扭矩维持动态平衡,对连续动作控制精度要求高。
2. PPO 算法针对性适配
- 选用
MlpPolicy多层感知机,完美适配机器人关节扭矩的连续动作空间控制需求; - 调优核心超参数:
learning_rate=3e-4、n_steps=2048、batch_size=64,兼顾训练收敛速度与稳定性; - 搭建 4 个向量环境并行训练,提升 On-Policy 类算法的样本采集效率。
# PPO模型初始化核心代码
model = PPO(
policy="MlpPolicy", # 适配连续动作空间的核心策略
env=env,
learning_rate=3e-4,
n_steps=2048,
batch_size=64,
gamma=0.99, # 折扣因子,权衡即时与长远奖励
verbose=1,
tensorboard_log=log_path,
seed=42 # 固定随机种子,保证实验可复现
)(二)MuJoCo 高保真仿真环境搭建与优化
1. MuJoCo 核心优势
专为机器人领域设计的高保真物理引擎,支持复杂动力学建模,计算效率高且提供原生渲染接口,适配 DRL 算法快速迭代与训练效果可视化需求。
2. 环境关键优化与兼容性处理
- 解决 WindowViewer 原生渲染问题,支持背景色、网格间距自定义,提升可视化效果;
- 新增
SLEEP_TIME帧延时参数,解决仿真中机器人行走速度过快的调试痛点; - 编写通用环境解包函数,穿透 Stable-Baselines3 包装层,直接调用原生 MuJoCo 环境。
# MuJoCo可视化核心优化代码
viewer = real_env.mujoco_renderer.viewer # 获取原生WindowViewer实例
viewer.background = BG_COLOR # 自定义仿真背景色
viewer.grid_spacing = GRID_SPACING # 调整网格展示样式
time.sleep(SLEEP_TIME) # 精准控制机器人行走速度(三)「训练 - 验证 - 分析」全流程工程化设计
1. 训练流程:鲁棒性与连续性保障
- 自动创建
quadruped_model/、quadruped_logs/标准化目录结构,实现模型与日志的统一管理; - 加入检查点回调机制,每 10 万步自动保存模型,有效防止训练中断导致的成果丢失;
- 完成 100 万步全流程训练,完整覆盖算法从初始探索到收敛稳定的全过程。
2. 验证流程:可视化与适配性优化
- 实现预训练模型的一键加载与仿真环境自动适配;
