Alpamayo-R1:打通推理与动作预测,迈向稳健 L4 级自动驾驶
本文是对论文《Alpamayo-R1: Bridging Reasoning and Action Prediction for Generalizable Autonomous Driving in the Long Tail》的深度解读。在自动驾驶领域,端到端模型在长尾安全关键场景的脆弱性是迈向 L4 级自动驾驶的核心瓶颈。NVIDIA 团队提出的 Alpamayo-R1 模型,通过因果链数据
在自动驾驶技术演进中,端到端(E2E)框架凭借数据驱动的规模化优势,已逐渐取代传统模块化架构成为行业主流。然而,现有 E2E 模型在长尾安全关键场景中仍表现脆弱 —— 这些场景中监督数据稀疏、因果理解不足,导致模型难以做出稳健决策,成为制约其迈向 L4 级自动驾驶的核心瓶颈。NVIDIA 2025 年提出的 Alpamayo-R1(AR1)模型,通过融合因果链推理与轨迹规划,构建了视觉 - 语言 - 动作(VLA)统一框架,为解决这一痛点提供了切实可行的技术路径。
原文链接:https://arxiv.org/pdf/2511.00088
沐小含持续分享前沿算法论文,欢迎关注...
一、研究背景与核心挑战
1.1 自动驾驶技术范式演进
自动驾驶系统已从传统的感知 - 预测 - 规划分离式模块化架构,转向直接将传感器输入映射为车辆运动指令的端到端架构。这种转变消除了人工设计的中间接口,支持联合优化和规模化数据驱动的策略学习,结合 Transformer 架构和大规模驾驶数据集的突破,显著提升了模型的整体性能和泛化能力。
1.2 现有端到端方案的核心瓶颈
尽管端到端架构取得了长足进步,但在处理长尾场景(如突发障碍物、复杂路口交互、极端天气)时仍面临三大核心挑战:
- 监督数据稀疏:长尾场景出现概率低,难以获取足够标注数据进行有效训练;
- 因果理解不足:模型依赖模式匹配而非因果推理,难以应对未见过的复杂场景组合;
- 推理与动作脱节:现有视觉 - 语言 - 动作模型(VLAs)要么缺乏显式推理能力,要么推理过程无结构化约束,导致推理与实际驾驶动作不一致。
1.3 大语言模型带来的新机遇
大型语言模型(LLMs)的推理能力为解决上述问题提供了新方向。前沿 LLM(如 OpenAI o1、DeepSeek-R1)引入的 "思维链"(Chain of Thought)范式,通过生成中间推理轨迹模拟人类问题解决过程,使推理成为可调节的资源。将这种推理能力引入自动驾驶,可实现三大优势:
- 安全增强:通过反事实推理进行运行时安全校验;
- 可解释性提升:生成人类可读的决策理由;
- 训练信号丰富:提供可验证的奖励信号,提升长尾场景性能。
但关键挑战在于:自动驾驶推理需紧密结合驾驶任务的结构化知识(车道几何、交通规则、动态约束等),而非自由文本生成。因此,AR1 的核心目标是构建 "因果接地、结构对齐" 的推理机制,实现推理与动作预测的深度融合。
