LightVLA详解---通过可微分Token剪枝实现高效视觉-语言-动作模型
文章摘要: LightVLA提出了一种高效视觉-语言-动作模型框架,通过可微分token剪枝技术解决传统VLA模型的计算瓶颈问题。该模型采用双分支视觉编码器(DINOv2和SigLIP)提取互补特征,将2176维视觉token输入LLM解码器。相比传统方法,LightVLA显著降低了计算复杂度(从89.34 GFLOPs优化至更高效水平),在LIBERO基准测试上实现了更高任务成功率。创新性的to
1. 引言
随着人工智能技术的快速发展,机器人正在从传统的工业制造领域扩展到家庭服务、医疗护理、自动驾驶等更广泛的应用场景。在这一变革过程中,视觉-语言-动作(Vision-Language-Action,VLA)模型的出现标志着机器人智能化的重要里程碑。这类模型能够直接将视觉信息和自然语言指令转换为可执行的动作策略,为机器人提供了前所未有的理解和执行复杂任务的能力。
典型的VLA模型如OpenVLA,通过整合大型语言模型(LLM)的推理能力和视觉编码器的感知能力,实现了对复杂机器人操作任务的端到端学习。这些模型在LIBERO等基准测试上展现了令人印象深刻的性能,能够完成"拿起牛奶并将其放入篮子"这样需要多步骤推理的复杂任务。然而,VLA模型的成功也带来了新的挑战。由于这些模型通常包含数十亿参数的大型语言模型(如基于LLaMA-2-7B的模型),其计算复杂度极高,特别是在处理大量视觉token时需要进行昂贵的注意力机制计算。
具体而言,一张224×224的输入图像经过ViT编码后会产生256个patch token,加上CLS token总计257个视觉token。在典型的LIBERO任务中,视觉token数量(257个)远大于语言token数量(约20-30个),而LLM的Transformer解码器需要对所有这些token进行自注意力计算,其复杂度为O(n²)。完整的LLaMA-2-7B模型包含32层解码器,每层都需要处理这些token,导致总计算量达到约89.34 GFLOPs。此外,模型在推理时需要12-16GB的GPU显存,单次前向传播延迟可能达到200-300毫秒,这远远无法满足实时机器人控制的需求。
2025年9月,来自理想汽车、清华大学和中科院计算所的研究团队发表了题为The Better You Learn, The Smarter You Prune: Towards Efficient Vision-language-action Models via Differentiable Token Pruning"的重要论文,提出了LightVLA框架,为解决这一关键问题提供了创新性的解决方案。相关代码也已经开源了:Github
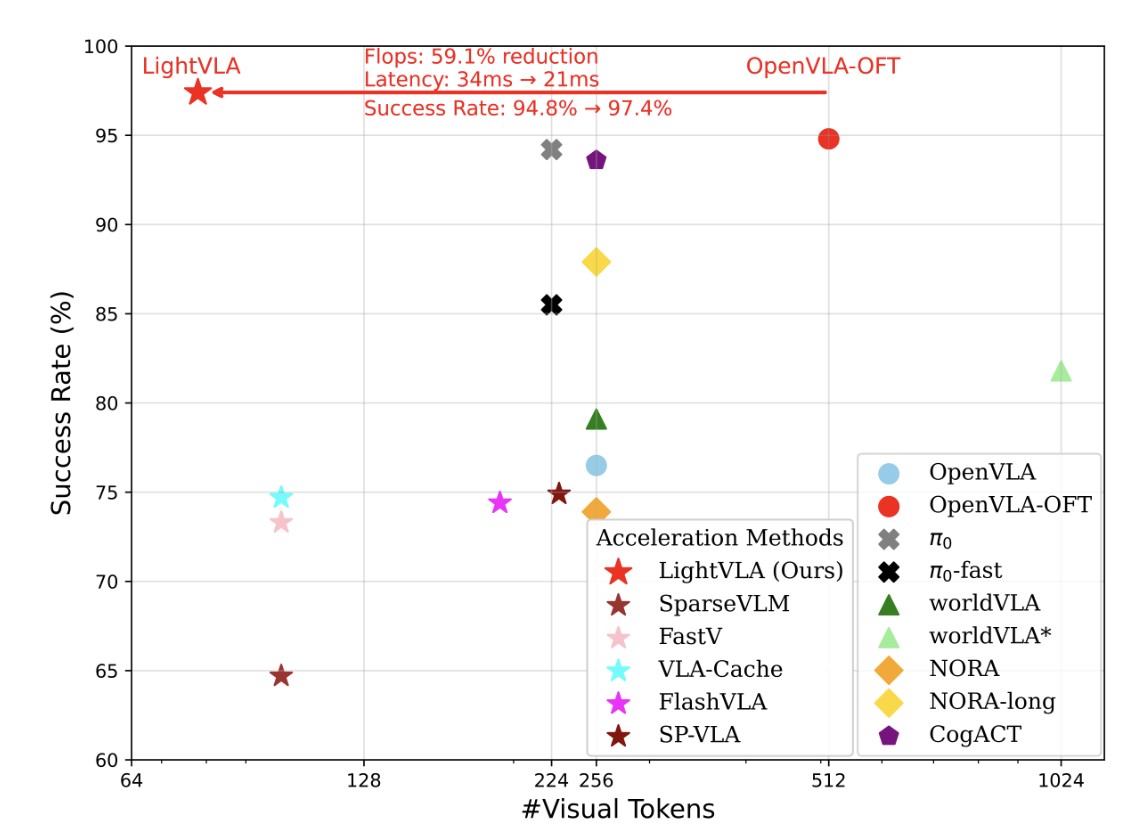
图1:LightVLA在LIBERO基准测试上的性能对比。LightVLA以更少的视觉token数量实现了更高的任务成功率和显著降低的计算开销。
2. VLA模型架构与计算瓶颈深度分析
2.1 VLA模型的基本架构概述
在深入理解LightVLA的创新之前,我们需要首先了解传统VLA模型的工作原理。一个典型的VLA模型(以OpenVLA为例)本质上是一个多模态的深度学习系统,它能够同时处理视觉信息、自然语言指令,并输出机器人可执行的动作。这个系统的核心挑战在于如何有效地融合不同模态的信息,并在保证性能的前提下控制计算开销。整个VLA模型可以分解为三个核心组件,它们相互配合完成从感知到决策的完整流程。
2.1.1 视觉编码器(Vision Encoder):将图像转换为token序列
视觉编码器是VLA模型的第一个关键组件,它的任务是将原始的RGB图像转换为一系列可以被语言模型理解的token。这个过程类似于人类视觉系统将光信号转换为神经信号的过程。在LightVLA的实现中,采用了一个创新的双分支视觉编码器架构,这种设计能够从不同角度提取图像特征,从而获得更丰富的视觉表示。
双分支架构的设计理念:
为什么需要两个分支而不是一个?这是因为不同的视觉模型在训练过程中学到了不同类型的特征。具体来说:
-
DINOv2分支:这是一个通过自监督学习训练的视觉模型,它擅长捕获图像的语义特征。例如,它能够很好地识别"这是一个杯子"、"这是一张桌子"这样的高层语义信息。DINOv2在物体识别和场景理解方面表现出色,这对于机器人理解环境中的物体至关重要。
-
SigLIP分支:这是一个专门针对视觉-语言对齐训练的模型,它的优势在于理解视觉内容和语言描述之间的关系。例如,当指令说"红色的杯子"时,SigLIP能够更好地关注图像中与"红色"和"杯子"这些词语相关的视觉区域。
这两个分支的特征在最后会被拼接在一起,形成一个综合的视觉表示。这种设计虽然增加了一些计算开销,但显著提升了模型对复杂场景的理解能力。
class PrismaticVisionBackbone(nn.Module):
"""
视觉骨干网络,支持双分支融合
对于融合骨干,SigLIP和DINOv2的特征在特征维度上拼接
"""
def __init__(
self,