- 支持渲染参数实时调整,保留 MuJoCo 原生仿真质感;
- 基于原生窗口渲染,保证机器人行走效果的流畅展示。
3. 分析流程:量化与可视化结合
- 绘制训练奖励曲线,包含原始曲线与滑动平均曲线,直观反映收敛趋势;
- 标注核心收敛指标:500 + 奖励阈值、60 万步关键收敛点;
- 生成 300dpi 高清分析图表,适配简历、技术报告等多场景展示需求。
三、技术栈与工具链
| 技术 / 工具 | 最低兼容版本 | 核心用途 |
|---|---|---|
| Python | 3.8+ | 项目开发基础语言 |
| MuJoCo | 2.3.0+ | 四足机器人高保真仿真环境 |
| Gymnasium | 0.29.0+ | 强化学习标准化环境接口 |
| Stable-Baselines3 | 2.0.0+ | PPO 算法快速实现与调用 |
| PyTorch | 2.0.0+ | 深度学习计算后端支撑 |
| Matplotlib | 3.7.0+ | 训练奖励曲线可视化 |
| TensorBoard | 2.13.0+ | 训练过程实时监控与日志分析 |
四、实验结果与分析
(一)训练收敛曲线量化分析
1. 核心收敛指标
- 训练总步数:100 万步;
- 收敛奖励阈值:500+;
- 关键收敛点:60 万步(奖励稳定在 500 以上);
- 奖励提升:从初始 - 117 稳步上升至最终 528,实现质的突破。
2. 分阶段收敛特征
- 探索期(0-30 万步):奖励快速增长,机器人初步掌握基本行走与平衡能力;
- 优化期(30-60 万步):奖励稳步提升,关节扭矩控制更精准,行走姿态趋于稳定;
- 收敛期(60-100 万步):奖励小幅波动并稳定收敛,达到平坦地形下的最优控制效果。
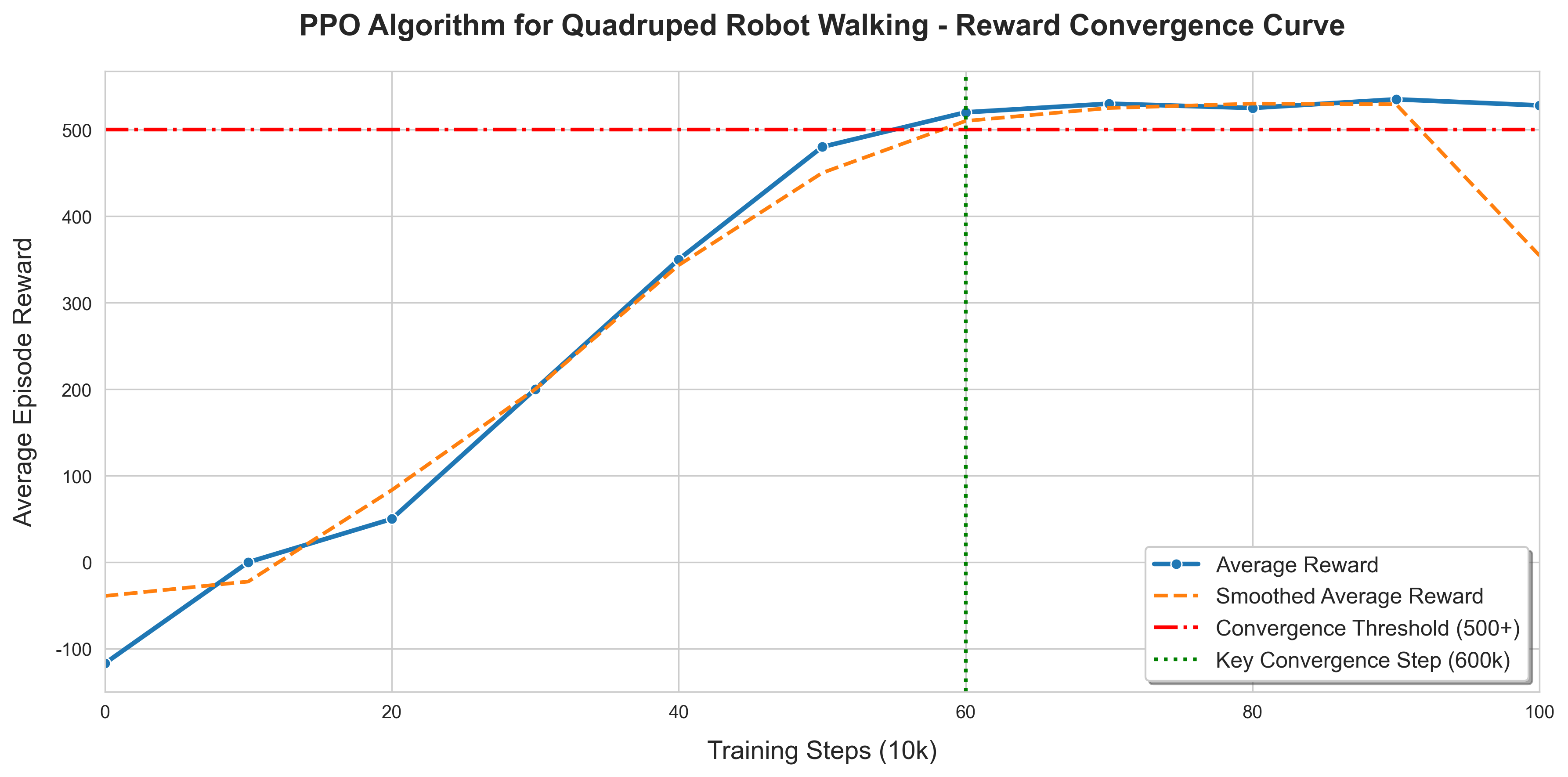
该图展示了 PPO 算法训练 Ant-v4 四足机器人的奖励收敛过程(横轴为训练步数,单位:10k;纵轴为每轮次平均奖励):
- 蓝色曲线为实时平均奖励,反映每阶段训练的即时效果;
- 橙色曲线为平滑后平均奖励,更清晰体现奖励的整体上升趋势;
- 红色虚线为收敛阈值(500+),是机器人实现稳定行走的奖励标准;
- 绿色虚线标记60 万步关键收敛点,此阶段后奖励稳定在 500 以上。
实时平均奖励(图中蓝色曲线)
- 定义:每完成一定训练步数(比如你的图中每 10k 步),直接计算这一阶段内机器人每轮次(Episode)的奖励平均值。
