GENMANIP:基于LLM的通用指令跟随操作仿真
25年6月来自上海AI实验室、西安交大、浙大和南京大学的论文“GENMANIP: LLM-driven Simulation for Generalizable Instruction-Following Manipulation”。在真实世界环境中进行机器人操作仍然充满挑战,尤其是在鲁棒泛化方面。现有的仿真平台缺乏足够的支持来探索策略如何适应不同的指令和场景。因此,它们落后于人们对指令-跟随基础
25年6月来自上海AI实验室、西安交大、浙大和南京大学的论文“GENMANIP: LLM-driven Simulation for Generalizable Instruction-Following Manipulation”。
在真实世界环境中进行机器人操作仍然充满挑战,尤其是在鲁棒泛化方面。现有的仿真平台缺乏足够的支持来探索策略如何适应不同的指令和场景。因此,它们落后于人们对指令-跟随基础模型(例如LLM)日益增长的兴趣,而LLM的适应性至关重要,但在公平的比较中仍未得到充分研究。为了弥补这一差距,推出GENMANIP,一个专为策略泛化研究而设计的逼真桌面仿真平台。它具有一个自动化流程,该流程通过LLM驱动面向任务的场景图,利用1万个带注释的3D目标资源合成大规模、多样化的任务。为了系统地评估泛化能力,提出GENMANIP-BENCH,这是一个包含200个场景的基准测试,这些场景通过人机交互修正进行优化。评估两种策略类型:(1)集成感知、推理和规划基础模型的模块化操作系统;(2)通过可扩展数据收集训练的端到端策略。结果表明,虽然数据规模化有利于端到端方法,但采用基础模型增强的模块化系统在各种场景下能更有效地进行泛化。
