大模型狂飙2025:一篇文理清从模型到智能体的架构演进
1.1 2025年 AI 工程化的范式转移在2023年至2025年的短短两年间,大语言模型(LLM)的工程生态经历了一场深刻的范式转移。如果说2023年是“聊天机器人(Chatbot)”的元年,其特征是依靠提示词工程(Prompt Engineering)来试图驯服随机性模型;那么2025年则是“智能体(Agent)”与“系统工程(System Engineering)”的时代。在这个新阶段,工程
大模型狂飙2025:一篇文理清从模型到智能体的架构演进
01 == 宏观生态概览:从随机生成到确定性工程
1.1 2025年 AI 工程化的范式转移
在2023年至2025年的短短两年间,大语言模型(LLM)的工程生态经历了一场深刻的范式转移。如果说2023年是“聊天机器人(Chatbot)”的元年,其特征是依靠提示词工程(Prompt Engineering)来试图驯服随机性模型;那么2025年则是“智能体(Agent)”与“系统工程(System Engineering)”的时代。在这个新阶段,工程重心已从单一的“对话框”转移到了构建具备自主性、互操作性和状态持久性的复杂系统上 [1]。
根据开源LLM开发生态报告的数据,截至2025年12月,GitHub上94%的趋势项目都与AI相关,显示出开发者社区的注意力已完全被这一领域通过。然而,这种关注点的性质发生了根本变化。早期的“哪个模型最强”的军备竞赛思维,正在被“如何为特定场景构建最可靠的系统”的工程思维所取代 [1]。我们正处于“自主时代(Era of Autonomy)”的开端,这一时代的标志是AI不再仅仅是被动的问答工具,而是能够主动规划、使用工具并改变环境的智能体。
这种转变背后的核心驱动力是从“对话交互”向“任务闭环”的跨越。当应用场景从简单的聊天机器人(Chatbot)升级为能够独立解决问题的智能体(Agent)时,单纯依赖模型能力的随机性已不可接受。为了实现系统工程所需的确定性与可靠性,工程架构必须从单一的模型调用,进化为能够协调多个专用模型、管理复杂工具链、并维持长期记忆的精密编排系统。
1.2 现代 LLM 应用架构的四层模型
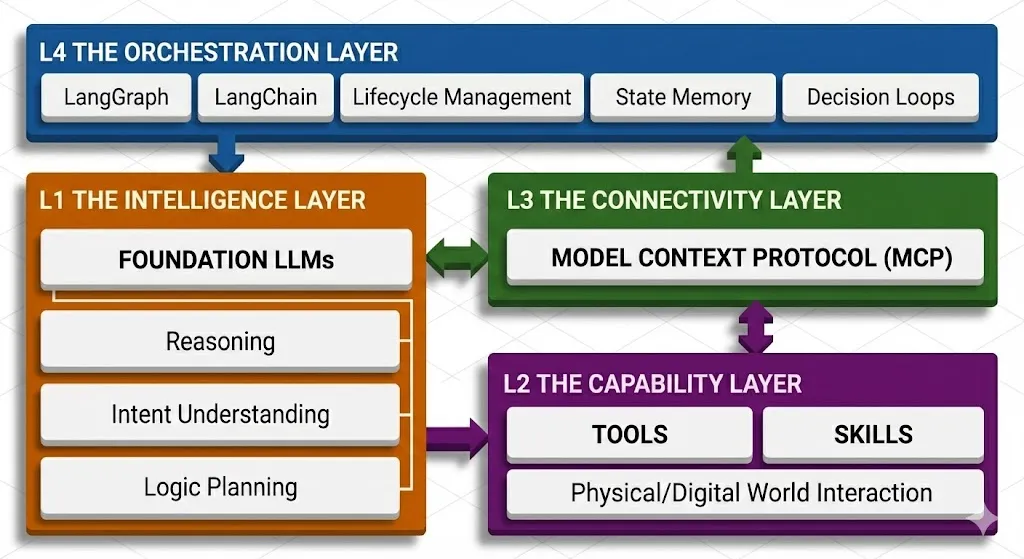
为了系统性地理解当前的工程生态,我们需要将现代AI应用栈解构为四个核心层次。这四个层次恰好对应了用户询问的几个核心概念:Agent、Skills/Tools、MCP、以及LangGraph/LangChain。
-
智能层(The Intelligence Layer):这是系统的“大脑”,由基础大模型(如Claude 3.5, GPT-4o, DeepSeek, Llama 3)构成。它们提供核心的推理(Reasoning)能力,即理解意图和生成逻辑计划的能力 [2]。
-
能力层(The Capability Layer):这是系统的“手”和“技能书”。它包含了工具(Tools)(可执行的函数,如API调用)和技能(Skills)(领域知识与操作流程)。这是智能体与物理世界或数字世界交互的界面 [3]。
-
连接层(The Connectivity Layer):这是系统的“神经系统”或“总线”。随着工具数量的激增,专用的API封装已不再适用。模型上下文协议(Model Context Protocol, MCP) 应运而生,成为了连接模型与数据源、工具的标准接口,被誉为AI时代的“USB-C”接口 [4]。
-