use_fused_vision_backbone: bool,
image_sizes: List[int],
timm_model_ids: List[str],
timm_override_act_layers: List[Optional[str]],
) -> None:
super().__init__()
self.use_fused_vision_backbone = use_fused_vision_backbone
# 创建主要特征提取器 (SigLIP)
self.featurizer = timm.create_model(
timm_model_ids[0],
pretrained=False,
num_classes=0, # 移除分类头
img_size=image_sizes[0],
act_layer=timm_override_act_layers[0],
)
self.embed_dim = self.featurizer.embed_dim
# 创建次要特征提取器 (DINOv2)
if self.use_fused_vision_backbone:
self.fused_featurizer = timm.create_model(
timm_model_ids[1],
pretrained=False,
num_classes=0,
img_size=image_sizes[1],
act_layer=timm_override_act_layers[1],
)
self.embed_dim += self.fused_featurizer.embed_dim
def forward(self, pixel_values: torch.Tensor) -> torch.Tensor:
"""
前向传播
Args:
pixel_values: [B, 2*3, H, W] 对于融合骨干
[B, 3, H, W] 对于单一骨干
Returns:
patches: [B, num_patches, embed_dim]
"""
if not self.use_fused_vision_backbone:
return self.featurizer(pixel_values)
# 分割像素值为两个分支
img, img_fused = torch.split(pixel_values, [3, 3], dim=1)
# 提取两个分支的特征
patches = self.featurizer(img) # SigLIP特征
patches_fused = self.fused_featurizer(img_fused) # DINOv2特征
# 在特征维度上拼接
return torch.cat([patches, patches_fused], dim=2)
视觉token的生成过程详解:
理解token的概念对于理解整个VLA系统至关重要。Token本质上是一个向量,它包含了图像某个局部区域的信息。对于224×224的输入图像,使用patch size为14的Vision Transformer(ViT)模型进行处理时,整个过程如下:
-
图像分割:首先,224×224的图像被分割成14×14像素的小块(patch)。简单计算可知,224÷14=16,因此每个维度上有16个patch,总共产生16×16=256个patch。
-
Token化:每个patch被展平成一个向量,然后通过一个线性投影层转换成token。此外,Vision Transformer还会添加一个特殊的CLS(classification)token在序列开头,用于汇总全局信息。因此总共有257个视觉token。
-
特征融合:这是双分支架构的关键步骤。两个分支分别输出不同维度的特征:
-
SigLIP分支的维度计算:LightVLA使用的是
vit_so400m_patch14_siglip_224模型,这是一个SigLIP-SO400M(Sigmoid Loss for Language-Image Pre-training, Small-Optimized 400M参数版本)架构。在Vision Transformer的命名规范中,"SO"表示一种特殊的架构变体,其隐藏维度(embed_dim)为1152。这个维度是由模型架构预先定义的,具体来说是Transformer编码器中每个token的表示维度。 -
DINOv2分支的维度计算:使用的是
vit_large_patch14_reg4_dinov2.lvd142m模型,这是DINOv2的Large变体(ViT-L)。在标准Vision Transformer架构中,Large变体的隐藏维度为1024。"reg4"表示使用了4个寄存器token(用于提升性能的技术细节),但这不影响每个patch token的维度。 -
维度拼接:两个分支的特征在最后一个维度(特征维度)上进行拼接。因此,每个token的最终维度 = 1152(SigLIP)+ 1024(DINOv2)= 2176。
-