GENMANIP是一个逼真的大规模桌面仿真平台,专为评估通用机器人在各种场景和指令下的性能而设计。如图所示,GENMANIP拥有丰富的3D目标资源、一种名为面向任务场景图(ToSG)的标准化范式,以及一个由LLM驱动的自动任务生成流程。ToSG提供一种可扩展且结构化的任务相关目标表示方法,其理念类似于PDDL[1]的自然语言适配,它将弥补级关系和空间关系显式地编码为图中的节点和边。重要的是,ToSG结构与LLM完全兼容,从而可以灵活地访问特权场景信息。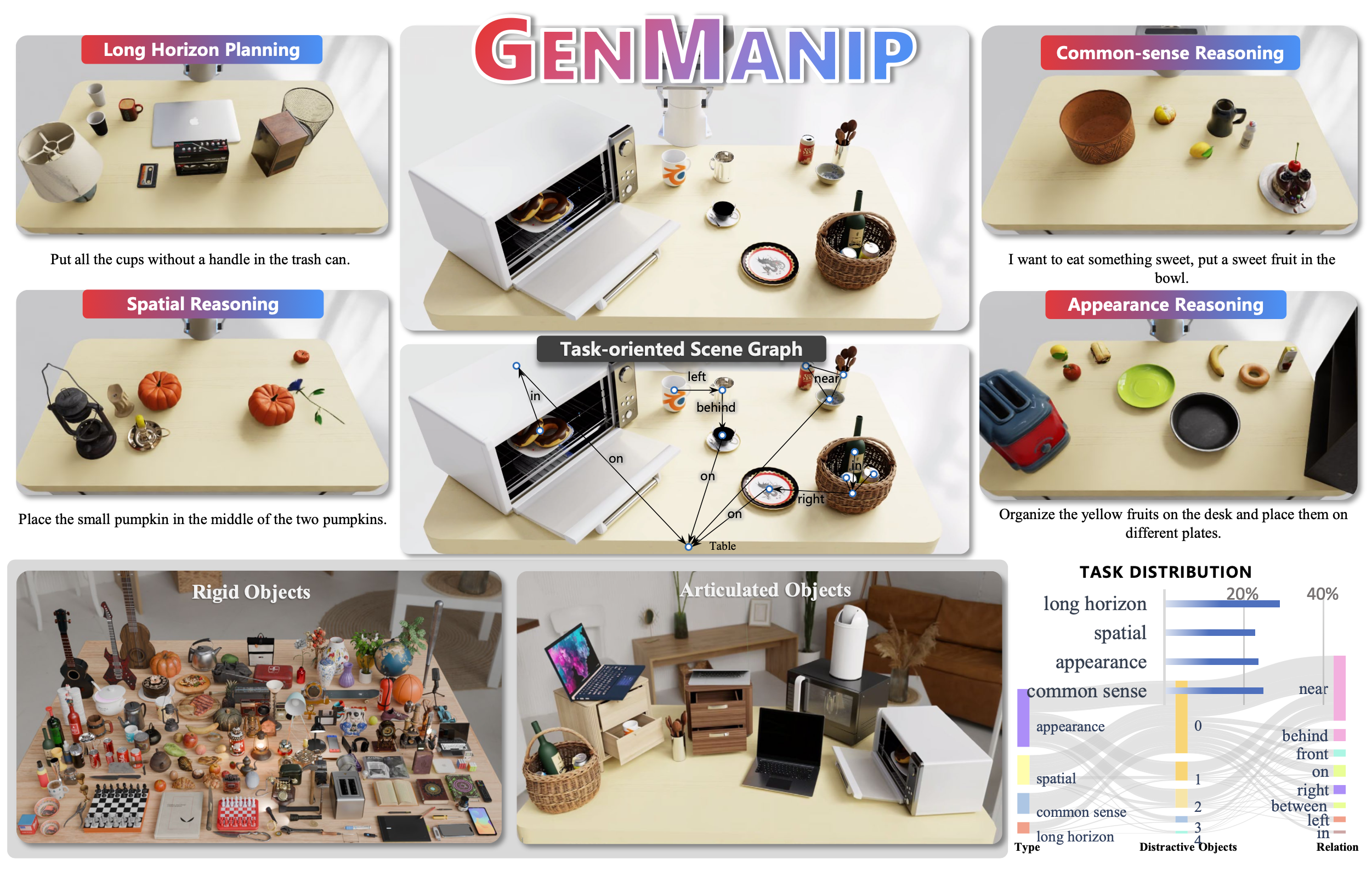
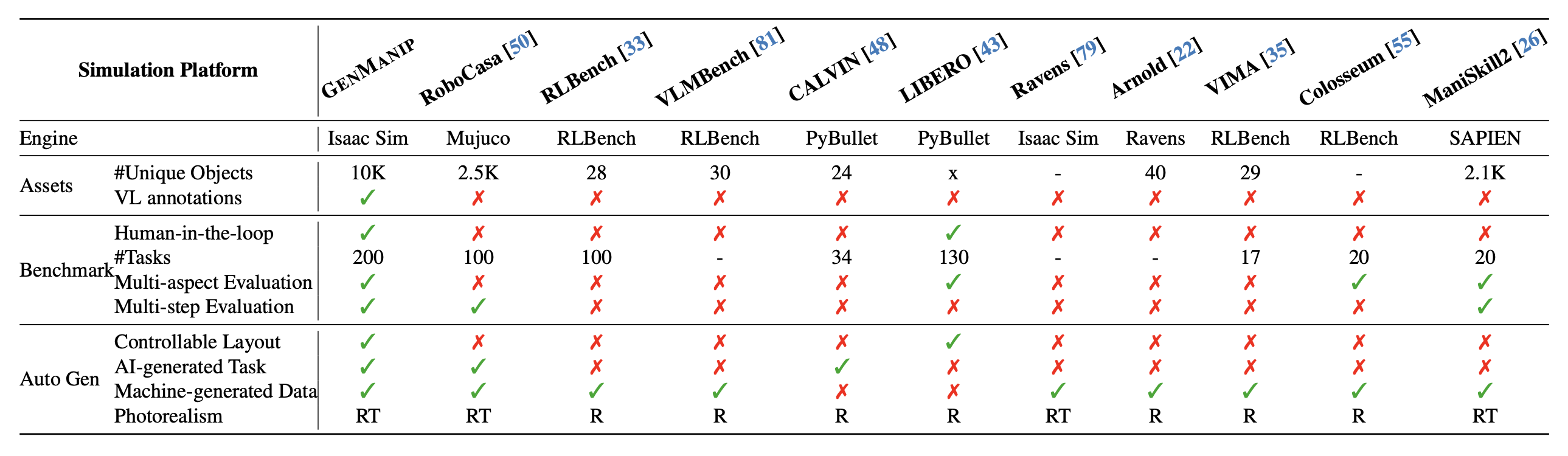
GENMANIP-BENCH 是一个基于 GENMANIP 生成场景构建的综合基准测试平台。如表所示,GENMANIP-BENCH 提供可控的布局和多维评估标准,用于评估策略在物体外观、常识知识、空间关系和长期任务完成方面的泛化能力。为了支持全面的基准测试,GENMANIP-BENCH 包含 200 个由人工精心设计的真实场景,并且具有可扩展性和适应性,能够满足各种机器人研究方向的需求。
仿真平台设置
GENMANIP 基于 NVIDIA 的 IsaacSim [46] 构建,充分利用其逼真的渲染效果和高效的并行数据采集能力。
带有 VL 标注的刚体模型。在各种操作任务中实现稳健的策略泛化需要大规模、多样化且标注丰富的 3D 对象集。因此,通过从 Objaverse [9] 获取刚体模型,以及从 GRUtopia [68] 和 PartNet-Mobility [73] 获取关节模型来精心挑选高质量模型,如上图所示。标注流程包括:
- 筛选:根据标签和标题进行筛选,将 Objaverse 中的模型数量从 66 万个减少到 7 万个。进一步排除那些网格面数少于 1000 个或缺少法线贴图的模型。
- 基于 GPT-4V 的虚拟语言标注:为每个模型生成结构化标注,包括物体描述、物理属性(尺寸、质量)和语义属性(类别、颜色、形状、材质)。