二、核心创新:三大技术支柱
AR1 的突破源于三大核心创新,分别从数据、架构、训练三个维度解决推理与动作融合的关键问题,形成完整技术闭环。
2.1 创新一:Chain of Causation(CoC)数据集 —— 因果接地的推理数据基础
现有自动驾驶推理数据集存在三大缺陷:行为描述模糊、推理表面化、因果混淆(引用未来未观测信息)。为解决这些问题,AR1 构建了结构化的 CoC 数据集,通过 "人工 - 自动" 混合标注 pipeline 生成决策接地、因果关联的推理轨迹。
2.1.1 数据集核心设计原则
- 决策接地:每个推理轨迹锚定明确的驾驶决策(如跟车、避让、变道);
- 因果局部性:所有推理依据均来自历史观测窗口,避免因果混淆;
- 标注经济性:仅保留与决策直接相关的关键因素,避免冗余描述。
2.1.2 结构化标注框架
CoC 数据集的标注过程分为五步(如图 3 所示):
- 片段筛选:选择包含明确驾驶决策的视频片段,过滤低信息密度片段;
- 关键帧标注:确定决策发生的关键时刻,区分历史观测与未来轨迹;
- 因果因素标注:从历史窗口中提取影响决策的关键组件(车辆、行人、交通灯等);
- 驾驶决策标注:从预定义的封闭决策集中选择纵向(如跟车、停车)和横向(如车道保持、变道)决策;
- 因果链构建:将因果因素与驾驶决策组织为自然语言推理轨迹。

2.1.3 关键标注组件定义
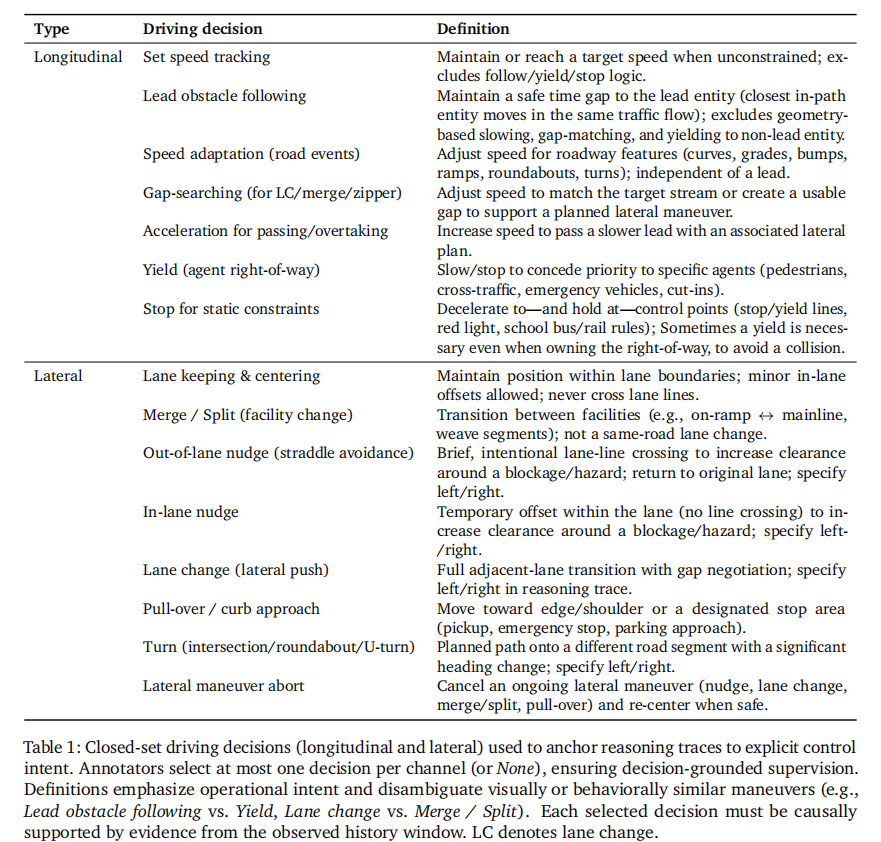
- 驾驶决策集(表 1):包含 14 种纵向和横向决策,覆盖所有核心驾驶场景,确保决策描述的标准化;
- 纵向决策:涵盖定速跟踪、前车跟驰、速度适配、间隙搜索、超车加速、让行、静态约束停车 7 类,明确区分不同速度控制逻辑(如跟驰与让行的核心差异在于是否针对特定主体让步);
- 横向决策:包含车道保持、合流 / 分流、车道外微调、车道内微调、变道、靠边、转弯、横向动作中止 8 类,细化动作边界(如变道与合流的区别在于是否跨设施)。
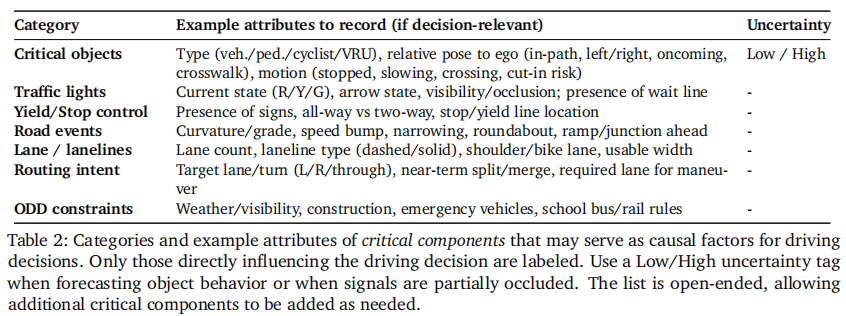
- 关键组件类别(表 2):开放式类别设计,包含关键物体、交通灯、道路事件等,支持灵活标注决策相关因素;
- 关键物体:记录类型(车辆 / 行人 / 骑行者等)、相对姿态、运动状态及不确定性标签;
- 交通控制:涵盖红绿灯状态、标志类型、停车线位置等;
- 道路事件:包含车道属性、曲率、障碍物等;
- 路径意图:目标车道、转向需求等;
- 运行域约束:天气、施工、紧急车辆等。
- 场景分类:分为反应式场景(如避让突发障碍物)和主动式场景(如弯道提前减速),确保数据集覆盖不同决策类型。
2.1.4 混合标注 pipeline
- 人工标注:占比约 10%,采用两阶段标注流程,结合 BEV 可视化、车辆动力学数据等辅助工具,确保标注质量;
- 阶段一(0-2s):仅基于历史观测窗口标注关键组件,避免未来信息泄露;