这些维度由模型的内部结构决定,包括注意力头数量、每个头的维度、前馈网络的大小等因素。例如,ViT-Large使用16个注意力头,每个头的维度为64,因此总的embed_dim = 16 × 64 = 1024。
这意味着,一张简单的输入图像最终会被表示为一个形状为**[257, 2176]**的矩阵,其中257是token数量(256个patch + 1个CLS token),2176是每个token的特征维度(1152 + 1024)。这个矩阵将被送入后续的投影器模块进行进一步处理。
2.1.2 视觉投影器(Vision Projector):桥接视觉和语言
视觉投影器是连接视觉编码器和语言模型的桥梁。它的作用是将视觉特征投影到语言模型的嵌入空间,使得视觉信息能够被语言模型"理解"。这个过程类似于翻译,将视觉的"语言"翻译成文本的"语言"。
为什么需要投影器?
视觉编码器输出的特征维度(2176)与语言模型期望的输入维度(4096)不匹配,而且两者的特征分布也完全不同。视觉特征关注的是颜色、纹理、形状等视觉属性,而语言模型的嵌入空间关注的是语义关系。投影器通过一个多层感知机(MLP)网络,将视觉特征映射到语言模型的嵌入空间,同时也进行特征的语义对齐。
class PrismaticProjector(nn.Module):
"""
将视觉特征投影到LLM嵌入空间
"""
def __init__(
self,
use_fused_vision_backbone: bool,
vision_dim: int, # 2176 (SigLIP 1152 + DINOv2 1024)
llm_dim: int # 4096 (LLaMA-2-7B的隐藏维度)
) -> None:
super().__init__()
self.use_fused_vision_backbone = use_fused_vision_backbone
self.vision_dim, self.llm_dim = vision_dim, llm_dim
if self.use_fused_vision_backbone:
# 对于融合骨干,使用三层MLP
initial_projection_dim = 4 * vision_dim # 8704
self.fc1 = nn.Linear(self.vision_dim, initial_projection_dim, bias=True)
self.fc2 = nn.Linear(initial_projection_dim, self.llm_dim, bias=True)
self.fc3 = nn.Linear(self.llm_dim, self.llm_dim, bias=True)
self.act_fn1 = nn.GELU()
self.act_fn2 = nn.GELU()
else:
# 对于单一骨干,使用两层MLP
self.fc1 = nn.Linear(self.vision_dim, self.llm_dim, bias=True)
self.fc2 = nn.Linear(self.llm_dim, self.llm_dim, bias=True)
self.act_fn1 = nn.GELU()
def forward(self, img_patches: torch.Tensor) -> torch.Tensor:
"""
Args:
img_patches: [B, num_patches, vision_dim]
Returns:
projected_features: [B, num_patches, llm_dim]
"""
if not self.use_fused_vision_backbone:
projected_features = self.fc1(img_patches)
projected_features = self.act_fn1(projected_features)
projected_features = self.fc2(projected_features)
else:
projected_features = self.fc1(img_patches)
projected_features = self.act_fn1(projected_features)
projected_features = self.fc2(projected_features)
projected_features = self.act_fn2(projected_features)
projected_features = self.fc3(projected_features)
return projected_features
投影器的网络结构:
在LightVLA的实现中,投影器使用了一个三层MLP网络。第一层将2176维的视觉特征投影到一个更高维的中间表示(8704维,即4倍的视觉维度),然后通过GELU激活函数引入非线性,接着投影到语言模型的维度(4096维),再经过一次GELU激活,最后通过第三层确保特征的稳定性。这种设计虽然看起来复杂,但每一步都有其作用:高维中间表示允许模型学习更复杂的特征转换,而多次非线性激活则确保了视觉和语言特征的充分融合。