- 居中和缩放:用 GPT-4V 将 1 万个选定的模型居中并缩放至桌面游戏尺寸,然后进行人工校正。
面向任务的场景图用于场景合成
为了从大规模标注资源中自动合成各种任务场景,采用一种结构化且直观的格式来表示每个场景,以便于机器人逻辑模型(LLM)进行操作。传统的表示方法,例如 PDDL [1],会显式地定义世界状态、初始条件、动作和目标。然而,它们僵化的语法(涉及详细的动作前提条件和状态转换)对于 LLM 来说过于繁琐,尤其是在处理复杂或大规模任务时。因此,为了简化中间表示,引入面向任务的场景图(ToSG),这是一种结构化且自然的格式,专门用于涉及空间和关系推理的机器人操作场景。ToSG 由以下组件构成:
1)任务指令:用于阐明和消除歧义的文本指令,用于描述设计的场景图。
2)场景图:节点表示对象内部状态(例如,打开、关闭),表示为:(object,status);边定义了对象间的关系,其形式为:(object,relation,anchor object);可能的关系包括左、右、前、后、近、上、内,所有关系均相对于摄像机视角。
3)目标条件:定义为条件项列表,每个条件包含成对的条件(目标对象状态)或三元组(目标关系)。
基于LLM的ToSG生成。如图所示,为了确保任务的多样性和连贯性,首先使用视觉语言(VL)标注随机抽取初始种子对象。种子任务类型涵盖短期推理(空间、外观和常识)和长期推理任务。相关对象从已标注的资源集合中检索,通常按标签抽样,每个场景大约产生50个独特的对象。然后,GPT-4使用详细的描述合成任务场景,并将其输出为面向任务的场景图(ToSG)格式。该过程通过多样化的对象选择来促进任务多样性,而结构化的ToSG则确保了空间和关系的一致性。相比之下,RoboCasa [50] 侧重于技能水平的任务生成,并且预先定义了有限的场景,并进行了一定的随机化处理。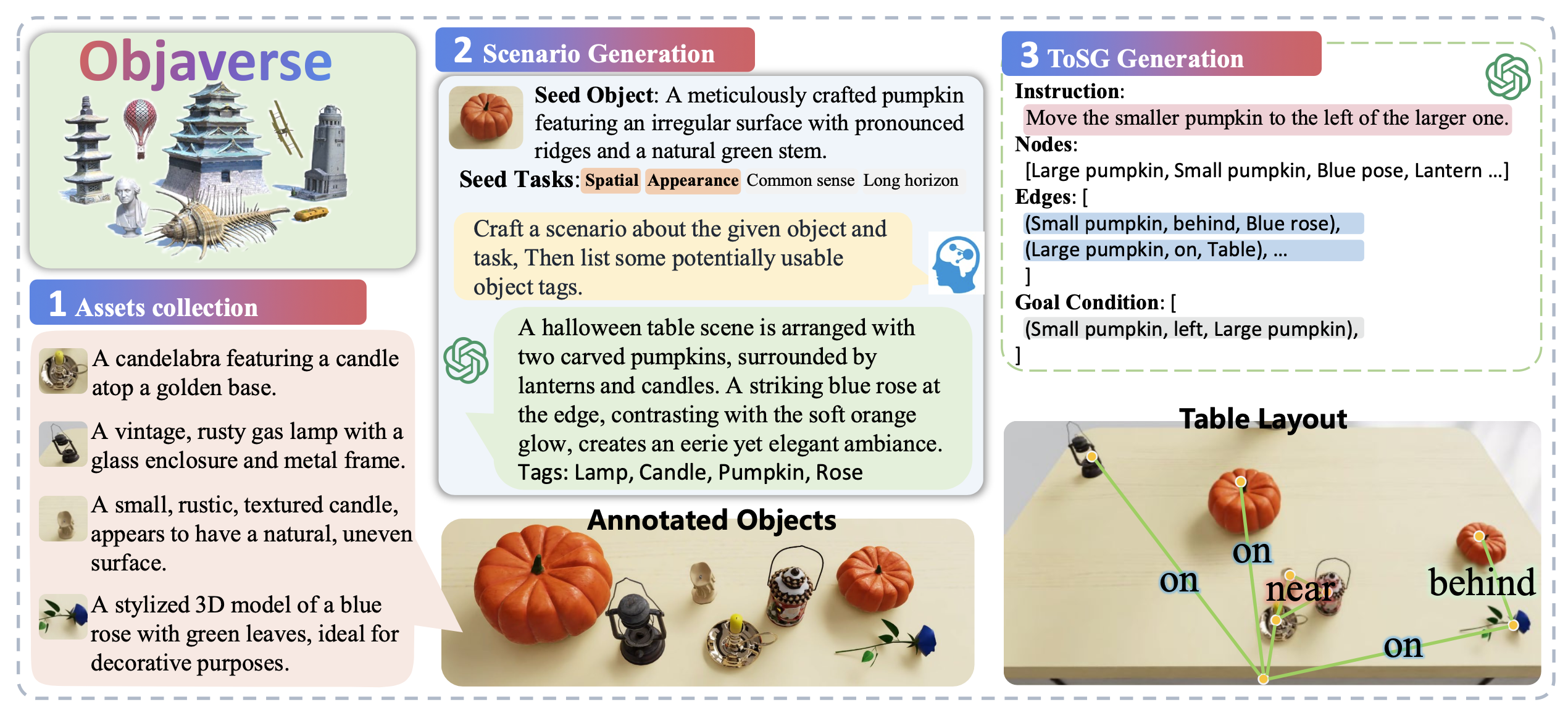