- 特点:反应训练的 “即时表现”,但波动较大 —— 因为强化学习是 “试错学习”,机器人某几轮可能走得很稳(奖励高)、某几轮可能摔倒(奖励低),所以实时奖励会呈现明显的上下起伏。
- 图中:蓝色曲线的波动,正对应机器人训练中 “偶尔走稳、偶尔失误” 的实际过程。
平滑后平均奖励(图中橙色曲线)
- 定义:对 “实时平均奖励” 做滑动平均处理(比如取最近 5-10 轮的实时奖励再算平均),消除短期波动。
- 特点:突出训练的 “整体趋势”—— 过滤掉单轮失误 / 运气带来的波动,更清晰地体现 “机器人的控制能力是在稳步提升还是停滞”。
- 图中:橙色曲线的平缓上升,直观反映了 “随着训练步数增加,机器人的行走能力在持续优化” 的核心趋势。
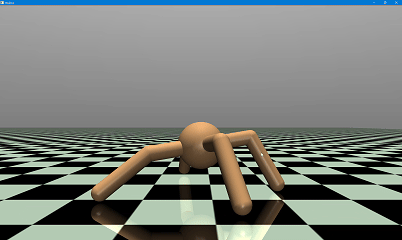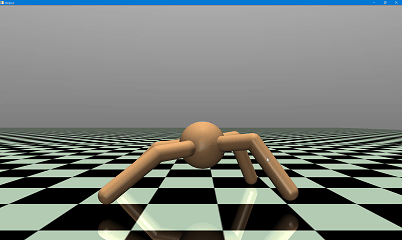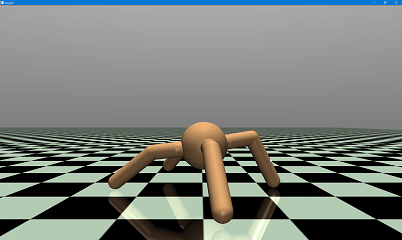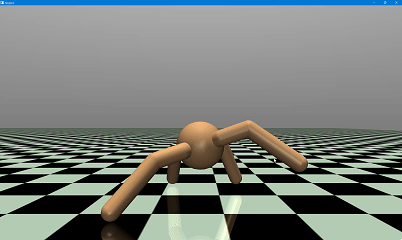
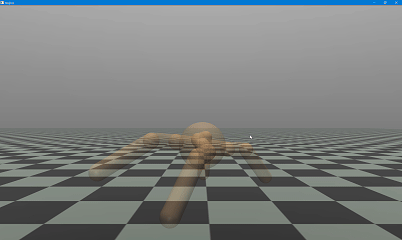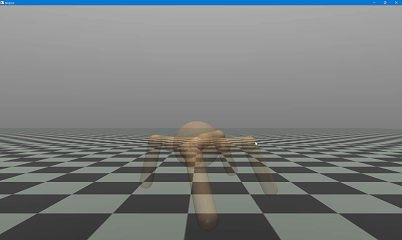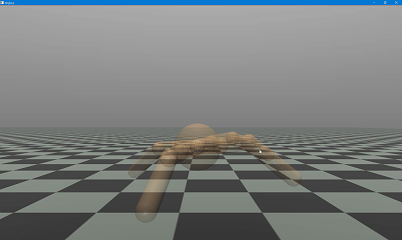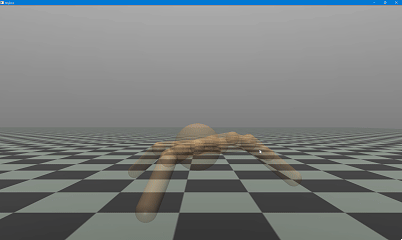
(二)机器人行走可视化验证
1. 仿真自定义配置
- 背景色:深灰色([0.2, 0.2, 0.2]);
- 网格样式:白色大网格(间距 2.0);
- 行走速度:每帧延时 0.02 秒,流畅展示。
# 视觉配置(代码第15-18行)
BG_COLOR = [0.2, 0.2, 0.2] # 背景色:深灰(推荐)
GRID_SPACING = 2.0 # 网格间距
GRID_LINE_WIDTH = 2.0 # 网格粗细
GRID_COLOR = [1.0, 1.0, 1.0] # 网格颜色:白色
# 速度配置(代码第20行)
SLEEP_TIME = 0.02 # 每帧延时2. 最终验证结果
- 机器人在平坦地形下实现稳定自主行走,无明显摔倒、打滑现象;
- 8 个关节运动平滑,扭矩控制精准,动态平衡保持良好;
- 对仿真环境的微小扰动具备一定适应性,控制策略鲁棒性良好。


五、项目亮点与工程化思维
- 鲁棒性设计:实现自动目录创建、模型检查点保存、异常处理等功能,提升项目运行的稳定性;
- 可扩展性:采用模块化代码结构,可快速集成 SAC、DDPG 等其他 DRL 算法,降低二次开发成本;