- 阶段二(0-8s):筛选有效数据、选择驾驶决策、撰写因果推理轨迹,严格关联阶段一标注的因素。
- 自动标注:通过规则检测器识别低级别元动作转换时刻作为关键帧,利用 GPT-5 等大模型生成结构化推理轨迹,实现规模化数据生成;
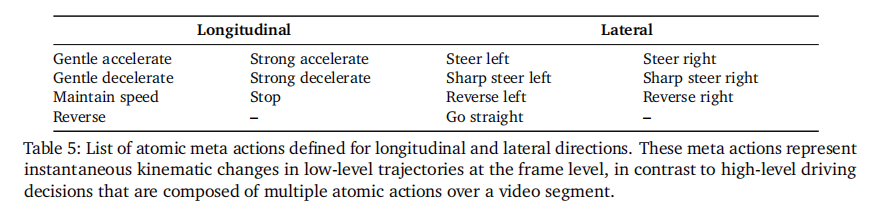
- 元动作定义(表 5):包含纵向(平缓加速 / 减速、急加速 / 减速、停车、倒车、匀速)和横向(平缓转向、急转向、直线行驶、倒车转向)共 12 种原子动作,以 10Hz 频率标注;
- 标注逻辑:模型基于 2 秒历史视频识别因果因素,结合 6 秒未来轨迹和元动作确定驾驶决策,筛选关键因素生成推理轨迹。
- 元动作定义(表 5):包含纵向(平缓加速 / 减速、急加速 / 减速、停车、倒车、匀速)和横向(平缓转向、急转向、直线行驶、倒车转向)共 12 种原子动作,以 10Hz 频率标注;
- 质量评估:采用 "人工验证 + LLM 自动评估" 的混合策略,将评估分解为决策一致性、因果因素存在性、因果关系有效性三个结构化子任务,确保标注质量(与人类评估一致性达 92%)。
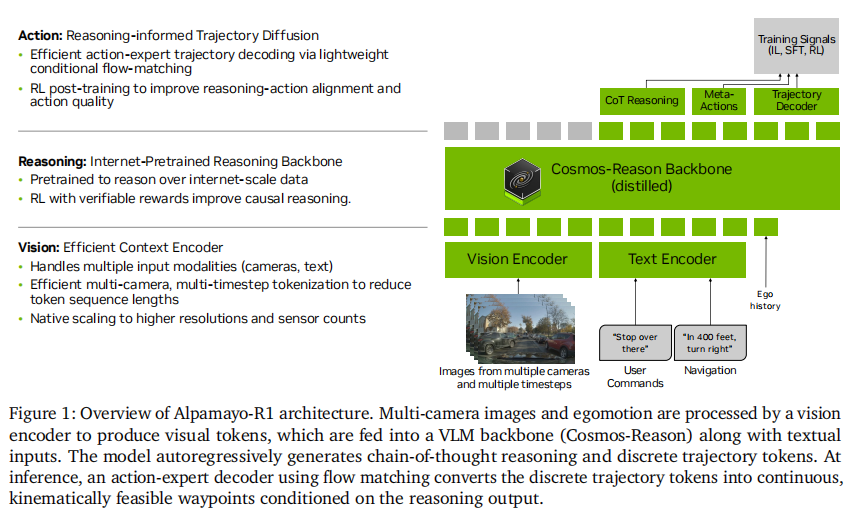
2.2 创新二:模块化 VLA 架构 —— 推理与动作的高效融合
AR1 采用模块化架构设计,既保留了通用 VLM 的推理能力,又通过领域适配组件满足自动驾驶的实时性和物理约束要求,架构整体如图 1 所示。
核心公式定义如下:
- 任务建模:给定多摄像头图像
和
运动历史
,模型需生成推理轨迹 Reason 和未来 6 秒轨迹
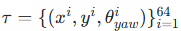 (10Hz 采样),序列关系为
(10Hz 采样),序列关系为 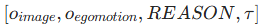 ;
; - 控制表示:采用单轮车动力学模型,轨迹由控制输入
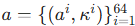 描述(
描述(为加速度,
为曲率),通过欧拉离散化映射为位置轨迹:
其中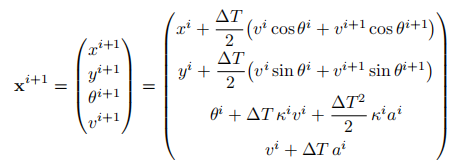
=0.1s,
为鸟瞰图位置,
为偏航角,
为速度。
2.2.1 核心 backbone:Cosmos-Reason VLM
选择 Cosmos-Reason 作为基础 VLM,其核心优势在于:
- 物理 AI 优化:专门针对物理世界应用预训练,包含 370 万视觉问答样本和 2.47 万驾驶场景专项样本;
- 领域适配:通过自动驾驶、机器人等多领域物理 AI 数据微调,增强物理常识和具身推理能力;
- 驾驶场景强化:补充 10 万自动驾驶专项样本,包含环境关键物体标注和动作推理轨迹。
2.2.2 领域适配组件一:高效视觉编码
