RoboMirror:视频-到-人形运动中模仿之前先理解
25年12月来自北京智源、悉尼大学、香港科大、哈工大、西安交大、中科院大学、上海交大和北大的论文“RoboMirror: Understand Before You Imitate for Video to Humanoid Locomotion”。人类通过视觉观察学习运动,先解读视觉内容,然后再模仿动作。然而,目前最先进的人形机器人运动系统依赖于精心制作的运动捕捉轨迹或稀疏的文本指令,导致视觉理
25年12月来自北京智源、悉尼大学、香港科大、哈工大、西安交大、中科院大学、上海交大和北大的论文“RoboMirror: Understand Before You Imitate for Video to Humanoid Locomotion”。
人类通过视觉观察学习运动,先解读视觉内容,然后再模仿动作。然而,目前最先进的人形机器人运动系统依赖于精心制作的运动捕捉轨迹或稀疏的文本指令,导致视觉理解与控制之间存在显著差距。文本-到-运动的方法存在语义稀疏性和流程阶段性错误的问题,而基于视频的方法仅能进行机械姿态模仿,缺乏真正的视觉理解。本文提出 RoboMirror,这是首个无需重定向的视频-到-运动(locomotion)框架,体现“先理解后模仿”的理念。它利用视觉语言模型(VLM),将原始的自我为中心/第三人称视角视频提炼成视觉运动意图,这些意图直接影响基于扩散的策略,从而生成物理上合理且语义一致的运动,而无需显式的姿态重建或重定向。大量实验验证 RoboMirror 的有效性,它能够通过以自我为中心的视频实现远程呈现,将第三人称控制延迟大幅降低 80%,并且任务成功率比基线系统提高 3.7%。
人形机器人全身控制。基于模型的全身控制器通过精确的动力学和接触建模,实现精准的任务执行,但建模工作量巨大,且对新技能或未建模动力学的泛化能力有限[7, 41]。基于学习的方法减轻建模负担,但依赖于精心设计的、针对特定任务的奖励;尽管在复杂地形上的移动、跳跃和跌倒恢复等挑战性场景中取得成功[14, 18, 24, 34, 43],但它们需要针对每个任务进行奖励设计,并且通常难以产生协调的、类人的行为。为了区分上肢和下肢的不同目标,一些研究将控制分解为独立的策略[22, 54],但这可能会削弱肢体间的协调性并限制泛化能力。另一些研究则采用分层规划来学习复杂的序列技能,例如乒乓球[42],这提高模块化程度,但也增加设计的复杂性和延迟。全身运动追踪通过直接利用人体运动作为监督信息[11]重新定义目标,消除特定任务的奖励,同时促进跨越多种技能的全局协调、富有表现力的运动。这种视角提供一个统一的控制目标,并为实现类人全身行为提供一条可扩展的途径。
基于模态的人形机器人运动。近期研究探索基于高级模态(其中语言是重要的接口)的人形机器人运动。LangWBC [39] 将一个紧凑的辅助网络与控制策略相结合,以根据指令在线生成运动,但其有限的容量限制其扩展到复杂多样运动分布的能力,并且对未见过提示的泛化能力保证较弱。RLPF [50] 对 LLM 进行微调,并引入来自运动跟踪策略的物理可行性反馈,以迭代地将语义意图与可执行的运动对齐,从而有助于弥合仿真与现实之间的差距;然而,频繁的解码器更新可能会导致预训练知识的灾难性遗忘。RoboGhost [27] 提出一种潜模态驱动、无需重定向的框架,该框架将运动视为生成过程,从而减少误差累积和推理延迟,但它仅将语言作为输入模态。 LeVERB [48] 利用视觉反馈和语言指令,探索视觉-语言引导的全身控制;它依赖于对预收集的运动数据进行重定向,主要关注准静态或低动态任务。
