面向训练的 AI 设计——辩论、陪练、教学三种模式的策略与反馈体系
训练的核心目标并不是获得一句看似合理的回答,而是通过持续、结构化、可反馈的互动,促使学习者能力发生可验证的提升。在“辩核 AI 具身辩论数字人系统”中,系统被明确定位为**训练系统**而非聊天产品,其核心差异并不体现在模型参数规模,而体现在模式设计、策略约束与反馈机制之中。本文将围绕辩论模式、陪练模式与教学模式三种核心形态,系统阐述其背后的设计逻辑与工程化实现思路。
前言
当大语言模型逐渐具备接近人类的语言生成能力后,一个常见误区随之出现:只要“能对话”,就等于“能训练”。在真实的教学与能力训练场景中,这一假设往往并不成立。训练的核心目标并不是获得一句看似合理的回答,而是通过持续、结构化、可反馈的互动,促使学习者能力发生可验证的提升。
在“辩核 AI 具身辩论数字人系统”中,系统被明确定位为训练系统而非聊天产品,其核心差异并不体现在模型参数规模,而体现在模式设计、策略约束与反馈机制之中。本文将围绕辩论模式、陪练模式与教学模式三种核心形态,系统阐述其背后的设计逻辑与工程化实现思路。
1 引言:为什么模式设计决定系统上限
1.1 不同用户的不同训练需求
在实际应用中,系统的用户画像高度多样:有的是需要高强度对抗的辩论选手,有的是刚入门、需要引导的学习者,还有的是教师或教练,希望借助 AI 进行教学辅助。如果所有用户都被迫使用同一种对话方式,系统的价值将被严重削弱。
训练型 AI 的首要问题不是“模型会说什么”,而是“在什么训练目标下说什么”。
1.2 单一对话模式的天然局限
单一对话模式往往只能在某一个维度表现良好。例如,偏向对抗的模式容易让初学者产生挫败感,而偏向讲解的模式又难以满足高水平选手的训练强度需求。因此,模式分化并非功能堆叠,而是系统能力进化的前提。
在设计之初,系统即明确区分三种模式,其本质是对 AI 行为边界的重新定义。
2 辩论模式设计

2.1 自动立场对立机制
辩论模式的核心在于“对立”。系统在进入该模式后,会根据辩题与用户选择,自动锁定与用户相反的立场,并在整个回合中保持立场一致性。这一约束并非完全交由大模型自行推理,而是通过系统提示词与状态参数进行强绑定。
这种显性立场建模,避免了 AI 在长对话中出现立场漂移的问题。
2.2 高强度对抗策略
在辩论模式下,AI 的回复策略被设定为优先反驳与追问,而非解释与引导。系统会刻意放大用户论证中的漏洞,频繁使用质询、反证与假设反驳等方式,模拟真实比赛中的高压环境。
为了避免对抗失控,系统在策略层面引入了“攻击强度”阈值,用于限制语言风格,确保对抗集中于观点而非情绪。
2.3 多维度评分体系设计
辩论模式并不以“输赢”作为唯一结果,而是通过多维度指标对用户表现进行评估。下表展示了系统中常用的评分维度示例:
| 维度名称 | 评估重点 | 说明 |
|---|---|---|
| 立场一致性 | 是否自洽 | 是否出现自我矛盾 |
| 论证结构 | 逻辑完整度 | 是否具备论点—论据—论证 |
| 反驳质量 | 针对性 | 是否真正回应对方观点 |
| 表达清晰度 | 可理解性 | 是否简洁、有重点 |
这些评分并非即时裁决,而是作为训练反馈的一部分,帮助用户理解自身能力结构。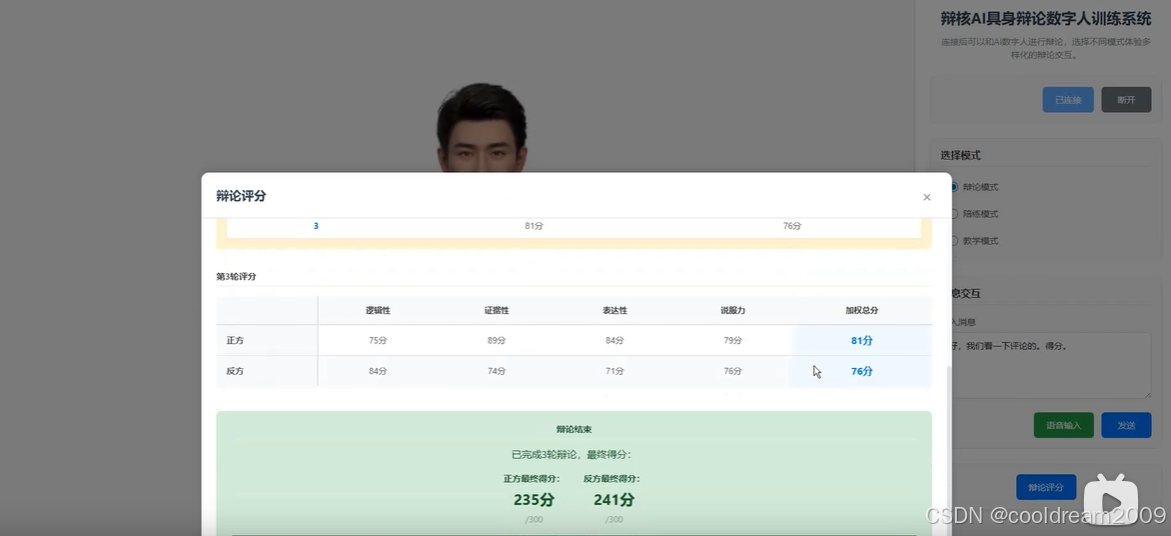
3 陪练模式设计
3.1 中等对抗强度的控制逻辑
陪练模式的目标并非压制用户,而是“托住”用户的表达过程。系统在该模式下会降低反驳强度,更多采用补充、提示与引导式追问,使对话保持一定挑战性但不至于中断用户思路。