针对自动驾驶多摄像头、多时间步输入的特点,设计了三级视觉编码策略,在保证信息完整性的同时降低计算开销:
- 单图像编码:采用 ViT 架构将单帧图像分割为 patches 编码,默认配置下 448×280 图像生成 160 个 token;
- 编码流程:先将图像转换为
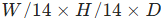 的 patch 特征,再通过 2 倍双线性下采样得到
的 patch 特征,再通过 2 倍双线性下采样得到 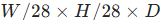 特征,平衡分辨率与计算量。
特征,平衡分辨率与计算量。
- 编码流程:先将图像转换为
- 多摄像头编码:基于三平面(triplane)表示的 3D 归纳偏置,将多摄像头图像编码为固定数量 token(如 7 摄像头仅需 288 个 token),与摄像头数量和分辨率解耦;
- token 计算方式:对于网格大小
和 patch 大小
,token 数为三个平面的 patch 数之和:
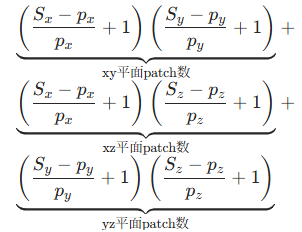
- token 计算方式:对于网格大小
- 多摄像头视频编码:采用 Flex 框架通过自注意力和固定查询向量压缩多帧多摄像头数据,最高可实现 20 倍 token 压缩率,同时保持甚至提升驾驶性能;
- 核心逻辑:利用帧间信息冗余,通过全自注意力层聚合多摄像头、多时间步的图像 token,通过固定查询向量控制信息瓶颈大小。
- 额外压缩手段:采用 SparseVILA 等训练后 token 剪枝技术,推理时动态移除冗余 token,无需重训即可降低计算成本。
2.2.3 领域适配组件二:轨迹解码
为解决动作生成的准确性、实时性和物理可行性问题,设计了基于流匹配(flow matching)的轨迹解码器:
- 双表示机制:训练时采用离散 token 编码(128 个 token / 轨迹),推理时通过流匹配解码器生成连续轨迹;
- 离散编码:将加速度和曲率量化为等间隔区间,映射为专用 token;
- 连续解码:采用正弦位置编码 + MLP 投影,将离散 token 转换为连续嵌入。
- 流匹配解码器:
- 架构设计:与 VLM 共享 Transformer 注意力头和维度,缩小隐藏层和 MLP 维度以提升效率;
- 训练损失:采用条件流匹配损失,目标向量场为高斯条件最优传输路径:
其中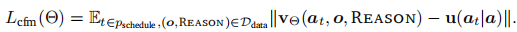
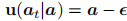 ,
,为带噪声的控制输入,
为噪声项;
- 推理过程:从随机噪声开始,通过欧拉积分迭代 denoise:
默认设置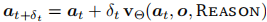
=0.2(5 步迭代),平衡速度与精度。