如图所示,无论是第一人称视角还是第三人称视角的视频都包含丰富的环境线索,包括场景属性、时间动态和动作目标。关键洞见在于,这些丰富的视觉证据必须被内化,才能直接影响策略的制定,而不是通过姿态估计简化为僵化的运动学信息。因此,将人形机器人的运动视为一个生成问题:在内化的视觉上下文基础上,合成物理上合理且语义上合理的运动。这种直接的“先理解-后行动”的映射方式解锁以往方法无法实现的两种能力:(1)远程呈现,即第一人称视角的视频演示引导机器人执行相应的运动,从而创造一种“身临其境”的体验;(2)稳健的、无需重定向的第三人称视角模仿,避免传统流程中常见的误差累积问题。
如图所示RoboMirror概述。它采用两阶段框架:首先,利用Qwen3-VL处理以自我为中心或第三人称视角的视频输入,并通过DiT Dθ扩散模型生成运动潜能。随后,在策略学习阶段,使用强化学习训练基于MoE的教师策略,同时在重建的运动潜能指导下,训练基于扩散的学生策略来学习动作去噪。在推理阶段,它无需运动获取和重定向,即可先理解视频中的运动,然后进行模仿。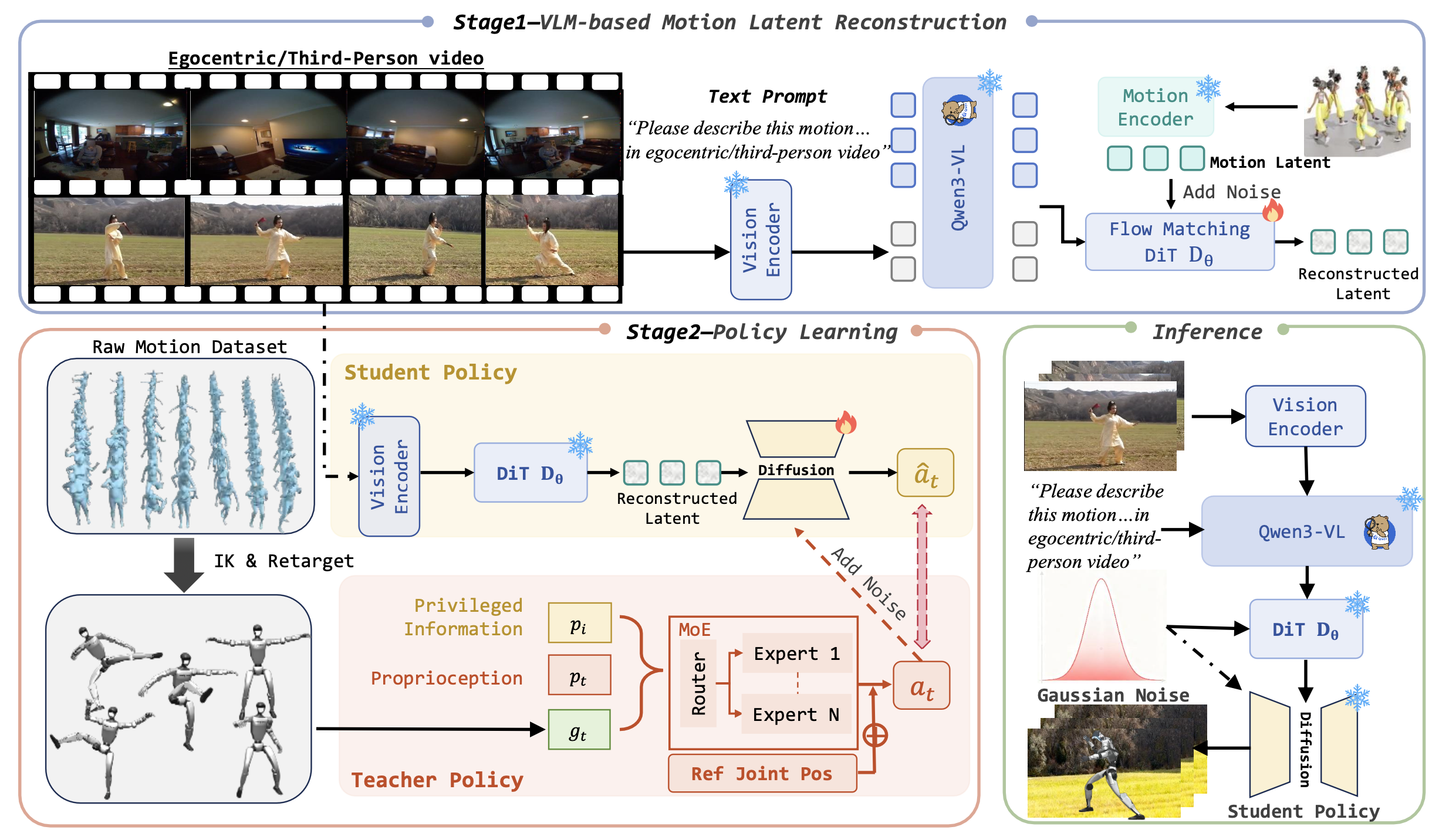
概述
本文提出一种框架,使机器人能够理解视频中的视觉内容,并以连贯的方式执行相应的物理动作。该框架的核心在于,它用运动潜重建取代简单的跨模态对齐。这一选择源于这样一个原则:稳健且语义清晰的视觉-运动映射源于生成式重建,而非表面特征匹配。如上图所示,方法包含三个顺序连接的组件:基于 VLM 的多视角视频理解模块、用于运动潜重建的 VLM 条件扩散模型以及基于扩散的策略训练模块。其解决一个关键挑战:直接从不同视角(第一人称或第三人称)的视频中生成人形机器人可执行的物理动作,从而完全消除对易出错的姿态估计的依赖。
该流程遵循自然的“理解-重建-控制”顺序展开。首先,将输入视频输入到预训练的VLM模型中,该模型提取出编码动作细节和上下文场景信息的高级语义潜变量lVLM。与现有方法简单地将lVLM用作控制信号不同,将该潜变量视为基于扩散的运动潜变量重建器的语义锚点。这种设计源于一个关键洞察:“重建优于对齐”。当模型学习从VLM语义中重建运动学上连贯的运动潜变量时,它不仅实现更鲁棒的跨模态对齐,而且还固有地嵌入物理合理性约束,从而避免直接对齐策略中常见的语义脱节问题。
然后,将重建的运动潜变量l_motion与机器人的本体感觉状态和实时观测数据融合,以生成基于扩散的部署策略π。通过迭代去噪,该策略输出可以直接在人形机器人平台上执行的动作。通过避免显式的运动估计和对齐程序,基于重建的范式实现端到端的视频-到-动作映射,特别适用于可靠性和效率至关重要的实际部署场景。
基于视觉-语言模型的运动潜重建