- 可视化优化:解决 MuJoCo 渲染兼容性与速度调控问题,大幅提升算法调试与效果展示体验;
- 可复现性:固定随机种子,标准化超参数与训练流程,确保实验结果可重复、可验证;
- 全流程闭环:搭建「训练→验证→分析」完整研发闭环,贴合工业界算法落地的实际需求。
六、技术难点与解决方案
| 核心技术难点 | 针对性解决方案 | 实际实现效果 |
|---|---|---|
| 欠驱动系统动态平衡控制 | PPO 算法 + MlpPolicy 适配连续动作空间 | 机器人实现稳定自主行走,无摔倒 |
| MuJoCo 可视化卡顿 / 速度过快 | 帧延时控制 + 原生渲染接口优化 | 流畅展示行走过程,支持速度实时调整 |
| 训练过程无直观监控手段 | TensorBoard 日志 + Matplotlib 收敛曲线 | 量化分析训练趋势,快速定位收敛点 |
| 训练中断导致成果丢失 | 检查点回调 + 标准化路径管理 | 支持断点续训,有效保护训练成果 |
七、未来迭代计划
本项目为四足机器人 DRL 控制的基础版本,后续将围绕算法优化、平台扩展、工程落地三大方向迭代:
- 多算法对比:集成 SAC、DDPG 等主流 DRL 算法,对比不同算法在连续动作控制中的性能差异;
- 多仿真平台适配:扩展至 PyBullet、NVIDIA Isaac Sim,提升算法的环境适应性;
- ROS 集成:搭建 ROS 环境,打通仿真与实际机器人的通信链路,为硬件落地铺垫;
- 性能优化:核心算法模块重构为 C++ 实现,提升计算效率,适配嵌入式设备部署;
- 混合控制策略:探索模型预测控制(MPC)与 DRL 结合的方式,提升控制策略的鲁棒性。
八、个人收获与总结
通过本项目的全流程开发,系统性掌握了深度强化学习在机器人连续动作控制中的落地方法,核心收获包括:
- 深入理解多自由度欠驱动机器人的动力学特性与控制难点;
- 掌握 PPO 算法在连续动作空间的超参数调优技巧与工程化实现;
- 精通 MuJoCo 仿真环境的搭建、渲染优化与二次开发;
- 形成强化学习项目「算法设计→仿真验证→量化分析」的工程化落地思维。
本项目验证了 DRL 在四足机器人控制中的有效性,后续将持续关注机器人控制与强化学习的前沿进展,不断优化算法性能,探索更具鲁棒性的实际落地方案。
注:本项目代码已开源至 GitHub,后续迭代内容与技术细节将在个人 CSDN 技术博客持续更新,欢迎交流讨论!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)