2.3 创新三:多阶段训练策略 —— 从推理到动作的精准对齐
AR1 采用三阶段训练流程(如图 5 所示),逐步实现 VLM 的驾驶领域适配、推理能力激发和推理 - 动作一致性优化。
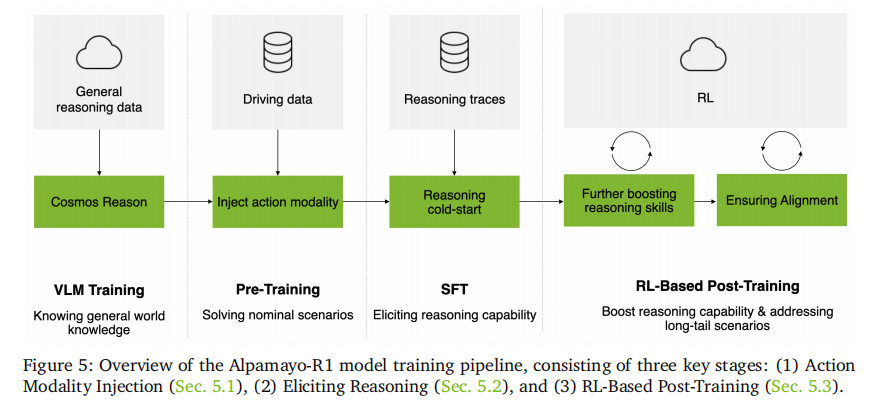
2.3.1 阶段一:动作模态注入
目标是让 VLM 具备轨迹预测能力,核心步骤包括:
- 轨迹 token 化:将加速度和曲率控制序列量化为离散 token,与语言 token 共享统一空间;
- 联合训练:采用交叉熵损失优化 图像运动推理轨迹 的联合序列预测;
- 解码器训练:单独训练流匹配动作专家,训练时对 VLM 产生的 KV-cache 施加 stop-gradient,避免梯度回传污染 VLM 权重。
- 核心优势:
- 统一训练空间:推理与轨迹共享 token 空间,实现因果解释与车辆行为的紧密耦合;
- 高效 RL 适配:离散表示支持直接梯度流动,便于后续 GRPO 算法优化;
- 物理可行性保障:流匹配专家确保轨迹满足动力学约束;
- 实时性:解码速度远超自回归采样(128 个 token)。
2.3.2 阶段二:推理能力激发(SFT)
基于 CoC 数据集进行有监督微调,目标是让模型生成因果接地的推理轨迹:
- 训练目标:最大化推理 - 动作序列的条件对数似然:
其中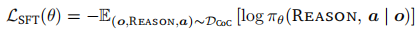
为 VLA 策略,包含视觉编码器、语言 backbone 和嵌入适配器;
- 损失计算:对推理 token 和离散轨迹 token 均施加交叉熵损失,实现语言推理与动作预测的联合学习;
- 局限性分析:
- 数据偏差:自动标注数据可能存在因果关系缺陷,导致模型过拟合标注噪声;
- 泛化不足:仅记忆常见推理模式,缺乏深层因果理解,难以应对新场景;
- 视觉接地弱:next-token 预测未强制视觉一致性,可能出现场景中不存在的因果因素幻觉;
- 一致性缺失:联合优化未明确约束推理与轨迹的对齐,可能出现 "说一套做一套"。
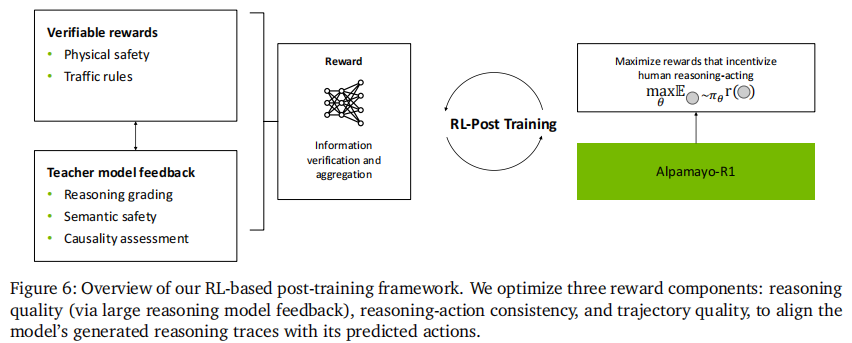
2.3.3 阶段三:RL-based 后训练对齐
采用 GRPO(Group Relative Policy Optimization)算法,通过三大奖励信号实现推理质量、动作一致性和安全性的联合优化(如图 6 所示):
-
后训练算法:
- GRPO 目标函数:
其中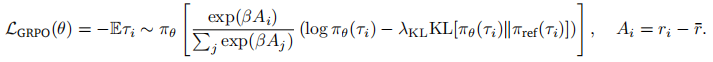
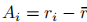 为相对优势(
为相对优势( 为样本奖励,
为组平均奖励),
控制权重分布锐度,
为
正则系数,
为 SFT 模型(避免偏离预训练先验)。
- GRPO 目标函数:
-
奖励模型设计(总奖励
):
- 推理质量奖励(
):