经过投影器处理后,原本的[257, 2176]的视觉特征矩阵被转换为[257, 4096]的矩阵,这样就可以和语言token(同样是4096维)进行拼接了。
2.1.3 语言模型主干(LLM Backbone):理解和推理的核心
语言模型主干是整个VLA系统的"大脑",负责理解视觉和语言输入,并进行推理决策。LightVLA基于OpenVLA-OFT,使用LLaMA-2-7B作为语言模型主干。这是一个包含70亿参数的大型Transformer模型,它的设计遵循了经典的decoder-only架构。
LLaMA-2-7B的架构细节:
- 隐藏维度(hidden_size):4096 - 这是每个token的表示维度,所有的视觉token和语言token都会被统一到这个维度
- 解码器层数(num_hidden_layers):32 - 模型包含32层Transformer解码器,每一层都会对输入序列进行处理和提炼
- 注意力头数(num_attention_heads):32 - 每层的自注意力机制被分成32个头,每个头关注输入的不同方面
- 中间层维度(intermediate_size):11008 - 在前馈神经网络(FFN)中,特征会先被投影到11008维,这约是隐藏维度的2.7倍
- 词汇表大小(vocab_size):32000 - 语言模型可以识别和生成32000个不同的token
工作流程详解:
当视觉token(257个)和语言token(约25个)被拼接成一个长度约282的序列后,这个序列会依次通过32层Transformer解码器。在每一层中,发生以下操作:
-
自注意力计算:每个token都会与序列中的所有其他token计算注意力分数,这使得模型能够理解token之间的关系。例如,表示"牛奶"的视觉token会与表示"拿起"的语言token建立关联。
-
前馈网络处理:注意力层的输出会经过一个前馈神经网络进行非线性变换,这有助于模型学习更复杂的特征表示。
-
残差连接和归一化:每个子层都使用残差连接和层归一化,这些技术确保了深层网络的稳定训练。
这32层的堆叠使得模型能够逐步提炼和抽象信息。浅层可能关注简单的视觉特征和词汇关系,而深层则能够理解复杂的语义和执行推理。
2.1.4 动作头(Action Head):从理解到执行
动作头是VLA系统的最后一个组件,它负责将语言模型的抽象理解转换为机器人可以执行的具体动作。在机器人学中,动作通常表示为一个向量,包含了关节角度、末端执行器位置、抓取器开合状态等信息。
L1回归动作头的设计:
LightVLA使用L1回归方式生成连续动作。具体来说,它会提取语言模型最后一层输出序列的最后一个token(这个token被认为包含了所有的决策信息),然后通过一个线性层将其投影到动作空间。对于LIBERO任务,动作维度是7,包括:
- 3维的位置增量(x, y, z方向的移动)
- 3维的旋转增量(通过axis-angle表示)
- 1维的抓取器状态(开或关)
为了确保动作值在合理范围内,模型会对输出应用tanh激活函数,将动作限制在[-1, 1]区间。在实际执行前,这些归一化的动作会根据数据集统计信息进行反归一化,转换为真实的物理量。
class L1RegressionActionHead(nn.Module):
"""
L1回归动作头 - 用于连续动作预测
"""
def __init__(
self,
llm_dim=4096,
action_dim=7, # LIBERO任务的动作维度
num_actions_chunk=1 # 动作块大小
):
super().__init__()
self.action_dim = action_dim
self.num_actions_chunk = num_actions_chunk
# 动作预测投影层
self.action_proj = nn.Linear(
llm_dim,
action_dim * num_actions_chunk
)
def forward(self, hidden_states):
"""
Args:
hidden_states: [B, seq_len, 4096] LLM输出的隐藏状态
Returns:
actions: [B, num_actions_chunk, action_dim] 预测的动作序列
"""
# 提取最后一个token的隐藏状态作为动作表示
last_hidden = hidden_states[:, -1, :] # [B, 4096]
# 投影到动作空间
actions = self.action_proj(last_hidden) # [B, action_dim * num_actions_chunk]
actions = actions.view(-1, self.num_actions_chunk, self.action_dim)
# 应用tanh激活,将动作限制在[-1, 1]范围
actions = torch.tanh(actions)
return actions
2.2 计算瓶颈的量化分析:为什么VLA模型这么慢?