基于ToSG的布局构建。基于ToSG,首先使用“在……之上”和“在……之中”关系对所有目标进行拓扑排序——例如,将桌子放置在其上方的物体之前。接下来,按顺序放置同一拓扑级别的目标,在满足场景图关系约束的同时解决碰撞问题。例如,“靠近”关系被定义为在特定阈值(例如,5厘米)内。违反场景图约束的放置将被丢弃。通过收集至少一个有效的演示来确保任务的可执行性。如图所示,用标准机器人基准测试进行一项用户研究。
自动行为克隆数据采集。为了研究基于学习的操作的泛化,提供自动数据收集脚本。利用有关场景布局和基本技能的特权信息——类似于 MimicGen [47]—— 用运动规划库 [27] 为每个目标条件生成一个演示。
基于场景图的布局生成伪代码如下所示:
为了系统地评估操作策略在不同指令和场景下的泛化能力(这项能力对于基于基础模型的系统至关重要,但在现有平台中尚未得到充分探索),推出 GENMANIP-BENCH,这是一个精心挑选的包含 200 个任务场景的集合,这些场景经过人工参与的修正而得到完善。基于 GPT 合成的场景,人工标注者对每个任务进行了优化,以确保其在短期推理和长期目标方面都具有多样性,同时保留了真实的布局和日常活动。
近期的模块化方法[30, 44, 51, 77]利用基于标记(mark)的视觉提示,在LLM或基础模型中实现强大的泛化能力。将这些策略抽象成一个统一的模块化系统(如图所示),以研究各个组件的贡献。该框架包含四个模块:affordance提议生成器、基于网格的运动规划器、轨迹-动作链生成器和长时域规划器。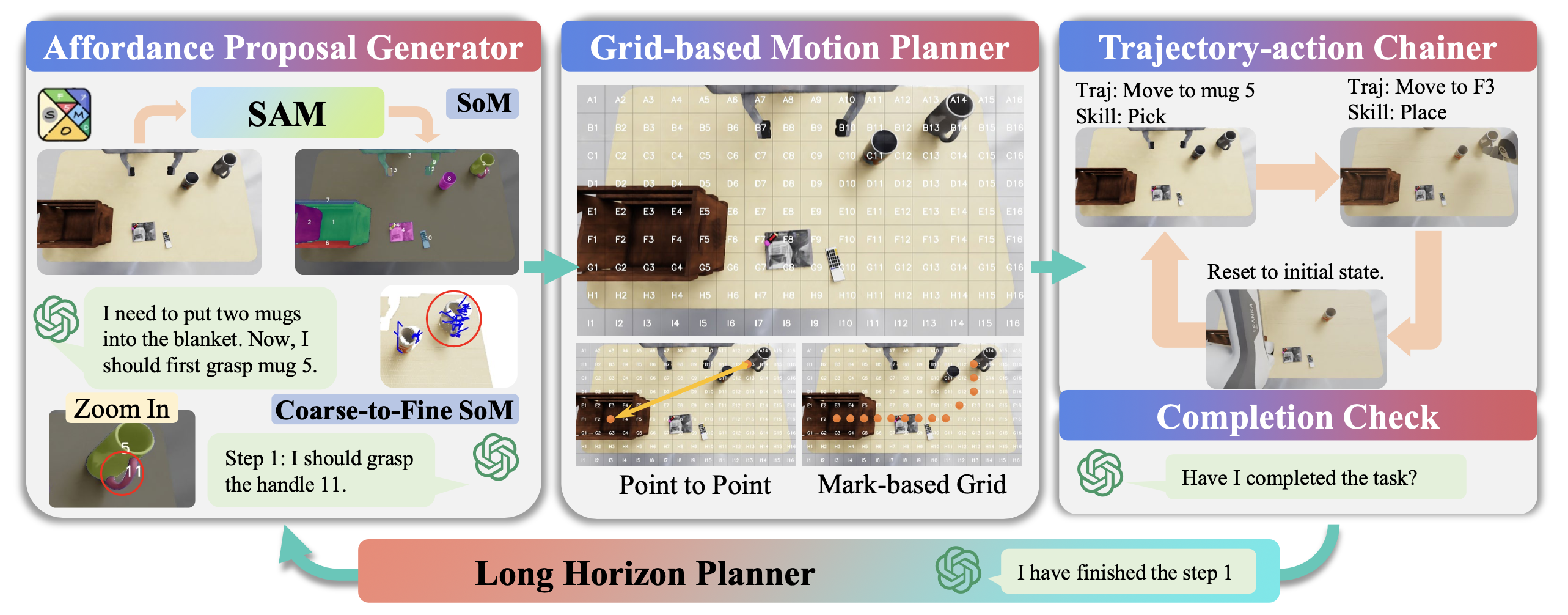