- 评估主体:采用 DeepSeek-R1、Cosmos-Reason 等大型推理模型作为评估器;
- 评估维度:行为一致性(推理描述的决策与真实决策是否一致)、因果推理质量(是否准确识别历史窗口中的因果因素);
- 评分标准:0-5 分结构化 rubric(5 分:完全一致;4 分:行为正确、推理基本一致;3 分:行为大致正确、推理有缺陷;2 分:行为部分错误或推理严重不一致;1 分:行为错误;0 分:完全无关)。
- 推理 - 动作一致性奖励(
):
- 转换逻辑:将预测轨迹转换为元动作序列(纵向 + 横向),解析推理轨迹得到预期行为;
- 匹配方式:规则 - based 比对预期行为与元动作,完全一致得 1 分,否则得 0 分;
- 特殊处理:推理无法解析为有效决策时,保守赋值 0 分。
- 轨迹质量奖励(
):
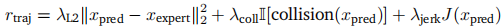
- L2 模仿项:拉近预测轨迹与专家轨迹的距离;
- 碰撞惩罚项:发生碰撞时施加惩罚;
- 加加速度惩罚项: 对突变动作施加惩罚,提升舒适性。
- 推理质量奖励(
-
高效数据筛选:
- 核心逻辑:优先选择模型内部偏好(logits 隐含)与外部奖励信号分歧大的样本;
- 实现方式:将模型 logits 转换为概率分布,将奖励转换为玻尔兹曼分布,选择分布分歧大的样本;
- 数据混合:高分歧样本与随机样本按比例混合,平衡对齐效率与分布多样性。
-
训练基础设施:基于 Cosmos-RL 框架定制,支持分布式数据加载、混合并行训练、vLLM-based 样本生成、多 GPU 节点奖励计算,保障大规模多模态 RL 的高效执行。
三、实验验证:全方位性能评估
AR1 的实验评估覆盖开环轨迹预测、闭环仿真、真实道路测试三个维度,全面验证模型在常规和长尾场景下的性能。
3.1 实验设置
- 数据集:8 万小时真实驾驶数据,覆盖 25 个国家 1700 多个城市,包含高速公路、城市道路等多种场景,以及 70 万段 CoC 标注数据;
- 评估指标:
- 开环:minADE(最小平均位移误差)、ADE(平均位移误差);
- 闭环(AlpaSim 模拟器):偏离道路率、近距离碰撞率、AlpaSim 分数(事件间行驶距离);
- 推理质量:LLM 评估分数、推理 - 动作一致性分数;
- 基线模型:轨迹仅预测模型、元动作 + 轨迹预测模型。
3.2 核心实验结果
3.2.1 开环性能:推理提升轨迹预测准确性
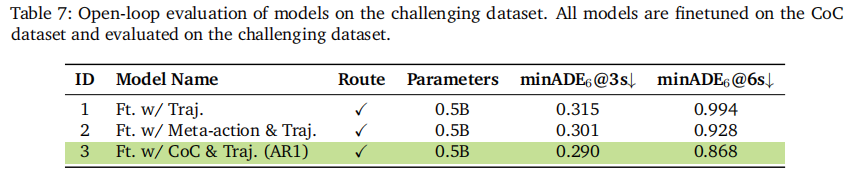
如表 6 和表 7 所示,AR1 在常规场景和挑战场景中均显著优于基线:
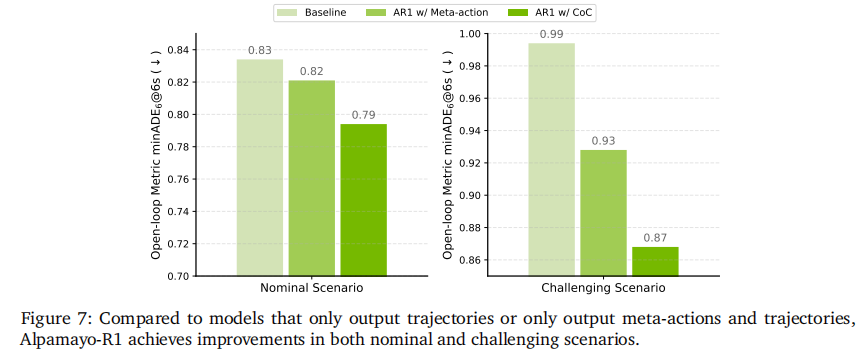
- 常规场景(表 6):0.5B 参数 AR1 在 6 秒预测 horizon 上的 minADE 达 0.794m,比轨迹仅基线提升 4.8%;3B 参数模型进一步提升至 0.908m;