理解了VLA模型的架构后,我们需要深入分析它为什么计算开销如此巨大。这对于理解LightVLA的优化策略至关重要。简单来说,计算瓶颈主要来自于Transformer中的自注意力机制,而视觉token的大量存在使得这个问题被成倍放大。
2.2.1 注意力机制的计算复杂度详解
在LLM主干的每一层中,自注意力机制是主要的计算瓶颈。要理解为什么,我们需要先了解注意力机制是如何工作的。
自注意力的计算过程:
对于一个包含n个token的序列,每个token的维度为d,自注意力机制需要执行以下步骤:
-
Query、Key、Value投影:每个token都需要通过三个不同的线性层生成Query(查询)、Key(键)、Value(值)向量。这一步的计算量是3 × n × d²。
-
注意力分数计算:每个Query需要与所有Key计算相似度,得到n×n的注意力分数矩阵。这一步的计算量是2 × n² × d(包括矩阵乘法和缩放)。
-
Value加权求和:根据注意力分数对Value进行加权求和。这一步的计算量是2 × n² × d。
-
输出投影:最后通过一个线性层将结果投影回原始维度。这一步的计算量是n × d²。
将这些步骤加起来,单层注意力的总计算量为:
F L O P s a t t e n t i o n = 4 × n 2 × d + 4 × n × d 2 FLOPs_{attention} = 4 × n² × d + 4 × n × d² FLOPsattention=4×n2×d+4×n×d2
关键观察:二次复杂度的影响
注意公式中的n²项——这意味着计算量随序列长度的平方增长。当n=282(257个视觉token + 25个语言token)时,n²=79,524。而如果我们能把视觉token减少到105个,那么n=130,n²=16,900,仅为原来的21.3%!这就是为什么减少token数量能够带来如此显著的效率提升。
完整模型的计算量:
对于LightVLA使用的LLaMA-2-7B模型:
- 序列长度 n = 282(257个视觉token + 25个语言token)
- 隐藏维度 d = 4096
- 层数 L = 32
- 前馈网络中间维度 = 11008
完整的计算量包括注意力层和前馈网络层:
def calculate_flops(
num_visual_tokens=257,
num_text_tokens=25,
hidden_dim=4096,
num_layers=32,
intermediate_size=11008
):
"""计算VLA模型的总FLOPs"""
n = num_visual_tokens + num_text_tokens # 总序列长度
d = hidden_dim
# 单层注意力FLOPs
# Q, K, V投影: 3 * n * d²
# 注意力计算: 2 * n² * d
# 输出投影: n * d²
attention_flops = 4 * n**2 * d + 4 * n * d**2
# FFN FLOPs (两个线性层)
# 第一个线性层: n * d * intermediate_size
# 第二个线性层: n * intermediate_size * d
ffn_flops = 2 * n * d * intermediate_size
# 单层总FLOPs
layer_flops = attention_flops + ffn_flops
# 所有层的总FLOPs
total_flops = layer_flops * num_layers
return total_flops
# 原始OpenVLA-OFT的FLOPs
original_flops = calculate_flops(257, 25, 4096, 32)
print(f"原始模型FLOPs: {original_flops / 1e9:.2f} GFLOPs")
# LightVLA平均保留105个视觉token后的FLOPs
lightvla_flops = calculate_flops(105, 25, 4096, 32)
print(f"LightVLA FLOPs: {lightvla_flops / 1e9:.2f} GFLOPs")
print(f"FLOPs减少: {(1 - lightvla_flops/original_flops) * 100:.1f}%")
输出结果:
原始模型FLOPs: 89.34 GFLOPs
LightVLA FLOPs: 36.52 GFLOPs
FLOPs减少: 59.1%
这一计算结果与论文报告的59.1% FLOPs减少完全一致,验证了LightVLA的计算效率提升。
2.2.2 内存占用分析:为什么需要16GB显存?