利用视觉语言模型强大的图像和视频理解能力以及鲁棒的泛化能力,采用 Qwen3-VL [3] 作为视频理解模块。首先,在运动数据集上训练一个 VAE [21] 来重建运动序列。对于视频处理,将第一人称或第三人称视频输入到 Qwen3-VL 中,并附带特定任务的提示。对于第一人称视频,提示为“请描述视频中第一人称人物的运动”,而对于第三人称视频,提示为“请描述视频中的运动”。这种设计确保 Qwen3-VL 输出的潜表示能够包含关于运动内容的高质量语义信息。
为了将运动学信息注入视频潜变量并重建运动表征,采用一种基于流匹配的扩散模型,记为D_θ。该模型以VLM导出的视频潜变量作为条件信号,重建VAE学习的运动潜变量。如上图所示,D_θ由堆叠的Transformer模块组成,并采用自适应层归一化,从而能够在保持运动学结构的同时,有效地对视频语义进行条件化[4]。该模型作用于带噪声的运动潜变量ε_motion,其中交叉注意模块关注视频潜变量lVLM以强制语义一致性,而自注意模块则捕获运动序列中的时间依赖性。
策略训练
基于运动模式的残差运动跟踪器
使机器人能够直接从视频中观察或推断人类运动并执行动作的关键在于运动跟踪器的泛化能力。具体而言,目标是使这些跟踪器能够成功响应新的提示,同时实现真正的部署灵活性,这两个特性对于连接视频理解和现实世界中的机器人运动至关重要。
首先,用 PPO 算法 [37] 结合特权模拟器状态信息训练一个预言教师策略。为了学习一个能够泛化到各种运动输入的策略 π_t,首先在一个高度多样化的运动数据集 D0 [20, 27] 上训练一个初始策略 π_0。考虑到以自我为中心的运动数据集 D_first 相对简单,将 π_0 的训练限制在第三人称视角的运动数据集 D_third 上。
随后,评估 π_0 对每个运动序列 s ∈ D_third 的跟踪精度,尤其关注下肢运动的精度。该评估采用误差指标 e(s) = α · E_key(s) + β · E_dof(s),其中 E_key(s) 表示关键下肢标志点的平均位置误差,E_dof(s) 表示下肢关节角度的平均跟踪误差。过滤掉 e(s) > 0.6 的运动序列,并将剩余的数据 D 用于训练一个可泛化的教师策略。
教师策略 π_t 通过 PPO 算法训练为模拟预言机,利用现实世界中无法获取的特权信息:真实根速度、全局关节位置、物理属性(例如摩擦力、运动强度)、本体感觉状态和参考运动。此外,为了应对复杂的运动,设计的策略侧重于学习动态信息,特别是校正偏移量 δ_a,而不是直接学习运动学信息,例如绝对关节目标 p_target。该偏移量添加到参考运动学轨迹的关节位置,得到最终输出动作 aˆ_t,公式为:aˆ_t = p_target + δ_a。该公式通过累积奖励进行优化,以确保精确的运动跟踪和鲁棒的行为。
此外,集成一个专家混合模型 (MoE)以增强表达能力和泛化能力。该策略包含专家网络和一个门控网络,该门控网络接收相同的输入,并计算专家输出的权重,以形成加权和。最终动作计算如下:aˆ_t = sum (p_i · a_i),其中 p_i 表示专家 i 的门控概率,a_i 是其对应的输出。这种设计增强泛化能力,提高跟踪精度,并实现对学生策略的精确监督。
基于扩散的学生策略