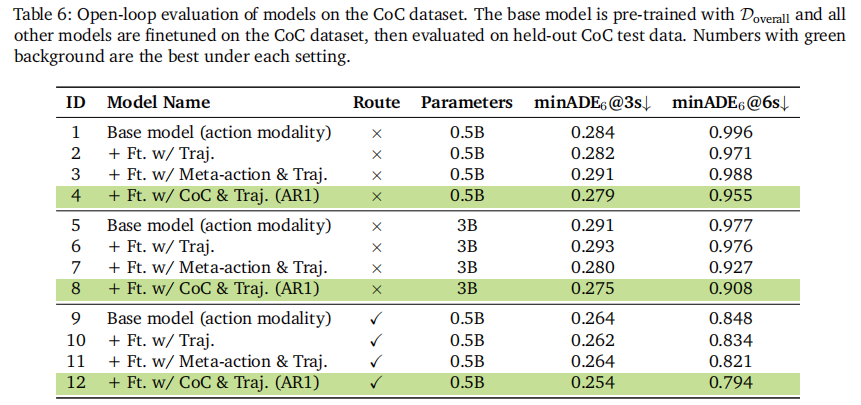
- 挑战场景(表 7):AR1 的 minADE 达 0.868m,比轨迹仅基线提升 12%,验证了推理对复杂场景的增益;
- 模型缩放效应:从 0.5B 到 7B 参数,模型性能持续提升,证明架构的可扩展性。
3.2.2 闭环性能:推理提升驾驶安全性
如表 8 所示,在 AlpaSim 的 75 个挑战场景中:
- AR1 的偏离道路率从 17% 降至 11%(降低 35%);
- 近距离碰撞率从 4% 降至 3%(降低 25%);
- AlpaSim 分数从 0.38 提升至 0.50,证明推理能力显著提升了闭环驾驶的安全性和稳健性。

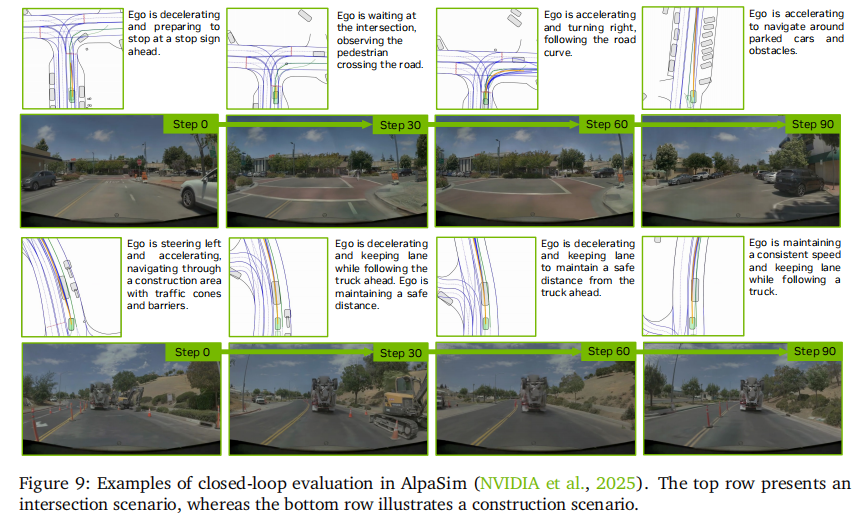
可视化展示如下:
3.2.3 RL 后训练的关键作用
如表 9 所示,RL 后训练实现了多维度性能提升:
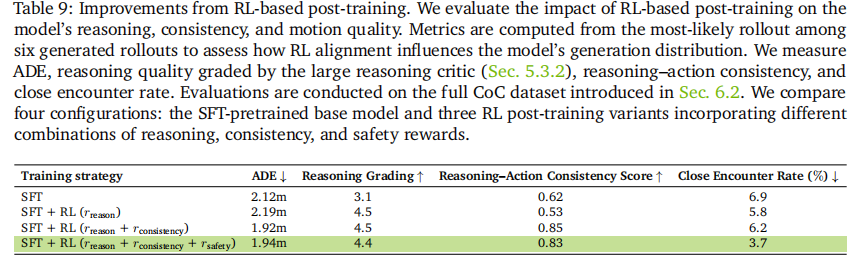
- 推理质量:LLM 评估分数从 3.1 提升至 4.5(提升 45%);
- 推理 - 动作一致性:从 0.62 提升至 0.85(提升 37%);
- 轨迹准确性:ADE 从 2.12m 降至 1.92m(降低 9.4%);
- 安全性:近距离碰撞率从 6.9% 降至 3.7%(降低 46%)。
定性结果显示(图 10、图 11),后训练后的模型能更准确识别关键场景因素(如施工区域、行人),并确保推理描述与实际驾驶动作严格一致


3.2.4 消融实验:关键组件的必要性验证
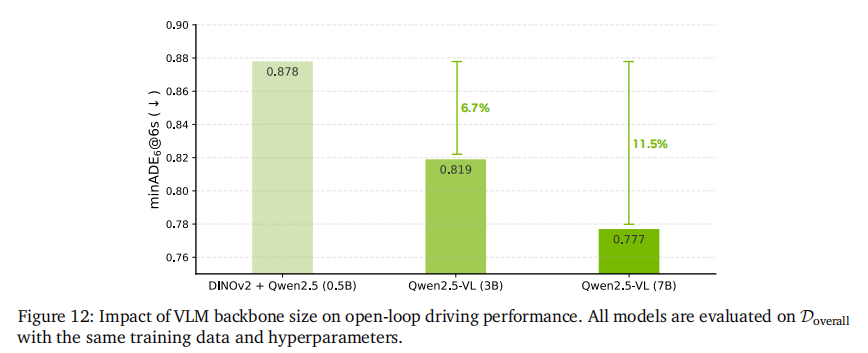
- VLM backbone 选择(表 10、图 12):Cosmos-Reason 在驾驶场景理解基准 LingoQA 上达到 66.2% 准确率,优于 GPT-4V(59.6%)等通用 VLM;模型规模从 0.5B 扩展到 7B,minADE 降低 11%,证明物理 AI 预训练和模型缩放的双重价值;

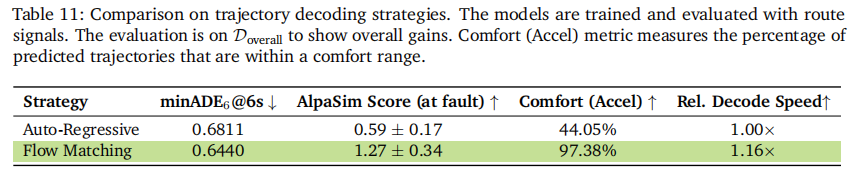
- 动作模态注入(表 11):流匹配解码相比自回归解码,在 minADE 降低 5.4% 的同时,解码速度提升 16%,舒适性指标提升 121%;
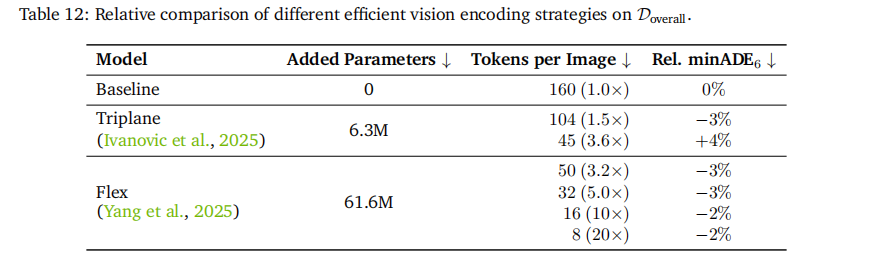
- 视觉编码策略(表 12):triplane 编码实现 3.6 倍 token 压缩,Flex 编码最高实现 20 倍压缩,且均保持与基线相当的驾驶性能,为实时部署提供可能。
3.3 实时性与真实道路测试
- 实时性能:在 NVIDIA RTX 6000 Pro Blackwell 平台上,端到端推理延迟仅 99ms(表 13),满足自动驾驶 100ms 的实时性要求;