除了计算量,内存占用也是VLA模型部署的一大障碍。很多边缘设备(如机器人上的嵌入式GPU)只有4-8GB显存,而VLA模型却需要12-16GB,这使得实际部署变得困难。让我们详细分析内存都用在了哪里。
VLA模型的内存组成:
内存占用主要分为三个部分,每个部分都不可忽视:
-
模型参数(约13.1GB):LLaMA-2-7B有约70亿个参数,使用半精度浮点数(FP16,每个参数2字节)存储时需要约13.1GB内存。这部分是固定的,无论序列长度如何都需要这么多内存。
-
激活值(动态,与序列长度相关):在前向传播过程中,每一层都需要存储中间结果(激活值),用于后续层的计算。对于序列长度282、32层的模型,这部分可能需要2-3GB内存。关键是,这部分内存随序列长度线性增长——序列越长,需要的内存越多。
-
KV缓存(动态,与序列长度相关):这是一个特殊的优化技术。在生成动作时,模型会缓存每一层的Key和Value矩阵,避免重复计算。但是,每个token的K和V都需要存储,所以这部分内存也随序列长度增长。对于282个token,32层模型,这部分大约需要1-2GB。
def calculate_memory_usage(
batch_size=1,
num_tokens=282,
hidden_dim=4096,
num_layers=32,
dtype_bytes=2 # FP16使用2字节
):
"""计算内存使用(单位:GB)"""
# 模型参数(FP16)
model_params_gb = 7e9 * dtype_bytes / 1024**3 # 约13.1GB
# 激活值(FP16)
# 每层需要存储:input, attention output, FFN intermediate, FFN output
activations_per_layer = batch_size * num_tokens * hidden_dim * 4
total_activations = activations_per_layer * num_layers * dtype_bytes / 1024**3
# KV缓存(FP16)
# 每层存储K和V,每个形状为[batch_size, num_heads, seq_len, head_dim]
# head_dim = hidden_dim / num_heads = 4096 / 32 = 128
kv_cache_per_layer = 2 * batch_size * num_tokens * hidden_dim
total_kv_cache = kv_cache_per_layer * num_layers * dtype_bytes / 1024**3
total_gb = model_params_gb + total_activations + total_kv_cache
return {
'model_params_gb': model_params_gb,
'activations_gb': total_activations,
'kv_cache_gb': total_kv_cache,
'total_gb': total_gb
}
# 原始模型
original_mem = calculate_memory_usage(1, 282)
print(f"原始模型内存使用:")
print(f" 模型参数: {original_mem['model_params_gb']:.2f} GB")
print(f" 激活值: {original_mem['activations_gb']:.2f} GB")
print(f" KV缓存: {original_mem['kv_cache_gb']:.2f} GB")
print(f" 总计: {original_mem['total_gb']:.2f} GB")
# LightVLA
lightvla_mem = calculate_memory_usage(1, 130) # 105+25
print(f"\nLightVLA内存使用:")
print(f" 模型参数: {lightvla_mem['model_params_gb']:.2f} GB")
print(f" 激活值: {lightvla_mem['activations_gb']:.2f} GB")
print(f" KV缓存: {lightvla_mem['kv_cache_gb']:.2f} GB")
print(f" 总计: {lightvla_mem['total_gb']:.2f} GB")
print(f" 内存节省: {(1 - lightvla_mem['total_gb']/original_mem['total_gb']) * 100:.1f}%")
3. LightVLA核心技术原理
3.1 Token剪枝框架总体设计
LightVLA提出了一个创新的基于查询的视觉token剪枝策略。核心思想是:生成动态查询来评估每个视觉token的重要性,并通过可微分的方式选择最有价值的token。整个剪枝过程可以分为三个关键步骤:
- 查询生成(Query Generation):通过视觉token和语言token之间的交叉注意力生成查询
- Token评分(Token Scoring):每个查询为所有视觉token打分
- Token选择(Token Selection):使用Gumbel-Softmax实现可微分的token选择
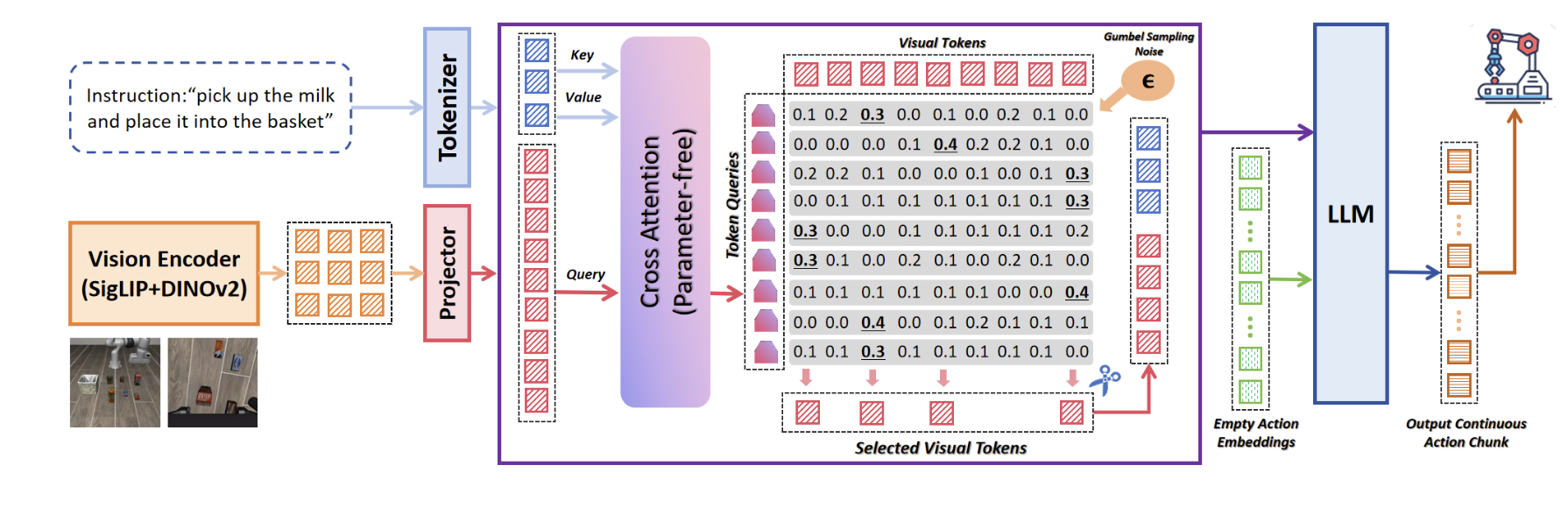
图2:LightVLA的整体架构。灰色区域表示使用Gumbel-Softmax进行可微分token选择的部分。
3.2 TokenPruner的实现细节
下面是LightVLA中TokenPruner的完整实现,这是项目的核心组件:
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class TokenPruner(nn.Module):
"""
LightVLA的核心组件:可微分Token剪枝器