编排层(The Orchestration Layer):这是系统的“操作系统”。它负责管理任务的生命周期、状态记忆、决策循环以及错误恢复。LangChain 提供了组件集成的胶水层,而 LangGraph 则提供了构建复杂、有状态、循环工作流的运行时环境 [6]。
1.3 从 MLOps 到 AgentOps 的演进
随着架构的复杂化,传统的机器学习运维(MLOps)正在向智能体运维(AgentOps)转型。传统的MLOps关注的是模型训练的流水线和参数监控,而AgentOps关注的是非确定性软件的行为管理 [8]。在2025年的生态中,我们看到Arize AI、Galileo等工具的兴起,它们专注于解决LLM特有的问题:幻觉检测、链路追踪(Tracing)、以及多步推理过程中的成本控制。
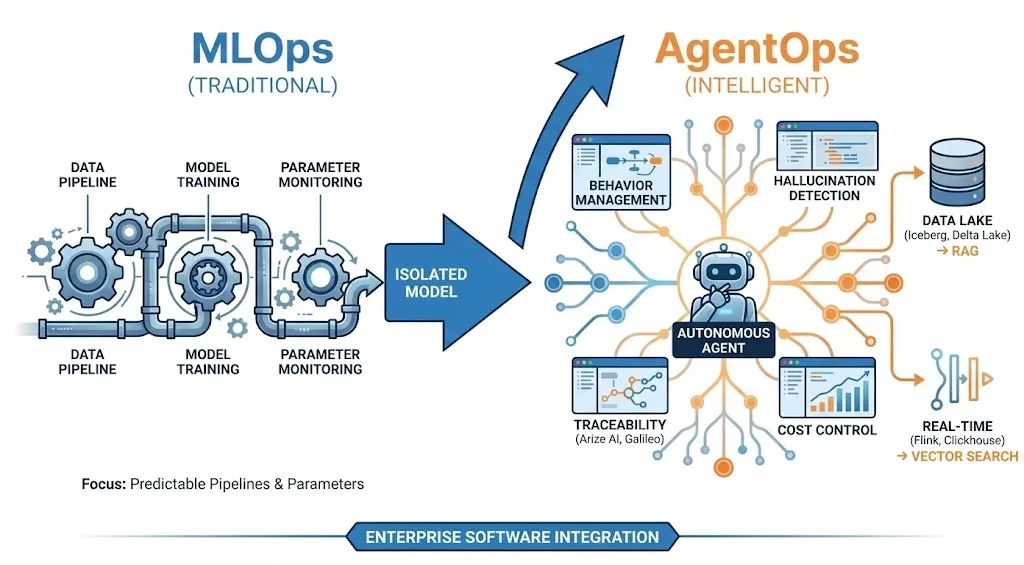
在这一背景下,数据工程的基础设施也在发生适应性变化。数据湖架构标准化为Apache Iceberg和Delta Lake,以支持大规模的非结构化数据管理,从而喂养RAG(检索增强生成)系统;流处理引擎如Apache Flink和Clickhouse正扩展向量搜索能力,以满足智能体对实时上下文检索的需求 [8]。这一切都表明,LLM工程已不再是孤立的脚本编写,而是深深嵌入到了企业级软件工程的版图中。
02 == 智能体(Agent):自主决策的核心单元
2.1 智能体的定义与本质区别
在深入探讨技术细节之前,必须厘清“智能体(Agent)”这一概念的工程定义。在市场营销话术中,任何接入了API的聊天机器人都可能被称为Agent,但在严谨的系统架构中,智能体与传统的工具或助手有着本质的区别。
根据行业共识,智能体是一个利用大语言模型决定应用程序控制流的系统 [9]。其核心特征在于自主性(Autonomy)。
| 特征维度 | 工具 (AI Tools) | 助手 (AI Assistants) | 智能体 (AI Agents) |
|---|---|---|---|
| 触发机制 | 被动:由人类明确调用 | 响应式:响应用户查询 | 主动/半主动:基于目标自主规划 |
| 决策权 | 无:仅执行预定义逻辑 | 低:建议行动,由人决策 | 高:自主决定步骤、工具选择与执行顺序 |
| 状态与记忆 | 无状态(Stateless) | 短期会话记忆 | 长期持久化状态,跨会话记忆 |
| 环境交互 | 单向输出 | 文本交互为主 | 感知环境 -> 推理 -> 行动 -> 观察结果 -> 循环 |
| 典型示例 | 图像识别API、摘要生成器 | ChatGPT 网页版、客服机器人 | 自主软件工程师(Devin)、自动驾驶系统 |
智能体不仅仅是回答问题,它是为了完成目标。正如Stuart Russell和Peter Norvig在经典定义中所述,智能体是“感知环境并对其采取行动以实现目标的任何事物” [9]。在LLM语境下,这意味着模型不再仅仅是生成文本,而是生成行动序列。它会观察当前的各种状态(如数据库的内容、代码的运行结果),通过推理决定下一步做什么(如“查询数据库”或“修改代码”),然后执行并检查结果。这种“感知-推理-行动-观察”的循环(PRO Loop)是智能体架构的灵魂 [10]。
2.2 认知架构:智能体如何“思考”
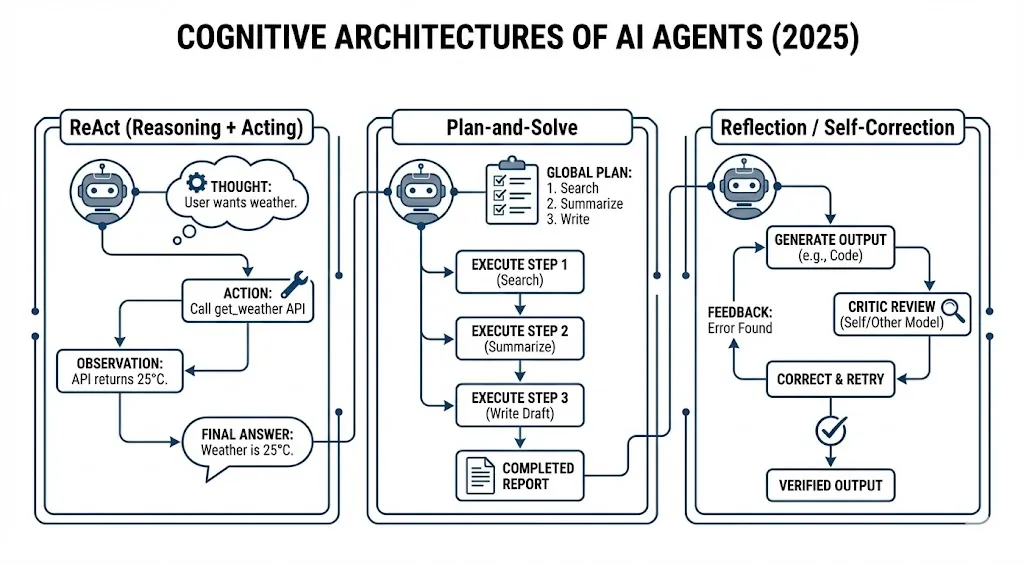