affordance提议生成器。利用SAM2[58]生成观测掩码,并为每个掩码分配一个唯一的编号。然后,VLM根据指令选择目标对象的掩码,这一过程被称为标注集(SoM)提示[75]。受 CoPA [30] 的启发,其抽象为多次 SoM 调用,以确定可抓取物体(例如,杯柄)的精确位置,称为由粗到精的 SoM (CtoF SoM)。用 AnyGrasp [14] 处理 RGB-D 图像,为整幅图像生成抓取姿态建议。然后,使用 SoM 选择的掩码对这些建议进行过滤,以获得目标物体的抓取姿态。
基于网格的运动规划器。采用类似于 MOKA [44] 的策略,使用 VLM 进行运动规划。具体来说,将图像划分为 9 × 16 的网格,并将目标物体的网格 ID(包含上一步选择的掩码中心的网格)和指令告知 VLM。与 MOKA 类似,在基于标记(mark)的网格提示设置中,VLM 依次选择一系列网格以及相应的桌面高度和机械臂方向。将选择单个目标网格称为点对点选择(仅选择终点),这是 CoPA [30] 中约束生成的简化版。通过将选定的网格中心以及 VLM 的输出高度重新投影到 3D 空间,得到一系列轨迹点,然后使用 MPlib [27] 求解一系列动作。
轨迹-动作链。在系统中,每个子任务都可以分解为轨迹-动作对。“轨迹”一词表示末端执行器的大范围运动,而“动作”指的是脚本技能(例如,拾取、放置)。智体必须标记网格 ID 在上一步规划的完整轨迹上执行的操作。
长时域规划器。长时域循环包含任务分解和完成检查。任务分解要求智体分析指令、历史背景和当前情况,以确定合适的后续步骤。完成反馈会评估任务尚未完成时,智体是否必须返回调用第一个模块。该模块不仅支持执行长期任务,还为智体提供了一种机制,使其能够从先前操作的任何失败中恢复。