该模块负责从视觉token中选择最重要的token,同时保持可微分性以支持端到端训练。
关键特性:
- 无额外可训练参数
- 使用Gumbel-Softmax实现可微分采样
- 动态调整保留的token数量
"""
def __init__(self, config, num_patches):
"""
Args:
config: 模型配置,包含hidden_size等参数
num_patches: patch token的数量(不包括CLS token)
"""
super().__init__()
self.num_patches = num_patches
self.noise_scale = None # Gumbel噪声的尺度
self.scale_factor = 1 / math.sqrt(config.hidden_size)
def set_noise_scale(self, noise_scale):
"""设置Gumbel噪声尺度(训练时动态调整)"""
self.noise_scale = noise_scale
def rms_norm(self, hidden_states, eps=1e-6):
"""
RMS归一化 - 用于稳定训练
RMS归一化比Layer Norm更简单,只使用均方根进行归一化,
不需要计算均值和方差,计算效率更高
Args:
hidden_states: 输入张量 [B, N, D]
eps: 防止除零的小常数
Returns:
归一化后的张量
"""
input_dtype = hidden_states.dtype
hidden_states = hidden_states.to(torch.float32)
variance = hidden_states.pow(2).mean(-1, keepdim=True)
hidden_states = hidden_states * torch.rsqrt(variance + eps)
return hidden_states.to(input_dtype)
def get_score(self, patches, prompts):
"""
计算token评分矩阵
这是LightVLA的核心创新之一:通过视觉token和语言token之间的
交叉注意力生成查询,然后用查询来评估每个视觉token的重要性
Args:
patches: [B, num_patches, D] 视觉patch token
prompts: [B, prompt_len, D] 语言prompt token
Returns:
score: [B, num_patches, num_patches] 评分矩阵
"""
# 归一化输入
patches = self.rms_norm(patches)
prompts = self.rms_norm(prompts)
# 通过交叉注意力生成查询
# queries[i,j] 表示第i个patch关注第j个prompt后的表示
queries = F.scaled_dot_product_attention(patches, prompts, prompts)
queries = self.rms_norm(queries)
# 计算查询和patch之间的相似度作为评分
# score[i,j,k] 表示第i个样本中,第j个查询对第k个patch的评分
score = queries @ patches.transpose(-2, -1) * self.scale_factor
return score
def score_to_mask(self, score):
"""
在推理时将评分转换为二值掩码
这个方法只在推理时使用,通过argmax选择每个查询得分最高的token,
并随机丢弃10%的选中token以增加鲁棒性
Args:
score: [B, num_patches, num_patches] 评分矩阵
Returns:
mask: [B, num_patches] 布尔掩码,True表示保留的token
"""
bsz = score.shape[0]
# 初始化全False的掩码
mask = torch.zeros(bsz, self.num_patches, dtype=torch.bool, device=score.device)
# 对每个查询,选择得分最高的token
indices = score.argmax(-1) # [B, num_patches]
batch_indices = torch.arange(bsz, device=score.device).unsqueeze(1).expand_as(indices)
# 将选中的token设为True
mask[batch_indices, indices] = True
# 随机丢弃10%的token以增加鲁棒性
rand_mask = torch.rand(bsz, self.num_patches, device=score.device) > 0.9
mask[rand_mask] = False
return mask
def score_to_indices(self, score, patches):
"""
在训练时使用Gumbel-Softmax实现可微分的token选择
这是LightVLA的核心创新:通过Gumbel-Softmax使得离散的argmax操作
在反向传播时可微分,从而能够端到端地训练整个模型
Args:
score: [B, num_patches, num_patches] 评分矩阵
patches: [B, num_patches, D] 视觉patch token
Returns:
indices: [B, num_patches] 选中的token索引
pruned_patches: [B, num_patches, D] 剪枝后的patch token
"""
# 注入Gumbel噪声
if self.noise_scale is not None:
score = score + torch.rand_like(score) * self.noise_scale
# 硬选择:使用argmax + one-hot编码
hard_score = F.one_hot(
score.argmax(dim=-1),
num_classes=self.num_patches
).float()
# 软选择:使用softmax
soft_score = torch.softmax(score, dim=-1)
# Straight-through estimator:
# 前向传播使用硬选择,反向传播使用软选择的梯度
score = hard_score + soft_score - soft_score.detach()
# 根据选择结果提取对应的patch
indices = score.argmax(dim=-1)
pruned_patches = score @ patches
return indices, pruned_patches
def forward(self, tokens, position_ids, attention_mask):
"""
TokenPruner的主要前向传播逻辑
该方法将输入token序列分为三部分:
1. CLS token(始终保留)
2. Patch tokens(需要剪枝)
3. Task tokens(语言指令,始终保留)
Args:
tokens: [B, seq_len, D] 输入token序列
position_ids: [B, seq_len] 位置ID
attention_mask: [B, seq_len] 注意力掩码
Returns:
tokens: [B, pruned_seq_len, D] 剪枝后的token序列
position_ids: [B, pruned_seq_len] 剪枝后的位置ID
attention_mask: [B, pruned_seq_len] 剪枝后的注意力掩码
"""
bsz, seq_len, dim = tokens.shape
# 分割token序列为三个部分
cls_token, patches, task = torch.split(
tokens,
[1, self.num_patches, seq_len - self.num_patches - 1],
dim=1
)
# 分割位置ID
cls_token_id, patches_id, task_id = torch.split(
position_ids,
[1, self.num_patches, seq_len - self.num_patches - 1],
dim=1
)
# 分割注意力掩码
if attention_mask is not None:
cls_token_mask, patches_mask, task_mask = torch.split(
attention_mask,
[1, self.num_patches, seq_len - self.num_patches - 1],
dim=1
)
# 计算token评分
score = self.get_score(patches, task)
if not self.training:
# 推理时:使用确定性的掩码选择
mask = self.score_to_mask(score)
# 根据掩码提取保留的patch
patches = patches[mask].view(bsz, -1, dim)
tokens = torch.cat([cls_token, patches, task], dim=1)
# 更新位置ID
patches_id = patches_id[mask].view(bsz, -1)
position_ids = torch.cat([cls_token_id, patches_id, task_id], dim=1)
# 更新注意力掩码
if attention_mask is not None:
patches_mask = patches_mask[mask].view(bsz, -1)
attention_mask = torch.cat([cls_token_mask, patches_mask, task_mask], dim=1)
else:
# 训练时:使用Gumbel-Softmax进行可微分选择
indices, patches = self.score_to_indices(score, patches)
batch_indices = torch.arange(bsz, device=patches.device).unsqueeze(1).expand_as(indices)
# 重新组合token序列
tokens = torch.cat([cls_token, patches, task], dim=1)
# 更新位置ID
patches_id = patches_id[batch_indices, indices].view(bsz, -1)
position_ids = torch.cat([cls_token_id, patches_id, task_id], dim=1)
# 更新注意力掩码
if attention_mask is not None:
patches_mask = patches_mask[batch_indices, indices].view(bsz, -1)
attention_mask = torch.cat([cls_token_mask, patches_mask, task_mask], dim=1)
return tokens, position_ids, attention_mask
3.3 PrunedLlamaModel的集成
…详情请参照古月居

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 14
14 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)