智能体的“智力”不仅取决于底层模型的参数量,更取决于其认知架构(Cognitive Architecture)的设计。这是指系统如何组织提示词、记忆和控制流,以引导模型完成复杂任务。2025年的主流认知架构包括:
-
ReAct (Reasoning + Acting) 模式
这是最基础的智能体模式。模型被要求在执行动作前先进行“思考”。例如,面对“查询天气”的任务,模型会输出:“思想:用户想知道天气 -> 行动:调用get_weather API -> 观察:API返回25度 -> 思想:我已经有了答案 -> 最终回答:天气是25度”。这种显式的推理链条极大地提高了模型使用工具的准确性 [11]。
-
规划与执行(Plan-and-Solve)模式
对于复杂任务(如“写一份关于AI趋势的市场报告”),单步的ReAct往往容易迷失方向。规划模式要求智能体首先生成一个全局计划(Plan),例如“1. 搜索最新论文;2. 总结关键趋势;3. 撰写草稿”。然后,智能体按顺序执行这些步骤。这种将“规划”与“执行”解耦的设计,是解决长程任务的关键 [2]。
-
反思与自我修正(Reflection / Self-Correction)模式
这是迈向高可靠性的关键一步。在这种架构中,智能体在生成输出后,会有一个“批评者(Critic)”角色(可以是同一个模型,也可以是另一个更强的模型)来审查结果。如果发现错误或不足,智能体会进入修正循环。例如,OpenManus等项目就利用这种机制,在生成代码后自我运行测试,根据报错信息修正代码,直到通过为止 [1]。
2.3 从单智能体到多智能体系统(Multi-Agent Systems)
2025年工程生态的一个显著趋势是多智能体协作的兴起。单智能体系统(Single-Agent)虽然部署简单,但在面对复杂、多领域的任务时,往往会遭遇“上下文污染”和能力瓶颈。一个试图既做程序员又做产品经理的Prompt,往往两样都做不好 [10]。
多智能体系统(MAS)通过专业化分工解决了这一问题。
- 角色专业化:每个智能体被赋予特定的角色(Persona)和有限的工具集。例如,“研究员智能体”只能使用搜索引擎,“编码智能体”只能使用代码解释器。这大大降低了模型产生幻觉的概率,因为上下文更加聚焦。
- 协作模式:智能体之间通过标准化的消息进行通信。最典型的模式是监督者模式(Supervisor Pattern)。在这种模式下,一个中心化的“监督者”智能体负责接收用户需求,将任务拆解并分发给底层的“工入”智能体,然后汇总结果。这种层级化的控制结构模拟了人类组织的管理方式,显著提升了复杂任务的成功率 [13]。
03 == 能力层:Agent Skills 与 Tools 的辩证关系
在构建智能体时,开发者面临的一个核心问题是:如何赋予智能体能力?这里存在两个经常被混淆但架构上截然不同的概念:工具(Tools)与技能(Skills)。理解这两者的区别是构建生产级智能体的关键 [3]。
3.1 定义与区别:执行 vs. 专业知识
-
工具(Tools)是“手”,代表执行能力。
工具是一个具有明确输入输出的可执行函数。它通常由JSON Schema定义。当智能体调用工具时,会在物理或数字世界产生副作用——查询数据库、发送邮件、写入文件。工具是确定性的、无状态的。工具本身不包含“智慧”,它只是能力的端点。OpenAI的Function Calling是典型的工具范式:系统给模型一把锤子,模型需要自己判断何时以及如何使用它 [3]。
-
技能(Skills)是“脑中的知识”,代表专业素养。