与以往通过显式参考运动从教师那里提取知识的学生策略不同,将学生策略视为一个生成模型,并将其构建为一个潜驱动的生成任务 [27]。它以视频潜引导下生成的运动潜信息以及观测历史作为输入,生成类人机器人动作。这种设计使机器人能够更快地模仿视频中目标的运动,绕过姿态估计和运动重定向等容易出错的步骤,从而显著降低了整个过程的耗时。
遵循类似 DAgger 的范式,在模拟环境中运行来训练学生模型,并向教师模型查询在可观测状态下的最优动作 aˆ_t。在训练过程中,将高斯噪声 ε_t 注入教师模型的动作中,并使用从视频潜变量中重构的潜变量 l_v2m 作为引导潜变量。噪声注入过程遵循马尔可夫链。
步骤 t 的去噪建模为 x_t−1 = ε_θ(x_t,t),其中 ε_θ 为去噪器。用 x0 预测策略,并通过均方误差损失方式进行监督。收敛的策略不需要任何特权知识或显式参考,从而可以实际部署。
推理流程
为了确保流畅的运动,采用 DDIM 采样 [40] 和基于 MLP 的扩散模型进行动作生成来最大限度地减少去噪时间。
在推理过程中,流程如下:首先,将自我为中心或第三人称视角的视频输入到 Qwen3-VL 模型中,以获得视频潜表示 l_vlm。然后,将该视频潜表示 l_vlm 输入到预训练的扩散模型 D_θ 中,生成富含运动学语义的运动潜表示 l_v2m。最后,用 l_v2m 作为条件信号来指导基于扩散的学生策略,该策略直接生成可部署的动作。
值得注意的是,该流程无需从第三人称视角视频中进行姿态估计,也无需从以自我为中心的视频中进行运动猜测。通过利用视频潜表示 (VLM) 的视频理解能力和策略的潜理解能力,成功实现视频-到-运动的转换,使机器人能够模仿输入视频中存在的稀疏和密集运动模态。
数据集:用 Nymeria [32] 和 Motion-X [30] 数据集训练模型。 Nymeria 是一个大规模的实物设备数据集,捕捉室内外各种人类日常活动,提供文本-视频-动作配对数据,包括以自我为中心的视频、全身动作以及人工标注的动作叙述。该数据集包含约 1000 个视频,每个视频时长约 15-20 分钟。由于其规模庞大,从中选取 100 个视频,并将每个视频分割成 5 秒的片段,最终得到 18000 个视频-动作配对。动作和视频的采样率均为 30 FPS。Motion-X 是一个大规模的 3D 表现力丰富的全身动作数据集,由海量在线视频和八个现有的动作数据集构建而成,动作格式为 SMPL-X。从中选择与视频配对的动作类别作为第三人称数据集。将数据集按 8:2 的比例划分为训练集和测试集。
实现细节:首先将视频输入到预训练的视频理解模型(VLM)中,以获取视频潜信息,其中使用 Qwen3-VL-4B-Instruct 模型。对于运动潜信息重建网络,采用一个 16 层多层感知器(MLP)作为骨干网络,并通过 AdaLN [19] 注入条件,以指导模型从高斯噪声中重建运动潜信息。在策略训练方面,教师策略采用由 5 位专家组成的 MoE 结构,学生策略则采用以 4 层 MLP 为骨干网络的扩散模型;这种紧凑的网络架构结合 DDIM 采样,确保部署过程中的实时性能。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 24
24 0
0- 0



 已为社区贡献211条内容
已为社区贡献211条内容

所有评论(0)