在工程实现上,这一差异主要通过策略参数与提示词风格共同控制。
3.2 引用用户原文的点评方式
与泛泛而谈的评价不同,陪练模式强调“针对具体表达的反馈”。系统在生成点评时,会直接引用用户的原始表述片段,并指出其中的优点或可改进之处。
这种基于原文的点评方式,显著提升了反馈的可操作性,也更容易被用户接受。
3.3 可执行改进建议的生成策略
陪练模式下的建议并不追求宏观概括,而是强调“下一步怎么做”。例如,建议用户补充事实例证、调整论点顺序或简化句式。这类建议通常具有明确动作指向,便于用户在下一轮训练中立即实践。
4 教学模式设计
4.1 辩题拆解方法
教学模式面向的是系统性学习需求,其首要任务是帮助用户理解“一个辩题应该如何分析”。系统会从概念界定、价值冲突与现实背景等角度,对辩题进行层次化拆解。
这一过程强调方法论,而非直接给出结论。
4.2 正反方论证框架输出
在教学模式中,系统会同时给出正反双方的典型论证框架,帮助用户建立完整视角。框架本身以结构为主,内容为辅,避免用户直接背诵观点。
通过这种方式,用户学习到的是“如何搭建论证”,而不是“该支持哪一方”。
4.3 从“结论”到“思路”的转变
教学模式刻意弱化最终立场,强化推理路径。系统更关注论点如何生成、论据如何筛选、论证如何展开,从而引导用户形成可迁移的思维能力。
5 反馈系统的统一设计
5.1 不同模式的反馈差异
虽然三种模式目标不同,但反馈系统在结构上保持统一。差异主要体现在反馈内容的侧重点与呈现时机,而非反馈机制本身。
这种统一设计,有助于用户在不同模式间切换时保持认知连续性。
5.2 弹窗与表格的表达方式
即时反馈通常通过弹窗形式呈现,用于提示关键问题;阶段性总结则采用表格化方式,帮助用户从整体上审视表现。这种组合设计兼顾了即时性与系统性。
5.3 用户心理与正向激励
训练系统如果长期只指出问题,容易导致用户流失。因此,反馈机制中被刻意加入了正向强化元素,用于强调进步点与可持续改进空间。其目标并非安慰,而是维持训练动力。
6 模式切换与系统提示词策略
6.1 提示词即“AI 教练人格”
在系统内部,提示词并不只是上下文说明,而是对 AI 行为人格的定义。不同模式对应不同的“教练人格”,其语气、关注点与评价标准均有明确区分。
这一设计使模式切换不再是简单的功能开关,而是整体行为风格的切换。
6.2 模式与输出风格的强绑定
系统通过模式参数与提示词模板的强绑定,确保输出风格稳定一致,避免用户在训练过程中产生角色混乱感。这种稳定性,是训练系统可信度的重要来源。
7 小结
从辩论、陪练到教学,三种模式共同构成了一个完整的训练闭环。它们的差异并不体现在模型能力高低,而体现在对“训练目标”的理解深度上。
真正成熟的 AI 训练系统,关注的从来不是“能不能回答问题”,而是“是否能帮助用户进步”。当 AI 能够在不同模式下做到会对抗、会引导、会讲解、会评价,它才真正从聊天工具,演进为可用、可信、可持续的训练型智能系统。
参考资料
- 辩论教学与能力评估相关教育研究文献
- 智能教学系统(ITS)设计方法论资料
- 大语言模型在教育场景中的应用实践文章
- 人机协同训练系统设计相关研究

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 35
35 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)