技能是封装好的专业知识(Expertise)。它不仅包含工具,还包含使用这些工具的上下文、指令、最佳实践和流程模板。技能不直接执行代码,而是塑造智能体的思维方式。例如,一个“Python编程技能”不仅仅是提供一个运行代码的工具,它还包含了“编写符合PEP8规范的代码”、“遇到错误时先检查依赖库”等指导性知识。Anthropic的Agent Skills架构强调的是:赋予智能体解决特定领域问题的“元知识” [17]。
3.2 架构上的权衡:Token经济学与上下文管理
这种区分在工程实施中带来了巨大的差异,主要体现在Token消耗和上下文窗口的管理上。
-
工具优先(Tools-Heavy)架构的挑战:
在纯工具架构中,智能体启动时需要加载所有可用工具的定义(Schema)。如果一个企业级智能体接入了1000个API,仅加载这些API的描述就可能消耗数万个Token的上下文窗口 [3]。这不仅极其昂贵,而且由于上下文过长,会干扰模型的推理能力,导致“大海捞针(Needle in a Haystack)”效应,降低工具选择的准确性。
-
技能优先(Skills-Heavy)架构的优势:
Anthropic提出的技能架构采用了渐进式披露(Progressive Disclosure)的设计模式。
-
元数据层(Level 1):智能体初始只加载技能的名称和简短描述(如“法律文档助手”)。这只占用极少的Token。
-
指令层(Level 2):当智能体决定使用某项技能时,它才会动态加载该技能对应的详细指令文件(通常是SKILL.md)。
-
资源层(Level 3):如果技能执行过程中需要参考具体的模板或数据,智能体再按需读取。
这种类似人类专家的工作方式——不需要背诵所有法律条文,只需要知道去哪里查阅——极大地优化了Token使用效率,并提升了推理的聚焦度 [17]。
3.3 技术实现对比:OpenAI vs. Anthropic
| 特性 | OpenAI Tools (Function Calling) | Anthropic Agent Skills |
|---|---|---|
| 核心理念 | 工具即函数(Code-First) | 技能即知识包(Knowledge-First) |
| 载体形式 | JSON Schema | 文件夹结构(Markdown + 脚本) |
| 上下文管理 | 预加载所有Schema | 动态加载(Progressive Disclosure) |
| 适用场景 | 确定性强、动作单一的任务 | 流程复杂、需要领域知识的任务 |
| 生态封闭性 | 倾向于封闭生态(Assistants API) | 倾向于开放标准(结合MCP) |
工程建议:在实际开发中,最佳实践是将二者结合。使用Skills来包装Tools。即,将相关的工具集(如GitHub API的增删改查)封装在一个Skill(如“代码审查技能”)中,并在Skill的Prompt中写入代码审查的最佳实践。这样既利用了工具的执行力,又注入了领域的专业性 [3]。
04 == 连接层:模型上下文协议(MCP)
随着智能体需要连接的外部系统越来越多,传统的“一对一”集成方式(为每个模型写适配每个API的代码)遇到了严重的瓶颈,这就是所谓的“N x M”集成难题。模型上下文协议(Model Context Protocol, MCP) 的出现,旨在解决这一问题,被形象地称为AI时代的“USB-C接口” [4]。
4.1 MCP 的核心价值与架构