- 延迟分解:视觉编码 3.43ms + 预填充 16.54ms + 推理解码 70ms + 轨迹解码 8.75ms = 99ms;
- 关键优化:流匹配解码(5 步)替代自回归解码(127 个 token),将轨迹解码延迟从 222ms 降至 8.75ms。
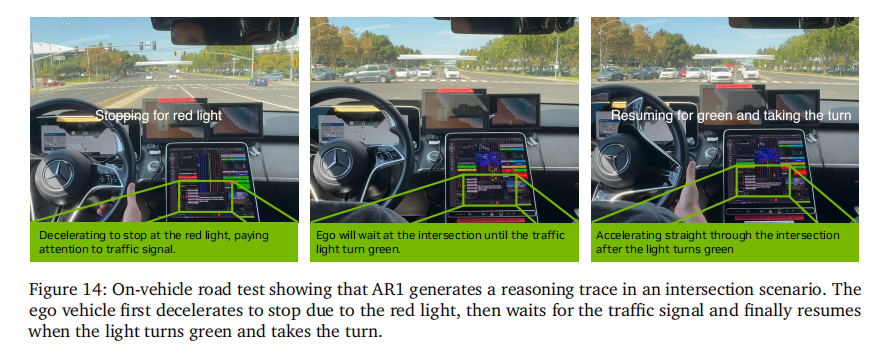
- 道路测试:在城市道路场景中成功实现无人工干预导航,能准确处理路口停车、绿灯起步、避让障碍物等复杂场景(图 14),验证了仿真性能向真实世界的迁移能力。
四、关键分析与未来方向
4.1 核心优势总结
AR1 的成功源于三个关键设计决策的协同作用:
- 数据层面:CoC 数据集通过结构化标注解决了推理数据的因果接地问题,为后续训练提供高质量监督信号;
- 架构层面:模块化设计平衡了通用推理能力与领域适配需求,高效视觉编码和流匹配解码确保了实时部署能力;
- 训练层面:多阶段流程从模态注入到 RL 对齐,逐步解决了 "能推理、会动作、保一致" 的核心问题。
4.2 局限性分析
- 推理触发机制:当前模型对所有场景均生成推理轨迹,未实现自适应推理(仅在关键场景触发),存在计算冗余;
- 决策粒度:驾驶决策集虽覆盖核心场景,但在极端长尾场景(如特殊交通标志、罕见道路事件)的覆盖仍需扩展;
- 世界模型缺失:当前依赖观测直接预测动作,缺乏对环境动态的建模,难以应对高度不确定场景。
4.3 未来研究方向
论文提出四大未来探索方向:
- 分层策略架构:将高层元动作分解为结构化运动原语,进一步提升可解释性和效率;
- 按需推理:设计自适应机制,仅在安全关键或模糊场景中触发推理,优化计算资源分配;
- 辅助任务融合:整合深度估计、场景流预测等自监督任务,提升视觉 backbone 的语义理解能力;
- 世界模型集成:引入学习型世界模型,支持前向仿真和反事实推理,增强动态场景的稳健性。
五、总结
Alpamayo-R1 通过 "因果链数据集 + 模块化 VLA 架构 + 多阶段训练" 的三位一体方案,成功打通了推理与动作预测的壁垒,为端到端自动驾驶提供了新的技术范式。其核心贡献在于:首次实现了结构化因果推理与车辆控制的深度融合,既提升了长尾场景的决策稳健性,又保持了实时部署能力;提出的 CoC 数据集和训练方法,为自动驾驶推理研究提供了可复用的工具链。
实验结果表明,AR1 在开环轨迹预测、闭环驾驶安全、推理质量等维度均显著优于现有方案,真实道路测试进一步验证了其实际部署价值。该研究不仅推动了端到端自动驾驶技术向 L4 级迈进,也为具身智能领域的推理 - 动作融合问题提供了重要参考。随着后续开源模型和数据集的释放,有望进一步激发自动驾驶推理研究的创新浪潮。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 4
4 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)