对于基于学习的操作,采用两种具有代表性的端到端策略:GR-1 和 ACT。GR-1 [72] 是一种 GPT 风格的模型,它联合处理语言、视觉和机器人状态以进行动作预测。ACT [18, 80] 是一种基于 Transformer 的策略,它通过视觉增强和时间集成来提高鲁棒性。
实验设置
GENMANIP 在桌面场景下运行,使用 Isaac Sim 4.1.0 上的单个 Franka 机械臂。它包含三个不同的摄像头位置,用于基于提示的方法,以及两个额外的摄像头位置,用于数据采集和基于学习的方法的测试,如图所示。默认情况下,每个摄像头捕获 RGB 图像,并可选择提供深度图像和点云。设计用户友好的界面,方便用户调整摄像头的内参和外参。用户还可以添加或移除摄像头,以自定义视图并根据其特定方法定制基准测试。在 GENMANIP-BENCH 中,将场景背景设置为白色,以获得更简洁的视图并简化测试环境。
将潜在的模型调用(例如,Anygrasp [14]、SAM2 [58]、自定义的基于学习模型)封装为后端服务,与主程序交互。这种架构促进模型和程序之间的异步通信,提高可用性和可重用性。
如图展示行为克隆 BC 数据采集流程。首先,利用 AnyGrasp [14] 生成末端执行器的抓取位置。为了确保高质量的抓取提议,从渲染的 RGB-D 图像中裁剪出目标物体,并按方向过滤抓取提议,以避免末端执行器与工作台发生碰撞。然后,根据目标场景图随机放置目标物体。最后,借助 MPlib [27] 生成一条轨迹,将 Franks 初始位姿、抓取位姿和目标放置位姿平滑连接起来。每个演示都在基于物理的模拟器中进行测试,以确保它们能够在实际环境中实现。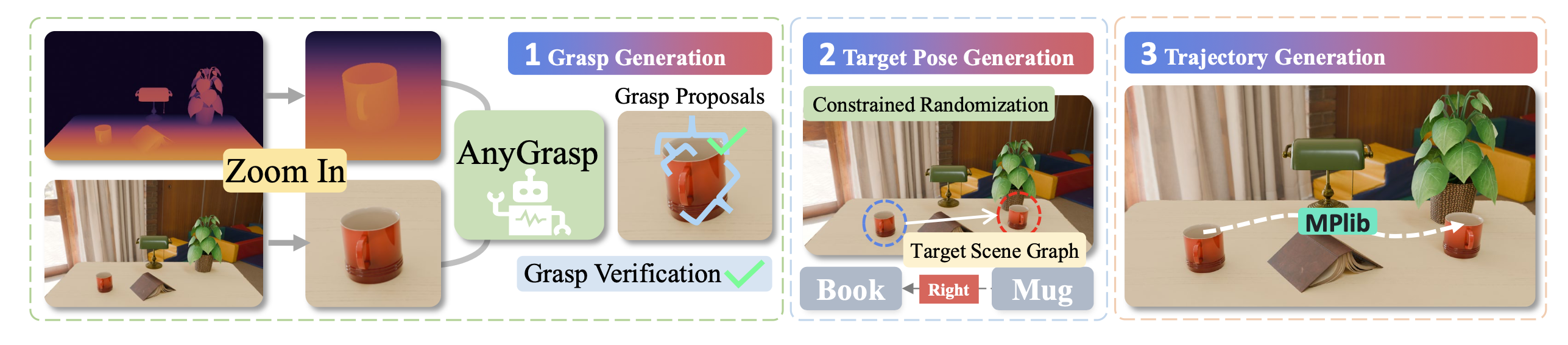

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 34
34 0
0- 0



 已为社区贡献211条内容
已为社区贡献211条内容

所有评论(0)