MCP是一个开放标准,旨在标准化AI应用(Host)与外部数据/工具(Server)之间的连接。它的核心思想是解耦:开发者只需要为某个数据源(如Google Drive)编写一次MCP Server,它就可以被任何支持MCP的客户端(如Claude Desktop, Cursor, LangChain应用)直接使用,而无需为每个应用单独开发插件 [5]。
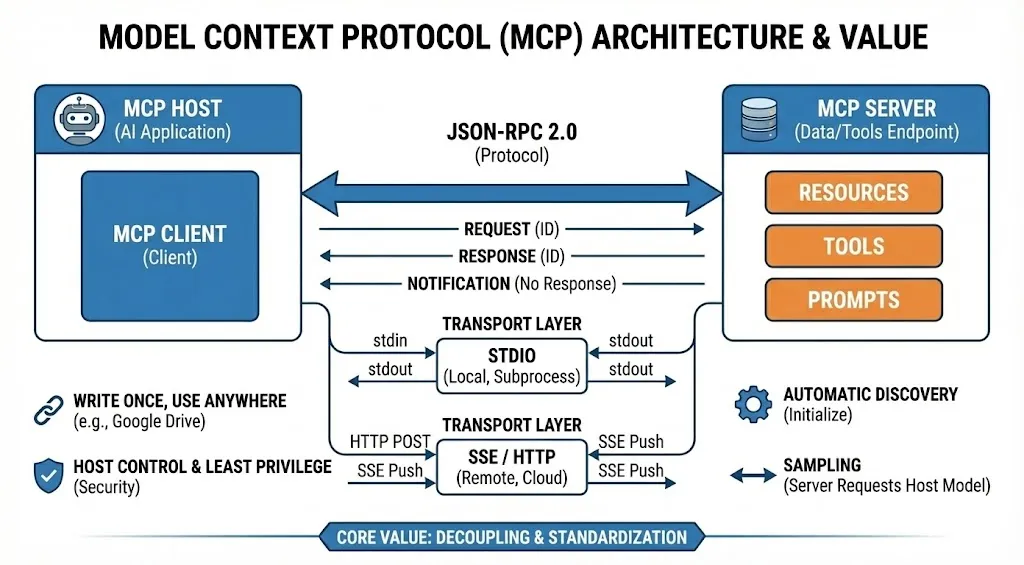
MCP的架构由三个主要部分组成:
-
MCP Host(主机):发起请求的AI应用程序(例如你的智能体或IDE)。
-
MCP Client(客户端):位于Host内部,负责与Server建立连接并维持协议通信。
-
MCP Server(服务端):提供数据和能力的端点。它通过标准接口暴露资源(Resources)、工具(Tools)和提示词(Prompts)。
4.2 协议细节:JSON-RPC 与传输层
MCP的技术实现基于JSON-RPC 2.0协议。这是一种轻量级的、无状态的远程过程调用协议。
通信机制:
- 请求(Request):Client向Server发送请求,例如“列出所有工具(tools/list)”或“调用工具(tools/call)”。请求必须包含唯一的ID。
- 响应(Response):Server处理后返回结果或错误信息。
- 通知(Notification):一种不需要响应的单向消息,常用于日志记录(logging/message)或进度报告(progress) [21]。
传输层(Transport Layer): MCP定义了两种主要的传输方式,适应不同的部署场景 [4]:
-
Stdio(标准输入输出):适用于本地集成。Host通过子进程(Subprocess)启动Server,并通过标准输入(stdin)和标准输出(stdout)进行通信。这种方式安全性高,延迟低,非常适合桌面应用(如让Claude读取你本地的文件)。
-
SSE(Server-Sent Events)/ HTTP:适用于远程分布式集成。Client通过HTTP POST发送请求,Server通过SSE长连接推送异步更新。这是构建云端智能体集群的标准方式。
4.3 MCP 对工程生态的深远影响
MCP不仅仅是一个技术协议,它正在重塑AI的供应链。
- 标准化发现机制:MCP Server可以像微服务一样被发现。智能体可以通过initialize握手,自动获知Server提供了哪些工具,而无需开发者手动硬编码 [24]。
- 安全性增强:在MCP架构中,Server是被动响应的,且Host(即用户端)拥有控制权。用户可以明确授权智能体可以访问哪些数据,遵循“最小权限原则”。这比传统的将所有数据上传到云端向量库的做法更安全、更合规 [18]。
- 采样(Sampling)能力:MCP允许Server反向请求Host的大模型进行推理。这意味着一个简单的文件读取工具,可以请求Host的大模型“先总结一下这个文件的内容再传给我”,实现了计算能力的双向流动 [25]。
目前,Anthropic、LangChain等主流玩家都已全面支持MCP,这标志着AI工程正在从封闭的“围墙花园”走向开放互联的“万维网”模式 [26]。
05 == 编排层:LangChain 与 LangGraph 的演进
当我们就拥有了模型(大脑)、技能(知识)和MCP(连接)后,还需要一个框架将它们组装起来,管理任务的流转和状态。这就是编排层的作用。在这一领域,LangChain 和 LangGraph 是两个绕不开的名字,但它们解决的问题截然不同。
5.1 LangChain:集成的胶水
LangChain 是LLM应用开发的先驱。它的核心价值在于封装和组件化。
-
统一接口:它抹平了不同模型提供商(OpenAI, Anthropic, Google)API的差异,让开发者可以轻松切换模型。
-
链(Chains)的概念:LangChain最初的设计哲学是基于有向无环图(DAG)的“链式调用”。输入 -> 提示词模板 -> 模型 -> 输出解析器。这种线性的流处理非常适合简单的问答或RAG应用 [6]。
-
局限性:随着应用向“智能体”进化,线性的链式结构变得捉襟见肘。智能体需要循环(Loop)、需要根据结果回退、需要复杂的条件分支。用LangChain的旧式AgentExecutor去实现这些逻辑,往往导致代码变得难以维护和调试 [28]。
5.2 LangGraph:智能体的运行时环境
为了解决LangChain在复杂场景下的局限性,LangChain团队推出了LangGraph。LangGraph并非LangChain的替代品,而是其核心能力的升维——从“链”进化到了“图” [7]。
核心架构:状态机(State Machine) LangGraph将智能体建模为一个有状态的图。
- 节点(Nodes):代表执行步骤(如“调用LLM”、“执行工具”、“更新记忆”)。
- 边(Edges):代表控制流。可以是普通的跳转,也可以是条件跳转(Conditional Edges),例如“如果工具调用成功,去下一步;如果失败,回退重试” [7]。
- 状态(State):这是LangGraph的灵魂。不同于LangChain隐式的传递变量,LangGraph要求开发者显式定义一个全局状态Schema(通常是一个TypedDict)。图中的每个节点都接收这个状态,并输出对状态的更新(Update)。这种显式的状态管理使得系统的行为高度可预测和可调试 [29]。
关键特性:持久化与“时间旅行” LangGraph引入了检查点(Checkpointer)机制。系统会在每一步执行后,将当前的状态快照保存到数据库(如Redis, Postgres)中 [29]。这带来了两大革命性能力:
-
容错与恢复:如果系统崩溃,重启后可以从断点处继续执行,而不是从头开始。这对于耗时较长的智能体任务至关重要。
-
人机协同(Human-in-the-Loop):智能体可以运行到某个节点(如“发送邮件前”)暂停,等待人类用户的批准或修改,然后再继续执行。这种交互模式在企业级应用中是刚需 [30]。
-
时间旅行(Time Travel):开发者可以查看智能体在过去某一步的状态,甚至修改该状态并从那里重新分叉(Fork)执行,这极大地便利了调试和测试 [30]。
5.3 LangChain 与 LangGraph 的选择指南
| 比较维度 | LangChain | LangGraph |
|---|---|---|
| 核心隐喻 | 流水线 (Pipeline / DAG) | 循环图 (Cyclic Graph / State Machine) |
| 控制流 | 线性为主,难以实现复杂循环 | 原生支持循环、分支、回退 |
| 状态管理 | 隐式传递,较难追踪 | 显式定义的共享状态 (Schema-First) |
| 适用场景 | 简单RAG、一次性问答、数据处理管道 | 长期运行的智能体、多轮对话、人机协同 |
| 学习曲线 | 较低,适合快速原型 | 较高,需要理解图论和状态机概念 |
总结:在2025年的架构中,LangGraph是骨架,LangChain是肌肉。通常的做法是使用LangGraph来定义智能体的整体流程(图结构),而在图的节点内部,使用LangChain的组件来调用模型或处理文档 [7]。
06 == 未来的挑战与展望
LLM的工程生态已经完成了一次蜕变,但更大的挑战在于“人”的思维转型。对于算法研究员和应用开发者而言,全面拥抱AI和LLM新时代,意味着必须完成从传统软件思维到智能体思维(Agentic Thinking)的深刻跨越。
6.1 思维范式的根本性重构
这不仅仅是技术栈的更新,而是全流程的认知重塑:
-
产品设计:从“功能堆砌”到“意图设计”
传统产品设计关注用户点击哪个按钮触发哪个功能。而在智能体时代,产品经理需要定义的是“目标(Goal)”和“约束(Constraints)”。我们需要设计的是智能体如何理解模糊的用户意图,以及在何种边界内自主行动。交互界面将从复杂的菜单树回归到自然语言与多模态的混合交互。
-
应用研发:从“确定性编程”到“概率系统工程”
开发者习惯了
if-else的确定性逻辑,但LLM本质上是概率性的。新的挑战在于如何在一个不确定的核心(LLM)之上构建可靠的系统。这要求我们掌握提示词工程(Prompt Engineering)来引导模型,利用评估驱动开发(Evaluation-Driven Development)来量化效果,并设计鲁棒的容错与回退机制。代码不再只是指令的集合,而是对模型思考过程的编排。 -
算法研究:从“模型优化”到“认知架构设计”
对于算法人员,单纯追求模型参数的SOTA已不足够。重心正转向设计更优秀的认知架构(Cognitive Architecture)——如何让模型拥有更长期的记忆、更高效的规划能力、以及更精准的自我反思机制。未来的算法创新将更多发生在System 2(慢思考)的系统设计层面,而非仅仅是System 1(快思考)的模型训练层面。
6.2 展望:构建 AI 原生的未来
尽管挑战巨大,但工具生态的成熟正在加速这一进程。
- MCP 让万物互联成为可能,为智能体提供了标准化的感官与手脚。
- LangGraph 赋予了智能体逻辑严密的“心智模型”,让复杂的业务流转变得可控。
- Skills 沉淀了领域专家的智慧,让智能体真正具备了职业素养。
在这个新时代,核心竞争力不再仅仅是写代码的速度,而是定义问题、设计智能体认知流程、以及与AI协作共创的能力。工程的严谨性与AI的创造力将在“智能体思维”的指引下完美融合。
文章来自网上,侵权请联系博主
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。
4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。
👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
5.免费获取
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码或者点击以下链接都可以免费领取【保证100%免费】


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 30
30 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)